아키텍처
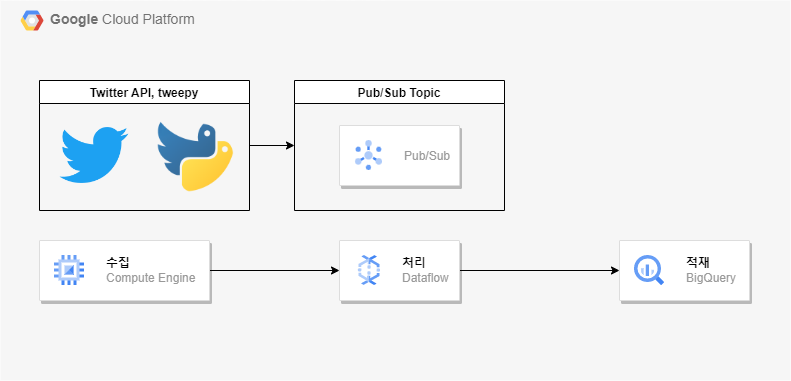
우선 Twitter API를 통해 ACCESS 및 Bearer Token 등을 받아온 상태여야 한다.
해당 과정은 Twitter API 이 포스팅을 참고하면 된다.
이 키가 내 트위터 계정에 대한 정보를 잘 받아오는 지 확인하려면 아래 명령어를 실행시켜보면 된다.
curl "https://api.twitter.com/2/users/by/username/<계정 이름>" -H "Authorization: Bearer <Bearer Token>"
잘 받아오는 것 확인.
그리고 GCP 콘솔에서 아래 리소스들을 생성해준다.
- VM 생성 (나는 Ubuntu 20.04를 사용했다.)
- PubSub 주제와 기본 구독 생성
- twitter_data 데이터 세트 생성
- Cloud Storage 버킷 생성
venv 세팅
VM 접속
서비스 계정 키를 import하고 환경 변수에 등록
export GOOGLE_AUTH_CREDENTIALS=<서비스 계정 Key 파일 경로># python 가상환경 설치
sudo apt update
sudo apt install python3-venv
python3 -m venv <설정할 가상환경 이름>
# 가상환경 접속
source <설정해준 가상환경 이름>/bin/activate
# 가상환경에 필요한 라이브러리 설치
pip install --upgrade pip
pip install google-cloud-pubsub
pip install tweepy
pip install apache-beam[gcp]
데이터 수집
아래 코드를 실행시켜 twitter API에서 넷플릭스에 관한 정보를 Pub/Sub으로 가져와보자.
stream_to_pubsub.py
import argparse
import json
from google.cloud import pubsub_v1
import tweepy
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--bearer_token', type=str, required=True)
parser.add_argument('--stream_rule', type=str, required=True)
parser.add_argument('--project_id', type=str, required=True)
parser.add_argument('--topic_id', type=str, required=True)
return parser.parse_args()
def write_to_pubsub(data, stream_rule):
data["stream_rule"] = stream_rule
data_formatted = json.dumps(data).encode("utf-8")
id = data["id"].encode("utf-8")
author_id = data["author_id"].encode("utf-8")
future = publisher.publish(
topic_path, data_formatted, id=id, author_id=author_id
)
print(future.result())
class Client(tweepy.StreamingClient):
def __init__(self, bearer_token, stream_rule):
super().__init__(bearer_token)
self.stream_rule = stream_rule
def on_response(self, response):
tweet_data = response.data.data
user_data = response.includes['users'][0].data
result = tweet_data
result["user"] = user_data
write_to_pubsub(result, self.stream_rule)
if __name__ == "__main__":
tweet_fields = ['id', 'text', 'author_id', 'created_at', 'lang']
user_fields = ['description', 'created_at', 'location']
expansions = ['author_id']
args = parse_args()
streaming_client = Client(args.bearer_token, args.stream_rule)
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(args.project_id, args.topic_id)
# remove existing rules
rules = streaming_client.get_rules().data
if rules is not None:
existing_rules = [rule.id for rule in streaming_client.get_rules().data]
streaming_client.delete_rules(ids=existing_rules)
# add new rules and run stream
streaming_client.add_rules(tweepy.StreamRule(args.stream_rule))
streaming_client.filter(tweet_fields=tweet_fields, expansions=expansions, user_fields=user_fields)stream_to_pubsub.py 실행
난 Netflix에 관한 트윗을 추출하고 싶어서 필터링할 키워드에 Netflix를 넣어줬다.
nohup python3 stream_to_pubsub.py --bearer_token "<Bearer token>" --stream_rule <필터링할 키워드> --project_id "<프로젝트 ID>" --topic_id "<Pub/Sub 주제>" &Pub/Sub 구독에서 메시지를 가져와보면 데이터를 잘 가져오고 있는 것을 확인할 수 있다.
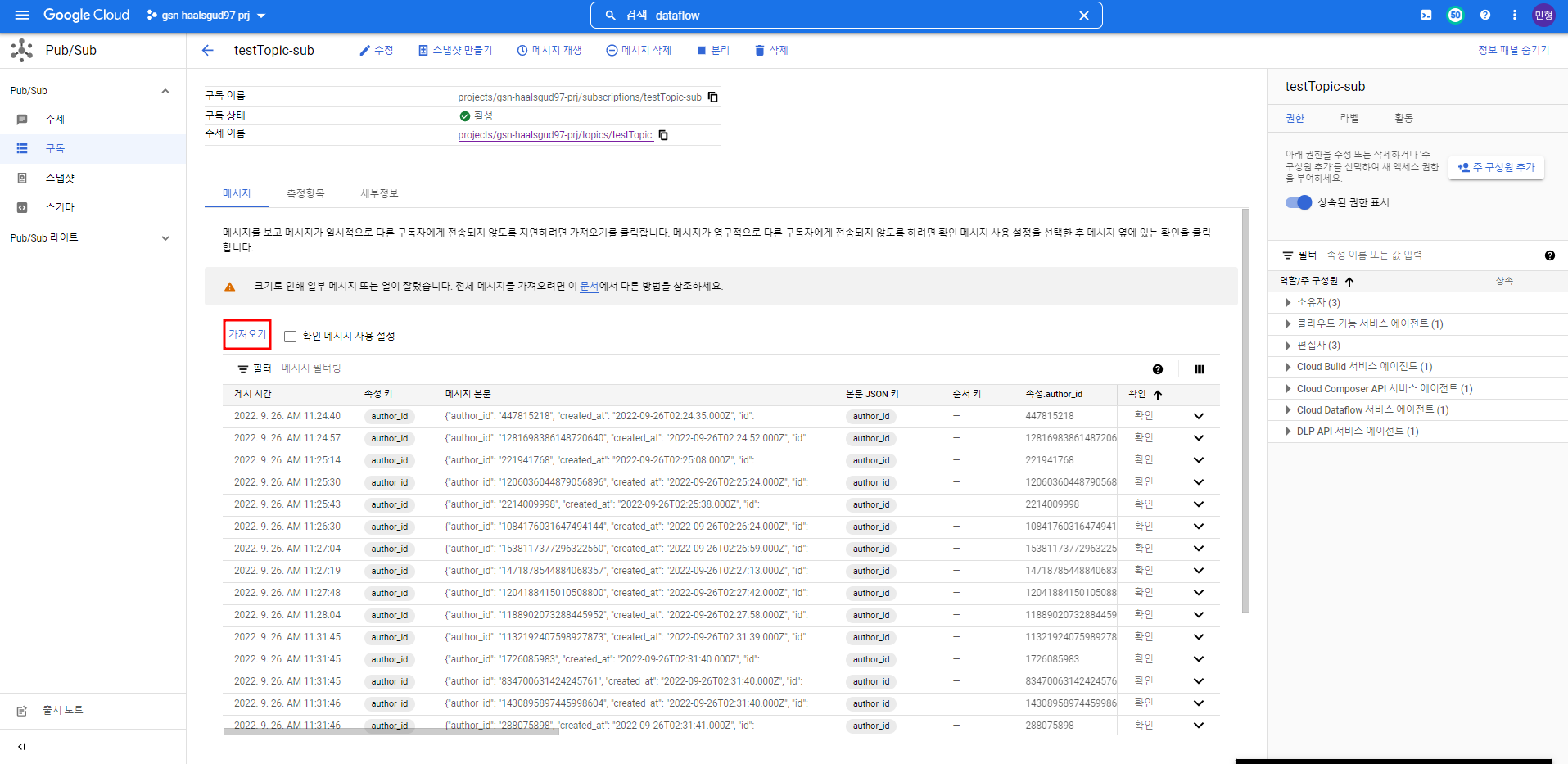
파이프라인 실행
이제 실시간으로 Pub/Sub으로 받아오는 정보들을 Dataflow 파이프라인을 통해 빅쿼리에 적재하는 파일을 실행시킬 것이다.
pipeline.py
import argparse
import json
import typing
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import GoogleCloudOptions
from apache_beam.transforms.combiners import CountCombineFn
class GetTimestamp(beam.DoFn):
def process(self, element, window=beam.DoFn.WindowParam):
window_start = window.start.to_utc_datetime().strftime("%Y-%m-%dT%H:%M:%S")
output = {'timestamp': window_start, 'language': element.lang, 'tweet_count': element.tweet_count}
yield output
class PerLangAggregation(typing.NamedTuple):
lang: str
tweet_count: int
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--project_id', type=str, required=True)
parser.add_argument('--input_topic', type=str, required=True)
return parser.parse_known_args()
def run():
# Setting up the Beam pipeline options
args, pipeline_args = parse_args()
options = PipelineOptions(pipeline_args, save_main_session=True, streaming=True)
options.view_as(GoogleCloudOptions).project = args.project_id
output_table_name = "raw_tweets"
agg_output_table_name = "minute_level_counts"
dataset = "twitter_data"
window_size = 60
raw_tweets_schema = {
"fields": [
{
"name": "author_id",
"type": "STRING"
},
{
"name": "created_at",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "id",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "lang",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "stream_rule",
"type": "STRING",
},
{
"name": "text",
"type": "STRING",
},
{
"name": "user",
"type": "RECORD",
"mode": "NULLABLE",
"fields": [
{
"name": "created_at",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "description",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "id",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "location",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "name",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "username",
"type": "STRING",
"mode": "NULLABLE"
},
]
},
]
}
agg_tweets_schema = {
"fields": [
{
"name": "timestamp",
"type": "STRING"
},
{
"name": "language",
"type": "STRING",
},
{
"name": "tweet_count",
"type": "STRING",
}
]
}
# Create the pipeline
p = beam.Pipeline(options=options)
raw_tweets = (p | "ReadFromPubSub" >> beam.io.ReadFromPubSub(args.input_topic)
| "ParseJson" >> beam.Map(lambda element: json.loads(element.decode("utf-8")))
)
# write raw tweets to BQ
raw_tweets | "Write raw to bigquery" >> beam.io.WriteToBigQuery(
output_table_name,
dataset=dataset,
project=args.project_id,
schema=raw_tweets_schema,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND,
)
# aggregate tweets by window and write to BQ
(raw_tweets
| "Window" >> beam.WindowInto(beam.window.FixedWindows(window_size))
| "Aggregate per language" >> beam.GroupBy(lang=lambda x: x["lang"])
.aggregate_field(lambda x: x["lang"], CountCombineFn(), 'tweet_count')
| "Add Timestamp" >> beam.ParDo(GetTimestamp())
| "Write agg to bigquery" >> beam.io.WriteToBigQuery(
agg_output_table_name,
dataset=dataset,
project=args.project_id,
schema=agg_tweets_schema,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND,
)
)
p.run().wait_until_finish()
if __name__ == "__main__":
run()파이프라인 실행
python3 pipeline.py \
--project_id "<프로젝트 ID>" \
--input_topic "projects/<프로젝트 ID>/topics/<Pub/Sub 주제>" \
--runner DataflowRunner \
--staging_location "gs://<위에서 생성해준 버킷 이름>/stg" \
--temp_location "gs://<위에서 생성해준 버킷 이름>/temp" \
--region <리전>
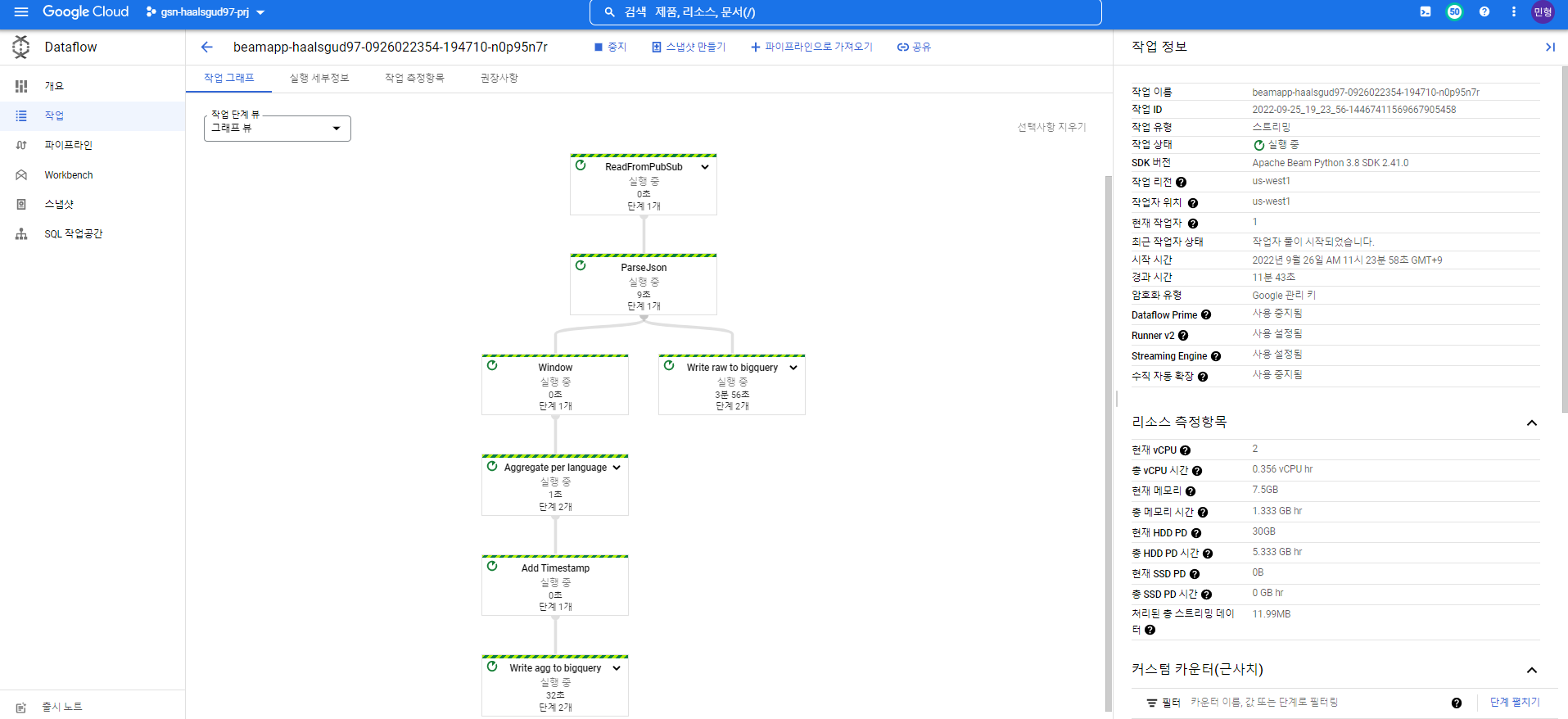
Dataflow가 정상적으로 실행중인 것 확인
나라별로 Netflix관련 트윗들을 분 단위로 가져오는 테이블
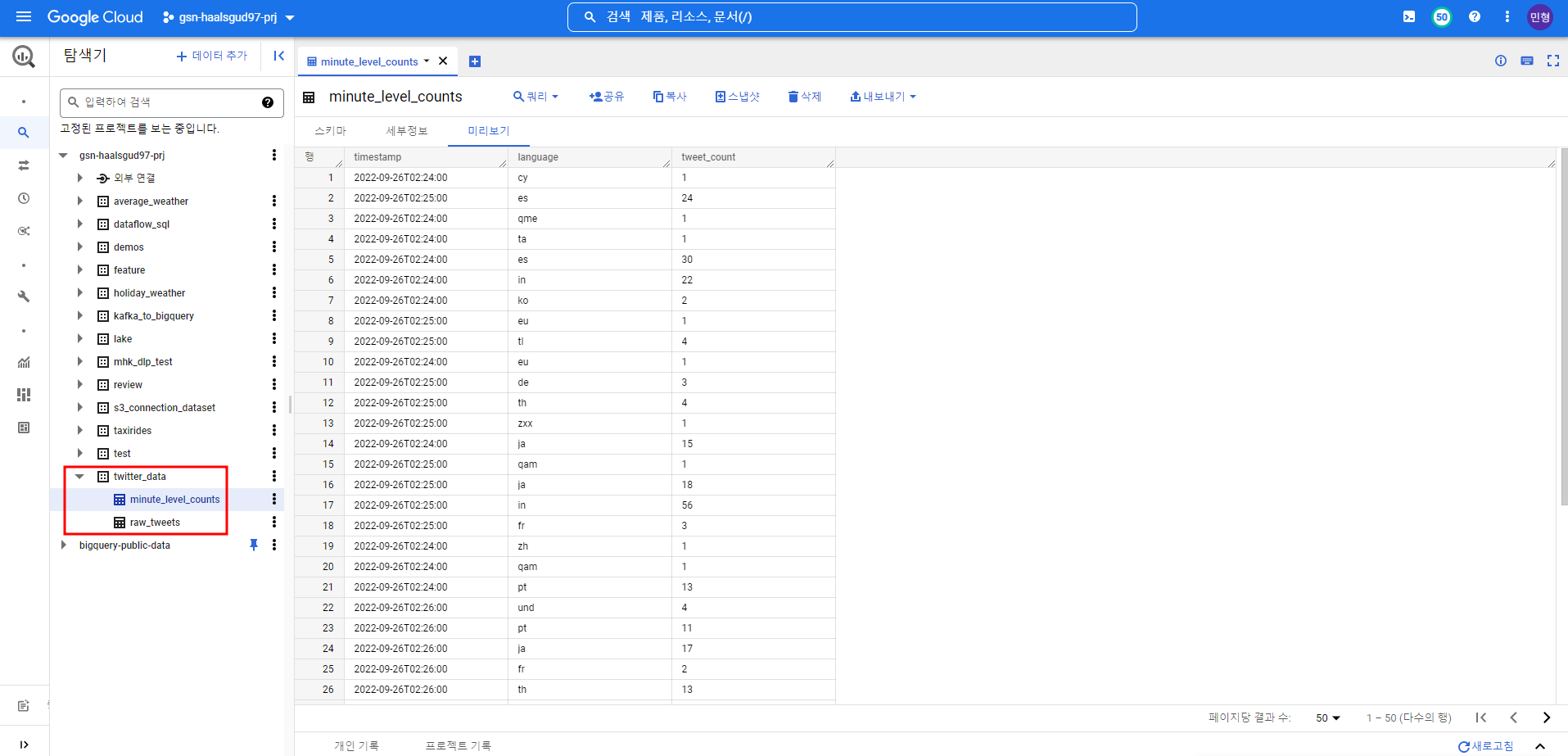
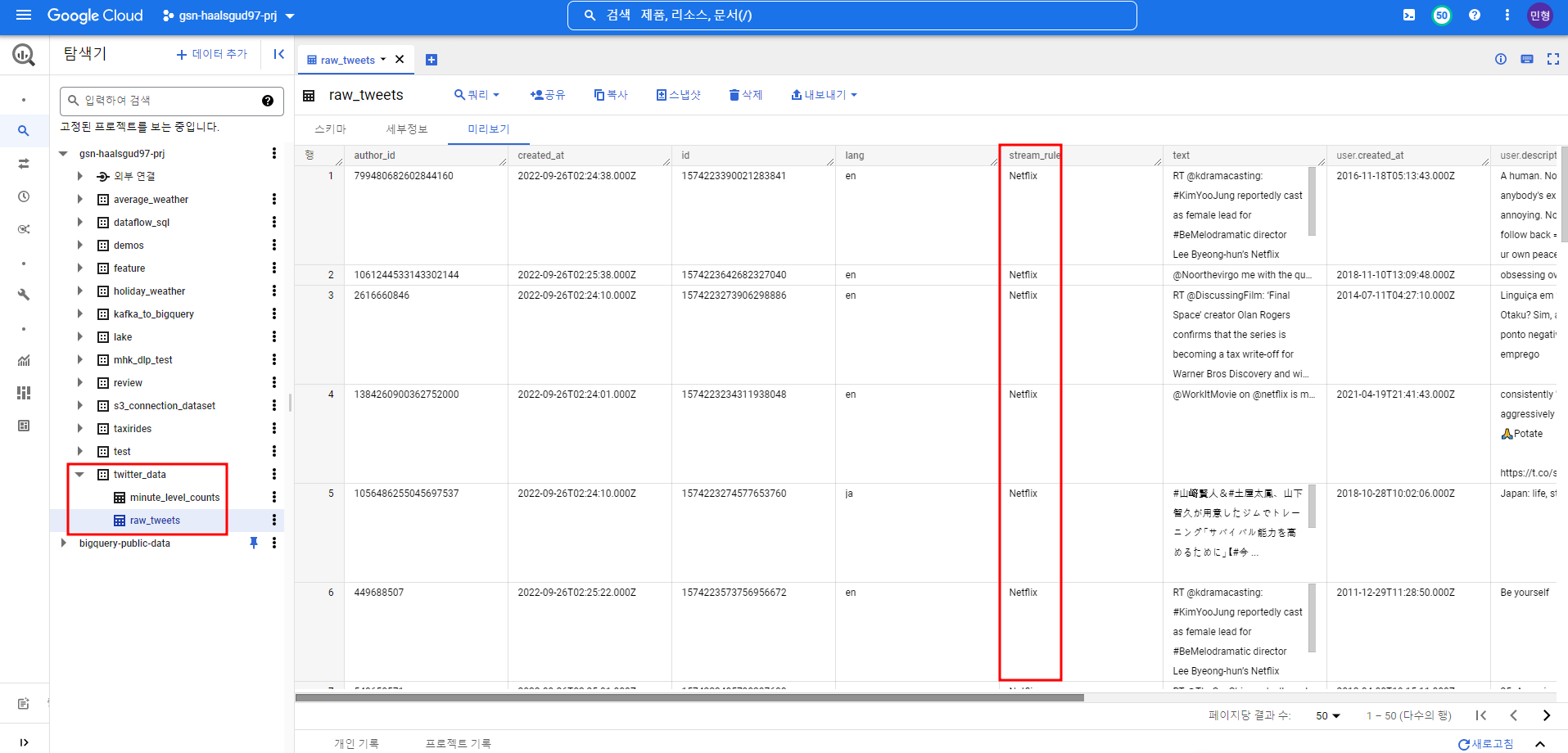
Netflix 관련 트윗 내용 및 해당 트윗 계정, 생성시간 등의 정보를 가져오는 테이블
[Twitter API를 사용한 스트리밍 파이프라인 구축 참고]
https://dsstream.com/streaming-twitter-data-with-google-cloud-pub-sub-and-apache-beam/

AI Solutions Architect