선형 모델 중 분류 모델에 대한 페이지입니다.
- 개념
- 종류
- 원리
- 사용법
- 평가지표
개념
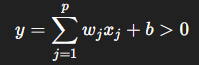
- 특성들의 가중치 합이 0보다 크면 class 를 +1(양성클래스)로, 0보다 작다면 클래스를 -1(음성클래스)로 분류
- 분류용 선형모델은 결정 경계가 입력의 선형함수
모델 종류
Logistic Regression
 Reference: https://cdn.analyticsvidhya.com/wp-content/uploads/2024/08/711091.webp
Reference: https://cdn.analyticsvidhya.com/wp-content/uploads/2024/08/711091.webp
- 선형 회귀 모델 기반인데, 시그모이드 함수를 활용한 모델!
- 0 ~ 1 사이 (1에 가까워지지만 1이 되지는 않음)
- 이름에 Regression 이 붙지만, 분류모델임! (사실 회귀하려고 만들었다가 분류가 더 잘돼서 분류에서 사용하게 되었다는 후문이 …)
Linear SVM(Support Vector Machine)
 Reference: https://cdn.analyticsvidhya.com/wp-content/uploads/2021/04/image-356-6756c92915662.webp
Reference: https://cdn.analyticsvidhya.com/wp-content/uploads/2021/04/image-356-6756c92915662.webp
- 가장 가까운 데이터를 기준으로 가장 멀리 떨어져 있을 수 있는 선을 긋는 것
- SV(support vector): 각 클래스 중 직선과 가장 가까운 데이터
- 용어 정리
- 초경계면(Hyperplane): Margin 이 최대가 되는 선/면
- Support Vector: 초경계면과 가장 가까운 벡터
- Margin: Support Vecter 사이 거리 → Margin 이 가장 큰 Hyperplane 을 찾는 것이다~
다중 분류 모델
- class 만큼 직선 그어서, 각 클래스 인지 아닌지 판별
원리
 Reference: https://media.geeksforgeeks.org/wp-content/uploads/20231008131358/file.png
Reference: https://media.geeksforgeeks.org/wp-content/uploads/20231008131358/file.png
 Reference: https://arize.com/wp-content/uploads/2022/11/log-loss-1.png
Reference: https://arize.com/wp-content/uploads/2022/11/log-loss-1.png
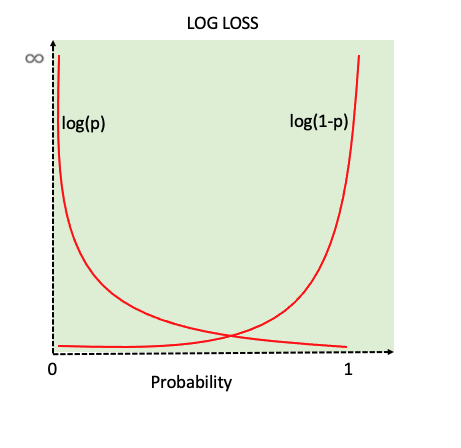
- 분류에서 오차 지표로 mse 를 사용하면 가장 큰 오차여봤자 1. 겨우 1.
- 분류에서 오차 지표는 ‘크로스 엔트로피’를 이용함
- 잘못 예측했을 때 오차 많~이 주려고!
- 위 그림에서 왼쪽 그래프가 크로스 엔트로피에 대한 그래프
- 실제값 = 1 → 왼쪽 그래프 활성화
- 예측값 = 0 → 오차 짱 많이 반환!
- 예측값 ~ 0 → 0에 가까워질수록 오차 점점 커짐
- 예측값 ~ 1 → 1에 가까워 질수록 오차 점점 작아짐
- 예측값 = 1 → 오차=0 (실제값이랑 예측값 동일하니까!)
- 실제값 = 0 → 오른쪽 그래프 활성화
- 실제값 =1 때와 동일한 조건
- 각 클래스마다 크로스 엔트로피 그래프 하나씩. “해당 클래스에 속하냐 안속하냐!!!”
- 실제값 = 1 → 왼쪽 그래프 활성화
- 위 그림에서 오른쪽 식이 크로스 엔트로피 값
- 이 값이 줄어드는 방향으로 학습한다아!!!!!
사용법
-
Logistic Regression
from sklearn.linear_model import LogisticRegression lg_model = LogisticRegression() lg_model.fit(X_train, y_train) -
Linear SVM
from sklearn.svm import LinearSVC svm_model = LinearSVC() svm_model.fit(X_train, y_train)
평가지표
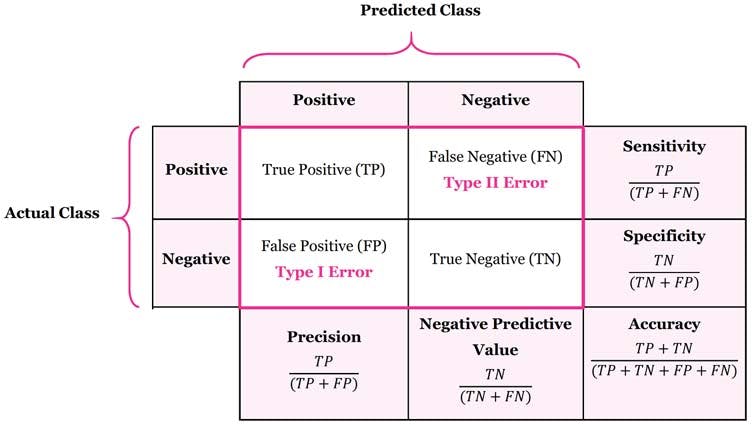
혼동행렬(confusion_matrix)
 Reference: https://images.prismic.io/encord/edfa849b-03fb-43d2-aba5-1f53a8884e6f_image5.png?auto=compress,format
Reference: https://images.prismic.io/encord/edfa849b-03fb-43d2-aba5-1f53a8884e6f_image5.png?auto=compress,format
(T/N) 맞췄냐 틀렸냐 / (P/N) 예측한 값
정확도(Accuracy)
- 식
(TP + TN) / (TP + FP + TN + FN)
- 전체 데이터에서 정답을 맞춘 비율
- 0 ~ 1 사이의 숫자를 가짐
- 불균형한 데이터가 들어있을 경우 정확도로 성능을 평가하는 것은 문제가 됨
재현율(Recall)
- 식
TP / (TP + FN)
- 실제 양성 중에 예측 양성 비율
- 실제 암 환자 중 얼마나 잘 맞췄는가!
정밀도(Precision)
- 식
TP / TP + FP
- 예측 양성 중 실제 양성 비율
- 암이라고 한 사람 중 실제 암 환자의 비율!
F1 score
- 식
2 ( 정밀도재현율 / (정밀도 + 재현율) )
- 정밀도와 재현율의 조화평균
- 둘의 결과가 조화로울수록 높은 수치를 나타냄
상황에 따른 재현율과 정밀도의 상대적인 중요도
- Recall(재현율)이 선호하는 경우
- 실제 positive 인 데이터를 예측을 negative 로 잘못 판단하게 되면 업무상 큰 영향을 줌
- 예) 암 진단, 금융사기 판별, 도둑 판별
- Precision(정밀도)를 선호하는 경우
- 실제 negative 인 데이터 예측을 positive 로 잘못 판단하게 되면 업무상 큰 영향을 줌
- 예) 스팸 메일(스팸메일 양성, 정상메일 음성) / 어린아이 제공 영상 (안전 영상 양성, 비안전 영상 음성)
사용 예시
# 실제값, 예측값이 필요
from sklearn.metrics import classification_report
print(classification_report(y_test, pred_svm)) # 실제값과 예측값의 순서 중요!!- 결과
precision recall f1-score support 0 0.88 0.97 0.92 370 1 0.68 0.32 0.44 71 accuracy 0.87 441 macro avg 0.78 0.65 0.68 441 weighted avg 0.85 0.87 0.85 441 - 해석
# 해석 방법 # precision # class 0 -> 모델이 0으로 예측한 것 중 0.88 가 실제 class 0 # class 1 -> 모델이 1 로 예측한 것 중 0.68 가 실제 class 1 # recall # class 0 -> 실제 class 0 중에서 97%를 맞췄다 # class 1 -> 실제 class 1 중에서 44%를 맞췄다 # f1-score # class 0 일때가 조화평균이 좋다, 균형있다. # Summary # SVM이 전체적으로는 정확히 맞추지만, 소수 클래스(1)를 잘 못 잡고 있다. # 즉, 불균형 데이터 문제에 의해 SVM이 0을 우선적으로 맞추고 1을 놓치는 상황.
