- 머신러닝의 7과정을 이해하자!
- 머신러닝의 학습과정을 이해하고 결과를 확인해보자!
- 온습도 데이터를 분석하여 결과를 예측하자!
0. 순서
1. 문제 정의
2. 데이터 수집
3. 데이터 전처리 (이상치, 결측치 정리)
4. EDA
5. Model 선택, Hyper Parameter 조절
6. Training (model.fit(X_Train,y_test))
7. Evaluation1. 문제 정의
- 온습도 데이터를 활용하여 환기 여부를 파악
- Role: 서비스 기획자
- 가정 내 온습도 데이터를 측정하는 기기를 고객에게 제공
- AI 제습기 개발하고자 함 (머신러닝 모델을 탑재 예정)
온도, 습도에 따른 상쾌(1), 불쾌(0) 를 판단하는 이진분류 실습
2. 데이터 수집
- 온습도 데이터 사용
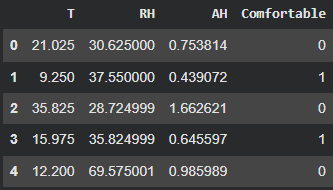
- 데이터 명세
Column Name 컬럼명 설명 T(temperature) 온도 주변 환경의 온도 (섭씨) RH(relative humidity) 상대습도 공기 중 습도의 비율 (%) AH(absolute humidity) 절대습도 공기 중 실제 수증기량 Comfortable 쾌적 여부 환경이 쾌적한지 나타내는 이진값 - 0(불쾌), 1(상쾌)
3. 데이터 전처리
- 이상치, 결측치 제거
- 입력변수 처리
- 특성공학 -> 피쳐 추가, 삭제, 새로운 피쳐 생성 등(입력 피쳐에 대한 수정)
- 인코딩
- 문자열 데이터 -> 수치형
- 머신러닝 학습 시, 주의사항
- 결측치 제거
- 비어있는 값이 있으면 학습 불가 (오류)
- 문자열 데이터 인코딩
- 문자 형태의 값 학습 불가 (오류)
- 숫자 형태로 변경 (인코딩)
- 결측치 제거
df.info()
# 머신러닝 학습을 위해 확인 !!
# 1. Non-null count: 결측치 여부 확인
# 2. Dtype: 데이터 타입 확인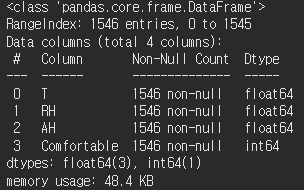
→ 해당 실습에서는 이상치, 전처리 작업 X
4. EDA
- 탐색적 데이터 분석, Exploratory Data Analysis
- 데이터의 기술통계량 확인 (요약된 수치 정보) -> 데이터를 다양한 과점에서 관찰하고 이해하는 과정
- 데이터를 전처리하는 근거가 되기도 함
- 결측치, 이상치를 명확하게 확인 후 재 전처리도 가능
기술통계량
-
count: 데이터 개수
-
mean: 평균
-
median: 중앙값
-
std: 표준편차 -> 데이터 분포 파악할 때 사용 (분산의 루트 값)
-
min, max: 최솟값, 최댓값
-
25%, 50%(중위값, 중위수), 75%: 4분위수 -> 데이터의 분포를 4등분해서 확인
-
대푯값: 평균, 중앙값, 최빈값
-
보통 확인하는 값
- mean vs median : outlier 가 있을 확률 높음
- std : outlier 가 있을 확률 높음
df.describe().T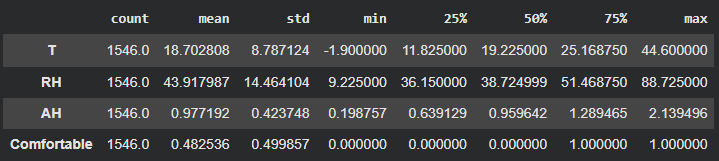
상관계수
- 컬럼(피쳐 혹은 정답) 간에 상관관계를 확인
- 상관계수: 컬럼들 사이에 연관성 확인 -> 비례/반비례 정도를 수치로 표현
- 1 ~ 1 사이의 값을 가짐
- 절댓값이 1에 가까울수록 연관성이 높은 값!
- 사용 예시) 어떤 피쳐가 정답과 상관이 없을 경우, 해당 피쳐 제거
# 상관계수
# -1 ~ 1 사이의 값을 가지며 "절댓값"이 1에 가까울수록 연관성이 높다!
df.corr()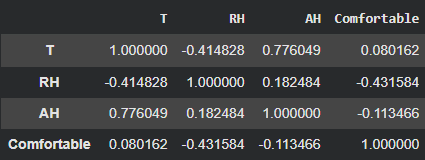
→ Comfortable과 가장 연관성이 높은 피쳐는 RH !
5. model 선택 및 하이퍼 파라미터 조절
5.1. 학습 전 데이터 준비 (분리)
- feature(X) 와 label(target, y) 분리
- 학습용 데이터(train), 평가용 데이터(test) 분리
# 1. 머신러닝 학습을 위한 데이터 분리
# 문제데이터 (X): T, RH, AH
# 정답데이터 (y): Comfortable
X = df.drop(['Comfortable'], axis=1)
y = df['Comfortable']
X, y
# 2. # 학습용 vs 평가용
# 데이터 분할 도구 활용하기 (train_test_split())
from sklearn.model_selection import train_test_split
# 문제와 정답을 넣으면 4개의 변수에 대입 -> 변수명 고정!
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, stratify=y, random_state=42)
# 데이터 확인
X_train.shape, y_train.shape, X_test.shape, y_test.shape-
문제와 정답의 개수가 동일해야 한다!
-
입력 특성의 개수가 동일해야 한다!
-
train_test_split 옵션
- 랜덤샘플링 -> randome_stat: 매번 다르게 추출되는 데이터를 일관성 유지하기 위해 고정 변수 지정
- stratify: 클래스 비율 일정 맞춰주기 위해 사용 -> 클래스 불균형 해결 (regression 에서는 사용 불가!)
5.2. 모델 선택
- 모델 도구 불러오기
# 분류 모델 도구 불러오기 from sklearn.neighbors import KNeighborsClassifier- sklearn (사이킷런) 라이브러리
- 대표적인 머신러닝 라이브러리, 머신러닝에 필요한 다양한 도구 지원
- 지도학습모델, 비지도학습 모델, 전처리도구, 실습용데이터 등 지원
- KNN(K-Nearest Neighbors, 최근접이웃모델)
- 데이터의 특성 중 가장 가까운 이웃을 따라가는 방법
- 거리 계산을 하는 모델 (가까운지 판단하기 위해) - 보통 유클리디언 거리계산 공식 이용
- 분류: 클래스의 개수를 다수결로 결정
- 회귀: label 값들의 평균으로 결정
- sklearn (사이킷런) 라이브러리
- 모델 객체 생성
# 모델 객체 생성 knn_model = KNeighborsClassifier(n_neighbors=1)- 분류 모델에서는 이웃수(n_neighbors)는 홀수!
- 짝수를 설정해도 오류는 발생하지 않으나, 같은 결과 값이 나올 경우 클래스 번호가 작은걸 선택하기 때문에 의미가 없음!
- 그래서 홀수를 설정하는 것이 좋음.
6. 모델 학습
# 모델 학습 (학습용 문제, 학습용 전달)
knn_model.fit(X_train, y_train)7. 모델 예측 및 평가
from sklearn.metrics import accuracy_score
### 예측
pred = knn_model.predict(X_test)
# 방법 1
accu = accuracy_score(y_test, pred) # 순서 상관 없음
accu
# 방법 2
# sklearn 모델이 제공하는 기능
# 예측 단계를 건너뛰고 바로 정확도만 확인하고 싶을 때 사용 (예측과 평가를 동시에 진행 -> 결과값(정확도)만 출력)
knn_model.score(X_test, y_test)- 분류 모델의 평가 지표 -> 정확도 (accuracy)
- metrics - 평가지표 모음집 (다양한 지표들 수록)
- accuracy 정확도: 전체 평가 데이터에서 맞힌 데이터의 비율
- 0~1 사이의 숫자를 가짐 -> 1에 가까울수록 성능이 좋은 모델 (정확도 1 = 100% 정답)
- 의문점
- 그럼 정확도가 높다고 무조건 좋은 모델일까?
- → 놉! 모델의 일반화가 가장 중요!!
- 그럼 정확도가 높다고 무조건 좋은 모델일까?
