📢 활성화 함수의 종류와 각 layer 에서의 활성화 함수 역할에 대한 페이지입니다.
Hidden vs Output Layer 에서의 활성화 함수 역할
- 선형 모델이 출력한 결과에 추가 연산
- 중간층, 출력층의 역할이 다르다 ~
- 중간층: 역치 (활성화 여부 결정)
- 출력층: 선형모델이 예측한 값에 추가 연산을 해줌으로써 출력하고자 하는 데이터 형태로 변경
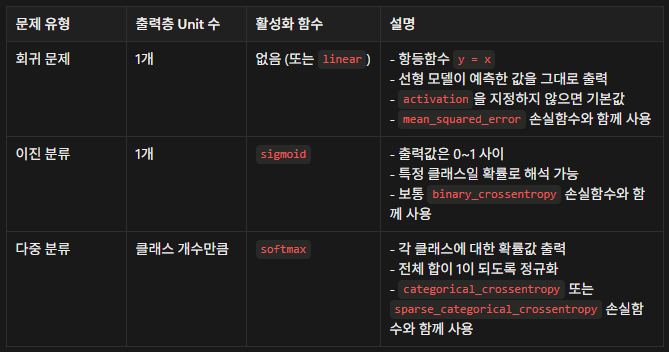
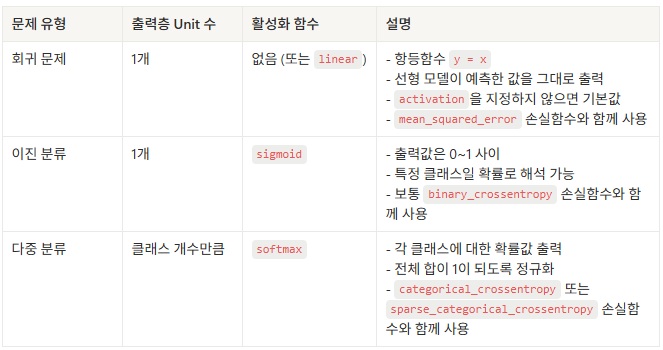
- 회귀: 연속값(선형 모델이 출력한 값을 그대로 출력, 변환 X), Linear(항등함수, y=x) -> default
- 분류: 확률값으로 변환 (0~1), sigmoid 사용
Activation function 종류
Step function
- 분류 초기 활성화 함수 (분류니까 0아니면 1이라서 계단함수로 가능)
- 경사하강법이라는 optimizer 를 만나자 문제 발생
- 미분을 통해 기울기 구하는데 step function 은 모두 기울기가 0 … 문제닷! → 경사하강법 쓸 수가 없다 ..
- 그래서 계단함수 모양을 가져가되, 곡선으로 만들자! (기울기를 만들자!)
- 미분을 통해 기울기 구하는데 step function 은 모두 기울기가 0 … 문제닷! → 경사하강법 쓸 수가 없다 ..
Sigmoid function
Sigmoid 를 사용함으로써 기울기가 생기긴 했지만
여전히 문제가 있어요..
그건 바로 기울기 소실 문제!
이걸 알려면 오차 역전파를 알아야 해서 그 내용부터 봅시다.
오차 역전파(Back Propagation)
순전파, 역전파
- 순전파: 입력 데이터를 입력층에서부터 출력층까지 정방향으로 이동시키며 출력값을 예측해 나가는 과정 → 예측값 출력
- 역전파: 출력층에서 발생한 에러를 입력층 쪽으로 전파시키면서 최적의 결과를 학습해 나가는 과정 → 에러를 바탕으로 학습
- 순전파와 역전파를 계속 돌면서 모델 학습하게 됨
손실 함수 및 Sigmoid 함수의 미분
- 신경망이 학습하기 위해서는 경사하강법(loss 함수를 미분)을 사용
- Step function 은 기울기가 없으니까 Sigmoid 함수 사용하게 됨
기울기 소실 문제 (Vanishing Gradient)
- 컴퓨터 발전하면서 연산량 많아도 되자, 층을 더 깊게 쌓음
- 그런데 모든 층에서 활성화 함수로 sigmoid 를 사용하다 보니
- sigmoid 의 미분 값을 계속 곱하게 됨
- 그러다 보니 오차가 0으로 가까워지는 기울기 소실 문제 발생
그렇다면 왜 sigmoid 미분 값을 계속 곱하면 0이 되는가?
Sigmoid 함수의 문제점
- Sigmoid 가 loss 로서 함께 미분됨
- Sigmoid 미분했을 때 최댓값은 겨우 0.25
- 오차역전파를 할 때 오차에 계속 0.25를 곱하면 점점 값이 0이 되어감 → 앞쪽 층으로 가면 거의 오차가 없는 것처럼 보임 → 오차가 없다고 착각하고 모델이 학습되지 못함 (제대로된 학습 X) = 기울기 소실 문제
중간층에서의 activation function 변천사
- Sigmoid 함수의 미분값의 최댓값이 줄어드므로, 미분한 값이 1이 될 수 있도록 -1 ~ 1 사이 값을 가지는 hyperbolic tangent 함수를 만듦!
- but, 최댓값만 1인거지 그 외 부분에서는 또 오차를 작게 만듦 ..
- 그래서 사용한 것이 ‘relu’! 기울기도 가지면서 오차 그대로 반영해줌.
- 0보다 작을 때는 0으로
- 0보다 클 때는 x 값 그대로!
Softmax function
- 각 클래스에 대한 확률값 출력
- 전체 합이 1이 되도록 정규화
- 보통 다중분류 모델의 출력층에서 사용
회귀/분류에 따른 출력층에 사용하는 활성화 함수 종류
- 코드
# 회귀 model.add(Dense(uniuts=1, activation='Linear')) # = model.add(Dense(uniuts=1)) # 분류 (이진 분류) model.add(Dense(uniuts=1, activation='sigmoid')) # 분류 (다중 분류) model.add(Dense(uniuts=10, activation='softmax'))
