일반화, 과대/과소적합에 대한 내용을 정리한 페이지입니다.
개념
- 모델의 신뢰도를 측정하고, 성능을 확인하기 위한 개념
- 일반화
- 과대적합
- 과소적합
과대적합 = overfitting
하나의 관측치에만 과하게 학습하여 다른 데이터가 들어왔을 때 부정확한 값을 내뱉는 것
train GOOD / test(new data) BAD
즉, “train 에 대해서 너무 과하게 학습되어 train 데이터에만 잘 동작하고 test 에서는 예측 성능이 저하되는 현상”
→ 지양해야 하는 학습법!
과소적합 = underfitting
너무 간단하게 학습 시켜버림!
train BAD / test(new data) BAD
즉, “train 데이터를 충분히 반영하지 못해 train, test 데이터 모두 예측 성능이 저하되는 현상 (학습을 제대로 하지 못한 것)”
→ 지양해양 하는 학습법!
일반화 = generation
train 데이터로 학습한 모델이 test 데이터에 대해서도 정확히 예측하는 현상
→ 지향해야 하는 학습법! 우리의 목표!
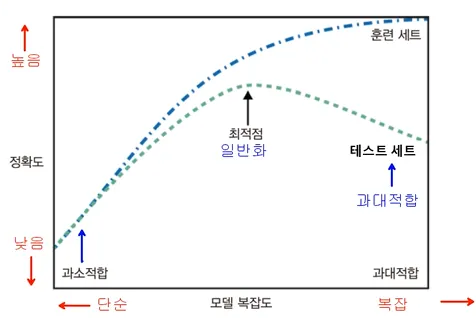
우리의 목표
목표: “일반화 성능이 최대화 되는 모델을 찾는 것”
- 과대적합: 너무 상세하고 복잡한 모델링 → 훈련 데이터만 과도하게 정확히 동작하는 모델
- 과소적합: 모델링을 너무 간단하게 해서 성능이 제대로 나오지 않는 모델
모델 복잡도 곡선
(추가) 분류 모델에서 과소/과대 방지 방법
- class 의 비율을 맞춰주기
y의 비율을 맞춰 줌으로써 클래스 불균형 해결 한쪽 클래스가 너무 쏠려있는 경우, 해당 클래스에 대해서만 과대적합됨!train_test_split(X, y, **stratify=y**)
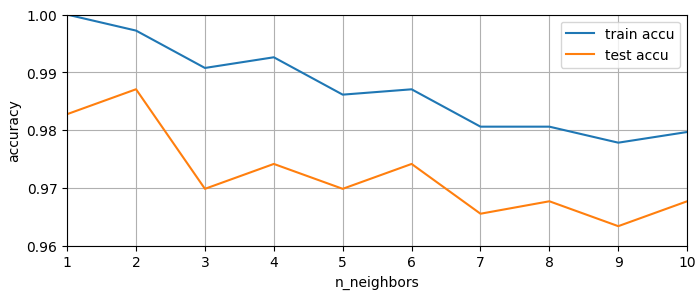
모델의 일반화 곡선 그리기
- 1부터 50까지의 이웃의 수를 하이퍼 파라미터 조절하여 모델링 진행 -> 복잡도 확인 위함
- 시각화 -> 학습 후의 train, test 결과의 정확도 출력
각 정확도 구하기
# train, test 정확도 담을 list
train_list = []
test_list = []
n_set = range(1,51) # 1~50 까지 1씩 증가하는 수
# 학습~평가 반복
for k in n_set:
# model 객체 생성
knn_tmp = KNeighborsClassifier(n_neighbors=k)
# model 학습
knn_tmp.fit(X_train, y_train)
# model 예측 및 평가
accu_train = knn_tmp.score(X_train,y_train)
accu_test = knn_tmp.score(X_test,y_test)
# 정확도 저장
train_list.append(accu_train)
test_list.append(accu_test)시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(8,3)) # 캔버스 크기 결정 -> 가장 상단에 작성
plt.plot(n_set, train_list, label='train accu')
plt.plot(n_set, test_list, label='test accu')
plt.legend() # 범례 표시
plt.xlabel('n_neighbors') # X축 이름
plt.ylabel('accuracy') # Y축 이름
plt.xlim((1,10))
plt.ylim((0.96,1))
plt.grid() # 눈금 표시 -> 모눈종이 형태로 출력
plt.show() # print 역할