아키텍처
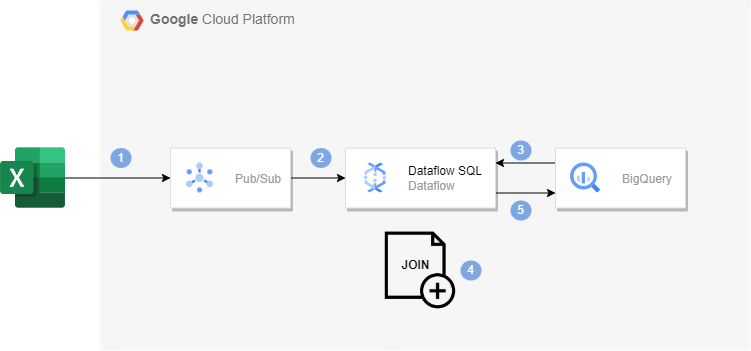
Dataflow SQL을 사용해 Pub/Sub 스트리밍 데이터를 BigQuery 테이블 데이터와 join해볼 것이다.
빅쿼리 테이블 생성
빅쿼리에 데이터 세트를 만들어주고 us_state_salesregions 테이블을 만들어준다.
us_staste_salesregions.csv
state_id,state_code,state_name,sales_region
1,MO,Missouri,Region_1
2,SC,South Carolina,Region_1
3,IN,Indiana,Region_1
6,DE,Delaware,Region_2
15,VT,Vermont,Region_2
16,DC,District of Columbia,Region_2
19,CT,Connecticut,Region_2
20,ME,Maine,Region_2
35,PA,Pennsylvania,Region_2
38,NJ,New Jersey,Region_2
47,MA,Massachusetts,Region_2
54,RI,Rhode Island,Region_2
55,NY,New York,Region_2
60,MD,Maryland,Region_2
66,NH,New Hampshire,Region_2
4,CA,California,Region_3
8,AK,Alaska,Region_3
37,WA,Washington,Region_3
61,OR,Oregon,Region_3
33,HI,Hawaii,Region_4
59,AS,American Samoa,Region_4
65,GU,Guam,Region_4
5,IA,Iowa,Region_5
32,NV,Nevada,Region_5
11,PR,Puerto Rico,Region_6
17,CO,Colorado,Region_6
18,MS,Mississippi,Region_6
41,AL,Alabama,Region_6
42,AR,Arkansas,Region_6
43,FL,Florida,Region_6
44,NM,New Mexico,Region_6
46,GA,Georgia,Region_6
48,KS,Kansas,Region_6
52,AZ,Arizona,Region_6
56,TN,Tennessee,Region_6
58,TX,Texas,Region_6
63,LA,Louisiana,Region_6
7,ID,Idaho,Region_7
12,IL,Illinois,Region_7
13,ND,North Dakota,Region_7
31,MN,Minnesota,Region_7
34,MT,Montana,Region_7
36,SD,South Dakota,Region_7
50,MI,Michigan,Region_7
51,UT,Utah,Region_7
64,WY,Wyoming,Region_7
9,NE,Nebraska,Region_8
10,VA,Virginia,Region_8
14,OK,Oklahoma,Region_8
39,NC,North Carolina,Region_8
40,WV,West Virginia,Region_8
45,KY,Kentucky,Region_8
53,WI,Wisconsin,Region_8
57,OH,Ohio,Region_8
49,VI,United States Virgin Islands,Region_9
62,MP,Commonwealth of the Northern Mariana Islands,Region_9이 csv파일을 갖고 테이블을 생성해줄 것이다.


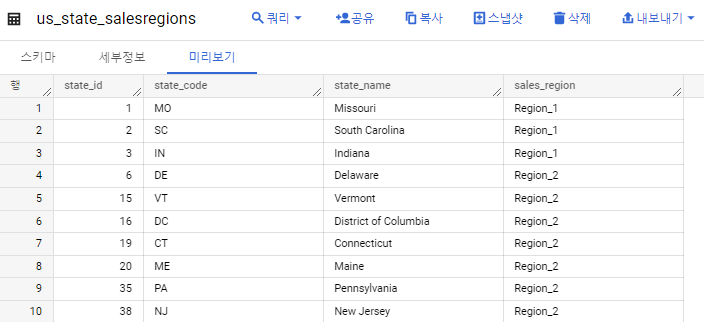
테이블 확인
Pub/Sub 주제에 스키마 할당
Pub/Sub 주제를 만들어주면서 스키마를 할당해줄 수 있다.
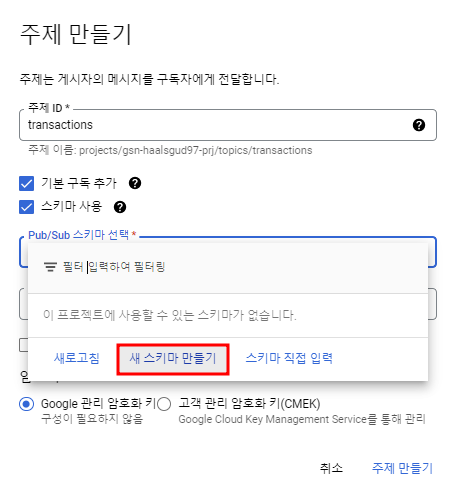
콘솔에선 AVRO 형식만 지원이 된다.
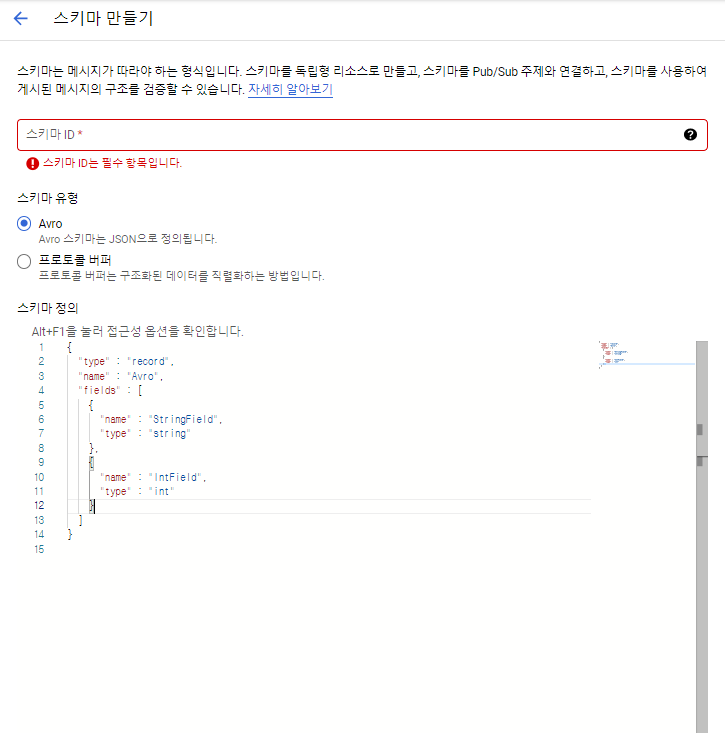
여기선 YAML 형식으로 넣어줄 것이다.
(YAML형식으로 넣어주는 것은 CLI로만 가능)
Data Catalog를 활용해 Pub/Sub에 yaml형식으로 스키마를 넣어줄 수 있다.
transactions_schema.yaml
- column: event_timestamp
description: Pub/Sub event timestamp
mode: REQUIRED
type: TIMESTAMP
- column: tr_time_str
description: Transaction time string
mode: NULLABLE
type: STRING
- column: first_name
description: First name
mode: NULLABLE
type: STRING
- column: last_name
description: Last name
mode: NULLABLE
type: STRING
- column: city
description: City
mode: NULLABLE
type: STRING
- column: state
description: State
mode: NULLABLE
type: STRING
- column: product
description: Product
mode: NULLABLE
type: STRING
- column: amount
description: Amount of transaction
mode: NULLABLE
type: FLOATCloud Shell에서 위의 파일을 저장한 후 아래의 명령어 실행
gcloud data-catalog entries update \
--lookup-entry='pubsub.topic.`<프로젝트 ID>`.transactions' \
--schema-from-file=<transactions_schema.yaml 경로>내가 권한이 있는 프로젝트들 내에서 Pub/Sub 주제를 만들면 Data Catalog에서 확인할 수 있다.
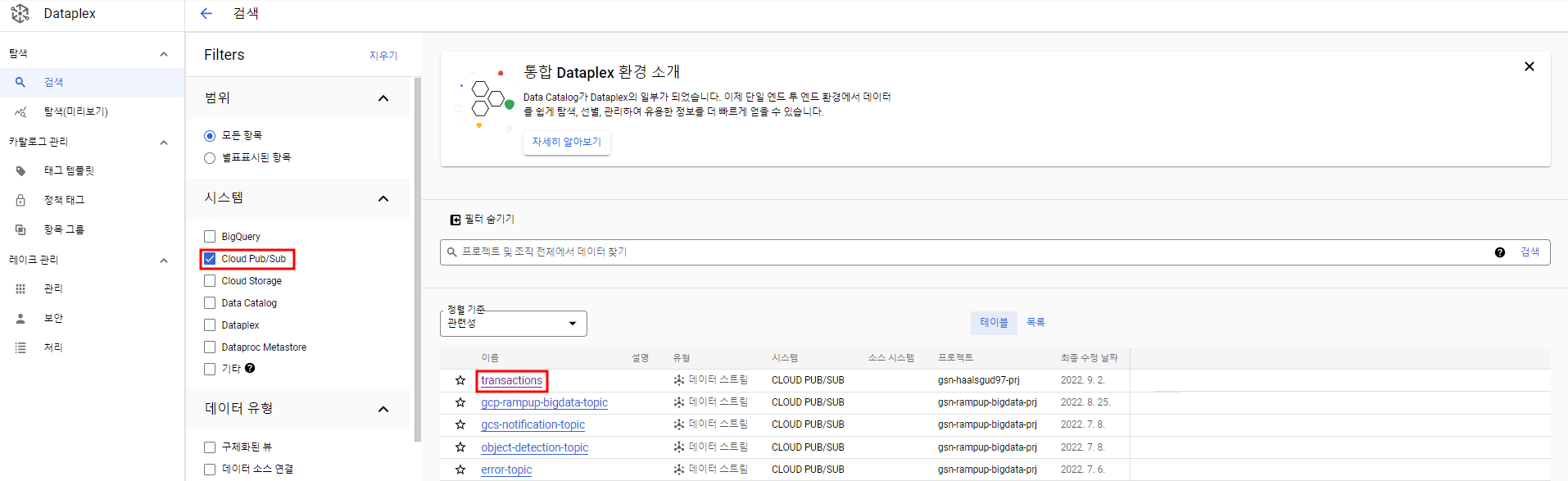
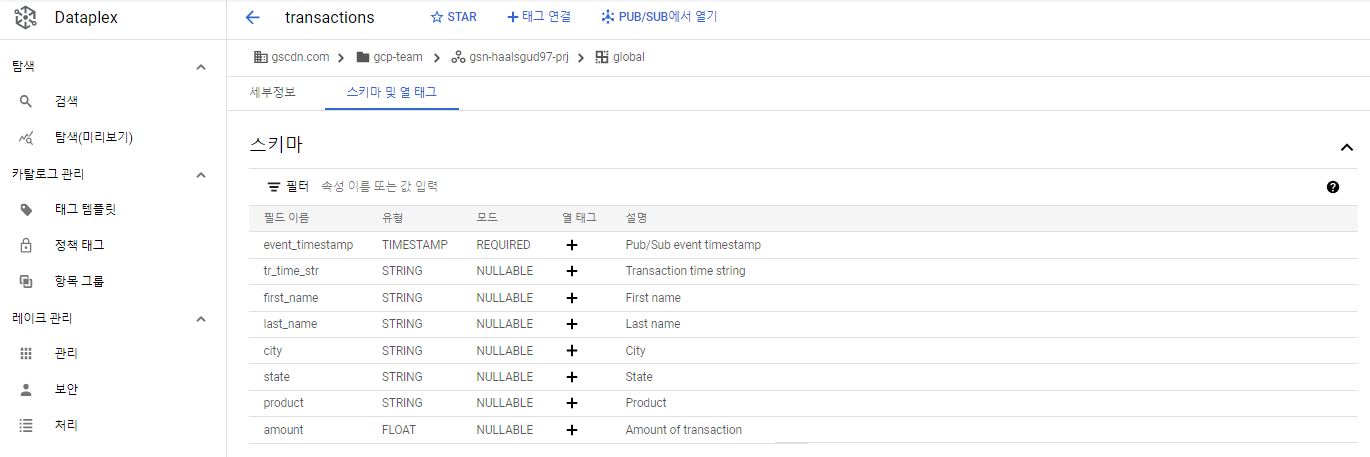
Dataflow SQL UI에서 만들어준 Pub/Sub 소스를 찾아볼 수 있다
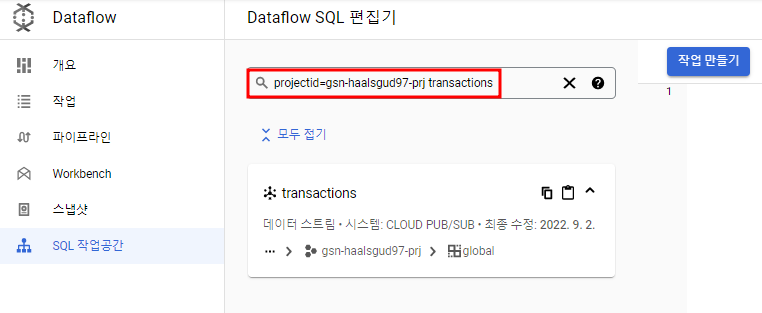
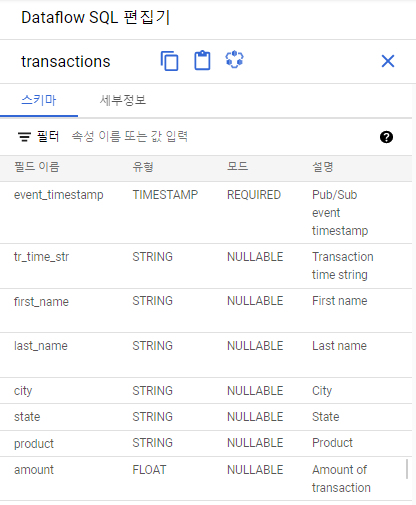
Dataflow 작업을 실행하는 SQL 쿼리 작성
Pub/Sub 주제에 메시지를 게시하는 Python 스크립트
transactions_injector.py
#!/usr/bin/env python
import datetime, json, os, random, time
# Set the `project` variable to a Google Cloud project ID.
project = '<프로젝트 ID>'
FIRST_NAMES = ['Monet', 'Julia', 'Angelique', 'Stephane', 'Allan', 'Ulrike', 'Vella', 'Melia',
'Noel', 'Terrence', 'Leigh', 'Rubin', 'Tanja', 'Shirlene', 'Deidre', 'Dorthy', 'Leighann',
'Mamie', 'Gabriella', 'Tanika', 'Kennith', 'Merilyn', 'Tonda', 'Adolfo', 'Von', 'Agnus',
'Kieth', 'Lisette', 'Hui', 'Lilliana',]
CITIES = ['Washington', 'Springfield', 'Franklin', 'Greenville', 'Bristol', 'Fairview', 'Salem',
'Madison', 'Georgetown', 'Arlington', 'Ashland',]
STATES = ['MO','SC','IN','CA','IA','DE','ID','AK','NE','VA','PR','IL','ND','OK','VT','DC','CO','MS',
'CT','ME','MN','NV','HI','MT','PA','SD','WA','NJ','NC','WV','AL','AR','FL','NM','KY','GA','MA',
'KS','VI','MI','UT','AZ','WI','RI','NY','TN','OH','TX','AS','MD','OR','MP','LA','WY','GU','NH']
PRODUCTS = ['Product 2', 'Product 2 XL', 'Product 3', 'Product 3 XL', 'Product 4', 'Product 4 XL', 'Product 5',
'Product 5 XL',]
while True:
first_name, last_name = random.sample(FIRST_NAMES, 2)
data = {
'tr_time_str': datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
'first_name': first_name,
'last_name': last_name,
'city': random.choice(CITIES),
'state':random.choice(STATES),
'product': random.choice(PRODUCTS),
'amount': float(random.randrange(50000, 70000)) / 100,
}
# For a more complete example on how to publish messages in Pub/Sub.
# https://cloud.google.com/pubsub/docs/publisher
message = json.dumps(data)
command = "gcloud --project={} pubsub topics publish transactions --message='{}'".format(project, message)
print(command)
os.system(command)
time.sleep(random.randrange(1, 5))Cloud Shell은 Python이 설치되어 있으므로 Cloud Shell에서 파일을 만들고 실행해주자.
python transactions_injector.py
Dataflow SQL UI의 검사기를 통해 쿼리 구문 확인
SELECT tr.*, sr.sales_region
FROM pubsub.topic.`<프로젝트 ID>`.transactions as tr
INNER JOIN bigquery.table.`<프로젝트 ID>`.<데이터 세트>.us_state_salesregions AS sr
ON tr.state = sr.state_code유효한 쿼리인 것 확인
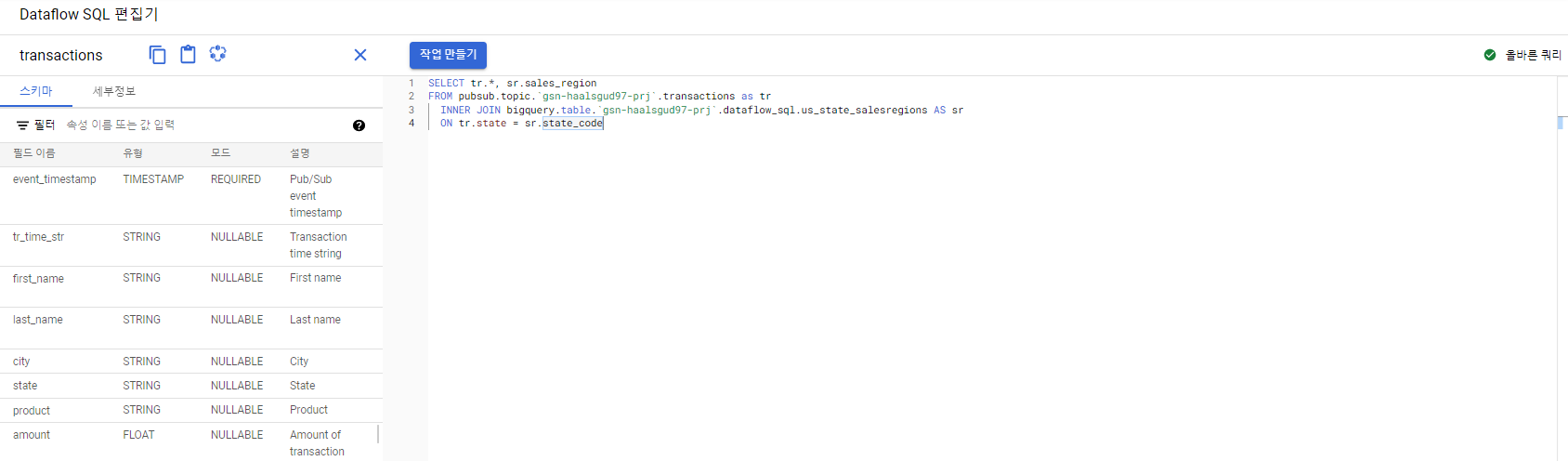
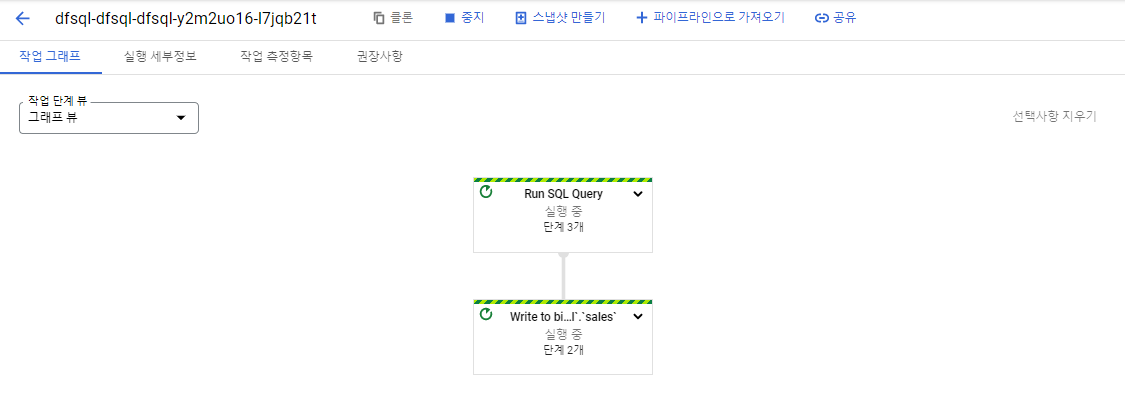
Dataflow SQL UI에서 작업 생성
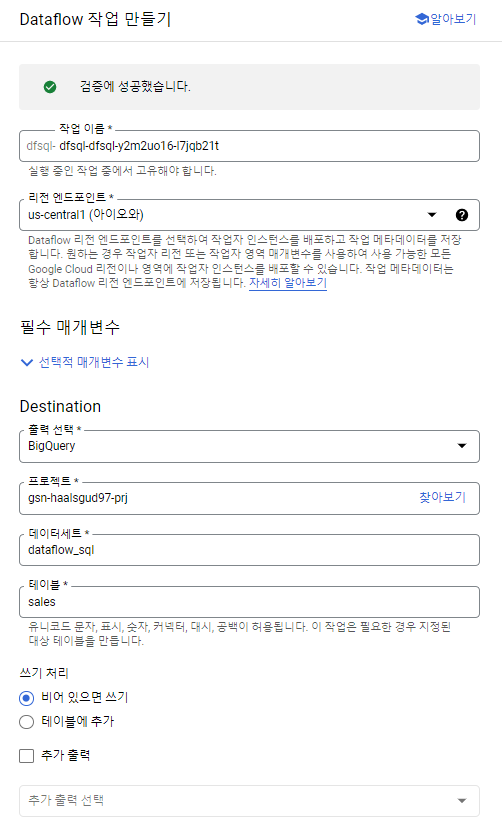
Dataflow에서 작업을 확인할 수 있다.
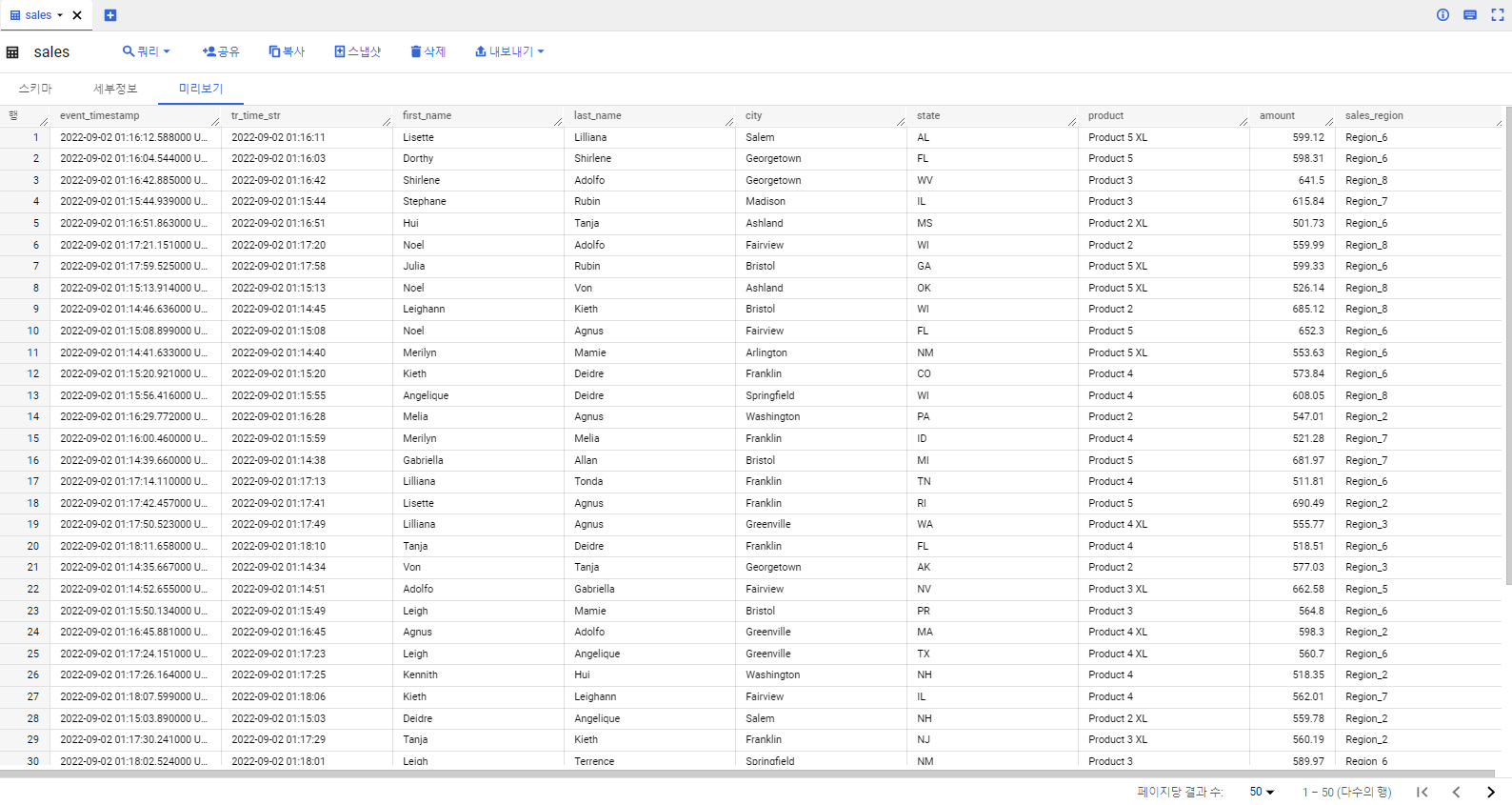
기존에 빅쿼리에 있던 데이터와 Pub/Sub을 통해 스트리밍으로 들어오는 데이터들이 join해서 Sales라는 테이블에 적재된 것을 확인할 수 있다.
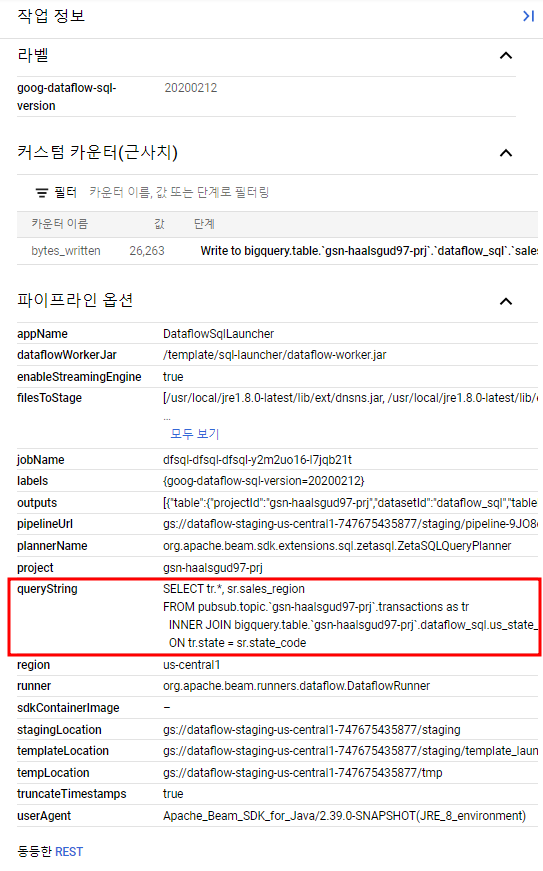
Dataflow 작업 정보를 보면 QueryString에서 내가 실행한 데이터 처리에 관한 쿼리를 확인할 수 있다.