이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.
Word2Vec
Item2Vec은 워드 임베딩의 대표적인 방법론은 Word2Vec의 아이디어를 차용한 것이다.
따라서 Word2Vec의 원리를 먼저 알아보자.
개요
임베딩(Embedding)이란?
임베딩이란 주어진 데이터를 낮은 차원의 Vector로 만들어서 표현하는 방법
-
Sparse Representation : 아이템의 전체 가지수와 차원의 수가 동일한 이진값으로 이루어진 벡터로 표현하는 방식 (one-hot-encoding)
아이템 개수가 많아질수록 벡터의 차원이 한없이 커지고 공간이 낭비됨 -
Dense Representation : 아이템의 전체 가지수보다 훨씩 작은 차원으로 실수값으로 이루어진 벡터로 표현하는 방식 (nn.Embedding)
이러한 Dense Representation을 하기 위해서는 데이터로부터 학습시켜야 함 (Embedding 시킴)
MF에서 P(유저 Latent Feature Matrix), Q(아이템 Latent Feature Matrix)도 Embedding으로 볼 수 있음
워드 임베딩(Word Embedding)이란?
워드 임베딩이란 텍스트 분석을 위해 단어(word)를 벡터로 표현하는 방법이다.
즉 단어들의 one-hot-encoding(Sparse Representation)을 Dense Representation 하는 것이다.
Dense Representation으로 바꾸면서 단어들은 단어간 의미적인 유사도를 구할 수 있다. 임베딩되는 과정에서 비슷한 의미를 가진 단어일수록 Embedding Vector가 가까운 위치에 분포하기 때문이다.
이러한 임베딩으로 표현하기 위해서는 학습모델이 필요하다.
Word2Vec이란?
Word2Vec은 뉴럴 네트워크 기반의 모델로 대량의 문서 데이터셋을 vector 공간에 투영한다.
이때 각 단어는 압축된 형태의 많은 의미를 갖는 dense vector로 표현한다.
Word2Vec 학습방법
Word2Vec은 3가지 학습방법이 있다.
- CBOW
- Skip-Gram
- Skip-Gram with Negative Sampling(SGNS)
CBOW(Continuous Bag of Words)
어떤 글에서 주변 단어끼리 서로 연관성이 있다는 가정을 하고 주변에 있는 단어를 가지고 센터에 있는 단어를 예측하는 방법이다.
센터 단어를 예측하기 위해 앞뒤로 몇개의 단어를 사용할 것인지 정해야 한다. 이를 window 의 크기라고 부르며 window의 크기가 n이라면 실제 예측에서는 센터 단어의 앞뒤로 n개를 참고하여 총 2n개의 단어를 사용한다.
예시
위 그림에서 마지막 줄을 고려해보면
예측 단어 : fox, n = 2
사용할 단어 "quick", "brown", "jumps", "over" 가 된다.
학습방법
이제 실제로 어떤 방식으로 학습이 진행되는지 살펴보도록하자.
위의 예시에서 사용할 단어는 Input, 예측 단어는 Output이 된다.
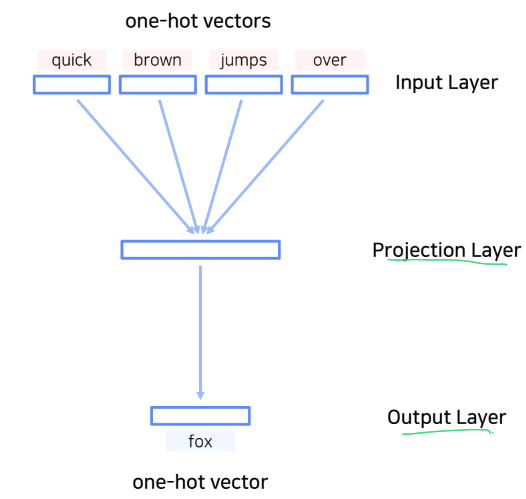
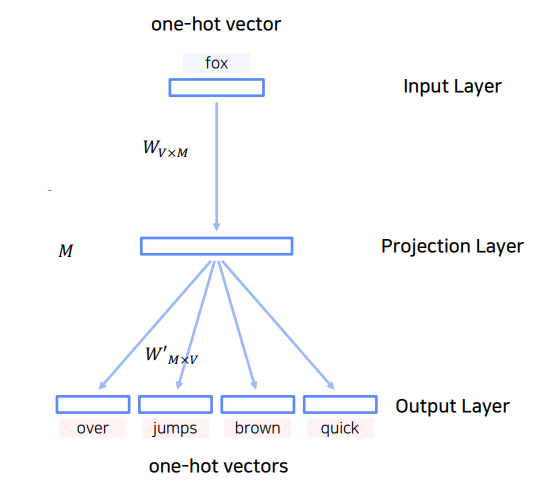
이 모델은 총 두가지 학습 파라미터를 가진다.
- : Input Layer(sparse vector) -> Projection Layer(dense vector)
- V개의 유니크한 단어(one-hot-vector)가 M개로 임베딩(embedding vector) 시킬 때 사용 - : Projection Layer(dense vector) -> Output Layer(sparse vector)
- M개의 임베딩(embedding vector) 이 다시 V개의 유니크한 단어(one-hot-vector)로 변형시킬 때 사용
이때 는 단어의 총 개수, 은 임베딩 벡터의 사이즈를 뜻한다.
위 그림중 brown과 jumps를 임베딩 시키는 과정을 보자
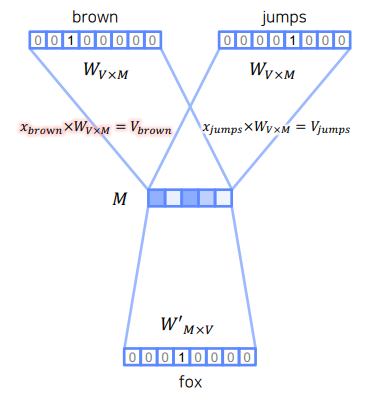
이라는 원핫 벡터에 임베딩을 위한 파라미터를 행렬곱 해주면 이라는 임베딩 벡터가 생성된다.
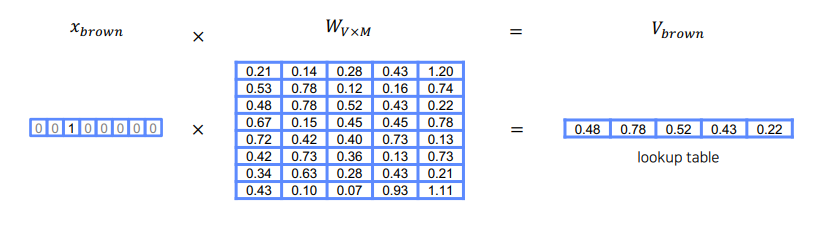
행렬곱 연산에서 볼 수 있듯이 의 brown행(3번째 행)을 그대로 읽어오기 때문에 은 Lookup table 이라고도 한다.
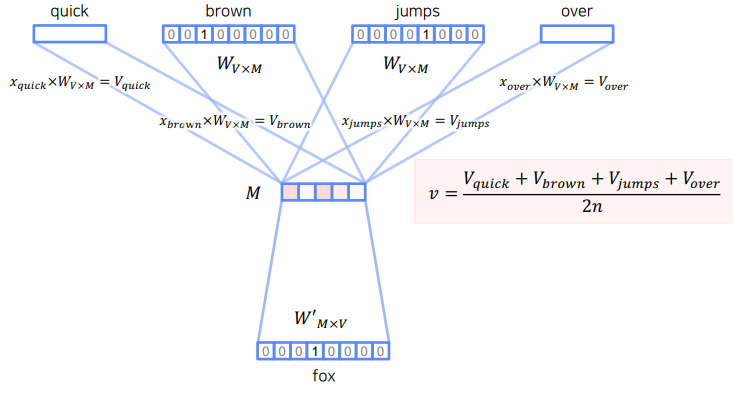
이렇게 각 단어를 임베딩 시킨뒤 단순평균을 구하여 최종 임베딩 벡터을 구한다.
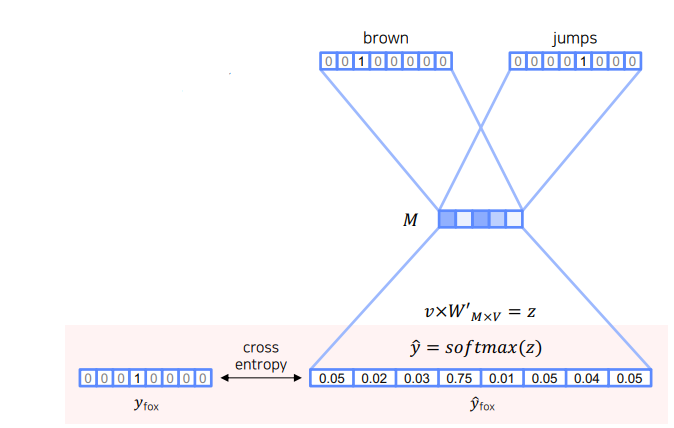
마지막으로 에 를 곱한 뒤 softmax를 씌워줘 센터 단어의 최종 예측값 을 구한다.
이렇게 구한 는 참값인 은 Cross Entropy를 이용하여 Loss값을 구한 뒤 학습 파라미터인 , 을 업데이트 시킨다.
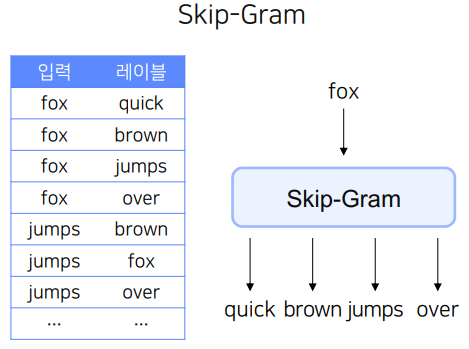
Skip Gram
Skip Gram은 CBOW와 수행하는 Task는 동일하다.
CBOW와 다른 점은 입력층과 출력층이 반대로 구성되어 있는 모델이라는 점이다.
즉 중심단어에서 주변단어를 예측하는 모델이고, 입력이 1개이기 때문에 벡터의 평균을 구하는 과정이 없게 된다.
일반적으로 CBOW보다 Skip Gram이 성능이 좋다고 알려져 있다.
여기서 말하는 성능이랑 classification의 성능보다는 Word2Vec 학습 후 Embedding의 표현력이 더 좋다는 것을 의미한다.
SGNS(Skip Gram with Negative Sampling)
SGNS는 Item2Vec이 차용한 아이디어이다.
Skip-Gram은 다음과 같이 주어진 입력(중심단어)->주변단어를 예측하는 Mulit class classification 이다.
여기서 SGNS는 주변단어를 1로 주변단어가 아닌것을 0으로 두어 binary calssification 문제로 바꾸게 된다.
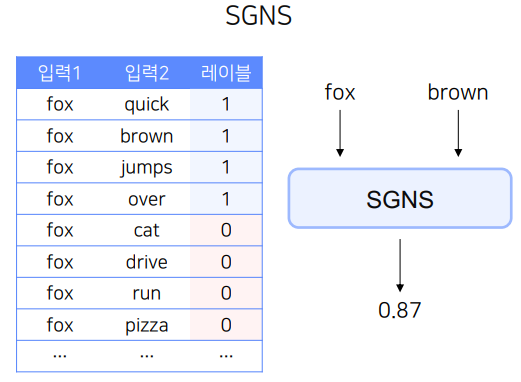
입력은 두개가 들어간다.
- 입력1 : 중심단어
- 입력2 : 주변단어(positive) or 주변단어가 아닌 단어(Negative)
입력과 문제정의가 바뀜에 따라 모델구조도 바뀌게 된다.
우선 입력이 어떻게 바뀌는지 자세히 알아보도록 하자.

그림에서 첫번째 표는 Skip Gram의 데이터를 나타낸다.
이를 입력으로 바꾸고 중심단어와 주변단어(Positive Sample)을 그대로 두고 레이블을 붙이면 두번째 표처럼 모든 레이블이 1이된다.
따라서 0 label을 만들기 위해 세번째 표처럼 주변단어가 아닌 단어를 샘플링 해야하는데 이것이 Negative Sampling이다.
이때 Negative Sampling의 개수K는 모델의 하이퍼파라미터이다.
positive sample 하나당 K개의 Negative Sampling을 하게 되고, K는 보통 학습데이터가 적은 경우 5~20개, 충분히 큰 경우에는 2~5개가 적당하다고 알려져 있다.
이렇게 생성된 중심단어와 주변단어는 각각의 임베딩 파라미터(같은 size)를 따로 가지게 된다.
학습은 두 임베딩 파라미터를 학습하게 된다.
그림으로 과정을 이해해보자.
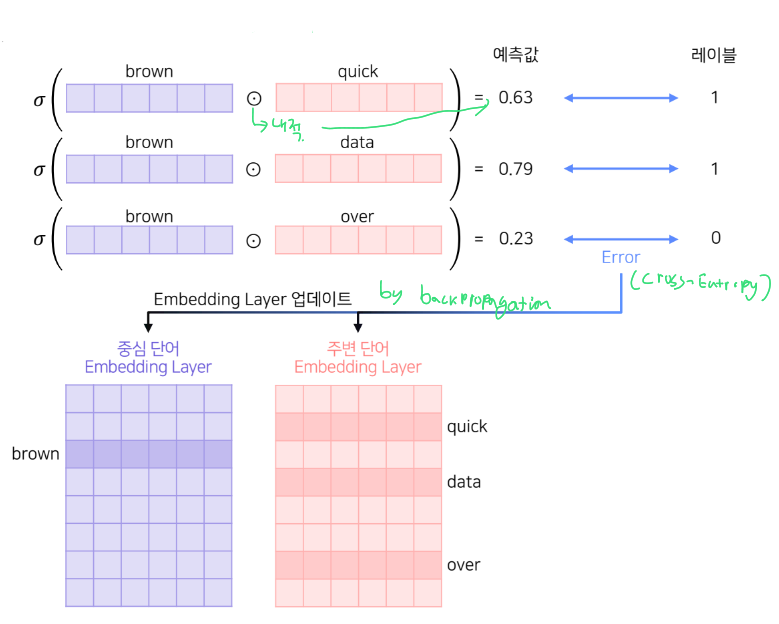
-
중심단어를 기준으로 주변 단어들과의 내적의 sigmoid를 예측값으로 하여 0과 1을 분류
-
역적파를 통해 각 임베딩이 업데이트 되면서 모델이 수렴
-
최종 생성된 워드 임베딩이 2개이므로 선택적으로 하나만 사용하거나 평균을 사용한다
(성능의 차이는 크지 않기 때문에 어떤 것을 써도 괜찮다)
Item2Vec
Item2Vec은 Word2Vec의 SGNS에서 영감을 받아 추천시스템에 적용한 형태이다.
개요
Item2Vec은 단어가 아닌 추천 아이템을 Word2Vec을 사용하여 임베딩하는 방법이다.
기존의 MF도 유저와 아이템을 임베딩하는 방법이기 때문에 논문에서는 MF와 성능비교를 하는데
SVD 기반 MF를 사용한 Item-based MF보다 Item2Vec이 더 높은 성능과 양질의 추천 결과를 제공한다고 한다.
Word2Vec에 적용할 때 아이템 리스트를 문장, 아이템을 단어로 가정하여 적용하게 된다. 여기서 중요한 점은 Item2Vec은 User-item matrix를 사용하지 않는다는 점인데 그렇기 때문에 유저식별 없이 세션 단위로도 데이터 생성이 가능하다는 장점이 있다.
최종 목표는 SGNS기반 Word2Vec을 사용하여 아이템을 벡터화 하는 것이다. 이렇게 임베딩된 벡터는 최종 추천에 활용할 수 있게 된다.
방법
기본적인 방법은 SGNS와 동일하지만 학습 데이터를 생성하는 부분에서 약간의 차이가 있다.
Item2Vec은 유저 or 세션 별로 소비한 아이템 집합을 생성한다.
여기서 집합을 사용하였기 때문에 공간적/시간적 정보(일반 문장에서 Sequential한 정보)는 사라지게 된다.
대신 집합안에 있는 아이템은 서로 유사하다고 가정할 수 있다.
이는 세션별로 sequence의 의미가 제각각 다르기 때문에 그냥 다 동일하게 집합으로 만들어서 집합안에 있는 모든 item의 pair에 대해서 학습데이터를 생성하기 위함이다.
이렇게 sequence 정보를 무시하기 때문에 동일한 아이템 집합 내 모든 아이템 쌍들은 SGNS의 Positive Sample이 된다.(기존의 Skip-Gram이 주어진 단어 앞뒤로 n개의 단어를 사용한 것과 달리 모든 단어(item)쌍을 사용)
이를 통해 Sparse 문제를 해소할 수 있다.
학습데이터 예시아이템 집합 : {A, B, C} -> Word2Vec 데이터 : [A,B,1], [A,C,1], [B,C,1], [A,D,0], ...

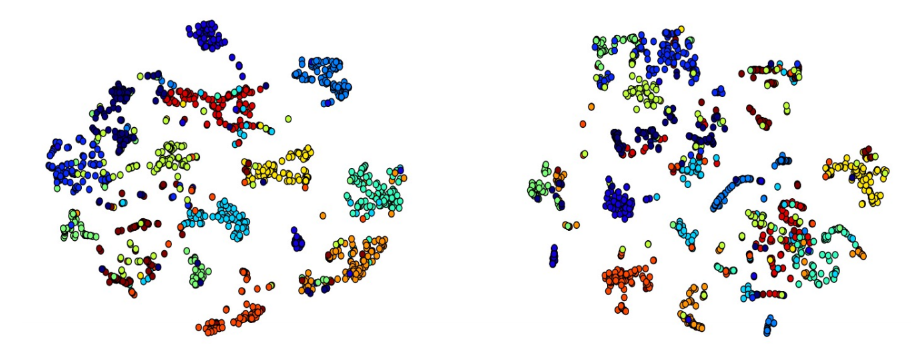
SVD(MF)와 정성적 비교
두 모델의 아이템 벡터를 t-SNE로 임베딩하여 시각화한 결과이다.
왼쪽이 Item2Vec, 오른쪽이 SVD로 한 결과인데, 비슷한 카테고리에 대해 Item2Vec의 클러스터링이 더 잘 된 것을 시각적을 확인 할 수 있다.
다음은 Seed Item(가수)을 두고 Top4 를 추천해준 결과이다.
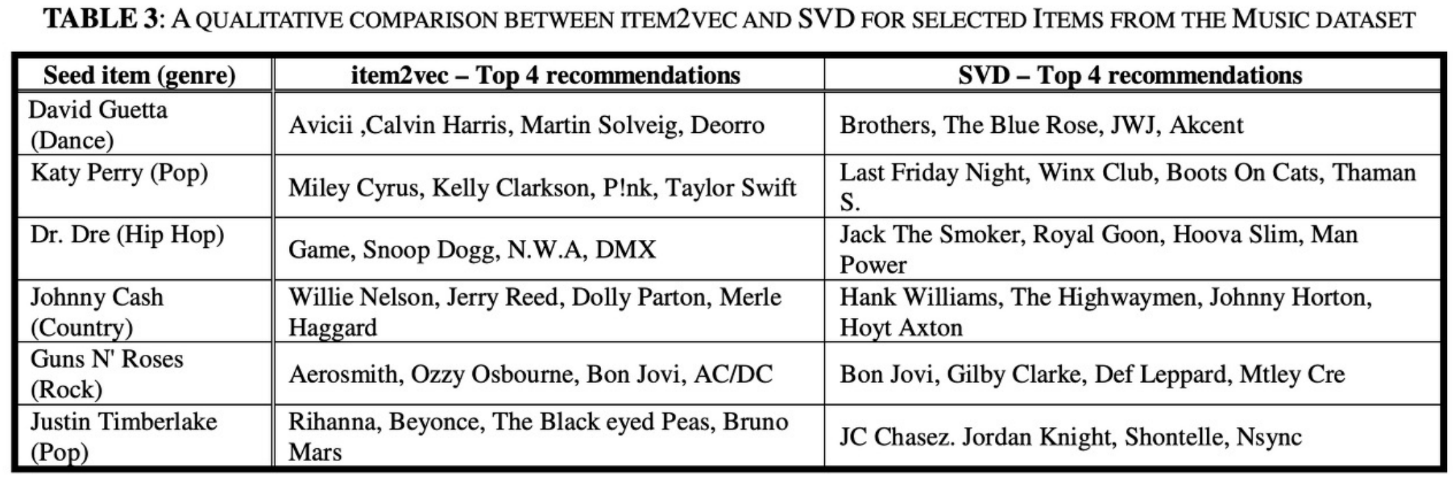
Item2Vec 사례
Item2Vec은 문장과 단어를 어떻게 구성하는지에 따라 많은 분야에서 활용이 가능하다.
- 아프리카tv의 Live2Vec
문장 : 유저의 시청이력 / 단어 : 라이브 방송
-
Spotify의 Song2Vec
문장 : 유저의 플레이리스트 / 단어 : 노래 -
Criteo의 Meta-Prob2Vec
문장 : 유저의 쇼핑 세션 / 단어 : 상품
이렇게 문장과 단어를 어떻게 구성하는가가 각 서비스의 추천을 잘하는 노하우가 될 수 있다.
