이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.
Neighborhood-based CF(Memory-based) 의 한계
앞서 배운 Neighborhood-based CF(UBCD, IBCF, KNN-CF) 는 두가지 큰 문제점이 있다.
-
Sparsity(희소성)문제
-
데이터가 불충분 하다면 추천 성능이 떨어진다 (유사도 계산이 부정확해지기 때문에)
-
신규유저,아이템 처럼 데이터가 부족하거나 없는 경우 추천이 불가능(Cold Start Problem)
-
-
Scalability(확장성)문제
- 유저와 아이템이 늘어날수록 유사도 계산량이 늘어남
- 많은 데이터는 정확한 예측을 하지만 시간이 오래걸린다.
- 특히 Memory-based CF는 매 유저가 들어올 때마다 계산하기 때문에 실시간으로 추천해주기 어렵다.
Model Based CF
그동안 배운 Memory-based CF는 (유저간 or 아이템간) 유사성을 단순 비교하는 하였다.
이와 다르게 Model-based CF는 데이터에 내재된 패턴을 이용하여 추천하는 CF기법이다.
내재된 패턴을 학습하기 때문에 ML 이 가능해지며 큰 발전이 이뤄지고 있다.
Model Based CF는 Parametric Machine Learning 사용하여 주어진 데이터를 모델학습시킨다.
그 결과 데이터는 파라미터 형태로 모델에 압축되게 되고 이 파라미터는 데이터의 패턴을 나타내게된다. 이후 최적화를 통해 지속적으로 모델과 파라미터(데이터의 패턴)을 업데이트 시킨다.
Model Based CF의 특징
- 데이터에 숨겨진 User-Item relationship 의 잠재적(Latent) 특성,패턴을 찾음
- NBCF는 유저 아이템 벡터를 그대로 계산
- 현업에서 많이 사용 (특히 Matrix Factorization)
- 최근에는 MF의 원리를 DL 모델에 응용하는 기법이 높은 성능을 냄
Model Based CF의 장점
-
모델 학습/서빙 용이
- 데이터는 학습에만 사용되어 모델에 압축된 형태로 저장됨
- 이미 학습된 모델을 통해 서빙하기 때문에 속도가 빠름
-
Sparsity / Scalability 문제 개선
- NBCF에 비해 sparse한 데이터에서도 좋은 성능
- 유저 아이템 개수가 늘어나도 좋은 추천 성능
-
Overfitting 방지
- 전체 데이터 패턴을 학습 -> 특정 주변이웃에 의한 영향력 없어짐
-
Limited Coverage 극복
- NBCF의 경우 공통의 유저/아이템을 많이 공유해야만 유사도 값의 정확도 향상
- MBCF는 유사도를 사용하지 않고 전체 데이터 패턴을 학습하기 때문에 이웃 없이도 추천 가능
Explicit vs Implicit Feedback
Explicit feedback
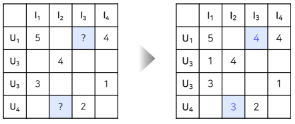
- 평점, 별점 등 item에 대한 user의 명확한 선호도를 알 수 있는 데이터
- 이전에 다룬 데이터는 모두 Explicit feedback
Implicit feedback
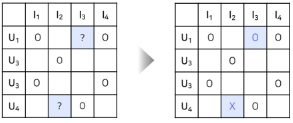
- 클릭여부, 구매여부, 시청여부 등 item에 대한 user의 선호도를 간접적으로 알 수 있는 데이터
- 유저-아이템간 상호작용이 있었다면 1(positive), 없었다면 0(negative) 를 원소로 갖는 행렬로 표현
- 이때 1이라고 해서 유저가 아이템을 선호한다고 볼 수는 없고, 0이라고 해서 유저가 아이템을 비선호 한다고 볼 수 없다(아이템 자체를 몰랐을 수도 있기 때문에)
- 현실에서는 Implicit feedback 데이터의 크기가 훨씬 크고 많이 사용됨
Latent Factor Model
Latent Factor Model 이란 유저와 아이템의 관계를 잠재적 요인(Latent Factor)으로 표현할 수 있을 것이라는 아이디어에서 출발한 모델이다.
이 모델들은 User-item Matrix 를 저차원의 행렬로 분해하는 방식으로 작동한다. 행렬의 차원축소이기 때문에 각 Latent Factor가 무엇을 의미하는지 표면적으로 explicit하게 알 수 없다.
같은 벡터공간에서 유저와 아이템의 벡터 유사도를 확일 할 수 있고, 이를 통해 추천이 진행된다.
Latent Factor Model의 대표적인 기법들
- SVD : Singular Value Decomposition
- Matrix Factorization (SGD, ALS, BPR) - 가장 많이 사용
- Deep Learning
