iris(붓꽃) 데이터를 이용하여 군집화 모델을 만들어보자!
1. import library and data
-
학습용 그래프 라이브러리 ‘mglearn’
# 학습용 그래프를 제공해주는 라이브러리 # !pip install mglearn import mglearn -
‘sklearn’ 에 있는 iris data
# 사이킷런에서 제공하는 데이터인 붓꽃데이터 확용 from sklearn.datasets import load_iris iris = load_iris() # 입력 데이터 X = iris['data'] # 실제 정답 y = iris['target'] # 정답 -> 클래스 이름 확인 iris['target_names'] # feature name iris['feature_names'] # 입력 데이터 df 로 바꾸기 X = pd.DataFrame(iris['data'], columns = iris['feature_names']) X- 아예 정답이 없으면 배울 때 답답해 해서 그냥 정답 있는 데이터 가져온거래요~
- 데이터
- 번치객체 (묶음, 다발) = sklearn 전용 데이터 타입 = dictionary
- 예시
{'data': array([[5.1, 3.5, 1.4, 0.2], [4.9, 3. , 1.4, 0.2], [4.7, 3.2, 1.3, 0.2], [4.6, 3.1, 1.5, 0.2], [5. , 3.6, 1.4, 0.2], [5.4, 3.9, 1.7, 0.4], [4.6, 3.4, 1.4, 0.3], [5. , 3.4, 1.5, 0.2], [4.4, 2.9, 1.4, 0.2], ... 'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]), #['sepal length (cm)',: 꽃받침의 길이 # 'sepal width (cm)',: 꽃받침의 너비 # 'petal length (cm)',: 꽃잎의 길이 # 'petal width (cm)']: 꽃잎의 너비
2. K-means 군집화
-
모델 학습
from sklearn.cluster import KMeans # 객체 생성 km_model = KMeans(n_clusters=5, random_state=42) # 모델 학습 km_model.fit(X) # 비지도라서 정답 데이터 없음!!- hyper parameter
n_clusters: k 개의 군집으로 데이터를 나누겠다는 의미random_state: 초기 중심점의 위치를 고정하여 “결과 재현성 보장”
- hyper parameter
-
결과 확인
# 결과 확인 labels = km_model.labels_ labels array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 2, 0, 2, 0, 2, 0, 2, 2, 2, 2, 0, 2, 0, 2, 2, 0, 2, 0, 2, 0, 0, 0, 0, 0, 0, 0, 2, 2, 2, 2, 0, 2, 0, 0, 0, 2, 2, 2, 0, 2, 2, 2, 2, 2, 0, 2, 2, 4, 0, 3, 4, 4, 3, 2, 3, 4, 3, 4, 4, 4, 0, 4, 4, 4, 3, 3, 0, 4, 0, 3, 0, 4, 3, 0, 0, 4, 3, 3, 3, 4, 0, 0, 3, 4, 4, 0, 4, 4, 4, 0, 4, 4, 4, 0, 4, 4, 0], dtype=int32)- 시각화
# 결과 시각화 # 특성 4개라서 4차원으로 그릴 수 없으니, 특성 2개만 사용 sns.scatterplot(x = X['petal length (cm)'], y = X['petal width (cm)'], hue = labels, palette = 'Set1')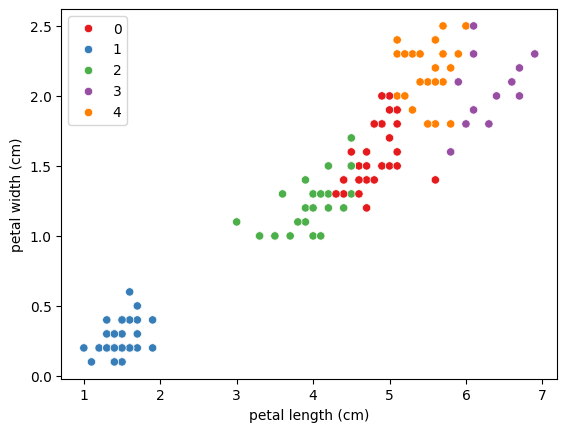
- 시각화
-
최적의 군집 수 찾기
-
엘보우 기법
# 1 ~ 10 개 클러스터에 대한 SSE 를 계산 k_range = range(1,11) sse = [] for k in k_range: kmeans = KMeans(n_clusters=k, random_state=42) kmeans.fit(X) sse.append(kmeans.inertia_) # inertia_ : sse # 시각화 plt.plot(k_range, sse, marker = 'o') plt.grid() plt.xticks(k_range) # x 축 range 표시 plt.show()-
결과
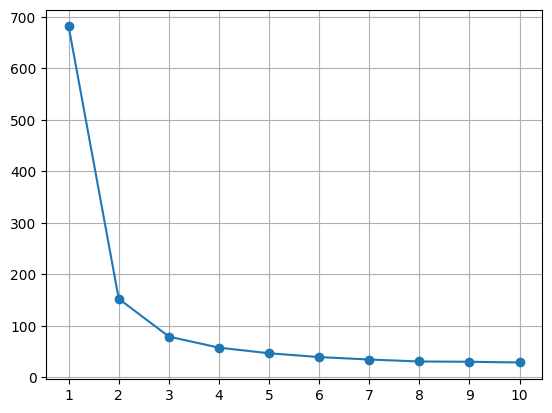
- k = 3 이후로 완만해짐
-
-
-
평가
-
k=3 으로 설정하고 ARI 계산해보자! (이번엔 실제 데이터랑 비교. 비지도는 다른 클러스터링 결과와 비교)
-
ARI 계산 및 시각화
# 실제 값과 군집화 결과 비교하기 # k = 3 으로 모델링 kmeans_3 = KMeans(n_clusters=3, random_state=42) kmeans_3.fit(X) labels_3 = kmeans_3.labels_ # ari 값 계산 from sklearn.metrics import adjusted_rand_score ari_3 = adjusted_rand_score(iris['target'], labels_3) ari_3 # 0.7163421126838476 # 시각화 sns.scatterplot(x=X['petal length (cm)'], y=X['petal width (cm)'], hue=labels_3, palette='Set1')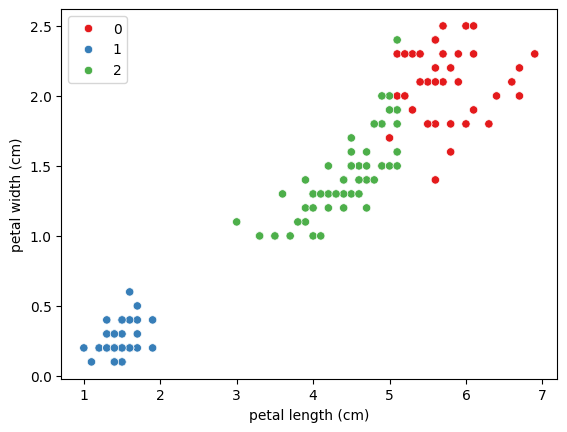
# 실제 데이터와 군집화 후 데이터 시각화 비교 # subplot(행,열,위치): 2개의 그래프를 따로 그려 합치는 것 plt.figure(figsize=(15,5)) # 실제 데이터 plt.subplot(1,2,1) plt.title('target') sns.scatterplot(x=X['petal length (cm)'], y=X['petal width (cm)'], hue=y, palette='Set1') # 군집화 데이터 plt.subplot(1,2,2) plt.title('clustering') sns.scatterplot(x=X['petal length (cm)'], y=X['petal width (cm)'], hue=labels_3, palette='Set1')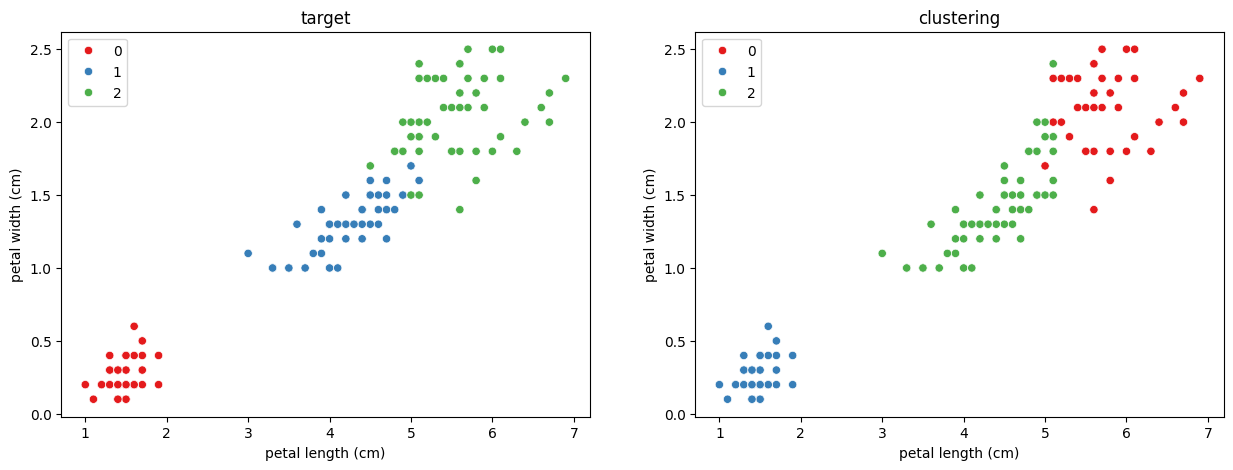
-
3. Hierarchical clustering
import scipy.cluster.hierarchy as sh
plt.figure(figsize=(12,8))
sh.dendrogram(sh.linkage(X,method='ward'))
plt.show()-
결과 예시
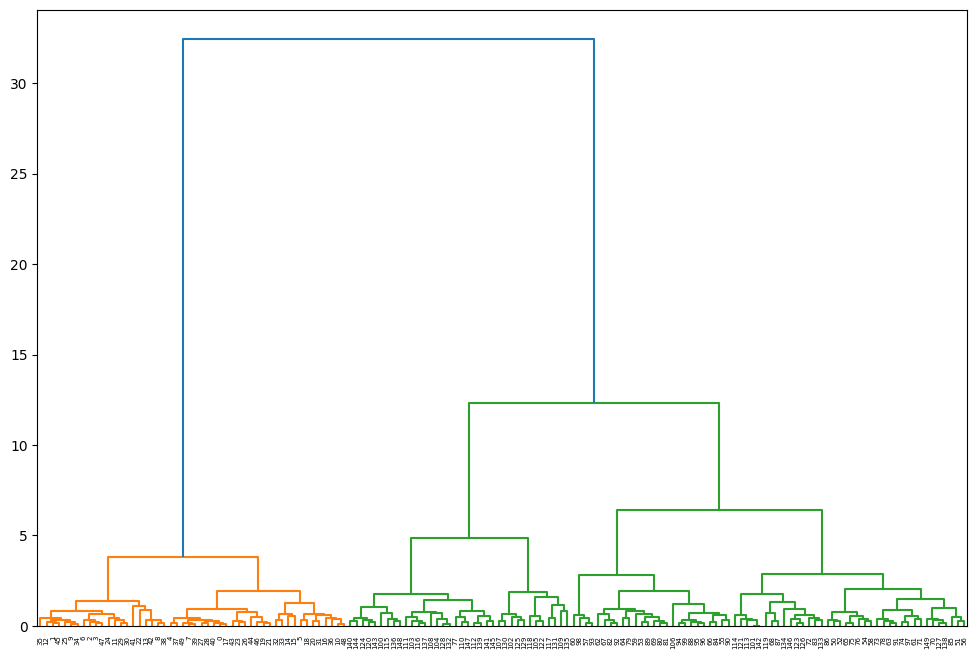
- 3~4로 나누면 되겠군!
4. DBSCAN
-
학습
from sklearn.cluster import DBSCAN dbscan = DBSCAN(eps=0.5, min_samples=4) dbscan.fit(X) -
결과 확인
X_copy = X.copy() X_copy['dbscan_cluster'] = dbscan.fit_predict(X) X_copy-
결과
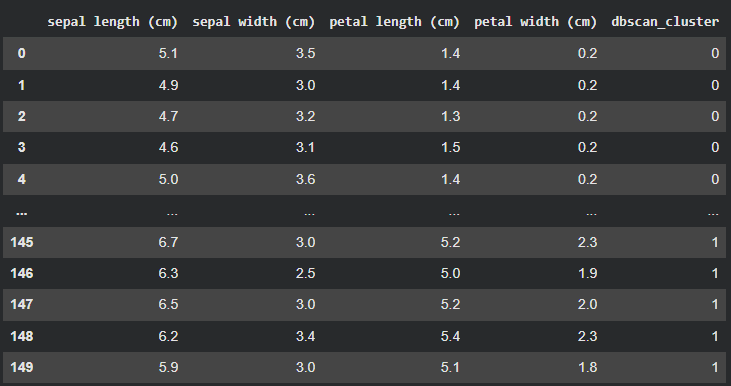
- 마지막 컬럼에
dbscan_cluster결과 있음
- 마지막 컬럼에
X_copy['dbscan_cluster'].value_counts() # -1: noise point # 따라서 3개의 군집으로 나눔!- 결과
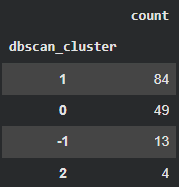
-
