- 군집(clustering) 에 대해 이해할 수 있다.
- K-means, 계층적 군집, DBSCAN 을 이해하고 사용할 수 있다.
개념
 Reference: https://media.geeksforgeeks.org/wp-content/uploads/20250904105944868523/Clustering.webp
Reference: https://media.geeksforgeeks.org/wp-content/uploads/20250904105944868523/Clustering.webp
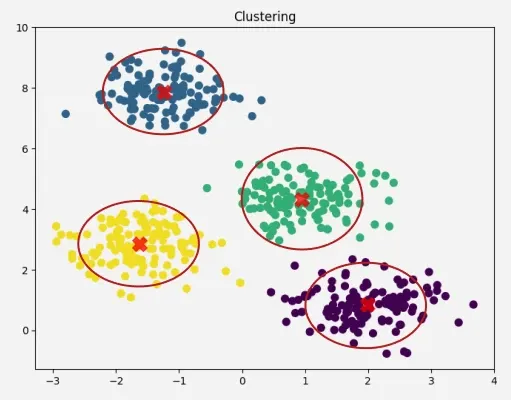
- 비슷한 데이터끼리 하나의 클러스터로 묶고, 다른 데이터끼리는 다른 클러스터로 분류
종류
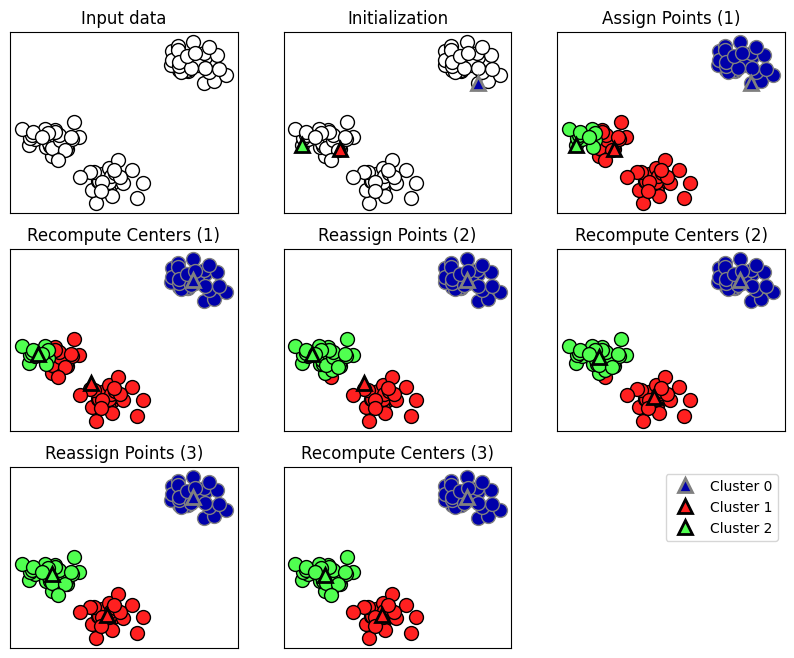
K-means
- 일반적으로 사용되는 알고리즘
- 알고리즘이 쉽고 간결함
- 거리 기반 알고리즘으로 피쳐 개수 많으면 군집화 정확도 떨어짐
- 이유
- 피처가 많아질수록 모든 데이터 포인트가 서로 비슷하게 멀어짐 → 거리의 차이가 아주 작아짐
- 피처 수가 늘어나면 노이즈의 영향도 같이 커져서 거리 계산이 흐트러짐 → 군집이 정확하지 않음
- 위 두 현상이 합쳐지면 고차원에서는 밀도 기반/거리 기반 군집화 자체가 잘 안 됨
- 이유
- 반복 횟수가 많아질 경우 수행 시간이 매우 느려짐
- noise 에 매우 민감
- 하이퍼 파라미터: 군집 개수 ‘K’
- 적절한 개수 지정 필요
- 몇으로 설정해야 할지 가이드하기 어려움
- 초기 Centroid 위치는 랜덤하게 설정
성능 저하 원인
- 흩어진 데이터가 있는 경우
- 데이터가 고리 모양인 경우
- 모양이 복잡한 경우
- cluster 수보다 k가 작은 경우
- cluster 수보다 k가 큰 경우
- 중심이 치우친 경우
군집 평가
 Reference: https://cdn.analyticsvidhya.com/wp-content/uploads/2024/10/image-24.png
Reference: https://cdn.analyticsvidhya.com/wp-content/uploads/2024/10/image-24.png
- 엘보우 기법(Elbow, 팔꿈치)
- 클러스터링 알고리즘에서 최적의 클러스터 수를 결정하기 위해 사용되는 시각화 기법
- SSE(Sum of Squared Errors)
- 클러스터 내 데이터 포인트들이 클러스터 중심으로 얼마나 떨어져 있는지를 나타내는 값
- 오차 제곱의 합
- SSE 가 낮다고 무조건 좋은 건 아님 → 너무 잘게 쪼개서 과대적합했다는 것!
- 클러스터 수가 증가함에 따라 SSE 가 급격히 감소하다가 완만해지는 지점을 찾는 것이 목표
- 완만해지는 지점이 최적의 클러스터 수를 나타낸다고 판단 → 위 그래프에서는 “4”
- 그래프를 통해 직곽적으로 파악할 수 있으나, 주관이 개입될 수 있음
사용법
from sklearn.cluster import KMeans
# 객체 생성
km_model = KMeans(n_clusters=5, random_state=42)
# 모델 학습
km_model.fit(X)
# 결과 확인
labels = km_model.labels_계층적 군집
- Hierarchical clustering
- 데이터 포인트들을 계층적인 구조로 그룹화 하는 방법
- 계층적 트리 모형을 이용하여 개별 데이터 포인트들을 순차적, 계층적으로 유사한 클러스터로 통합하여 군집화를 수행하는 알고리즘
- K-means 군집 알고리즘과는 달리 클러스터의 개수를 사전에 정하지 않아도 학습 수행
덴드로그램
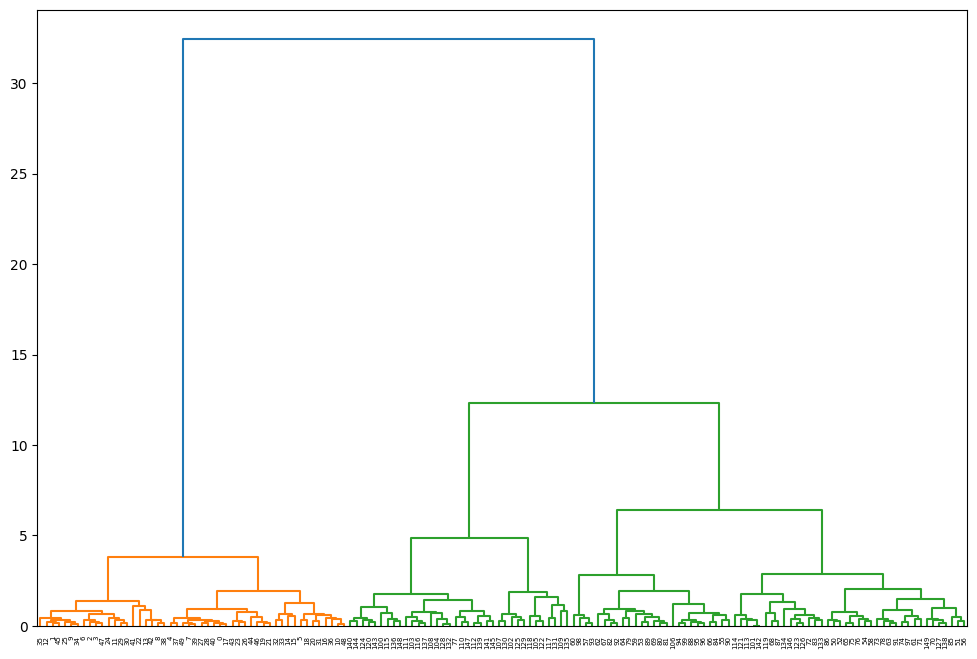
- 계층 군집을 시각화하는 도구
- 덴드로그램에서 가지의 길이는 합쳐진 클러스터가 얼마나 멀리 떨어져 있는지를 보여줌
- 계층적으로 군집화를 완료한 후에 사용자가 시각화된 덴드로그램을 보고 가로 선으로 분할하면 클러스터를 임의로 나눌 수 있음
- K-menas 군집과 마찬가지로, 계층적 군집에서도 데이터 간의 거리를 기반으로 하기 때문에 복잡한 형상의 데이터 세트는 구분하지 못함
사용법
import scipy.cluster.hierarchy as sh
plt.figure(figsize=(12,8))
sh.dendrogram(sh.linkage(X, method='ward'))
plt.show()- 결과 예시
- 3~4개로 나눌 수 있겠군!
DBSCAN
- “밀도” 기반 알고리즘! (위에 2개는 “거리” 기반~)
- 밀도 있게 연결되어 있는 데이터 집합은 동일한 클러스터라고 판단
- 일정한 밀도를 가지는 데이터의 무리가 마치 체인처럼 연결되어 있으면, 거리의 개념과는 관계없이 같은 클러스터로 판단
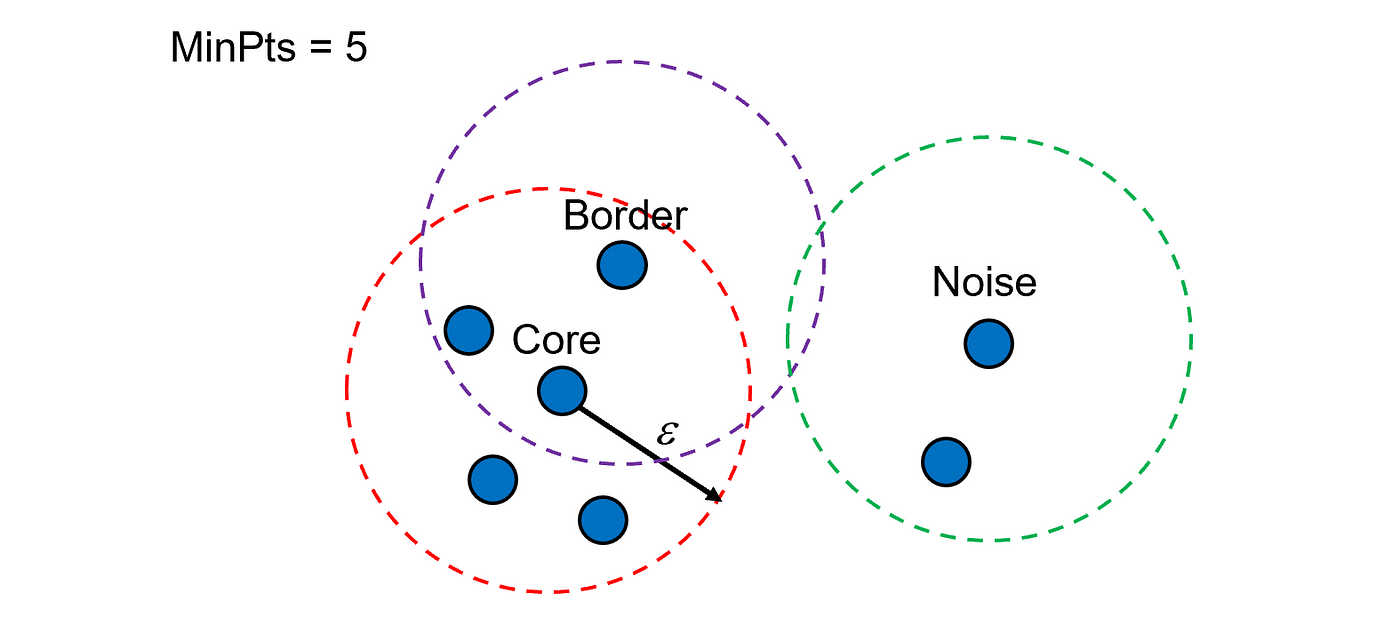
- hyper parameter
epsilon: 일정 반경min_samples: 최소 포인트 수
- 포인트 종류
 Reference: https://miro.medium.com/v2/resize:fit:1400/1*arv3b3Um_Opu_zOECGwt6w.png
Reference: https://miro.medium.com/v2/resize:fit:1400/1*arv3b3Um_Opu_zOECGwt6w.png
장단점
- 장점
- K-means 단점인 초기 군집 개수 정할 필요 없음
- K-means 는 거리기반인데 DBCAN은 밀도이기 때문에 outlier 에 대해서는 noise 로 치부함 → noise 민감 X
- K-means 단점인 고리형과 같은 비선형도 군집화 할 수 있음 즉, 클러스터의 모양과 크기에 관계없이 효과적으로 클러스터를 찾을 수 있음
- 단점
- epsilon 과 min_samples 하이퍼 파라미터에 대해 군집 결과가 달라질 수 있음 → 즉, 하이퍼 파라미터 설정에 민감함
- 데이터의 밀도가 크게 차이나는 경우, 클러스터링 결과가 좋지 않을 수 있음
- epsilon 과 min_samples 하이퍼 파라미터에 대해 군집 결과가 달라질 수 있음 → 즉, 하이퍼 파라미터 설정에 민감함
사용법
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.5, min_samples=4)
dbscan.fit(X)
X_copy = X.copy()
X_copy['dbscan_cluster'] = dbscan.fit_predict(X)
X_copy- 결과
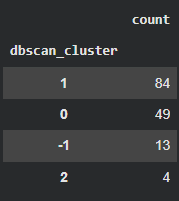
X_copy['dbscan_cluster'].value_counts()
# -1: noise point
# 따라서 3개의 군집으로 나눔!- 결과
평가 지표
- 비지도 학습의 특성상 어떠한 지표라도 정확하게 성능을 평가하기는 어려움
- 그러나 군집화의 성능을 평가하는 지표들은 존재함
- 여러 지표들을 활용하여, 어느 정도 군집화에 대한 성능 판단 가능
ARI
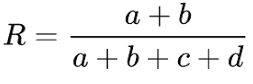
- 유사성 비교! → 얼마나 비슷하냐~
- Adjusted Rand Index: RI를 보정한 지표
- RI: 두 클러스터링 결과가 어느 정도 일치하는지에 대한 지표
- 예측된 군집화와 실제 라벨(비지도는 정답이 없으므로, 다른 클러스터링 결과) 간의 유사성 측정
- 값 범위
- -1 ~ 1 사이 값을 가짐
- 1 에 가까울수록 두 클러스터링 결과가 완벽하게 일치 GOOD
- 0 에 가까울수록 두 클러스터링 결과가 특별히 잘 맞지도, 완전히 엉망도 아닌 상태 SOSO
- -1에 가까울수록 두 클러스터링 결과 간의 일치도가 랜덤보다 낮음 BAD
사용법
from sklearn.metrics import adjusted_rand_score
ari_3 = adjusted_rand_score(iris['target'], labels_3)
ari_3