
백엔드를 구성하는 요소 중에서는 웹서버, 인프라 스트럭쳐 (Infra-structure)가 있다.
인프라 스트럭쳐 중에서도 데이터베이스가 있는데 데이터 베이스 중에서도 크게 RDBMS, NoSQL가 동작을 할 것이다.
백엔드에서는 데이터 베이스를 잘 다루기 위해서 인프라 스트럭쳐에 대한 이해도 필요하지만 결론적으로 데이터 베이스를 어떻게 설계하고 그러한 구조를 얼마나 견고하게 설계했는지가 중요한 점이라고 할 수 있다.
1일차에서는 RDGMS에서 MySQL, NoSQL에서는 MongoDB에 대해서 배워볼 예정이다.
01. 데이터 베이스 (DB)
1. 데이터 베이스 (Database, DB)란?
데이터 베이스는 간단하게 말하면 데이터의 저장소이다.
데이터 베이스가 왜 필요할까?
그 특징은 아래와 같다.
- 효율적인 데이터관리 (데이터를 통합하여 관리)
- 데이터 누락 및 중복 방지 (DBMS의 특징 ACID)
- 여러 사용자가 실시간으로 데이터 사용 가능
*ACID
: 데이터의 독립성, 데이터 무결성, 데이터 보안성, 데이터 일관성
DB라는 것이 있기 전에는 파일 형태로 데이터를 관리를 했다. 파일 형태로 관리를 하다보니 데이터를 업데이트하면 기존 버전의 데이터를 알 수 없다는 큰 단점이 있었다.
2. DB의 역사
DB의 역사를 간략히 설명하자면 아래와 같다.
DB의 역사
: 파일 시스템
→ 네트워크 DBMS → 계층 DBMS // (1세대)
→ 관계 DBMS // (2세대)
→ 객체 DBMS → 객체관계 DBMS // (3세대)
→ NoSQL DBMS → NewSQL DBMS // (4세대)
1963년 처음 등장하여 파일로 시작해서 4세대까지 발전을 해왔다. 관계 DBMS(RDBMS)가 주로 사용되며 그 종류가 많다. 요즘 빅데이터 시대, AI(GPT) 시대에 맞추어 벡터 DB의 사용이 퍼지는 추세이다.
3. 데이터 모델 종류
데이터를 어떻게 저장하고 관리할지 그 방법에 따라 데이터 모델이 크게 4가지로 분류된다.
-
계층형 데이터 모델
: 가장 밀접한 예시로는 윈도우 파일 시스템의 디렉터리 구조이다. 정보를 디렉터리 형태로 분류하기 때문에 복잡한 구조를 묘사할 수 없다는 단점이 있다.-
구조
: 데이터를 트리 구조로 표현하며, 각 레코드는 하나의 상위 레코드에 대한 하위 레코드를 가질 수 있다.
(부모 요소와 그 자식 요소, 또 그 자식 요소 ... 자식 요소는 하나의 부모 요소만 가질 수 있다.) -
특징
: 상위 레코드와 하위 레코드 간의 부모-자식 관계가 정의되어 있어 주로 조직도나 파일 시스템과 같은 계층적인 데이터에 유용하다.
-
-
네트워크형 데이터 모델
: 계층형 데이터베이스의 단점을 보완하기 위해 자료간 연결을 망형태로 (network link) 자유롭게 연결할 수 있도록 개선한 것이다. 자료구조 변경시에 디스크에 저장된 데이터의 물리적 구조를 재구성해야하는 번거로움이 있다.-
구조
: 계층형 데이터 모델과 유사하지만, 각 레코드는 여러 상위 레코드를 가질 수 있어 계층형 데이터 모델보다 부모-자식간의 관계가 복잡하다. -
특징
: 각 레코드 간의 관계를 명시적으로 정의하며, 네트워크 형태의 그래프로 표현되어 주로 복잡한 데이터 관계를 다루는데 사용된다.
-
-
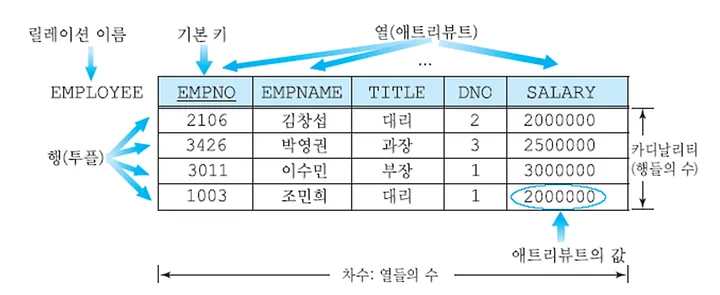
관계형 데이터 모델 (RDBMS) 🌟
: 앞으로 자주 다루게 될 데이터 모델로 테이블 형태 (like excel)이다. 복잡한 구조를 단순하게 표현이 가능하며 속도도 빨라 사용성이 뛰어나다.-
구조
: 데이터를 저장하며, 각 테이블은 레코드(행)과 필드(열)로 구성 된다. 테이블 간에 관계를 정의하여 데이터를 관리한다. -
특징
: 표 형태로 데이터를 저장하고 SQL(Structured Query Language)를 사용하여 데이터를 조작한다. 관계형 데이터 베이스 시스템(RDBMS)에서 지원된다.
-
-
객체 지향형 데이터 모델 (OODBMS)
: 데이터를 저장할 때 어떤 형식을 갖추는 것이 아닌 하나의 객체로서 저장하면 안될까라는 생각에서 나온 모델이다.-
구조
: 현실 세계의 개체(Entity)와 그들 간의 상호 작용을 모델링한다. 클래스와 객체의 개념을 기반으로 한다. -
특징
: 데이터와 해당 동작을 캡슐화하며, 객체 간의 관계를 강조한다. 소프트웨어 개발에서 객체 지향 프로그래밍 언어에서 주로 사용된다.
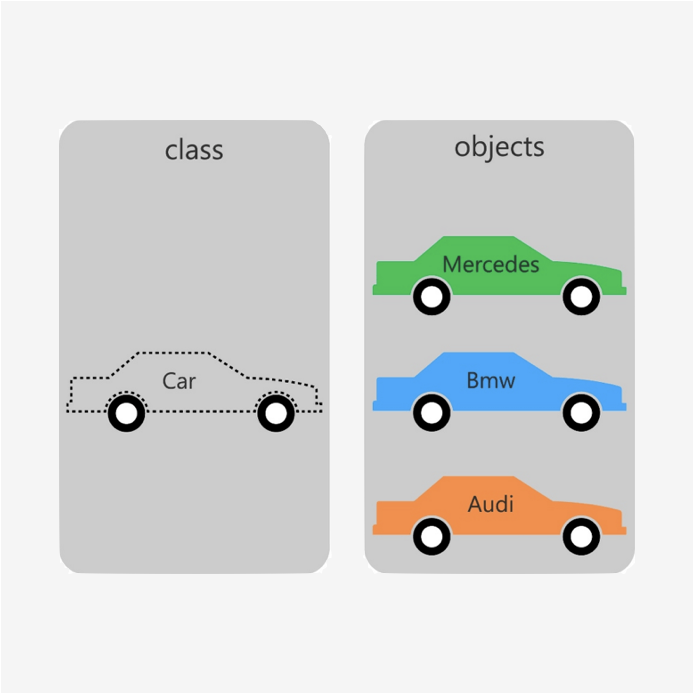
ex) 영희라는 사람은 이름, 주소, 계좌 등 다양한 정보를 가지고 있다 이 정보들은 서로 연결되어 있어 객체 지향 데이터 베이스로 표현하면 한 객체가 여러 관련 객체와 관계를 맺을 수 있음을 보여준다.
관계형 데이터 모델은 표로 정리되어 셀마당 관계가 있다면 이건 각 데이터가 하나의 객체를 이루어 객체끼리 관계를 맺는 다는 것에서 차이점이 있다. (그래도 잘 이해가 안된다면 사진 참고!) -
02. DBMS
1. DBMS (Database Management System) 란?
DBMS는 데이터베이스 관리시스템으로 데이터의 저장, 검색, 업데이트, 관리를 위한 소프트웨어이다. DBMS는 대용량 데이터의 효율적인 처리와 접근을 가능하게 하며, 데이터의 무결성, 보안, 백업 및 복구 기능을 제공한다.
- 주요 DBMS
- Oracle Database
- MySQL 🌟
- Microsoft SQL Server
- PostgreSQL
- MongoDB
- Redis (Remote Dictionary Server)
- Elasticsearch
- SQLite
- Snowflake
- Cassandra
- MariaDB
- Apache Hive
- Google BigQuery
각 DBMS는 특징이 있고 장단점이 있기 때문에 간략하게 각 DBMS를 소개한다.
2. Oracle Database
-
용도
: 대형 기업이나 복잡한 애플리케이션에 적합하며 고성능, 대규모의 트랜잭션 처리와 데이터 웨어하우징에 자주 사용된다. -
특징
1. 강력한 트랜잭션 관리, 높은 데이터 무결성 및 보안 기능을 제공한다.- 확장성이 뛰어나며, 다양한 운영 체제에서 실행된다.
- PL/SQL이라는 Oracle 전용 프로그래밍 언어를 사용한다.
- 비싼 라이센스 비용이 있지만, 대규모 엔터프라이즈 환경에서의 신뢰성과 성능은 매우 높다.
3. MySQL
-
용도
: 주로 웹 어플리케이션 및 소규모에서 중간 규모의 프로젝트에서 사용된다. -
특징
1. 오픈소스이며, 사용이 쉬워 소규모 어플리케이션에 인기가 많다.- PHP와의 통합이 용이하여 웹 개발에서 자주 사용된다. (LEMP Stack)
- 비교적 가벼우면서도 성능이 좋으며, 다양한 운영 체제를 지원한다.
- 대규모 데이터베이스와 고급 기능이 필요한 환경에서는 다소 제한적일 수 있다.
- 오픈소스이다보니 보안이나 어떤 관리적인 측면에서는 약할 수 있다.
4. Microsoft SQL Server
-
용도
: 주로 중대형 기업에서 사용되며, .NET와 같은 Microsoft 기술과 잘 통합된다. -
특징
1. Window 기반 시스템에 최적화되어 있어 Microsoft 환경에서 뛰어난 성능을 발휘한다.- 사용자 친화적인 관리 도구와 강력한 보안 기능을 제공한다.
- 데이터 웨어하우징, 비즈니스 인텔리전스(BI), 데이터 분석에 유용한 기능을 포함하고 있다.
5. PostgreSQL
-
용도
: 복잡한 쿼리와 대규모 데이터 베이스 관리가 필요한 경우 적합하다. -
특징
1. 객체-관계형 DBMS로 확장 가능한 고급 기능을 제공한다.- 오픈 소스이며, SQL 표준을 잘 준수한다.
- 복잡한 데이터 타입과 사용자 정의 함수를 지원한다.
- 거대한 데이터 세트와 복잡한 쿼리에 적합하며 높은 확장성과 성능을 자랑한다.
6. MongoDB
-
용도
: 실시간 분석, 대규모 데이터 처리가 필요한 어플리케이션에 적합하다. -
특징
1. NoSQL 데이터 베이스 중 하나로 문서 지향적 구조를 갖고 있다.-
Schema가 없어 데이터 구조가 유연하고 개발과 확장이 쉽다.
-
JSON 형식의 문서를 사용하여 데이터를 저장하며 데이터 샤딩을 지원한다.
-
대용량 데이터 처리와 실시간 분석에 최적화 되어있다.
*데이터 샤딩 : 데이터베이스 샤딩은 대규모 데이터베이스를 여러 머신에 저장하는 프로세스입니다. 단일 머신 또는 데이터베이스 서버는 제한된 양의 데이터만 저장하고 처리할 수 있습니다. 데이터베이스 샤딩은 데이터를 샤드라고 하는 더 작은 청크로 분할하고 여러 데이터베이스 서버에 저장함으로써 이러한 한계를 극복합니다. 모든 데이터베이스 서버의 기본 기술은 일반적으로 동일하며 함께 작동하여 대량의 데이터를 저장하고 처리합니다.
-
NoSQL에 대해 배울때 다뤄볼 예정이다.
7. Redis (Remote Dictionary Server)
-
용도
: 고성능 키-값 저장소로, 주로 캐싱, 세션 관리, 게임 리더보드, 실시간 애플리케이션 등에서 사용된다.
ex) 실시간 랭킹, 실시간 배달 라이더 위치 등 -
특징
- 인메모리 데이터 스토어로, 매우 빠른 읽기와 쓰기 속도를 제공한다.
- 간단한 키-값 구조부터 리스트, 세트, 해시, 정렬된 세트 등 다양한 데이터 타입을 지원한다.
- 데이터 지속성을 위해 디스크에 스냅샷을 저장하거나 변경 사항을 기록한다.
- 마스터-슬레이브 복제, 자동 파티셔닝 기능을 지원하여 확장성이 뛰어나다.
NoSQL 종류 중 하나이다.
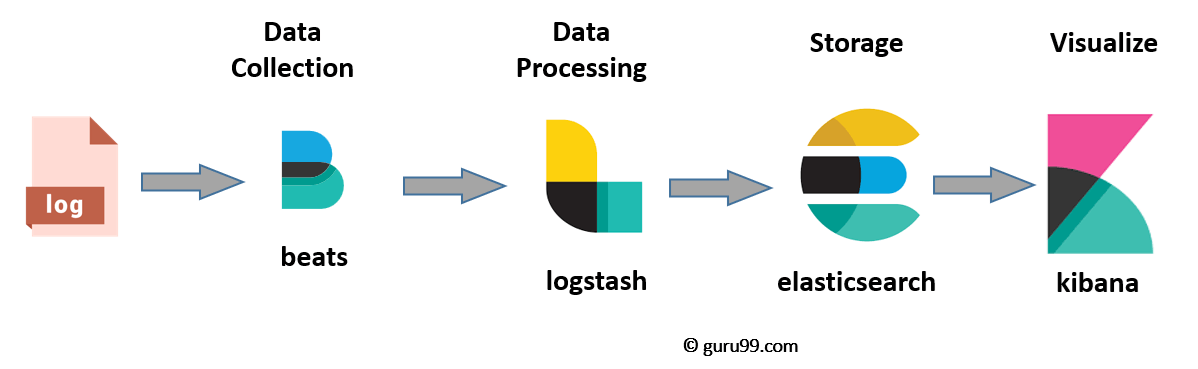
8. Elasticsearch
-
용도
: 분산 검색 엔진으로, 복잡한 검색, 데이터 분석, 로그 및 데이터 집계에 사용된다. -
특징
-
RESTful API를 통해 데이터 인덱싱, 검색, 분석 기능을 제공한다.
-
JSON 형식의 문서를 인덱싱하며, 풀 텍스트 검색 기능이 강력하다.
-
높은 확장성과 실시간 분석 능력을 갖고 있습니다.
-
ELK(Elasticsearch, Logstash, Kibana) 스택으로 널리 사용되며, 대용량 데이터에 적합하다.
-
-
Grafada Dash-board를 함께 사용해서 서버 현황을 확인할 수 있다. (백엔드에서는 트래픽 컨트롤 중요하기 때문)
9. SQLite
-
용도
: 경량, 자체 포함, 서버리스, 제로-구성 데이터베이스로, 임베디드 시스템 및 모바일 애플리케이션에 주로 사용된다. -
특징
-
파일 기반의 데이터베이스로, 별도의 서버 설정이 필요 없다.
-
작고 가볍지만, SQL 표준을 상당 부분 지원한다.
-
ACID(Atomicity, Consistency, Isolation, Durability) 트랜잭션을 지원한다.
-
설치가 필요 없으며, 매우 적은 리소스를 사용한다.

-
10. Snowflake
-
용도
: 클라우드 기반의 데이터 웨어하우스로, 대규모의 데이터 저장, 분석 및 공유에 사용된다. (유료, 저장에 특화) -
특징
- 클라우드에서 완전 관리되는 서비스로, 유연한 확장성을 제공한다.
- 데이터 웨어하우징 및 빅데이터 분석에 최적화되어 있다.
- 별도의 하드웨어나 소프트웨어 설치 없이 사용할 수 있다.
- 고유한 아키텍처를 사용하여, 저장, 컴퓨팅, 서비스 계층을 분리한다.
11. Cassandra
-
용도
: 대규모 분산 데이터베이스로, 큰 규모의 데이터를 관리하고, 높은 가용성과 확장성이 필요한 환경에서 사용된다.
(분산 → 빅데이터 이용 으로 이해하면 편하다.) -
특징
- NoSQL 데이터베이스로, 분산 환경에서 뛰어난 확장성과 성능을 제공한다.
- 데이터는 여러 노드에 걸쳐 분산 저장되며, 하나의 노드가 실패해도 데이터 손실 없이 운영된다.
- 컬럼 기반의 데이터 스토리지 모델을 사용하며, 행의 각 열은 독립적으로 저장된다.
- 높은 쓰기 및 읽기 처리량을 지원하며, 데이터 복제를 통해 고가용성을 보장한다.
- 특히, 대규모 온라인 서비스, IoT, 시계열 데이터 등의 처리에 적합하다.
12. MariaDB
-
용도
: MySQL의 포크로, 웹 기반 애플리케이션, 데이터 웨어하우징, 개인 및 소규모 기업용 데이터베이스로 사용된다. -
특징
- 오픈 소스 관계형 데이터베이스 관리 시스템(RDBMS)이다.
- MySQL과의 높은 호환성을 유지하면서도, 여러 가지 새로운 기능과 최적화가 추가되었다.
- 스토리지 엔진의 다양성을 지원하며, 성능과 보안 면에서 개선되었다.
- 강력한 쿼리 최적화, 복제 및 샤딩 기능을 제공한다.
- 커뮤니티 중심의 개발 모델을 따르며, MySQL 대비 개방적이고 확장성 있는 대안으로 자리잡고 있다.
13. Apache Hive
-
용도
: Hive는 Hadoop 위에 구축된 데이터 웨어하우스 시스템으로, 대규모 데이터 세트의 저장, 쿼리 및 분석에 사용된다. -
특징
- Hadoop의 저장 시스템인 HDFS(Hadoop Distributed File System) 위에서 작동한다.
- SQL과 유사한 HiveQL 쿼리 언어를 제공하여, SQL 사용자가 Hadoop 데이터를 쉽게 쿼리할 수 있게 해준다.
- Hive는 대량의 데이터를 처리할 수 있으나, 실시간 쿼리 처리에는 최적화되어 있지 않다.
- 배치 처리와 데이터 분석, 보고서 생성에 적합하다.
- 데이터는 빅 데이터 환경에서의 병렬 처리를 위해 여러 노드에 분산 저장된다.
- Hadoop 생태계의 일부로서 복잡한 배치 처리 작업에 적합하며, 자체 인프라 관리가 필요하다.
*하둡이란? 관계형 테이블 내에서 모델링하고 저장할 수 있는 기존 데이터와는 달리 웹 페이지, 소셜 미디어 사이트, 검색 인덱스, 클릭 스트림, 비디오 및 사진을 포함한 모든 유형의 멀티미디어 데이터들의 저장과 분석이 가능한 소프트웨어 프레임 워크.
14. Google BigQuery
-
용도
: BigQuery는 Google Cloud Platform의 완전 관리형 엔터프라이즈 데이터 웨어하우스로, 대용량 데이터 분석 및 SQL 쿼리 실행에 사용된다. -
특징
- 서버리스이며, 사용자는 인프라 관리에 대해 걱정할 필요가 없다.
- 빠른 속도로 대규모 데이터 세트에 대한 SQL 쿼리를 실행할 수 있다.
- 데이터 샤딩 및 복제를 자동으로 관리하며, 고가용성을 제공한다.
- 대용량 데이터 세트에 대한 실시간 분석 및 인터랙티브한 데이터 탐색이 가능하다.
- BigQuery ML을 통해 SQL 쿼리 내에서 머신러닝 모델을 생성하고 실행할 수 있다.
- BigQuery는 완전 관리형 서비스로서 복잡한 인프라 관리 없이 즉각적인 분석을 가능하게 한다.
03. RDBMS
1. RDBMS (Relational DBMS)
RDBMS (관계형 데이터베이스 관리 시스템)은 표 형태로 데이터를 구조화하고 관리하는 데이터 베이스이다.
2차원 테이블 (행, 열)을 사용하여 데이터를 정의하고 표현하는 데이터 모델이다. 여기서 데이터는 속성(Attribute)와 해당 속성에 대응하는 데이터 값(Attribute Value)로 이루어져 있다. 데이터를 정리하고 설명하기 위해 속성과 데이터 값 간의 관계를 찾아내어 이를 테이블 형태로 나타낸다.
이 테이블은 열(Column)과 행(Row)로 이루어져 있고
각 열은 데이터의 속성,
각 행은 해당 속성에 대응하는 데이터 값을 포함하고 있다.
2. RDBMS 기본 구조
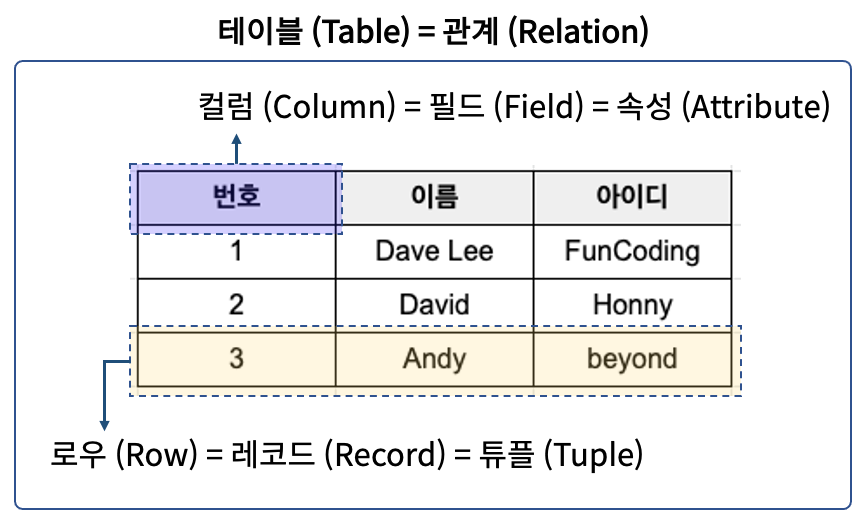
데이터 베이스 안에 여러가지 테이블을 만들 수 있는데 그 테이블 안에서도 행(Colunm)과 열(Row) 데이터로 구분할 수 있다. (Database > Table > Column, Row)
-
컬럼 (Column) = 속성 (Attribute) = 필드 (Field)
-
로우 (Row) = 튜플 (Tuple) = 레코드 (Record)
-
관련 용어들
- Schema (스키마)
: 테이블, 행, 열, 인덱스, 관계 등의 데이터베이스 구조를 말한다. - SQL (Structured Query Language)
: 데이터 베이스에서 데이터를 관리하기 위해 사용되는 표준 프로그래밍 언어다.
SQL을 사용하여 데이터 베이스에 질의, 업데이트, 삭제 등의 작업을 수행할 수 있다. - Index (인덱스)
: 데이터 베이스에서 데이터 검색 속도를 빠르게 하기 위해 사용되는 객체다.
인덱스는 특정 열에 대한 포인터를 포함하여 데이터 검색 시간을 단축시킨다. - DBMS (데이터 베이스 관리 시스템)
: 데이터 베이스를 생성하고 관리하는 소프트웨어다.
ex) Oracle, MySQL, Microsoft SQL Server, PostgreSQL 등 - Transaction (트랜잭션)
: 데이터 베이스의 상태를 변화시키는 하나의 작업 단위다.
트랜잭션은 데이터 무결성을 유지하는데 중요한 역할을 한다.
- Schema (스키마)
3. RDBMS 단점
-
성능
: 대용량 데이터 처리나 복잡한 쿼리에 대한 성능이 다른 모델에 비해 낮을 수 있다. -
확장 어려움
: 수직적 확장이 한계가 있고, 수평적 확장은 복잡하고 비용이 많이 들 수 있다. -
유연성 부족
: 스키마 변경이 어려워서 요구사항 변경에 대응하기 어려울 수 있다. → 그래서 탄생한게 NoSQL -
복잡한 조인
: 많은 테이블 간의 조인은 성능에 부정적인 영향을 미칠 수 있다. -
고비용
: 서버 하드웨어 및 라이선스 비용이 상대적으로 높을 수 있다.
RDBMS는 데이터의 구조화와 안정성 측면에서 강력하며, 일반적인 업무 응용에 적합합니다. 그러나 성능이나 유연성 등의 측면에서 고려해야 할 부분도 있다.
4. RDBMS 구성 요소
데이터 베이스의 구성 요소를 학교로 예시를 들어 설명해보려 한다.
<예시>
-
데이터 베이스 : 학교
-
테이블 = 모델
: 학생, 교실, 선생님(급여), 행사, 급식, 동아리, 방과후활동, 과목, 시험, 비품 -
행 : 하나의 데이터
-
열 : 컬럼
- (테이블) 학생 - (컬럼) 나이, 성별, 주소, 성적
- 교실 - 학생수, 평균성적
- 선생님 - 나이, 성별, 주소, 급여
-
키 : ID (User_ID 식으로 지정.)
- PK (Primary Key) id or pk
: 테이블 내에서 중복이 절대 불가능 (고유값으로 사용이 가능)- 행(=하나의 데이터)을 식별할 수 있는 유일한 값
- 유니크한 값이면 가능하다.
- 주민등록번호
- 국가 코드 (+82, +1, +86 …)
- 학번 (2010+119+09)
- 군번
- FK (Foreign Key)
: 다른 테이블의 기본키로 지정된 키
- PK (Primary Key) id or pk
정리하자면
-
데이터 베이스 (Database)
: 구조화된 데이터의 집합이다. 데이터베이스는 데이터를 저장, 검색, 수정, 삭제할 수 있게 해주는 시스템이다. -
테이블 (Table)
: 데이터 베이스 내에서 데이터가 저장되는 장소이다. 테이블은 행과 열의 격자 형태로 구성된다. -
행 (Row) / 레코드 (Record)
: 테이블 내의 개별 데이터 항목을 나타낸다. 각 행은 하나의 데이터 항목 또는 개체를 나타낸다. -
열 (Column) / 필드 (Field)
: 테이블 내의 특정 카테고리 또는 데이터 유형을 나타낸다. -
기본 키 (Primary Key, PK)
: 테이블 내의 각 행을 고유하게 식별하는 열이다. 기본 키 값은 유일해야하며, 각 행마다 다른 값을 가져야 한다. -
외래 키 (Foreign Key, FK)
: 다른 테이블의 기본 키를 참조하는 열이다. 외래 키는 두 테이블간의 관계를 설정하는데 사용된다.
5. 대표적인 RDBMS
RDBMS로 여러가지 툴들이 있는데 대표적인 5가지를 소개하려한다.
-
MySQL
: 개방 소스 RDBMS로서 가장 인기 있는 데이터 베이스 중 하나다. 다양한 환경에서 사용되며 웹 어플리케이션부터 대규모 엔터프라이즈 시스템에 이르기까지 다양한 용도로 활용된다. -
PostgreSQL
: 객체 관계형 데이터 베이스 시스템으로 확장 가능하고 풍부한 기능을 제공한다. ACID 호환성 및 다양한 데이터 유형을 지원하여 고급 데이터 베이스 요구에 적합하다. -
Microsoft SQL Server
: Microsoft에서 제공하는 RDBMS로 Windows 기반 환경에서 주로 사용된다. 엔터프라이즈 급 데이터 베이스 솔루션으로 개발 및 관리에 용이하다. -
Oracle Database
: 오라클이 개발한 대규모 엔터프라이즈용 RDBMS이다. 뛰어난 성능과 안정성, 확장성을 제공하여 대부분의 산업 분야에서 사용된다. -
SQLite
: 경량이면서 서버 없이 로컬에서 사용할 수 있는 RDBMS이다. IoT 개발에 많이 사용되며 임베디드 시스템이나 모바일 어플리케이션에서 많이 활용된다.
정리하자면 이 중 MySQL과 PostgreSQL는 오픈 소스로 무료로 사용할 수 있어 커뮤니티에서도 널리 사용되고 있다. Microsoft SQL Server와 Oracle Database는 주로 기업 환경에서 사용되며, 각각의 특정 용도나 환경에 따라 선택될 수 있다.
SQLite는 경량 환경이나 모바일 애플리케이션에서 간단한 데이터베이스 요구에 활용된다.
각 RDBMS를 설치해서 쿼리도 날려보고 아키텍처는 어떻게 되어있는지 공부하면 RDBMS를 다방면으로 이해하는데 유용할 것이다. 이 중 MySQL을 우선으로 사용해볼 예정이다.
04. 데이터베이스 스키마 (Schema)
1. Schema (스키마)
데이터 베이스 스키마 (Schema)는 데이터 베이스에서 데이터의 구조와 구성을 정의하는 청사진 또는 설계도이다.
이는 데이터 베이스 테이블, 필드, 관계 등을 어떻게 구성할지 명세한 것으로 데이터 베이스 시스템이 데이터를 저장, 관리, 조작하는 방식을 결정한다.
일반적으로, 관계형 데이터 베이스에서는 여러 테이블로 구성되며, 각 테이블의 속성을 식별하여 컬럼으로 정의한다.
2. 논리적 스키마, 물리적 스키마
-
논리적 스키마
: 테이블 간의 관계, 각 테이블의 속성과 데이터 타입, 제약 조건 등 -
물리적 스키마
: 데이터의 실제 저장과 관련 있는 부분, 디스크에 저장하는 방식 등
스키마가 있다면 동일한 구조의 데이터 베이스를 쉽게 만들 수 있다. 데이터 베이스의 백업과 달리 스키마는 데이터의 구조만을 정의하므로, 데이터 구조를 동일하게 만드는데 사용된다.
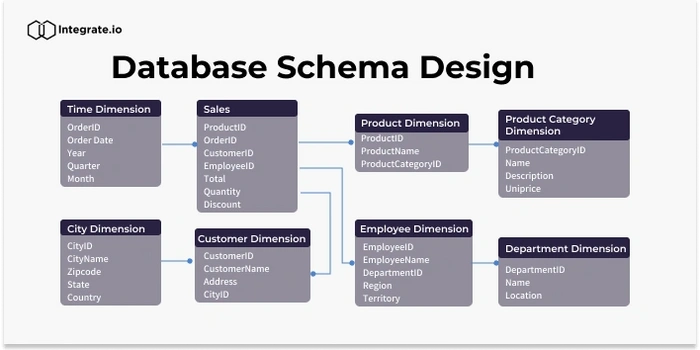
각 테이블은 FK로 연결이 되어있다.
05. SQL (Structured Query Language)
SQL (Structured Query Language)은 관계형 데이터 베이스에서 데이터를 정의, 처리, 제어하는데 사용되는 표준화된 언어이다.
SQL은 주로 데이터 베이스 관리 시스템(DBMS)와 상호작용을 위해 만들어졌다.
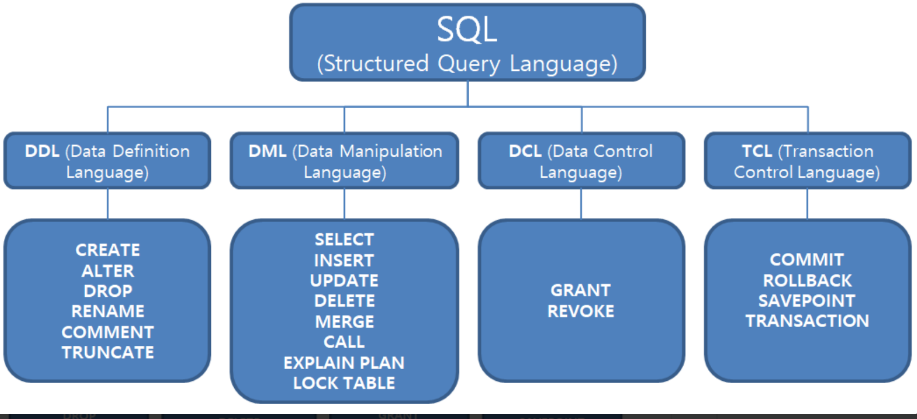
SQL은 그림과 같이 크게 4가지로 나뉘어져 있다.
-
DDL (Data Definition Language)
: 데이터베이스의 구조를 정의하는데 사용되는 언어 -
DML (Data Manipulation Language)
: 데이터베이스 내의 데이터를 처리하는 데 사용되는 언어 -
DCL (Data Control Language)
: 데이터베이스 사용자의 권한을 관리하고 데이터 접근을 제어하는데 사용되는 언어 -
TCL (Transaction Control Language)
: 데이터베이스 내의 트랜잭션을 관리하는데 사용되는 언어
각 언어에 대해서는 아래 "07. SQL의 주요 언어 유형"에서 확인할 수 있다.
06. MySQL + MySQL WorkBench
1. 프로그램 설치
-
MySQL은 MySQL 공식 웹사이트로 이동하여 "MySQL Community Server"을 다운 받으면 된다. (윈도우와 맥 방법 상이.)
-
MySQL Workbench(GUI 프로그램)은 MySQL 데이터베이스를 시각적으로 관리하기 위해 설치해 준다. MySQL Workbench 다운로드 페이지에서 다운로드 후 설치하면 된다.
(이거 설치하다가 오류가 계속 떠서 2시간 걸렸다...)
2. 데이터 베이스 생성
-
데이터베이스 생성
-- mydatabase라는 이름의 데이터베이스 생성 CREATE DATABASE mydatabase; -
데이터베이스 목록 조회
-- 모든 데이터베이스 목록 조회 SHOW DATABASES; -
데이터베이스 사용
-- mydatabase 데이터베이스 사용 USE mydatabase; -
데이터베이스 삭제 (IF EXISTS 옵션 사용)
-- mydatabase 데이터베이스 삭제 (만약 존재하면) DROP DATABASE IF EXISTS mydatabase;
07. SQL의 주요 언어 유형
1. DDL (Data Definition Language)
DDL (Data Definition Language)은 데이터 정의 언어로 데이터 베이스의 구조를 정의하고 관리하는데 사용된다.
주요 명령어는 다음과 같다.
-
CREATE
: 데이터 베이스 객체를 생성. (CREATE TABLE, CREATE INDEX 등) -
ALTER
: 데이터 베이스 객체를 수정. (ALGER TABLE 등) -
DROP
: 데이터 베이스 객체를 삭제. (DROP TABLE 등) -
TRUNCATE
: 테이블의 모든 레코드를 삭제하지만 테이블은 유지.
2. DML (Data Maipulation Language)
DML (Data Maipulation Language)은 데이터 처리 언어로 데이터를 검색, 삽입, 수정 삭제하는데 사용된다.
주요 명령어는 다음과 같다.
-
SELECT
: 데이터 베이스에서 정보를 검색. -
INSERT
: 새로운 데이터를 테이블에 삽입. -
UPDATE
: 테이블의 기존 데이터를 수정. -
DELETE
: 테이블에서 데이터를 삭제. -
이 외에도 MERGE, CALL, EXPLAIN PLAN, LOCK TABLE ...
우리가 쿼리라고 했을 때 핵심이 되는 부분이다.
3. DCL (Data Control Language)
DCL (Data Control Language)은 데이터 제어 언어로 데이터 베이스에 대한 엑세스를 제어하는데 사용된다.
주요 명령어는 다음과 같다.
-
GRANT
: 사용자에게 특정 작업을 수행할 권한을 부여. -
REVOKE
: 사용자로부터 특정 작업 수행 권한을 제거.
4. TCL (Transaction Control Language)
TCL (Transaction Control Language)은 데이터베이스 내의 트랜잭션을 관리하는데 사용된다.
주요 명령어는 다음과 같다.
-
COMMIT
: 트랜잭션을 완료하고, 데이터베이스 변경사항을 영구적으로 저장. -
ROLLBACK
: 트랜잭션을 취소하고, 마지막COMMIT이후의 모든 변경사항을 되돌림. -
SAVEPOINT
: 트랜잭션 내 특정 지점을 마킹하여 필요시 그 지점으로 되돌릴 수 있음.
각각의 언어 유형은 데이터베이스의 다양한 측면을 다루며, 데이터베이스의 구조를 정의하고(DDL), 데이터를 처리하며(DML), 사용자 권한을 관리하고(DCL), 트랜잭션을 제어하는(TCL) 역할을 합니다. 이러한 분류를 통해 데이터베이스 시스템의 효과적인 관리와 운영이 가능해집니다.
08. MySQL User 데이터
1. 시작하기
- 관리자 권한: 유저와 관련된 작업을 수행하기 위해서는 MySQL에서 관리자(보통 root) 권한이 필요하다.
-
명령 프롬프트 (MAC 경우 터미널)에서
mysql -u root -p을 입력하여 로그인을 한다. -
해당 명령어를 입력하면 'Enter Password:'가 뜨는데 이전에 설정했던 비밀번호를 입력하면 된다.
2. 유저 확인하기
프롬프터에서 mysql 유저 확인하기 위해 아래 명령어를 순차적으로 입력한다.
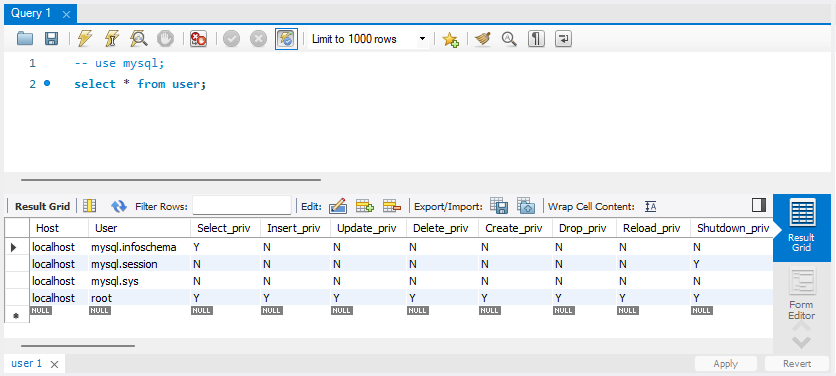
mysql> USE mysql;
mysql> select * from user;입력하고 보면 굉장히 깨져 보이는데 더 알아보기 쉽게 하기 위해서 MySQL WorkBench에서 동일하게 명령어를 실행해본다.
MySQL WorkBench에서는 하나의 명령어 작성하고 ctrl + enter (또는 번개모양 버튼)을 해주고 작성한 명령어 앞에 --를 적어 주석 처리 후 다음 명령어 작성한 다음 다시 실행하는 식으로 실행시킨다.
실행하면 아래와 같은 화면을 얻을 수 있다.
3. 유저 생성하기
아래 코드를 작성하고 ⚡
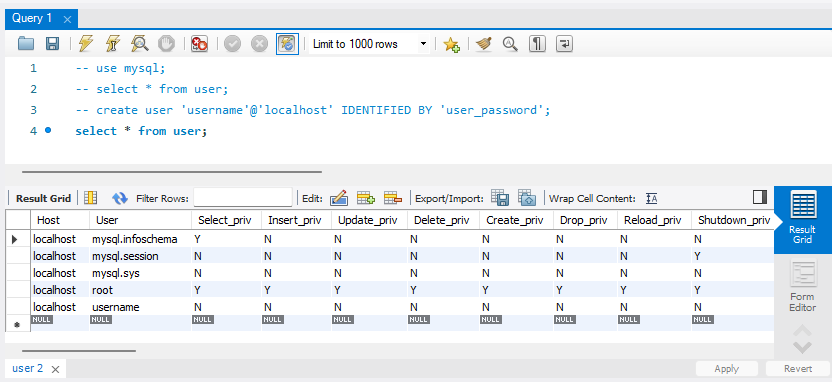
CREATE USER 'username'@'%' IDENTIFIED BY 'user_password';
-- % 부분에는 원하는 user 이름 작성.
-- user_password에는 원하는 비밀번호 작성.다시 아래 코드를 입력해 확인 ⚡하면
select * from user;아래 그림과 같이 username이라는 행이 추가된 것을 확인할 수 있다.
만약 해당 유저의 비밀번호를 바꾸고 싶다면
SET PASSWORD FOR 'username'@'%' = '신규비밀번호';
-- %에는 user 이름을 적어준다.를 입력하면 바꿀 수 있다.
4. 권한 부여하기.
권한 부여 중에 모든 데이터 베이스의 권한을 부여하고 부여한 권한을 확인해 볼 수 있다.
아래 코드를 입력한 뒤 실행 ⚡
GRANT ALL PRIVILEGES ON *.* TO 'username'@'%'; -- 유저에게 모든 권한 적용
FLUSH PRIVILEGES; -- 변경된 권한 적용
SHOW GRANTS FOR 'username'@'%'; -- 부여된 권한 확인
SHOW GRANTS; -- 현재 로그인한 유저(root)의 권한 확인기본적으로 localhost란 유저를 만들 때 모든 권한을 부여했기 때문에 세번째와 네번째 코드만 작성해서 확인해보는 것을 추천한다★
5. 유저 삭제하기.
방금 생성했던 유저를 삭제하기 위해서는 아래 코드를 작성하고 실행 ⚡
DROP USER 'username'@'%';
-- %에는 만든 user 이름을 넣어주면 된다.만든 유저가 사라진 것을 아래 코드를 작성해서 실행하면 ⚡ 그림과 같이 나올 것이다.
select * from user;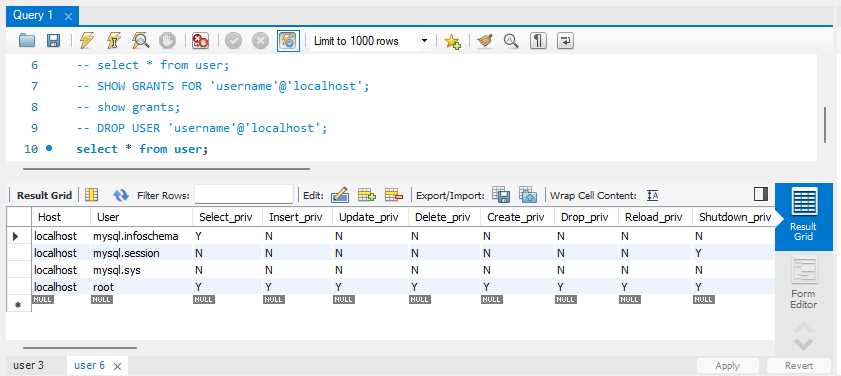
09. MySQL 데이터 베이스 Schema 구성 (DDL)
Schema를 구성한다는 것은 우리가 데이터 베이스를 만들때 테이블 구조를 만드는 것을 의미한다.
1. CREATE TABLE
우선 실습용으로 작업할 데이터 베이스를 만들어 준다.
create database testdatabase; -- 데이터 베이스 만들기
use testdatabase; -- 해당 데이터 베이스 사용- 아래 코드로 'users'라는 이름의 테이블을 만든다.
그리고 ID를 PRIMARY KEY라는 고유한 값으로 만든다.
- PRIMARY KEY
: 테이블의 주요 식별자(primary key)를 정의합니다. 주로 유일성을 보장하고 검색 속도를 향상시키기 위해 사용된다.
- ID라는 값을 1씩 증가하게 만들어주는 것이 좋아 아래 옵션을 사용한다.
- AUTO_INCREMENT
: 숫자 자동 증가 속성을 가진 칼럼에 사용됩니다.
이 옵션을 사용하면 해당 칼럼의 값이 자동으로 1씩 증가한다.
- ID에 빈값이 저장되지 않도록 제약을 걸어야하는데 그 코드는 아래 옵션을 사용한다.
- NOT NULL
: NOT NULL 제약은 해당 칼럼에 NULL 값을 허용하지 않도록 한다. 즉, 해당 칼럼에는 항상 값이 존재해야한다.
- 이메일 데이터 추가
유니크한 개별적 아이디를 생성하기 위함으로 아래 옵션을 사용한다.
예를 들면 메이플 스토리나 인스타 아이디 생성시 이미 누군가 사용하고 있다. 확인창이 뜨는 것과 같은 원리이다.
- UNIQUE
: 이 제약은 해당 칼럼에 중복된 값을 허용하지 않는다.
- 비즈니스 계정 데이터 추가
원래는 일반 계정이지만(False) 특별한 승인이 있는 경우 다른 케이스로 바뀌는 것(True)을 구현할 수 있다.
- DEFAULT
: 새로운 레코드가 삽입될 때 해당 칼럼에 지정된 기본값을 사용한다.
- 나이 데이터 추가
만 14세 이상인지 미만인지 확인하는 것과 같은 제약을 거는 것이다.
- CHECK
: 이 제약은 해당 칼럼에 저장될 수 있는 값의 범위나 조건을 지정한다.
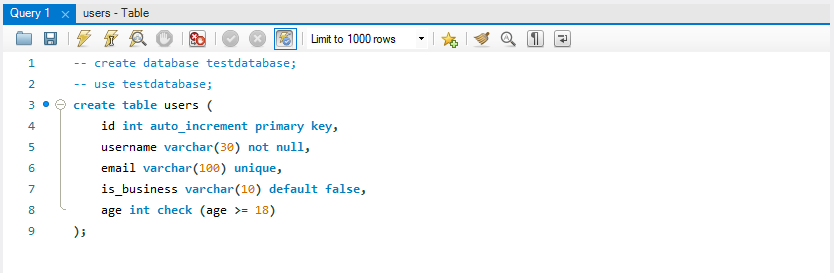
위 옵션들을 모두 포함하여 테이블을 만들면 아래 코드, 사진과 같다.
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
is_business VARCHAR(10) DEFAULT False,
age INT CHECK (age >= 18)
);
2. 실습
위에서 연습한 내용을 바탕으로 2개의 테이블을 더 만들어 보자.
-
첫번째 테이블 만들기
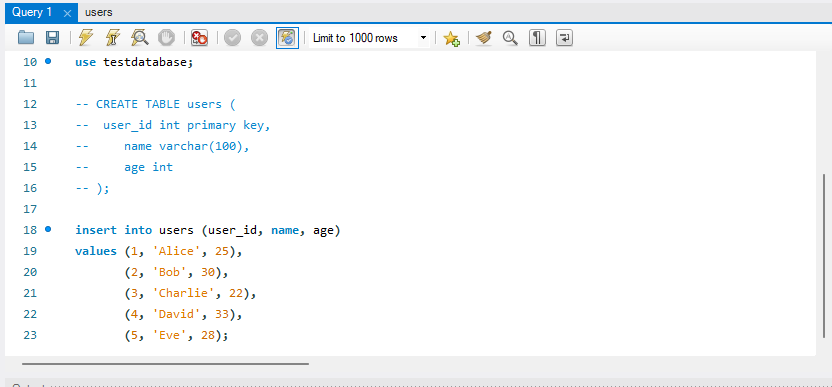
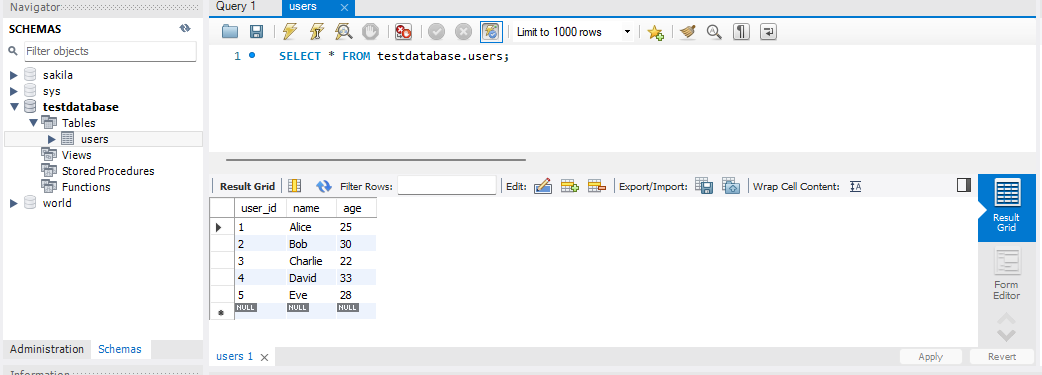
1. users 테이블 만들기 use testdatabase; CREATE TABLE users ( user_id INT PRIMARY KEY, name VARCHAR(100), age INT ); 2. 데이터 삽입 INSERT INTO users (user_id, name, age) VALUES (1, 'Alice', 25), (2, 'Bob', 30), (3, 'Charlie', 22), (4, 'David', 33), (5, 'Eve', 28);🌟주의사항
- 테이블을 먼저 만들고 실행, 그리고 실행한 코드 주석 처리후
- 데이터 삽입 진행.
-
두번째 테이블 만들기
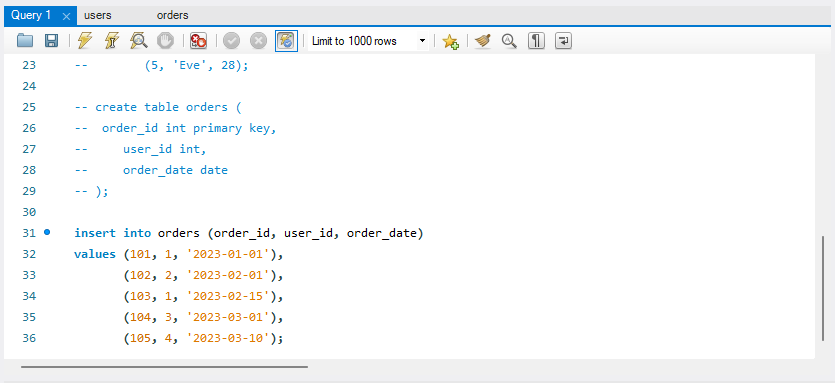
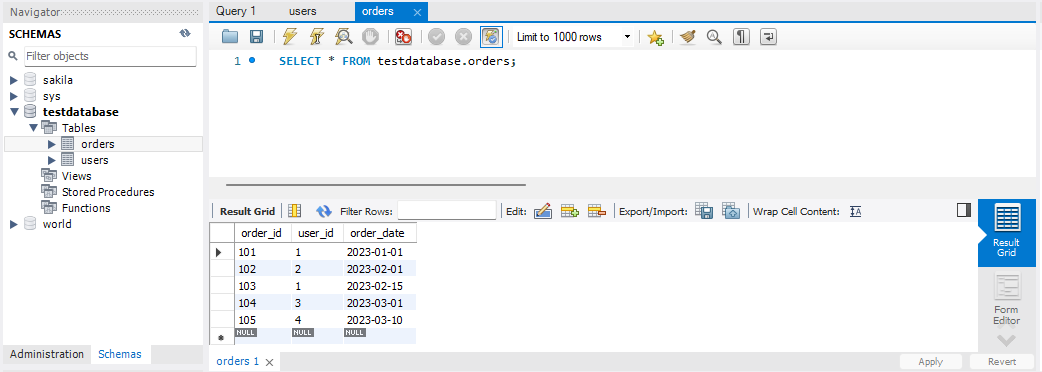
1. orders 테이블 만들기 CREATE TABLE orders ( order_id INT PRIMARY KEY, user_id INT, order_date DATE ); 2. 데이터 삽입 INSERT INTO orders (order_id, user_id, order_date) VALUES (101, 1, '2023-01-01'), (102, 2, '2023-02-01'), (103, 1, '2023-02-15'), (104, 3, '2023-03-01'), (105, 4, '2023-03-10');
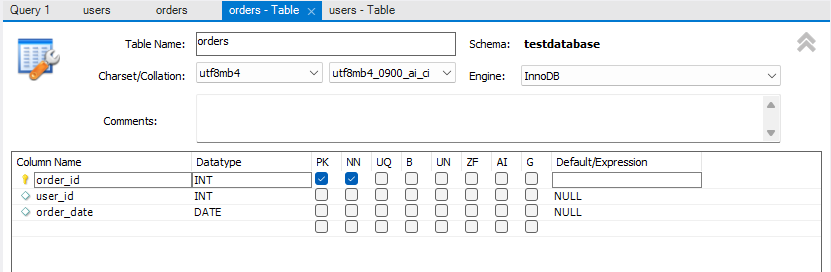
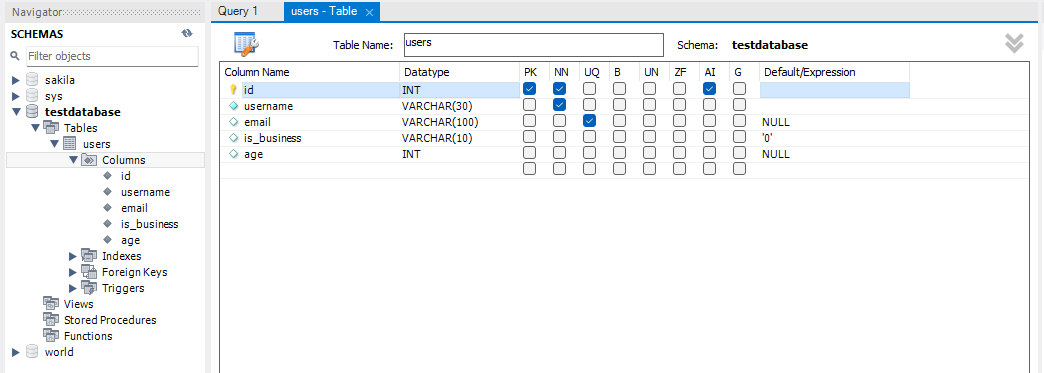
테이블 만드는 방법은 이렇게 코드로 하나하나 입력하는 방법도 있지만 SCHEMAS에 있는 항목에서 Tables에 Create Table을 눌러서 만들 수도 있다. (표 형식으로 보여주기 때문에 가시적으로 만들기 좋다!)
테이블을 만들고 데이터를 넣다보니 데이터 타입으로 int, varchar, date를 사용해보았다. 이 외에도 다양한 데이터 타입이 있는데 그에 대한 설명은 다음 chapter에서 자세히 다룬다.
10. MySQL 데이터 타입
MySQL 데이터 타입에 대한 자세한 설명은 공식 사이트를 참고하면 좋다.
자주 사용하는 데이터 타입에 대해 소개를 해보려 한다.
1. 숫자형 타입
-
BIT(M)
: 0과 1로 구성된 이진값, M은 1~64 사이의 값. -
BOOL
: 0은 false, 0이 아닌 값은 true로 간주되는 논리형 데이터. (true: 1) -
TINYINT(M)
: 1바이트 정수, 부호 있는 수는 -128 ~ 127, 부호 없는 수는 0 ~ 255. -
SMALLINT(M)
: 2바이트 정수, 부호 있는 수는 -32768 ~ 32767, 부호 없는 수는 0 ~ 65535. -
MEDIUMINT(M)
: 3바이트 정수, 부호 있는 수는 -8388608 ~ 8388607, 부호 없는 수는 0 ~ 16777215. -
INT(M) 또는 INTEGER(M)🌟
: 4바이트 정수, 부호 있는 수는 -2147483648 ~ 2147483647, 부호 없는 수는 0 ~ 4294967295. -
BIGINT(M)
: 8바이트 정수, 부호 있는 수는 -92233720036854775808 ~ 92233720036854775807, 부호 없는 수는 0 ~ 18446744073709551615. -
DECIMAL(M,D) 또는 NUMERIC
: M자리 정수(정밀도)와 D자리 소수점(스케일)으로 표현. 최대 65자리까지 표현 가능.
(M)에는 숫자를 적어주고 해당 숫자에 맞춰 최적화를 해준다.
2. 문자형 타입
-
CHAR(M)
: 고정 길이 문자열 저장 (M: 0 ~ 255). -
VARCHAR(M)🌟
: 가변 길이 문자열 저장 (M: 0 ~ 65,535). -
TINYTEXT
: 1 ~ 255 길이의 가변 길이 문자열. -
TEXT
: 1 ~ 65,535 길이의 가변 길이 문자열. -
MEDIUMTEXT
: 1 ~ 16,777,215 길이의 가변 길이 문자열. -
ONGTEXT
: 1 ~ 429,496,729 길이의 가변 길이 문자열. -
ENUM
: 최대 65,535 개의 문자열 중 하나를 반환. -
SET
: 비트 연산 열거형, 문자열 값을 정수값으로 매핑하여 저장.
TEXT는 블로그나 인스타 등 게시글에 사용할 수 있다.
※ CHAR(M)과 VARCHAR(M)의 차이
CHAR(M)
- 고정 길이 문자열 저장:
CHAR(M)은 항상 M개의 문자를 저장한다. - 길이 범위: 0에서 255 사이의 길이를 가질 수 있다.
- 공간 사용: M 길이의 고정 공간을 사용한다.
저장된 문자열이 M보다 짧으면 나머지 공간은 공백으로 채워진다. - 사용 사례: 길이가 일정하거나 변하지 않는 데이터에 적합하다. 예를 들어, 성별, 국가 코드 등.
VARCHAR(M)
- 가변 길이 문자열 저장:
VARCHAR(M)은 최대 M개의 문자를 저장할 수 있으며, 실제 저장되는 문자열의 길이에 따라 공간을 사용한다. - 길이 범위: 0에서 65,535 사이의 길이를 가질 수 있다.
- 공간 사용: 실제 문자열 길이에 따라 가변적인 공간을 사용한다.
추가적으로, 문자열 길이를 저장하기 위한 1~2바이트의 추가 공간이 필요하다. - 사용 사례: 길이가 예측 불가능하거나 변할 수 있는 데이터에 적합합니다. 예를 들어, 사용자 이름, 설명 텍스트 등.
<차이점 요약>
- 길이:
CHAR는 고정 길이,VARCHAR는 가변 길이다. - 공간 효율성:
CHAR는 항상 고정된 공간을 사용하지만,VARCHAR는 실제 데이터 길이에 따라 공간을 사용한다. - 적용 사례:
CHAR는 데이터 길이가 일정한 경우에,VARCHAR는 길이가 변할 수 있는 경우에 적합하다.
3. 날짜형 타입
-
DATE
: 날짜를 표현하는 타입 (3바이트), '1000-01-01' ~ '9999-12-31'. -
DATETIME
: 날짜와 시간을 같이 나타내는 타입 (8바이트), '1000-01-01 00:00:00' ~ '9999-12-31 23:59:59'. -
TIMESTAMP🌟
: '1970-01-01 00:00:00' ~ '2037-01-19 03:14:07', INSERT, UPDATE 연산에 유리 (4바이트). -
TIME
: 시간을 표현하는 타입 (3바이트), '-838:59:59' ~ '838:59:59'. -
YEAR
: 연도를 나타냄 (1바이트), 1901 ~ 2155, 70 ~ 69 (1970 ~ 2069).
※ DATETIME과 TIMESTAMP 의 차이
DATETIME
- 범위:
1000-01-01 00:00:00부터9999-12-31 23:59:59까지. - 저장 크기: 8바이트.
- 시간대에 무관:
DATETIME값은 시간대 변환 없이 그대로 저장됩니다. - 사용 사례: 특정 사건이 발생한 정확한 시점을 기록할 때 사용. 예를 들어, 사용자의 생일이나 기념일 등.
TIMESTAMP
- 범위:
1970-01-01 00:00:00부터2037-01-19 03:14:07까지. - 저장 크기: 4바이트.
- 시간대 인식:
TIMESTAMP는 UTC로 저장되며, 조회 시 서버의 시간대 설정에 따라 변환됩니다. - 자동 갱신:
INSERT나UPDATE연산 시 현재 시간으로 자동 갱신될 수 있습니다. - 사용 사례: 레코드의 생성 또는 수정 시간을 기록할 때 주로 사용. 예를 들어, 게시물의 작성 시간이나 마지막 수정 시간 등.
※ 실제 사용 예시
DATETIME사용 예시: 사용자 프로필
-
date_of_birth DATETIME: 사용자의 생일 데이터의 경우 회원 가입 이후 변경되지 않으며, 시간대에 영향을 받지 않는다.CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100), email VARCHAR(100), date_of_birth DATETIME );
TIMESTAMP사용 예시: 블로그 게시물
-
created_at TIMESTAMP: 게시물이 처음 생성된 시간. 이 필드는 게시물이 만들어질 때 현재 시간으로 자동 설정됩니다. -
updated_at TIMESTAMP: 게시물이 마지막으로 수정된 시간. 이 필드는 게시물이 수정될 때마다 현재 시간으로 자동 갱신됩니다.CREATE TABLE blog_posts ( id INT AUTO_INCREMENT PRIMARY KEY, title VARCHAR(255), content TEXT, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP );
<사용시 고려사항>
- 시간대: 국제화된 애플리케이션에서는 시간대 변환의 중요성 때문에
TIMESTAMP가 유리할 수 있습니다. - 범위와 저장 크기:
DATETIME은 더 넓은 범위를 커버하며 더 많은 저장 공간을 사용합니다. - 자동 갱신의 필요성: 레코드의 생성 또는 수정 시간을 자동으로 추적하고 싶다면
TIMESTAMP가 적합합니다.
-
DATETIME은 시간대에 무관한 넓은 범위의 날짜와 시간을 8바이트로 저장 -
TIMESTAMP는 시간대를 인식하는 좁은 범위의 날짜와 시간을 4바이트로 저장하며, 자동 갱신 기능
[DB 1일차 후기]
이런 데이터를 다루는 프로그램을 처음 써봐서 신기했다.
MySQL 자체는 인터페이스가 없는 프로그램이고 이 프로그램을 가시화해서 편하게 사용하기 위한 것이 WorkBench인 것도 신기했다.
(데이터를 넣는 작업을 하면서 예전에 설계 일할때 Midas 프로그램에서 응력값 집어넣고 저항값 설정하고 하중 조합 넣고 했던 것이 생각났다. ㅎㅎ)
초반에 설치하는데 오류가 많아서 힘들었지만 구글링을 통해 극복!🌟(세상엔 똑똑한 사람들이 너무 많당)
막상 해보면 어려운 프로그램이나 언어가 아니라고 하니 아직 초반엔 익숙하지 않아서 낯선 것이다 라고 생각하는 중이다.
MySQL이 끝나고 다른 프로그램들도 맛볼 수 있길!
이제 또 C언어를 공부하러,,,⭐
[참고 자료]
- [오즈스쿨 스타트업 웹 개발 초격차캠프 백엔드 데이터베이스 강의]
