아키텍처
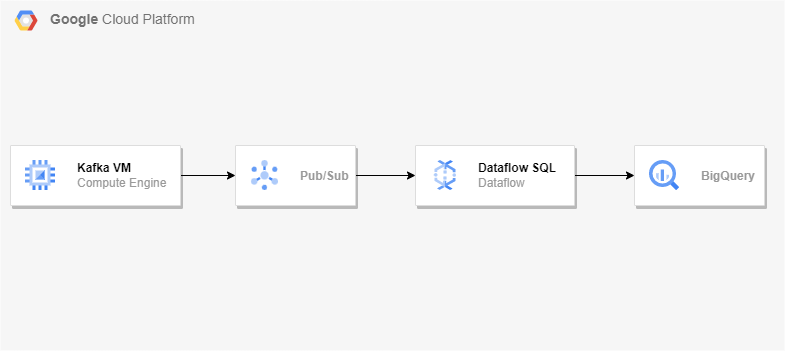
Kafka 설정
우분투 VM 하나 생성 후 2181 2888 3888 9092 포트 방화벽을 열어준다.
2181 2888 3888은 zookeeper가 사용, 9092는 kafka가 사용.
zookeeper와 kafka는 java를 필요로 하므로 jdk 설치
sudo apt update
sudo apt install default-jdkApache Kafka 다운로드
Kafka downloads 링크
Kafka downloads 링크에서 3.2.0 버전을 받아올 것이다.
wget https://archive.apache.org/dist/kafka/3.2.0/kafka_2.13-3.2.0.tgz
# 아카이브 파일 압축 해제
tar xzf kafka_2.13-3.2.0.tgz
sudo mv kafka_2.13-3.2.0 /usr/local/kafkakafka와 zookeeper를 systemctl 명령을 사용하여 시작/중지하도록 설정
zookeeper
sudo vim /etc/systemd/system/zookeeper.service아래의 내용 추가
[Unit]
Description=Apache Zookeeper server
Documentation=http://zookeeper.apache.org
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties
ExecStop=/usr/local/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetkafka
sudo vim /etc/systemd/system/kafka.service아래의 내용 추가
[Unit]
Description=Apache Kafka Server
Documentation=http://kafka.apache.org/documentation.html
Requires=zookeeper.service
[Service]
Type=simple
Environment="JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64"
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
[Install]
WantedBy=multi-user.target새로운 변경사항을 적용하기 위해 systemd 데몬 reload
sudo systemctl daemon-reloadkafka 시작
sudo systemctl start zookeeper
sudo systemctl start kafka
sudo systemctl status kafka빅쿼리에서 kafka_to-bigquery 데이터세트와 transactions 테이블을 하나 만들어줄 것이다.
(transaction_time을 기준으로 파티션)
테이블 스키마
[
{
"description": "Transaction time",
"name": "transaction_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"description": "First name",
"name": "first_name",
"type": "STRING",
"mode": "REQUIRED"
},
{
"description": "Last name",
"name": "last_name",
"type": "STRING",
"mode": "REQUIRED"
},
{
"description": "City",
"name": "city",
"type": "STRING",
"mode": "NULLABLE"
},
{
"description": "List of products",
"name": "products",
"type": "RECORD",
"mode": "REPEATED",
"fields": [
{
"description": "Product name",
"name": "product_name",
"type": "STRING",
"mode": "REQUIRED"
},
{
"description": "Product price",
"name": "product_price",
"type": "FLOAT64",
"mode": "NULLABLE"
}
]
}
]kafka 주제 생성
/usr/local/kafka/bin/kafka-topics.sh --create --bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 --topic <kafka 주제>
# 주제 list를 나열해 생성되었는지 확인
/usr/local/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092
주제에 보낼 메시지 생성
message.json
{
"transaction_time": "2022-09-16 15:14:54",
"first_name": "minhyoung",
"last_name": "Kim",
"products": [
{
"product_name": "Pixel 4",
" product_price": 799.5
},
{
"product_name": "Pixel Buds 2",
"product_price": 179
}
]
}kafka 메시지 키를 추가하고 jq를 사용해 message.json 압축하여 kafka 주제에 메시지 전송
sudo apt-get install jq
(echo -n "1|"; cat message.json | jq . -c) | /usr/local/kafka/bin/kafka-console-producer.sh \
--broker-list localhost:9092 \
--topic <kakfa 주제> \
--property "parse.key=true" \
--property "key.separator=|"kafka Connect 설정
Pub/Sub 주제를 하나 생성해준다.
그리고 Pub/Sub 주제에 해당하는 서비스 계정 키를 다운받은 후에 VM에 넣어주고 해당 키 파일 경로를 환경 변수로 등록해주자.
export GOOGLE_APPLICATION_CREDENTIALS=<키 파일 경로>kafka Connect를 통해 Pub/Sub과 메시지를 동기화할 것이다.
sudo apt install git-all
sudo apt install maven
git clone https://github.com/GoogleCloudPlatform/pubsub
cd pubsub/kafka-connector/
mvn package
sudo mkdir /usr/local/kafka/connectors/
sudo cp target/pubsub-kafka-connector.jar /usr/local/kafka/connectors/
sudo cp config/cps-sink-connector.properties /usr/local/kafka/config//kafka/config/cps-link-connector.properties 파일 수정
아래의 설정들 추가
name=CPSSinkConnector
connector.class=com.google.pubsub.kafka.sink.CloudPubSubSinkConnector
tasks.max=10
topic=<kafka 주제>
cps.topic=<Pub/Sub 주제>
cps.project= <프로젝트 ID>/kafka/config/connect-standalone.properties 파일 수정
Kafka Connect가 이전에 패키징하고 복사한 cps-kafka-connector.jar파일을 찾을 수 있도록 plugin.path의 주석을 제거하고 편집해주고 아래 사진과 같이 추가로 설정들을 변경해준다.
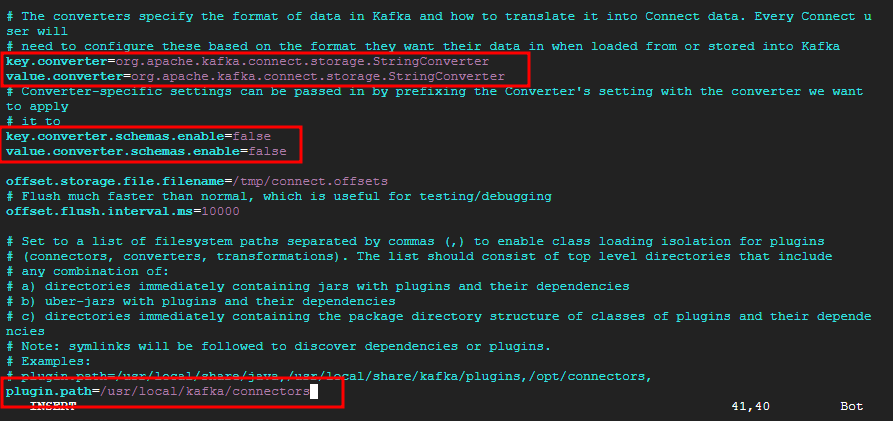
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=falseString Converter를 사용하여 커넥터에 데이터를 해석하지 않고 JSON을 그대로 Pub/Sub으로 전달하도록 한다.
Kafka Connect 실행
/usr/local/kafka/bin/connect-standalone.sh /usr/local/kafka/config/connect-standalone.properties /usr/local/kafka/config/cps-sink-connector.properties &
# 새 창을 열고 Pub/Sub 커넥터의 현재 상태 확인
curl localhost:8083/connectors/CPSSinkConnector/status | jq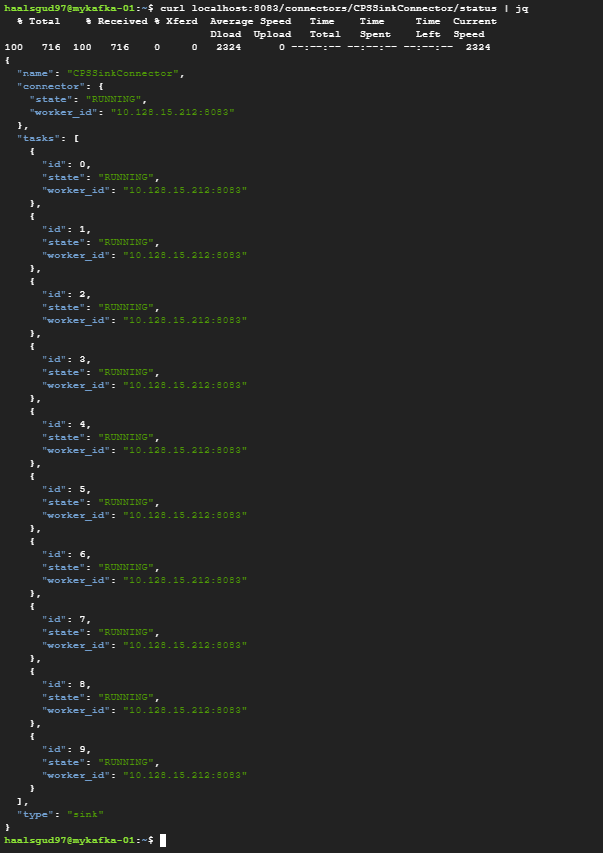
Connector가 정상적으로 Running 중이라는 것을 확인할 수 있다.
Pub/Sub을 생성해줄 때 구독을 만들었다면 그냥 가져오기를 클릭하고 아니면 구독을 하나 생성해준 후 가져오기를 클릭.
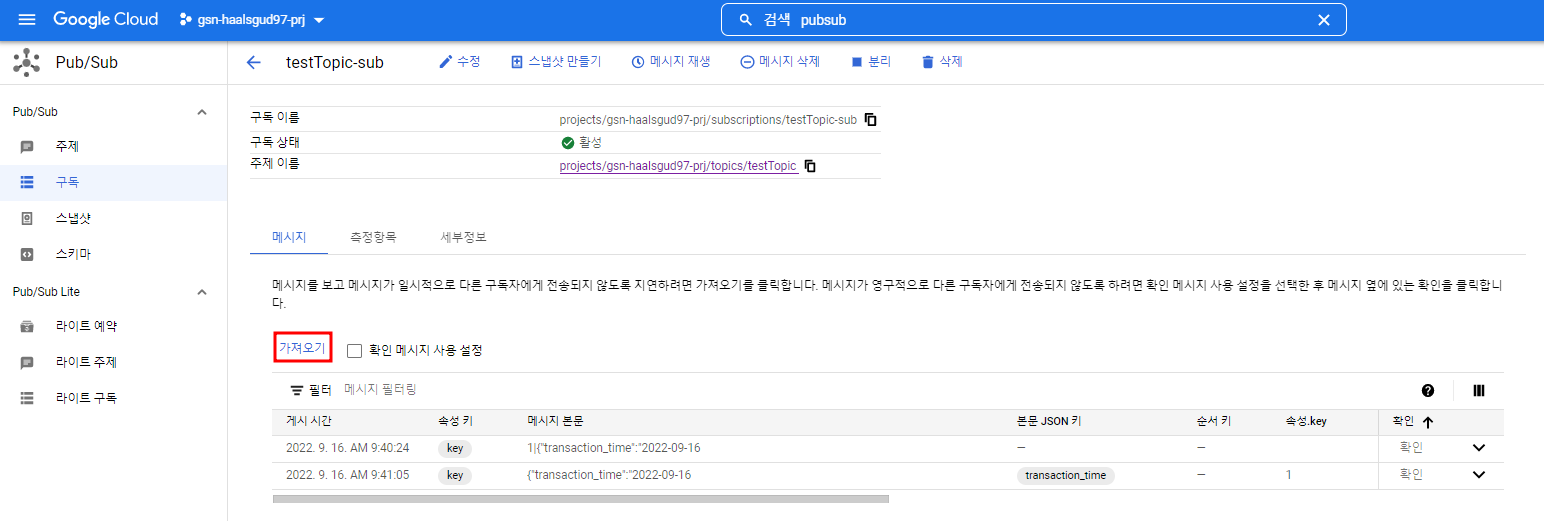
내가 보낸 message.json이 Pub/Sub으로 떨어진 것을 확인할 수 있다.
Dataflow SQL을 사용하여 파이프라인 구축
Pub/Sub에 스키마를 부여해줄 것이다.
Pub/Sub 스키마
- column: event_timestamp
description: Pub/Sub event timestamp
mode: REQUIRED
type: TIMESTAMP
- column: transaction_time
description: Transaction time
mode: NULLABLE
type: STRING
- column: first_name
description: 이름
mode: NULLABLE
type: STRING
- column: last_name
description: 성
mode: NULLABLE
type: STRING
- column: products
description: 상품
mode: REPEATED
type: STRUCT
subcolumns:
- column: product_name
description: 상품 이름
mode: NULLABLE
type: STRING
- column: product_price
description: 상품 가격
mode: NULLABLE
type: FLOAT64Dataflow SQL Data type -> 참고
Dataflow SQL에선 RECORD type이 지원되지 않는다... Dataflow를 실행 했었으나 빅쿼리에 적재가 안됐었다. STRUCT로 넣어줘야 한다.
아래 명령어를 통해 위의 yaml 형식의 스키마를 Pub/Sub 주제에 붙인다.
이 Pub/Sub주제에 붙인 스키마대로 빅쿼리에 테이블을 만들어줄 수 있다.
gcloud data-catalog entries update \
--lookup-entry='pubsub.topic.`<프로젝트 ID>`.<Pub/Sub주제>' \
--schema-from-file=<스키마 파일 경로>콘솔에서 Pub/Sub 스키마를 JSON 형식으로 붙여줄 수 있는 줄 알았으나 형식이 맞지 않는다는 오류가 계속됐고, 우선 yaml파일로 작성하고 data-catalog 명령어로 스키마를 붙여줬다.
나중에 알고보니 지원되는게 AVRO 형식이었는데 JSON과 비슷하지만 조금 다른 형태로 작성해야 했었다. 기본 스키마를 생성할 때 예시로 나오는 형식인 "type": "record", "name": "<이름>", fields[] 에서 fields 안에 스키마들을 정의해줬어야 했다.
이제 Dataflow SQL에서 Pub/Sub을 통해 받아오는 데이터를 처리하여 빅쿼리에 적재하는 파이프라인을 만들어보자.
아래 쿼리를 통해 처리된 데이터들을 적재할 것이다.
SELECT *,"New York" as city FROM pubsub.topic.<프로젝트 ID>.<Pub/Sub 주제>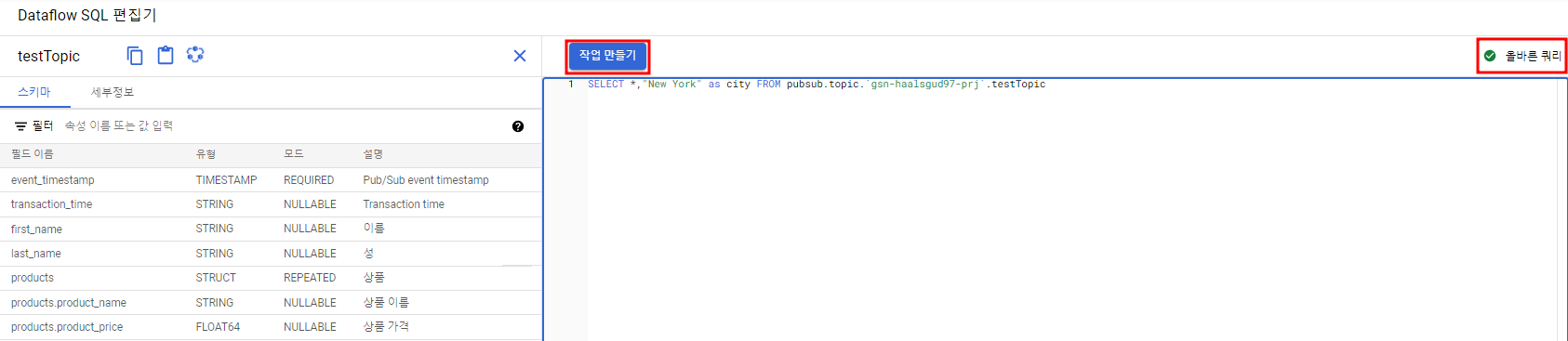

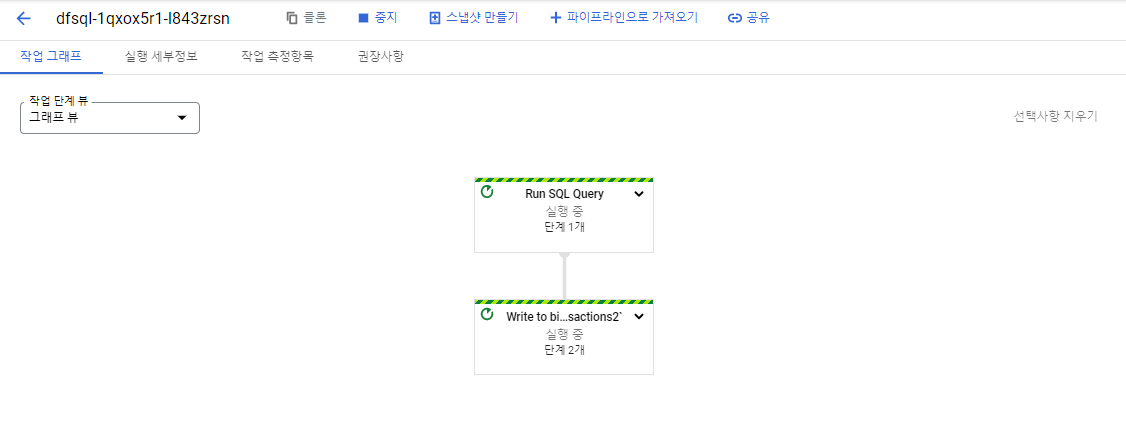
Dataflow가 실행중인 것을 확인할 수 있고 빅쿼리에 처리된 데이터가 적재될 것이다.
transaction2 테이블이 생겼고 데이터가 테이블에 잘 들어왔다.
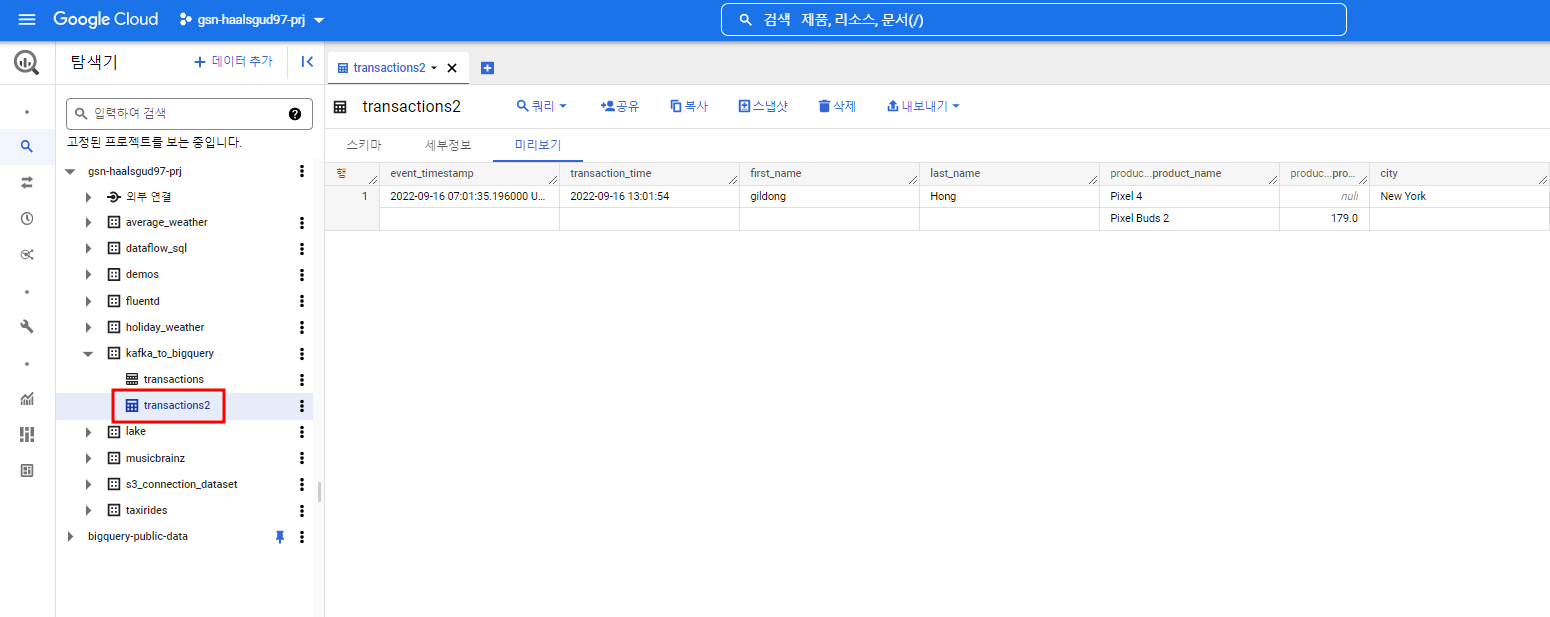
Kafka에서 여러 메시지를 먼저 보내고 Kafka Connect를 실행해줘도 kafka 파티션에 쌓인 데이터를 Pub/Sub이 pulling해와서 Pub/Sub 구독에서 볼 수 있지만, Dataflow 작업 실행 후에 들어온 Kafka 메시지만 처리하여 빅쿼리에 적재되기 때문에 테이블에 하나의 행 밖에 들어가지 않았다.
- [Kafka to BigQuery 파이프라인 참고]
https://medium.com/google-cloud/kafka-to-bigquery-using-dataflow-6ec73ec249bb - [Ubuntu에 Kafka 설치, 실행 참고]
https://deskinsight.net/ko/ubuntu-18-04%EC%97%90-apache-kafka%EB%A5%BC-%EC%84%A4%EC%B9%98%ED%95%98%EB%8A%94-%EB%B0%A9%EB%B2%95
