ANN의 필요성
Nearest Neighbor(NN)은 Vector Space Model 에서 내가 원하는 Query Vector 와 가장 유사한 Vector를 찾는 알고리즘이다.
NN 자체는 추천시스템과 원래는 관련 있는 문제는 아니었지만, Matrix Factorization 같은 Model-base 추천시스템이 등장하면서 Vector간 유사도 연산을 통해 인접한 이웃(유사도가 높은)을 찾기 위해 도입되었다.
즉 서빙관점에서 본다면 모델학습을 통해 구한 유저or아이템 Vector(Query Vector)가 주어질 때 이에 인접한 이웃을 찾아주는 것이기 때문에추천 모델 서빙은 Nearest Neighbor Search와 같다고 볼 수 있다.
NN의 가장 기본적인 형태는 Brute Force KNN으로 유사도를 정확하게 구하기 위해 모든 Vector와 유사도 비교를 수행하는 방법이다.
이는 차원의 개수에 비례한 Cost가 필요하고, AWS 기준 100차원 Vector 1개의 유사도를 구하는데 0.166초가 걸리고 100만개와 비교하게 된다면 유사도 비교 시간만 46.3시간이 걸리게 된다.
이는 서빙이 불가능한 수준이기 때문에 완전탐색이 아닌 다른 방법으로 유사도 비교를 해야하는 필요성이 생기게 된다.
이를 해결하기 위해 정확도는 조금 포기하고 아주 빠른 속도로 주어진 vector의 근접이웃을 찾아야하는데, 이렇게 정확한 근접 이웃이 아닌 근사적으로 구한 근접이웃을 Approximate Nearest Neighbor라고 부른다.
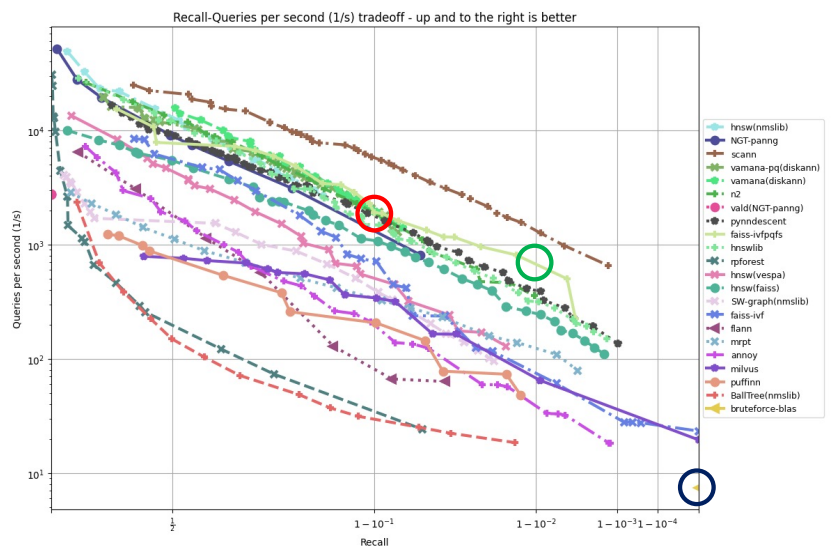
다음 그래프를 보자.
X축은 Recall의 logscale이고, Y축은 초당 처리 건수의 logscale값 이다.
우측하단 파란색 동그라미는 기존의 Brute Force KNN으로 구한 값인데, 100%의 정확도인 대신 1초에 5개의 유사도를 비교할 수 있다.
반면 중앙 빨간 동그라미는 다른 ANN기법들로 구한 값인데, 90%의 정확도를 가진 대신 1초에 1000개 이상 유사도를 비교할 수 있다.
초록 동그라미도 마찬가지로 99%의 정확도를 가지고 1초에 7~800개의 유사도 비교할 수 있게된다.
이처럼 실제 서빙시에는 근접 이웃의 정확도를 조금 포기하고 시간 비용을 크게 절감하여 서빙하는 것이 필수라고 생각 할 수 있다.
ANNOY(Approximate Nearest Neighbors Oh Yeah)
ANNOY는 Spotify에서 개발한 tree-based ANN 기법으로 주어진 벡터들을 여러개의 subset으로 나누어 tree형태의 자료구조로 구성하고 이를 활용하여 탐색하는 방법이다.
그림을 통해 ANNOY의 과정을 알아보자(그림에서 Vector는 편의상 2차원 점으로 나타낸다).
- Vector Space에서 임의의 두점을 선택한 뒤, 두점 사이의 Hyperplane로 Vector Space를 나눔

- Subspace에 있는 점들의 개수를 Node로 하여 Binary Tree 생성
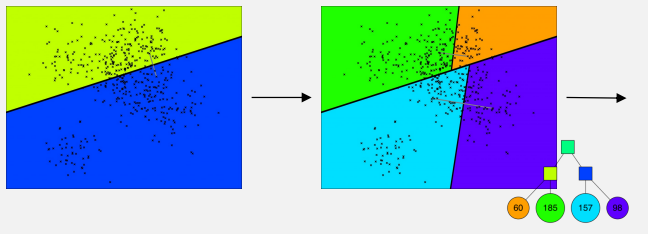
- Subspace 내에 점이 K개 초과로 존재한다면 1,2 반복 진행하여 최종 트리 생성
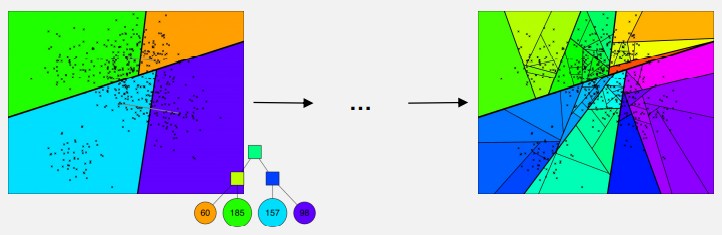
- Query vector(점)을 최종 binary Tree 에서 검색한 뒤(의 시간복잡도로 가능) 해당 Subset에서 NN을 탐색

이렇듯 준수한 성능에 빠른 속도로 근사이웃을 구할 수 있지만 Hyperplae이 랜덤하게 정해졌기 떄문에 가장 근접한 점이 tree의 다른 node에 있을 경우(경계선에 있을 경우) 해당점은 후보 subset에 포함되지 못한다는 문제점이 있다.
이를 해결하기 위해 두가지 해결방안을 제시한다.
- priority queue(우선순위 큐)를 사용하여 가까운 다른 node를 탐색하여 정확도를 높임(시간도 증가)
- binary tree를 앙상블 처럼 여러개 생성하여 병렬적으로 탐색
이 두가지 방안은 모두 정확도를 높일 수 있지만 시간 비용또한 증가함을 명심하자.
이를 적용하기 위해 ANNOY는 두가지 파라미터를 직접 지정해야 한다.
- number_of_trees : 생성하는 binary tree의 개수
- search_k : NN을 구할 때 탐색하는 node의 개수
예시) search_k = 8인 경우
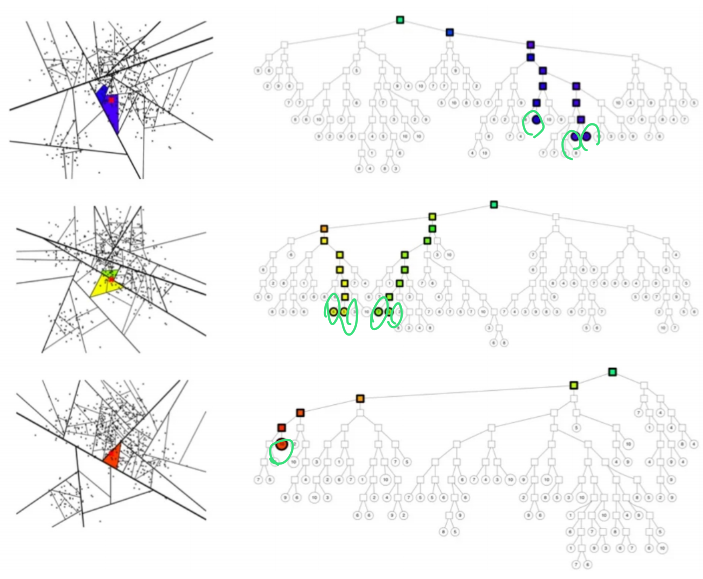
ANNOY를 요약하면 다음과 같다.
-
Serch Index를 생성하는 것이 다른 ANN기법에 비해 간단하고 가벼움
- 아이템 개수가 많지 않고 벡터의 차원이 100보다 낮은 경우 사용하기 적합
- 적은 데이터셋을 가진 추천 모델 학습시 ANNOY로 빠르게 적용해 보는 경우가 많음
-
Search 해야 할 이웃의 개수를 알고리즘이 보장 (이웃의 개수는 search_k를 이용)
-
파라미터 조정을 통해 acc/speed Trade-off 조절 가능
-
단, 학습한 모델이 아니기 때문에 기존에 생성된 binary tree에 새로운 데이터를 추가 할 수 없음
Hierarchical Navigable Small World Graphs (HNSW)
우선 용어의 각 단어들이 무엇을 의미하는지 보자.
-
Small World Graphs : 전체 벡터들 가운데 물리적으로 가까이 연결되어 있는 점만 연결한 그래프
-> 멀리있는(유사도 낮으) 벡터와는 Edge를 갖지 않고 유사한 것끼리만 edge를 갖음 -
Navigable : Small Word Graphs 각각을 서로 연결해 주는 Long Edge를 통해 유사하지 않은 노드들도 탐색할 수 있음(Navigable)
-
Hierarchical : Navigable Small World Graph를 계층적으로 쓰겠다는 의미.
즉 HNSW는 벡터를 그래프의 node로 표현하고 인접한 벡터를 edge로 연결하는 방식이다.
Layer를 여러개 만들어 계층적으로 탐색을 진행하여 search 속도를 향상시키고, Layer 0에 모든 노드가 존재하여 최상위 Layer로 갈수록 개수가 적은 특징이 있다.
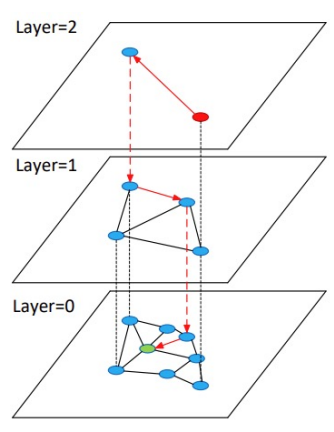
작동방식을 그림과 함께 이해해 보자.
- 최상위 Layer의 임의의 노드(최상단 빨간노드) 에서 시작
- 현재 Layer에서 타겟노드(최하단 초록노드)와 가장 가까운 노드로 이동
- 더 가까워 질 수 없다면 하위 Layer로 이동
- 타겟노드에 도착할 때 까지 2~3 반복
- 2~4에서 방문했던 노드들로 후보 NN을 탐색
이를 활용한 대표 라이브러리로는 nmslib, faiss가 있다.
위에 소개한 두가지 이외에도 Inverted File Index (IVF) , Product Quantization - Compression 등이 있다.
