아키텍처
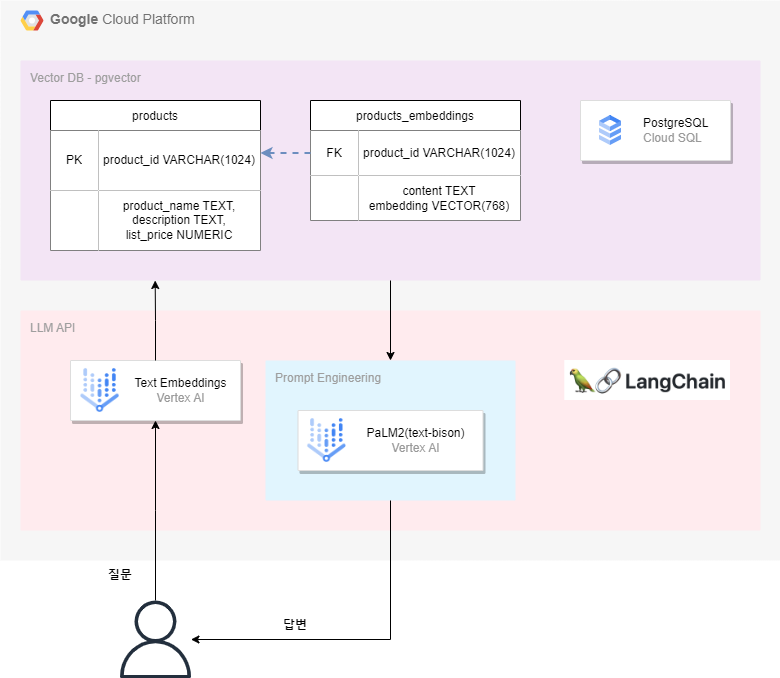
- 개발환경 : Vertex AI Workbench
- 데이터베이스 : Cloud SQL - PostgreSQL
- LLM : Vertex AI - text-embeddings, text-bison
- 데이터 : 어린이 장난감을 파는 온라인 마켓플레이스 데이터. 약800개의 장난감 관련 데이터가 포함.
Cloud SQL 생성 및 API 활성화
Cloud SQL - PostgreSQL 생성
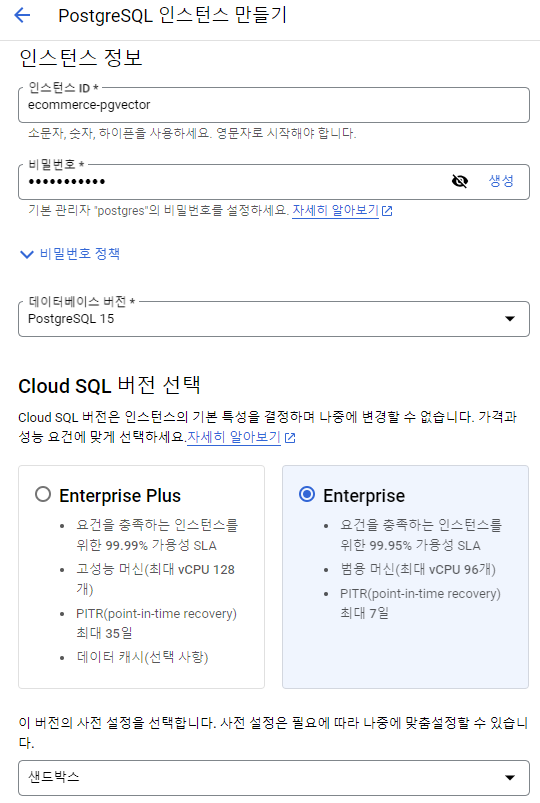
Cloud SQL에 접속을 허용할 IP 대역을 지정해준다.
(VM을 통해 접속하려면 VM IP를 지정)

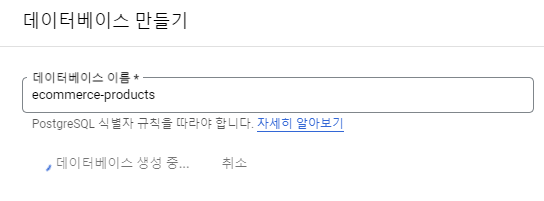
데이터베이스 생성

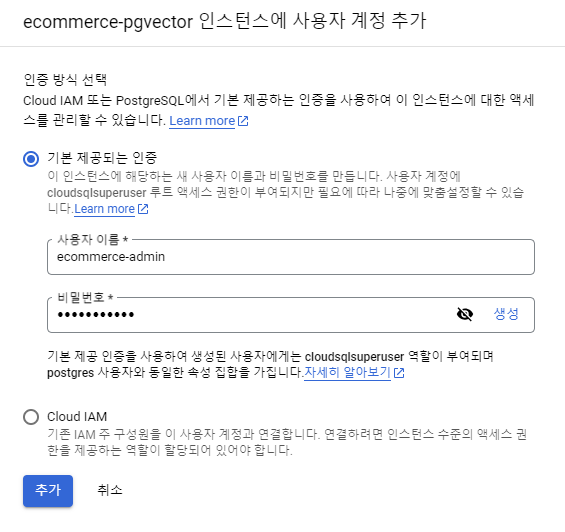
사용자 생성

추가로 Cloud SQL Admin API를 활성화 해주어야 한다.
콘솔의 검색창에 검색해서 활성화해주자.

환경 세팅
필요 라이브러리
!pip install asyncio==3.4.3 asyncpg==0.27.0 cloud-sql-python-connector["asyncpg"]==1.2.3
!pip install numpy==1.22.4 pandas==1.5.3
!pip install pgvector==0.1.8
!pip install langchain==0.0.196 transformers==4.30.1
!pip install google-cloud-aiplatform==1.26.0Setup
project_id = "<프로젝트 ID>"
database_password = "<DB Password>"
region = "<리전>"
instance_name = "<Cloud SQL 인스턴스 이름>"
database_name = "<데이터베이스 이름>"
database_user = "<사용자 이름>"
dataset_url = "https://github.com/GoogleCloudPlatform/python-docs-samples/raw/main/cloud-sql/postgres/pgvector/data/retail_toy_dataset.csv"데이터 로드
df = pd.read_csv(dataset_url)
df = df.loc[:, ["product_id", "product_name", "description", "list_price"]]
df = df.dropna()
df.head(10)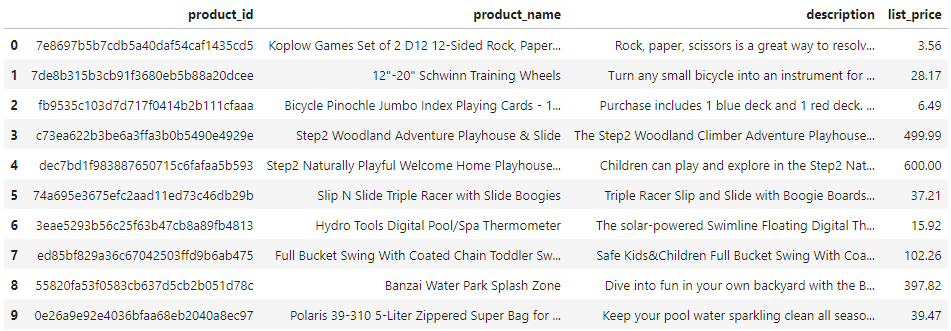
테이블 생성
import asyncio
import asyncpg
from google.cloud.sql.connector import Connector
async def main():
loop = asyncio.get_running_loop()
async with Connector(loop=loop) as connector:
# Cloud SQL 과의 연결 생성
conn: asyncpg.Connection = await connector.connect_async(
f"{project_id}:{region}:{instance_name}", # Cloud SQL 인스턴스 연결 이름
"asyncpg",
user=f"{database_user}",
password=f"{database_password}",
db=f"{database_name}",
)
await conn.execute("DROP TABLE IF EXISTS products CASCADE")
# products 테이블 생성
await conn.execute(
"""CREATE TABLE products(
product_id VARCHAR(1024) PRIMARY KEY,
product_name TEXT,
description TEXT,
list_price NUMERIC)"""
)
# 데이터 프레임에 저장한 장난감 데이터 Cloud SQL에 넣기
tuples = list(df.itertuples(index=False))
await conn.copy_records_to_table(
"products", records=tuples, columns=list(df), timeout=10
)
await conn.close()
# SQL 실행
await main() # type: ignoreCloud SQL에 접속하여 확인

텍스트 분할
Vertex AI - Text Embeddings를 보면 API는 최대 3072의 입력 토큰을 허용하고 768차원의 벡터 임베딩을 출력한다고 되어있다.
장난감에 대한 설명이 3072토큰 보다 길 수 있기 때문에 Langchain 라이브러리를 사용해 일정한 청크 사이즈(여기선 500)로 분할하여 임베딩 시켜줄 것이다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
separators=[".", "\n"],
chunk_size=500,
chunk_overlap=0,
length_function=len,
)
chunked = []
for index, row in df.iterrows():
product_id = row["product_id"]
desc = row["description"]
splits = text_splitter.create_documents([desc])
for s in splits:
r = {"product_id": product_id, "content": s.page_content}
chunked.append(r)임베딩
from langchain.embeddings import VertexAIEmbeddings
from google.cloud import aiplatform
import time
aiplatform.init(project=f"{project_id}", location=f"{region}")
embeddings_service = VertexAIEmbeddings()
# exponential backoff로 실패한 API 호출을 재시도 하기 위한 함수
def retry_with_backoff(func, *args, retry_delay=5, backoff_factor=2, **kwargs):
max_attempts = 10
retries = 0
for i in range(max_attempts):
try:
return func(*args, **kwargs)
except Exception as e:
print(f"error: {e}")
retries += 1
wait = retry_delay * (backoff_factor**retries)
print(f"Retry after waiting for {wait} seconds...")
time.sleep(wait)
batch_size = 5
for i in range(0, len(chunked), batch_size):
request = [x["content"] for x in chunked[i : i + batch_size]]
response = retry_with_backoff(embeddings_service.embed_documents, request)
# 각 청크에 대한 retrieved vector embeddings 값들 저장
for x, e in zip(chunked[i : i + batch_size], response):
x["embedding"] = e
product_embeddings = pd.DataFrame(chunked)
product_embeddings.head()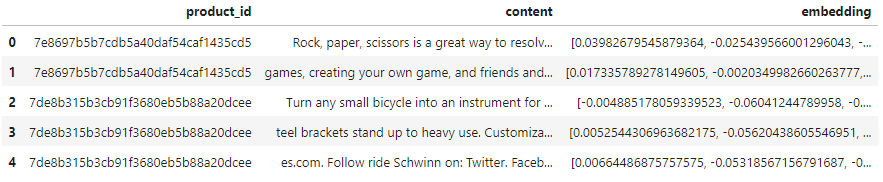
임베딩 테이블 생성
import asyncio
import asyncpg
from google.cloud.sql.connector import Connector
import numpy as np
from pgvector.asyncpg import register_vector
async def main():
loop = asyncio.get_running_loop()
async with Connector(loop=loop) as connector:
# Cloud SQL 과의 연결 생성
conn: asyncpg.Connection = await connector.connect_async(
f"{project_id}:{region}:{instance_name}", # Cloud SQL 인스턴스 연결 이름
"asyncpg",
user=f"{database_user}",
password=f"{database_password}",
db=f"{database_name}",
)
await conn.execute("CREATE EXTENSION IF NOT EXISTS vector")
await register_vector(conn)
await conn.execute("DROP TABLE IF EXISTS product_embeddings")
# product_embeddings 테이블 생성
await conn.execute(
"""CREATE TABLE product_embeddings(
product_id VARCHAR(1024) NOT NULL REFERENCES products(product_id),
content TEXT,
embedding vector(768))"""
)
# embeddings 값들 저장
for index, row in product_embeddings.iterrows():
await conn.execute(
"INSERT INTO product_embeddings (product_id, content, embedding) VALUES ($1, $2, $3)",
row["product_id"],
row["content"],
np.array(row["embedding"]),
)
await conn.close()
# SQL 실행
await main() # type: ignoreCloud SQL에 접속하여 확인
product_embeddings

옵션으로 pgvector 인덱스를 사용한 더 빠른 유사도 검색 링크에서처럼 벡터 인덱스를 추가하여 퍼포먼스를 향상시킬 수도 있다.
유사도 검색
이제 pgvector를 사용하여 관계형 데이터베이스의 기능을 벡터 유사도 검색 작업과 통합할 수 있다..!!
질문
아이들에게 숫자와 글자를 가르쳐주는 해변 장난감 세트가 있나요?
user_query = "Do you have a beach toy set that teaches numbers and letters to kids?"
query_embedding = embeddings_service.embed_query([user_query])
matches = []
async def main():
loop = asyncio.get_running_loop()
async with Connector(loop=loop) as connector:
# Cloud SQL 과의 연결 생성
conn: asyncpg.Connection = await connector.connect_async(
f"{project_id}:{region}:{instance_name}", # Cloud SQL 인스턴스 연결 이름
"asyncpg",
user=f"{database_user}",
password=f"{database_password}",
db=f"{database_name}",
)
await register_vector(conn)
similarity_threshold = 0.7
num_matches = 5
results = await conn.fetch(
"""
WITH vector_matches AS (
SELECT
product_id,
MAX(1 - (embedding <=> $1)) AS similarity
FROM product_embeddings
WHERE 1 - (embedding <=> $1) > $2
GROUP BY product_id
ORDER BY similarity DESC
LIMIT $3
)
SELECT
products.product_id,
products.product_name,
products.list_price,
products.description,
vector_matches.similarity
FROM
products
JOIN
vector_matches ON products.product_id = vector_matches.product_id
ORDER BY
vector_matches.similarity DESC;
""",
query_embedding,
similarity_threshold,
num_matches,
)
if len(results) == 0:
raise Exception("Did not find any results. Adjust the query parameters.")
for r in results:
# 모든 유사힌 장난감 제품에 대한 description을 수집.
matches.append(
f"""The name of the toy is {r["product_name"]}.
The price of the toy is ${round(r["list_price"], 2)}.
Its description is below:
{r["description"]}."""
)
await conn.close()
await main()
matches_df = pd.DataFrame(matches)
matches_df.head()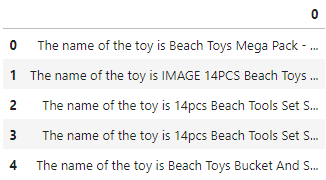
프롬프트 엔지니어링
위의 matches의 결과값에서 개별 제품 설명이 길어지면 API의 허용 토큰 수를 초과할 수 있으므로 Langchain 라이브러리를 사용하여 text summarization 수행
from langchain.chains.summarize import load_summarize_chain
from langchain.docstore.document import Document
from langchain.llms import VertexAI
from langchain import PromptTemplate, LLMChain
from IPython.display import display, Markdown
llm = VertexAI()
map_prompt_template = """
You will be given a detailed description of a toy product.
This description is enclosed in triple backticks (```).
Using this description only, extract the name of the toy,
the price of the toy and its features.
```{text}```
SUMMARY:
"""
map_prompt = PromptTemplate(template=map_prompt_template, input_variables=["text"])
combine_prompt_template = """
You will be given a detailed description different toy products
enclosed in triple backticks (```) and a question enclosed in
double backticks(``).
Select one toy that is most relevant to answer the question.
Using that selected toy description, answer the following
question in as much detail as possible.
You should only use the information in the description.
Your answer should include the name of the toy, the price of the toy
and its features. Your answer should be less than 200 words.
Your answer should be in Markdown in a numbered list format.
Description:
```{text}```
Question:
``{user_query}``
Answer:
"""
combine_prompt = PromptTemplate(
template=combine_prompt_template, input_variables=["text", "user_query"]
)
docs = [Document(page_content=t) for t in matches]
chain = load_summarize_chain(
llm, chain_type="map_reduce", map_prompt=map_prompt, combine_prompt=combine_prompt
)
answer = chain.run(
{
"input_documents": docs,
"user_query": user_query,
}
)
display(Markdown(answer))
[pgvector와 Langchain을 사용한 AI 기반 어플리케이션 구축 참고]

AI Solutions Architect
공유 감사합니다! 도움 많이 받고 있습니다.