이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.
이 글에서는 컨텍스트 기반 추천(Context-aware Recommendation, CAR)이 앞에서 다룬 협업필터링과 어떻게 다른지 이해하고, 이것이 어떠한 양상으로 발전해 왔는지 알아보도록 하자.
기존 MF를 활용한 CF의 한계
지난 글까지 우리가 추천에 사용한 데이터는 3가지이다.
- 유저 id 정보
- 아이템 id 정보
- 유저-아이템 상호작용 정보
행렬분해(MF)기법을 활용한 협업 필터링(CF)는 개별 유저와 아이템간 상호작용을 2차원 행렬로 표현하여 모델에서 학습하였다. 이렇게 상호작용을 2차원 행렬로 표현하게 되면 유저의 데모그래픽이나 아이템의 카테고리, 태그 등 여러 특성들을 추천 시스템에 반영할 수 없는 문제가 있다.
또한 만약 상호작용 정보가 부족하거나 없는 경우(서비스 런칭 초기)에는 Cold start 문제에 대한 대처가 어렵다는 한계점이 존재한다.
컨텍스트 기반 추천 시스템 개념
컨텍스트 기반 추천 시스템(Context-aware Recommendation, CAR)은 필수적으로 필요한 유저-아이템 상호작용 정보 뿐만아니라 맥락(Context)적 정보도 함께 반영하는 추천 시스템이다.
여기서 맥락적 정보는 상호작용이 일어났을 때의 시간, 공간적 정보 같은 것들로 서비스마다 형태가 다르기 때문에 다양한 특성을 담을 수 있는 general한 모델이 설계되어야 한다. 즉 기존의 CF와 데이터 구성, 접근방법이 달라지게 된다.
General한 모델로 만들기 위해 CAR은 CF의 평점 예측처럼 Matrix Completion문제가 아니라, 다음의 그림과 같이 X를 통해 Y값을 추론하는 일반적인 예측문제의 형태로 구성되어야 한다.
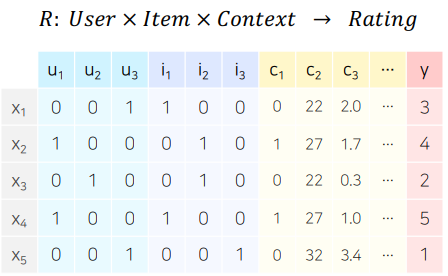
그림의 첫번째 행을 해석해보자.
첫번째 행인 은 이라는 사람이 을 소비하고 Context 정보들 이 있을 때 선호도 는 3이라는 것이다. 이때 Context정보는 원하는 만큼 추가할 수 있다.
CAR 활용 예시
다음은 CAR의 대표적인 활용 분야에 대해서 알아보자.
CTR 예측
CTR 예측은 유저가 주어진 아이템을 클릭할 확률을 예측하는 문제이다. CTR과 매출은 Online A/B Test시에 가장 많이 사용하는 지표지만 매출의 경우 추천의 영향 이외에도 외부변수의 유입가능성이 크기 때문에 CTR을 주로 사용한다.
CTR 예측에서 우리가 예측해야하는 y값은 클릭여부로 0 or 1의 이진 분류 문제에 해당한다. 따라서 모델을 만들 때에는 출력값에 sigmoid 함수를 통과시켜 0과 1사이의 확률값으로 변환 시켜 예측 CTR 값을 뽑아낸다.
추가적으로 CTR 예측은 광고 추천에서 주로 사용된다. 광고 추천을 잘하는 것은 곧 수익과 직결되기 때문인데, 광고가 노출된 상황의 유저, 광고, 컨텍스트 피쳐를 모델의 input으로 사용하고 유저 ID가 존재하지 않는 데이터도 다른 유저 피쳐나 컨텍스트 피쳐를 사용하여 예측할 수 있다.(실제 현업에서는 유저ID를 피쳐로 사용하지 않는 경우가 많다)
이진 분류 문제 - 로지스틱 회귀(Logistic Regression)
이제 CTR 예측모델의 가장 기본 형태인 로지스틱 회귀에 대해서 알아보자. 로지스틱 회귀는 이후에 다룰 FM,FFM,Deep CTR 등의 기초개념이 된다.
로지스틱 회귀의 기본 모형 수식은 다음과 같다.
기본모형
- : context 정보
추천(뿐만 아니라 모든 ML)에서 변수간 상호작용을 적용하는 것은 중요하다.
하지만 이 수식은 한개의 변수로 모델링을 하고 있기 때문에 유저-아이템 상호작용을 전혀 반영하지 못하고 있다.
Polynomial Model
Polynomial Model은 기본 모델에 을 붙인 형태이다.
새로 추가된 term은 를 이용해 강제로 두 변수의 상호작용을 만들어서 두 변수의 상호작용을 로 학습하게 한다. (이를 카티션 프로덕트라고 한다)
※ 카티션 프로덕트란 SQL 에서 두 변수의 모든 조합을 구하는 것으로 SELECT * FORM A,B 로 구할 수 있는데 총 개수는 A*B 개만큼이 나오게 된다.
이렇게 변수 간 상호작용을 추가로 고려한 모델운 2차 이상 항이 존재하기 때문에 Polynomial Model 이라고 부르며 파라미터 수가 급격하게 증가(카티션 프로덕트를 하기 때문에)한다는 단점이 존재한다.
파라미터 수가 급격하게 증가하는 단점을 해결하기 위해 이후에 FM, FFM이 있다.
CTR 예측에서 사용 데이터
앞에서 볼 수 있듯 CTR 예측에는 다양한 context feature를 사용할 수 있는데 이러한 feature 들은 2가지 종류(Dense Feature, Spare Feature)로 나눌 수 있다.
-
Dense Feature
벡터로 표현 했을 떄 비교적 작은 공간에 밀집되어 분포하는 수치형 변수
ex) 기온, 시간 등 -
Sparse Feature
벡터로 표현했을 시 비교적 넓은 공간에 분포하는 범주형 변수
ex) 유저id, 태그, 키워드, 요일 등 -> one/multi hot
CTR 예측문제에서 사용되는 데이터는 대부분 sparse feature이다.
CTR 예측 데이터의 예시(Avazu CTR Dataset)를 보자.
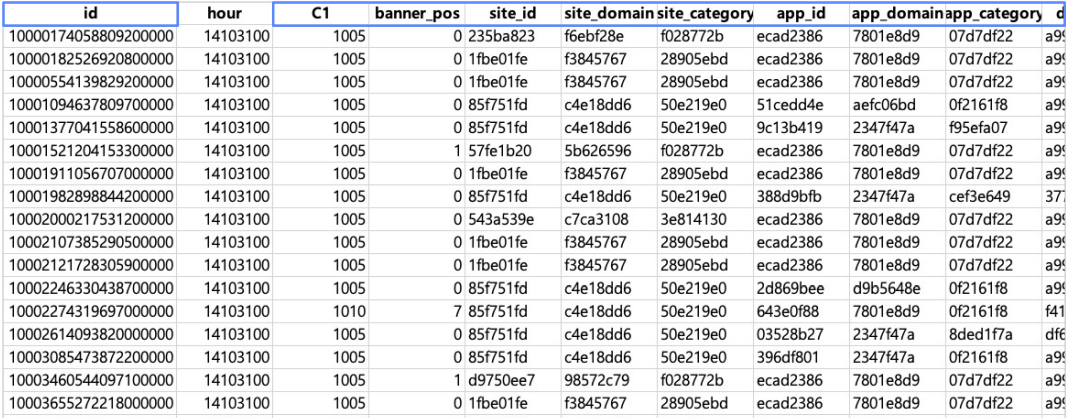
개인정보 보호를 위해 모든 값이 해쉬 값으로 나타나 있긴 하지만 하나하나의 칼럼은 feature를 나타낸다. 특히 파란색으로 표시된 것은 모두 sparse featuer를 나타내고 대부분의 feature가 sparse 한 feature임을 알 수 있다.
그래서 CTR 예측문제 데이터를 모두 다 one-hot-encoding해서 모델링을 할 경우에는 파라미터 수가 그 차원의 개수만큼 생기기 때문에너무 많아질 수 있고, 학습 데이터에 등장하는 빈도에 따라 특정 카테고리가 overfitting/underfitting 될 수 있다.
이를 막기 위해서 one hot encoding을 그대로 사용하지 않고 피쳐 임베딩을 한 이후에 이 피쳐를 가지고 예측을 한다. 이때 사용되는 것으로는 자연어 처리에서 사용되는 텍스트 임베딩 기법들(Item2Vec, BERT, LDA Topic Modeling 등)이 흔히 사용된다.
앞으로 배울 CTR 모델들의 공통점
- Embedding : sparse feature 들을 임베딩을 통해 잘 표현
- Interaction : sparse feature 들간 상호작용을 모델 설계에서 고려
이 두가지를 모델에서 어떻게 잘 표현할 것인가가 CTR 예측모델의 핵심이다.
