RecSys
1.[RecSys] 추천시스템이란?
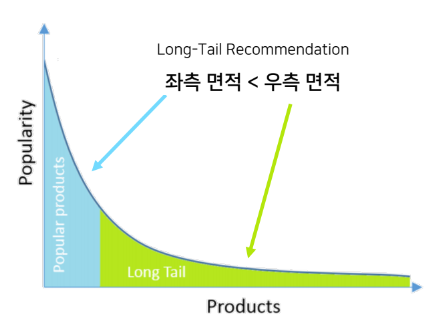
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.Query 라는 Keyword로 검색하면 그 결과에 맞는 정보를 주는 것사용자가 정확한 의도를 가지고 검색하여 당겨오는 방식으로 pull 방식이라고도 한다.사용자의 흥미나 의도를 고려하여 정보를 추출해
2.[RecSys] 추천 시스템의 평가 지표
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.추천 시스템 적용으로 인한 매출 , PV(page view) 증가추천 아이템으로 인한 유저의 CTR(노출 대비 클릭율) 상승연관성(Relevance) : 추천 아이템이 유저에게 관련 있는가? 40대 남
3.[RecSys] 인기도 기반 추천

이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.인기도 기반 추천은 추천시스템의 가장 단순한 형태머신 러닝을 이용한 것이 아니라 말 그대로 가장 인기있는 아이템을 추천 서비스 런칭 초반이라 데이터가 부족 하거나 추천 시스템 적용이 어려운 경우 활용됨
4.[RecSys] 연관분석(Association Analysis)

이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.연관 규칙 분석(Association Rule Analysis)은 장바구니 분석 or 서열 분석이라고도 불린다.주어진 Transaction(거래;영수증) 데이터에 대해서 상품A 구매시 상품B가 같이 등
5.[RecSys] TD-IDF를 활용한 컨텐츠 기반 추천
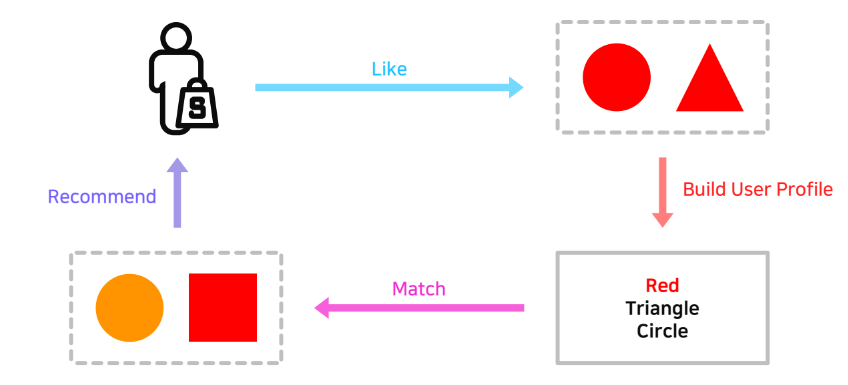
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.Content-based 는 TF-IDF를 활용해 Item Profile을 만든다.User와 Item 간의 유사도를 계산하여 Top-K 추천을 할 수 있다.새로운 아이템에 대해서는 유저가 선호한 아이템
6.[RecSys] CF : Collaborative Filtering 기초
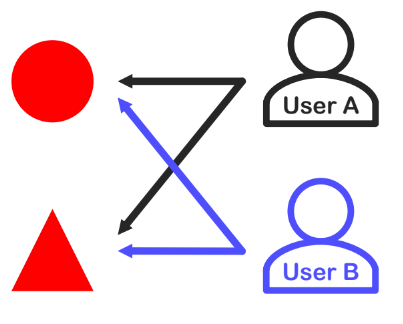
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.CF는 직관적으로 이해하기 쉽지만 앞으로 배울 다양한 기법의 기초가 되는 중요한 개념이다. 협업 필터링(Collaborative Filtering, CF)이란 많은 유저들로 부터 얻은 기호 정보 를 이
7.[RecSys] Neighborhood-based CF
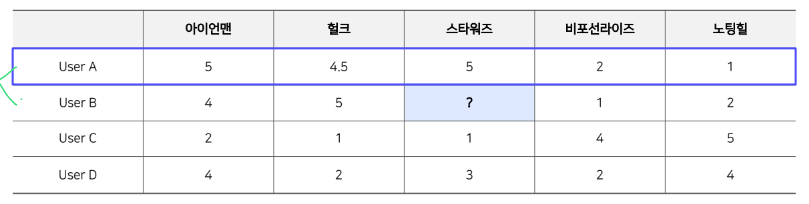
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.Neighnorhood-based CF 이웃 기반 협업 필터링은 가장 초기 CF모델로 User-based CFItem-based CF두개가 있다.두 CF는 같은방식으로 추천을 하지만 User-Item
8.[RecSys] K-Nearest Neighbors CF(KNN CF) 와 Similarity Measures
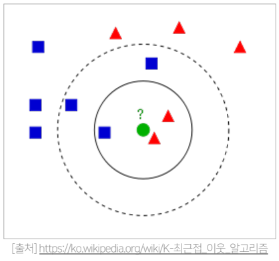
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.NBCF의 한계NBCF 는 아이템 i에 대한 평점을 예측하기 위해서는 $\\Omega\_{i}$에 속한 모든 유저와의 유사도를 구해야 한다.$\\Omega\_{i}$ : 아이템 $i$에 대한 평가를한
9.[RecSys] CF를 이용한 Rating Prediction
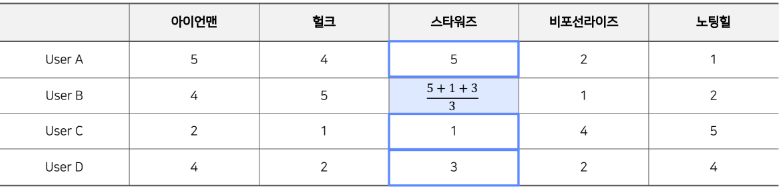
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.이 글에 다루는 Rating Prediction은 User-based CF를 기준으로 설명을 진행한다.Collaborative Filtering 의 최종목적은 평점을 예측하는 것이다. CF의 목적에서
10.[RecSys] Model-Based CF 개념
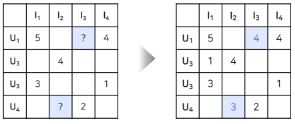
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.앞서 배운 Neighborhood-based CF(UBCD, IBCF, KNN-CF) 는 두가지 큰 문제점이 있다.Sparsity(희소성)문제데이터가 불충분 하다면 추천 성능이 떨어진다 (유사도 계산이
11.[RecSys] MF : Matrix Facotrization
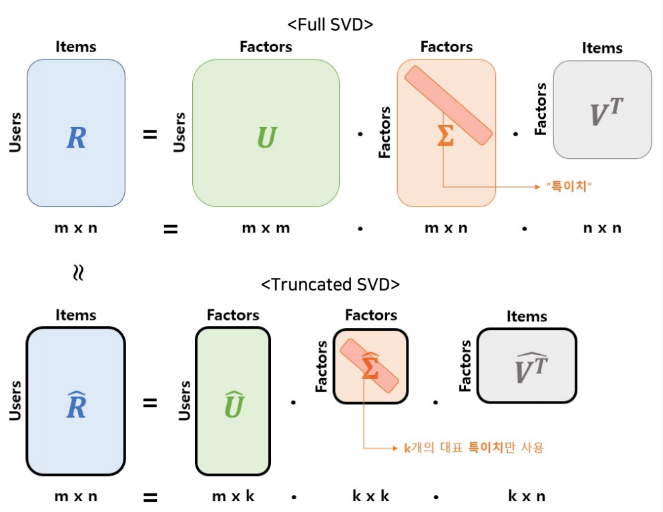
SVD는 선형대수학에서 차원축소 기법으로 쓰이는 것으로 추천시스템에서는 Rating Matrix에 대해 유저와 아이템의 잠재요인을 포함할 수 있는 행렬로 분해한다.SVD 종류와 방법대표값을 모두 사용Full SVD : $R = U\\sum V^T$대표값으로 사용될 K개
12.[RecSys] Item2Vec

이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다. Word2Vec Item2Vec은 워드 임베딩의 대표적인 방법론은 Word2Vec의 아이디어를 차용한 것이다. 따라서 Word2Vec의 원리를 먼저 알아보자. Item2Vec
13.[RecSys] ANN : Approximate Nearest Neighbor 기법
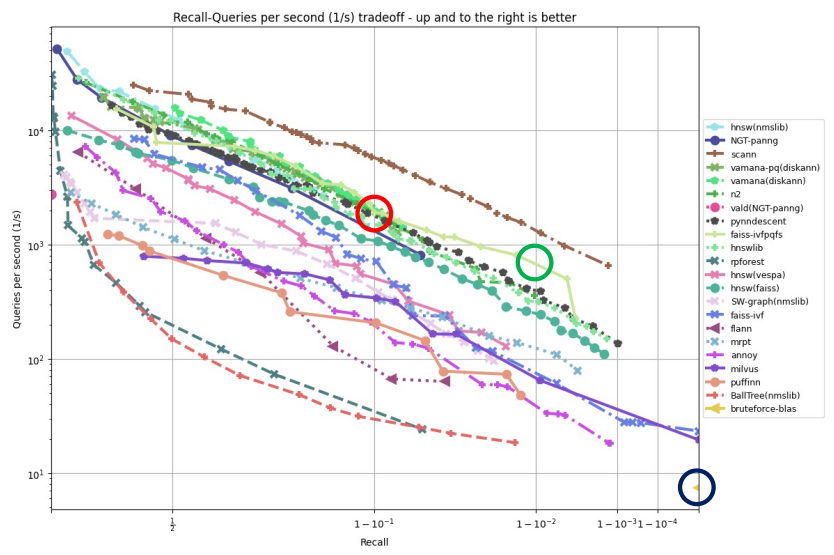
ANN의 필요성 Nearest Neighbor ANNOY 기타 ANN 기법 Hierarchical Navigable Small World Graphs (HNSW) Inverted File Index (IVF) Product Quantization - Compr
14.[RecSys] Recommender Sysyem with Deep Learning 1 (NCF, YouTube Rec)
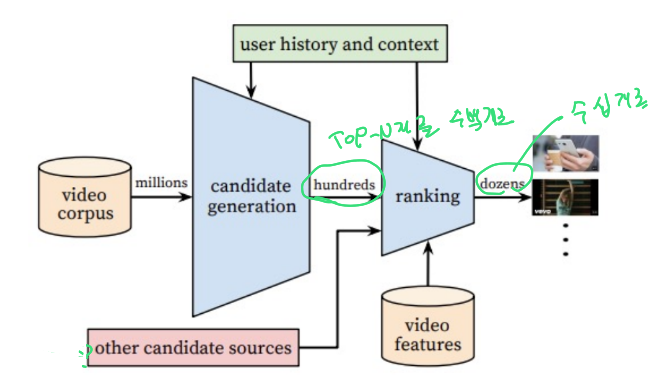
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다. Recsys에서 딥러닝을 활용하는 이유 추천시스템에서 딥러닝을 활용하는 이유를 알아보자. Nonlinear Transformation Deep Neural Network는 데이터의 비선형성을 효
15.[RecSys] Recommender Sysyem with Deep Learning 2 (AutoRec, CDAE)
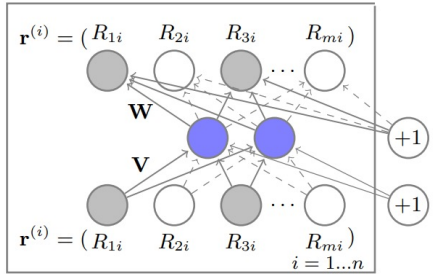
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.AutoEncoder를 Collaborative Filtering 에 적용하여 기본 CF모델에 비해 Representation과 Complexity 측면에서 좋은 성능을 보인 논문이다. AutoRec은
16.[RecSys] Recommender System with GNN 1 (GNN 기본개념)
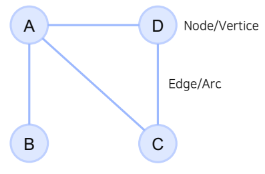
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.Graph Neural Network 를 알아보기 전에 Graph란 무엇인지 간단하게 알아보자.Graph란 꼭지점(Node)들과 그 노드들을 잇는 변(Edge)들을 모아 구성한 자료구조로 연결되어 있는
17.[RecSys] Recommender System with GNN 2 (NGCF : Neural Graph Collaborative Filtering, Light GCN)
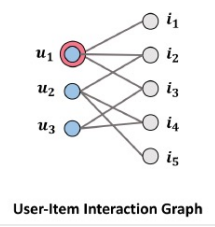
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다. Neural Graph Collaborative Filtering 논문 링크
18.[RecSys] Recommender System with RNN(GRU 4 Rec)
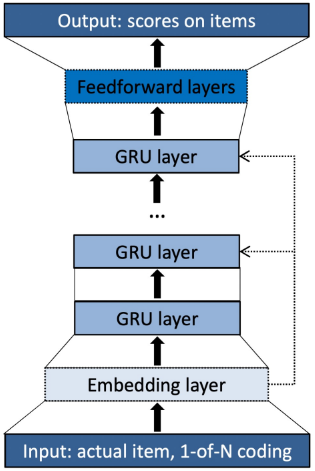
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.이전까지 다뤄왔던 추천모델들은 유저의 Sequence를 고려하지 않은 모델들이었다.실제 상황에서 유저의 선호도는 고정되지 않고 시간에 따라 달라지게 된다. 즉 추천 모델에서 해결해야할 문제는 단순 선호
19.[RecSys] Context-aware Recommendation 개념
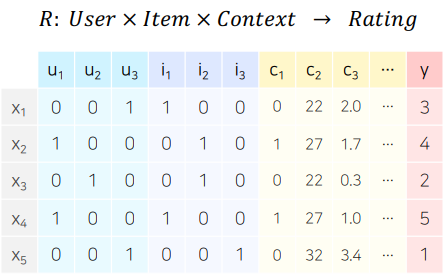
이 글에서는 컨텍스트 기반 추천(Context-aware Recommendation, CAR)이 앞에서 다룬 협업필터링과 어떻게 다른지 이해하고, 이것이 어떠한 양상으로 발전해 왔는지 알아보도록 하자.지난 글까지 우리가 추천에 사용한 데이터는 3가지이다.유저 id 정보
20.[RecSys] Context-aware Recommendation (FM;Factorization Machines, Field-aware FM)
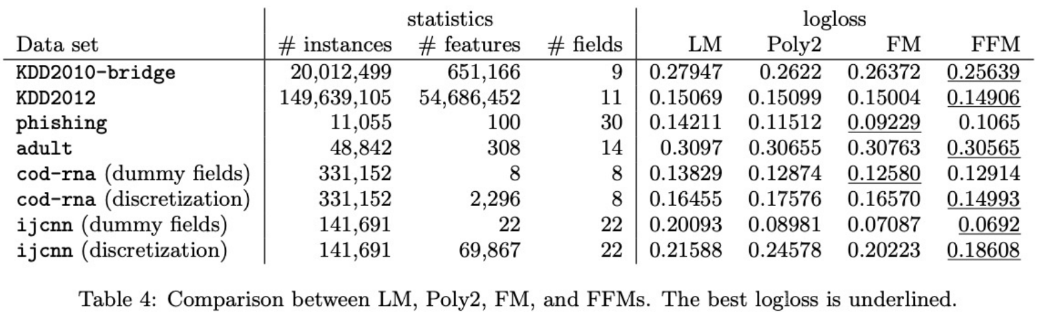
FM : Factorization Machines Factorization Machines 논문이 나올당시 많이 사용했던 SVM 과 MF 같은 Factorization 모델의 장점을 결합한 Factorization Machine을 처음 소개한 논문이다. 등장배경 딥러
21.[RecSys] DeepCTR 1 - Wide & Deep
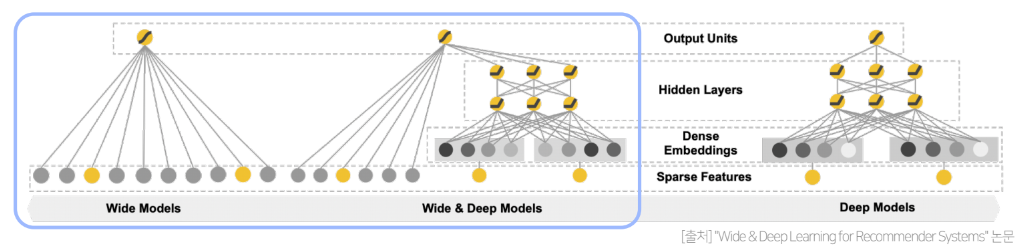
현실의 CTR 데이터(주로 광고 데이터)는 기존의 선형 모델로 예측하는 데에는 한계가 있다.그 이유는 CTR 데이터는 Highly Sparse 하고 super high-dimensional features 로 이루어져있져 있고, 각 feature간의 관계가 highly
22.[RecSys] 추천을 위한 MAB(Multi-Armed Bandit) - 개념과 기초 알고리즘(Greedy, Epsilon, UCB)
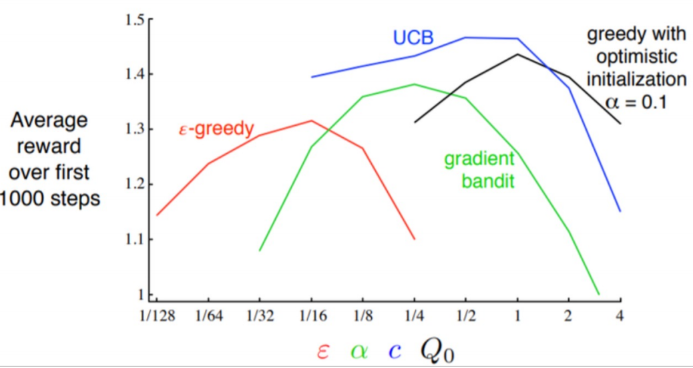
※ Bandit의 개념은 원래 강화학습의 기초개념이지만, 간단하게 구현되기 때문에 현업에서도 종종 쓰인다.MAB(Multi-Armed Bandit)가 추천시스템에 어떻게 적용되는지 알아보기 위해 우선 MAB가 무엇인지 알아보자.카지노에 있는 슬릇머신을 생각해 보자.슬릇
23.[RecSys] 추천을 위한 MAB(Multi-Armed Bandit) - 심화 알고리즘(Thompson sampling, LinUCB)
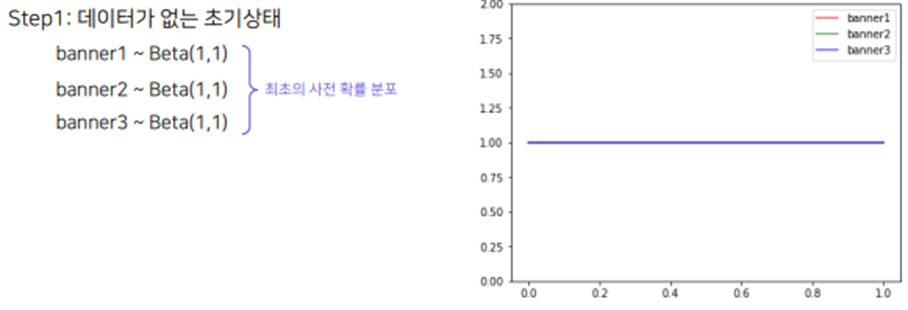
이번에는 이전글에서 다룬 Epsilon-Greedy나 UCB보다 발전된 기법으로 현업에서 자주 사용되는 MBA 알고리즘인 Thompson sampling과 LinUCB를 알아보자.Thompson Samping은 주어진 K개의 action에 해당하는 확률 분포를 구하는