
3일차에서는 MySQL 여러 예시를 이용해서 SELECT, UPDATE, GROUP, JOIN 등 다양한 Query를 해보았다. 추가적인 연습을 해보려고 한다.
각 문제는 초급 10문제, 중급 10문제, 고급 5문제로 25문제이다.
(종류는 4개로 총 100문제!!)
00. MySQL 추가 연습
1. 생성 Query - INSERT
<초급>
문제 1) customers 테이블에 새 고객을 추가
INSERT INTO customers (customerNumber, customerName, phone, addressLine1, city, postalCode, country)
VALUES (500, 'John Doe', '+82 123 4567', '123 Main St', 'Seoul', '12345', 'Korea'); 
문제 2) products 테이블에 새 제품을 추가
INSERT INTO products (productCode, productName, productLine, productScale, productVendor, productDescription, quantityInStock, buyPrice, MSRP)
VALUES ('S10_1500', 'Toy Car', 'Classic Cars', '1:100', 'Autoart Studio Design', 'example', 100, '19.99', 100); 
문제 3) employees 테이블에 새 직원을 추가
INSERT INTO employees (employeeNumber, lastName, firstName, extension, email, officeCode, jobTitle)
VALUES (2425, 'Johnson', 'Alice', 1500, 'example@email.com', 5, 'Sales Rep'); 
문제 4) offices 테이블에 새 사무실을 추가
INSERT INTO offices (officeCode, city, phone, addressLine1, country, postalCode, territory)
VALUES (8, 'Seoul', '+82 02 123 4567', '123 Main Park St', 'Korea', 12345, 'S.Korea'); 
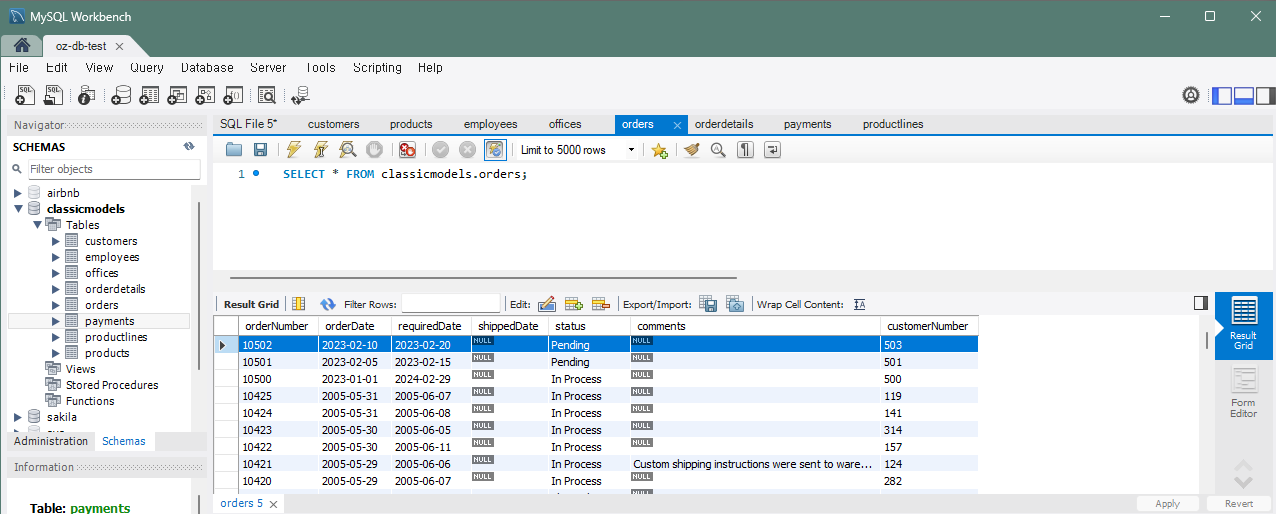
문제 5) orders 테이블에 새 주문을 추가
INSERT INTO orders (orderNumber, orderDate, requiredDate, status, customerNumber)
VALUES (10500, '2023-01-01', '2024-02-29', 'In Process', 500); 
문제 6) orderdetails 테이블에 주문 상세 정보를 추가
INSERT INTO orderdetails (orderNumber, productCode, quantityOrdered, priceEach, orderLineNumber)
VALUES (10500, 'S10_1500', 5, 20.00, 13); 
문제 7) payments 테이블에 지불 정보를 추가
INSERT INTO payments (customerNumber, checkNumber, paymentDate, amount)
VALUES (500, 'MJ240205', '2023-01-01', 178); 
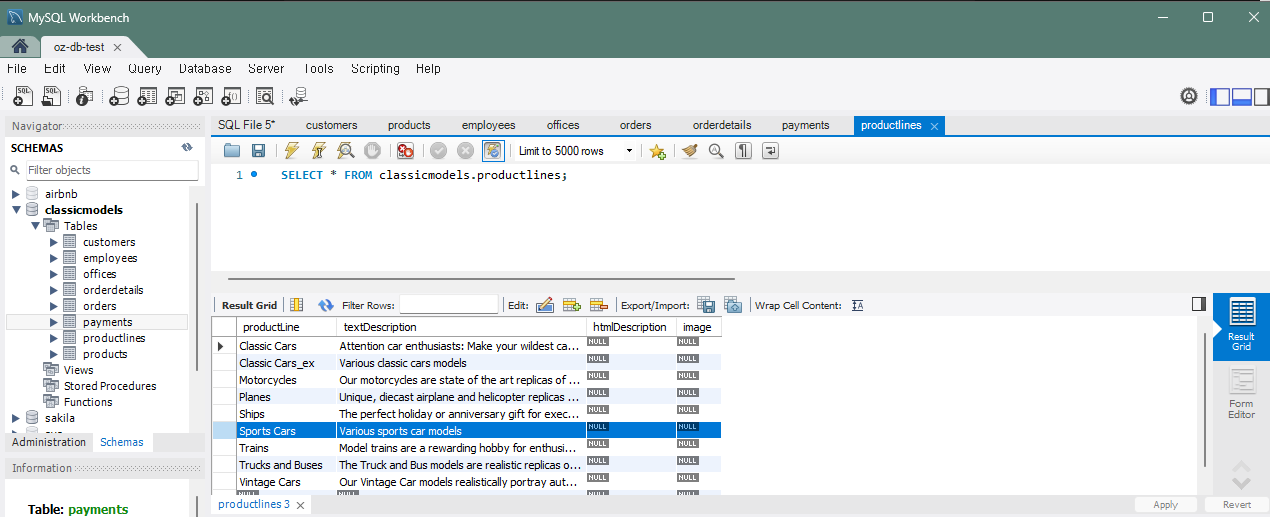
문제 8) productlines 테이블에 제품 라인을 추가
INSERT INTO productlines (productLine, textDescription)
VALUES ('Classic Cars_ex', 'Various classic cars models'); 
문제 9) customers 테이블에 다른 지역의 고객을 추가
INSERT INTO customers (customerNumber, customerName, phone, addressLine1, city, postalCode, country)
VALUES (499, 'Jane Smith', '2125551512', '456 Elm St', 'NYC', 'NY', 10030, 'USA'); 
문제 10) products 테이블에 다른 카테고리의 제품을 추가
INSERT INTO products (productCode, productName, productLine, productScale, productVendor, productDescription, quantityInStock, buyPrice, MSRP)
VALUES ('S10_1501', 'Vintage Train', 'Trains', '1:50', 'Classic Metal Creations', 'Miniature Train', 135, 34.99, 168.6); 
<중급>
문제 1) customers 테이블에 여러 고객을 한 번에 추가
INSERT INTO customers (customerNumber, customerName, phone, addressLine1, city, postalCode, country)
VALUES (501, 'Jane Smith', '987-654-3210', '456 Elm Street', 'Los Angeles', '90001', 'USA'),
(502, 'Michael Johnson', '555-123-4567', '789 Oak Avenue', 'Chicago', '60601', 'USA'); 
문제 2) products 테이블에 여러 제품을 한 번에 추가
INSERT INTO products (productCode, productName, productLine, productScale, productVendor, productDescription, quantityInStock, buyPrice, MSRP)
VALUES ('S10_1510', 'Model Ship', 'Classic Cars', '1:18', 'Ships', 'Detailed replica of a ship', 50, 99.99, 149.99),
('S10_1515', 'Vintage Motorcycle', 'Motorcycles', '1:24', 'Exoto Designs', 'Miniature replica of a vintage motorcycle', 30, 49.99, 79.99); 
문제 3) employees 테이블에 여러 직원을 한 번에 추가
INSERT INTO employees (employeeNumber, lastName, firstName, extension, email, officeCode, jobTitle)
VALUES (1801, 'Smith', 'John', 1234, 'john.smith@email.com', 1, 'Manager'),
(1802, 'Johnson', 'Emma', 2345, 'emma.johnson@email.com', 2, 'Sales Rep'); 
문제 4) orders와 orderdetails에 연결된 주문을 한 번에 추가
INSERT INTO orders (orderNumber, orderDate, requiredDate, status, customerNumber)
VALUES (10501, '2023-02-05', '2023-02-15', 'Pending', 501);
INSERT INTO orderdetails (orderNumber, productCode, quantityOrdered, priceEach, orderLineNumber)
VALUES (10501, 'S18_3232', 2, 99.99, 1),
(10501, 'S24_5678', 3, 49.99, 2); 
문제 5)payments 테이블에 여러 지불 정보를 한 번에 추가
INSERT INTO payments (customerNumber, checkNumber, paymentDate, amount)
VALUES (501, 'CK240206', '2023-02-02', 250.99),
(501, 'CK240207', '2023-02-03', 150.50); 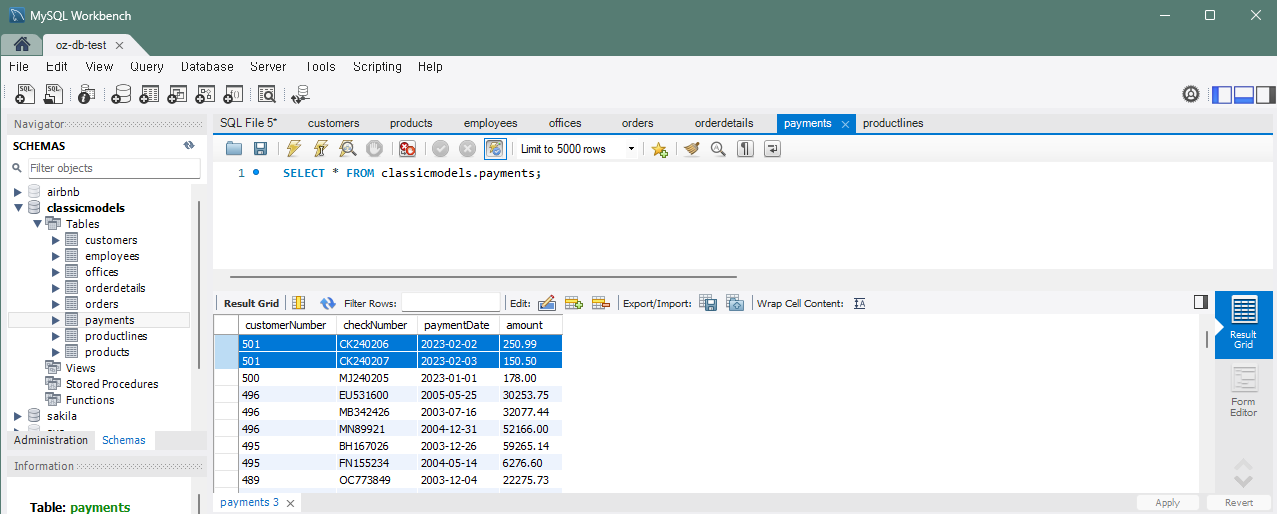
문제 6) customers 테이블에 고객을 추가하고 바로 주문을 추가
INSERT INTO customers (customerNumber, customerName, phone, addressLine1, city, postalCode, country)
VALUES (503, 'XYZ Corp', '987-654-3210', '123 Main Street', 'Seoul', '12345', 'Korea');
INSERT INTO orders (orderNumber, orderDate, requiredDate, status, customerNumber)
VALUES (10502, '2023-02-10', '2023-02-20', 'Pending', 503); 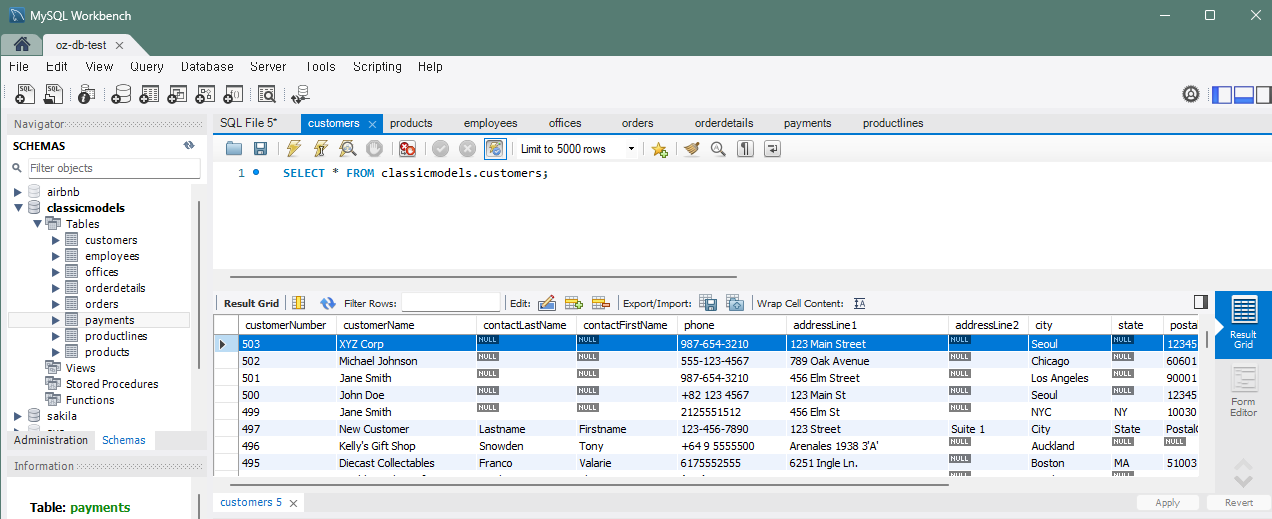
문제 7) employees 테이블에 직원을 추가하고 바로 직급을 할당
INSERT INTO employees (firstName, lastName, ...)
VALUES (1803, 'Smith', 'John', 'x1234', 'jsmith@example.com', 1, 'Sales Rep');
UPDATE employees SET jobTitle = 'Manager'
WHERE employeeNumber = LAST_INSERT_ID(); 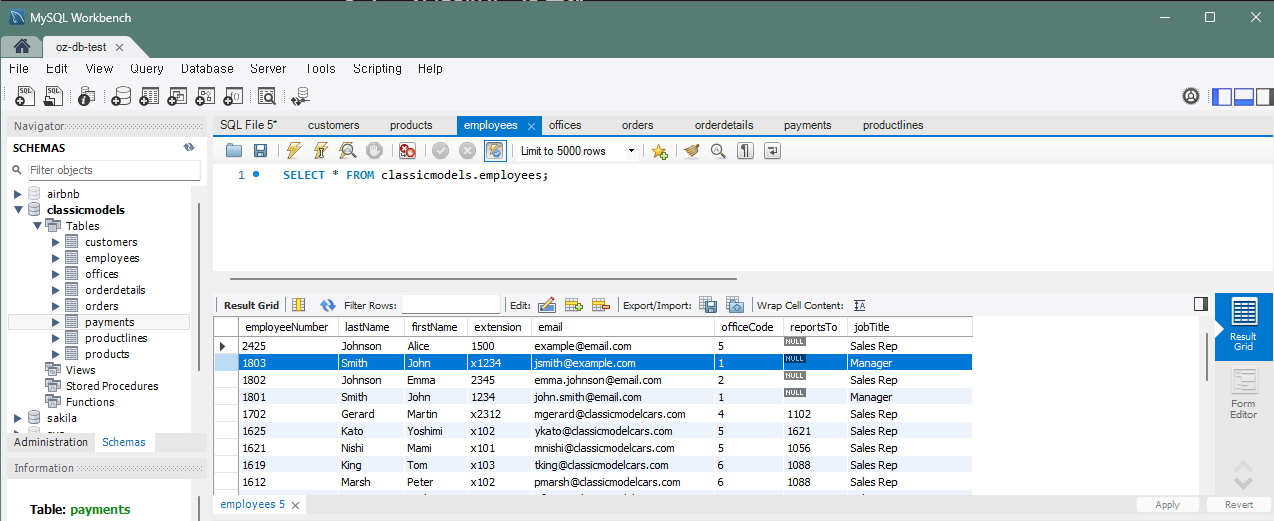
문제 8) products 테이블에 제품을 추가하고 바로 재고를 업데이트
INSERT INTO products (productCode, productName, productLine, productScale, productVendor, productDescription, quantityInStock, buyPrice, MSRP)
VALUES ('S10_1520', 'Vintage Wood Rocking Horse', 'Vintage Cars', '1:10', 'Red Start Diecast', 'Hand crafted wooden toy', 50.00, 100.00);
UPDATE products SET quantityInStock = 30 WHERE productCode = LAST_INSERT_ID(); 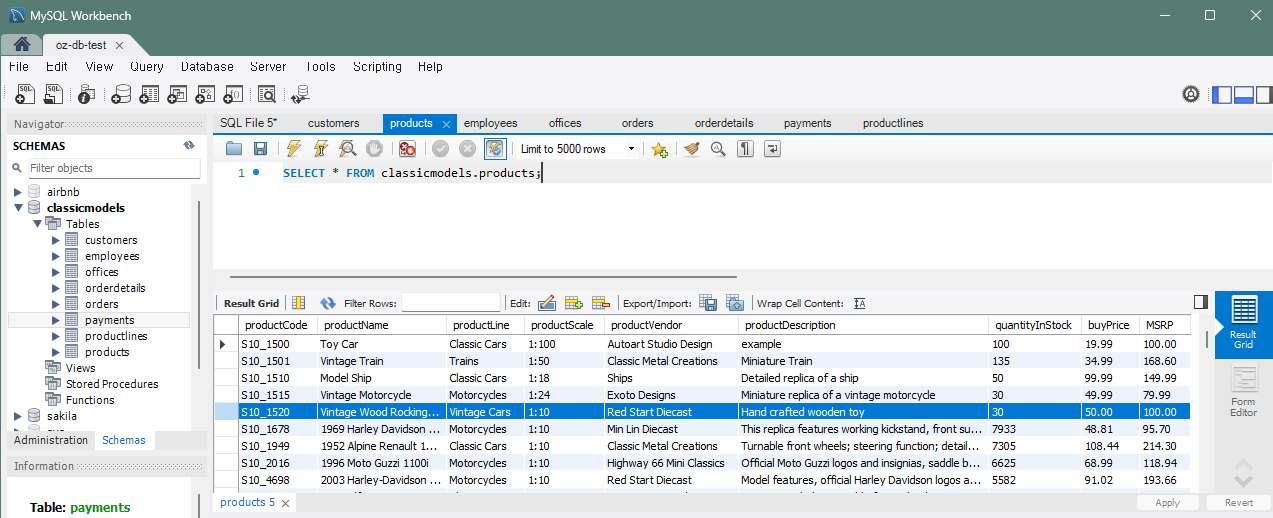
문제 9) offices 테이블에 새 사무실을 추가하고 바로 직원을 할당
INSERT INTO offices (officeCode, city, phone, addressLine1, country, postalCode, territory)
VALUES (9, 'Berlin', '+49 30 12345678', '123 Hauptstrasse', 'Germany', 54321, 'EMEA');
UPDATE employees SET officeCode = LAST_INSERT_ID()
WHERE lastName = 'Smith'; 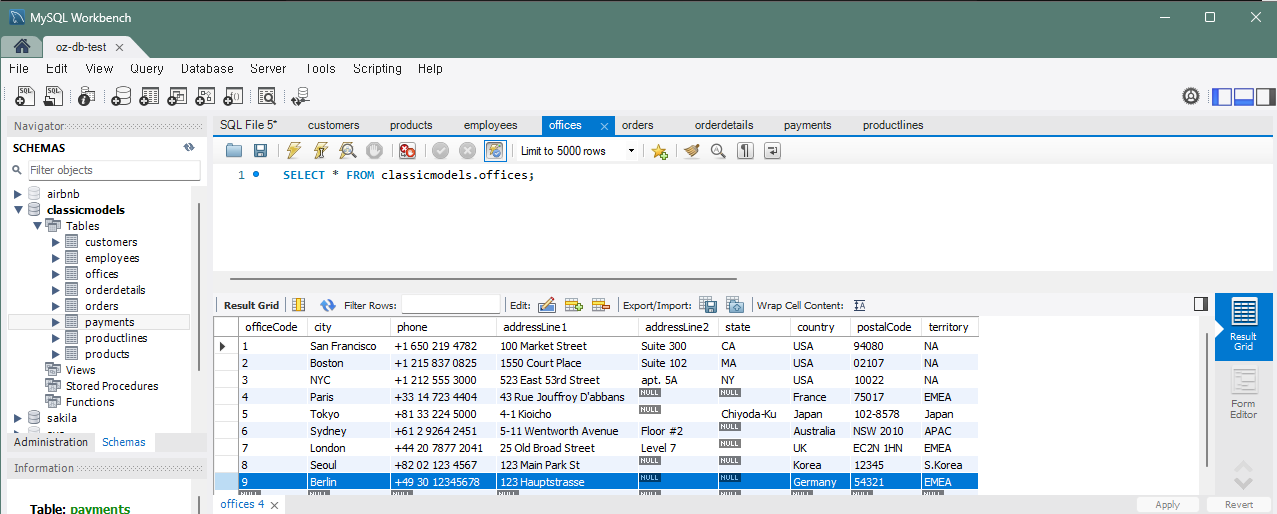
문제 10) productlines 테이블에 제품 라인을 추가하고 바로 여러 제품을 추가
INSERT INTO productlines (productLine, textDescription)
VALUES ('Sports Cars', 'Various sports car models');
INSERT INTO products (productCode, productName, productLine, productScale, productVendor, productDescription, quantityInStock, buyPrice, MSRP)
VALUES ('S10_1530', 'Porsche 911', 'Sports Cars', '1:18', 'Exquisite Cars', '1:18 scale diecast model of a Porsche 911', 50, 79.99, 99.99),
('S10_1531', 'Ferrari 488', 'Sports Cars', '1:18', 'Exquisite Cars', '1:18 scale diecast model of a Ferrari 488', 40, 89.99, 119.99); 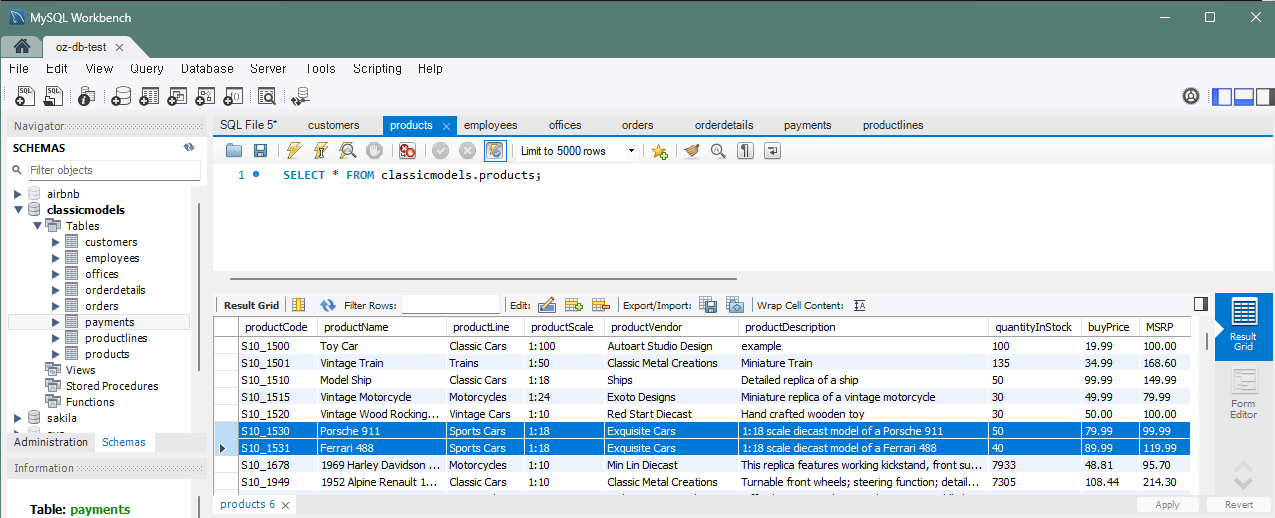
<고급>
문제 1) customers 테이블에 새 고객을 추가하고 바로 주문을 추가
INSERT INTO customers (customerNumber, customerName, phone, addressLine1, city, postalCode, country)
VALUES (504, 'Emily Davis', '555-987-6543', '321 Pine St', 'Seattle', '98101', 'USA');
INSERT INTO orders (orderNumber, orderDate, requiredDate, status, customerNumber)
VALUES (10503, '2024-02-05', '2024-02-10', 'In Progress', 504);
INSERT INTO orderdetails (orderNumber, productCode, quantityOrdered, priceEach, orderLineNumber)
VALUES (10503, 'S10_1530', 2, 79.99, 7);문제 2) employees 테이블에 새 직원을 추가하고 바로 그들의 매니저를 업데이트
INSERT INTO employees (employeeNumber, lastName, firstName, extension, email, officeCode, jobTitle)
VALUES (1804, 'Johnson', 'Emily', 'x5678', 'emily.johnson@example.com', 2, 'Sales Rep');
UPDATE employees
SET reportsTo = (
SELECT employeeNumber FROM employees
WHERE lastName = 'Johnson'
)
WHERE lastName = 'Smith';문제 3) products 테이블에 새 제품을 추가하고 바로 그 제품에 대한 주문을 추가
INSERT INTO products (productCode, productName, productLine, productScale, productVendor, productDescription, quantityInStock, buyPrice, MSRP)
VALUES ('S10_1540', 'Widget', 'Classic Cars_ex', '1:10', 'ABC Company', 'A fun and interactive toy', 50, 19.99, 29.99);
INSERT INTO orders (orderNumber, orderDate, requiredDate, status, customerNumber)
VALUES (10504, '2024-02-05', '2024-02-10', 'In Process', 499);
INSERT INTO orderdetails (orderNumber, productCode, quantityOrdered, priceEach, orderLineNumber)
VALUES (10504, 'S10_1540', 2, 19.99, 3);문제 4) orders 테이블에 새 주문을 추가하고 바로 지불 정보를 추가
INSERT INTO orders (orderNumber, orderDate, requiredDate, status, customerNumber)
VALUES (10505, '2024-02-06', '2024-02-11', 'Pending',);
INSERT INTO payments (customerNumber, checkNumber, paymentDate, amount)
VALUES (504, 'CHK123456', '2024-02-07', 99.99);문제 5)orderdetails 테이블에 주문 상세 정보를 추가하고 바로 관련 제품의 재고를 감소시키기
INSERT INTO orderdetails (orderNumber, productCode, quantityOrdered, priceEach, orderLineNumber)
VALUES (10502, 'S10_1520', 3, 25.00, 6);
UPDATE products SET quantityInStock = quantityInStock - 3
WHERE productCode = 'S10_1520';2. 읽기 Query - SELECT
<초급>
문제 1) customers 테이블에서 모든 고객 정보를 조회
SELECT * FROM customers; 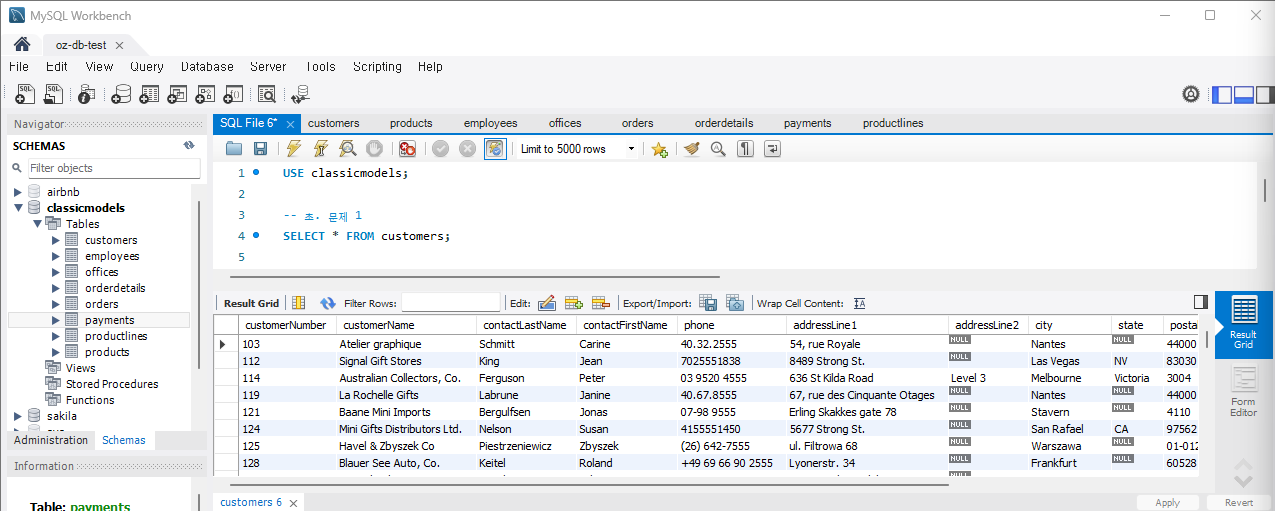
문제 2) products 테이블에서 모든 제품 목록을 조회
SELECT name, price FROM products; 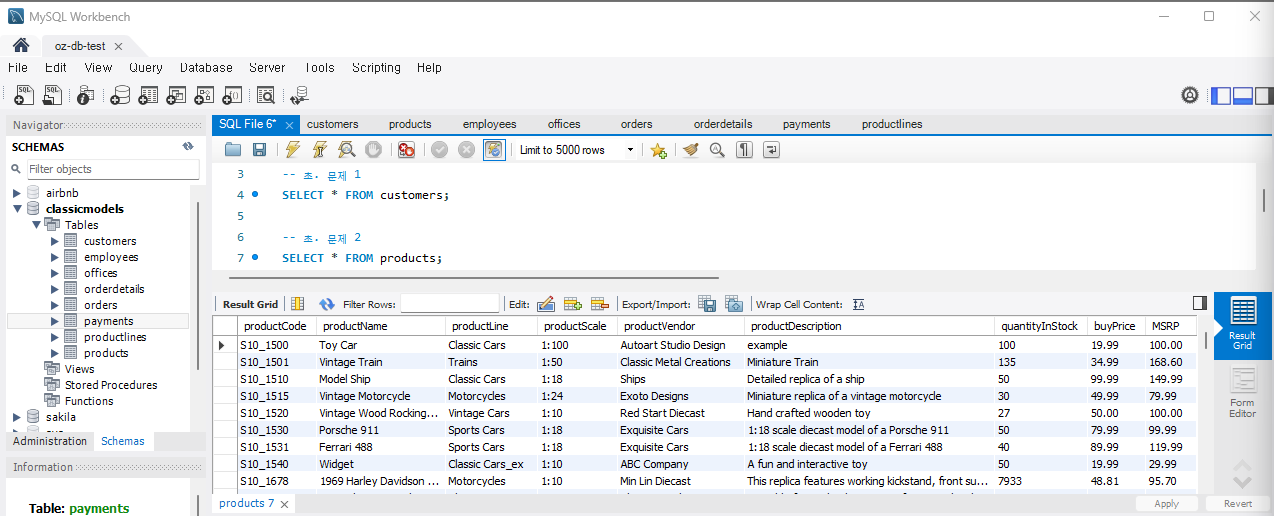
문제 3) employees 테이블에서 모든 직원의 이름과 직급을 조회
SELECT firstName, lastName, jobTitle FROM employees; 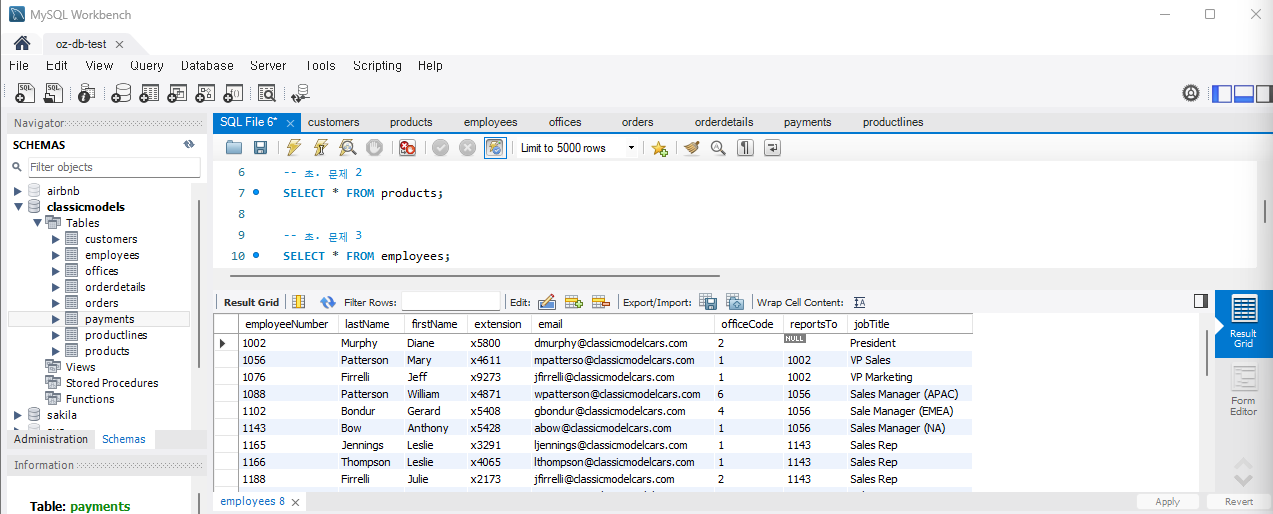
문제 4) offices 테이블에서 모든 사무실의 위치를 조회
SELECT city, address, phone FROM offices; 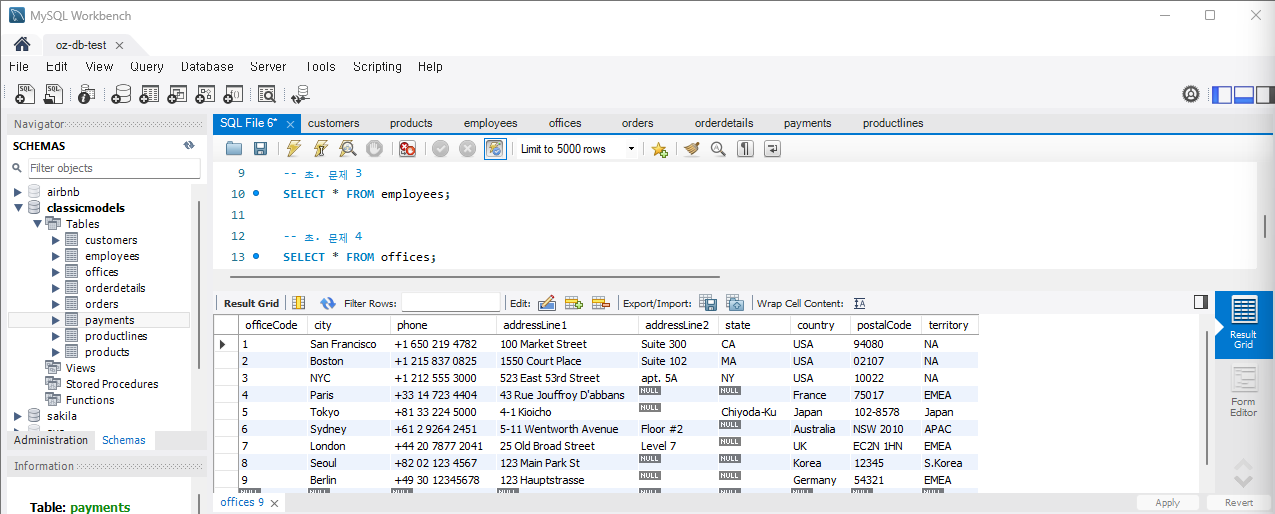
문제 5) orders 테이블에서 최근 10개의 주문을 조회
SELECT * FROM orders
ORDER BY orderDate DESC
LIMIT 10; 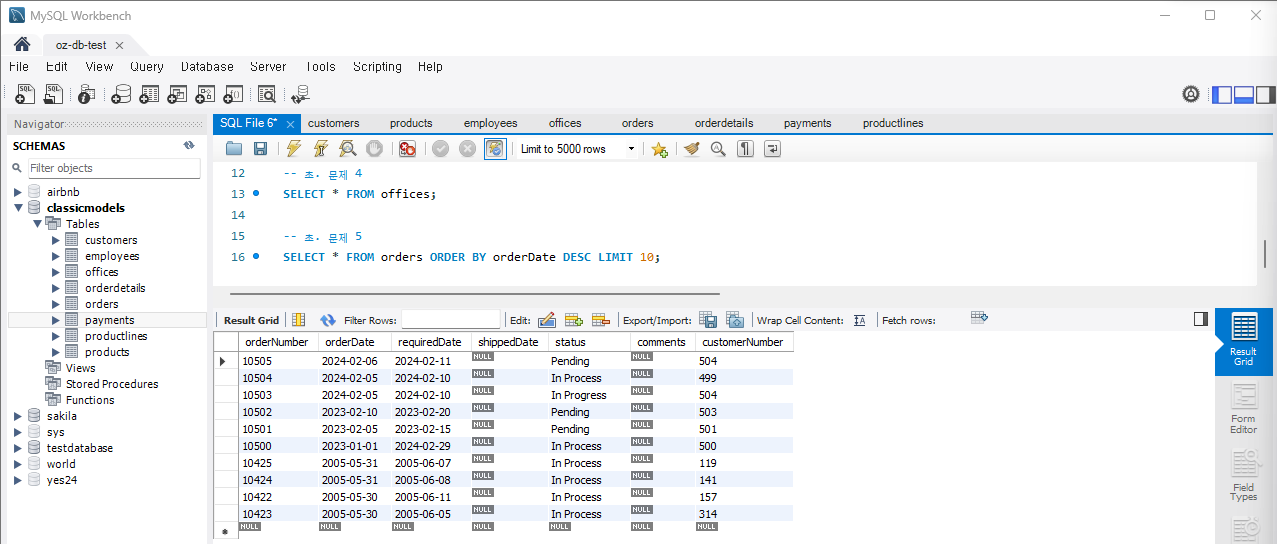
문제 6) orderdetails 테이블에서 특정 주문의 모든 상세 정보를 조회
SELECT * FROM orderdetails WHERE orderNumber = 10425; 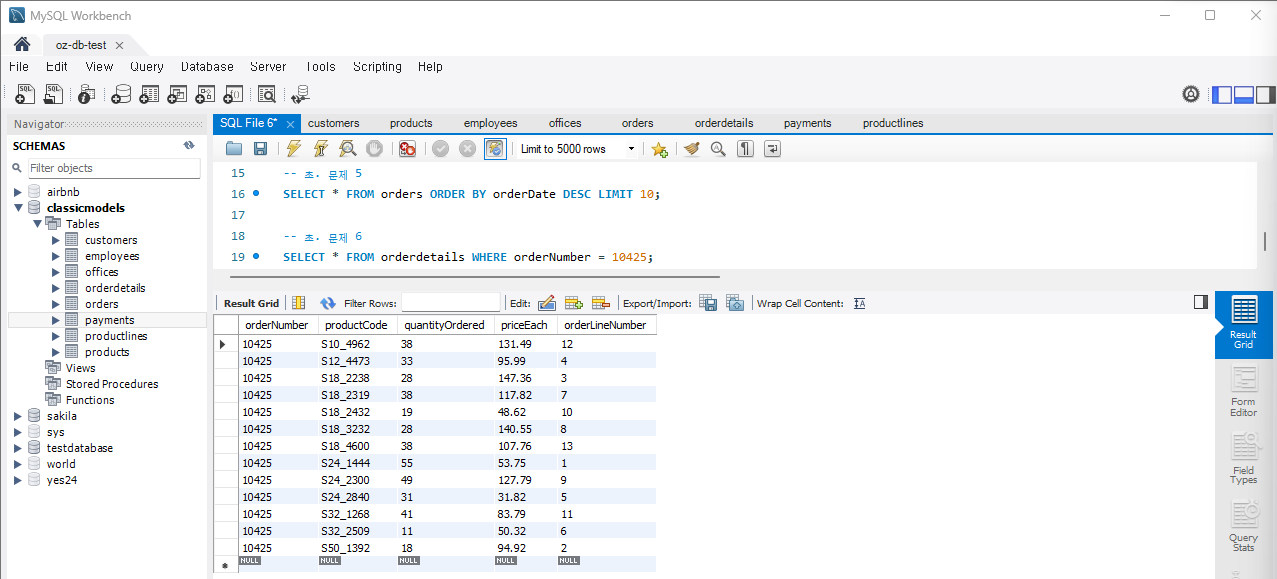
문제 7) payments 테이블에서 특정 고객의 모든 지불 정보를 조회
SELECT * FROM payments WHERE customerNumber = 486; 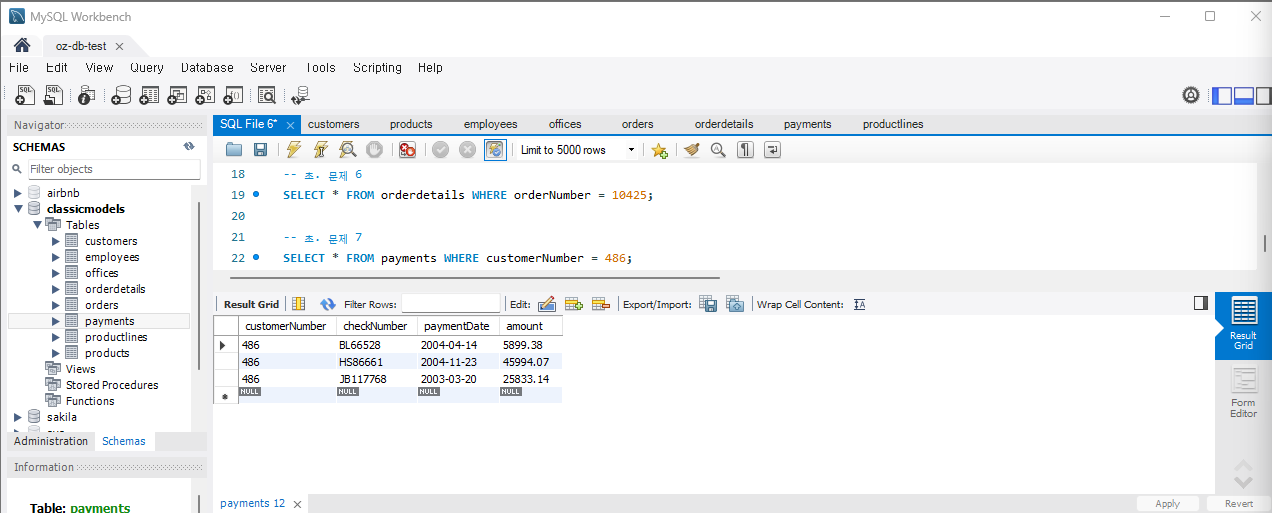
문제 8) productlines 테이블에서 각 제품 라인의 설명을 조회
SELECT productLine, textDescription FROM productlines; 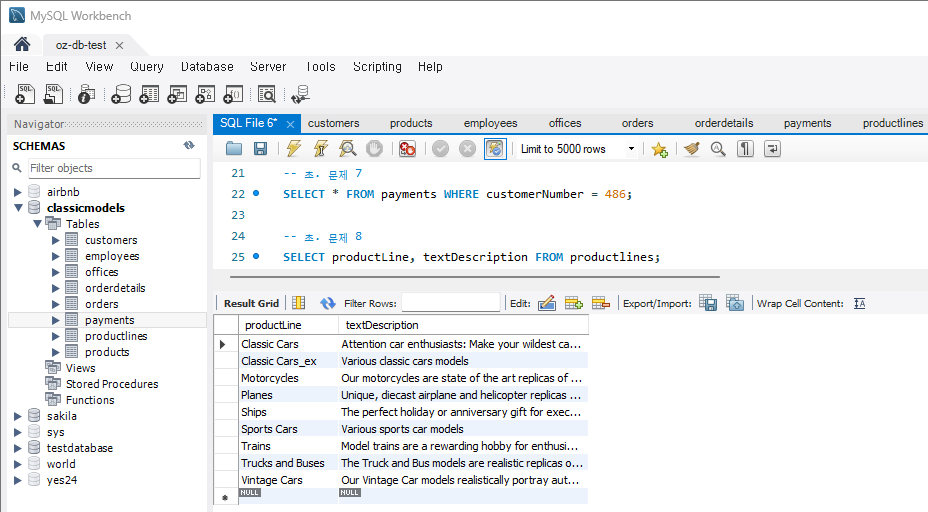
문제 9) customers 테이블에서 특정 지역의 고객을 조회하세요.
SELECT * FROM customers WHERE city = 'New York'; 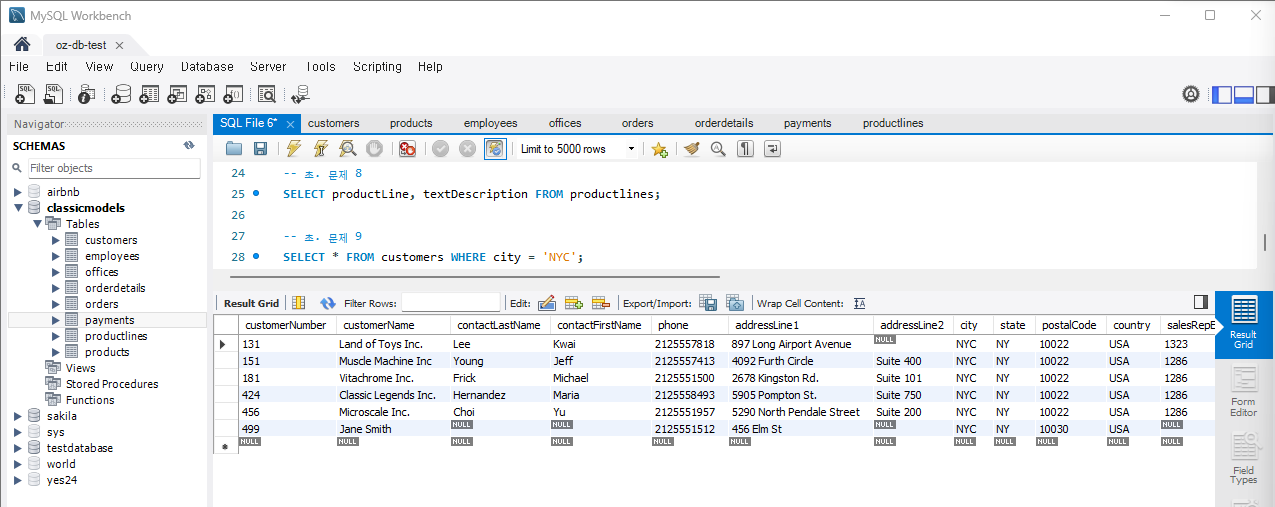
문제 10) products 테이블에서 특정 가격 범위의 제품을 조회
SELECT * FROM products WHERE buyPrice BETWEEN 10 AND 45 ORDER BY buyPrice ASC; 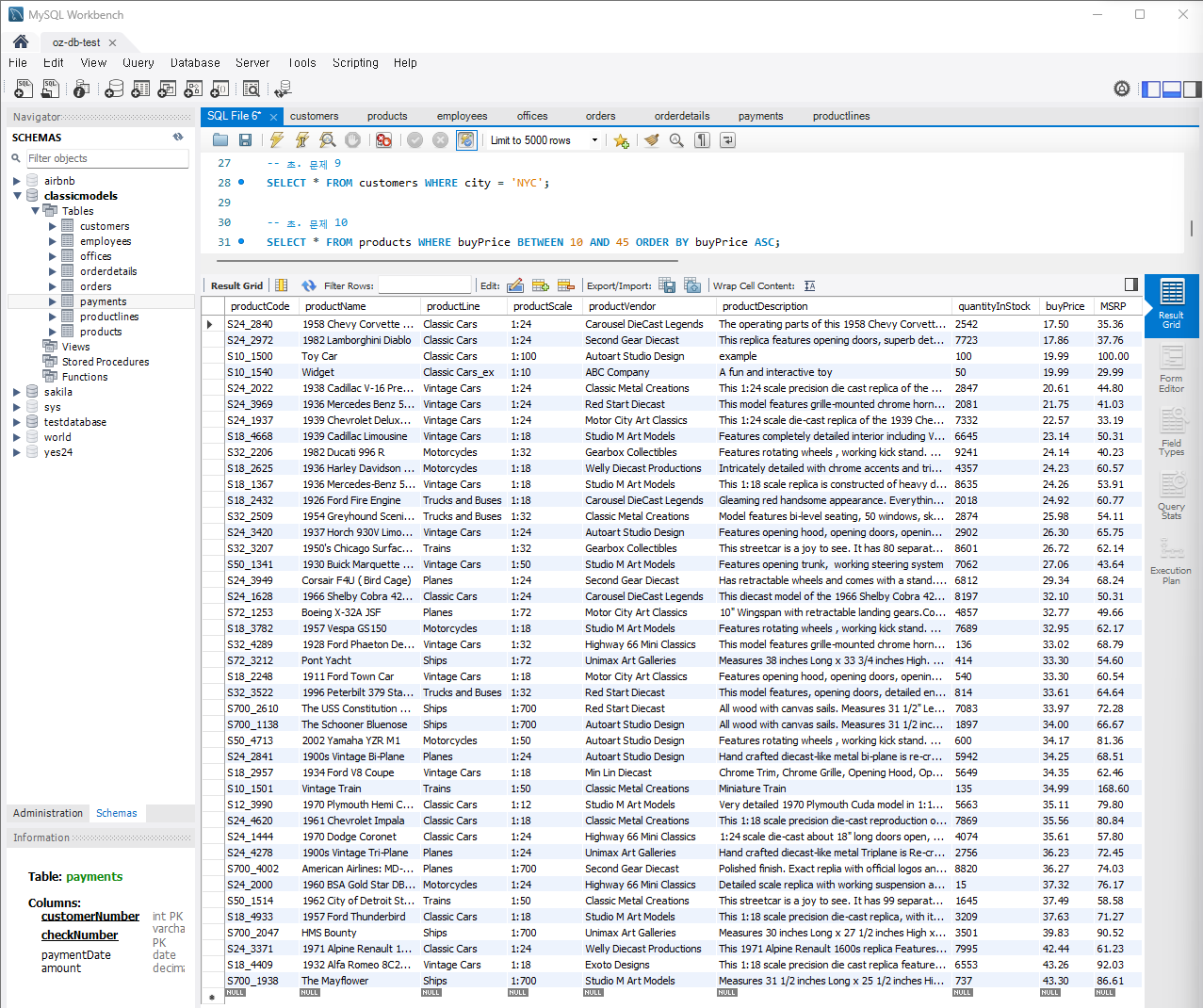
<중급>
문제 1) orders 테이블에서 특정 고객의 모든 주문을 조회
SELECT * FROM orders WHERE customerNumber = 124; 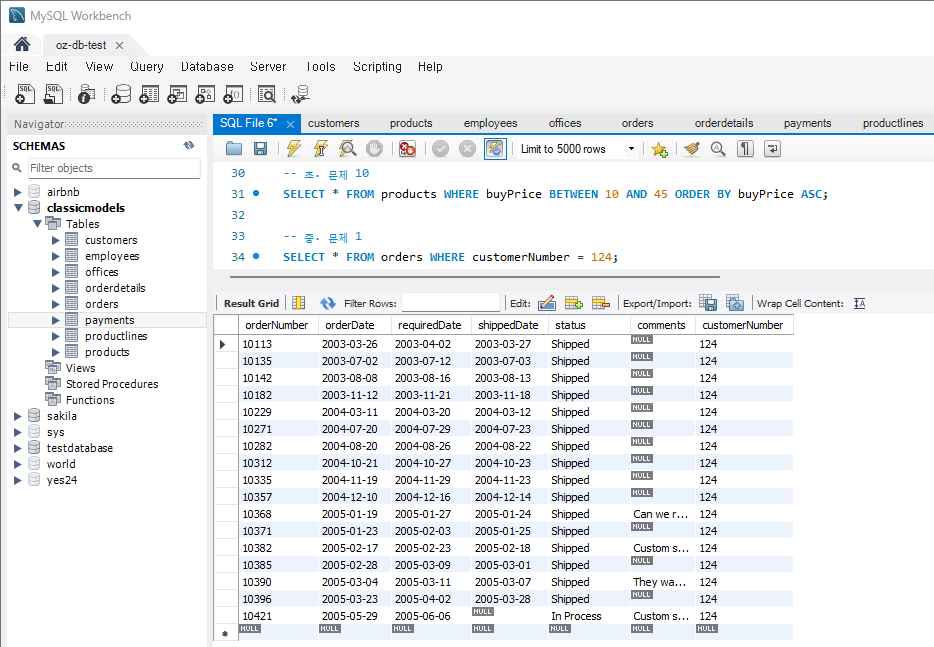
문제 2) orderdetails 테이블에서 특정 제품에 대한 모든 주문 상세 정보를 조회
SELECT * FROM orderdetails WHERE productCode = 'S18_4600'; 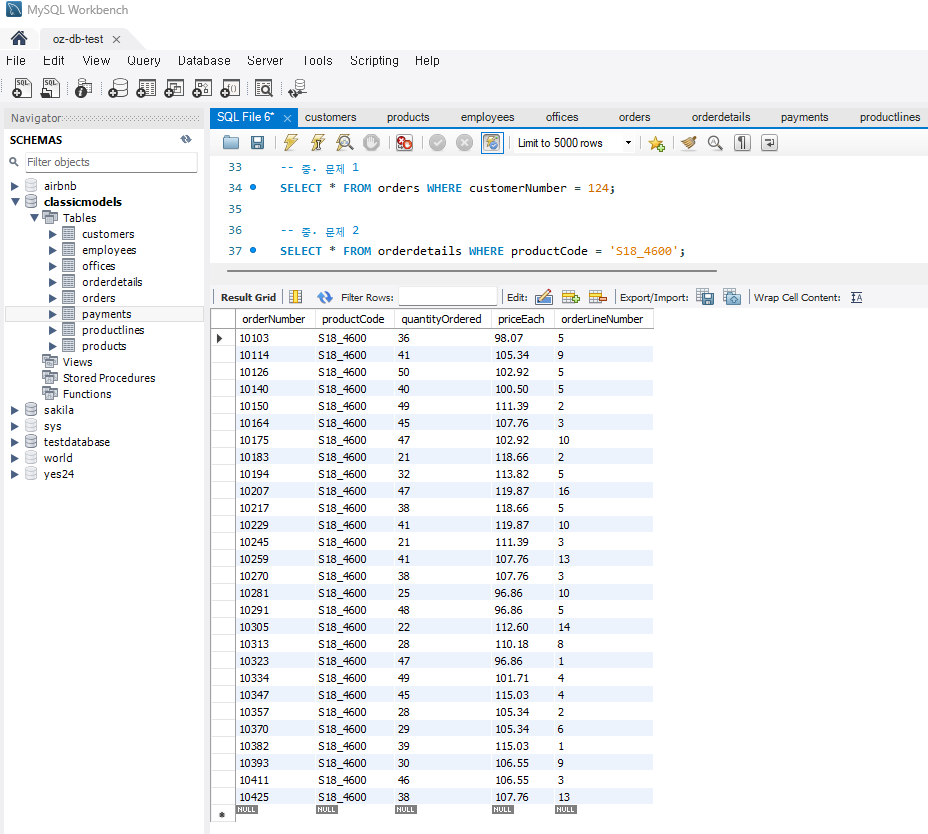
문제 3) payments 테이블에서 특정 기간 동안의 모든 지불 정보를 조회
SELECT * FROM payments WHERE paymentDate BETWEEN '2023-01-01' AND '2024-01-31'; 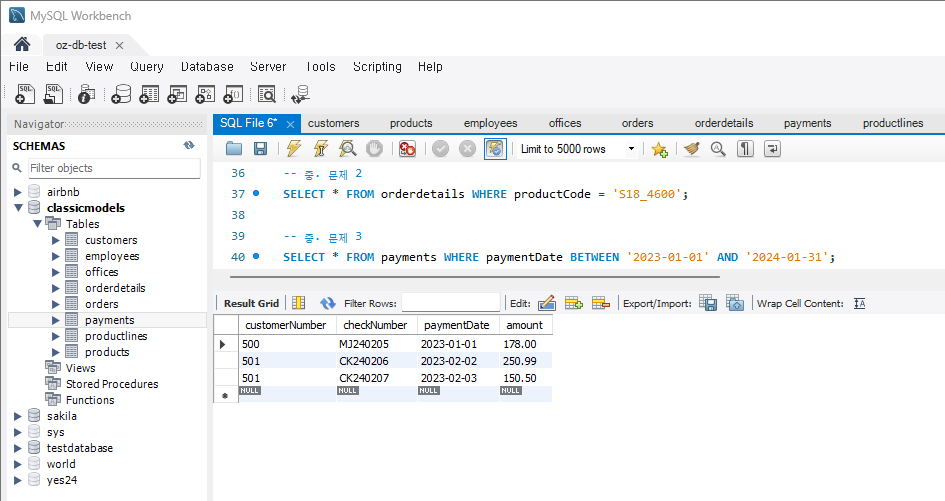
문제 4) employees 테이블에서 특정 직급의 모든 직원을 조회
SELECT * FROM employees WHERE jobTitle = 'Manager'; 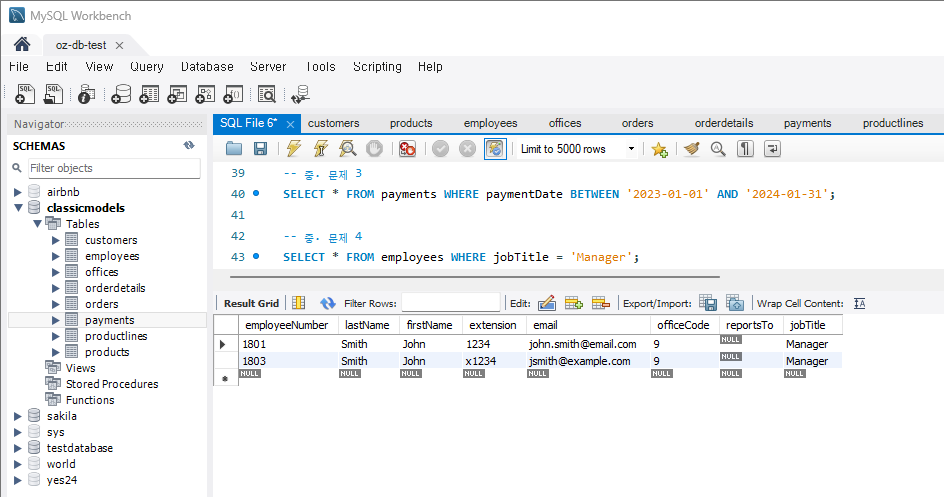
문제 5) offices 테이블에서 특정 국가의 모든 사무실을 조회
SELECT * FROM offices WHERE country = 'USA'; 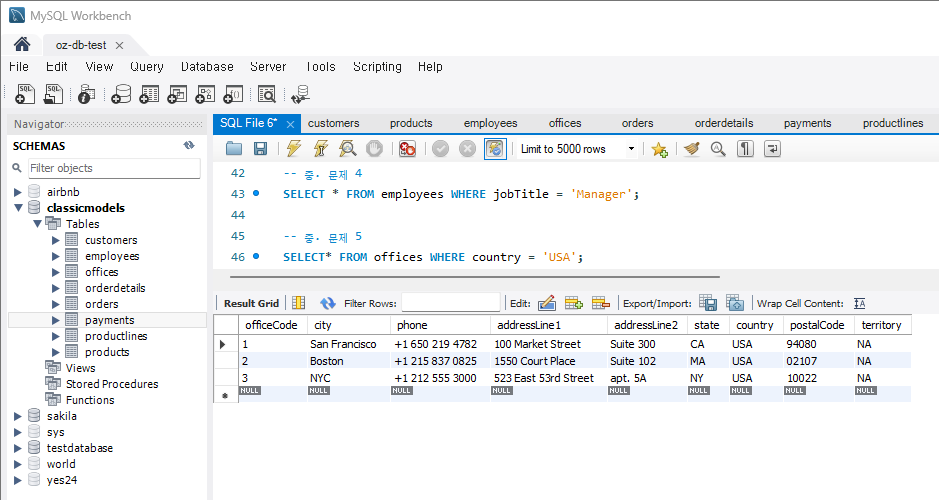
문제 6) product 테이블에서 특정 제품 라인에 속하는 모든 제품을 조회
SELECT * FROM products WHERE productLine = 'Classic Cars'; 
문제 7) customers 테이블에서 최근에 가입한 5명의 고객을 조회
SELECT * FROM customers ORDER BY customerNumber DESC LIMIT 5; 
문제 8) products 테이블에서 재고가 부족한 모든 제품을 조회
SELECT * FROM products WHERE quantityInStock < 50; 
문제 9) orders 테이블에서 지난 달에 이루어진 모든 주문을 조회
SELECT * FROM orders WHERE orderDate BETWEEN '2023-01-01' AND '2023-02-01'; 
문제 10) orderdetails 테이블에서 특정 주문에 대한 총 금액을 계산
SELECT orderNumber, SUM(quantityOrdered * priceEach) AS total_amount FROM orderdetails
WHERE orderNumber = 10417 GROUP BY orderNumber; 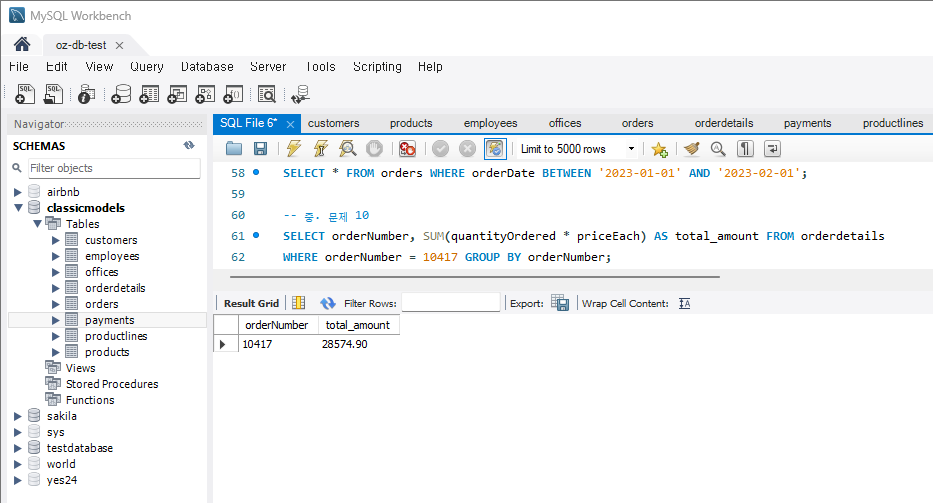
<고급>
문제 1) customers 테이블에서 각 지역별 고객 수를 계산
SELECT city, COUNT(*) AS customerCount FROM customers
GROUP BY city; 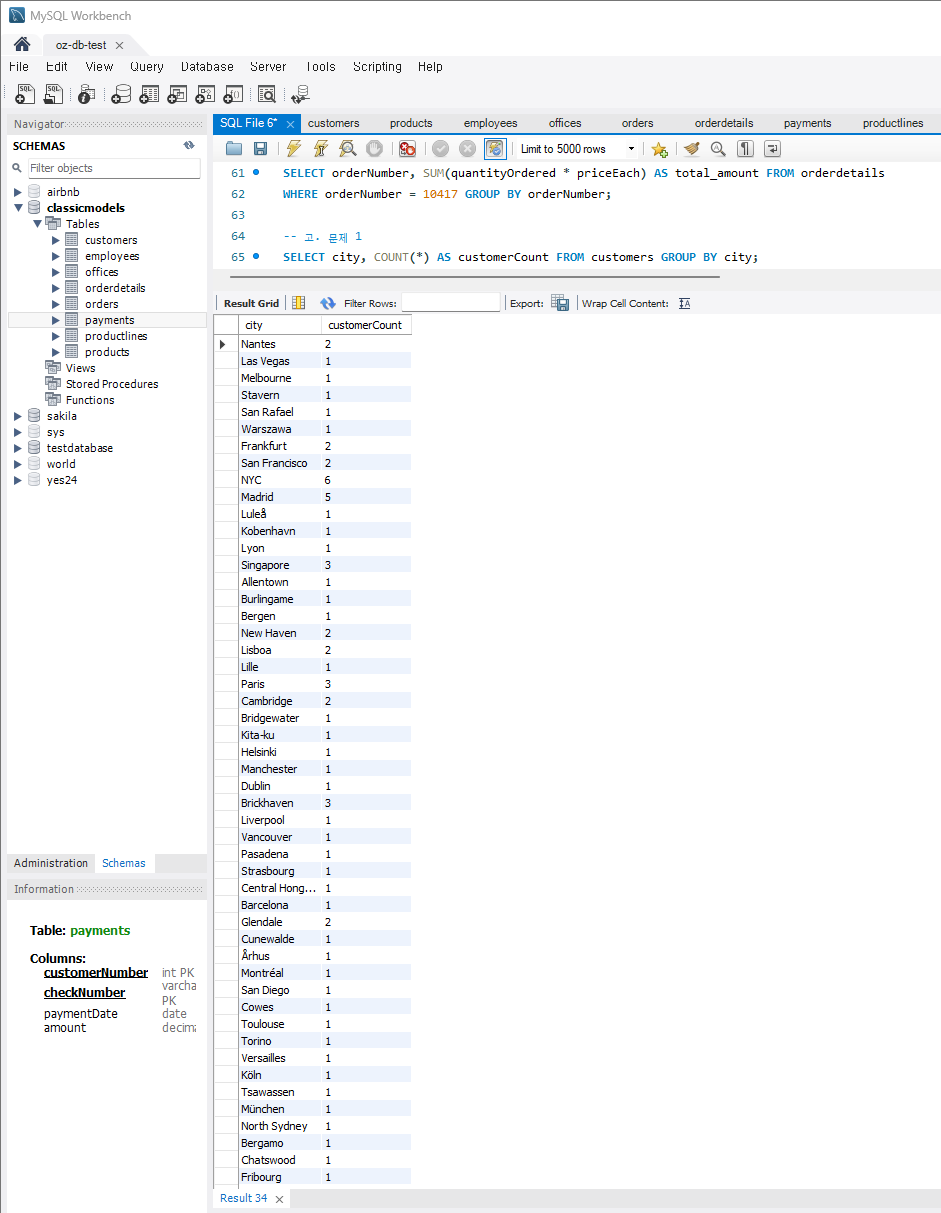
문제 2) products 테이블에서 각 제품 카테고리별 평균 가격을 계산
SELECT productline, AVG(buyPrice) AS avg_price FROM products GROUP BY productLine; 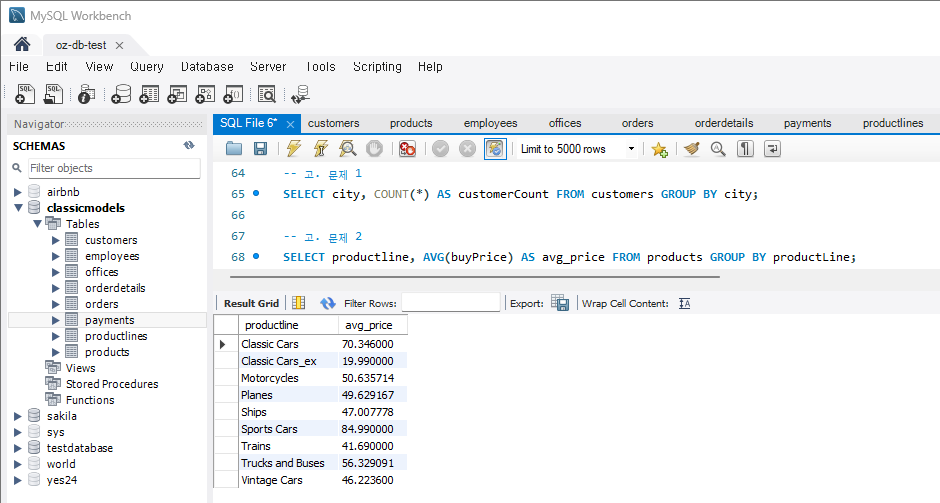
문제 3) employees 테이블에서 각 부서별 직원 수를 계산
SELECT officeCode, COUNT(*) AS employeeCount FROM employees
GROUP BY officeCode; 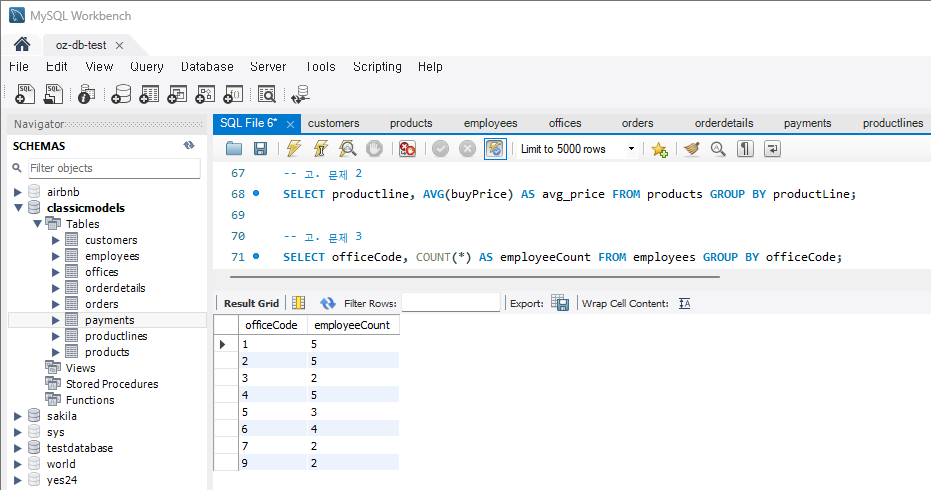
문제 4) offices 테이블에서 각 사무실별 평균 직원 연봉을 계산
SELECT officeCode, AVG(extension) AS avg_salary FROM employees GROUP BY officeCode; 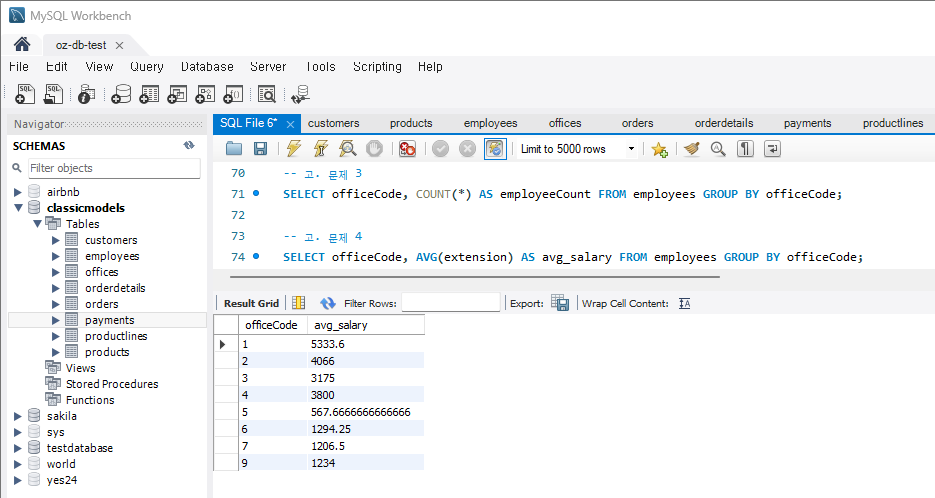
문제 5) orderdetails 테이블에서 가장 많이 팔린 제품 5개를 조회
SELECT productID, SUM(quantityOrdered) AS totalOrdered FROM orderdetails
GROUP BY productID
ORDER BY totalOrdered DESC
LIMIT 5; 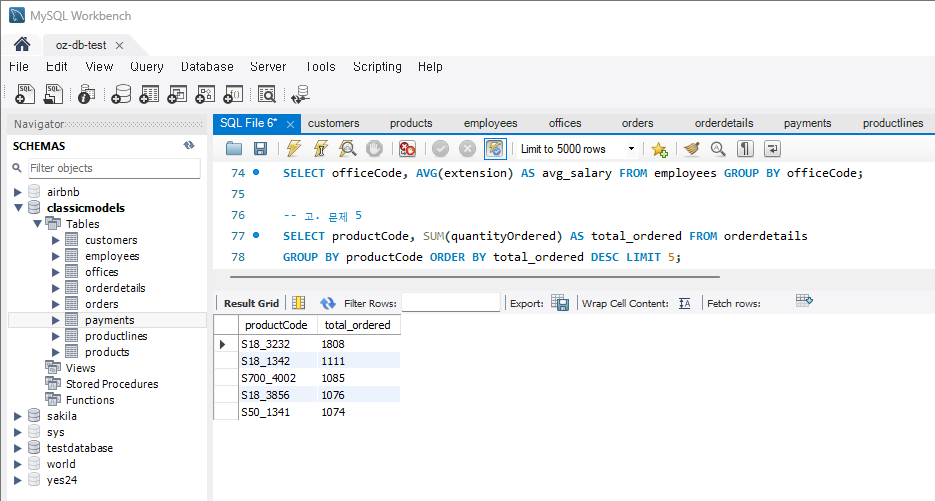
3. 갱신 Query - UPDATE
<초급>
문제 1) customers 테이블에서 특정 고객의 주소를 갱신
- 기존 주소 : '54, rue Royale'
UPDATE customers SET addressLine1 = '456 Updated St' WHERE customerNumber = 103;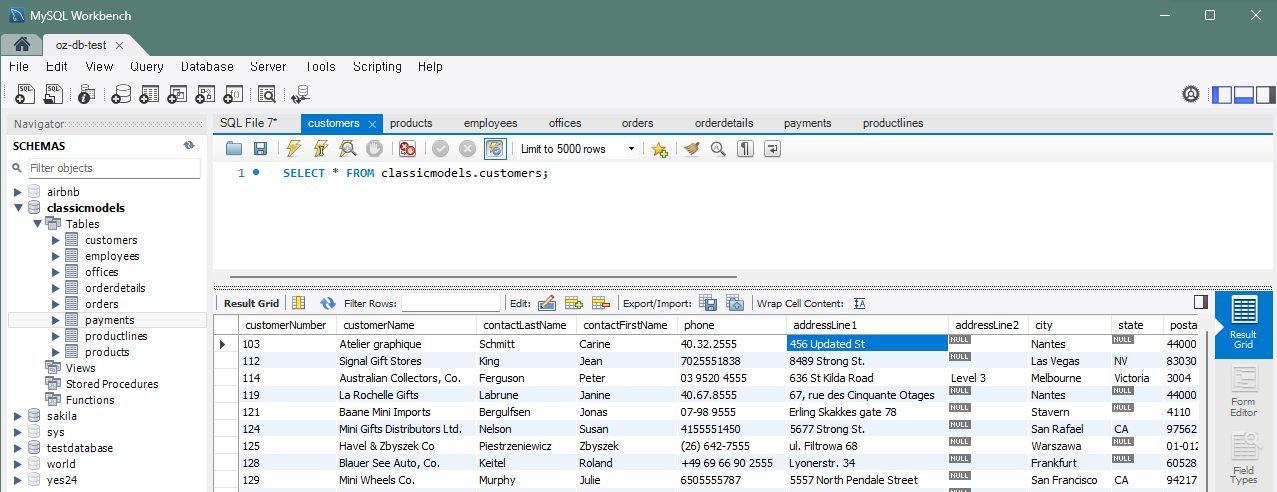
문제 2) products 테이블에서 특정 제품의 가격을 갱신
-
기존 가격 : 19.99
UPDATE products SET buyPrice = 21.99 WHERE productCode = 'S10_1500';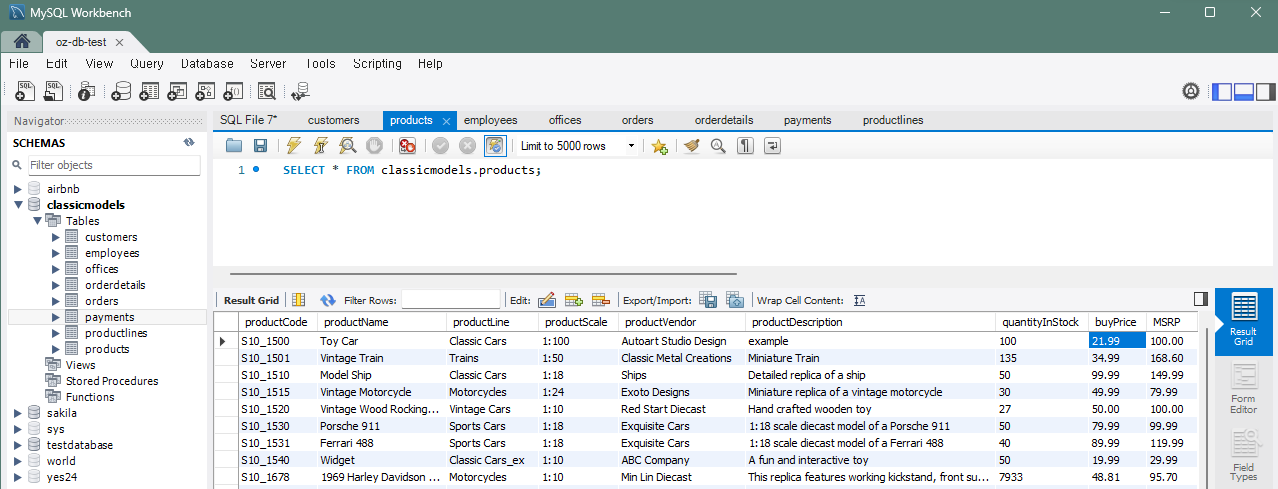
문제 3) employees 테이블에서 특정 직원의 직급을 갱신
-
기존 직급 : 'Sales Rep'
UPDATE employees SET jobTitle = 'Manager' WHERE employeeNumber = 1165;
문제 4) offices 테이블에서 특정 사무실의 전화번호를 갱신
-
기존 전화번호 : +1 650 219 4782
UPDATE offices SET phone = '123 456 7891' WHERE officeCode = 1;
문제 5) orders 테이블에서 특정 주문의 상태를 갱신
- 기존 주문 상태 : 'Pending'
UPDATE orders SET status = 'In Process' WHERE orderNumber = 10501;
문제 6) orderdetails 테이블에서 특정 주문 상세의 수량을 갱신
- 기존 수량 : 2
UPDATE orderdetails SET quantityOrdered = 12 WHERE orderNumber = 10504 AND productCode = 'S10_1540';
문제 7) payments 테이블에서 특정 지불의 금액을 갱신
- 기존 지불 금액 : 99.99
UPDATE payments SET amount = 210.00 WHERE customerNumber = 504 AND paymentDate = '2024-02-07';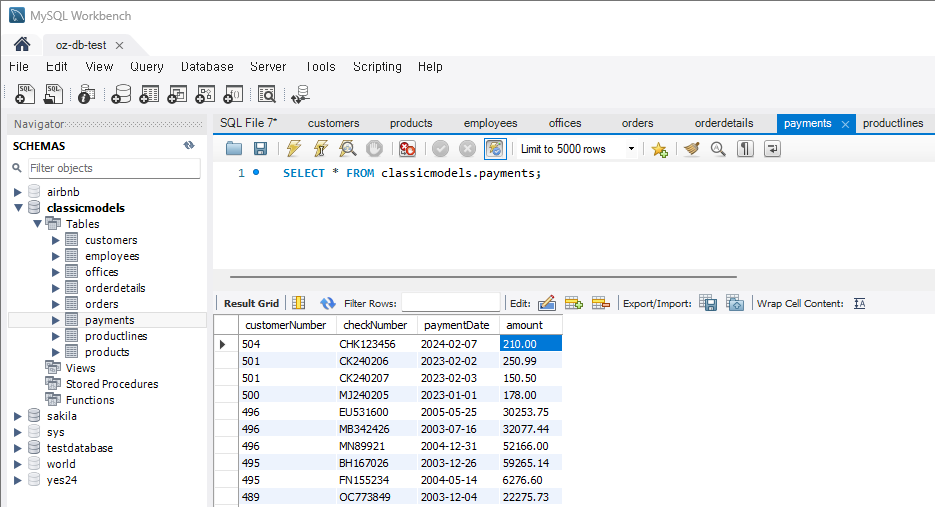
문제 8) productlines 테이블에서 특정 제품 라인의 설명을 갱신
- 기존 제품 라인 설명 : 'Our Vintage Car models realistically portray automobiles produced from ...'
UPDATE productlines SET textDescription = 'Updated description' WHERE productLine = 'Vintage Cars';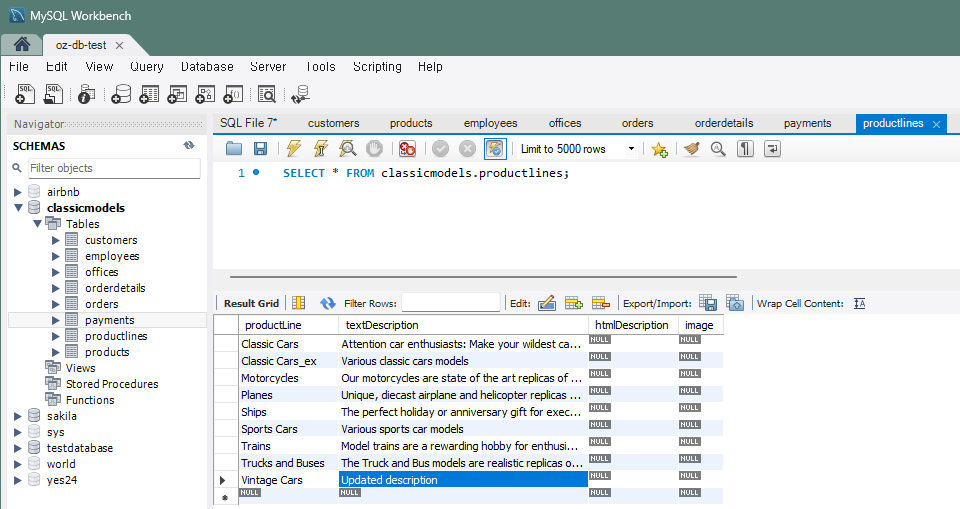
문제 9) customers 테이블에서 특정 고객의 전화번호를 갱신
- 기존 전화번호 : 40.32.2555
UPDATE customers SET phone = '40 32 2555' WHERE customerNumber = 103;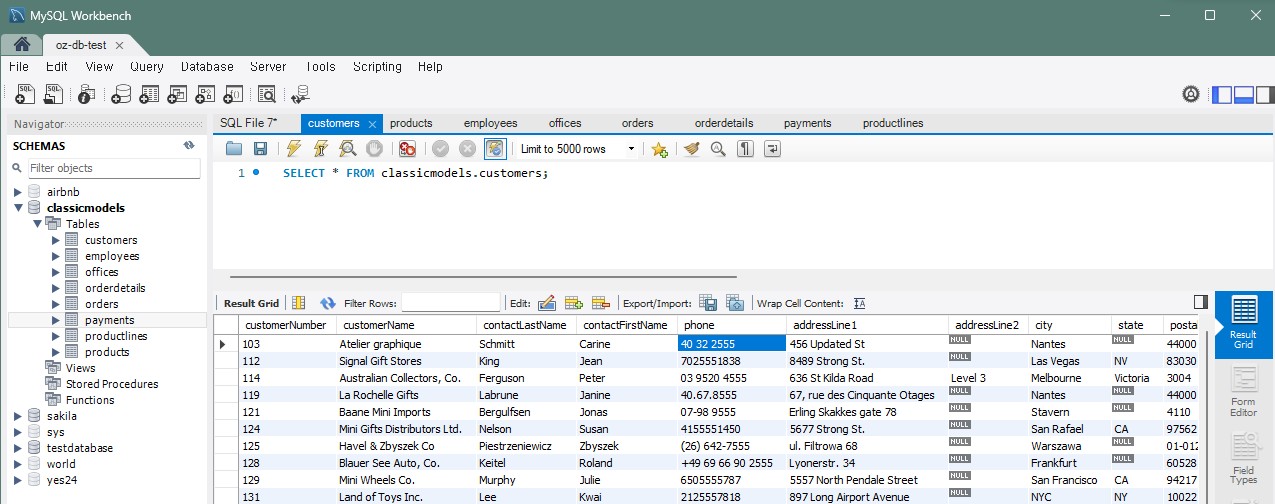
문제 10) products 테이블에서 여러 제품의 가격을 한 번에 갱신
UPDATE products SET buyPrice = buyPrice * 1.1; 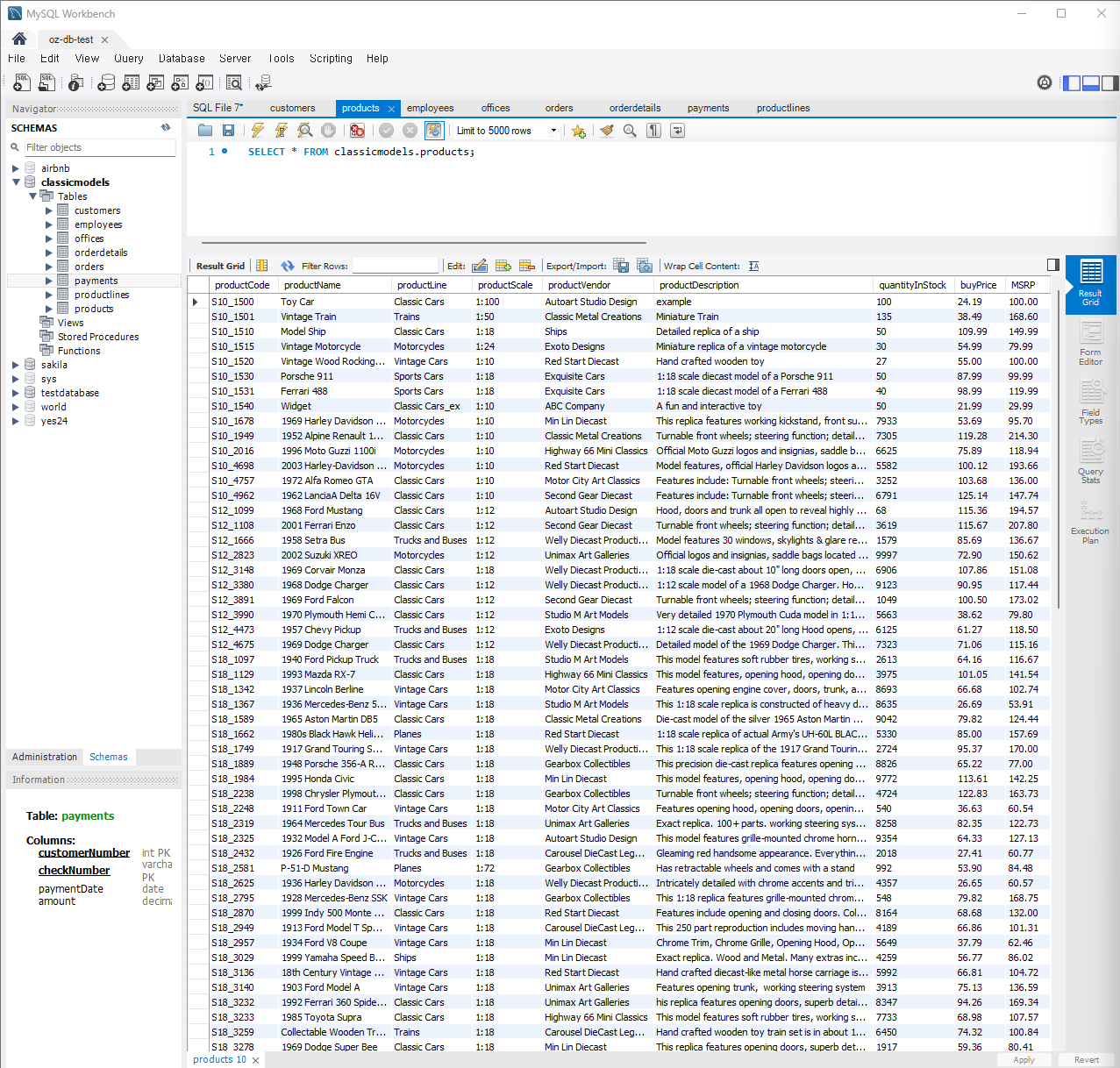
<중급>
문제 1) employees 테이블에서 여러 직원의 부서를 한 번에 갱신
UPDATE employees SET officeCode = 9 WHERE extension = 101; 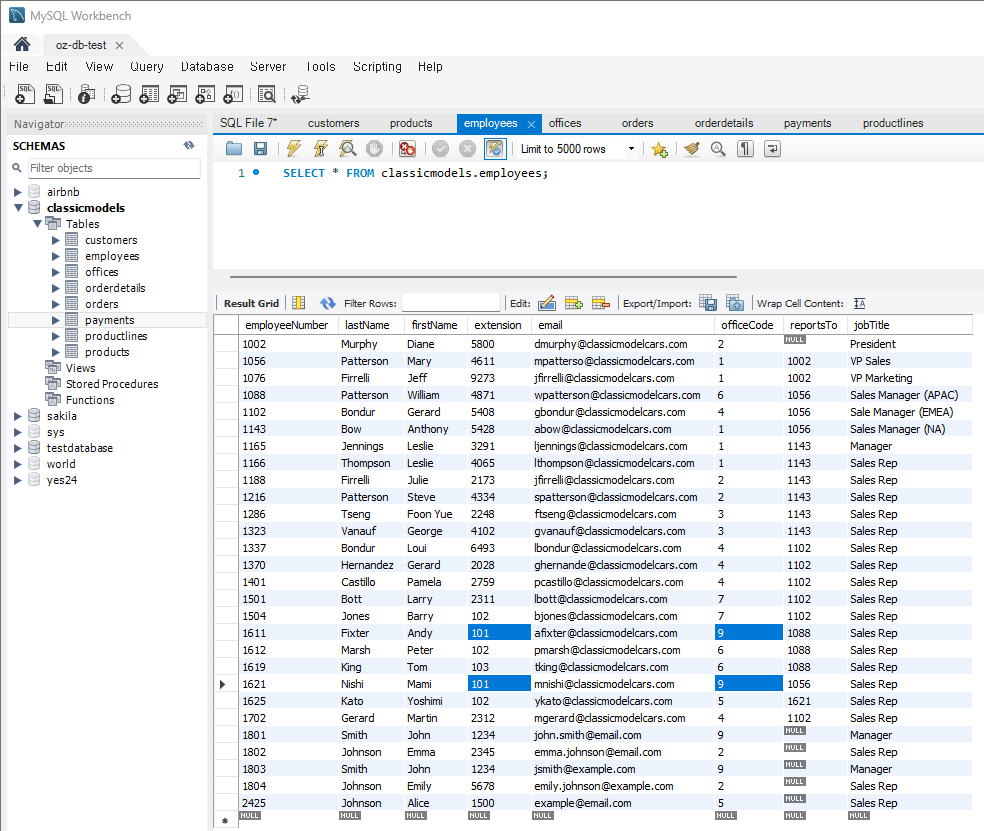
문제 2) offices 테이블에서 여러 사무실의 위치를 한 번에 갱신
- 기존 도시 : 'Seoul'
UPDATE offices SET city = 'Updated City' WHERE country = 'Korea';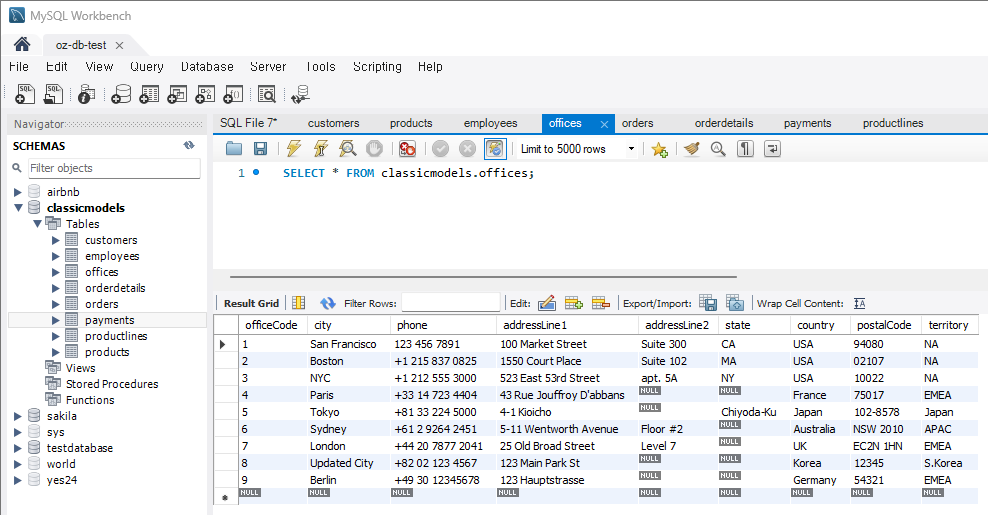
문제 3) orders 테이블에서 지난 달의 모든 주문의 배송 상태를 갱신
UPDATE orders SET status = 'Cancelled'
WHERE orderDate BETWEEN '2023-02-01' AND '2023-03-01'; 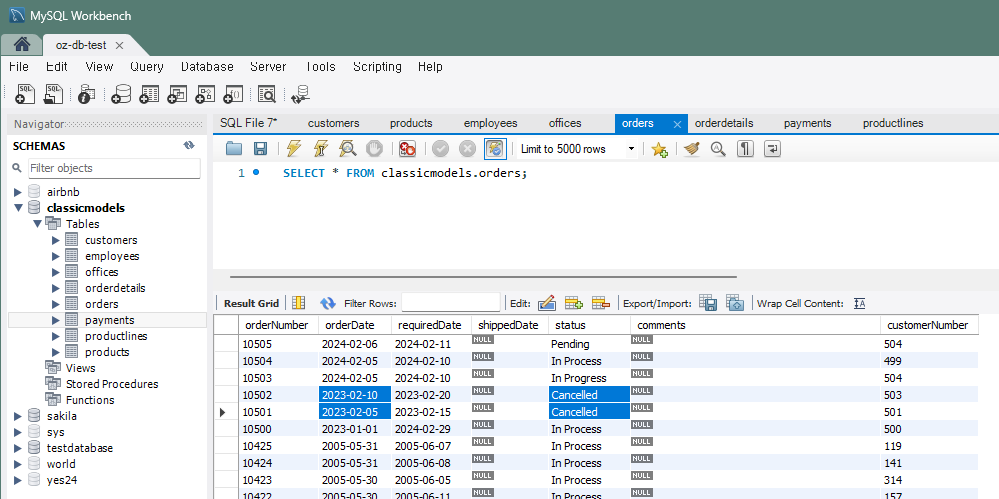
문제 4) orderdetails 테이블에서 여러 주문 상세의 가격을 한 번에 갱신
UPDATE orderdetails SET priceEach = priceEach * 1.1
WHERE orderNumber IN (
SELECT orderNumber FROM orders
WHERE orderDate BETWEEN '2023-02-01' AND '2023-02-31'); 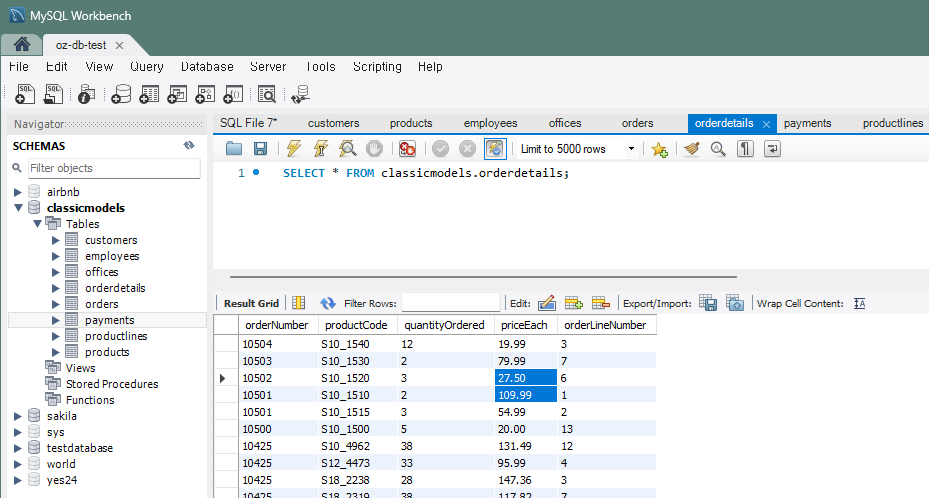
문제 5) payments 테이블에서 특정 고객의 모든 지불 내역을 갱신
UPDATE payments SET amount = amount * 1.05 WHERE customerNumber = 501; 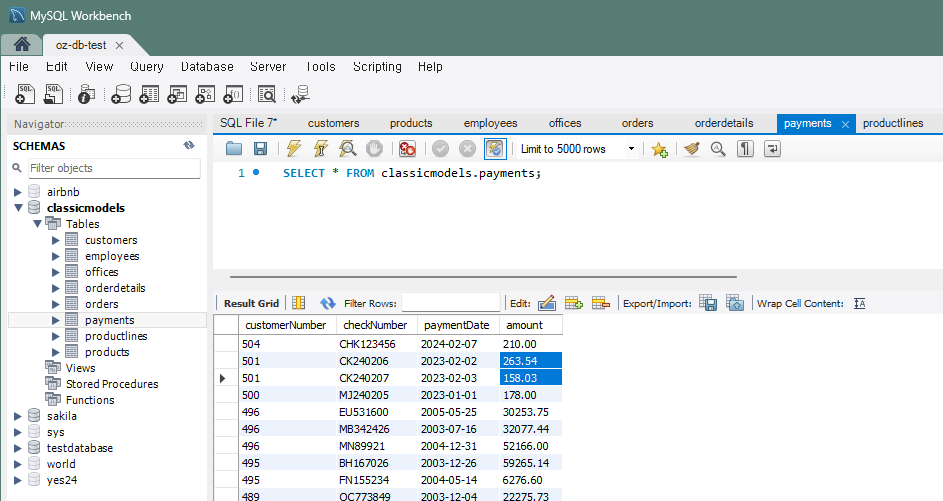
문제 6) productlines 테이블에서 여러 제품 라인의 설명을 한 번에 갱신
UPDATE productlines SET textDescription = 'New description'
WHERE productLine IN ('Classic Cars', 'Trains'); 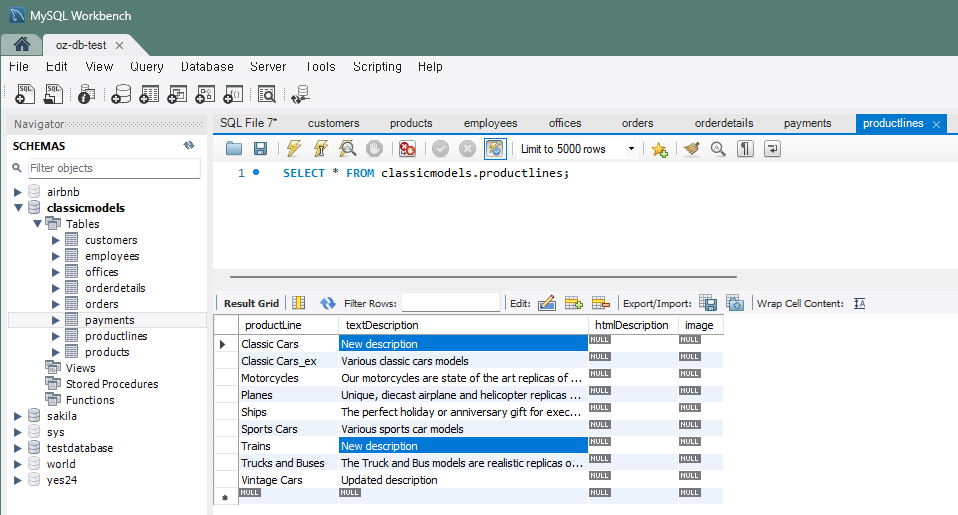
문제 7) customers 테이블에서 특정 지역의 모든 고객의 연락처를 갱신
UPDATE customers SET phone = '999-999-9999' WHERE city = 'San Francisco'; 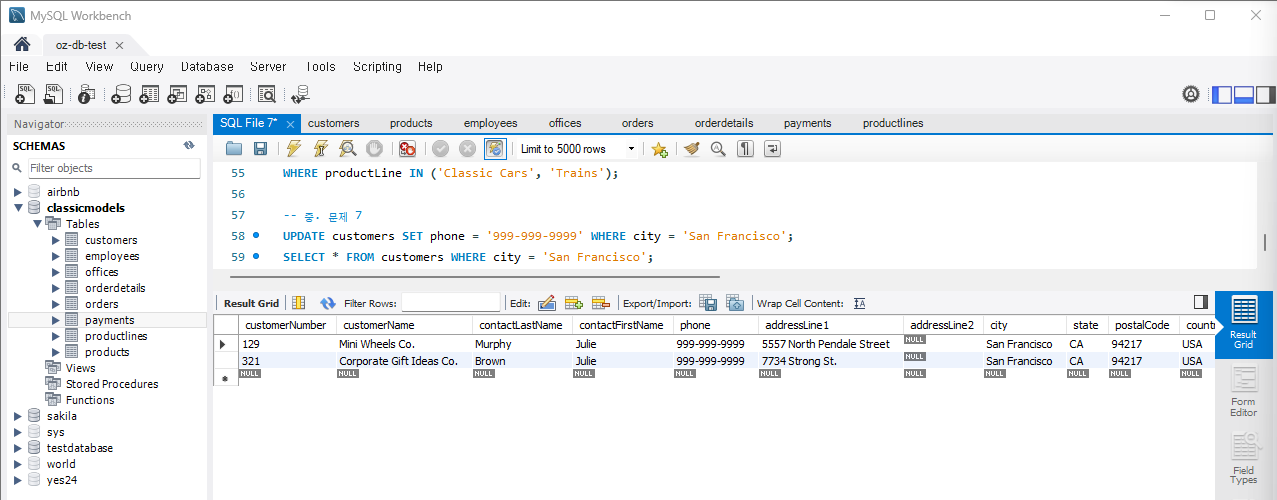
문제 8) products 테이블에서 특정 카테고리의 모든 제품 가격을 갱신
UPDATE products SET buyPrice = buyPrice * 0.95 WHERE productLine = 'Classic Cars'; 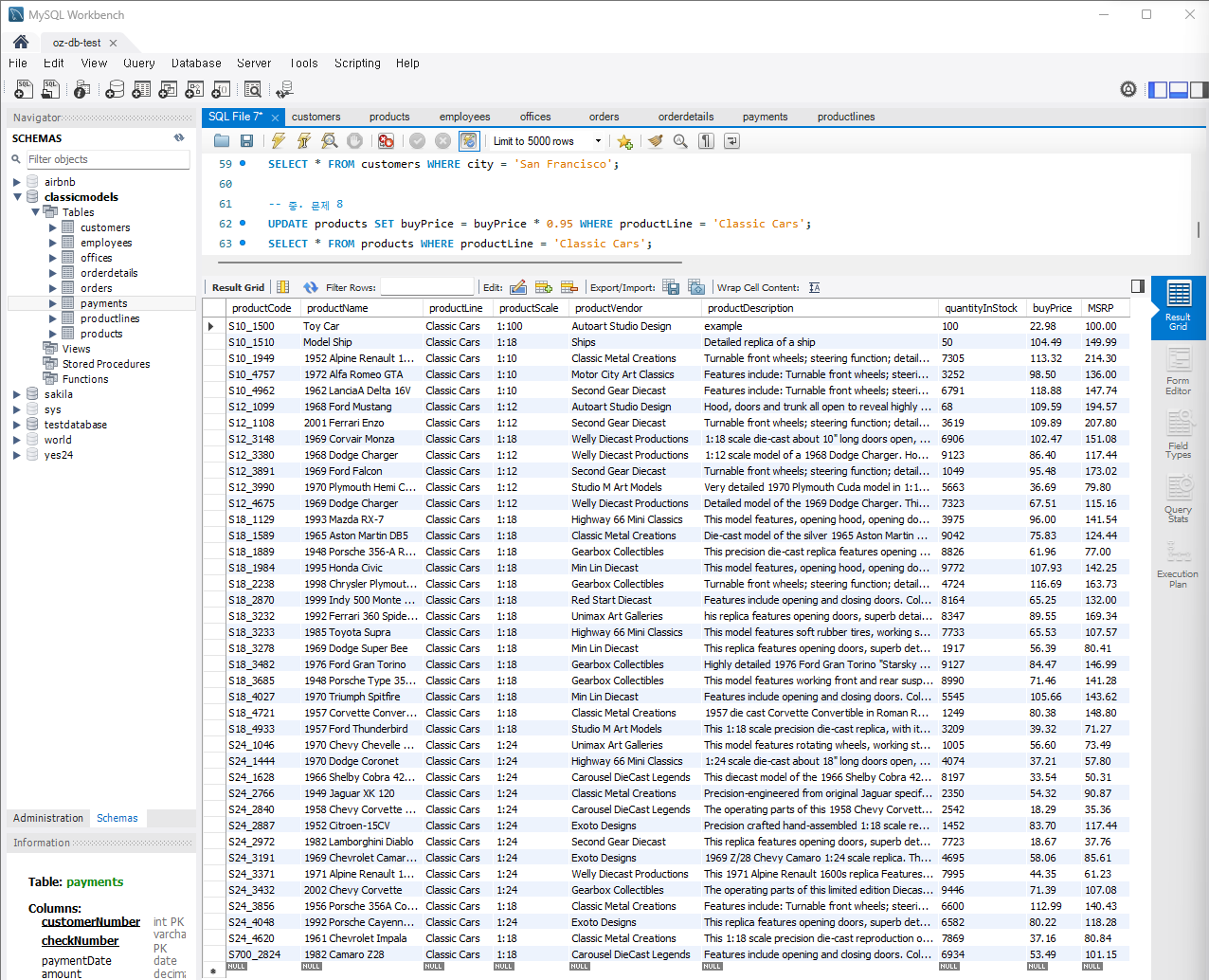
문제 9) employees 테이블에서 특정 직원의 모든 정보를 갱신
UPDATE employees SET extension = extension * 1.05 WHERE jobTitle = 'Manager'; 
문제 10) offices 테이블에서 특정 사무실의 모든 정보를 갱신
UPDATE offices SET addressLine1 = '123 New Address St', phone = '987 654 3211' WHERE officeCode = 2; 
<고급>
문제 1) orders 테이블에서 지난 해의 모든 주문 상태를 갱신
UPDATE orders SET status = 'On Hold'
WHERE orderDate BETWEEN '2023-01-01' AND '2023-12-31'; 
문제 2) orderdetails 테이블에서 특정 주문의 모든 상세 정보를 갱신
UPDATE orderdetails SET priceEach = priceEach * 1.1
WHERE orderNumber = 10504; 
문제 3) payments 테이블에서 지난 달의 모든 지불 내역을 갱신
UPDATE payments SET paymentDate = '2024-02-05'
WHERE paymentDate BETWEEN '2024-01-01' AND '2024-03-31'; 
문제 4) productlines 테이블에서 모든 제품 라인의 정보를 갱신
UPDATE productlines SET textDescription = 'New updated description'
WHERE productLine IN (
SELECT productLine FROM products
WHERE quantityInStock < 50); 
문제 5) customers 테이블에서 모든 고객의 주소를 갱신
UPDATE customers SET addressLine2 = 'New Address'
WHERE customerNumber BETWEEN 100 AND 150; 
4. 삭제 Query - DELETE
<초급>
문제 1) customers 테이블에서 특정 고객을 삭제
DELETE FROM customers WHERE customerNumber = 504;문제 2) products 테이블에서 특정 제품을 삭제
DELETE FROM products WHERE productCode = 'S10_1500';문제 3) employees 테이블에서 특정 직원을 삭제
DELETE FROM employees WHERE employeeNumber = 2425;문제 4) offices 테이블에서 특정 사무실을 삭제
DELETE FROM offices WHERE officeCode = 9;문제 5) orders 테이블에서 특정 주문을 삭제
DELETE FROM orders WHERE orderNumber = 10505;문제 6) orderdetails 테이블에서 특정 주문 상세를 삭제
DELETE FROM orderdetails WHERE orderNumber = 10504;문제 7) payments 테이블에서 특정 지불 내역을 삭제
DELETE FROM payments WHERE customerNumber = 504;문제 8) productlines 테이블에서 특정 제품 라인을 삭제
DELETE FROM productlines WHERE productLine = 'Classic Cars_ex';문제 9) customers 테이블에서 특정 지역의 모든 고객을 삭제
DELETE FROM customers WHERE city = 'Seattle';문제 10) products 테이블에서 특정 카테고리의 모든 제품을 삭제
DELETE FROM products WHERE productLine = 'Classic Cars_ex';<중급>
문제 1) employees 테이블에서 특정 부서의 모든 직원을 삭제
DELETE FROM employees WHERE officeCode = 9;문제 2) offices 테이블에서 특정 국가의 모든 사무실을 삭제
DELETE FROM offices WHERE country = 'Germany';문제 3) orders 테이블에서 지난 달의 모든 주문을 삭제
DELETE FROM orders WHERE orderDate BETWEEN '2024-01-01' AND '2024-12-31';문제 4) orderdetails 테이블에서 특정 주문의 모든 상세 정보를 삭제
DELETE FROM orderdetails WHERE orderNumber = 10503;문제 5) payments 테이블에서 특정 고객의 모든 지불 내역을 삭제
DELETE FROM payments WHERE customerNumber = 501;문제 6) productlines 테이블에서 여러 제품 라인을 한 번에 삭제
DELETE FROM productlines WHERE productLine IN ('Motorcycles', 'Planes');문제 7) customers 테이블에서 가장 오래된 5명의 고객을 삭제
DELETE FROM customers
WHERE customerNumber IN (
SELECT customerNumber FROM customers
ORDER BY customerNumber DESC
LIMIT 5);문제 8) products 테이블에서 재고가 없는 모든 제품을 삭제
DELETE FROM products WHERE quantityInStock < 50;문제 9) employees 테이블에서 특정 직급의 모든 직원을 삭제
DELETE FROM employees WHERE jobTitle = 'Sales Rep';문제 10)offices 테이블에서 가장 인원이 적은 사무실을 삭제
DELETE FROM offices
WHERE officeCode = (
SELECT officeCode
FROM (
SELECT officeCode, COUNT(*) AS office_employee_count
FROM employees
GROUP BY officeCode
ORDER BY office_employee_count ASC
LIMIT 1
) AS min_office
);<고급>
문제 1) orders 테이블에서 지난 해의 모든 주문을 삭제
DELETE FROM orders WHERE orderDate BETWEEN '2024-01-01' AND '2024-03-01';문제 2) orderdetails 테이블에서 가장 적게 팔린 제품의 모든 주문 상세를 삭제
DELETE od
FROM orderdetails od
JOIN (
SELECT productID
FROM products
ORDER BY quantityInStock ASC
LIMIT 5
) AS sub
ON od.productID = sub.productID;문제 3) payments 테이블에서 특정 금액 이하의 모든 지불 내역을 삭제
DELETE FROM payments WHERE amount < 200;문제 4) productlines 테이블에서 제품이 없는 모든 제품 라인을 삭제
DELETE FROM productlines WHERE productLine NOT IN (SELECT DISTINCT productLine FROM products);문제 5) customers 테이블에서 최근 1년 동안 활동하지 않은 모든 고객을 삭제
DELETE c
FROM customers c
JOIN (
SELECT orderNumber
FROM orders
WHERE orderDate < '2022-01-01'
) AS o
ON c.customerNumber = o.customerNumber;01. NoSQL 기초
1. NoSQL
NoSQL은 "Not Only SQL"의 약자이다.
일부 NoSQL 시스템은 SQL과 유사한 쿼리 언어를 제공하기도 한다.
대표적인 NoSQL은 아래 두개와 같다.
-
Cassandra
: Cassandra Query Language (CQL)을 제공한다.
CQL은 SQL과 유사한 구문을 가지고 있어 SQL에 익숙한 사용자가 쉽게 접근할 수 있다. -
MongoDB
: MongoDB는 전통적인 SQL 쿼리를 지원하지 않지만, SQL과 유사한 쿼리 구조를 가진 Aggregation Framework를 제공한다.
NoSQL 데이터베이스는 대량의 분산된 데이터를 다루거나 동적 스키마, 대용량 및 빠른 속도의 데이터 처리 등을 목표로 하는 다양한 요구 사항에 맞게 설계되어 있다.
NoSQL 데이터베이스는 특히 대규모 웹 애플리케이션과 분산 시스템에서 유용하게 사용된다.
NoSQL은 관계형 데이터베이스의 한계를 극복하고 다양한 형태의 데이터를 처리하기 위해 등장했다.
[RDBMS의 단점]
- 규모 확장성
: 대용량 데이터 처리와 분산 시스템에 대한 지원이 제한적이다.
수직적 확장(서버 성능 향상)에는 잘 작동하지만, 수평적 확장(서버 수 증가)에는 비효율적일 수 있다.
→ 클라우드 서버의 등장으로 대부분 해결된 상태. - 유연성 부족
: 데이터 스키마가 고정되어 있어, 변경이나 새로운 데이터 타입의 추가가 어렵다.
이는 비구조화된 데이터나 변화하는 데이터 구조를 다루는 데 불편함을 초래할 수 있다. - 복잡한 쿼리와 트랜잭션
: 복잡한 쿼리와 트랜잭션이 시스템의 성능에 영향을 미칠 수 있으며, 특히 대규모 분산 환경에서는 더욱 그렇다.
→ 데이터가 많은 경우 전체 데이터 조회 쿼리 한번으로 DB가 뻗어버릴 수 있다.
2. NoSQL 등장 배경
- 다양한 형태의 데이터가 중요성 증대
: 관계형 데이터베이스는 테이블 형태로 정형화된 데이터를 다루기에 적합하지만, 현대 애플리케이션에서는 반정형이나 비정형 데이터도 중요해졌다. 문서, 그래프, 키-값 등 다양한 형태의 데이터를 다루기에 NoSQL이 더 유연하게 대처할 수 있다.
- 데이터 저장 단위의 기하급수적 증가로 데이터 분산 처리의 중요성 증대
: 대규모의 데이터를 효과적으로 처리하고 확장하기 위한 목적에서 등장했다. NoSQL 데이터베이스는 수평적 확장이 용이하며, 분산 데이터베이스로서 대규모 트래픽과 데이터를 다룰 수 있다.
-
유연한 스키마
: NoSQL 데이터베이스는 고정된 스키마가 없어, 다양한 형태의 데이터를 쉽게 저장하고 관리할 수 있다. 이는 데이터 분산과 확장을 용이하게 한다.- 유연한 구조 덕분에 여러 노드에 분산시켜 데이터를 저장해도 추후 데이터 조회 및 저장에 큰 이슈가 없다.
-
분산 처리
: NoSQL 시스템은 데이터를 여러 노드에 걸쳐 분산시켜 저장하며, 이로 인해 단일 노드의 과부하 문제를 줄이고, 데이터의 병렬 처리를 향상시킨다. -
키-값 저장 방식
: 많은 NoSQL 데이터베이스가 키-값 저장 방식을 사용하여 간단하고 빠른 데이터 액세스를 제공한다. 이는 빠른 읽기/쓰기 작업을 가능하게 하며, 대규모 분산 시스템에서의 성능 향상에 기여한다.
3. NoSQL 특징
-
스키마 유연성 (Schema Flexibility)
: NoSQL 데이터베이스는 스키마가 동적(dynamic)이거나 덜 제한적이어서 데이터 모델을 쉽게 조정하고 변경할 수 있다. -
분산 처리 (Distributed Processing)
: NoSQL은 대부분 분산 데이터베이스로 설계되어 있어 대량의 데이터를 여러 서버에 분산하여 처리할 수 있다.
- 분산 데이터베이스로 설계되었다는 것은 NoSQL 데이터베이스가 데이터를 여러 서버 또는 노드에 걸쳐 저장하고 처리할 수 있도록 설계되었다는 것을 의미한다.
-
높은 가용성과 확장성 (High Availability and Scalability)
: NoSQL은 높은 가용성과 확장성을 제공하여 시스템이 확장될 때 성능이 떨어지지 않도록 한다. -
다양한 데이터 모델
: NoSQL은 다양한 데이터 모델을 지원한다. 주요 모델로는 문서 지향, 키-값, 와이드 컬럼, 그래프 등이 있다.
4. NoSQL 데이터 타입
- 정형 데이터 (Structured Data)
: 정해진 스키마에 따라 구조화된 데이터로, 관계형 데이터베이스나 스프레드시트, CSV와 같은 형식에서 사용된다. (Like RDBMS)
- 예시) 관계형 데이터베이스의 테이블 데이터
| ID | Name | Age | City | |----|---------|-----|------------| | 1 | Alice | 30 | New York | | 2 | Bob | 25 | San Francisco |
- 반정형 데이터 (Semi-Structured Data)
: 일정한 구조를 가지고 있지만 전체적인 데이터 모델에 엄격하게 준수하지 않는 데이터로, XML, JSON, HTML, 로그와 같은 형식에서 사용된다.
- 예시) JSON 데이터
{ "user": { "name": "Alice", "age": 30, "address": { "city": "New York" } } }
- 비정형 데이터 (Unstructured Data)
: 구조나 형태가 없으며, 연산이 어려운 데이터로, 영상, 이미지, 음성, 텍스트 등이 해당됩니다.
- 예시) 이미지 데이터, 음성 데이터, 텍스트 문서
(파일 경로를 지정하여 NoSQL에 저장하면 저장이 됩니다. 다만, 보통은 위와 같은 비정형 데이터들은 S3와 같은 저장소에 업로드한 다음 링크를 저장하는 방식을 많이 사용합니다.)
NoSQL 데이터베이스는 이러한 다양한 형태의 데이터를 효과적으로 저장하고 검색할 수 있도록 설계되어 있다. 각 데이터 모델에 따라 NoSQL은 정형, 반정형, 비정형 데이터를 다루는 데 있어 강점을 가지고 있다.
5. NoSQL 주요 종류
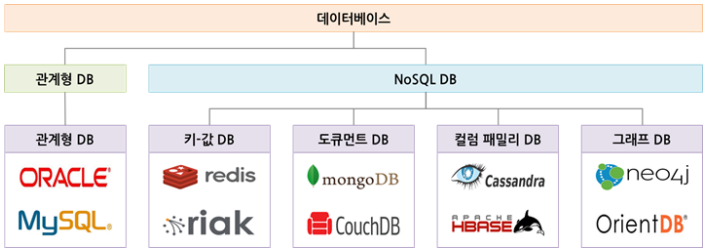
- 문서 지향 데이터베이스(Document Stores)
: MongoDB, CouchDB
- NoSQL에서 가장 많이 사용되는 타입 중 하나
- 데이터를 JSON이나 BSON과 같은 문서 형식으로 저장하는 방식
- 여러 필드를 포함하고 있어 복잡한 구조의 데이터를 표현 가능
- 예시)
{ "_id": ObjectId("5f3c92c8e948af08996285a4"), "name": "John Doe", "age": 30, "address": { "city": "New York", "zip": "10001" }, "interests": ["reading", "traveling"] }
- 키-값 데이터베이스(Key-Value Stores)
: Redis, DynamoDB
- 키와 값의 쌍으로 데이터를 저장하는 방식
- 주로 캐시나 설정 데이터와 같이 단순한 데이터에 사용
- 예시)
"user:1234" => {"username": "alice", "email": "alice@example.com"}
- 와이드 컬럼 데이터베이스(Wide-Column Stores)
: Cassandra, HBase
- 열 기반의 데이터 모델을 사용하여 테이블을 열의 집합으로 표현.
- Bigtable과 같은 모델로, 여러 개의 컬럼 패밀리(Column Family)를 가진 테이블로 데이터를 저장
- 각 로우는 다양한 수의 컬럼을 가질 수 있음
- 예시)
| Row Key | Column Family A | Column Family B | |--------------|------------------------|------------------------| | user1234 | {"name": "Alice"} | {"email": "alice@example.com"} | - 행 데이터에 컬럼이 포함되며, 슈퍼 컬럼 페밀리의 각 행은 하나 이상의 슈퍼 컬럼을 포함한다.
- 그래프 데이터베이스(Graph Databases)
: Neo4j, Amazon Neptune
- 계형 데이터(부모-자식 관계)를 표현하기 위해 그래프 구조를 사용하는 데이터 모델
- 노드(Node)와 엣지(Edge)로 구성
- 예시)
(Person)-[:FRIEND_OF]->(Person) - 2개의 Person 노드와 1개의 Location Residence 노드로 구성
- 위 두 사람이 거주하고 있는 주소지에 대한 정보를 담고 있음.
- 오브젝트 데이터베이스(Object-Oriented Databases)
: db4o, ObjectDB
- 객체 지향 프로그래밍의 객체를 직접적으로 데이터베이스에 저장하고 관리
- 관계형 데이터베이스와는 다르게 객체 간의 관계, 상속, 다형성과 같은 객체 지향 프로그래밍의 개념을 그대로 지원
- 예시)아래와 같은 Python 클래스가 있다고 가정한다.
위와 같은 클래스를 오브젝트 데이터베이스에 저장할 수 있다. 위 객체를 db4o 라이브러리를 사용한다면:class Person: def __init__(self, name, age): self.name = name self.age = age
이런식으로 객체를 데이터베이스에 저장하고, 객체 지향적인 쿼리를 사용하여 데이터를 검색할 수 있습니다. 이는 객체 지향 프로그래밍의 자연스러운 확장으로 볼 수 있으며, 객체 간의 관계를 더 직관적으로 표현할 수 있는 장점이 있다.# db4o를 사용한 데이터베이스 연결 database = db4o.openFile("people.db") # Person 객체 생성 및 저장 person1 = Person("Alice", 30) database.store(person1) person2 = Person("Bob", 25) database.store(person2) # 검색 예시 query = database.query() query.constrain(Person) query.descend("age").constrain(30).greater().andChain().descend("name").constrain("A").startsWith(False) result = query.execute() for person in result: print(f"Name: {person.name}, Age: {person.age}") # 데이터베이스 닫기 database.close()
6. 실제 활용 예시
- 웹 어플리케이션의 세션 관리
: 사용자가 로그인하면 웹 어플리케이션은 해당 사용자의 세션 정보(사용자 ID, 로그인 시간 등)를 저장해야 한다. Redis는 메모리 기반의 키-값 저장소로, 이러한 세션 데이터를 빠르게 저장하고 검색하여 웹 어플리케이션의 사용자 경험을 향상시키는 데 사용된다.
- flask, django등의 프레임워크들은 세션 기능을 제공하고있지만, 레디스의 키-벨류 세션을 활용하는 이유:
- Flask나 Django와 같은 웹 프레임워크는 기본적으로 서버의 로컬 메모리에 세션 데이터를 저장한다. 이 방식은 개발이나 트래픽이 적은 작은 어플리케이션에서는 충분할 수 있다. 그러나 사용자가 늘어나면 서버가 느려지거나 터지는 현상이 발생할 수 있다.
- 또한 기존 프레임워크들의 세션은 서버가 재시작되면 모두 삭제가 되지만, Redis는 서버가 재시작되더라도 데이터가 유실되지 않도록 디스크에 저장할 수 있다.
-
로그 및 이벤트 데이터 처리
: 대규모의 로그 데이터를 처리하는 경우 MongoDB와 Elasticsearch가 효과적이다. MongoDB는 JSON 형식의 문서를 저장하는데 용이하며, 로그 데이터를 구조화하여 쉽게 쿼리하고 분석할 수 있다. Elasticsearch는 로그 및 이벤트 데이터를 신속하게 색인화하여 검색 및 시각화에 사용된다. -
소셜 미디어 애플리케이션
: Neo4j와 같은 그래프 데이터베이스는 친구 관계를 그래프 형태로 모델링하는 데 적합하다. 예를 들어, 소셜 미디어에서 사용자 간의 친구 관계를 노드와 엣지로 표현하여 친구 추천이나 소셜 그래프 분석에 활용된다.
-
클라우드 기반 애플리케이션
: AWS DynamoDB는 NoSQL 데이터베이스로, 클라우드 기반의 웹 어플리케이션에서 사용자 데이터를 효과적으로 저장하고 관리하는 데 활용된다. 서버리스 아키텍처와의 통합을 통해 확장성과 가용성을 확보할 수 있다.
7. 추가 공부
- 여러 NoSQL을 찾아보고 리스트업
- Cassandra
- HBase
- Google BigTable
- Vertica
- Druid
- Accumulo
- HyperTable
- 자주 사용되는 2가지의 NoSQL에 대해서 정리
- 정리할 때는 Architecture에 대해서도 공부한다.
어떤 구조를 가졌길래 Document 방식의 문서 검색에 최적화되어있는 구조를 가지고 있는지?
왜 Redis는 key-value 형식의 캐쉬 서버로 많이 활용이 되고 있는지?
등..
8. 참고 공부 자료
02. NoSQL MongoDB
1. MongoDB
MongoDB란 NoSQL 데이터베이스의 한 종류로 문서 기반(Document-Oriented)의 데이터베이스 시스템이다.
관계형 데이터베이스의 테이블 대신 JSON/BSON 형식의 동적인 문서를 사용하여 데이터를 저장하고 조회한다.
→ 이러한 특징은 유연성, 확장성을 가져온다.
<주요 특징 및 개념>
-
문서 기반 데이터베이스
: MongoDB는 데이터를 문서(Document)라는 단위로 저장한다.
각 문서는 키-값 쌍으로 이루어진 BSON(Binary JSON) 형식으로 표현되며, 여러 문서가 컬렉션(Collection)에 저장된다. -
유연한 스키마
: MongoDB는 동적 스키마(Dynamic Schema)를 사용하므로, 각 문서가 다른 구조를 가질 수 있다. 필드를 동적으로 추가하거나 제거할 수 있어 데이터 모델의 변경이 유연하게 이루어진다. -
JSON/BSON 형식
: 데이터는 JSON과 유사한 문서 구조를 사용하며, BSON 형식으로 이진화되어 저장된다. 이는 대용량 데이터 처리 및 전송에서 성능 향상을 가져온다.
-
BSON이란?
: JSON의 이진 표현 형식으로, JSON과 유사하지만 이진 데이터로 표현된다.
MongoDB에서는 BSON 형식으로 데이터를 저장합니다.<JSON 코드>
{ "name": "John", "age": 30, "city": "New York" }<BSON 코드>
\x16\x00\x00\x00 // 전체 크기 \x02 // 문자열 타입 name\x00 // 필드 이름 \x04\x00\x00\x00John\x00 // 문자열 값 \x10\x00 // 16 (숫자 타입) age\x00\x00\x00 // 필드 이름 \x1E\x00\x00\x00 // 30 (숫자 값) \x02\x00 // 문자열 타입 city\x00 // 필드 이름 \x0C\x00\x00\x00New York\x00 // 문자열 값 \x00 // 마지막- BSON은 이진 형식이므로 직렬화 및 역직렬화가 JSON보다 빠르게 이루어집니다. MongoDB는 BSON을 내부 저장 형식으로 사용하므로 데이터베이스의 입출력이 효율적으로 처리됩니다.
- 높은 확장성
: MongoDB는 수평적 확장이 가능하다.
여러 서버에 데이터를 분산하고 데이터베이스의 용량을 증가시킬 수 있어 대규모 애플리케이션에 적합하다.
- 수평적 확장
: 수평적 확장을 위해선 데이터의 파티셔닝이나 샤딩(Sharding)과 같은 기술이 필요하며, 이는 구현 및 관리가 복잡할 수 있다.
MongoDB는 처음부터 수평적 확장을 염두에 두고 설계되었으며, 데이터를 자동으로 분산 및 관리하는 기능을 내장하고 있어 비교적 쉽게 수평적 확장이 가능하다.
-
인덱싱과 검색 기능
: MongoDB는 인덱싱을 지원하여 데이터의 검색 속도를 향상시킨다. 다양한 쿼리와 검색 연산자를 활용하여 유연한 데이터 검색이 가능하다. -
자동 샤딩(Sharding)
: 대용량의 데이터를 처리하기 위해 자동 샤딩 기능을 제공한다. 이를 통해 데이터베이스가 수평으로 확장되어 성능을 유지할 수 있다.
-
샤딩(Sharding)
Sharding — MongoDB Manual- 샤딩 방식
-
Increased read/write throughput
: 병렬성을 활용하여 데이터 집합을 여러 샤드에 분산시켜 읽기/쓰기 처리량을 증가시킬 수 있다. 예를 들어, 하나의 샤드가 초당 1,000개의 작업을 처리할 수 있다면, 각 추가 샤드는 처리량을 1,000개씩 더 늘려준다.- 요약: 데이터를 여러 샤드에 분산시켜 병렬로 작업을 수행하므로 읽기/쓰기 처리량이 증가하며, 각 샤드 추가는 처리량을 선형적으로 확장시킨다.
-
Data Locality
: Zone Sharding을 사용하면 지리적으로 분산된 애플리케이션을 지원하기 위해 분산 데이터베이스를 손쉽게 생성할 수 있으며, 데이터 유지 정책은 특정 지역 내에서 데이터 저장을 강제화한다. 각 지역은 하나 이상의 샤드를 가질 수 있다.- 요약: Zone Sharding을 통해 지리적으로 분산된 애플리케이션을 지원하고, 데이터의 저장 위치를 특정 지역에 강제화하여 데이터의 지역성을 제어할 수 있다.
2. 기본 설치
-
MongoDB 공식 사이트에서 설치 파일을 다운 받는다. (윈도우)
MAC의 경우 MongoDB 공식 사이트 다른 페이지를 참고해서 설치한다. -
Studio 3T 설치 (MongoDB GUI Tool)
Free ver. 프로그램 다운로드 사이드에서 파일을 다운받아 설치한다. -
Studio 3T에서
Create a New connection하기.
3. MongoDB 기본 구조
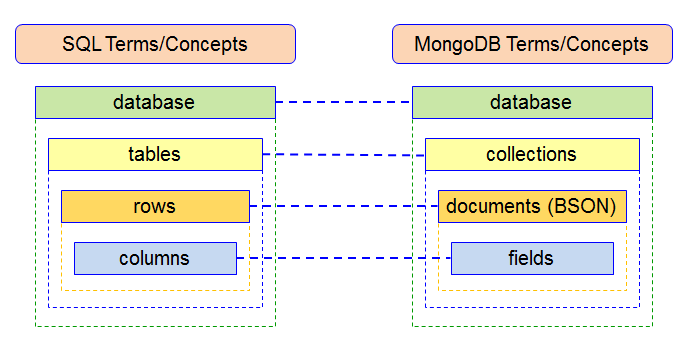
1) MongoDB의 구조: Database - Collection - Document
(RDBMS의 구조: Database - Table - Row, Data)
- Database (데이터베이스)
- MongoDB는 여러 개의 데이터베이스를 가질 수 있다. 각 데이터베이스는 독립적으로 관리되고 여러 컬렉션을 포함할 수 있다.
- 데이터베이스는 일반적으로 관련된 데이터를 그룹화하는 데 사용된다.
- Collection (컬렉션)
- 컬렉션은 문서(Document)의 그룹이다. 테이블과 유사하게 데이터를 저장하며 스키마가 없어 유연한 구조를 가지고 있다.
- 서로 다른 Document들이 하나의 컬렉션에 저장될 수 있다.
- Document (문서)
- 문서는 MongoDB에서의 기본 데이터 단위로, JSON 형태의 키-값 쌍을 갖는다.
- 각 문서는 서로 다른 구조를 가질 수 있으며, 필요에 따라 필드를 동적으로 추가할 수 있다.
- Document는 Collection 내에 저장되며, 각 Document는 고유한 ObjectId를 가진다.
-
예시
1) MongoDB Collection:{ "collection_name": "users", // LIKE TABLE IN MySQL "documents": [ { "_id": ObjectId("5fde7b8e69e01b3f95277b10"), "name": "John Doe", "age": 30, "city": "New York", "skills": ["JavaScript", "Python", "MongoDB"], "address": { "street": "123 Main St", "city": "New York", "zipcode": "10001" } }, { "_id": ObjectId("5fde7c1569e01b3f95277b11"), "name": "Jane Smith", "age": 25, "city": "San Francisco", "skills": ["Java", "C++", "SQL"], "address": { "street": "456 Oak St", "city": "San Francisco", "zipcode": "94105" } }, // Additional documents... ] }- 표가 문서 형태로 저장된 것이라고 볼 수 있다.
2) MongoDB Document:
{ "_id": ObjectId("5fde7b8e69e01b3f95277b10"), "name": "John Doe", "age": 30, "city": "New York", "skills": ["JavaScript", "Python", "MongoDB"], "address": { "street": "123 Main St", "city": "New York", "zipcode": "10001" } }
2) RDBMS의 구조와의 비교
- Database (데이터베이스)
- RDBMS에서의 Database는 일반적으로 정형화된 테이블들을 그룹화하고, 각 테이블은 고정된 스키마를 가진다.
- Table (테이블)
- RDBMS의 Table은 정해진 스키마를 가진 열과 행의 구조로 이루어져 있다.
- 각 테이블은 레코드(행) 단위로 데이터를 저장하며, 각 레코드는 미리 정의된 열에 맞춰진 데이터를 가진다.
- Row (레코드)
-
RDBMS에서의 레코드는 각각의 테이블에 속하는 하나의 행을 나타낸다.
-
각 레코드는 테이블의 스키마에 따라 고정된 구조를 가지고 있다.
3) 차이점 및 장점
- 유연성과 동적 스키마
- MongoDB는 동적 스키마를 허용하여 데이터의 유연한 구조를 제공한다.
- RDBMS는 정적인 스키마를 가지고 있어 데이터 모델을 변경하려면 일정한 절차가 필요하다.
- 수평적 확장
- MongoDB는 수평적 확장(Shading)이 가능하며, 여러 서버에 데이터를 분산하여 대용량 데이터를 처리할 수 있다.
- RDBMS는 주로 수직적 확장이 일반적이며, 서버의 성능을 업그레이드하는 방식으로 확장된다.
4. MongoDB 기본 명령어 (데이터베이스, 컬렉션 관련)
1) 데이터베이스 관련 명령어
- 데이터베이스 생성 또는 전환
use [데이터베이스 이름]- 지정된 데이터베이스로 전환하거나 없으면 새로 생성한다.
- 현재 데이터베이스 확인
db- 현재 사용 중인 데이터베이스를 표시한다.
- 데이터베이스 목록 조회
show dbs- 서버에 존재하는 모든 데이터베이스 목록을 보여준다.
- 데이터베이스 삭제
db.dropDatabase()- 현재 선택된 데이터베이스를 삭제한다.
- 데이터베이스 상태 확인
db.stats()- 현재 데이터베이스의 통계 정보를 제공한다.
2) 컬렉션 관련 명령어 예제
- 컬렉션 생성
db.createCollection("users", { capped: false })
-
이 예제는 'users'라는 이름의 새로운 컬렉션을 생성한다.
capped옵션은 해당 컬렉션이 용량 제한이 있는지 여부를 결정한다. -
컬렉션 생성 관련 옵션
1) Capped 컬렉션 생성
db.createCollection("log", { capped: true, size: 100000 })- "log"라는 이름의 컬렉션을 생성하고, 이를 capped 컬렉션으로 지정한다.
size는 컬렉션의 최대 크기를 바이트 단위로 설정한다.
이 경우 컬렉션의 크기가 100,000바이트를 초과하면, 가장 오래된 문서부터 새 문서로 대체된다. (Like Black-box)
2) 문서 유효성 검사가 있는 컬렉션 생성
db.createCollection("contacts", { validator: { $jsonSchema: { bsonType: "object", required: ["phone"], properties: { phone: { bsonType: "string", description: "must be a string and is required" }, email: { bsonType: "string", pattern: "@mongodb\.com$", description: "must be a string and match the regular expression pattern" } } } } })- $ : 함수나 기능을 사용할때 사용한다.
- "contacts"라는 컬렉션을 생성한다.
이 컬렉션은 JSON 스키마를 사용하여 유효성 검사를 적용한다.
여기서는phone필드가 필수이며,email필드는 특정 패턴을 따라야 한다.
3) 특정 스토리지 엔진 옵션을 사용하는 컬렉션 생성
db.createCollection("myData", { storageEngine: { wiredTiger: { configString: "block_compressor=zlib" } } })-
"myData"라는 컬렉션을 생성하면서 WiredTiger 스토리지 엔진에 대한 특정 설정을 지정한다.
여기서는block_compressor옵션을zlib으로 설정하여 데이터 압축을 사용한다. -
storageEngine 옵션들
1) WiredTiger
- MongoDB 3.2 버전부터 기본 스토리지 엔진으로 사용된다.
- 고성능, 고압축, 멀티스레딩 지원 등이 특징이다.
- 문서 수준의 잠금(Document-Level Locking) 기능을 제공하여 동시성을 향상시킨다.
- 데이터 압축과 색인 압축을 지원한다.
2) In-Memory Storage Engine
- 데이터를 메모리 내에서만 관리하는 엔진이다.
- 높은 처리 속도와 낮은 지연 시간이 필요한 애플리케이션에 적합하다.
- 데이터 지속성은 제공하지 않으므로, 주로 캐시나 실시간 데이터 분석에 사용된다.
- In-Memory 방식을 사용할 때는 Redis라는 NoSQL을 많이 사용한다.
3) MMAPv1
- MongoDB 3.0 버전 이전의 기본 스토리지 엔진이다.
- 각 컬렉션별로 별도의 파일을 사용하며, 파일 레벨 잠금을 지원한다.
- WiredTiger에 비해 더 낮은 수준의 동시성과 압축 기능을 제공힌다.
- MongoDB 4.0 버전부터는 더 이상 기본 엔진으로 사용되지 않으며, 추후 버전에서는 지원이 중단될 예정이다.
4) RocksDB (써드파티)
- Facebook에서 개발한 Key-Value 스토어 기반의 스토리지 엔진이다.
- 고성능 쓰기 작업과 효율적인 스토리지 사용이 특징이다.
- WiredTiger와 비슷하게 문서 수준의 잠금 기능을 제공한다.
- 일부 MongoDB 배포판에서 선택적으로 사용할 수 있다.
- 컬렉션 목록 조회
show collections
- 현재 데이터베이스에 있는 모든 컬렉션의 목록을 표시한다.
- 컬렉션 이름 변경
db.users.renameCollection("customers")
- 'users' 컬렉션의 이름을 'customers'로 변경한다.
- 컬렉션 삭제
db.customers.drop()
-
'customers'라는 이름의 컬렉션을 삭제한다.
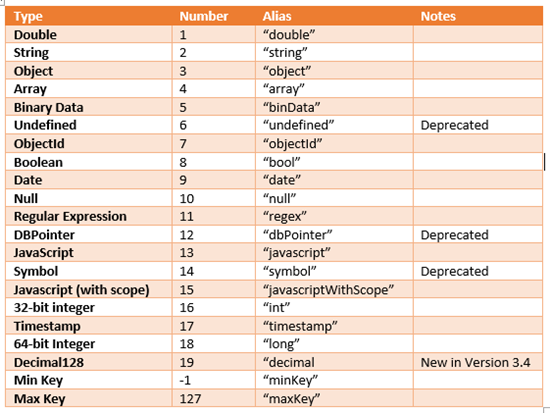
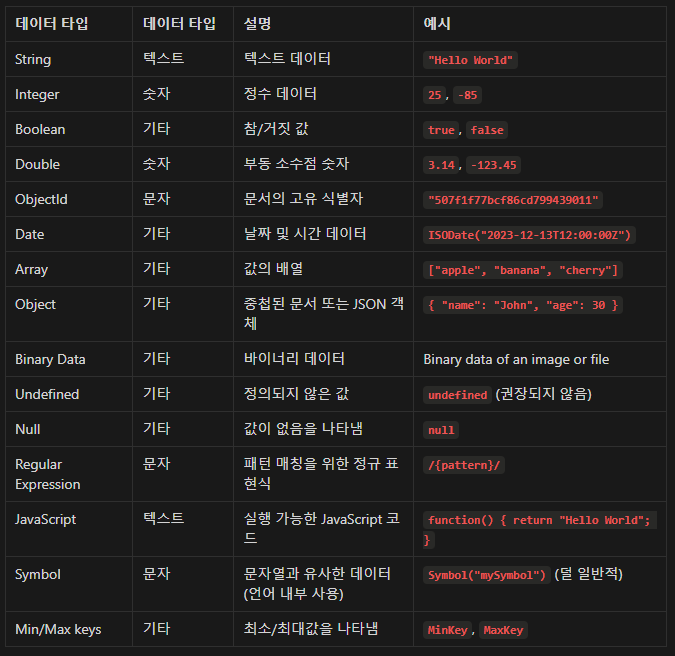
5. MongoDB 데이터 타입
6. MongoDB Query 기초 (CRUD)
db.createCollection("users", { capped: false })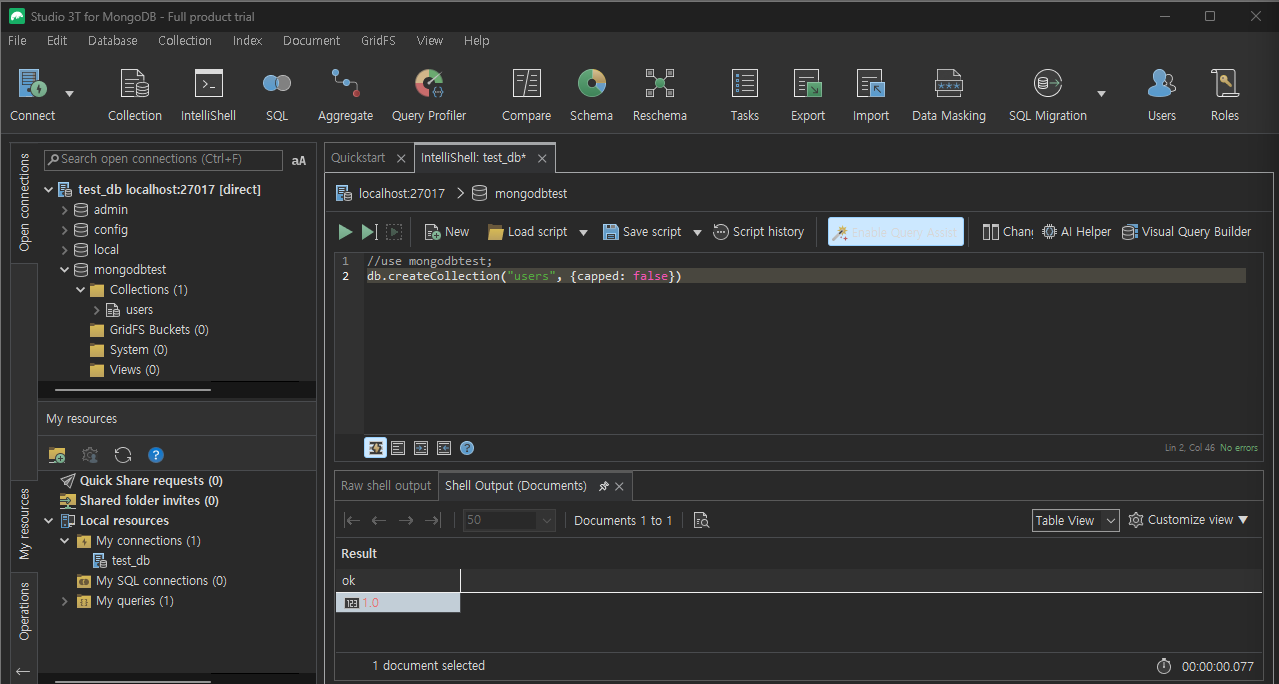
데이터 베이스를 하나 만들고, users라는 콜렉션을 하나 만들었다.
CRUD (Create, Read, Update, Delete) 중심으로 연습해봤다.
1) 생성 (Create)
// 기본 구조
db.(컬렉션 이름).insertOne({데이터 내용})
db.(컬렉션 이름).insertMany([{데이터 내용1}, {데이터 내용2}, ...])-
MongoDB
// 단일 문서 삽입 db.users.insertOne({ name: "Alice", age: 30, address: "123 Maple St" }) // 여러 문서 삽입 - 리스트 형식 db.users.insertMany([ { name: "Bob", age: 25, address: "456 Oak St" }, { name: "Charlie", age: 35, address: "789 Pine St" } ])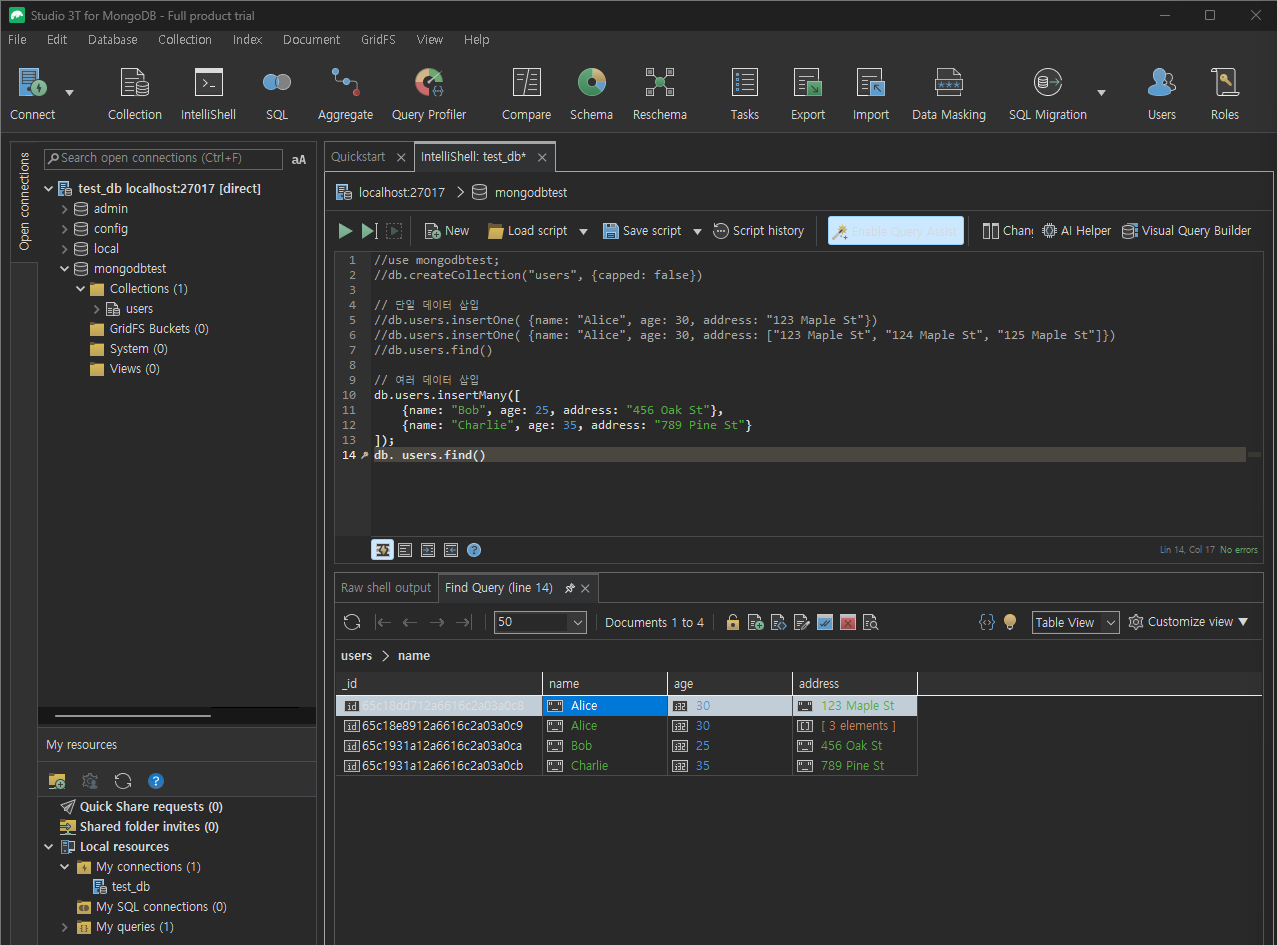
-
MySQL
-- 단일 레코드 삽입 INSERT INTO users (name, age, address) VALUES ('Alice', 30, '123 Maple St'); -- 여러 레코드 삽입 INSERT INTO users (name, age, address) VALUES ('Bob', 25, '456 Oak St'), ('Charlie', 35, '789 Pine St');
2) 읽기 (Read)
// 기본 구조
db.(컬렉션 이름).find({원하는 조건})-
MongoDB
// 모든 문서 조회 db.users.find() // 특정 필드 조회 db.users.find({}, { name: 1, address: 1 }) // 조건에 맞는 문서 조회 db.users.find({ address: "서울" })
-
MySQL
-- 모든 레코드 조회 SELECT * FROM users; -- 특정 열 조회 SELECT name, address FROM users; -- 조건에 맞는 레코드 조회 SELECT * FROM users WHERE address = '서울';
3) 갱신 (Update)
// 기본 구조
db.(컬렉션 이름).updateOne({업데이트할 데이터 조건}, {$set: {업데이트 할 내용}})
db.(컬렉션 이름).updateMany({업데이트할 데이터 조건}, {$set: {업데이트 할 내용}})-
MongoDB
// 특정 문서 업데이트 db.users.updateOne({ name: "Alice" }, { $set: { age: 31 } }) // 조건에 해당하는 첫번째 데이터만 변경 // 여러 문서 업데이트 db.users.updateMany({ address: "서울" }, { $set: { address: "부산" } }) // 조건에 해당하는 모든 데이터 변경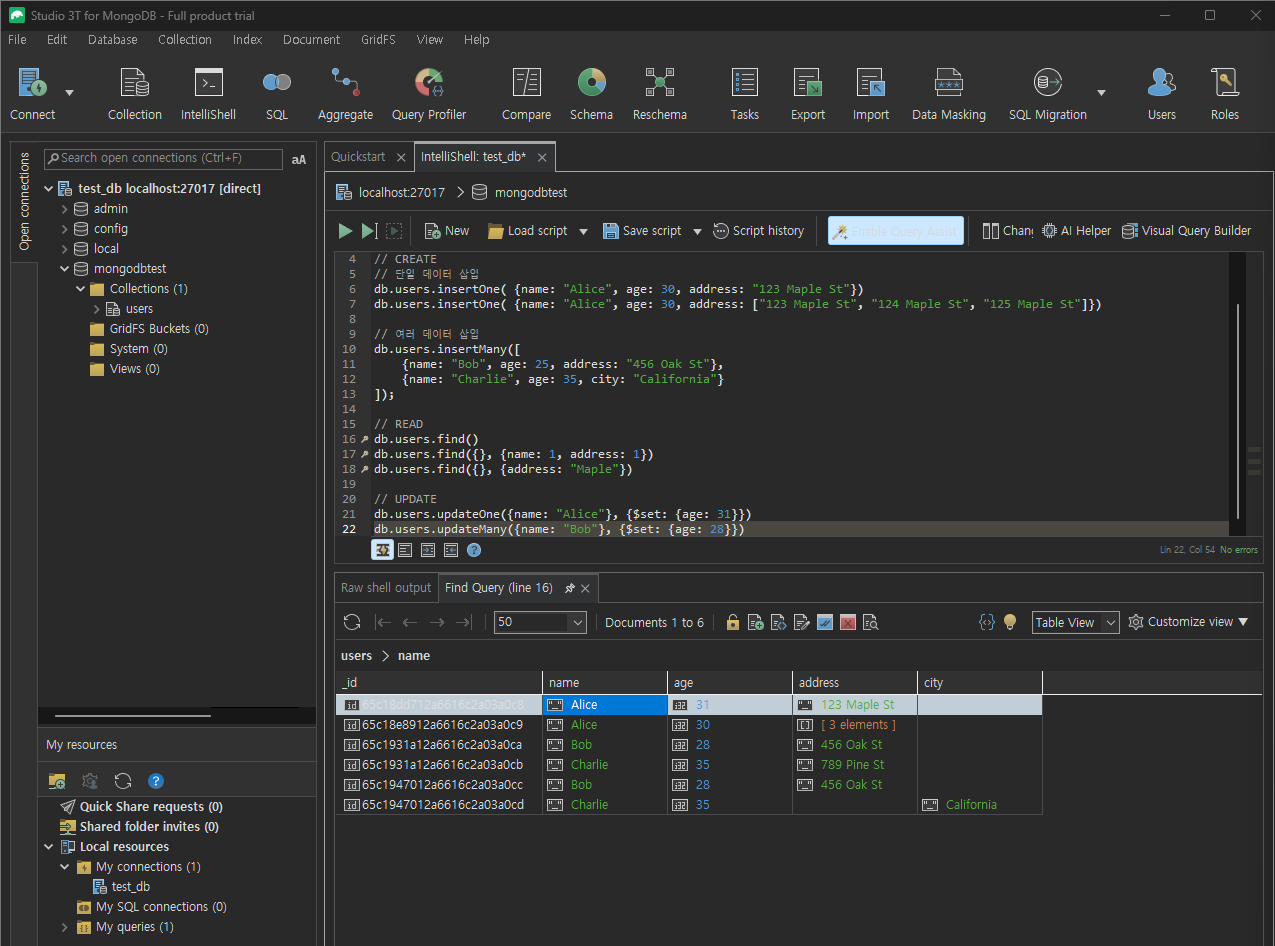
-
MySQL
-- 특정 레코드 업데이트 UPDATE users SET age = 31 WHERE name = 'Alice'; -- 조건에 맞는 여러 레코드 업데이트 UPDATE users SET address = '부산' WHERE address = '서울';
4) 삭제 (Delete)
// 기본 구조
db.(컬렉션 이름).deleteOne({삭제할 데이터 조건})
db.(컬렉션 이름).deleteMany({삭제할 데이터 조건})-
MongoDB
// 특정 문서 삭제 db.users.deleteOne({ name: "Alice" }) // 조건에 맞는 여러 문서 삭제 db.users.deleteMany({ address: "부산" })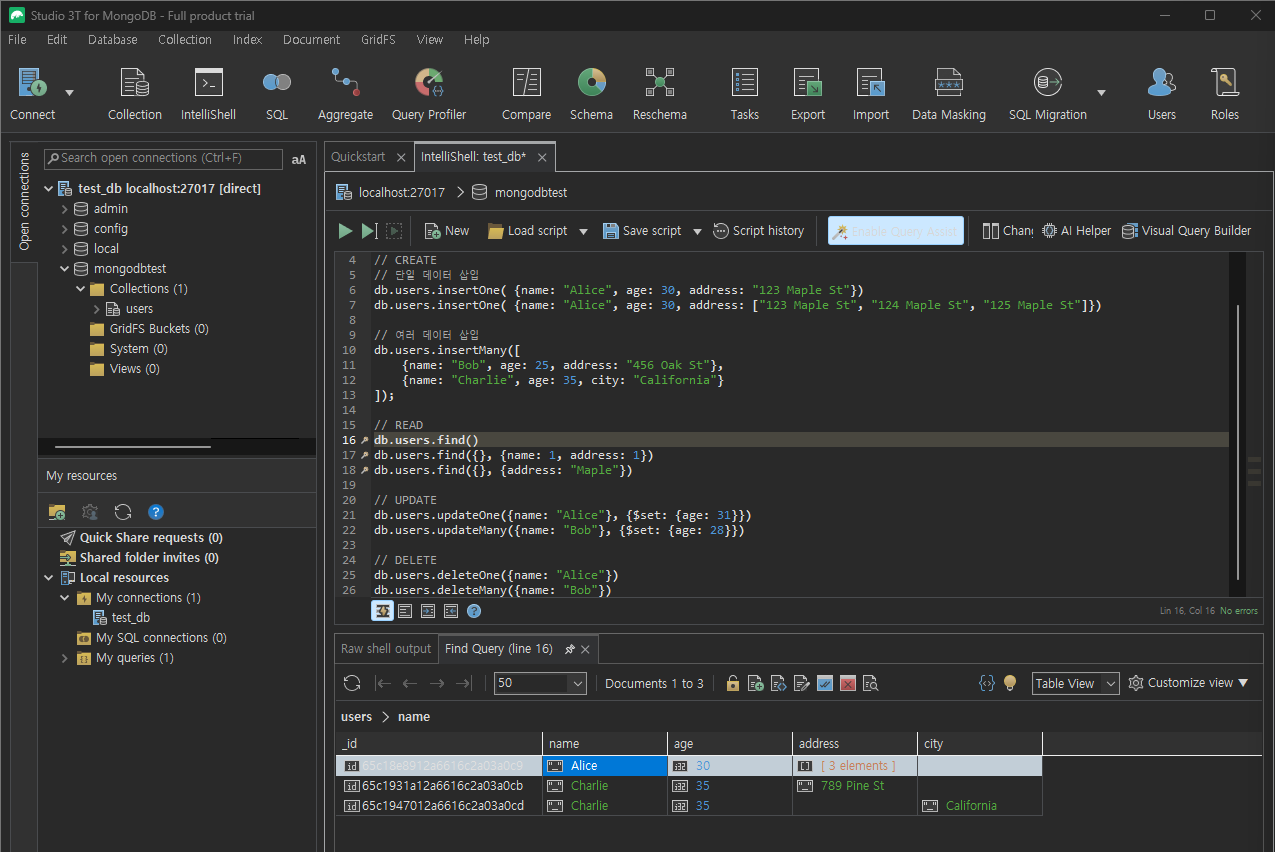
-
MySQL
-- 특정 레코드 삭제 DELETE FROM users WHERE name = 'Alice'; -- 조건에 맞는 여러 레코드 삭제 DELETE FROM users WHERE address = '부산';
※ MongoDB와 MySQL 주요 차이점
데이터 저장 방식과 쿼리 언어에 차이가 있다.
- MongoDB는 유연한 스키마를 가지고 JSON 스타일의 문서를 사용
→ 비정형 데이터와 빠른 개발이 필요한 경우 - MySQL은 엄격한 테이블 구조와 SQL 쿼리 언어를 사용
→ 복잡한 쿼리와 관계가 필요한 경우
5) 연습 문제
데이터가 따로 존재하지 않아 문제를 보고 코드를 작성하는 연습만 했다.
<초급>
(1) 생성
-
sports컬렉션에name: "Football",players: 11인 문서를 삽입db.sports.insertOne({ name: "Football", players: 11 })
(2) 읽기
-
products컬렉션에서price가 500보다 작거나 같은 모든 문서를 조회db.products.find({ price: { $lte: 500 } })$lte: 작거나 같은 값 (이하) (Less Than)
-
books컬렉션에서author가 "John Doe"인 모든 문서를 조회db.books.find({ author: "John Doe" })
(3) 업데이트
-
orders컬렉션에서status가 "Pending"인 모든 문서를 "Complete"로 변경db.orders.updateMany({ status: "Pending" }, { $set: { status: "Complete" } }) -
movies컬렉션에서genre가 "comedy"인 모든 문서의rating을 5로 변경db.movies.updateMany({ genre: "comedy" }, { $set: { rating: 5 } })
(4) 삭제
-
customers컬렉션에서age가 30 미만인 모든 문서를 삭제db.customers.deleteMany({ age: { $lt: 30 } })$lt: 작은 값 (미만) (Less)
<중급>
(1) 생성
-
myCollection컬렉션에 새로운 문서를 생성
문서는name: "Gadget",type: "Electronics",price: 300,ratings: [4, 5, 5]필드를 포함해야한다.db.myCollection.insertOne({ name: "Gadget", type: "Electronics", price: 300, ratings: [4, 5, 5] })
(2) 읽기
-
employees컬렉션에서department가 "Sales"이면서age가 30 이상인 모든 문서를 조회db.employees.find({ department: "Sales", age: { $gte: 30 } })$gte: 크거나 같은 값 (이상) (Greater Than)
-
employees컬렉션에서salary가 50000 이상인 문서를 찾되,name과title필드만 조회db.employees.find({ salary: { $gte: 50000 } }, { name: 1, title: 1 })
(3) 업데이트
-
products컬렉션에서stock필드가 없는 모든 문서에stock: 10을 추가db.products.updateMany({ stock: { $exists: false } }, { $set: { stock: 10 } })$exists: 데이터 유무 확인 가능. 값으로는 true, false를 사용한다.
-
vehicles컬렉션에서type이 "car"인 모든 문서에wheels: 4필드를 추가db.vehicles.updateMany({ type: "car" }, { $set: { wheels: 4 } })
(4) 삭제
-
orders컬렉션에서orderDate가 2023년 1월 1일 이전인 모든 문서를 삭제db.orders.deleteMany({ orderDate: { $lt: new Date('2023-01-01') } })newDate: 날짜 입력 함수
-
restaurants컬렉션에서rating이 3 미만인 모든 문서를 삭제db.restaurants.deleteMany({ rating: { $lt: 3 } })
<고급>
(1) 읽기
-
customers컬렉션에서age가 30 이상인 문서를 찾고, 결과를name으로 오름차순 정렬db.customers.find({ age: { $gte: 30 } }).sort({ name: 1 })sort: 정렬할 때 사용하는 함수.
-
users컬렉션에서birthdate가 1990년 이전인 사용자의 평균age를 계산하는 집계 쿼리를 작성db.users.aggregate([ { $match: { birthdate: { $lt: new Date('1990-01-01') } } }, { $group: { _id: null, avgAge: { $avg: "$age" } } } ])
(2) 업데이트
-
employees컬렉션에서department가 "HR"인 모든 문서의department를 "Human Resources"로,title을 "HR Manager"로 변경db.employees.updateMany( { department: "HR" }, { $set: { department: "Human Resources", title: "HR Manager" } } ) -
orders컬렉션에서delivered가false인 모든 문서에 현재 날짜를 나타내는deliveryDate필드를 추가db.orders.updateMany( { delivered: false }, { $set: { deliveryDate: new Date() } } )
(3) 삭제
-
products컬렉션에서lastModified필드가 30일 이상 된 모든 문서를 삭제db.products.deleteMany( { lastModified: { $lte: new Date(new Date() - 30 * 24 * 60 * 60 * 1000) } } ) -
products컬렉션에서stock이 0인 모든 문서를 삭제하세요.db.products.deleteMany({ stock: 0 })
7. MongoDB 비교문법 & 논리연산
[비교문법]
| 연산자 | 설명 | 예시 |
|---|---|---|
| $eq | 값이 지정된 값과 같은 경우 | db.myCollection.find({ age: { $eq: 30 } }) |
| $gt | 값이 지정된 값보다 큰 경우 | db.myCollection.find({ age: { $gt: 30 } }) |
| $gte | 값이 지정된 값보다 크거나 같은 경우 | db.myCollection.find({ age: { $gte: 30 } }) |
| $lt | 값이 지정된 값보다 작은 경우 | db.myCollection.find({ age: { $lt: 30 } }) |
| $lte | 값이 지정된 값보다 작거나 같은 경우 | db.myCollection.find({ age: { $lte: 30 } }) |
| $ne | 값이 지정된 값과 다른 경우 | db.myCollection.find({ age: { $ne: 30 } }) |
| $in | 값이 지정된 배열에 있는 경우 | db.myCollection.find({ age: { $in: [30, 35, 40] } }) |
| $nin | 값이 지정된 배열에 없는 경우 | db.myCollection.find({ age: { $nin: [30, 35, 40] } }) |
[논리연산]
| 연산자 | 설명 | 예시 |
|---|---|---|
| $and | 모든 조건이 참인 문서를 찾음 | db.myCollection.find({ $and: [{ age: { $gt: 20 } }, { age: { $lt: 30 } }] }) |
| $or | 하나 이상의 조건이 참인 문서를 찾음 | db.myCollection.find({ $or: [{ age: 20 }, { name: "Alice" }] }) |
| $not | 조건의 반대에 해당하는 문서를 찾음 | db.myCollection.find({ age: { $not: { $gt: 30 } } }) |
| $nor | 주어진 모든 조건이 거짓인 문서를 찾음 | db.myCollection.find({ $nor: [{ age: 20 }, { name: "Alice" }] }) |
이 연산자들은 특정 조건에 부합하는 문서를 찾거나 특정 조건을 제외한 문서를 찾는데 사용된다.
$and와 $or가 가장 자주 사용되며 복잡한 쿼리 조건을 구성하는데 필수적인 요소이다.
[연습 문제]
데이터가 따로 존재하지 않아 문제를 보고 코드를 작성하는 연습만 했다.
-
products컬렉션에서price가 100보다 큰 모든 문서 조회db.products.find({ price: { $gt: 100 } }) -
employees컬렉션에서age가 30보다 작거나department가 "HR"인 모든 문서 조회db.employees.find({ $or: [{ age: { $lt: 30 } }, { department: "HR" }] }) -
orders컬렉션에서quantity가 5 이상 10 이하인 모든 문서 조회db.orders.find({ quantity: { $gte: 5, $lte: 10 } }) -
customers컬렉션에서city가 "Seoul"이 아닌 모든 문서 조회db.customers.find({ city: { $ne: "Seoul" } }) -
movies컬렉션에서rating이 8 이상이고,genre가 "comedy" 또는 "drama"인 모든 문서 조회db.movies.find({ rating: { $gte: 8 }, genre: { $in: ["comedy", "drama"] } }) -
books컬렉션에서author가 "John Doe"이고publishedYear가 2000 이후인 모든 문서 조회db.books.find({ author: "John Doe", publishedYear: { $gt: 2000 } }) -
vehicles컬렉션에서type이 "car"가 아니고,price가 20000보다 큰 모든 문서 조회db.vehicles.find({ type: { $ne: "car" }, price: { $gt: 20000 } }) -
restaurants컬렉션에서rating이 5이고,cuisine이 "Italian" 또는 "French"가 아닌 모든 문서 조회db.restaurants.find({ rating: 5, cuisine: { $nin: ["Italian", "French"] } }) -
users컬렉션에서age가 30 이상이지만city가 "New York"이 아닌 모든 문서 조회db.users.find({ age: { $gte: 30 }, city: { $ne: "New York" } }) -
flights컬렉션에서departure가 "London"이거나arrival이 "Tokyo"인 모든 문서 조회db.flights.find({ $or: [{ departure: "London" }, { arrival: "Tokyo" }] })
8. MongoDB Aggregation 문법
MongoDB의 Aggregation Framework는 복잡한 데이터 처리 및 분석 작업을 위해 설계된 기능이다. 데이터를 변환하고, 결합하고, 계산할 수 있다.
-
예시
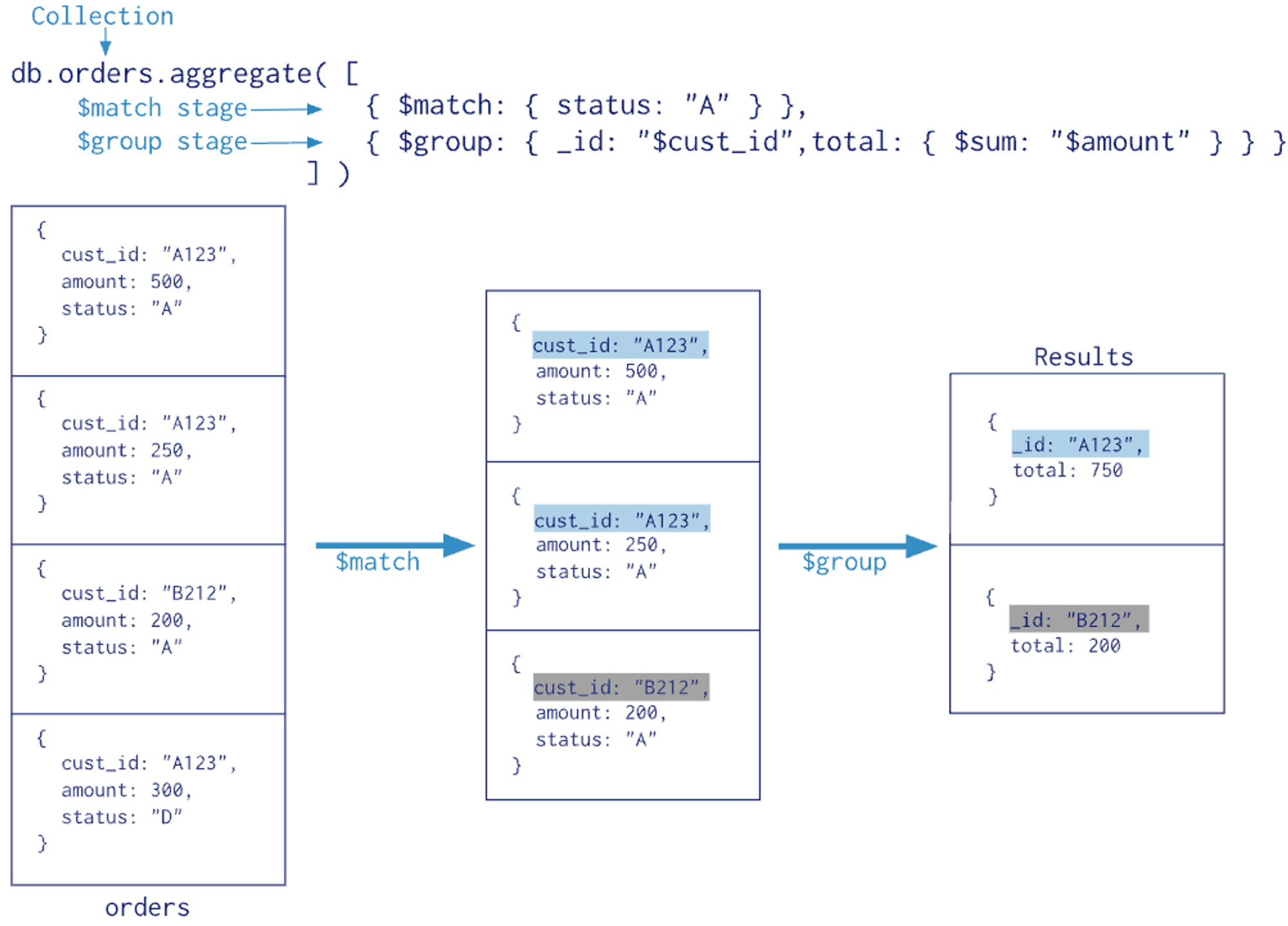
여러 document 들을 grouping 하여 연산을 수행한 후 하나의 result 를 반환하는 연산이다.
-
Aggregation Pipeline
: Aggregation Framework의 핵심 개념이다.
여러 단계(stage)를 통해 데이터를 처리한다. 각 단계는 입력으로 문서들을 받아, 변환을 수행하고, 출력으로 다음 단계로 문서들을 전달한다. -
Stages
: 각 단계는 특정 연산을 수행한다.
예를 들어, 필터링($match), 정렬($sort), 그룹화($group), 프로젝션($project) 등이 있다. -
Pipeline Operators
: 각 단계에서 사용되는 연산자다.
예를 들어,$sum,$avg,$min,$max,$group,$sort등이 있다.
users컬렉션에서 사용자들의 평균 나이를 계산하는 Aggregation Pipeline 예시가 아래와 같다.db.users.aggregate([ {$group: {_id: null, averageAge: {$avg: "$age"}}} ]);$group
: 이 단계에서는 문서들을 그룹화한다.
여기서는_id: null을 사용하여 모든 문서를 단일 그룹으로 묶는다.$avg: "$age"
: 각 사용자의age필드의 평균을 계산한다.
-
※ Aggregation 문법에서 사용되는 함수들
-
$match
: 데이터를 필터링한다.
예시) age가 30 이상인 문서만 선택db.collection.aggregate([ { $match: { age: { $gte: 30 } } } ]) -
$group
: 데이터를 그룹화하고 집계한다.
예시) 각 department 별로 평균 salary 계산db.collection.aggregate([ {$group: {_id: "$department", averageSalary: {$avg: "$salary"}}} ]) -
$project
: 특정 필드를 선택하거나 새로운 필드를 생성한다.
예시) name과 age 필드만 표시db.collection.aggregate([ { $project: { name: 1, age: 1 } } ]) -
$sort
: 결과를 정렬한다.
예시) age 필드로 오름차순 정렬db.collection.aggregate([ { $sort: { age: 1 } } ]) -
$limit
: 결과의 개수를 제한한다.
예시) 상위 5개 문서만 반환db.collection.aggregate([ { $limit: 5 } ]) -
$skip
: 특정 개수의 문서를 건너뛴다.
예시) 처음 10개 문서를 건너뛰고 그 다음 문서들 반환db.collection.aggregate([ { $skip: 10 } ]) -
$unwind
: 배열 필드를 개별 문서로 분리한다.
예시) interests 배열의 각 항목을 별도의 문서로 분리db.collection.aggregate([ { $unwind: "$interests" } ]) -
$lookup
: 다른 컬렉션과의 조인을 수행한다.
예시) orders 컬렉션과 customers 컬렉션을 customerId로 조인db.orders.aggregate([ { $lookup: { from: "customers", // 조인할 다른 컬렉션의 이름 localField: "customerId", // 현재 컬렉션(orders)의 필드 foreignField: "_id", // 조인 대상 컬렉션(customers)의 필드 as: "customerDetails" // 조인된 문서들이 저장될 새 필드의 이름 } ])
03. Python으로 다루는 MongoDB
0. 기본 설치
<Window 용>
> pip install pymongo<MAC 용>
> pip3 install pymongo1. MongoDB 데이터베이스에 연결하기
from pymongo import MongoClient
# MongoDB 인스턴스에 연결
client = MongoClient('mongodb://localhost:27017/')
# client = MongoClient('mongodb://username:password@localhost:27017/')
client
# [출력] MongoClient(host=['localhost:27017'], document_class=dict, tz_aware=False, connect=True)# 데이터베이스 선택 (없으면 자동 생성)
db = client['example_db']
db
# [출력] Database(MongoClient(host=['localhost:27017'], document_class=dict, tz_aware=False, connect=True), 'example_db')2. 콜렉션 생성 및 문서 삽입
# 콜렉션 선택 (없으면 자동 생성)
collection = db['example_collection']
collection
# [출력] Collection(Database(MongoClient(host=['localhost:27017'], document_class=dict, tz_aware=False, connect=True), 'example_db'), 'example_collection')# 새 문서 삽입
example_document = {"name": "John", "age": 30, "city": "New York"}
collection.insert_one(example_document)
# [출력] InsertOneResult(ObjectId('65c1cb6678a4ce9ff1d39d35'), acknowledged=True)여러 문서를 한번에 넣고 싶다면 insert_many를 하면 된다.
3. 문서 조회하기
# 모든 문서 조회
for doc in collection.find():
print(doc)
# [출력] {'_id': ObjectId('65c1cb6678a4ce9ff1d39d35'), 'name': 'John', 'age': 30, 'city': 'New York'}여러 문서가 들어가 있다면 ObjectID가 매겨지면서 여러 문서 리스트를 볼 수 있다.
# 조건에 맞는 문서 조회
query = {"name": "John"}
for doc in collection.find(query):
print(doc)
# [출력] {'_id': ObjectId('65c1cb6678a4ce9ff1d39d35'), 'name': 'John', 'age': 30, 'city': 'New York'}4. 문서 업데이트하기
# 하나의 문서 업데이트
collection.update_one({"name": "John"}, {"$set": {"age": 31}})
for doc in collection.find():
print(doc)
# [출력]
# {'_id': ObjectId('65c1cb6678a4ce9ff1d39d35'), 'name': 'John', 'age': 31, 'city': 'New York'}
# {'_id': ObjectId('65c1cc1a78a4ce9ff1d39d36'), 'name': 'John', 'age': 30, 'city': 'New York'}
# {'_id': ObjectId('65c1cc1d78a4ce9ff1d39d37'), 'name': 'John', 'age': 30, 'city': 'New York'}하나의 데이터 나이만 확인할 수 있다.
# 여러 문서 업데이트
collection.update_many({"name": "John"}, {"$set": {"age": 32}})
for doc in collection.find():
print(doc)
# [출력]
# {'_id': ObjectId('65c1cb6678a4ce9ff1d39d35'), 'name': 'John', 'age': 32, 'city': 'New York'}
# {'_id': ObjectId('65c1cc1a78a4ce9ff1d39d36'), 'name': 'John', 'age': 32, 'city': 'New York'}
# {'_id': ObjectId('65c1cc1d78a4ce9ff1d39d37'), 'name': 'John', 'age': 32, 'city': 'New York'}5. 문서 삭제하기
# 하나의 문서 삭제
collection.delete_one({"name": "John"})
for doc in collection.find():
print(doc)
# [출력]
# {'_id': ObjectId('65c1cc1a78a4ce9ff1d39d36'), 'name': 'John', 'age': 32, 'city': 'New York'}
# {'_id': ObjectId('65c1cc1d78a4ce9ff1d39d37'), 'name': 'John', 'age': 32, 'city': 'New York'}# 여러 문서 삭제
collection.delete_many({"name": "John"})6. 콜렉션 및 데이터베이스 삭제하기
# 콜렉션 삭제
db.drop_collection("example_collection")
# 데이터베이스 삭제
client.drop_database("example_db")[DB 4일차 후기]
데이터 베이스 교육이 끝이 났다.
다양한 데이터를 수집하고 분류하고 조회하고 업데이트 하는 것이 꽤나 재밌었다!
문제 푸는 과제가 많아서 손가락이 좀 아팠지만 ㅋㅋㅋ
생각보다 단순하고 함수만 많이 알면 더 효율적으로 코드를 작성해서 원하는 데이터를 뽑아낼 수 있을거 같다.
이제 과제 큰게 하나가 남아서 그것만 잘 해결하고 웹 스크랩핑 과제까지 잘 마무리 되었으면 좋겠다!💪🏻
[참고 자료]
- [오즈스쿨 스타트업 웹 개발 초격차캠프 백엔드 데이터베이스 강의]
