
1일차에서는 DB, DBMS 종류, RDBMS 종류, MySQL 설치 및 간단한 사용법에 대해서 공부했다.
오늘은 MySQL을 이용해서 DML, DDL을 활용하고 작은 실습 프로젝트들까지 진행하는 것이 목표이다.
01. SQL (DML) 기초
1. 테이블 생성 - CREATE TABLE (DDL)
지난번에 이어서 이미 만들어놓은 testdatabase란 데이타 베이스 안에 기존 테이블들을 모두 DROP(삭제)하고 새로운 테이블을 생성한다.
USE testdatabase; -- 먼저 실행.
CREATE TABLE users (
user_id INT PRIMARY KEY AUTO_INCREMENT,
username TEXT NOT NULL,
email TEXT NOT NULL,
age INT
); -- user_id, username, email, age란 컬럼 생성.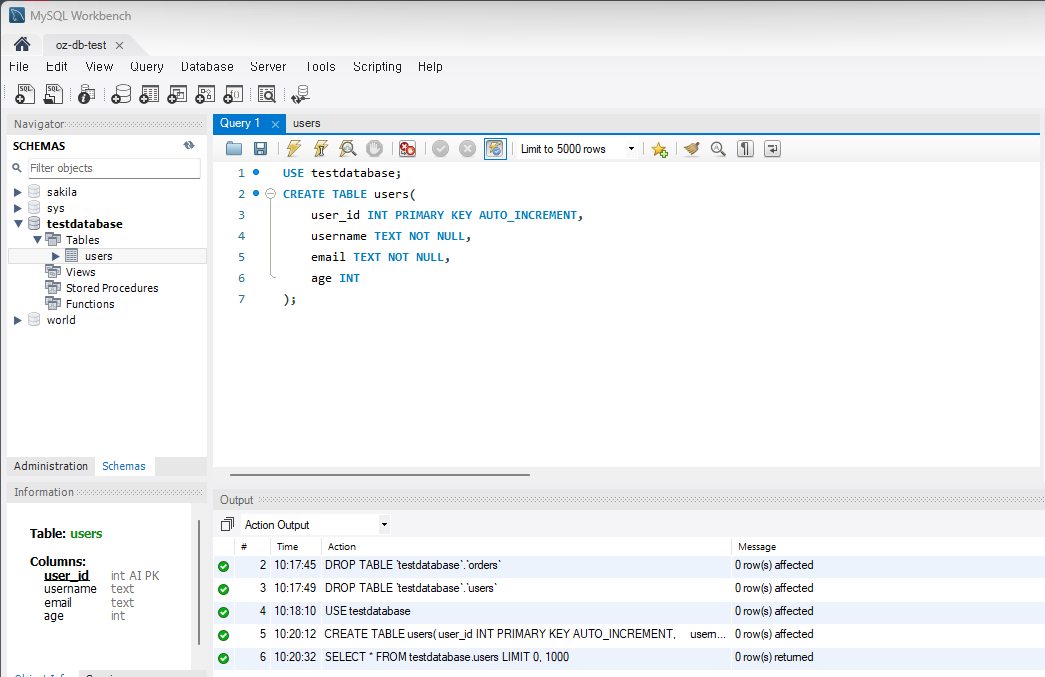
+) AUTO_INCREMENT 컬럼
AUTO_INCREMENT를 가진 컬럼은 자동으로 증가하는 값을 가지며, 명시적으로 값을 지정하지 않다.
INSERT INTO users (username, email) VALUES ('frank', 'frank@example.com');이러한 INSERT 쿼리문을 적절히 활용하여 데이터를 효과적으로 데이터베이스에 추가할 수 있다.
2. 데이터 생성 - INSESRT INTO
🌟주의🌟
코드 작성을 할 때 위에서 작성한 'CREATE TABLE' 문을 삭제하거나 주석 처리 후 하단의 코드를 작성하고 실행해야한다.
(단, USE문은 삭제나 주석처리하지 않는다.)
그러지 않으면 작업을 두번 실행시키는 것이 된다.
실제로는 명령 프롬프트 (터미널)에서 작성해야하는 것을 가시화 하기 위해 Workbench를 사용하는 것이기 때문에 그렇다고 이해하면 된다.
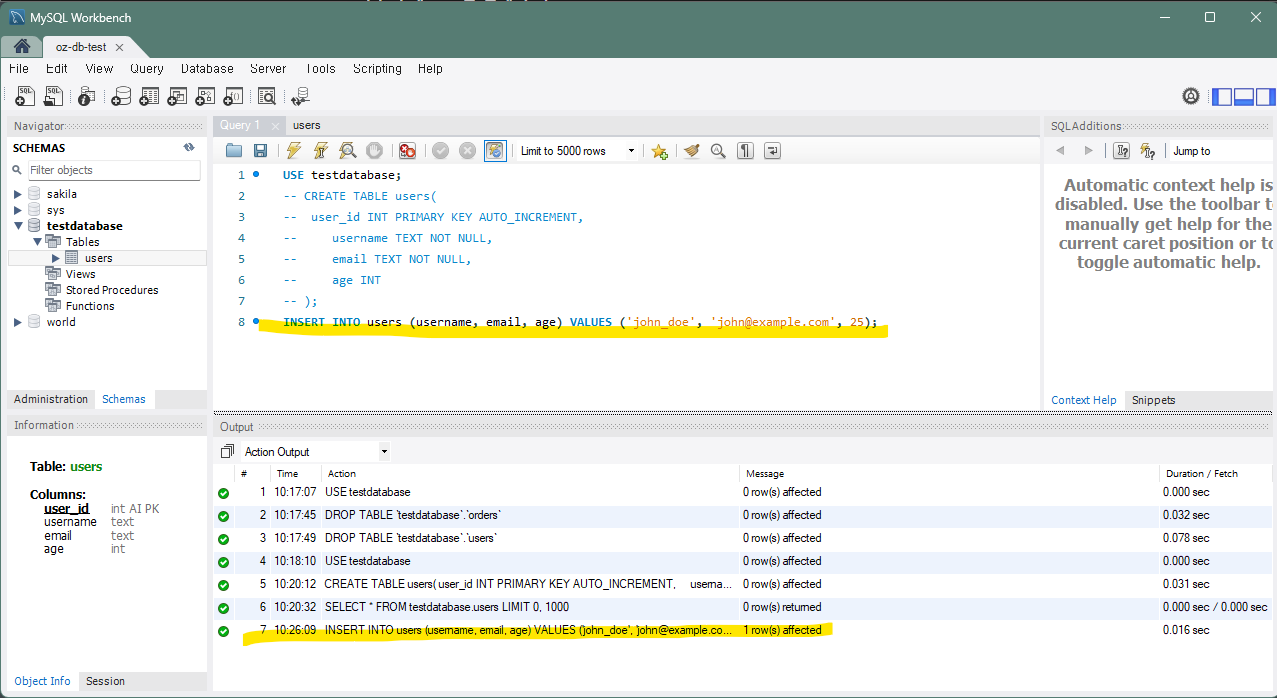
1) 기본적인 INSERT문
가장 기본적인 데이터 생성 형태로 모든 컬럼에 값을 지정하여 레코드(로우)를 추가합니다.
INSERT INTO users (username, email, age) VALUES ('john_doe', 'john@example.com', 25);코드를 실행하게 되면 'users'란 테이블에 첫번째 괄호 안에 작성한 컬럼마다 두번째 괄호 안 값들이 넣어진 것을 확인할 수 있다.
괄호로 데이터를 넣는 방법이 있지만 SET으로 일일이 컬럼과 로우 값을 연결하여 데이터를 넣는 방법도 있다.
+) SET 문
INSERT INTO users SET username='john_doe', email='john@example.com', age=25;지금은 쿼리 베이스로 데이터를 생성하지만,
심화 과정으로 가면 Python을 활용하여 프레임워크랑 결과를 합쳐서 프레임 워크에서 데이터를 조회하고 Rest API로 내려주는 것을 구현할 예정이다.
2) 모든 컬럼에 값을 지정하지 않는 경우
일부 컬럼에만 값이 지정되고 지정하지 않은 나머지는 기본값 또는 NULL 값을 가지게 된다.
INSERT INTO users (username, email) VALUES ('MJ', 'jane@example.com')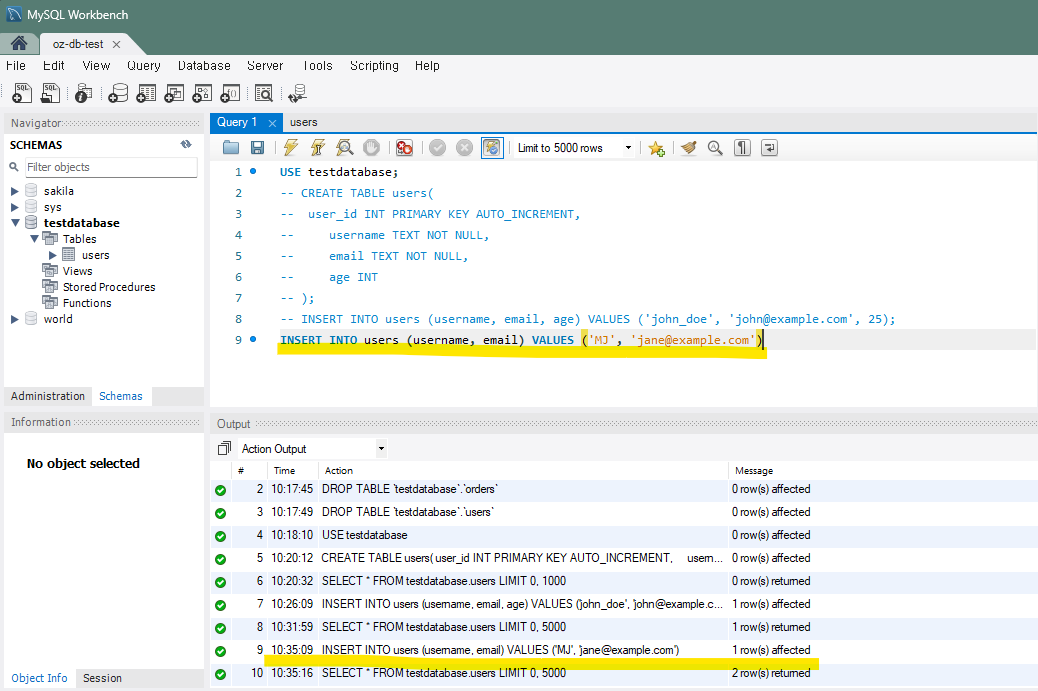
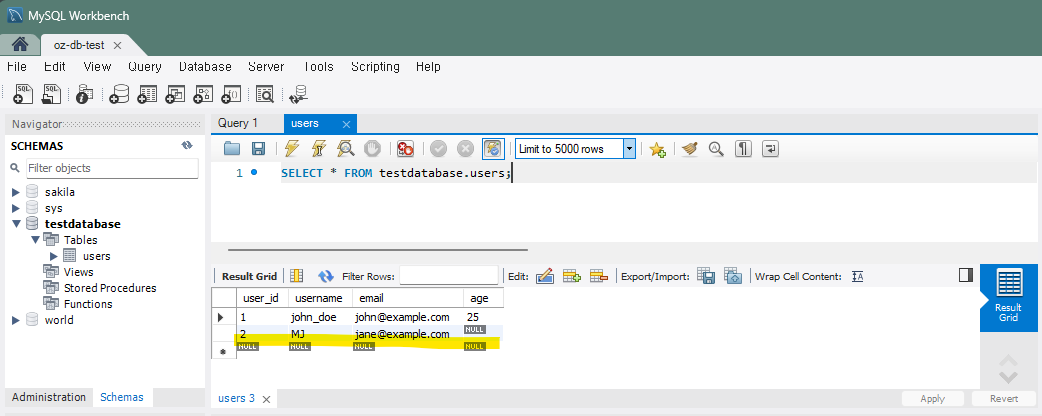
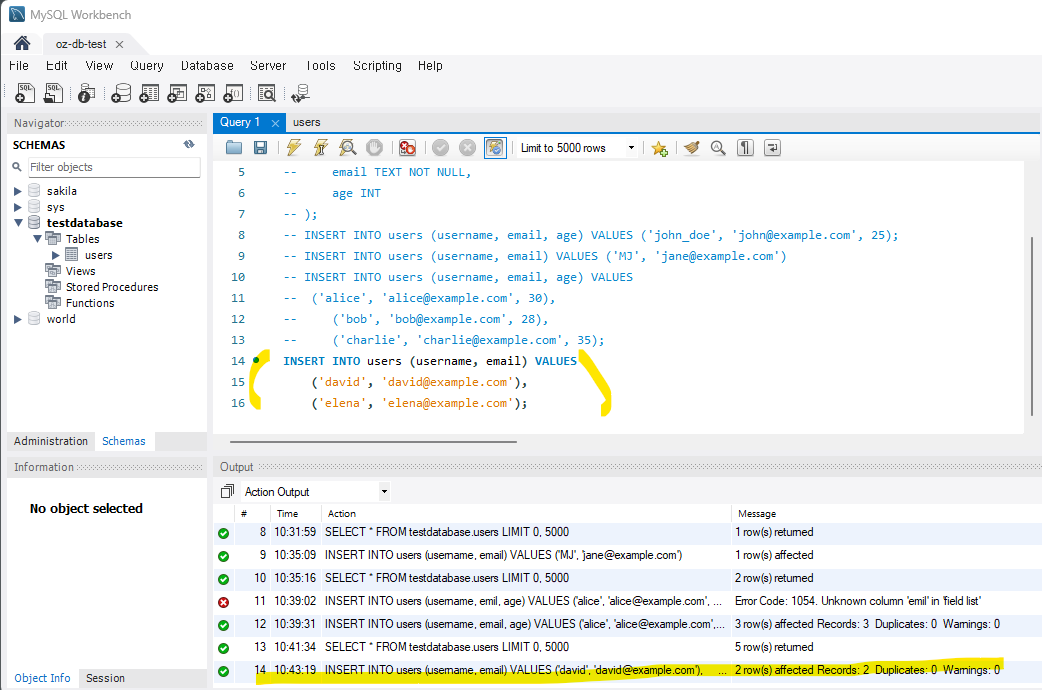
3) 다수의 레코드 한번에 추가하는 경우
아래코드와 같이 VALUES를 여러 괄호로 입력하면 한번에 여러가지 데이터를 추가할 수 있다.
INSERT INTO users (username, email, age) VALUES
('alice', 'alice@example.com', 30),
('bob', 'bob@example.com', 28),
('charlie', 'charlie@example.com', 35);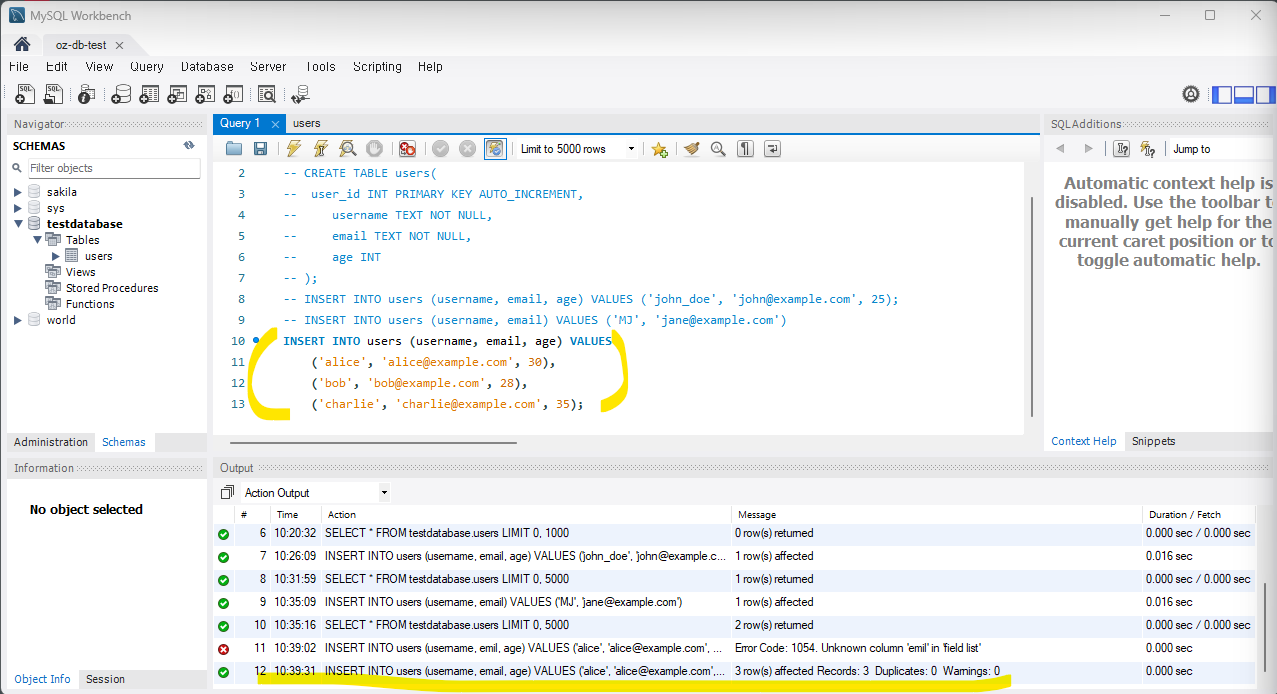
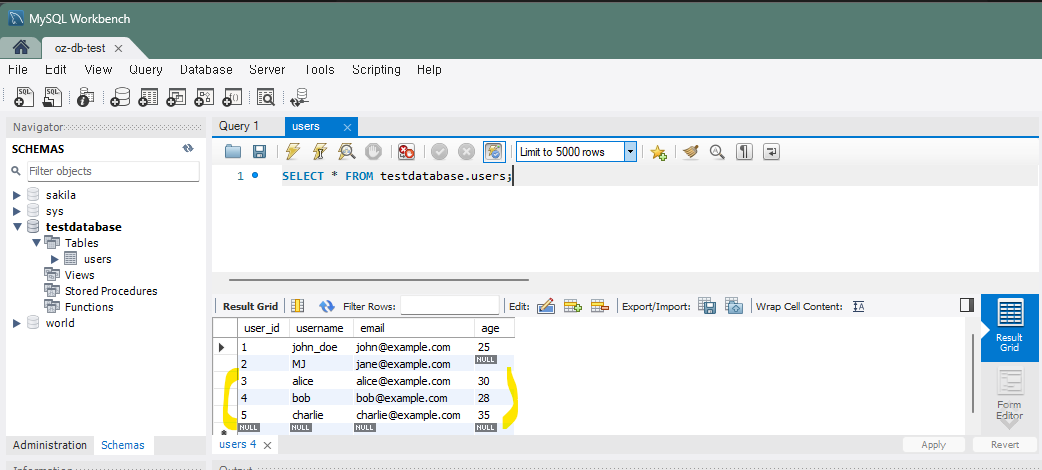
다수의 레코드를 한번에 추가하는 경우에도 특정 컬럼만 선택하여 값을 추가할 수 있다.
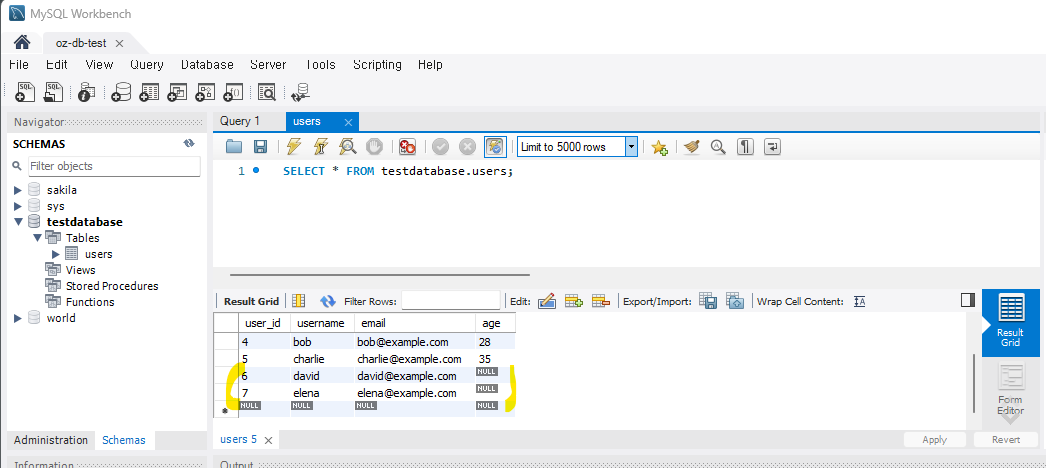
4) 중복된 레코드 피하기
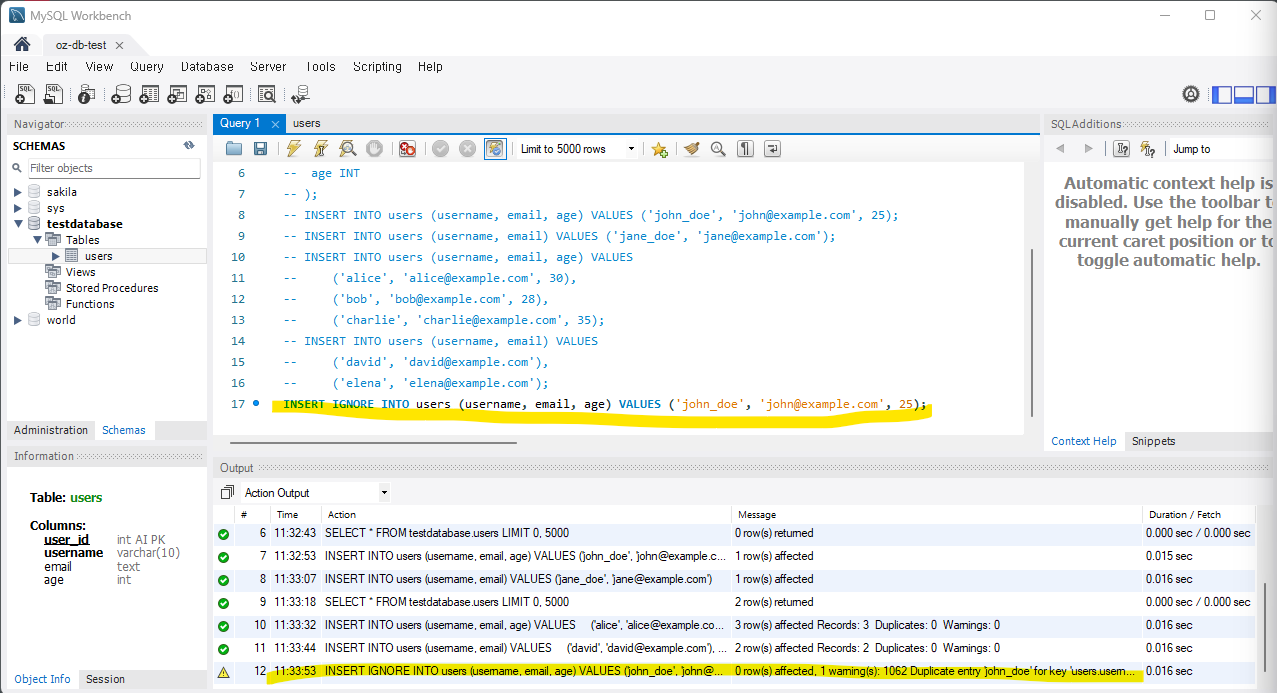
IGNORE을 추가로 입력하여 중복된 값이 있는 경우 레코드를 추가하지 않고 에러를 방지하는 방법이다.
INSERT IGNORE INTO users (username, email, age) VALUES ('john_doe', 'john@example.com', 25);사실 이 예제를 따라할 때 IGNORE이니깐 추가되지 않아야하는데 계속 추가가 되었다.
왜 계속 추가가 되지? 생각해보니
컬럼을 지정할때 UNIQUE 값으로 지정한 것이 없어서 (username이라던지 email이라던지) 계속 추가가 된 것이었다.
그래서 Query랑 테이블을 다시 다 삭제하고 하단의 테이블로 다시 만들어 예제를 진행했다.
USE testdatabase;
CREATE TABLE users (
user_id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(10) NOT NULL UNIQUE,
email TEXT NOT NULL,
age INT
); 오 IGNORE문이 작동을 했다!
5) 중복된 레코드 업데이트 하기
ON DUPLICATE KEY UPDATE를 입력하여 중복된 값이 있는 경우 해당 레코드의 데이터를 입력한 값으로 업데이트할 수 있다. (사실 이 코드도 제대로 실행이 안되서 UNIQUE 컬럼을 만들어서 다시 예제를 진행해야겠다 결심했다.)
INSERT INTO users (username, email, age) VALUES ('john_doe', 'john@example.com', 25)
ON DUPLICATE KEY UPDATE age = 27;
-- 기존의 john_doe의 나이를 25에서 27로 변경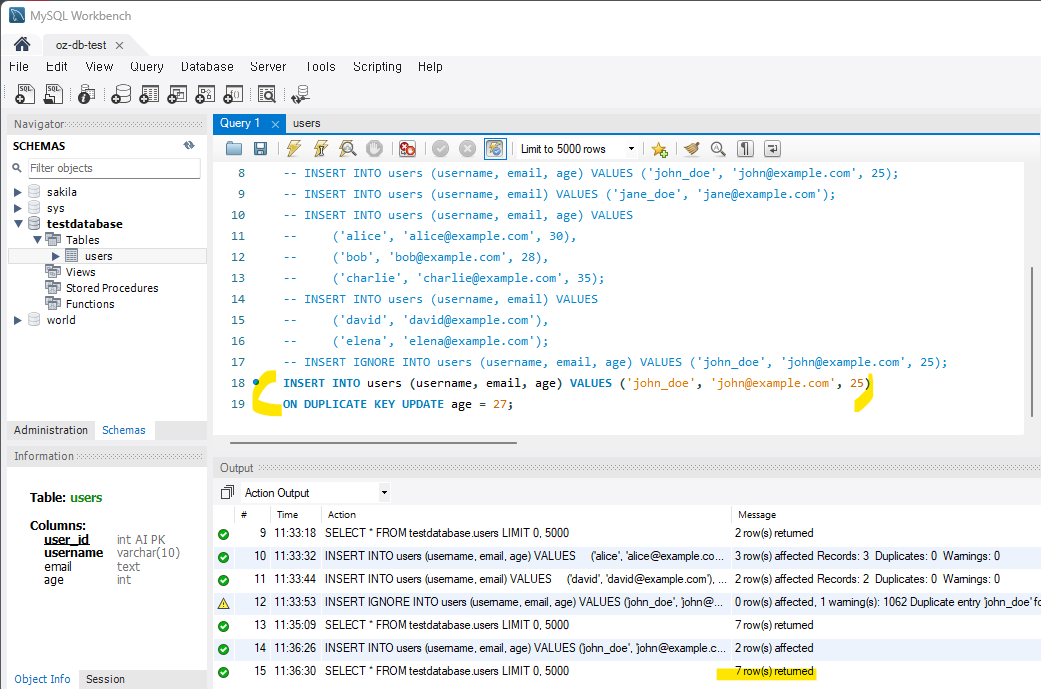
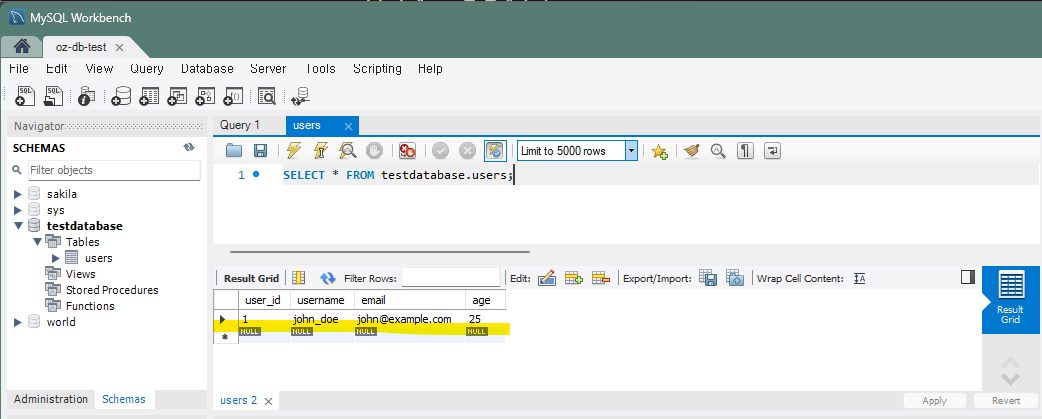
3. 데이터 조회 - SELECT FROM
데이터를 입력했다면 이번엔 저장한 데이터를 조회하는 방법을 소개한다.
1) 기본적인 조회 - SELECT
데이터가 잘 입력되었는지 확인할 때 다른 창으로 넘어가곤 했는데 그 때 사용되었던 코드가 조회 코드였다.
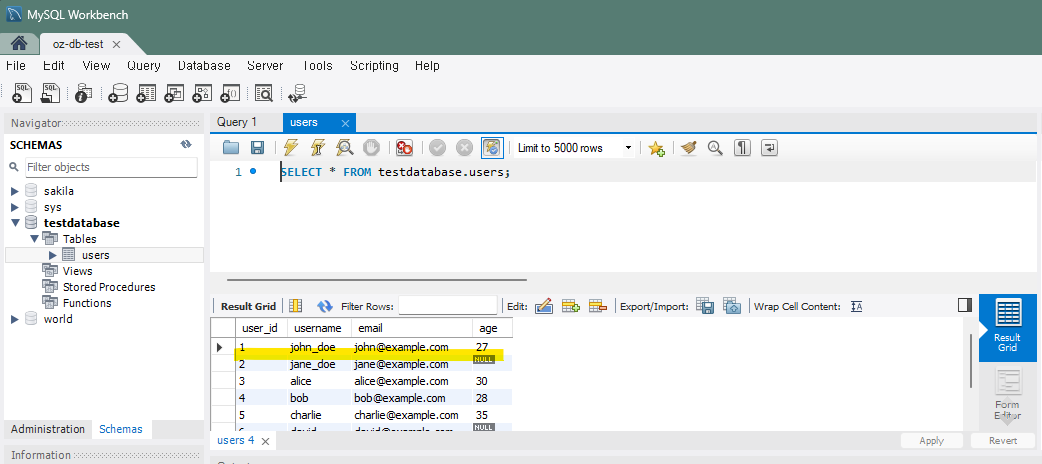
SELECT * FROM testdatabase.users;
: testdatabase란 데이터베이서에서 users라는 테이블 안에 모든 데이터 조회라는 뜻.
-- 모든 컬럼 조회
SELECT * FROM users;
-- 특정 컬럼만 조회
SELECT user_id, username, email FROM users;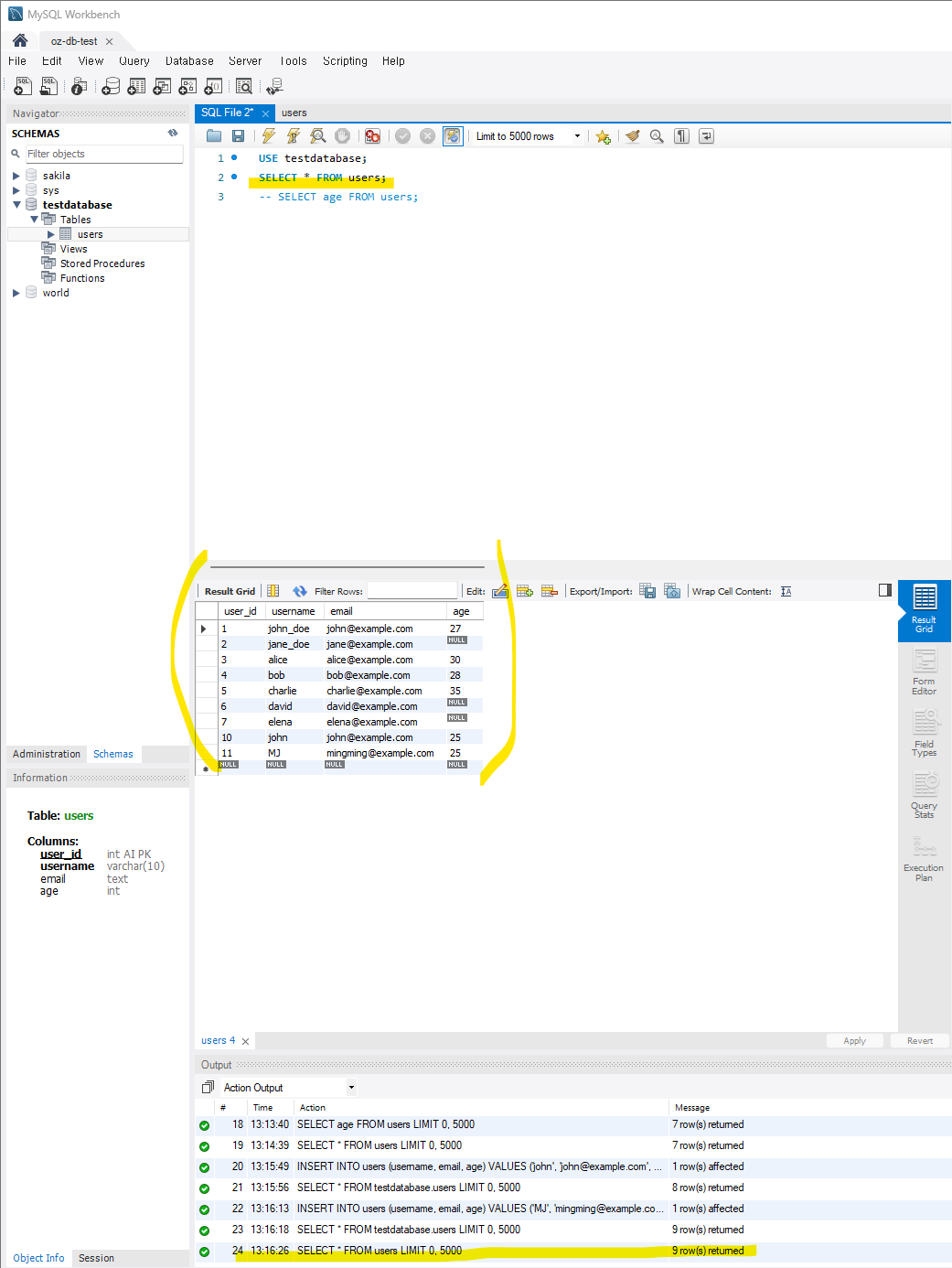

2) 중복 데이터 삭제 - DISTINCT
DISTINCT를 추가하여 중복된 데이터를 제외하고 조회가 가능하다.
-- 중복 제거한 나이 조회
SELECT DISTINCT age FROM users;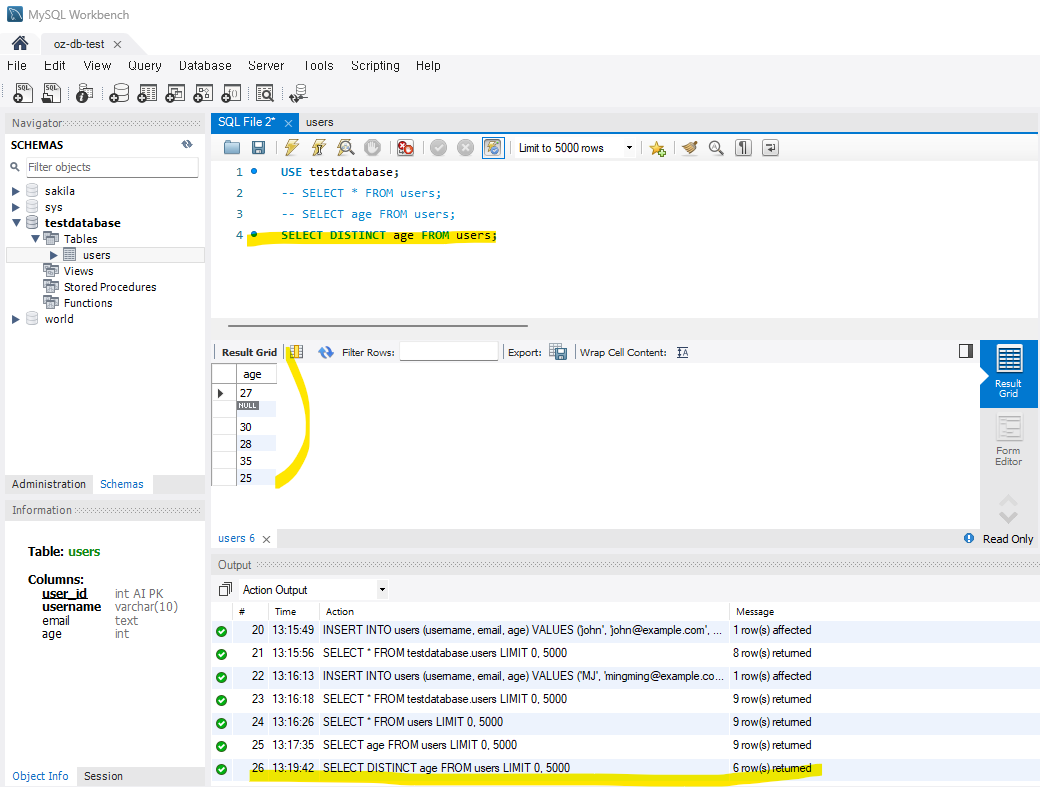
3) 일시적으로 추가 컬럼 만들기 - AS
AS를 추가해서 일시적으로 새로운 컬럼을 추가해서 조회할 수 있다.
예제에서는 숫자 연산 값을 조회하려고 하는데 이때 값이 INT등 숫자형 데이터여야 가능하다.
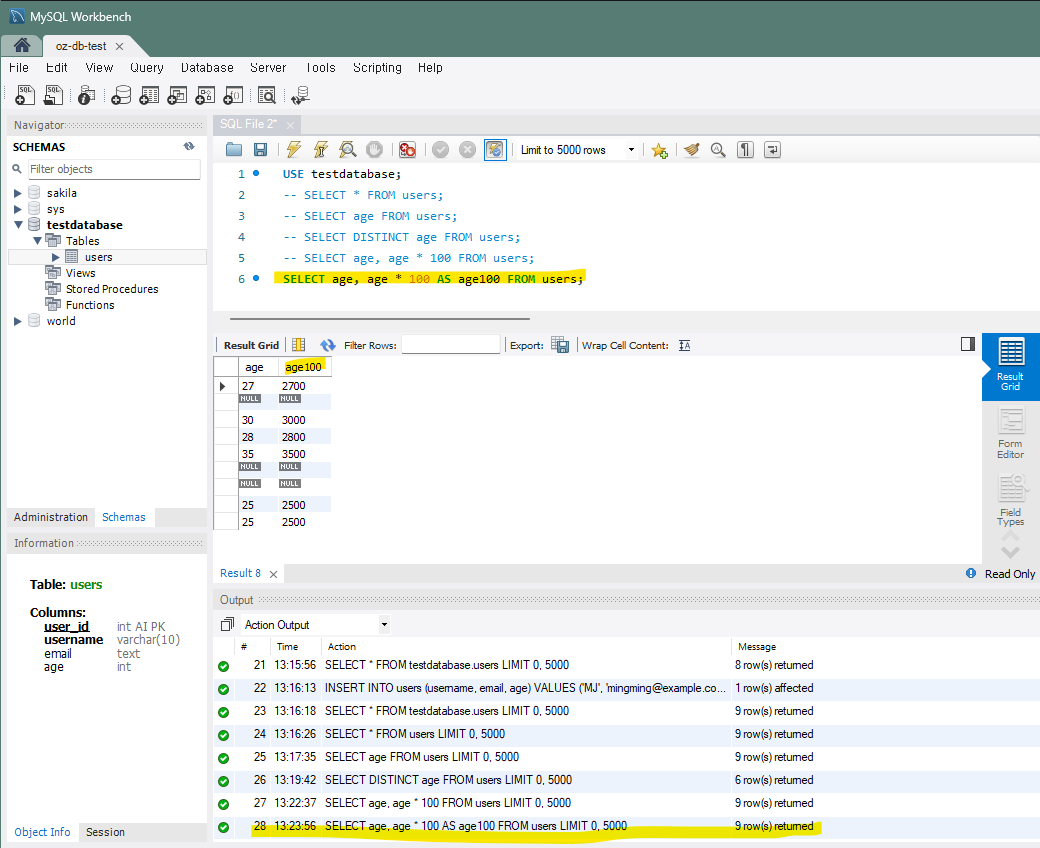
-- 나이와 나이에 100을 곱한 값을 조회 (컬럼명 따로 정의 X)
SELECT age, age * 100 FROM users;
-- AS를 사용하여 새로운 컬럼명 정의
SELECT age, age * 100 AS age100 FROM users;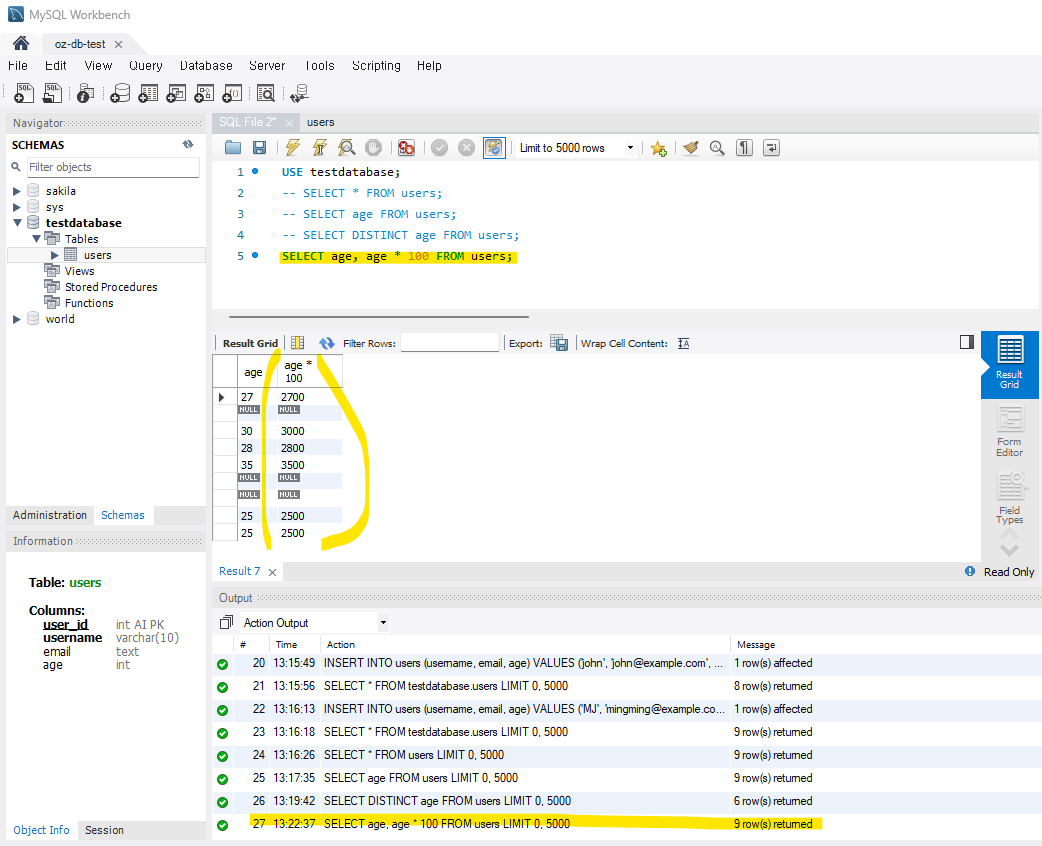
4) 조회 데이터 정렬해서 보기
데이터를 오름차순, 내림차순 등 정렬해서 볼 수 있다.
-- 나이순으로 오름차순 정렬
SELECT * FROM users ORDER BY age;
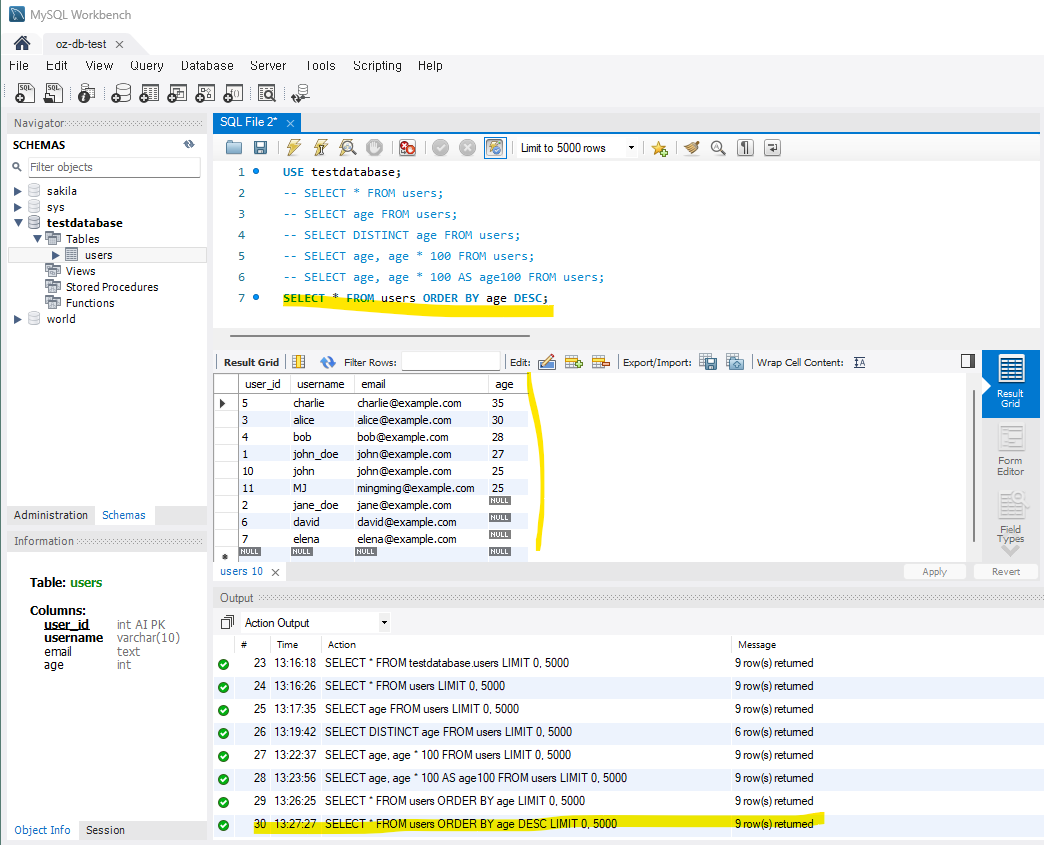
-- 나이순으로 내림차순 정렬
SELECT * FROM users ORDER BY age DESC;
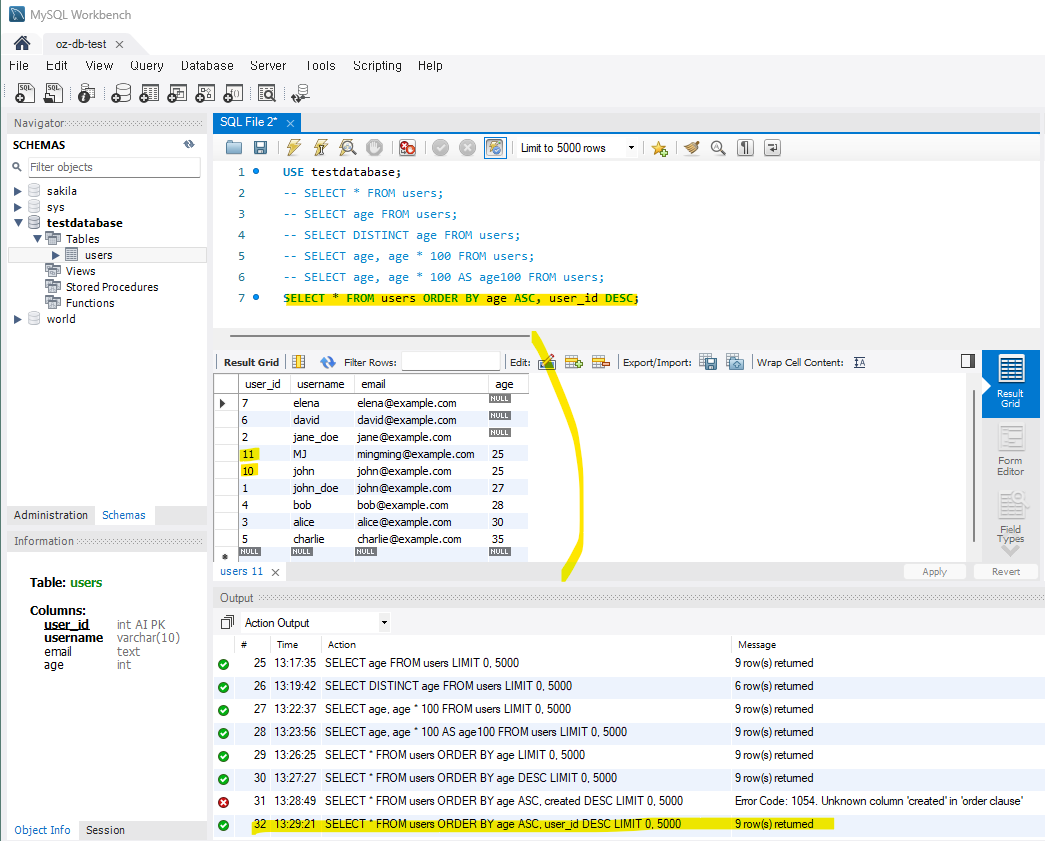
-- 여러 기준으로 정렬 (ASC: 오름차순, DESC: 내림차순)
SELECT * FROM users ORDER BY age ASC, user_id DESC;
-- 1) 나이 오름차순, 2) user_id 내림차순으로 정렬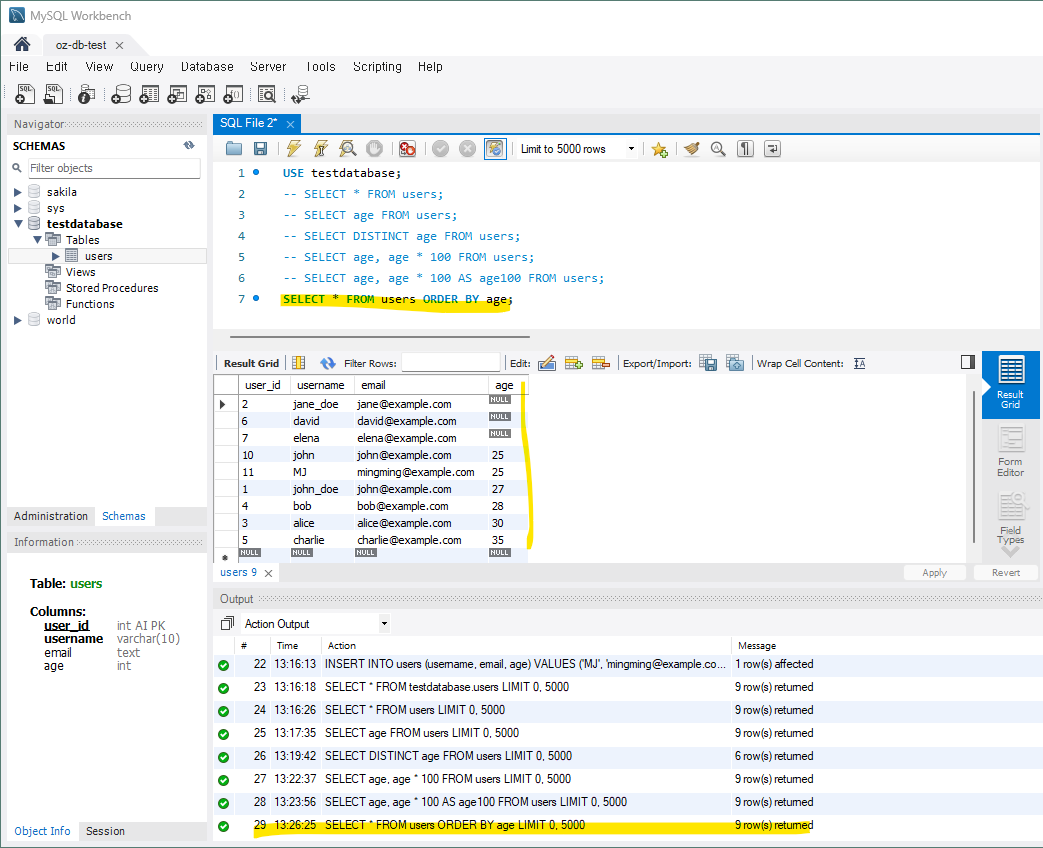
5) 조건문 - WHERE
WHERE문을 추가해서 기준을 만들어 데이터 일부만 조회할 수 있다.
-- 특정 조건에 맞는 데이터 조회
SELECT * FROM users WHERE age = 30;
-- 특정 조건 이상 데이터 조회
SELECT * FROM users WHERE age >= 30;
-- AND, OR를 사용한 복합 조건
SELECT * FROM users WHERE age = 33 AND name = 'Leo';
SELECT * FROM users WHERE age = 33 OR name = 'Leo';
-- NOT을 사용한 부정 조건
SELECT * FROM users WHERE NOT age = 33;
-- BETWEEN을 사용한 범위 지정
SELECT * FROM users WHERE age BETWEEN 20 AND 25;
-
나이가 입력되지 않았거나 25보다 작으면 조회되지 않는다.
-
AND는 교집합,OR은 합집합이라고 생각하면 된다.
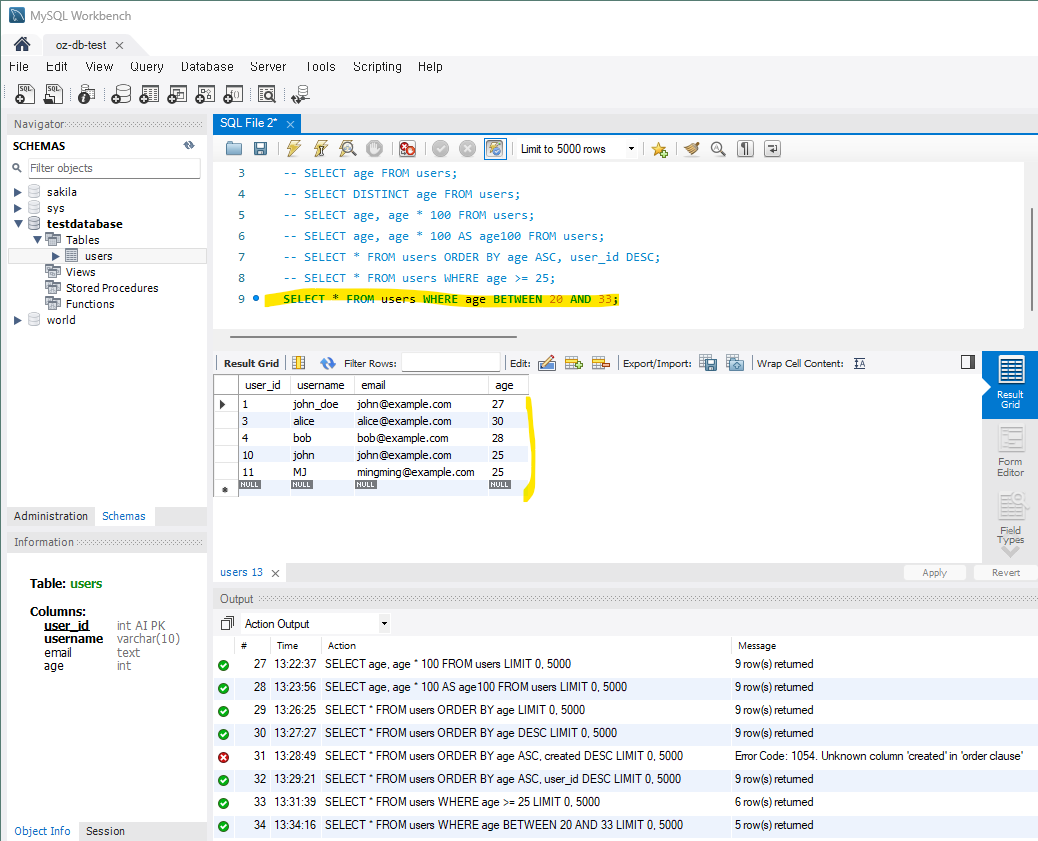
BETWEEN을 수식으로 20 < age < 33로 나타낼 수 있으며 범위를 지정할 수 있다.
6) 특정 개수 제한 - LIMIT
LIMIT을 사용하면 조회한 데이터 중 지정한 숫자 만큼의 상위 항목만 보여준다. 상위항목의 기준(몇번째부터인지)도 정할 수 있다. → 페이지 네이션 기능에 이용할 수 있다.
-- 상위 5개의 데이터 조회
SELECT * FROM users LIMIT 5;
-- 10번째부터 5개의 데이터 조회 (페이징)
SELECT * FROM users LIMIT 10, 5;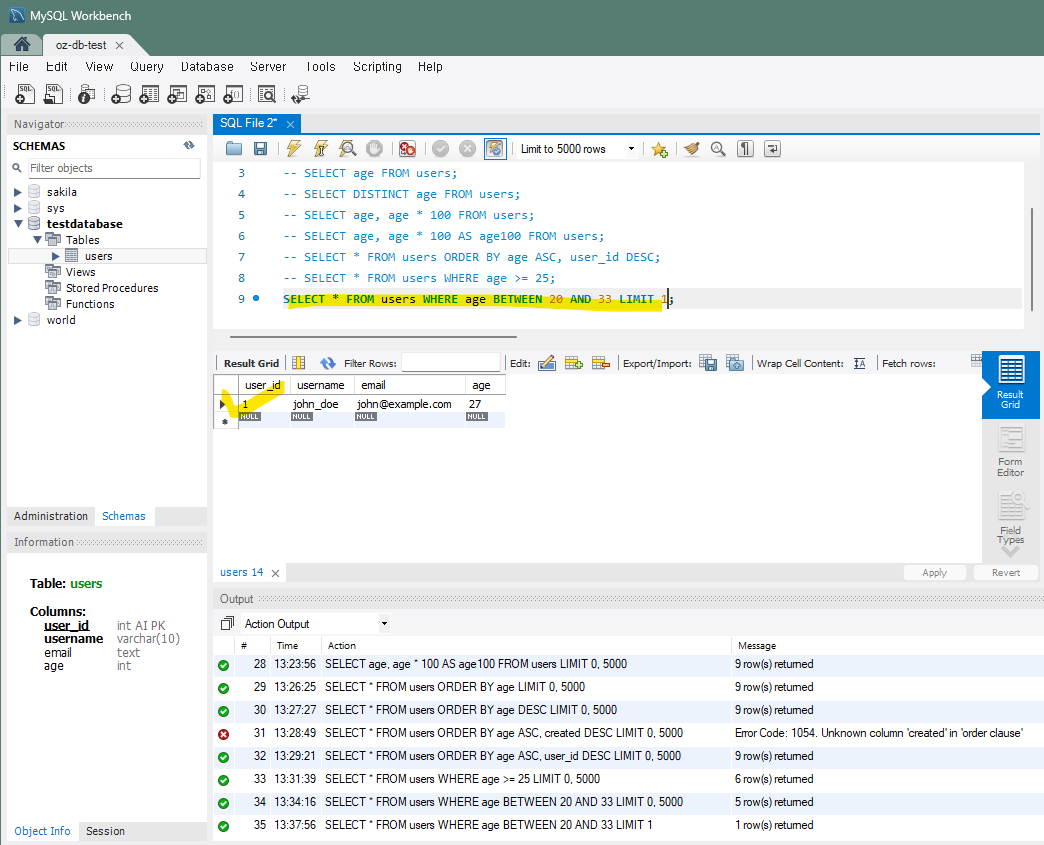
7) 결과 Grouping - GROUP BY
조회한 데이터를 같은 값이 있다면 같은 값끼리 묶어서 보여준다.
-- 나이별로 그룹화하여 user_count라는 그룹별로 데이터 개수 조회
SELECT age, COUNT(*) AS user_count FROM users GROUP BY age;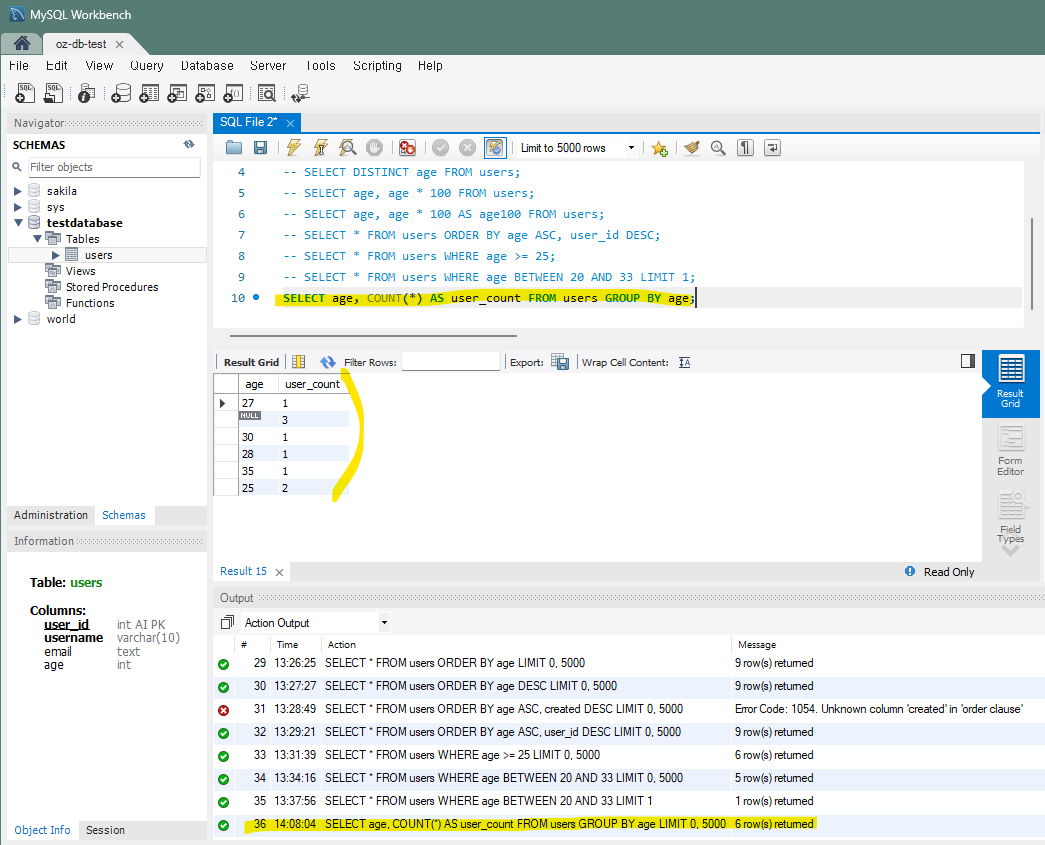
8) 특정 조건에 따라 값 변환 - CASE WHEN (조건문)
원하는 컬럼을 우선 적고 뒤에 CASE WHEN구문을 추가하여 특정 조건에 따른 새로운 임시 컬럼으로 데이터를 조회할 수 있다.
-- 나이가 30 이상인 경우 '성인', 미만인 경우 '미성년자'로 변환하여 name, age 조회
SELECT username, age,
CASE WHEN age >= 30 THEN '성인' ELSE '미성년자' END AS age_group
FROM users;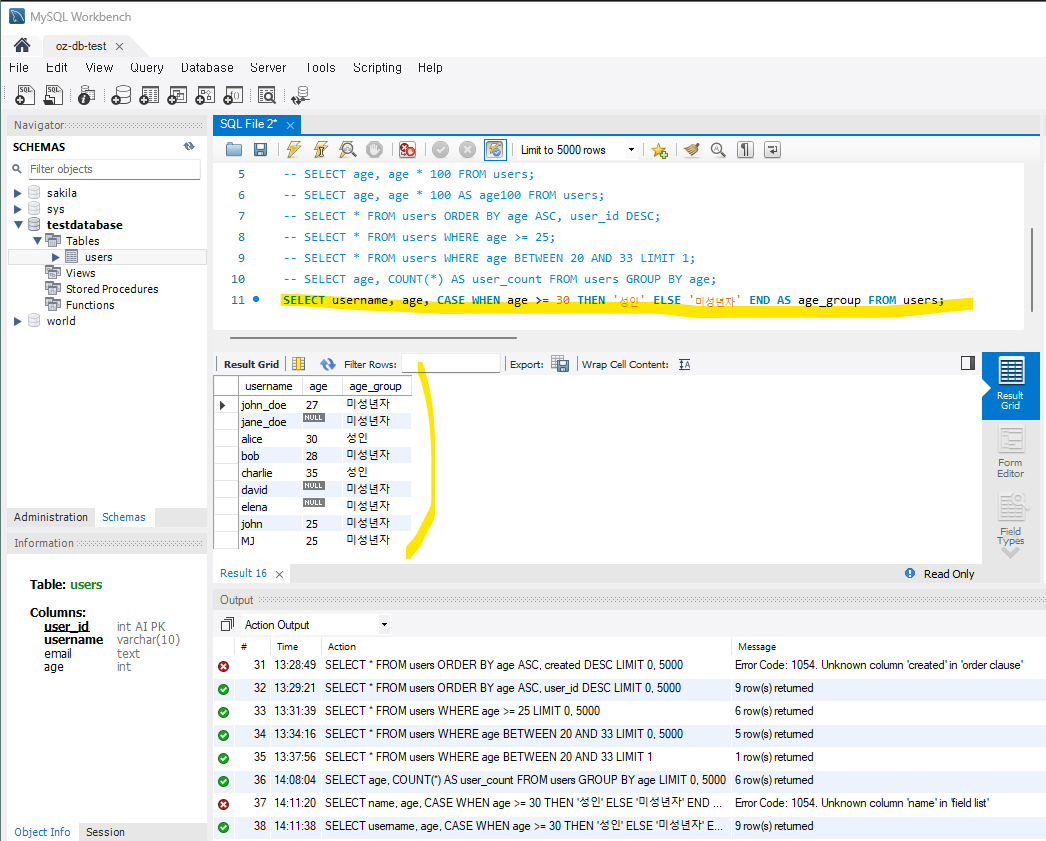
9) 여러 테이블 조인 - JOIN
여러 테이블들이 있다면 각 테이블에서 원하는 데이터를 가져와서 함께 조회할 수 있는 query이다.
이 예제는 추후 여러 테이블이 있을 때 해볼 예정이다.
-- users 테이블과 orders 테이블을 user_id를 기준으로 조인
SELECT users.name, users.age, orders.order_id
FROM users
JOIN orders ON users.user_id = orders.user_id;10) 결과 내림차순으로 순위 부여 - ROW_NUMBER()
-- 나이에 따라 내림차순으로 순위 부여하여 조회
SELECT username, age,
ROW_NUMBER() OVER (ORDER BY age DESC) AS 'rank'
FROM users;
-- rank라는 기능이 있기 때문에 따옴표 안에 넣어서 정의했다.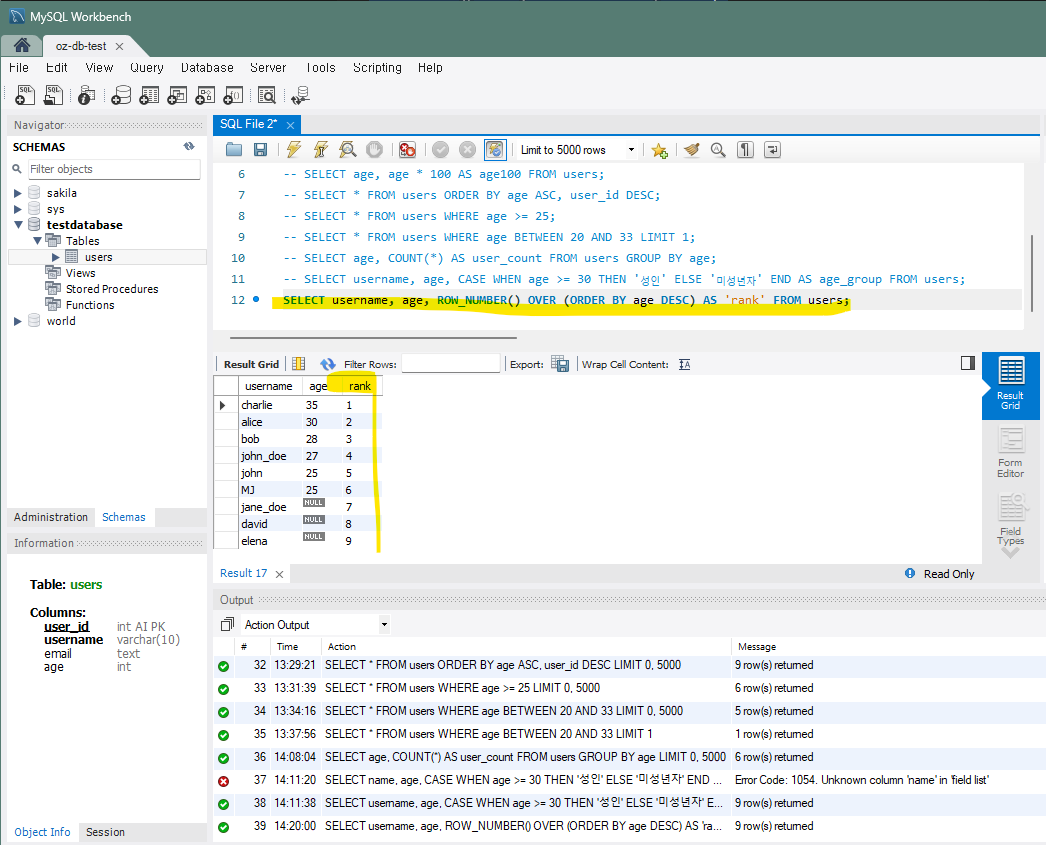
4. 데이터 업데이트 - UPDATE SET
1) 기본적인 UPDATE
UPDATE 테이블명
SET 컬럼1 = 값1, 컬럼2 = 값2, ...
WHERE 조건;-
테이블명: 업데이트할 테이블의 이름
-
컬럼 (= 값): 업데이트할 컬럼과 새로운 값을 지정
-
조건: 어떤 레코드를 업데이트할지 결정하는 조건
-
예시)
-- users 테이블에서 id가 1인 레코드의 이름을 'John'으로 수정 UPDATE users SET username = 'John_doe' WHERE user_id = 1; -
업데이트시 오류가 생긴다면 아래 사이트를 참고하길 바란다.
: https://ojava.tistory.com/148 -
여러 레코드 동시에 업데이트
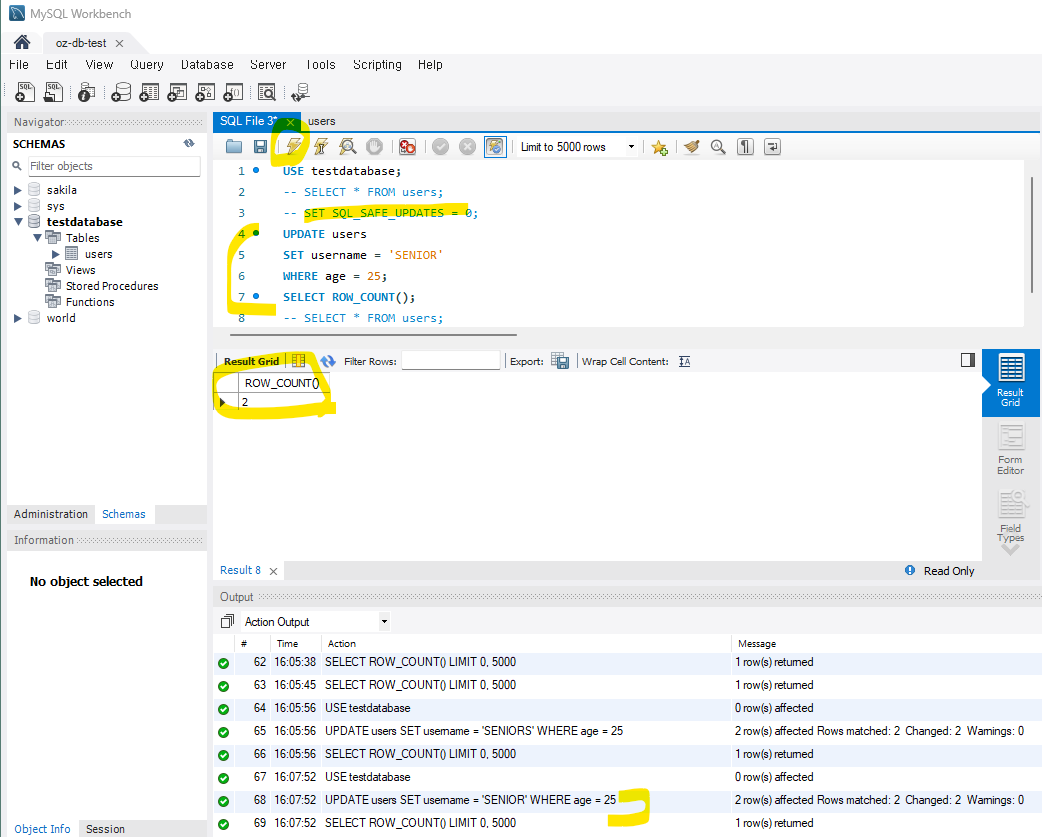
-- age가 25 이상인 모든 레코드의 username을 senior로 수정 UPDATE users SET username = 'senior' WHERE age >= 25;만약 변경되지 않는다면 아래 코드를 작성해본다.
SET SQL_SAFE_UPDATES = 0;
: 세이프 모드 비활성화
-
업데이트된 레코드 수 확인
: 기존에 업데이트 코드와 같이 작성하면 변경된 레코드 수를 확인할 수 있다.
(실행할 때 그냥 Ctrl + Enter를 하게 되면 해당 커서가 있는 코드만 실행되기 때문에 번개 모양 또는 'Shitf + Ctrl + Enter'를 눌러주는 것을 추천한다.)-- 업데이트된 레코드 수 반환 SELECT ROW_COUNT();
2) CASE문을 사용한 UPDATE
*60세가 넘는 사람의 데이터가 없다면 추가해주고 진행하길 바란다.
-- user의 age가 60 이상인 경우 'senior'로 username 설정,
-- 그 외의 경우 username은 'young'로 설정
UPDATE users
SET username = CASE
WHEN age >= 60 THEN 'senior'
ELSE 'young'
END;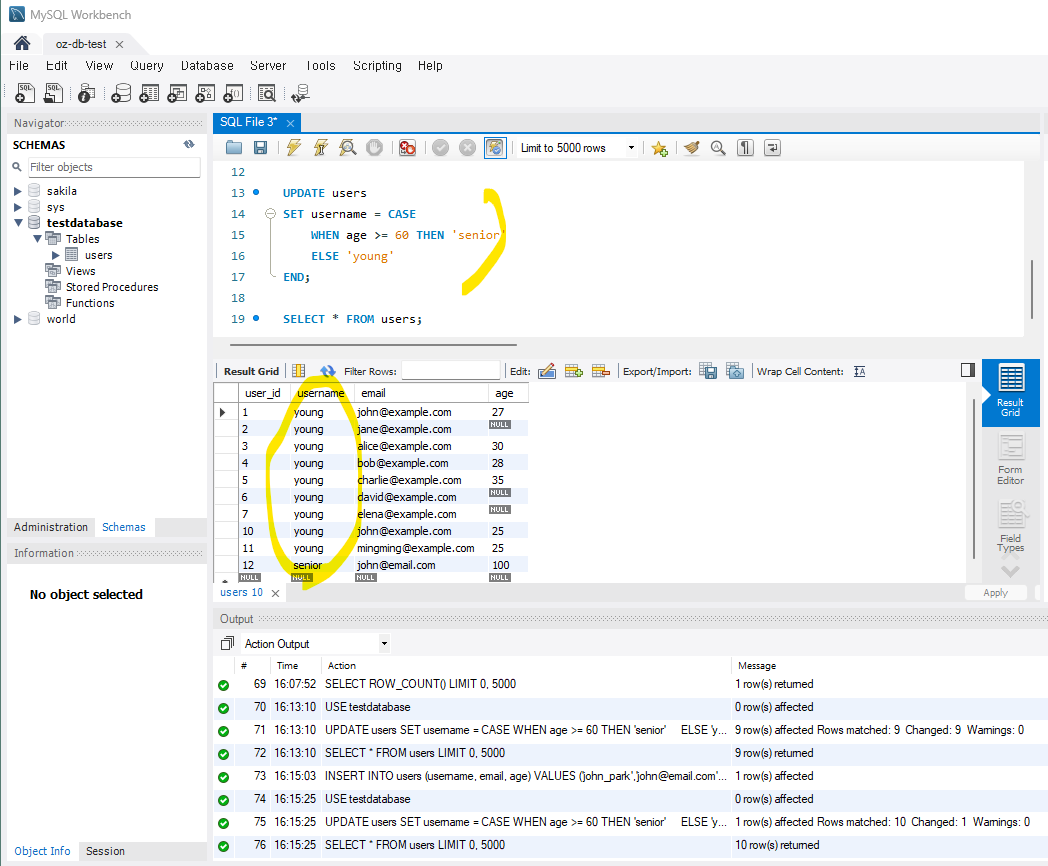
이렇게 일괄적으로 'username'이 변경된 것을 확인할 수 있는데 사실 이건 돌이킬 수 없는 강을 건넌 것이다!
실제로 이런 일이 벌어진다면 큰일이 난 것이기 때문에 이런 상황을 미연에 방지하기 위해서 '세이프 모드'가 있는 것이다.
3) LIMIT을 사용한 일부 레코드만 업데이트
-- age가 25이상인 레코드 중에서 나이값이 있는 레코드 중 순차적으로 5명 username 'top5_young'으로 수정
UPDATE users
SET username = 'top5_young'
WHERE age >= 25
LIMIT 5;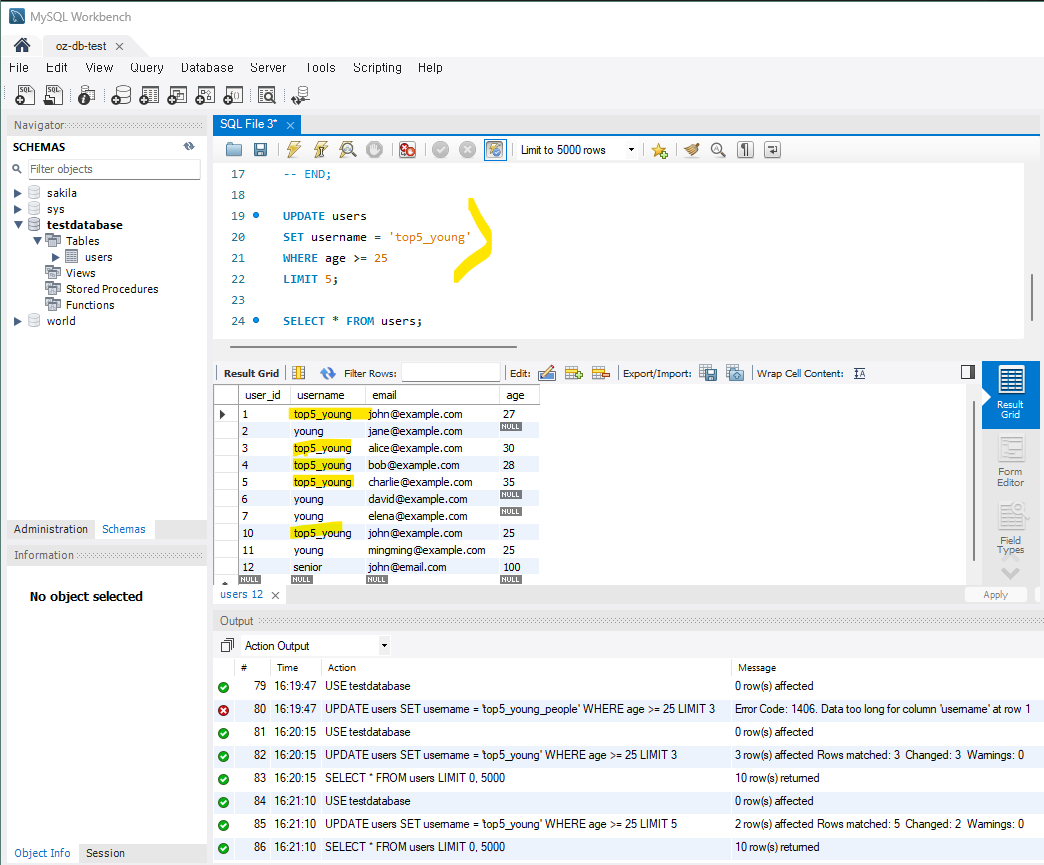
4) SUBQUERY를 사용한 업데이트
조건을 좀 더 구체화 해서 업데이트 할 수 있다.
-- 다른 서브쿼리 결과에 따라 업데이트
UPDATE products
SET price = price * 1.1
WHERE category_id IN (SELECT id FROM categories WHERE name = 'Electronics');5) REGEXP를 사용한 업데이트
이메일의 아이디부분만 데이터 입력을 받았다면 REGEXP을 이용해서 데이터 입력 양식을 통일하여 업데이트 할 수 있다.
-- 정규 표현식을 활용하여 업데이트
UPDATE users
SET email = CONCAT(email, '_new')
WHERE email REGEXP '@example\.com$';6) CASE 문을 사용한 다양한 조건에 따른 업데이트
-- 다양한 조건에 따라 다른 업데이트 수행
UPDATE products
SET price = CASE
WHEN stock < 10 THEN price * 1.1
WHEN stock >= 10 AND stock < 50 THEN price * 1.05
ELSE price
END;5. 데이터 제거 - DELETE FROM
1) 기본적인 DELETE
-- 특정 테이블에서 모든 행 삭제
DELETE FROM users;사실 한번에 테이블에 있는 모든 레코드를 지우는 일은 잘 없다.
2) 조건을 사용한 삭제
-- 특정 조건을 만족하는 행 삭제
DELETE FROM users WHERE age = 25;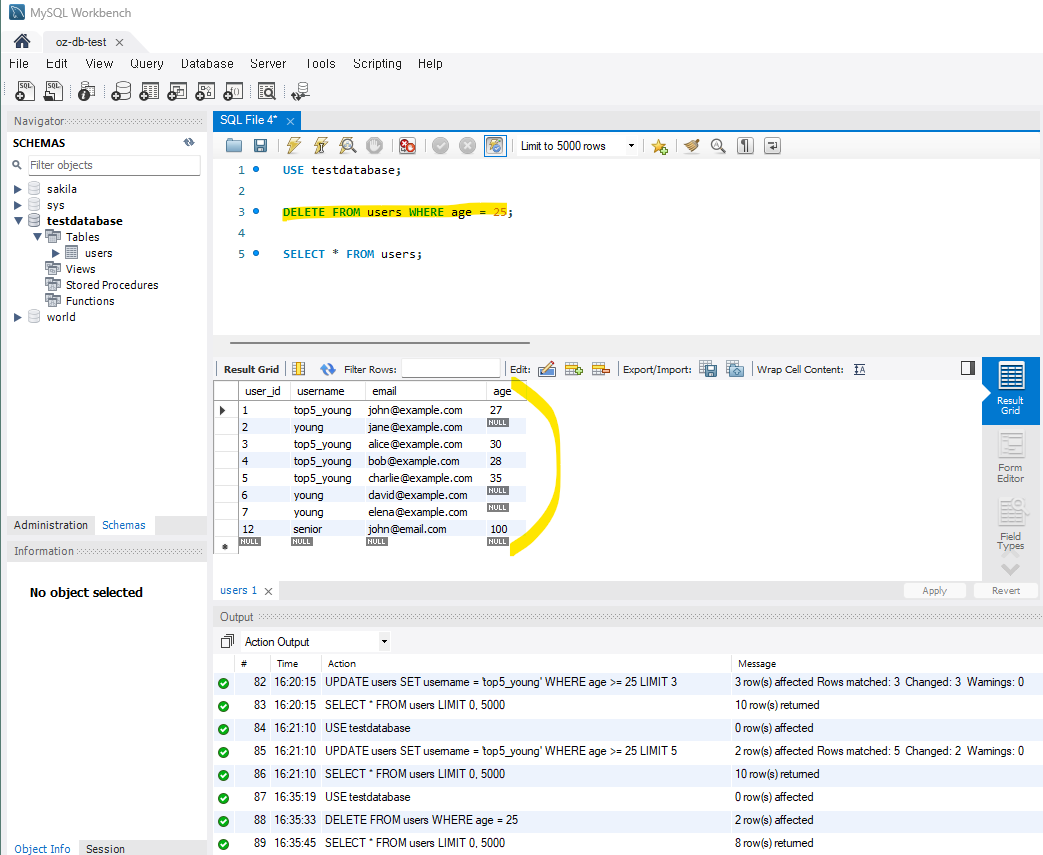
3) LIMIT을 사용한 삭제
-- 특정 개수 이상의 행을 삭제하지 않도록 제한
DELETE FROM orders WHERE username = 'top5_young' LIMIT 2;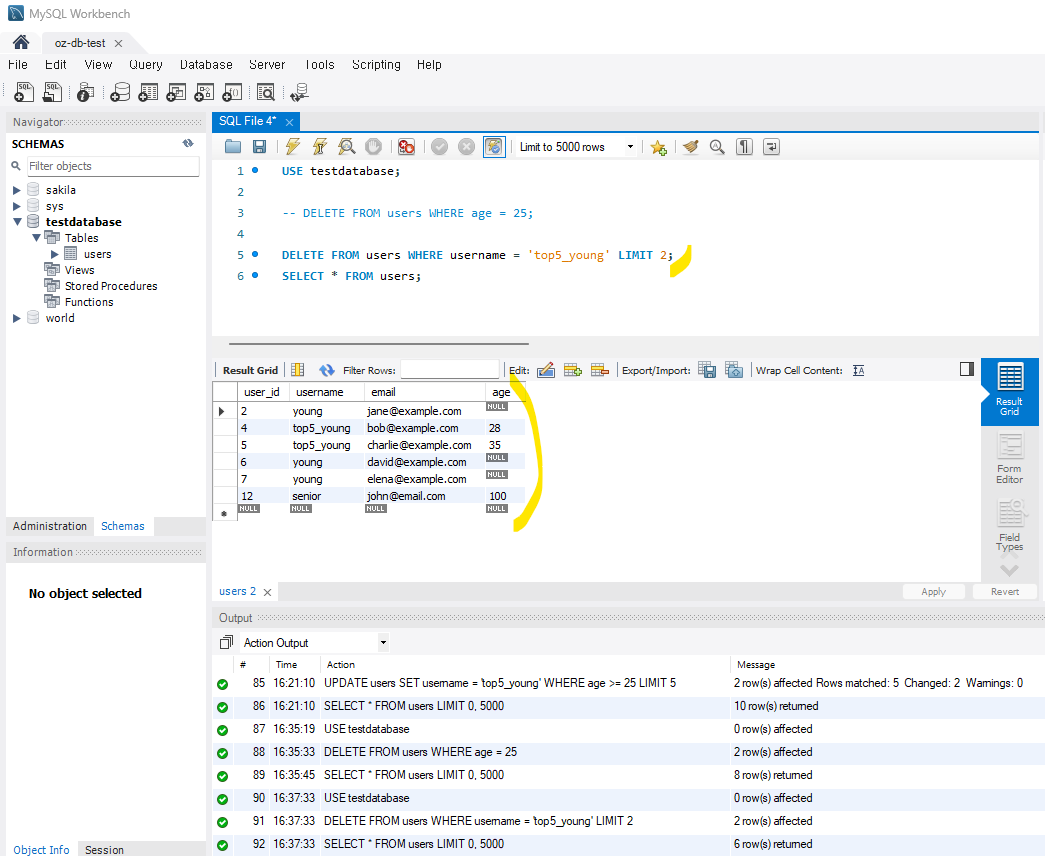
4) JOIN을 사용한 삭제
-- 다른 테이블과 조인하여 삭제
DELETE e FROM employees AS e
JOIN departments AS d ON e.department_id = d.id
WHERE d.name = 'Marketing';5) USING을 사용한 삭제
-- 다른 테이블과 조인하여 삭제 (USING 구문 활용)
DELETE FROM employees
USING employees, departments
WHERE employees.department_id = departments.id AND departments.name = 'HR';6) RETURNING을 사용한 삭제 및 반환
-- 삭제한 행 반환 (PostgreSQL에서 사용 가능)
DELETE FROM users WHERE age > 65 RETURNING *;02. SQL (DML) 심화
1. 테이블 생성
예제에 사용될 두 개의 테이블을 만들어 준다.
-
users 테이블
CREATE TABLE users ( user_id INT PRIMARY KEY AUTO_INCREMENT, username TEXT NOT NULL, email TEXT NOT NULL );기존의 users 테이블을 DROP(삭제)하고 새로운 users 테이블을 위와 같이 만들 수 있지만,
기존의 users 테이블을TRUNCATE TABLE을 하게 되면 안에 레코드들이 다 삭제된다.
이렇게 했을 때 단점은 user_id가 초기화 되진 않는다. -
orders 테이블
CREATE TABLE orders ( order_id INT PRIMARY KEY AUTO_INCREMENT, user_id INT, product_name VARCHAR(255), quantity INT, FOREIGN KEY (user_id) REFERENCES users(user_id) -- users 테이블에 있는 user_id를 참고하여 FK 설정. (하나로 묶어 연결하기) );
2. Python으로 데이터 랜덤 생성 (Generate)
1) 패키지 설치
우선 데이터를 랜덤으로 만들어주는 라이브러리 패키지 하나를 설치해야한다.
-
Window
pip install mysql-connector-python faker -
MAC
pip3 install mysql-connector-python faker
2) 모듈 불러오기
import mysql.connector
from faker import Faker
import random # 파이썬 기본 모듈
# (1) MYSQL 연결 설정
db_connection = mysql.connector.connect(
host='localhost',
user='root',
password='본인 비밀번호',
database='testdatabase'
)
# (2) MYSQL 연결
cursor = db_connection.cursor()
faker = Faker()
# 100명의 users 더미 데이터 생성
for _ in range(100):
username = faker.user_name()
email = faker.email()
sql = "INSERT INTO users(username, email) VALUES(%s, %s)"
values = (username, email)
cursor.execute(sql, values)
# user_id 불러오기
cursor.execute("SELECT user_id FROM users")
valid_user_id = [row[0] for row in cursor.fetchall()]
# 100개의 주문 더미 데이터 생성
for _ in range(100):
user_id = random.choice(valid_user_id)
product_name = faker.word()
quantity = random.randint(1, 10)
try:
sql = "INSERT INTO orders(user_id, product_name, quantity) VALUES(%s, %s, %s)"
values = (user_id, product_name, quantity)
cursor.execute(sql, values)
except:
print("오류 발생")
pass
db_connection.commit()
cursor.close()
db_connection.close()이렇게하면 랜덤하게 더미 데이터 100개가 users 테이블과 orders 테이블에 들어가게 된다.
3. 데이터 조인 - INNER, LEFT, RIGHT, FULL JOIN
두 개 이상의 테이블을 연결하여 하나의 테이블처럼 출력하고 싶을 때 JOIN을 사용한다.
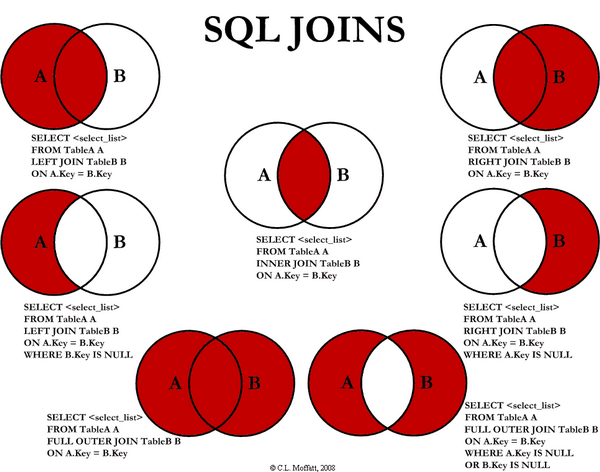
1) INNER JOIN (내부 조인)
사진을 참고하면 벤다이어그램으로 볼때 '교집합'에 속한다.
-- 기본구조
SELECT *
FROM TableA A
INNER JOIN TableB B
ON A.key = B.key모든 사용자와 그들이 만든 주문을 조회한다. 사용자와 주문 테이블 간의 user_id를 기준으로 매칭된 행을 반환한다.
SELECT * FROM users
INNER JOIN orders ON users.user_id = orders.user_id;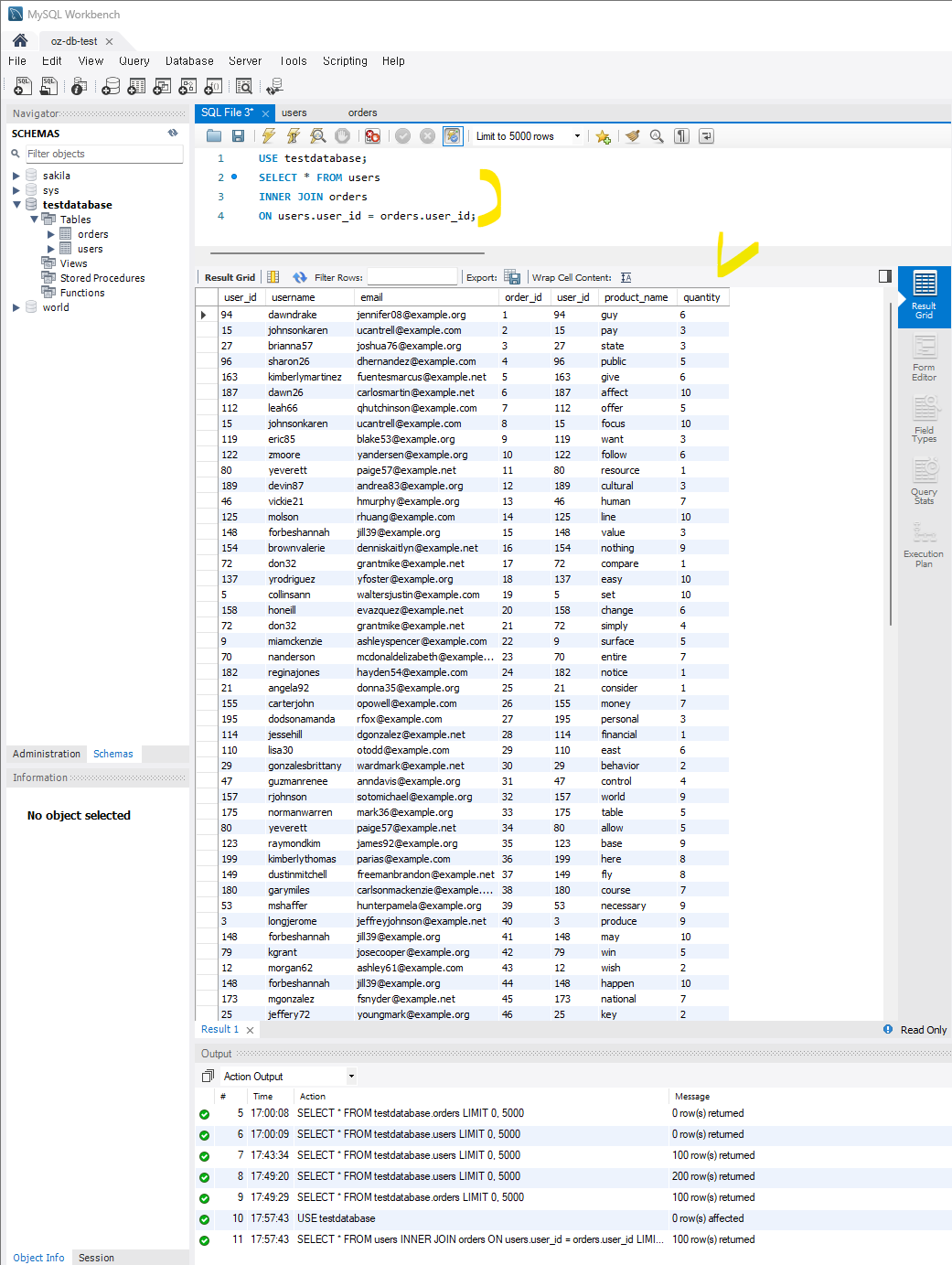
2) LEFT JOIN (왼쪽 조인)
이번엔 LEFT JOIN을 하여 사용자 테이블의 모든 행을 포함하고, 주문 테이블과 매칭되는 경우 해당 주문 정보를 포함하여 보여준다.
SELECT * FROM users
LEFT JOIN orders ON users.user_id = orders.user_id;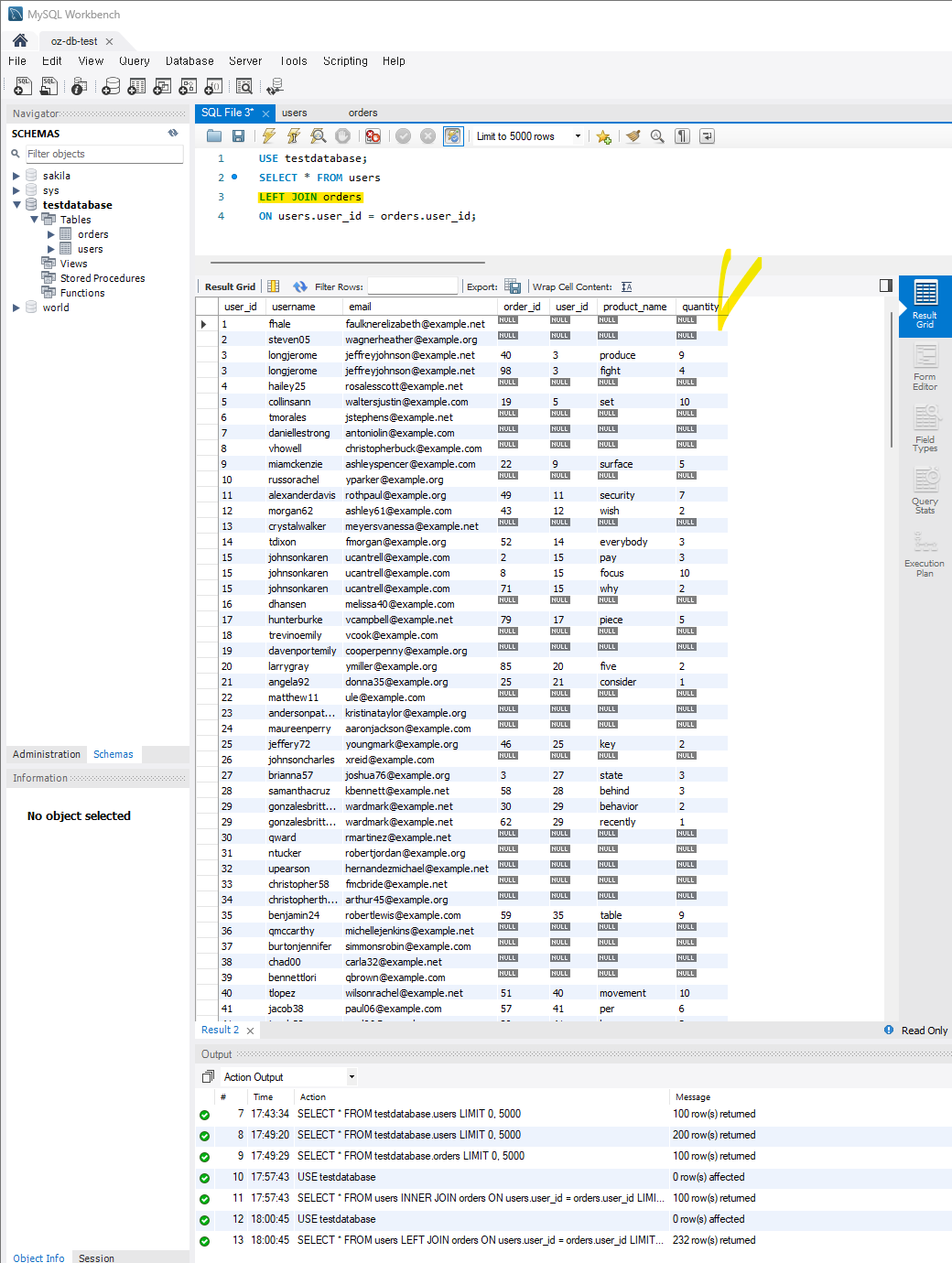
user_id는 다 보여주고 해당 user_id에 맞는 orders 테이블 데이터를 보여준다.
3) RIGHT JOIN (오른쪽 조인)
RIGHT JOIN은 주문 테이블의 모든 행을 포함하고, 사용자 테이블과 매칭되는 경우 해당 사용자 정보를 포함하여 보여준다.
SELECT * FROM users
RIGHT JOIN orders ON users.user_id = orders.user_id;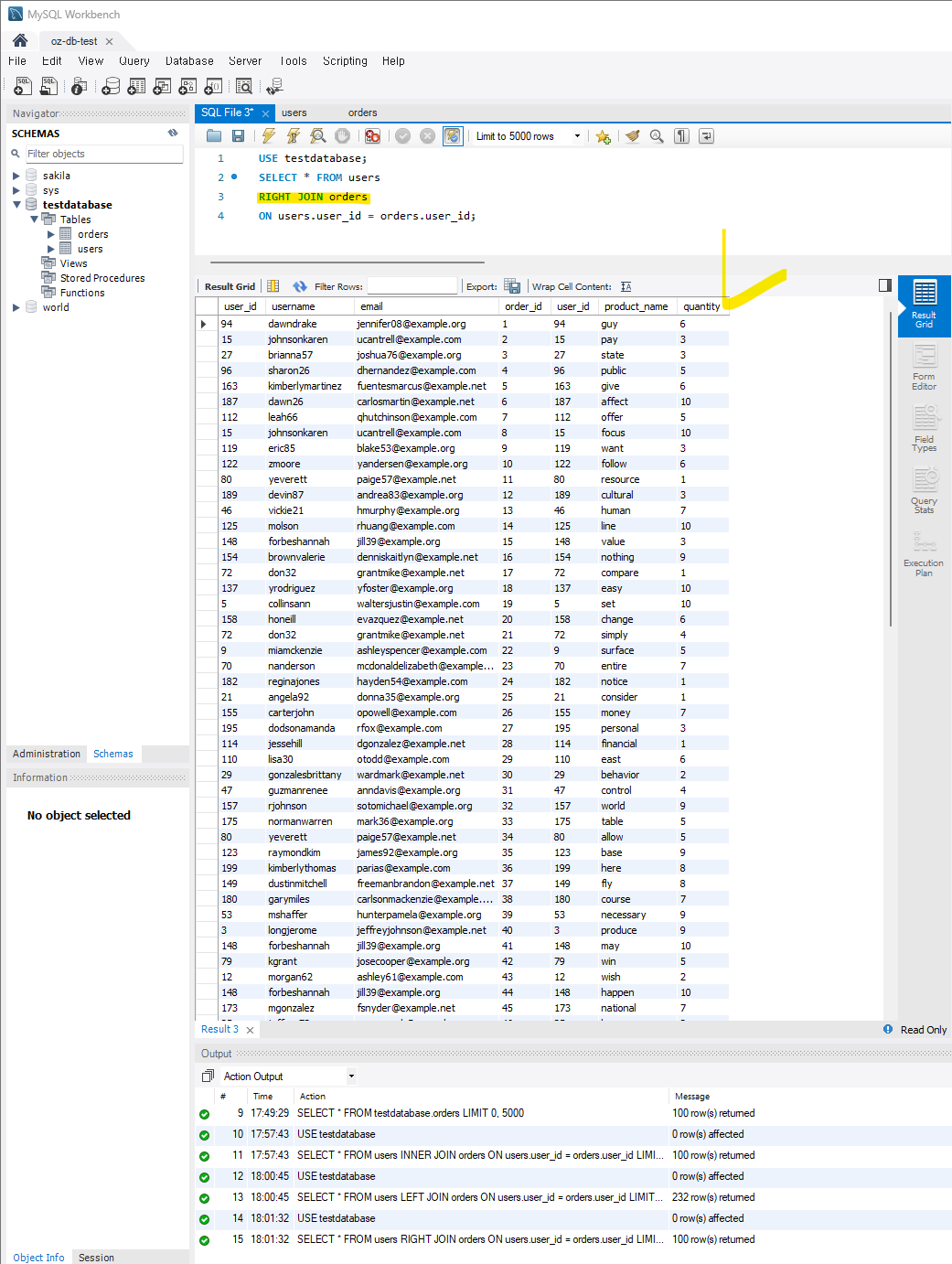
order_id는 다 보여주고 해당하는 users 테이블에 있는 데이터만 보여줬다.
03. 실습 -Ⅰ (간단한 Schema 설계하기)
1) users 테이블 만들기
- id: 자동으로 생성 (PK)
- password: 4자리 랜덤
- name: 한글 3자리
- gender: male, female 중 랜덤 선택
- email: 5자리영문@gmail.com (15자리)
- birthday: 숫자 6자리 랜덤
- age: 숫자 2자리 랜덤
- company: samsung, lg, hyundai 중 랜덤 선택
- 코드
CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, password VARCHAR(4), name VARCHAR(3), gender ENUM('male', 'female'), email VARCHAR(15), birthday CHAR(6), age TINYINT, company ENUM('samsung', 'lg', 'hyundai') ); ENUM(enumeration)
: 이 타입의 필드는 사전에 정의된 문자열 값 목록 중 하나의 값을 가질 수 있다. 이러한 특성 덕분에ENUM은 특정 범위의 값만을 허용해야 하는 경우에 유용하다.
2) boards 테이블 만들기
- id: 자동으로 생성 (PK)
- title: 5글자
- content: 10글자
- likes: 1~100사이 숫자인지 확인
- img: 정해진 값 - “c”
- created: 오늘 날짜
- user_id (foreign_key)
- 코드
CREATE TABLE boards ( id INT AUTO_INCREMENT PRIMARY KEY, title VARCHAR(5), content VARCHAR(10), likes INT CHECK (likes BETWEEN 1 AND 100), img CHAR(1) DEFAULT 'c', created DATE DEFAULT CURRENT_DATE, user_id INT, FOREIGN KEY (user_id) REFERENCES user(id) );
04. 실습 -Ⅱ (MySQL sample database 분석하기)
1. 실습 기본 Setting
MySQL Sample Database 이 링크에서 sample database를 받아서 실습을 진행할 것이다.
사이트에 들어가 파일을 다운 받으면 classicmodels라는 데이터 베이스를 만들고 그 안에 여러 테이블들이 있다는 것을 알 수 있다.
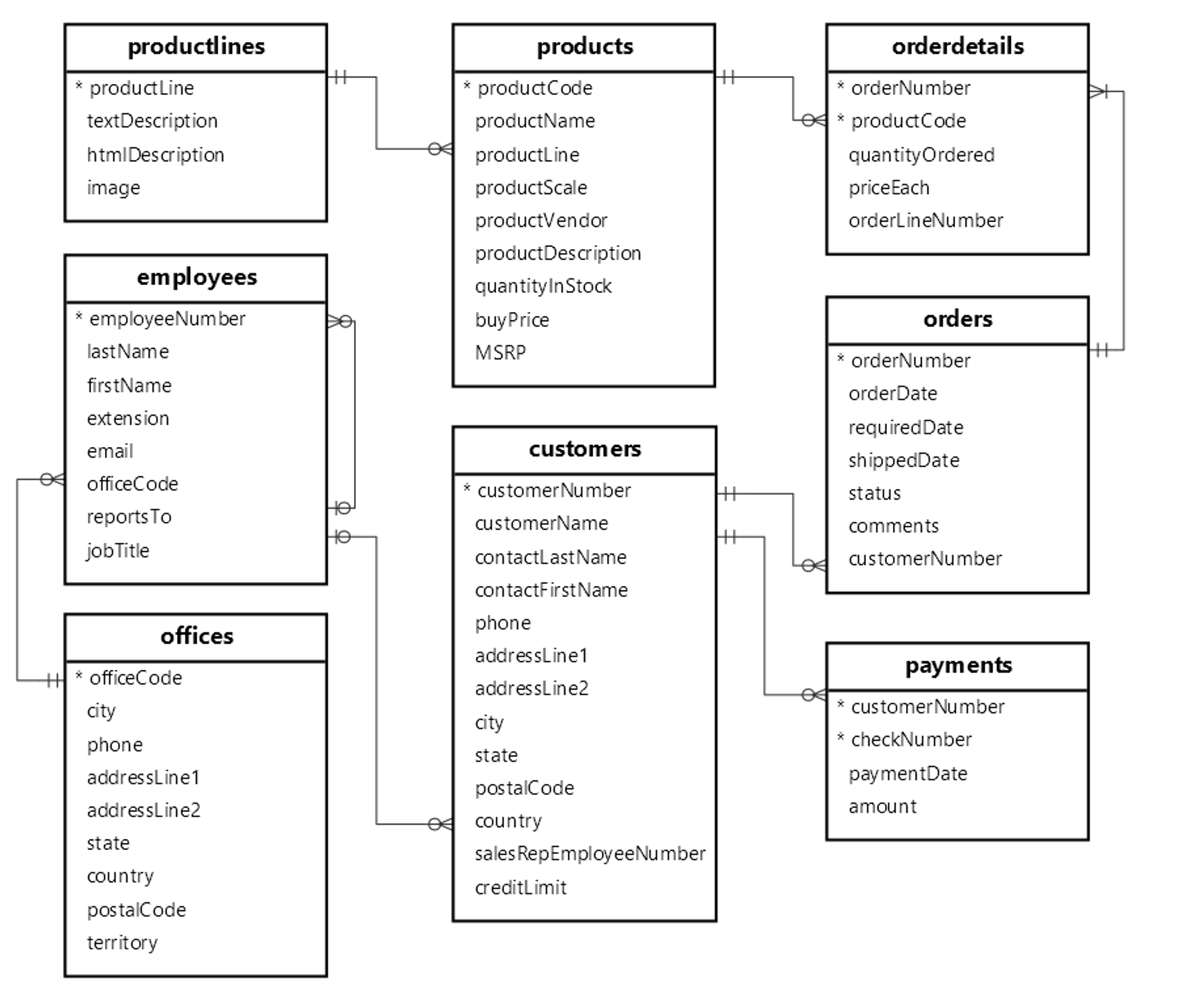
2. 기본 조회 및 필터링
-
고객 목록 조회
: 모든 고객의 이름 조회
(TABLE: customers)SELECT customerName FROM customers;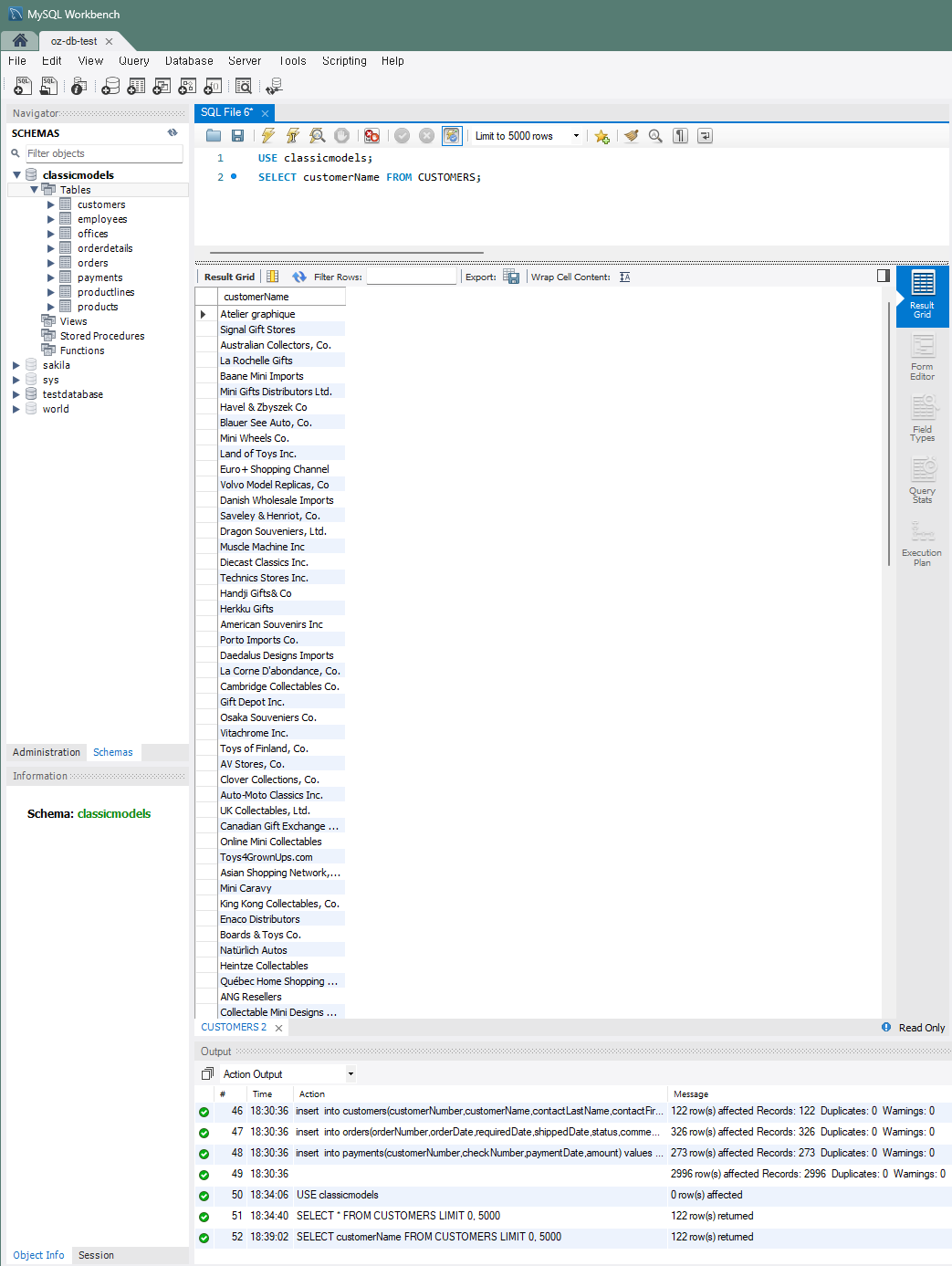
-
특정 제품 라인의 제품 조회
: 'Classic Cars' 제품 라인에 속하는 모든 제품의 이름과 가격을 조회
(TABLE: products, COL: productLine)SELECT * FROM products WHERE productLine = 'Classic Cars';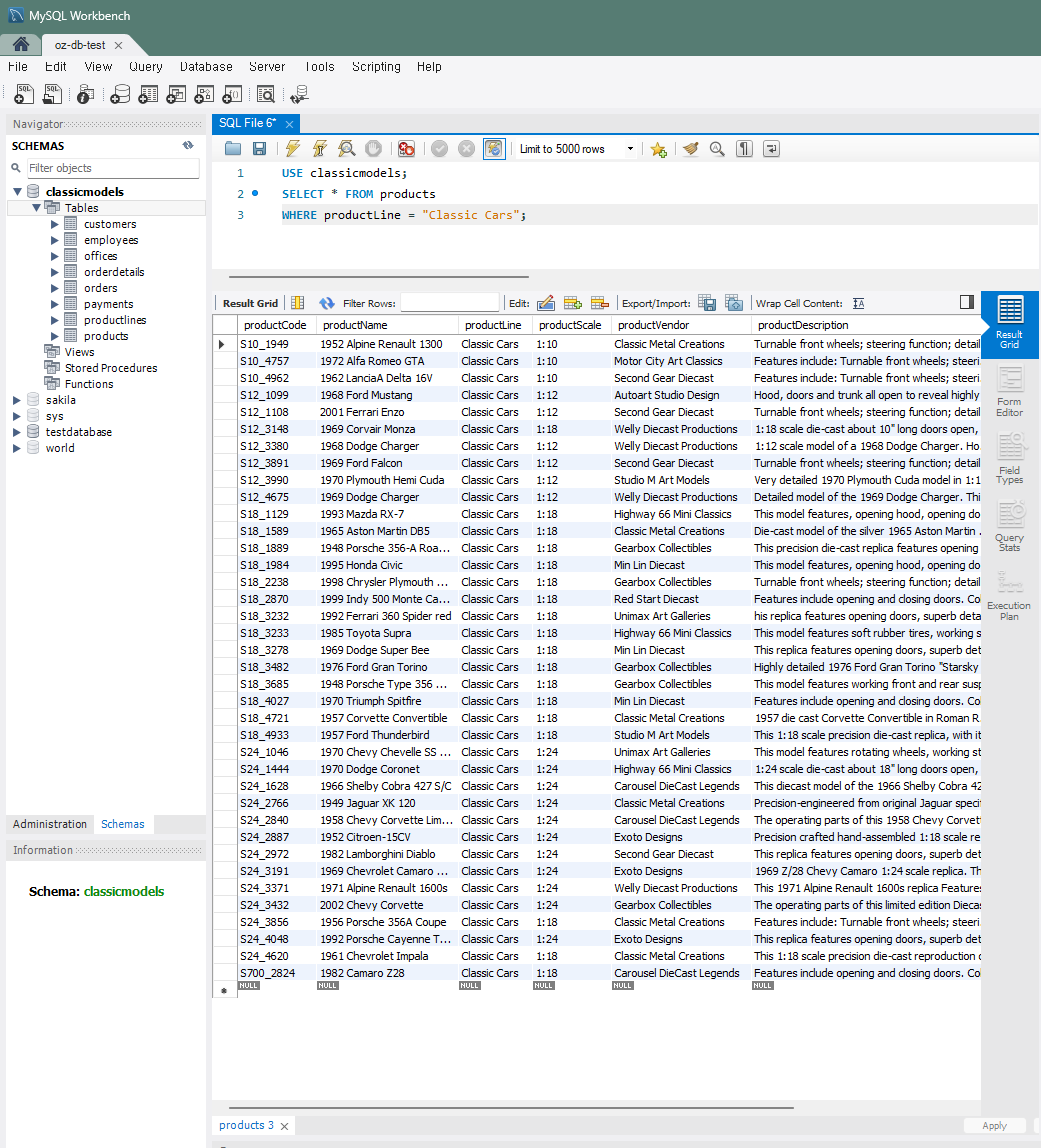
-
최근 주문 조회
: 가장 최근에 주문된 10개의 주문을 주문 날짜(orderDate)와 함께 조회
(TABLE: orders, COL: orderDate)SELECT * FROM orders ORDER BY orderDate DESC LIMIT 10;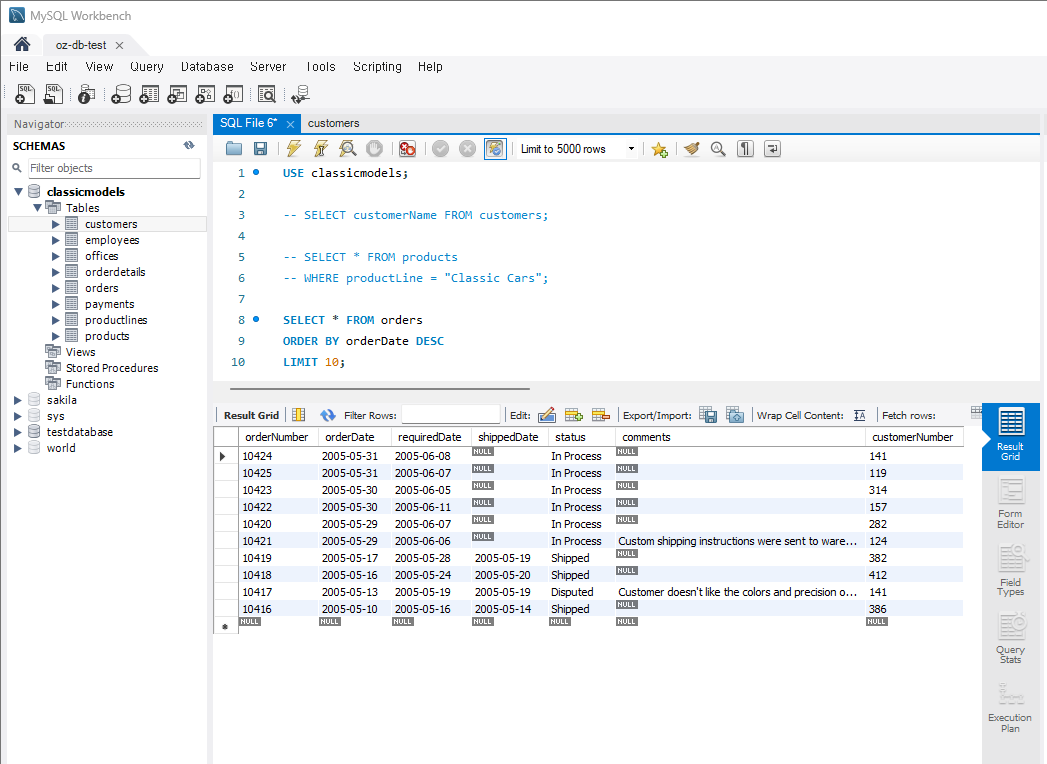
-
최소 금액 이상의 결제 조회
: 100달러 이상 결제된 거래(amount)만 조회
(TABLE: payments, COL: amount)SELECT * FROM payments WHERE amount >= 100;
3. JOIN Query
-
주문과 고객 정보 조합
: 각 주문에 대한 주문 번호(orders-orderNumber)와 주문한 고객(customers-customerName)의 이름을 조회SELECT o.orderNumber, c.customerName FROM orders o JOIN customers c ON o.customerNumber = c.customerNumber;
-
제품과 제품 라인 결합
: 각 제품의 이름(products-productName)과 속한 제품 라인의 설명(productlines-textDescription)을 조회SELECT p.productName, p.productLine, pl.textDescription FROM products p JOIN productlines pl ON p.productLine = pl.productLine;
-
직원과 상사 정보
: 각 직원의 이름(employees-employeeNumber & first name, last name)과 직속 상사(employees-reportsTo & first name, last name)의 이름을 조회SELECT e1.employeeNumber, e1.firstName, e1.lastName, e2.firstName AS 'ManagerFirstName', e2.lastName AS 'ManagerLastName' FROM employees e1 LEFT JOIN employees e2 ON e1.reportsTo = e2.employeeNumber;
-
특정 사무실의 직원 목록
: 'San Francisco' 사무실(offices-officeCode,city(San Francisco))에서 근무하는 모든 직원의 데이터(employees-employeeNumber, lastName, firstName, extension, email, officeCode, reportsTo, jobTitle)을 조회SELECT e.employeeNumber, e.lastName, e.firstName, e.extension, e.email, e.officeCode, e.reportsTo, e.jobTitle FROM employees e JOIN offices o ON e.officeCode = o.officeCode WHERE o.city = 'San Francisco';
4. GROUP Query
-
제품 라인별 제품 수
: 각 제품 라인(products-productLine)에 속한 제품의 수(COUNT)를 조회SELECT productLine, COUNT(*) AS productCount FROM products GROUP BY productLine;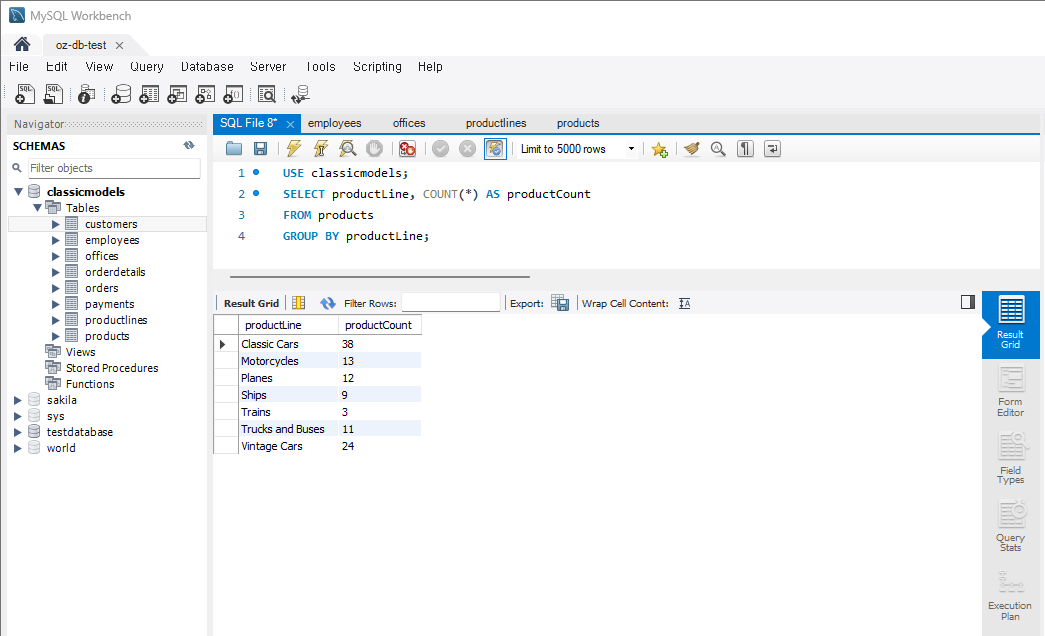
-
고객별 총 주문 금액
: 각 고객별(customers-customerNumber, customerName)로 총 주문 금액을 계산(orderdetails-quantityOrdered, priceEach)SELECT customers.customerNumber, customers.customerName, SUM(orderdetails.quantityOrdered * orderdetails.priceEach) AS totalAmount FROM customers JOIN orders ON customers.customerNumber = orders.customerNumber JOIN orderdetails ON orders.orderNumber = orderdetails.orderNumber GROUP BY customers.customerNumber, customers.customerName; ORDER BY totalAmount DESC;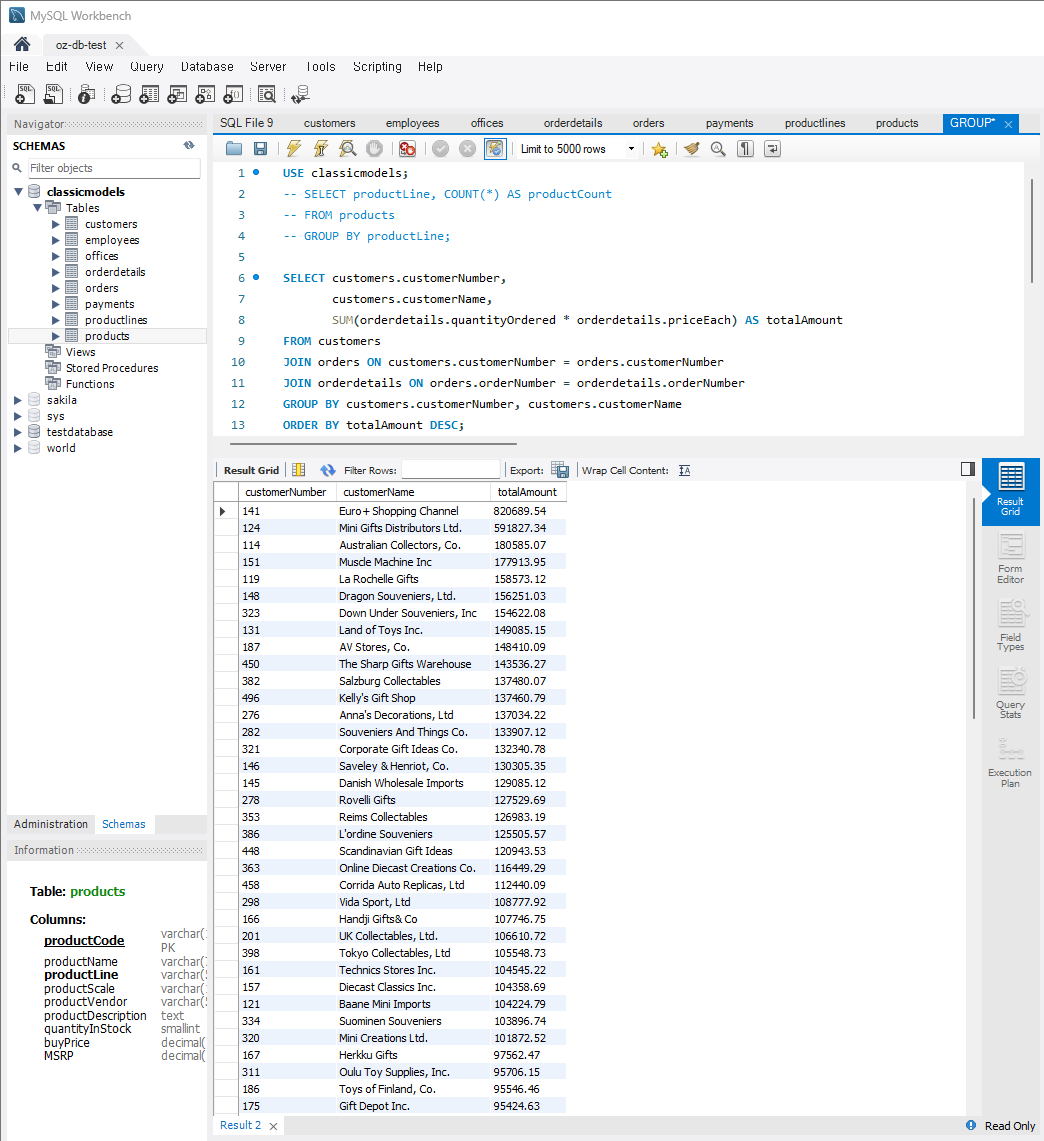
-
가장 많이 팔린 제품
: 가장 많이 판매된 제품(totalQuantity DESC LIMIT 1)의 이름과 판매 수량(products-productName/orderdetails-quantityOrdered)을 조회SELECT productName, SUM(quantityOrdered) AS totalQuantity FROM orderdetails od JOIN products p ON od.productCode = p.productCode GROUP BY productName ORDER BY totalQuantity DESC LIMIT 1;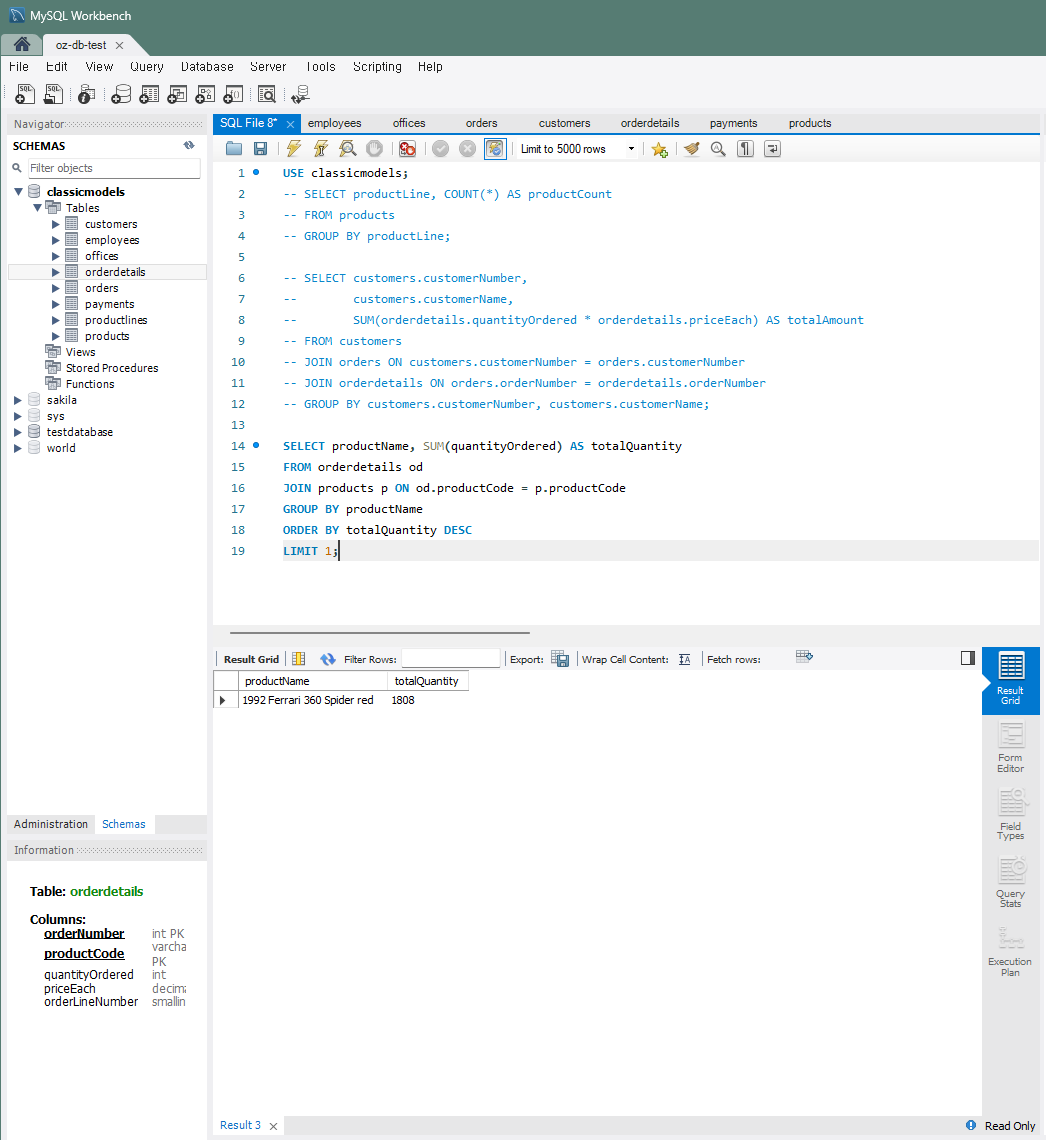
-
매출이 가장 높은 사무실
: 가장 많은 매출(totalSales DESC LIMIT 1)을 기록한 사무실의 위치(offices-officeCode)와 매출액(orderdetails-quantityOrdered/orders-priceEach)을 조회SELECT o.city, SUM(od.quantityOrdered * od.priceEach) AS totalSales FROM orders ord JOIN orderdetails od ON ord.orderNumber = od.orderNumber JOIN customers c ON ord.customerNumber = c.customerNumber JOIN employees e ON c.salesRepEmployeeNumber = e.employeeNumber JOIN offices o ON e.officeCode = o.officeCode GROUP BY o.city ORDER BY totalSales DESC LIMIT 1;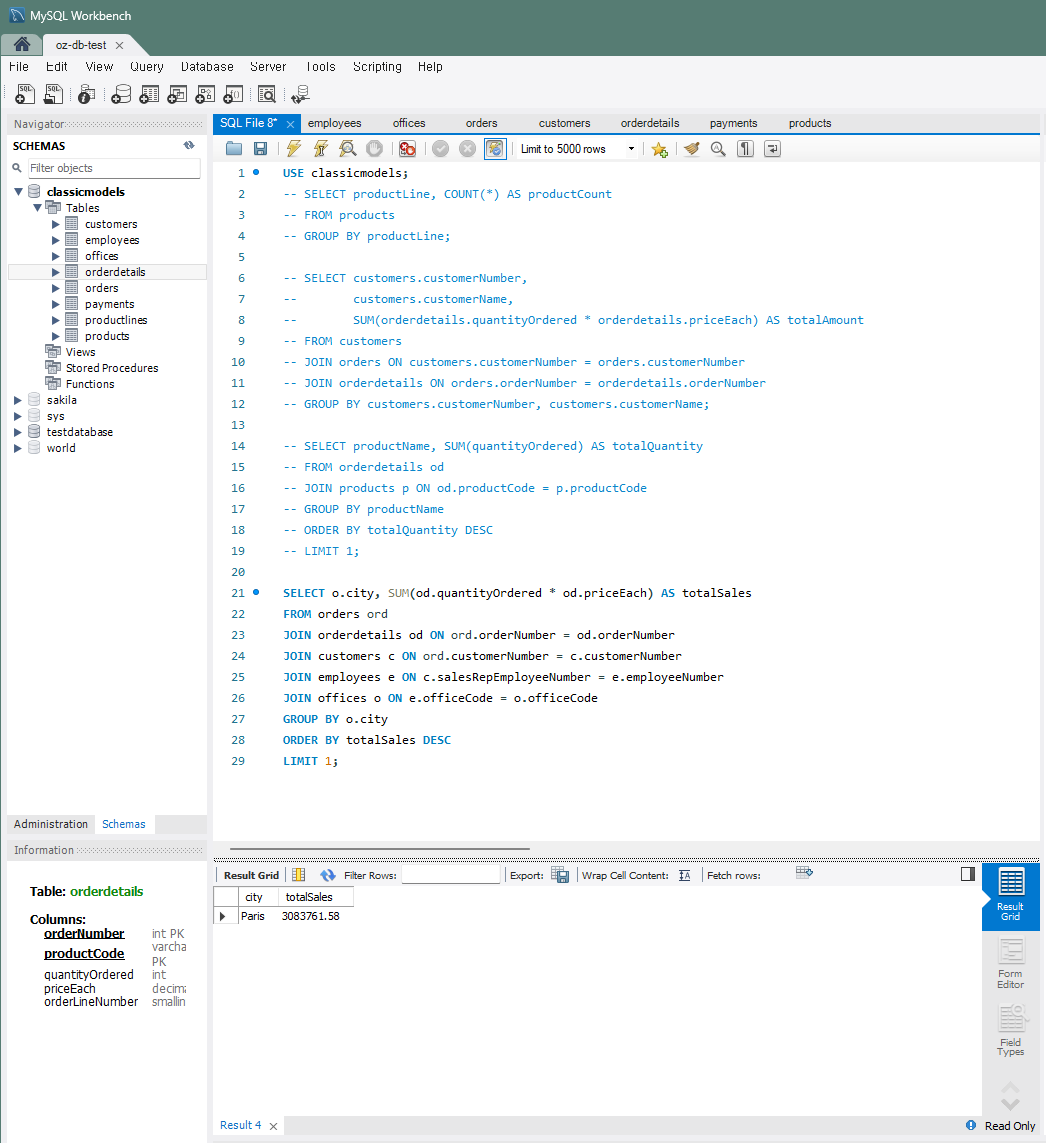
5. Sub Query
-
특정 금액 이상의 주문
: 500달러 이상의 총 주문 금액을 기록한 주문들을 조회SELECT orderNumber, SUM(quantityOrdered * priceEach) AS totalAmount FROM orderdetails GROUP BY orderNumber HAVING totalAmount > 500; -- GROUP BY 로 묶여 있을 때 WHERE보다 HAVING으로 원하는 조건의 데이터 찾을 수 있다.
-
평균 이상 결제 고객
: 평균 결제 금액보다 많은 금액을 결제한 고객들의 목록을 조회SELECT customerNumber, SUM(amount) AS totalPayment FROM payments GROUP BY customerNumber HAVING totalPayment > (SELECT AVG(amount) FROM payments) ORDER BY totalPayment DESC;
-
주문 없는 고객
: 아직 주문을 하지 않은 고객의 목록을 조회SELECT customerName FROM customers WHERE customerNumber NOT IN (SELECT customerNumber FROM orders);
-
최대 매출 고객
: 가장 많은 금액을 지불한 고객의 이름과 총 결제 금액을 조회SELECT c.customerName, SUM(od.quantityOrdered * od.priceEach) AS totalSpent FROM customers c JOIN orders o ON c.customerNumber = o.customerNumber JOIN orderdetails od ON o.orderNumber = od.orderNumber GROUP BY c.customerName ORDER BY totalSpent DESC LIMIT 1;
6. 데이터 수정 및 관리
-
신규 고객 추가
: 'customers' 테이블에 새로운 고객을 추가하는 쿼리를 작성INSERT INTO customers (customerName, contactLastName, contactFirstName, phone, addressLine1, addressLine2, city, state, postalCode, country, salesRepEmployeeNumber, creditLimit) VALUES ('New Customer', 'Lastname', 'Firstname', '123-456-7890', '123 Street', 'Suite 1', 'City', 'State', 'PostalCode', 'Country', 1002, 50000.00);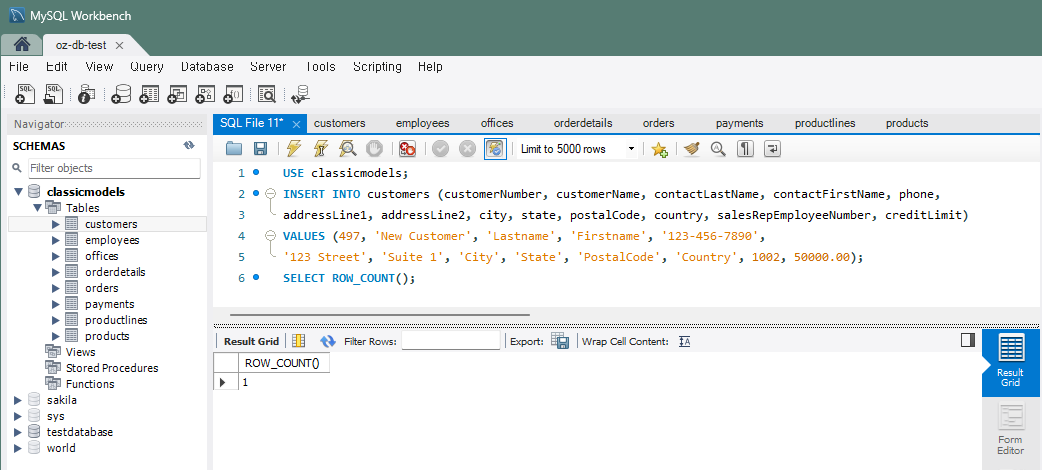
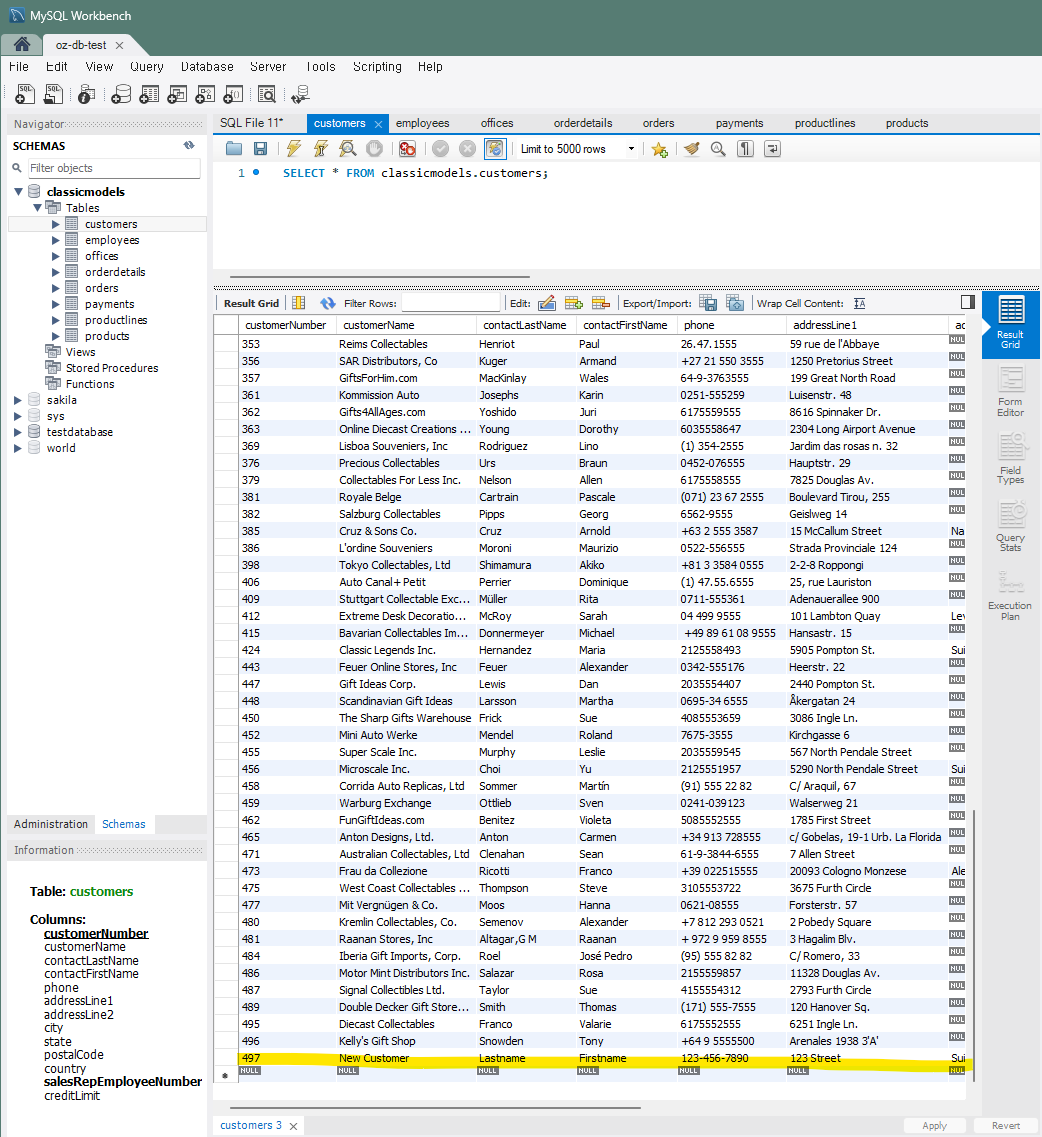
-
제품 가격 변경
: 'Classic Cars' 제품 라인의 모든 제품 가격을 10% 인상하는 쿼리를 작성UPDATE products SET buyPrice = buyPrice * 1.10 WHERE productLine = 'Classic Cars'; -
고객 데이터 업데이트
: 특정 고객의 이메일 주소를 변경하는 쿼리를 작성UPDATE customers SET email = 'newemail@example.com' WHERE customerNumber = 103; -
직원 전보
: 특정 직원을 다른 사무실로 이동시키는 쿼리를 작성UPDATE employees SET officeCode = '2' WHERE employeeNumber = 1002;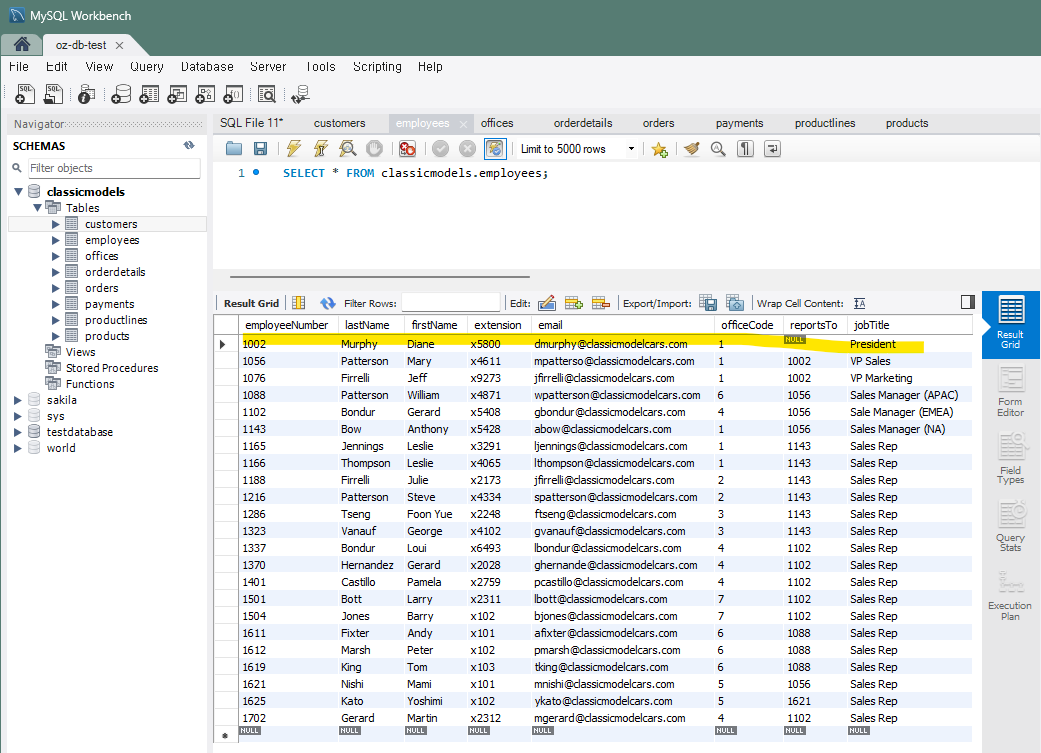
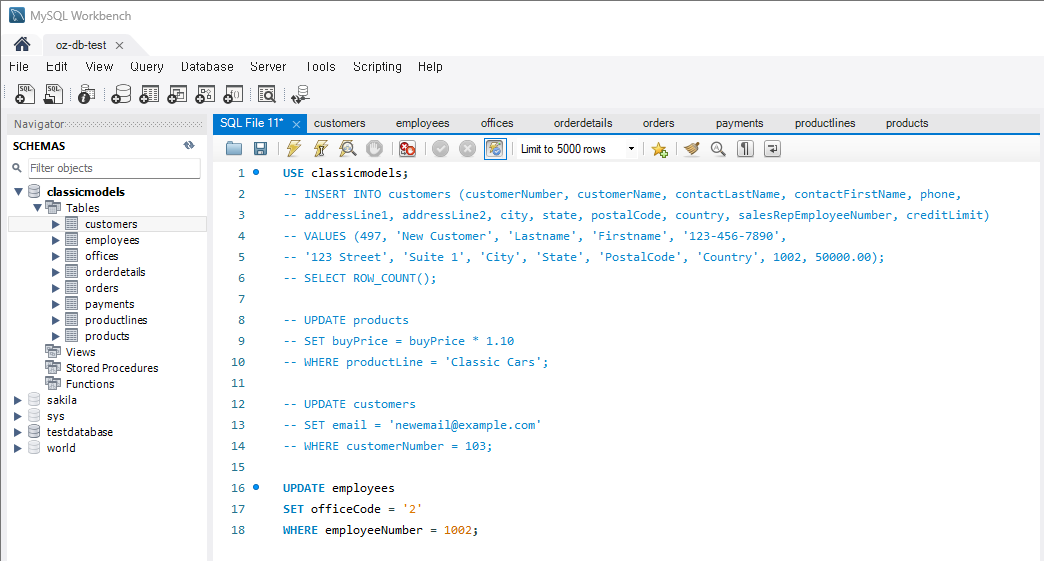
05. ERD 프로그램
1. ERD (Entity Relationship Diagram) 프로그램
ERD (Entity Relationship Diagram) 프로그램이란 DB 구조를 한분에 볼 수 있도록 만든 프로그램이다.
ERD 프로그램은 데이터베이스의 구조를 시각적으로 표현하는 도구다. 이러한 프로그램들은 데이터베이스의 테이블, 열, 관계 등을 그래픽으로 나타내어 복잡한 데이터 구조를 쉽게 이해하고 설계할 수 있게 도와준다. 대표적인 ERD 프로그램으로는 다음과 같은 것들이 있다.
-
Aquery
: 웹 기반의 ERD프로그램으로 테이블 제한이 있지만 사용 방법이 쉽고 UI가 간편하다는 장점이 있다. -
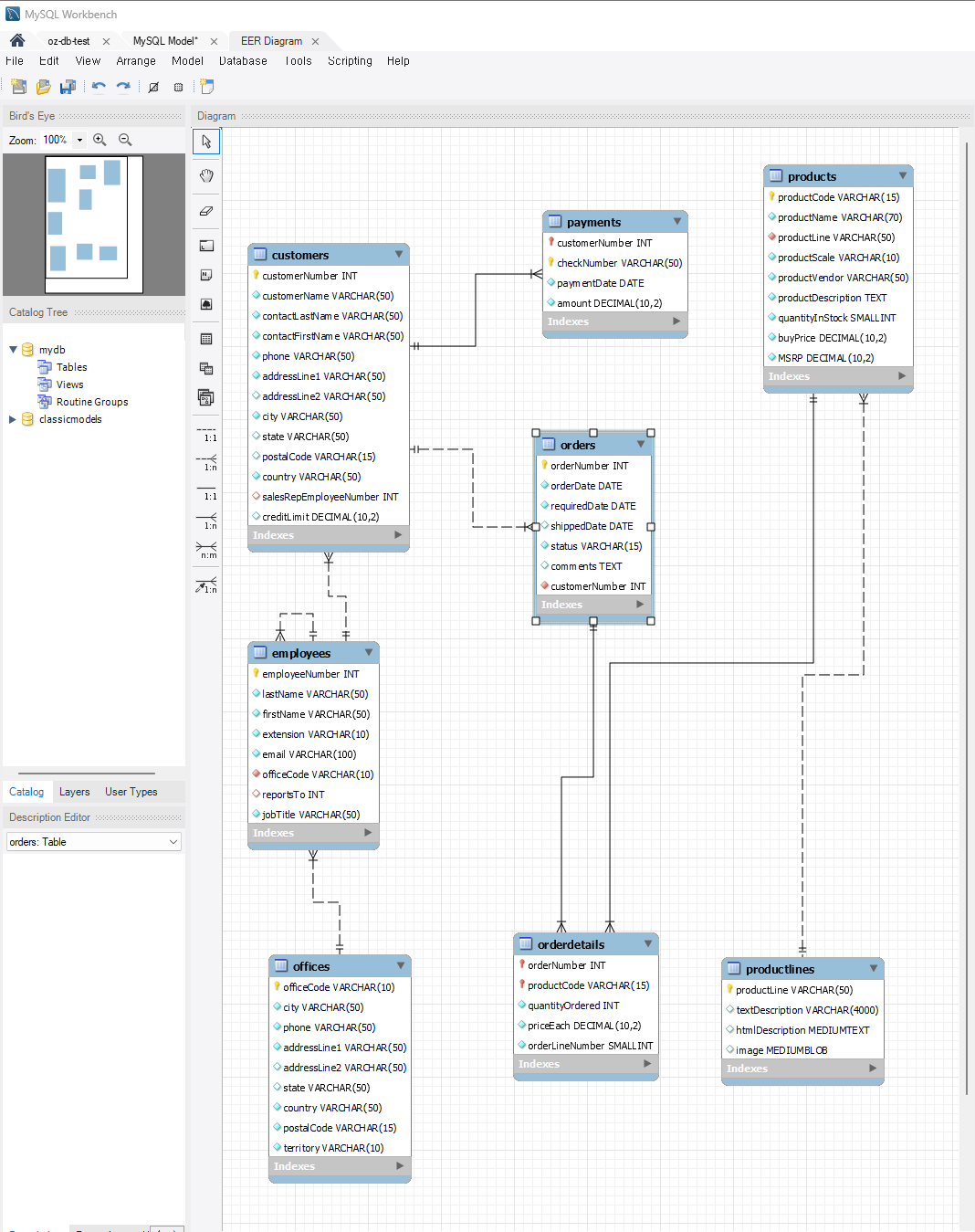
MySQL Workbench
: MySQL 데이터베이스용 ERD를 설계, 생성 및 관리할 수 있는 통합 도구다. 각 컬럼간의 연결 관계를 한눈에 볼 수 있게 할 수 있다.
-
Draw.io (현재는 diagrams.net)
: 무료 온라인 다이어그램 도구로, 기본적인 ERD를 손쉽게 그릴 수 있다.
2. ERD 연습
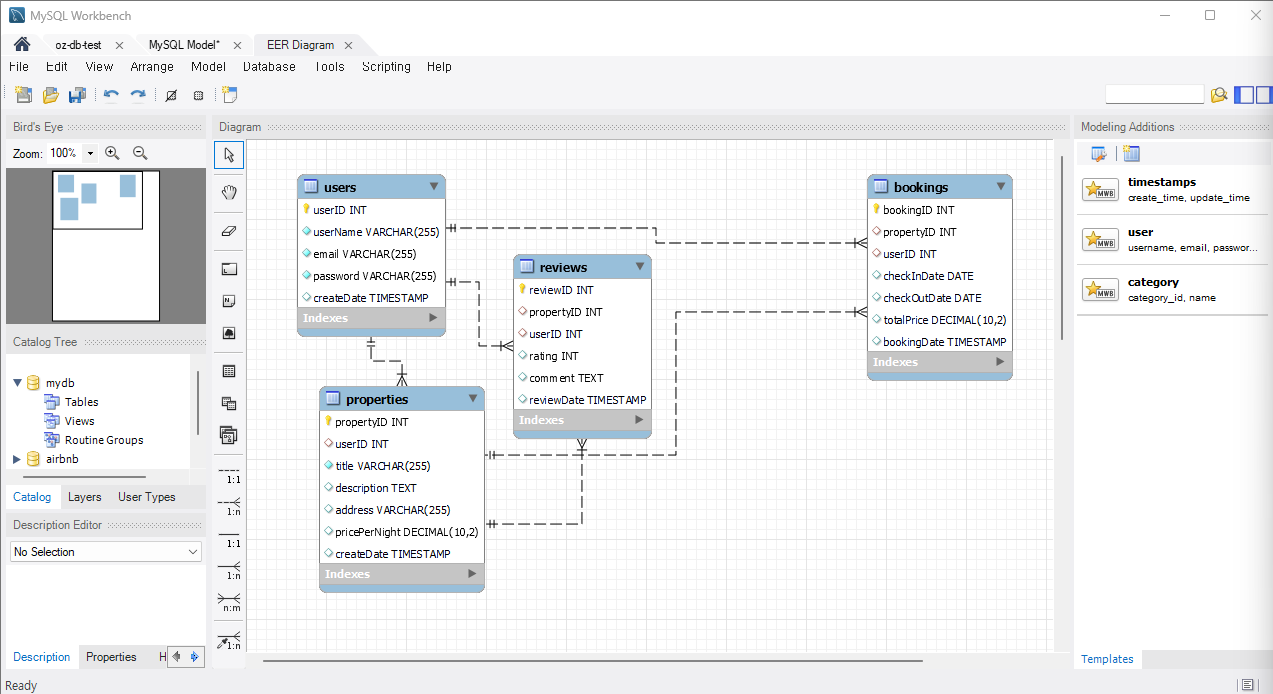
AirBnb 데이터베이스 따라하기
1. 테이블 정보
- Users: 사용자 정보를 저장
- Properties: 숙소 정보를 저장
- Bookings: 예약 정보를 저장
- Reviews: 사용자에 의한 숙소 리뷰를 저장
- Messages: 사용자 간의 메시지를 저장
2. ERD 설계
- Users와 Properties는 서로 관계가 있으며, 한 사용자가 여러 숙소를 등록할 수 있다.
- Users와 Bookings는 서로 관계가 있으며, 한 사용자가 여러 예약을 할 수 있다.
- Properties와 Bookings는 서로 관계가 있으며, 한 숙소에 여러 예약이 있을 수 있다.
- Properties와 Reviews는 서로 관계가 있으며, 한 숙소에 여러 리뷰가 있을 수 있다.
- Users와 Messages는 서로 관계가 있으며, 사용자 간에 여러 메시지가 오갈 수 있다.
3. 테이블 생성 Query
CREATE TABLE Users (
userID INT AUTO_INCREMENT PRIMARY KEY,
userName VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE,
password VARCHAR(255) NOT NULL,
createDate TIMESTAMP
);
CREATE TABLE Properties (
propertyID INT AUTO_INCREMENT PRIMARY KEY,
userID INT,
title VARCHAR(255) NOT NULL,
description TEXT,
address VARCHAR(255),
pricePerNight DECIMAL(10, 2),
createDate TIMESTAMP,
FOREIGN KEY (userID) REFERENCES Users(userID)
);
CREATE TABLE Bookings (
bookingID INT AUTO_INCREMENT PRIMARY KEY,
propertyID INT,
userID INT,
checkInDate DATE,
checkOutDate DATE,
totalPrice DECIMAL(10, 2),
bookingDate TIMESTAMP,
FOREIGN KEY (propertyID) REFERENCES Properties(propertyID),
FOREIGN KEY (userID) REFERENCES Users(userID)
);
CREATE TABLE Reviews (
reviewID INT AUTO_INCREMENT PRIMARY KEY,
propertyID INT,
userID INT,
rating INT,
comment TEXT,
reviewDate TIMESTAMP,
FOREIGN KEY (propertyID) REFERENCES Properties(propertyID),
FOREIGN KEY (userID) REFERENCES Users(userID)
);
CREATE TABLE Messages (
messageID INT AUTO_INCREMENT PRIMARY KEY,
senderID INT,
receiverID INT,
messageText TEXT,
sendDate TIMESTAMP,
FOREIGN KEY (senderID) REFERENCES Users(userID),
FOREIGN KEY (receiverID) REFERENCES Users(userID)
);테이블 작업 이후, MySQL Workbench로 reverse engineering 작업해준다.
[DB 2일차 후기]
뭔가 휘몰아친 느낌...
JavaScript를 처음 배웠을 때와 비슷한 느낌이다... ㅎㅎ
강의와 과제의 늪에 다시 빠지고 있는 느낌이다 ㅎㅎㅎ
더 열심히 해야겠다!!
[참고자료]
- [오즈스쿨 스타트업 웹 개발 초격차캠프 백엔드 데이터베이스 강의]
