📢 합성곱 신경망에 대한 페이지입니다.
MLP 이미지 분석의 한계
MLP 신경망을 이미지 처리에 사용한다면 “이미지의 위치”에 민감하게 동작
→ 위치에 종속적인 결과를 얻게 됨! (모든 픽셀을 연산하기 때문)
CNN
이미지의 특징을 추출해서 비교하자! → 이게 CNN!
CNN 출현 배경
인간이 이미지 인식할 때 노의 모든 부분이 아닌, 특정 부분 영역만 활성화 된다는 것을 바탕으로 CNN 발전됨!
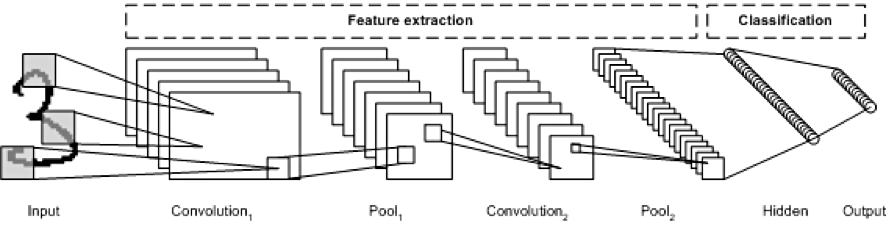
CNN 구조
 Reference: https://taewanmerepo.github.io/2018/01/cnn/head.png
Reference: https://taewanmerepo.github.io/2018/01/cnn/head.png
- dense 가 아닌 이미지 분석에 특화된 layer 사용 → conv, pooling
- 이미지 데이터 큼 → 📢 목표: 특징만 남기고 데이터 압축하기
- conv layer = 특징만 남기기 (위 이미지에서 빨간색 부분)
- pooling layer = 의미 없는(예, 배경) 데이터는 제거 (위 이미지에서 파란색 부분)
→ 이렇게 점차 특징만 남기고 데이터 줄임
- feature extractor: 특징 추출하는 부분 ← 이게 추가 됨!!!
- classifier: 특징 가지고 연산하는 부분 (MLP 로, 단순 연산하는 층)
CNN 과정
1단계: 심플 특징
2단계: 디테일 특징
…
마지막: 판단
CNN 원리
CNN 이 어떻게 특징 추출할까?
- CNN(합성곱)은 입력된 이미지에서 특징을 추출하기 위해 “필터(커널)” 개념 도입
- 이미지 전체 영역(전체 픽셀)에 대해 서로 동일한 연관성(중요도)으로 처리하는 대신 특정 범위에 한정해 처리한다면 훨씬 효과적일 것이라는 아이디어에서 착안
필터(커널) 적용 방식
 Reference: https://miro.medium.com/v2/resize:fit:1400/1*z3tVpwY2ULg3UlwXwAGQwg.png
Reference: https://miro.medium.com/v2/resize:fit:1400/1*z3tVpwY2ULg3UlwXwAGQwg.png
- 우선 필터의 개수와 크기는 지정해야 함
- 대신 그 값은 랜덤하게 지정됨!
- 필터 개수 많을수록 복잡해져서 좋지만 또 너무 많아서 과적합 될수도 있음
- 그 다음, 필터를 겹쳐서, 같은 자리에 있는 값들끼리 곱한 값들을 더함! → 특징 집약
- 필터는 계속 이동(슬라이딩) → 여기서는 9번 이동
CNN layer 설계 전략
- Input: input layer
- 맨 첫번째 Conv 에
input_shape지정해주면, 생략 가능
- 맨 첫번째 Conv 에
- Conv: 특징 추출
- Pooling: 특징 아닌 부분 삭제 (크기가 줄어듦)
- Flatten: 1차원으로 변경
- feature extractor 에서 classifier 로 넘길 때, MLP 한테는 1차원 데이터 넘겨야 해서 그 사이에 flatten 해야함!
- Dense: 집약된 특징들로 규칙찾기 (분석)
- Dense: output layer
무조건
conv 1개 → pooling 1개이렇게 사용하지 않고, 보통conv 2-3개 -> pooling 1개이런식으로 사용함!
CNN 연산 과정
- 네모 하나 = 픽셀 하나
- 픽셀 하나는 RGB 값으로 구성되어 있음
- 커널 종류는 짱 많음 (랜덤하게 생성됨)
- 이 커널들 중 이미지의 일부와 비슷하면 거기는 큰 값을 출력함
- conv 많아 질수록 복잡해짐 → 그렇게 복잡한 모양/특징 추출
축소 샘플링(subsampling)
- 합성곱을 수행한 결과 신호를 다음 계층으로 전달할 때, 모든 정보를 전달하지 않고 일부만 샘플링하여 넘겨주는 작업
- 축소 샘플링 하는 이유
- 의미 있는 정보만 다음 단계로 넘겨주기 위함!
- 딥러닝에서 원하는 결과를 얻기 위해서는 결국 핵심 정보만 다음 계층으로 전달하는 장치가 필요함!
- 2가지 기법
- 스트라이드(Stride)
- 풀링(Pooling)
스트라이드(Stride)
- 합성곱 연산을 수행할 때 필터를 한 픽셀씩 옆으로 이동하면서 출력을 얻는게 아니라, 2~3 픽셀씩 건너 뛰면서 합성곱 연산을 수행하는 방법 (스트라이드 2, 스트라이드 3)
- 기본적으로 커널 이동할 때 1 픽셀씩 이동하는데 연산량 많고 이미지가 크면 사실 1 픽셀씩 옆으로 이동하는게 큰 차이가 없음 → 그래서 이동하는 보폭을 크게 하자!
- 이렇게 하면 출력 데이터(특성 맵)의 크기를 1/4, 1/9로 줄일 수 있음
- 사용예시 (2,2) → 행/열 2칸씩 이동
- conv 층에 사용하는 속성
패딩(Padding)
- 여백 만들어줌! (엄밀히 말하면, 이미지 데이터 바깥쪽에
0값을 채워줌) - 패딩의 2가지 기능
- 가장자리 데이터 손실 막기 위함!
- 가장자리/모서리에 있는 것들은 커널이 1번밖에 지나가지 않아서 데이터 특징 소실될 수 있음. 그래서 겉에 의미없는 데이터(
0) 씌워줌 → 가장자리 데이터 잃지 않을 수 있음!
- 가장자리/모서리에 있는 것들은 커널이 1번밖에 지나가지 않아서 데이터 특징 소실될 수 있음. 그래서 겉에 의미없는 데이터(
- 입출력 크기 같게 맞춰주기 위함(크기 손실 방지)! → 즉, 층이 깊어지면서 이미지의 크기가 줄어드는 것을 방지
- 커널 사용해서 읽다 보니까 데이터가 작아지는 문제 발생
- 가장자리 데이터 손실 막기 위함!
- Conv2D 층에 사용하는 속성
same: 출력과 입력이 같아지게 적절한 수의 패딩을 자동으로 입력- 보통 모든 conv 에서
same옵션 사용! - 여기서 질문 .. 아니 우리 축소 하려고 하는데 왜 패딩으로 늘리는거야? CNN 목적은 의미있는 데이터를 잃지 않고, 집약하는 것! 그래서 padding 으로 손실을 막으면서 stride 나 pooling 으로 데이터를 줄여주는 전략 ~
- 보통 모든 conv 에서
valid: 패딩 사용 X (default)pooling: 입력보다 출력이 크게 만듦- 직접 지정은 안됨
Conv2D layer 속성
Conv2D(filters = 32,
kernel_size = (5,5),
padding = 'same',
input_shape = (28,28,1),
activation = 'relu',
strides = (2,2))filters- 커널(필터) 개수
kernel_size- 커널(필터) 사이즈
(행, 열)
padding- 데이터 경계 처리 방법 정의
input_shape- 샘플 수 제외한 입력 형태 정의
- 모델에서 첫 레이어일 때만 정의
(가로 픽셀, 세로 픽셀, 채널 수) - 흑백인 경우에는 채널
1, 컬러(RGb)인 경우에는 채널3으로 설정
strides- 필터 이동 보폭 크기
- stride 크기 지정
(행, 열)
