
1.파이썬 기초
파이썬을이용한 다양한 기능들을 사용하기 앞서 파이썬에 대한 기본적인 문법들을 공부하였다. 자세한 내용은 생략.
2.requests
크롤링을 하기 전에 리퀘스트라는 프로그램을 다운받았다.
그렇다면 requests는 무엇일까? requests 라이브러리는 ajax와 유사하게 api 데이터를 추출할 때 해당 패키지를 사용하며, 파이썬에서 http를 호출하는 프로그램을 작성할 때 주로 사용한다.
requests사용법
1. 설정 -requests패키지 깔아주기
2. (기본 코드)
import requests
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
print(rjson)
아래 사진과 같이 기본적인 문법을 연습해 보았다.
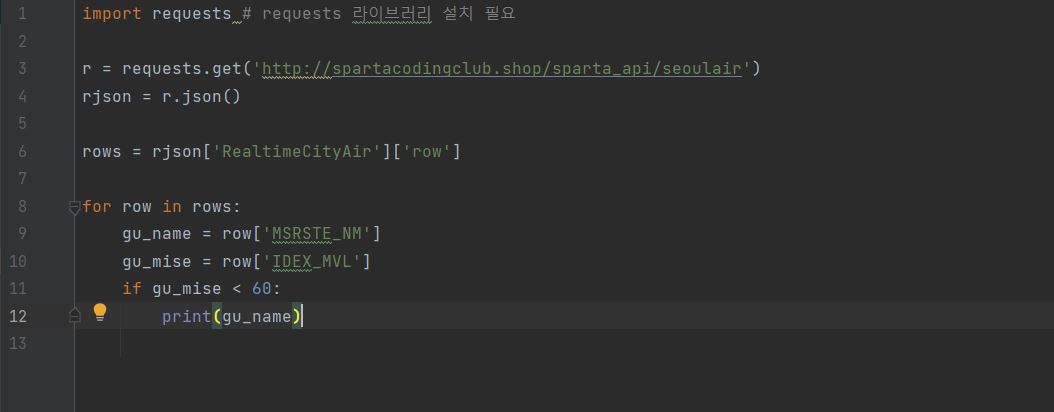
이런식으로 코드를 입력하면 아래와 같이 구 이름만 프린트 할 수 있다.

3. 웹 스크래핑(Web Scraping)이란
웹 페이지로부터 원하는 정보를 추출하는 기법이다.
웹 스크래핑은 흔히 웹 크롤링(Web Crawling)이라고도 많이 불린다. 물론 엄밀하게 두 단어는 서로 다른 의미이다.
크롤링은 여러 웹 페이지를 기계적으로 탐색하는 일을 말한다. 한편 웹 스크래핑은 특정한 하나의 웹 페이지를 탐색하고, 또 소스코드 작성자가 원하는 정보를 콕 집어 얻어낸다는 점에서 크롤링과 차이가 있다.
그럼에도 크롤링과 스크래핑은 구현방법이 거의 같기 때문에, 실무에서는 구분없이 많이 불린다.
첫 번째로 웹 페이지가 변경되거나 중단되면 수집 또한 중단된다는 것이다.
두 번째로 수집빈도를 높이는 것이 현실적으로 어렵다는 것이다.
마지막으로 법적이슈에 취약하다는 것이다.
웹스크래핑 하는 방법
1. html가져오기(리퀘스트이용)
2. bs4 패키지 설치
3. 필요한 데이터 찾기 (beautiful soup)
4.크롤링 기본코드
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
코딩 시작
4. beautiful soup 사용방법
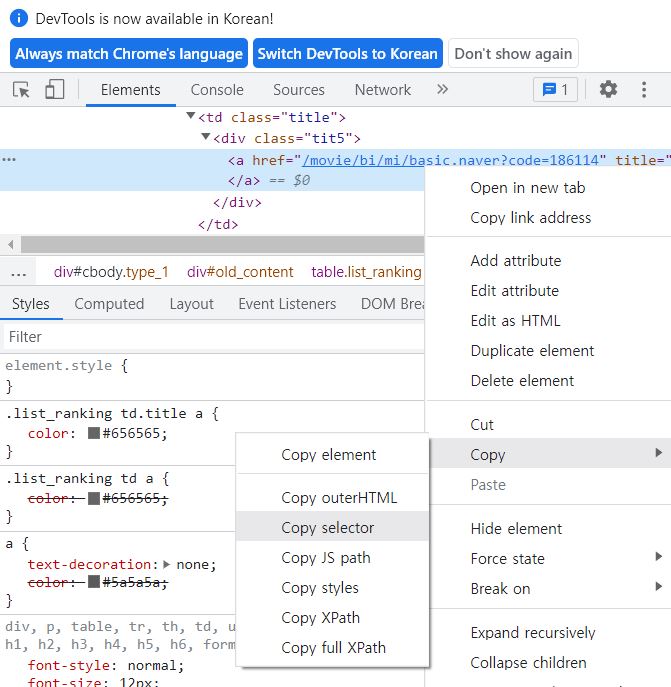
원하는 데이터에 카피셀렉터 클릭 하면 그 부분만 가져온다.
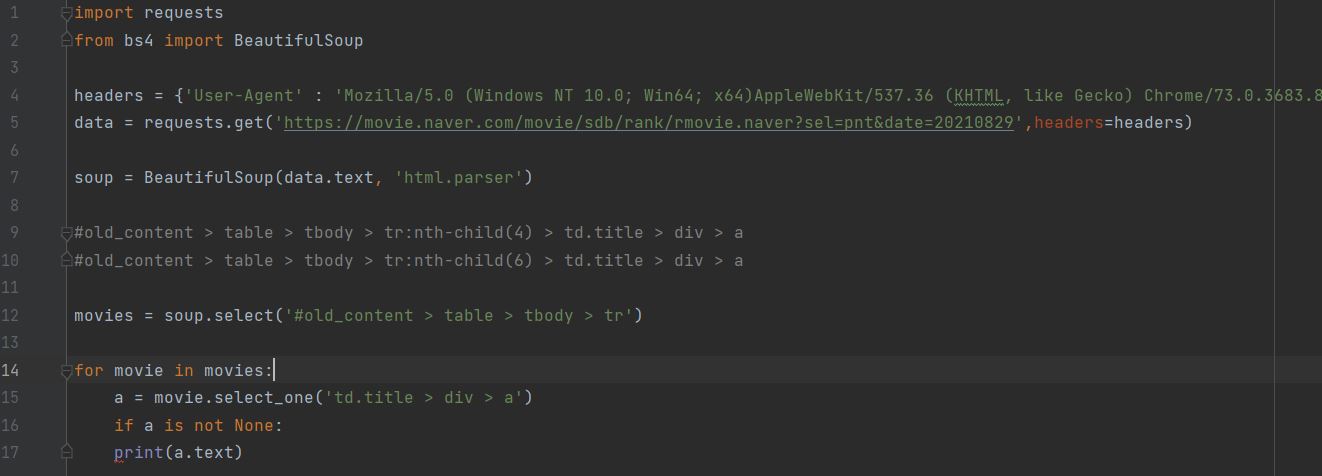
해당 데이터 하나만 이면 soup.selectone / 모두 이면 soup.select
row12)무비라는 데이터 꾸러미 만들기 (모두 일 경우 겹치는 선택자 까지 )
row14)무비를 모두 돈다.
row15)가져오고 싶은 데이터 중 겹치는 셀렉터 뒷부분을 셀렉트원 해주기
row17)값만 가져올려면 a.text해주기
alt속성을 데리고 오고 싶으면 ['alt'] --> 단 none 뒤에 해줘야 한다. 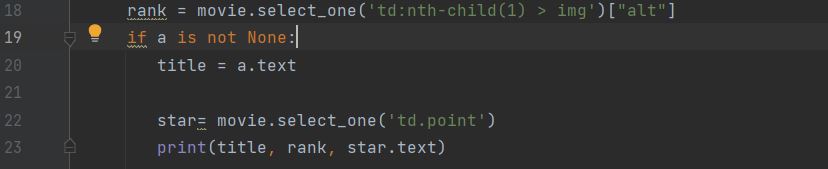

순서를 논 앞에 코드를 짰더니 오류가 발생하였다.
4. db
데이터베이스는 왜쓰는 걸까 나중에 데이터를 잘 찾아서 뽑아서 쓰기 위해서 사용하는 것이다.
db에는 두가지가 있다. sql(정형화, my sql)과 nosql (비 정형화, 유연성, mongodb)이 있다.
5.mongodb 사용하기
db는 클라우드 형태로 제공을 하는 것이 용이하다.클라우드의 장점 : 유저가 몰리거나, 백업해야하거나, 모니터링 하기에 아주 용이 하다. 그중에서
mongodb atlas가 최신 트렌드 이다.
몽고디비사용법
1.패키지: pymongo, dnspython 깔기
2.mongodb가입하기
3.. pymongo 기본코드
from pymongo import MongoClient
client = MongoClient('여기에 URL 입력')
db = client.dbsparta
내꺼: from pymongo import MongoClient
client = MongoClient('mongodb+srv://test:test@cluster0.us9qe.mongodb.net/myFirstDatabase?retryWrites=true&w=majority')
db = client.dbsparta
*파이몽고 이용하는데 필요한 코드는 : dbprac에 있다.
- 크롤링 한 내용 db에 저장하기
row23)앞전에 크롤링한 코드 아래에 doc={}을 만들고
row)28 저장하기 코드를 넣는다.
단, 이름은 원하는 원하는 파일명을 넣는다.
**
그외 공부한것들
SyntaxError: unexpected EOF while parsing : 이런 오류가 발생 --> 구문오류라고 함--> 그림4 따옴표 안넣음
alt 태그 : 태그의 alt 속성은 이미지를 보여줄 수 없을 때 해당 이미지를 대체할 텍스트를 명시합니다.
대부분의 데이터베이스에는 CRUD라는 개념이 있다(Create, Read, Update, Delete)
