이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.
Recsys에서 딥러닝을 활용하는 이유
추천시스템에서 딥러닝을 활용하는 이유를 알아보자.
- Nonlinear Transformation
Deep Neural Network는 데이터의 비선형성을 효과적으로 나타낼 수 있다.
따라서 복잡한 user-item interaction 의 패턴을 효과적으로 모델링하여 user의 선호도를 예측할 수 있다.
- Representation Learning
DNN은 raw data로부터 feature representation을 학습하기 때문에 사람이 직접 feature design을 하지 않아도 되기 때문에 텍스트, 오디오, 이미지 등 다양한 종류의 정보를 RecSys에 활용가능
-
Sequence Modeling
DNN은 자연어처리, 음성신호처리 등 sequntial 한 데이터에 대해 성공적인 성과를 얻었다.
추천시스템에서는 next-item prediction, session-based recommendation(같은 세션에서 추천)에 사용될 수 있다. -
Flexibility
Pytorch, Tensorflow 등 다양한 프레임워크가 존재하기 때문에 모델링의 flexibility가 높으며 효율적인 serving이 가능함
하지만 실제 서비스를 serving 할 때, 사용자와 서버의 Latency가 있고 기존 방법에 비해 월등히 좋은 성능을 보이지 않기 때문에 딥러닝으로 추천을 진행하는 기업은 Pinterset, Google 정도가 있다.
NCF : Neural Collaborative Filtering
NCF는 MF의 한계를 지적하여 신경망 기반의 구조를 사용해 더욱 일반화된 모델을 제시한다.
이 부분은 논문 리뷰를 통해 정리한 부분을 참조하도록 하자.
NCF 논문리뷰
Youtube Recommendation
Deep Neural Networks for YouTube Recommendations 논문으로 유튜브에서는 어떻게 영상 추천을 하는지 알아보도록 하자.
YouTube 추천 문제의 특징
-
Scale
: 엄청 많은 user 와 item 과 제한된 컴퓨팅 파워를 고려해야 하므로 효율적 서빙과 이에 특화된 추천 알고리즘이 필요 -
Freshness
: 잘 학습된 컨텐츠와 새로 업로드 된 컨텐츠를 실시간으로 조합해야함 -
Noise
: 높은 Sparsity, 외부 요인 등의 이요로 유저 행동을 예측하기 어려움
즉 explicit feedback 뿐만 아니라 Implicit Feedback과 메타 데이터를 잘 활용해야함
YouTube 추천모델
YouTube 추천모델은 두가지 서브 모델로 나누어져 있다.
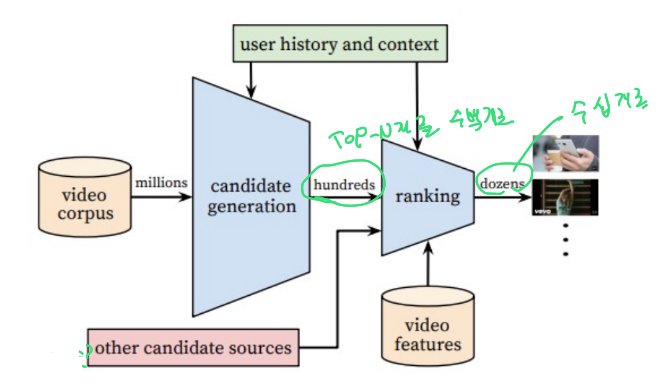
-
Candidatie Genderation
High Recall(실제 Positive 중 예측 Positive의 비율)을 목표로 한다.
주어진 사용장 대해 수백만개의 비디오중 수백개의 비디오 Top N 을 생성한다. -
Ranking
유저, 비디오 feature를 좀더 풍부하게 사용하여 스코어를 구하고 최종 추천 리스트를 제공해 준다.
이렇듯 딥러닝 기반 2단계 추천을 처음으로 제안한 논문이자, 단순 연구에서의 성능 뿐 아니라 어떻게 서빙해야 현업에서 사용할 수 있는지 제시한 기념비적인 논문이다.
기본 CF의 경우 유저 ID만 사용한 것에 비해 Candidatie Genderation에서는 기존 CF 아이디어 기반으로 다양한 피쳐를 사용해 추천 성능을 향상시켰다.
과거의 선형or트리기반 모델보다 Ranking 모델은 더 많은 feature를 사용하여 뛰어난 성능을 보여주었다.
Candidate Genernation
그림으로 차근차근 알아보자.
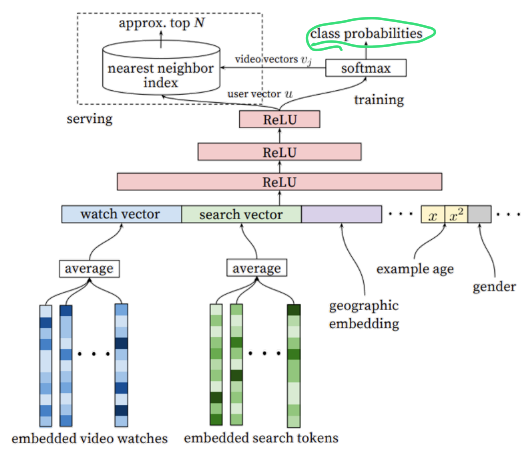
첫번째 서브모델인 Candidate Genernation 유저가 좋아할 만한 수백개의 비디오를 생성하는 Task로 Multi-class Classification의 문제로 접근한다.
특히 YouTube는 탐색할 비디오가 수백만개가 되기 때문에 Extreme 을 붙여 Extreme Multi-class Classification 문제라고 정의한다.
이를 위해 마지막에 특정시간(t)에 유저U가 C라는 context를 가지고 있을 때 비디오(i) 각각을 볼 확률을 구한다.
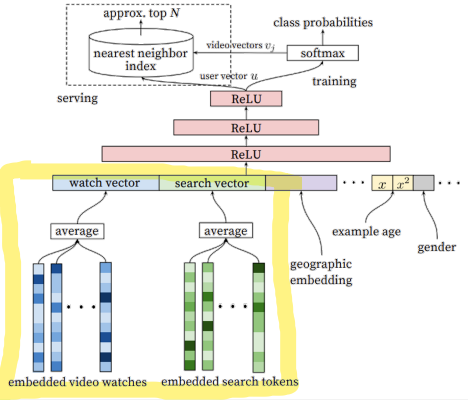
이번엔 watch vector와 search vector가 어떻게 생성되는지 살펴보자.
- 과거시청이력과 검색이력을 각각 임베딩 (embedded video watches, embeddie search tockens)
- average layer에서 각 임베딩 벡터를 평균냄(마지막 검색어가 너무 큰 힘을 갖지 않도록)
- watch vector와 search vector 생성
- 예측하기 위해 모델로 들어감
이렇게 되면 유저가 볼만한 비디오를 classification 할 때 과거에 스포츠 영상을 봤을 경우 스포츠 영상이 분류될 확률이 높아진다.
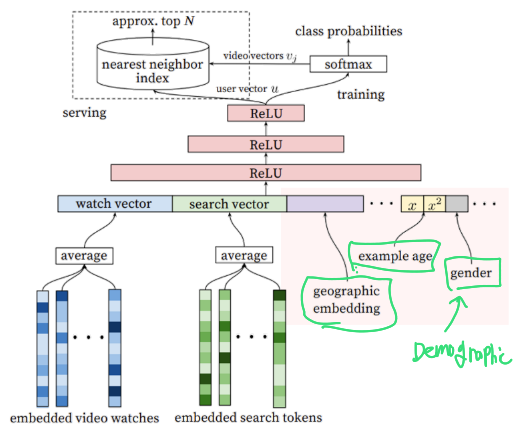
watch vector와 search vector 옆에는 어떤 벡터들이 들어가는지 보자.
총 3가지가 추가적으로 임베딩되어 모델 예측의 Input으로 추가된다.
- Demographic feature : 성별 등의 인구통계학 정보
- Geograpic feature : 지리적 정보
- Example age feature
: 이 아이템이 언제 생성됐는지에 관한 feature이다.
만약 Example Age가 없으면 모델이 과거 데이터 위주로 편향되어 학습하는 준제가 발생하기 때문에 시청로그가 학습시점으로부터 경과한 정도를 피쳐로 포함한다.
즉 과거는 덜 학습하고 최신은 더많이 학습할 수 있도록하기 위함이다.
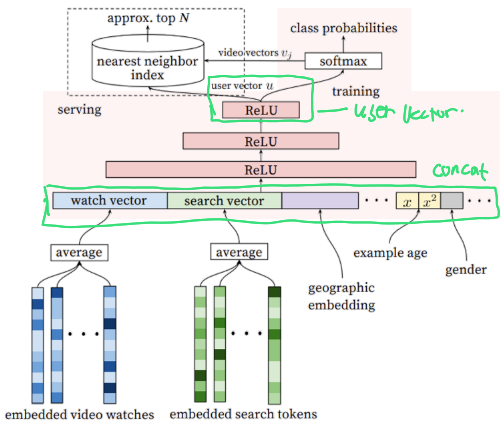
이제 위에서 구한 다양한 feature vector들을 한번에 Concat한다.
Concat한 vector을 N개의 Feed Forward Neural Network를 거쳐 User Vector를 생성한다.
최종 Output Layer는 Multi class classification을 하기 때문에 비디오를 분류하는 softamx function을 사용한다.
이렇게 유저를 Input으로 하여 상위 N개의 비디오를 추출한다.
이때 서빙시에 유저벡터()와 모든 수백만개의 비디오 벡터()의 내적을 계산하는 것은 사실상 불가능하기 때문에 Annoy나 Faiss같은 ANN 라이브러리를 사용하여 정확한 Top-N이 아닌 적당한 Top-N을 찾아 빠르게 서빙을 하게된다.
Ranking
Ranking 모델은 Candidate Genernation 단계에서 생성한 비디오 후보들을 Input으로 하여 최종 추천될 비디오들의 순위를 매기는 문제이다.
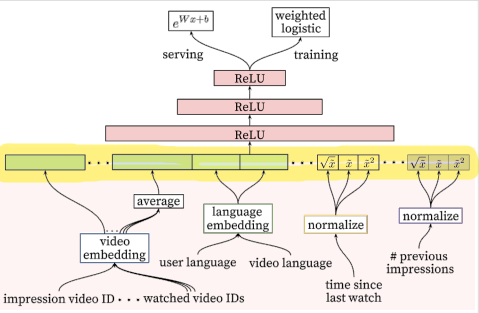
Input Feature 부분은 User actions feature을 사용한다.
- 유저가 특정채널에서 얼마나 많은 영상을 봤는지
- 특정 토픽의 동영상을 본지 얼마나 지났는지
- 영상의 과거 시청 여부 등을 입력
- 어떤 언어를 사용하는지
이 부분은 DL 구조보다는 Feature selection/engineer 등이 필요하고 도메인 지식이 중요한 부분이다.
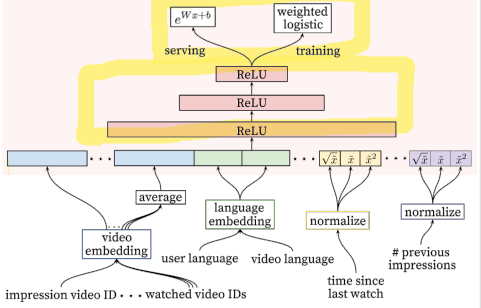
MLP 네트워크를 통과한 뒤 비디오가 실제로 시청될 확률로 매핑한다.
Logistic 회귀를 사용하여 노출시 클릭할 확률을 output으로 한다.
이때 Loss function에서 비교될 참값은 단순 클릭여부(binary)가 아니라 시청시간을 가중치로한 값(weighted cross-entropy loss)을 사용한다.
클릭 후 바로 나가는 비디오의 경우 낚시성/광고성 콘테츠로 간주하여 학습에 반영시키지 않게 하기 위함이다.
