이번엔 선형회귀 Linear Regression에 대해서 살펴보고, 지도학습의 전체적인 과정에 대해 볼 것이다.
지도학습과 회귀 문제
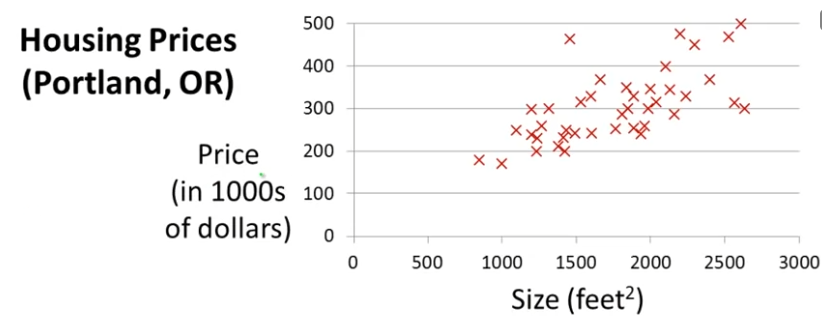
위는 Oregon과 Portland 도시의 주택 가격 Data Set이다. 집을 팔려고 하는 친구에게 이 자료를 준다고 가정하고, 친구의 집 사이즈가 일 때, 얼마에 팔 수 있는지를 알려준다고 하자.
처음 할 수 있는 일은 데이터를 따라 일직선을 그려서 예측하는 것이다.
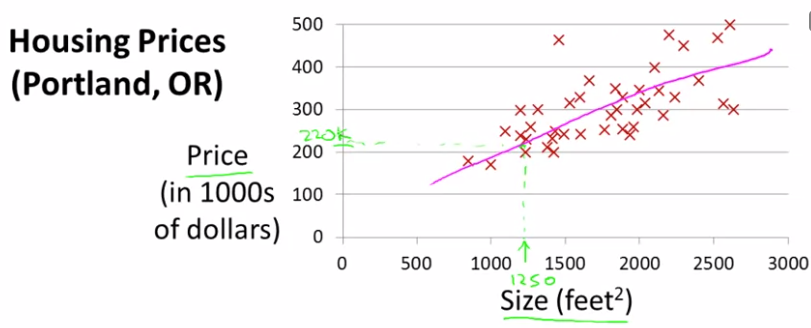
이에 따르면, 220,000 달러에 팔 수 있다고 말해줄 수 있다. 이것이 지도학습의 예시인 이유는, "적합한 답"을 주기 때문이다. 다시 말해, 각각의 어떤 가격에 팔렸는지에 대해 말하고 있고, 게다가 이것은 실제 수치의 결과, 가격의 예측하는 회귀라는 의미의 Regression 문제의 예시이다. 다른 대부분의 Supervised Learning 형태는 분류문제(Classification)로 불리는데, 예를 들면 암종양을 찾을 때 그게 악성인지 아닌지에 대한 것은 이산값을 예측하는 문제 같은 것이다. 따라서 0, 1의 이산값이다.
공식적으로, 지도학습(Supervised Learning)에서 우리는 데이터 셋을 가지고 있고, 이 데이터셋을 우리는 학습 셋이라고 부른다. 주택 가격 예제에서 우리는 서로 다른 주택 가격의 학습셋을 가지고 있고 우리가 할 일은 이 데이터로부터 어떻게 주택 가격을 예측할지 이다.
표기법
앞으로 강의 내내 사용할 표기법을 외우도록 하자.
m = Number of training example
x's = "input" variable / features
y's = "output"variable / "target" variable아까 주택 가격 예제에서,
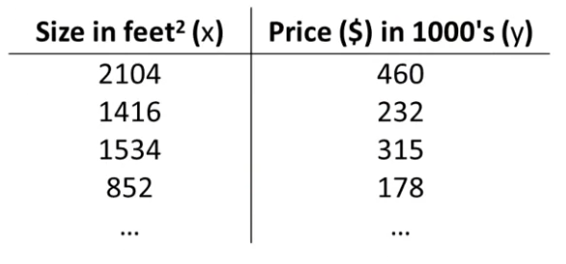
training example은 총 47개 였으므로 m = 47, x = size, y = price가 된다.
(x, y)는 하나의 학습 예제를 표기하는 데 사용할 것이고, 이 표에서 한 줄은 특정한 하나의 학습 예제와 대응된다. 는 i번째 학습 예제를 의미한다. 예를 들면 은 2104이고, 는 232이다.
가설 h
Training Set (훈련 집합)을 통해 배우게 될 것은 이 지도 학습이 어떻게 작동하냐이다. 주택 가격과 같은 Training set을 지도 알고리즘에 사용할 것이다. 지도 알고리즘은 결과값을 내는데 이는 h라고 부른다. h는 hypothesis를 의미한다.
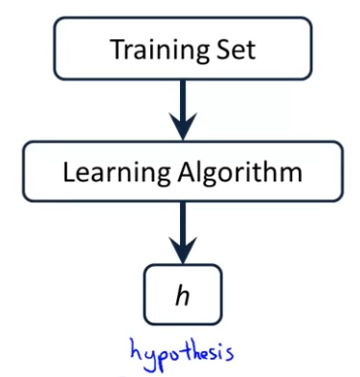
이제 이 h에서 x를 입력으로 받고, 결과를 y라고 하자.

이 경우 h maps from x's to y's.라고 할 수 있다. h가 '가설'이라는 의미를 가져서, 조금 어색하게 느껴질 수도 있지만, 이 단어는 기계학습에서 사용되는 전문용어다. 그러니 사람들이 왜 이렇게 부르는가에 대해서 너무 생각하지 않아도 된다.
h를 결정하기
지도 알고리즘을 디자인할 때, 우리가 그 다음으로 정해야할 것은 가설 h를 어떻게 표현할지에 대해서이다. 일단 예시로 가설 h를 다음과 같이 표현하자.
이를 shorthand로 나타내면 다음과 같다.
로 나타내기 귀찮아서 shorthand(약칭)로 라고 나타낸 것이다.
이를 그림으로 나타내면, 이 의미는 우리가 x의 선형함수인 y를 예측하는 것이다. 그래서, 자료와 함수가 하는 것은 x의 몇몇 직선함수인 y를 예측하는 것이다.
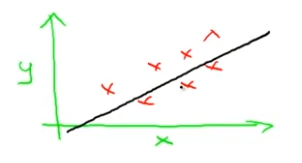
그리고 이 직선은 와 같다. 왜 로 선형함수를 사용할까? 가끔 우리는 비선형함수 같은 좀 더 복잡한 것을 사용하기도 하지만, 이 선형 유형은 간단한 빌딩 블록이라서 선형블록을 사용한다. 그리고 앞으로 더 복잡한 모델과 학습 알고리즘으로 갈 것이다.
이 모형은 선형 회귀라고 불리고, 실제로 선형회귀의 값은 하나이며, 이 값은 x이다. 하나의 x로 모든 가격을 예측한다. 또한, 이 모형의 다른 이름은 단일 변량 선형 회귀이다. 단일 변량이라는 말은 하나의 값을 멋있게 얘기한 것 뿐이다.
