
2일차에는 MySQL의 다양한 명령어로 데이터를 생성(CREATE, INSERT)하고, 조회(SELECT)하고 업데이트(UPDATE)해보았다. Python으로 랜덤한 자료를 받아서 조인(JOIN)도 해보았다.
간단한 실습 2가지를 진행했는데
내가 직접 Schema를 만드는 것과 (Database & tables)
예시로 주어진 데이터에서 원하는 데이터들을 조회 및 필터링, JOIN, GROUP, 그리고 기타 여러 기능과 데이터 수정 및 관리를 해보았다. (이부분은 어려워 보이지만 테이블간 관계를 이해하고 연습하다보면 쉬워질 수도!)
ERD라는 프로그램을 이용해서 만든 Schema를 도식화해 이해하기 편하게 해주는 것이 있다는 것을 알게 되었다.
01. PyMySQL
1. PyMySQL
PyMySQL은 Python에서 MySQL 데이터베이스를 사용하기 위한 라이브러리다. PyMySQL을 사용하면 Python 코드를 통해 MySQL 데이터베이스에 접속하고, 데이터를 조회, 삽입, 수정, 삭제할 수 있다.
기본적으로 사용하기에는 괜찮으나 이후 보안이나 속도에 있어서 Flask나 Django를 통해 데이터 베이스에 접근하는게 안전하다.
PyMySQL 공식 홈페이지에서 제공하는 다큐멘테이션과 예시를 가지고 진행할 예정이다.
2. PyMySQL 설치
-
PyMySQL 작업 폴더를 하나 만들어주고 VS Code에서 열어준다.
-
터미널에서 터미널이나 명령 프롬프트에서 다음 명령어를 실행하여 PyMySQL을 설치한다.
<Window> pip install pymysql <MAC> pip3 install pymysql -
PyMySQL 작업 폴더에 새로운 파일을 만들고 MySQL 데이터 베이스에 접속하는 기본적인 코드를 작성한다. 기본적인 구조는 아래 코드와 같다.
접근하는 데이터 베이스는 지난 실습에 받아둔 예시 'classicmodels'를 활용한다.import pymysql # 데이터베이스 연결 설정 connection = pymysql.connect(host='localhost', user='root', password='본인 비밀번호', db='classicmodels', charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor) try: # 커서 생성 with connection.cursor() as cursor: # SQL 쿼리 실행 sql = "원하는 Query 작성" cursor.execute(sql) # 결과 받아오기 result = cursor.fetchall() print(result) finally: # 데이터베이스 연결 종료 connection.close()-
charset='utf8mb4'- 이 설정은 데이터베이스 연결에 사용되는 문자 집합을 지정한다.
utf8mb4는 MySQL에서 유니코드를 완벽하게 지원하기 위한 문자 집합으로, 이모지를 포함한 모든 유니코드 문자를 지원한다.- 데이터베이스에 다양한 언어의 문자 데이터를 저장하거나, 이모지 등의 4바이트 유니코드 문자를 사용할 경우 이 설정이 필요하다.
-
cursorclass-
Default Cursor (
pymysql.cursors.Cursor)
: 기본 커서 클래스로, 결과를 튜플 형식으로 반환한다.
각 행은 값들의 튜플로 나타나며, 열 이름 정보는 포함하지 않는다. -
DictCursor (
pymysql.cursors.DictCursor)✅
: 이 커서 클래스는 결과를 딕셔너리 형식으로 반환한다.
각 행은 열 이름을 키로 하고 해당 데이터를 값으로 하는 딕셔너리로 나타난다. 이는 결과를 처리할 때 열 이름으로 데이터에 접근할 수 있게 해줘 편리하다. -
SSCursor (
pymysql.cursors.SSCursor)
: 서버 사이드 커서로, 큰 결과 집합을 처리할 때 유용하다.
이 커서는 모든 결과를 한 번에 메모리에 로드하지 않고, 필요할 때마다 서버에서 행을 가져온다. -
SSDictCursor (
pymysql.cursors.SSDictCursor)
: 서버 사이드 딕셔너리 커서로,SSCursor의 기능에 딕셔너리 형식의 결과 반환을 추가한 것이다. 큰 데이터 집합에서 열 이름으로 데이터에 접근해야 할 때 유용하다. -
cursorclass=pymysql.cursors.DictCursor
- 이 설정은 데이터베이스 쿼리의 결과를 어떻게 반환할지 결정한다.
- 기본적으로 PyMySQL은 쿼리 결과를 튜플(tuple) 형태로 반환한다.
-DictCursor를 사용하면 쿼리 결과를 딕셔너리(dictionary) 형태로 받을 수 있어, 각 열의 이름으로 결과에 접근할 수 있다. 이는 결과 데이터를 처리할 때 더 직관적이고 편리할 수 있다.{ 'column_name1': 'value1', 'column_name2': 'value2', ... } -
DictCursor와SSDictCursor
DictCursor와SSDictCursor는 PyMySQL에서 사용되는 두 종류의 커서다. 두 커서 모두 쿼리 결과를 딕셔너리 형식으로 반환하는 것은 같지만, 데이터를 처리하는 방식에서 차이가 있다.
-DictCursor
: 쿼리 결과를 딕셔너리 형식으로 반환한다.
이 경우, 쿼리의 전체 결과가 클라이언트의 메모리에 한 번에 로드된다. 이 방식은 결과 집합이 상대적으로 작을 때 효과적이다.
-SSDictCursor(Server-Side DictCursor)
: 쿼리 결과를 딕셔너리 형식으로 반환하지만, 서버 사이드 커서의 특징을 가진다.
즉, 쿼리의 전체 결과를 한 번에 메모리에 로드하지 않고, 필요할 때마다 서버에서 데이터를 가져온다. 이는 큰 결과 집합을 처리할 때 메모리 사용량을 줄이고 효율을 높이는 데 유용하다.
결론적으로, 작은 데이터 세트를 다룰 때는
DictCursor를, 큰 데이터 세트를 다룰 때는SSDictCursor를 사용하는 것이 더 효율적이다.
그러나SSDictCursor는 데이터를 서버에서 점진적으로 가져오기 때문에, 작은 데이터 세트에 대해서도 사용할 수 있지만, 이 경우에는DictCursor에 비해 약간의 오버헤드가 발생할 수 있다.
따라서 적절한 커서 선택은 사용 사례와 데이터 세트의 크기에 따라 달라질 수 있다. -
-
3. 데이터 다루기
위 코드에서 try: 문에 어떤 코드를 넣는지에 따라 데이터를 원하는대로 다룰 수 있다.
1. 데이터 조회(SELECT)
MySQL 데이터베이스에서 데이터를 조회하는 기본 구조 코드이다.
try:
with connection.cursor() as cursor:
sql = "SELECT * FROM table_name"
cursor.execute(sql)
result = cursor.fetchall()
for row in result:
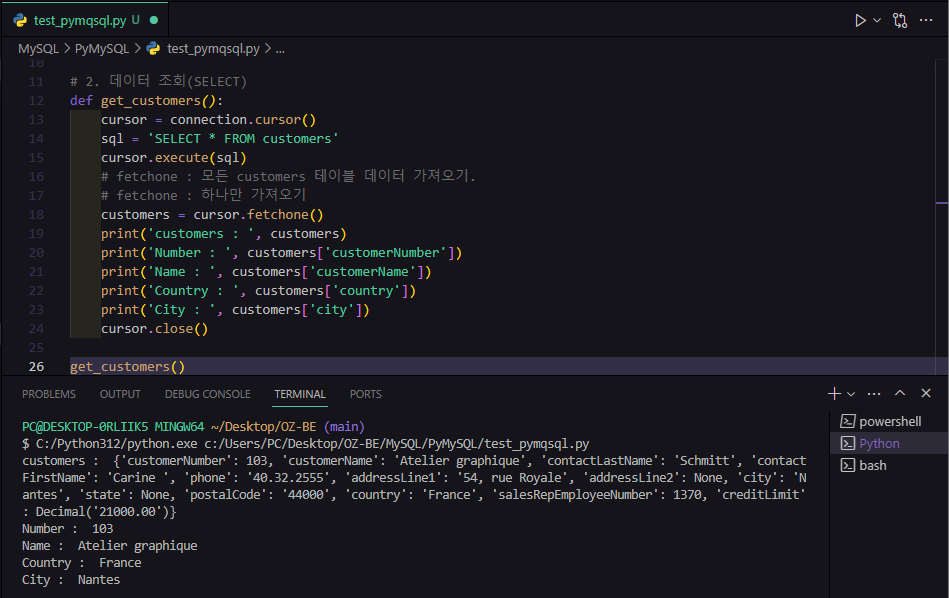
print(row)나는 customers라는 테이블을 조회했다.
함수를 사용해서 작동했다.
def get_customers():
cursor = connection.cursor()
sql = 'SELECT * FROM customers'
cursor.execute(sql)
# fetchone : 모든 customers 테이블 데이터 가져오기.
# fetchone : 하나만 가져오기
customers = cursor.fetchone()
print('customers : ', customers)
print('Number : ', customers['customerNumber'])
print('Name : ', customers['customerName'])
print('Country : ', customers['country'])
print('City : ', customers['city'])
cursor.close()<결과>
2. 데이터 삽입 (INSERT)
데이터를 삽입하는 기본 구조 코드이다. 삽입, 수정, 삭제시에는 connection.commit() 문을 넣어 데이터 베이스에 반영해줘야한다.
try:
with connection.cursor() as cursor:
sql = "INSERT INTO table_name (column1, column2) VALUES (%s, %s)"
cursor.execute(sql, ('data1', 'data2'))
# 변경 사항 저장
connection.commit()나는 customers라는 테이블에 새로운 고객으로 나를 넣어봤다.
넣기 전에 customers라는 테이블에 컬럼들 중 NOT NULL 항목들이 있는지 확인하고 NOT NULL 항목만 값을 넣어봤다.
def add_customer() :
cursor = connection.cursor()
name = 'Minjung'
country = 'South Korea'
city = 'Seoul'
sql = f"INSERT INTO customers(customerNumber, customerName, country, city) VALUES (500, '{name}', '{country}', '{city}')"
cursor.execute(sql)
connection.commit()
cursor.close()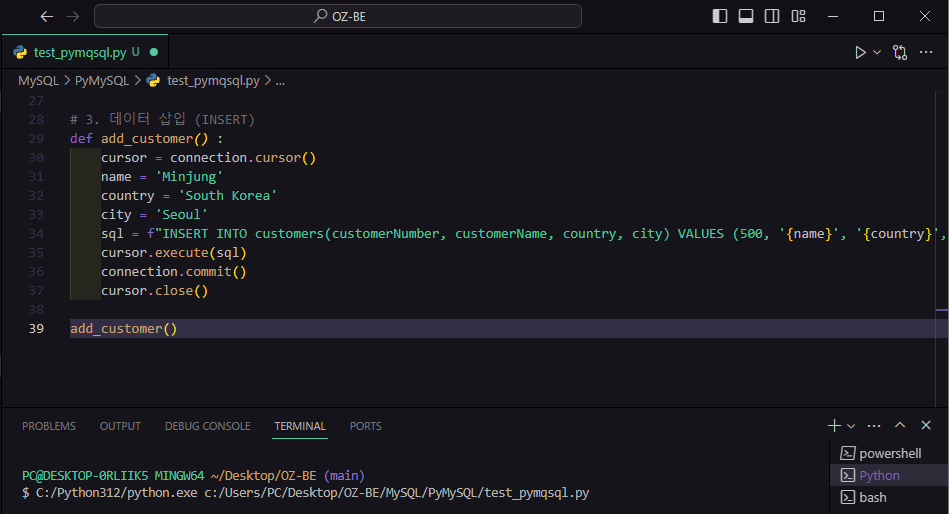
이렇게 실행이 되고
<결과>
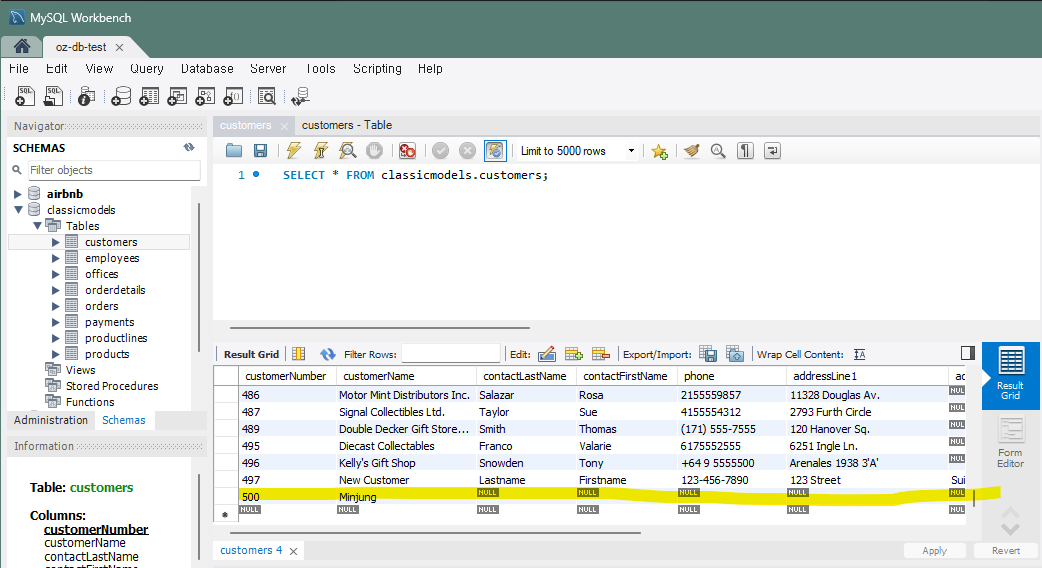
잘 들어간 것을 확인할 수 있다.
3. 데이터 수정 (UPDATE)
기존 데이터를 수정하는 코드 기본 구조이다.
try:
with connection.cursor() as cursor:
sql = "UPDATE table_name SET column1=%s WHERE column2=%s"
cursor.execute(sql, ('new_data', 'criteria'))
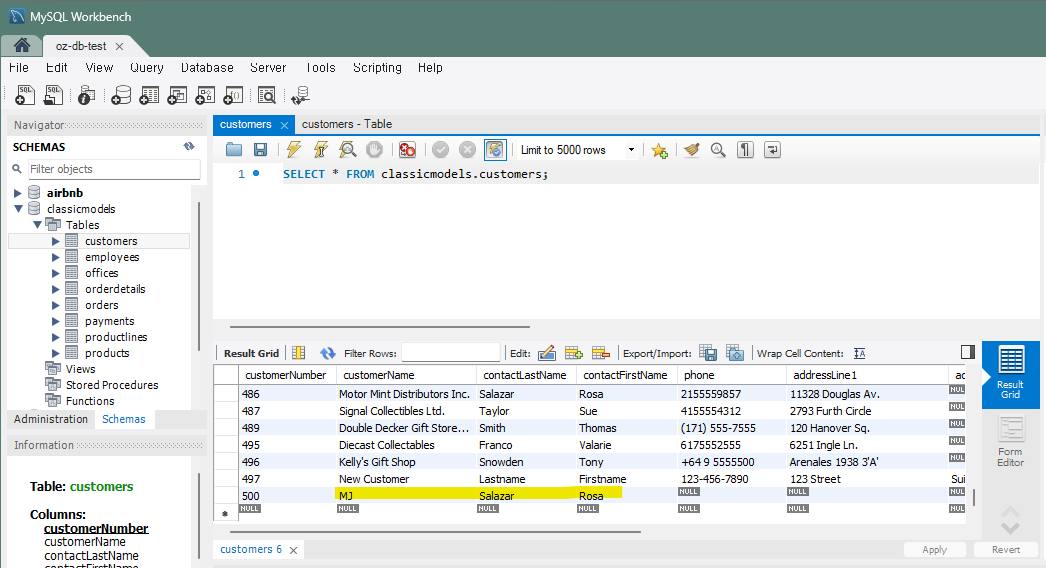
connection.commit()나는 이름을 좀 바꾸고 contactLastName, contactFirstName을 추가했다. 코드는 아래와 같고
def update_customer() :
cursor = connection.cursor()
name = 'MJ'
lastName = 'Salazar'
firstName = 'Rosa'
sql = f"UPDATE customers SET customerName='{name}', contactLastName='{lastName}', contactFirstName='{firstName}' WHERE customerNumber=500"
cursor.execute(sql)
connection.commit()
cursor.close()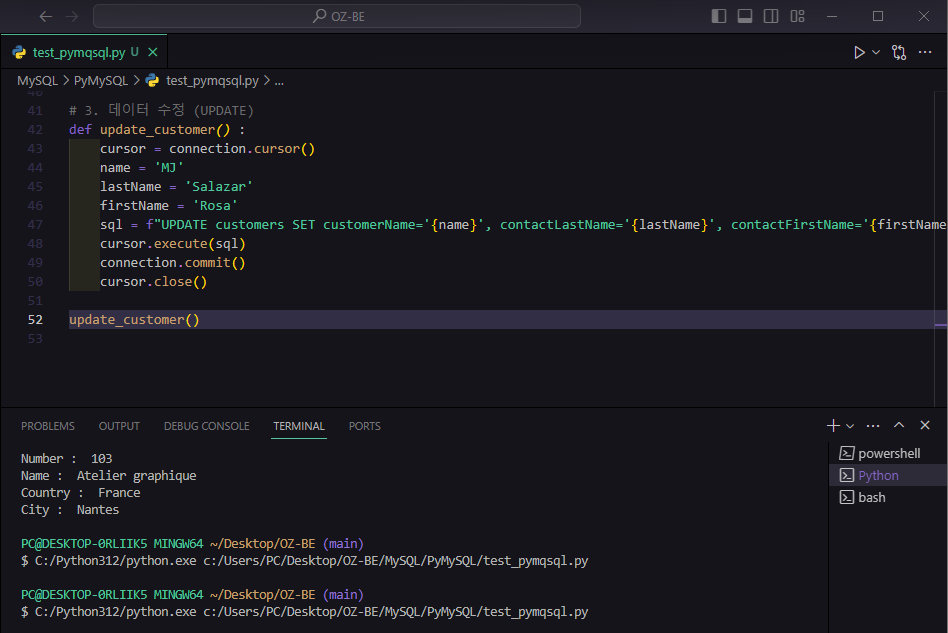
잘 들어갔다.
<결과>
4. 데이터 삭제 (DELETE)
데이터를 삭제하는 코드 기본 구조이다.
try:
with connection.cursor() as cursor:
sql = "DELETE FROM table_name WHERE column_name=%s"
cursor.execute(sql, ('criteria',))
connection.commit()내가 만들었던 cutomer 데이터를 삭제해봤다.
코드는 아래와 같다.
def delete_customer() :
cursor = connection.cursor()
sql = 'DELETE FROM customers WHERE customerNumber = 500'
cursor.execute(sql)
connection.commit()
cursor.close()
잘 작동했다.
<결과>
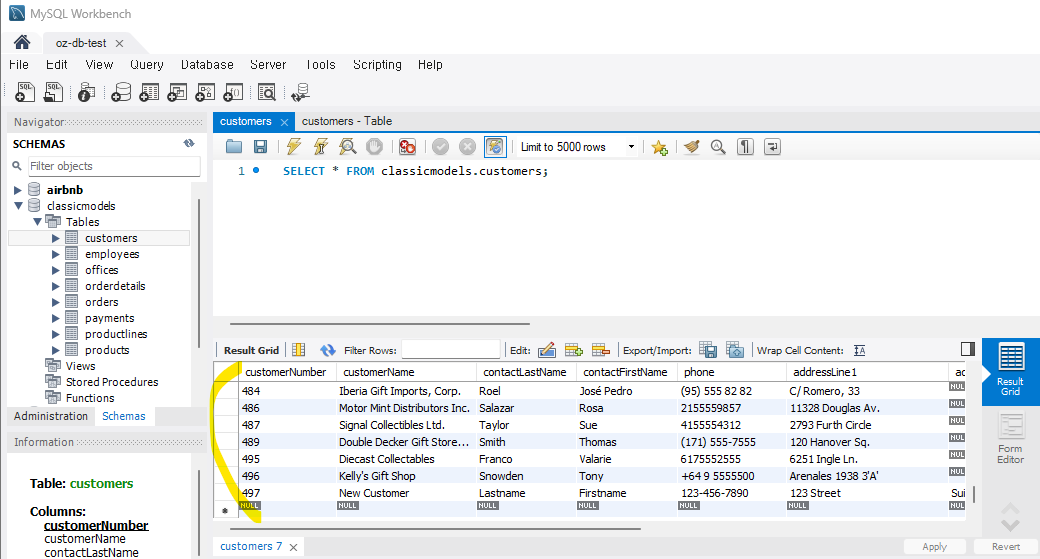
추가했던 데이터가 삭제되어 있는 것을 확인할 수 있다.
4. Code Refactoring
위에서 작성했던 코드들을 좀 더 간결하고 중복없이 리팩토링을 해봤다.
import pymysql
def execute_query(connection, query, args=None):
with connection.cursor() as cursor:
cursor.execute(query, args or ())
if query.strip().upper().startswith('SELECT'):
return cursor.fetchall()
else:
connection.commit()
def main():
connection = pymysql.connect(host='localhost',
user='username',
password='password',
db='database_name',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
try:
# SELECT 연산
result = execute_query(connection, "SELECT * FROM table_name")
print("SELECT 연산 결과:")
for row in result:
print(row)
# INSERT 연산
execute_query(connection, "INSERT INTO table_name (column1, column2) VALUES (%s, %s)", ('data1', 'data2'))
print("INSERT 연산 수행됨.")
# UPDATE 연산
execute_query(connection, "UPDATE table_name SET column1=%s WHERE column2=%s", ('new_data', 'criteria'))
print("UPDATE 연산 수행됨.")
# DELETE 연산
execute_query(connection, "DELETE FROM table_name WHERE column_name=%s", ('criteria',))
print("DELETE 연산 수행됨.")
finally:
connection.close()
if __name__ == "__main__":
main()with connection.cursor()로 cursor의 context를 유지할 수 있다. 데이터 베이스에 연결한 것을 파일이 끝날 때까지 가져갈 수 있도록 한다.as cursor로 cursor라는 변수를 만들어주고 그 변수에 대한execute를 실행한다.- if~else문을 써서
query라는 변수에SELECT이 있는지 없는지에 따라 'cursor.fetchall()'이라는 조회 명령을 할지,
'connection.commit()'라는 데이터 전송 명령을 할지 결정된다. - 실제 MySQL에 명령 내리는 코드
- SELECT의 경우
results = execute_query(connection, "원하는 SELECT Query 내용") for i in results : print(i) - 이 외
execute_query(connection, "원하는 Query 내용")
- SELECT의 경우
02. PyMySQL 연습
에어비앤비의 데이터베이스를 아래의 3개의 테이블로 구성하여 각 문제에 맞게 쿼리를 PyMySQL을 사용하여 작성해본다.
1. 테이블 생성
- Products: 제품 정보를 저장
- Customers: 고객 정보를 저장
- Orders: 주문 정보를 저장
각 테이블마다 Query는 다음과 같다.
MySQL에 작성하여 실행하면 된다.
USE airbnb;
-- Products 테이블
CREATE TABLE Products (
productID INT AUTO_INCREMENT PRIMARY KEY,
productName VARCHAR(255) NOT NULL,
price DECIMAL(10, 2) NOT NULL,
stockQuantity INT NOT NULL,
createDate TIMESTAMP
);
-- Customers 테이블
CREATE TABLE Customers (
customerID INT AUTO_INCREMENT PRIMARY KEY,
customerName VARCHAR(255) NOT NULL,
email VARCHAR(255) UNIQUE NOT NULL,
address TEXT NOT NULL,
createDate TIMESTAMP
);
-- Orders 테이블
CREATE TABLE Orders (
orderID INT AUTO_INCREMENT PRIMARY KEY,
customerID INT,
orderDate TIMESTAMP,
totalAmount DECIMAL(10, 2),
FOREIGN KEY (customerID) REFERENCES Customers(customerID)
);2. 데이터 생성
위 작업은 테이블만 생성한 것이고 데이터가 없기 때문에 랜덤한 데이터를 받았다.
아래 코드를 VS Code에서 .py 파일로 생성해주면 된다.
import pymysql
from faker import Faker
import random
# Faker 객체 초기화
fake = Faker()
# 데이터베이스 연결 설정
conn = pymysql.connect(
host='localhost', # 데이터베이스 서버 주소
user='root', # 데이터베이스 사용자 이름
password='oz-password', # 데이터베이스 비밀번호
db='airbnb', # 데이터베이스 이름
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
# Products 테이블을 위한 더미 데이터 생성
def generate_product_data(n):
for _ in range(n):
product_name = fake.word().capitalize() + ' ' + fake.word().capitalize()
price = round(random.uniform(10, 100), 2)
stock_quantity = random.randint(10, 100)
create_date = fake.date_time_this_year()
yield (product_name, price, stock_quantity, create_date)
# Customers 테이블을 위한 더미 데이터 생성
def generate_customer_data(n):
for _ in range(n):
customer_name = fake.name()
email = fake.email()
address = fake.address()
create_date = fake.date_time_this_year()
yield (customer_name, email, address, create_date)
# Orders 테이블을 위한 더미 데이터 생성
def generate_order_data(n, customer_ids):
for _ in range(n):
customer_id = random.choice(customer_ids)
order_date = fake.date_time_this_year()
total_amount = round(random.uniform(20, 500), 2)
yield (customer_id, order_date, total_amount)
# 데이터베이스에 데이터 삽입
with conn.cursor() as cursor:
# Products 데이터 삽입
products_sql = "INSERT INTO Products (productName, price, stockQuantity, createDate) VALUES (%s, %s, %s, %s)"
for data in generate_product_data(10):
cursor.execute(products_sql, data)
conn.commit()
# Customers 데이터 삽입
customers_sql = "INSERT INTO Customers (customerName, email, address, createDate) VALUES (%s, %s, %s, %s)"
for data in generate_customer_data(5):
cursor.execute(customers_sql, data)
conn.commit()
# Orders 데이터 삽입
# Customers 테이블에서 ID 목록을 얻어옵니다.
cursor.execute("SELECT customerID FROM Customers")
customer_ids = [row['customerID'] for row in cursor.fetchall()]
orders_sql = "INSERT INTO Orders (customerID, orderDate, totalAmount) VALUES (%s, %s, %s)"
for data in generate_order_data(15, customer_ids):
cursor.execute(orders_sql, data)
conn.commit()
# 데이터베이스 연결 종료
conn.close()※ 코드 해석
<import 부분>
- pymysql을 이용
- faker를 통해 랜덤한 데이터 받기
<데이터 베이스 연결>
- 이전에 연습한 내용과 같이 pymysql을 통해 MySQL로 데이터 연결
<데이터 생성 함수>
- products 테이블에 들어갈 데이터 내용 랜덤하게 받기.
- customers 테이블에 들어갈 데이터 내용 랜덤하게 받기.
- orders 테이블에 들어갈 데이터 내용 랜덤하게 받기.
<데이터 삽입>
- products 테이블에는 10개, customers 테이블에는 5개, orders 테이블에는 15개의 데이터를 만들어 달라는 코드를 작성하였다.
<결과>
-
products 테이블
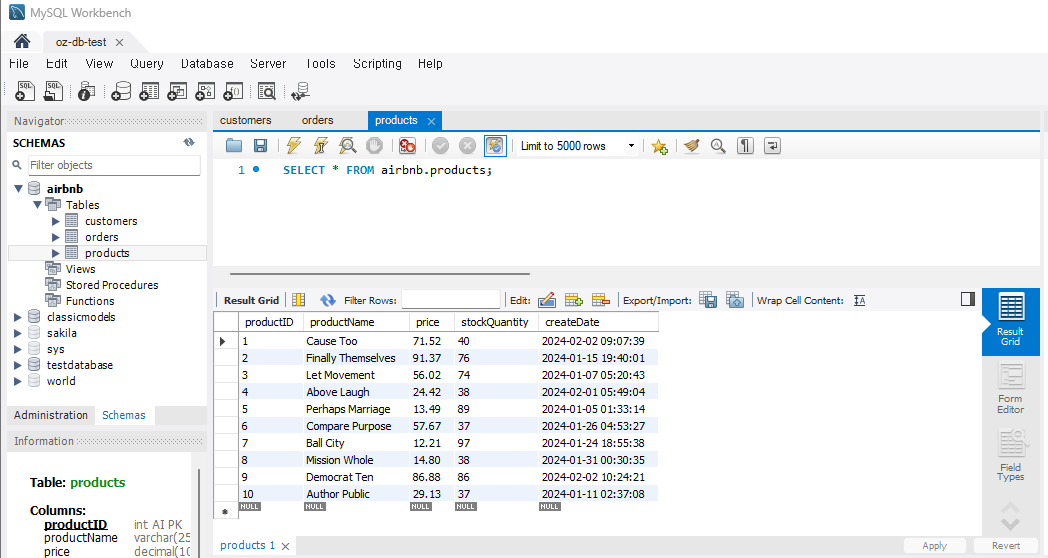
-
customers 테이블
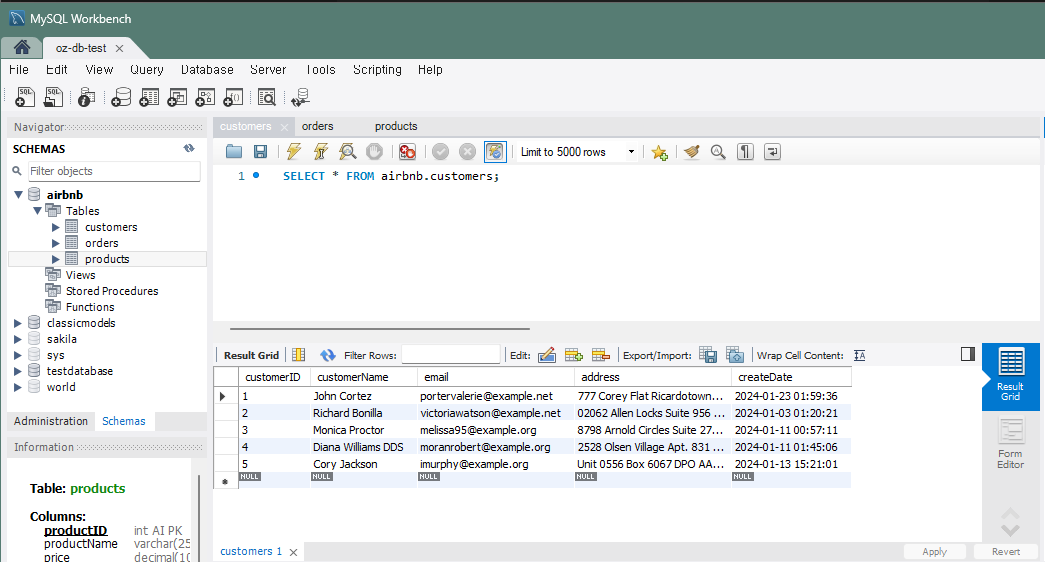
-
orders 테이블
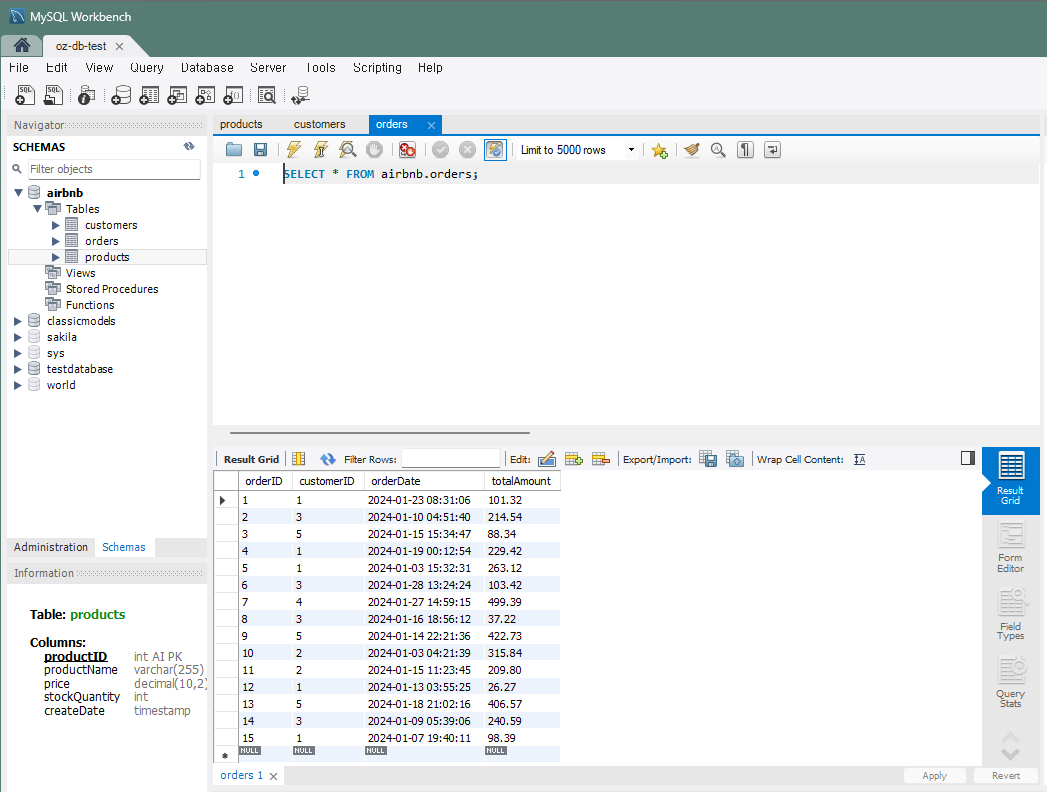
3. 실전 연습 문제
이제 위에서 추가한 데이터들을 가지고 몇가지 문제를 풀어보면서 PyMySQL을 실습해보려 한다.
0. 데이터 베이스 연결
아래 코드로 PyMySQL을 이용하여 데이터 베이스에 연결한다.
(계속 연습해왔던 코드이다.)
import pymysql
# 데이터 베이스 연결
connection = pymysql.connect(
host='localhost',
user='root',
password='본인 비밀번호',
db='airbnb',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)아래 문제들은 with connection.cursor() as cursor : 코드를 작성하고 그 뒤에 연속해서 코드를 작성할 것이다.
그리고 코드의 맨 마지막에는 cursor.close()를 넣어준다.
문제 1 - 새로운 제품 추가
Python 스크립트를 사용하여 'Products' 테이블에 새로운 제품을 추가하세요. 예를 들어, "Python Book"이라는 이름의 제품을 29.99달러 가격으로 추가한다.
# 문제 1 - 새로운 제품 추가
sql = "INSERT INTO products (productName, price, stockQuantity) VALUES (%s, %s, %s)"
cursor.execute(sql,('Python Book', 29.99, 10))
connection.commit()
# 문제 1 확인
cursor.execute("SELECT * FROM products")
for book in cursor.fetchall() :
print(book)실행하면
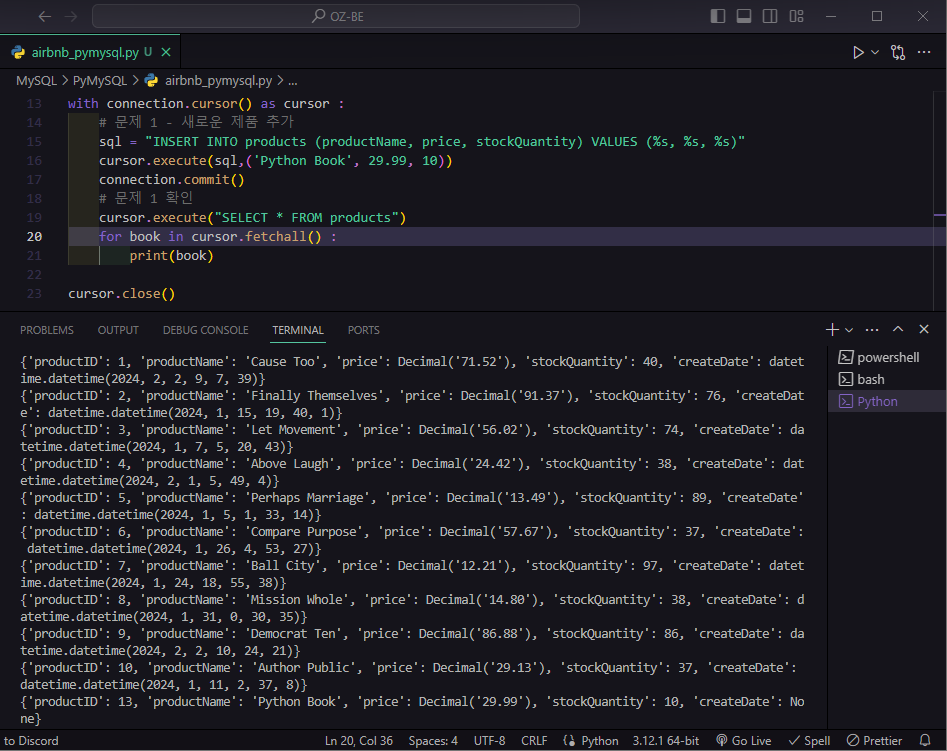
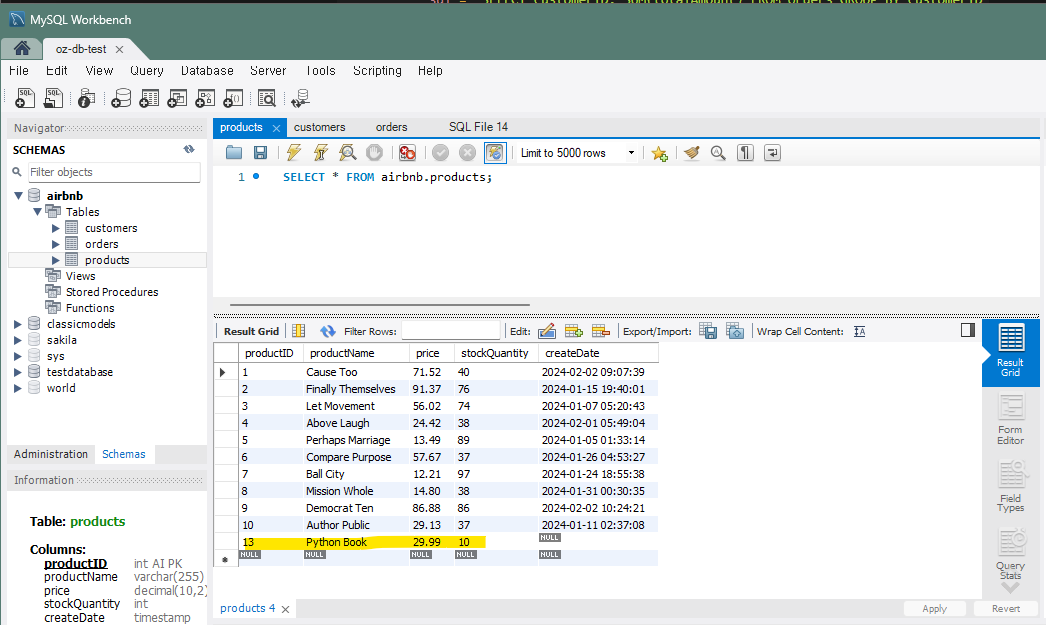
문제 2 - 고객 목록 조회
'Customers' 테이블에서 모든 고객의 정보를 조회하는 Python 스크립트를 작성해본다.
위에서 문제 1번이 잘 들어갔는지 확인하기 위해 작성한 코드와 거의 동일하다.
# 문제 2 - 고객 목록 조회
sql = "SELECT * FROM customers"
cursor.execute(sql)
for row in cursor.fetchall():
print(row)실행하면

문제 3 - 제품 재고 업데이트
제품이 주문될 때마다 'Products' 테이블의 해당 제품의 재고를 감소시키는 Python 스크립트를 작성해본다.
# 문제 3 - 제품 재고 업데이트
sql = "UPDATE products SET stockQuantity = stockQuantity - %s WHERE productID = %s"
cursor.execute(sql, (1, 1))
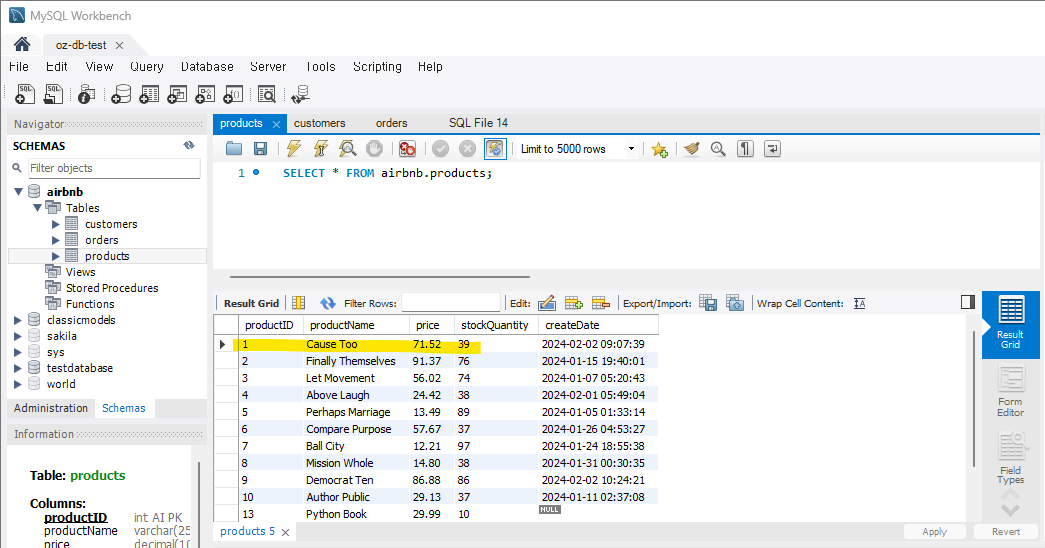
connection.commit()prodcutID가 1인 상품의 갯수를 1 감소 시켰다.
실행하면 기존에 productID가 1인 'Cause Too'란 제품의 stockQuantity가 40개였는데 39로 줄은 것을 확인할 수 있다.
문제 4 - 고객별 총 주문 금액 계산
'Orders' 테이블을 사용하여 각 고객별로 총 주문 금액을 계산하는 Python 스크립트를 작성해본다.
GROUP BY를 활용해서 총 주문 금액을 확인할 수 있다.
VS Code에서, MySQL에서 모두 확인 가능하다.
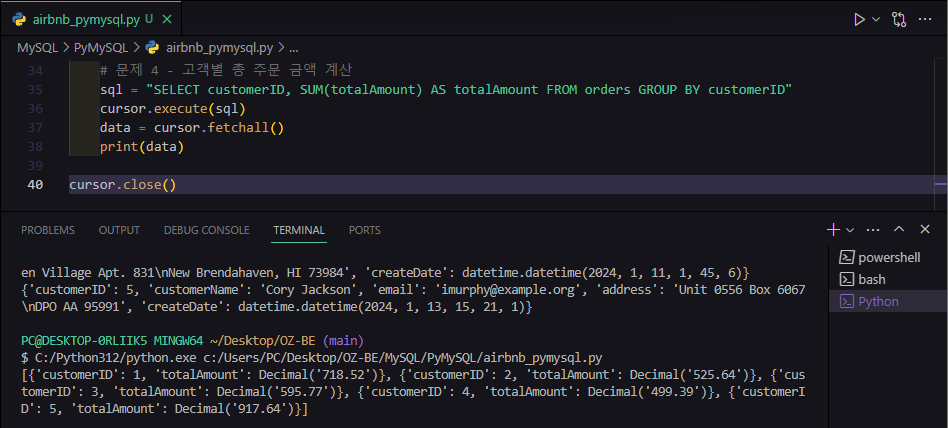
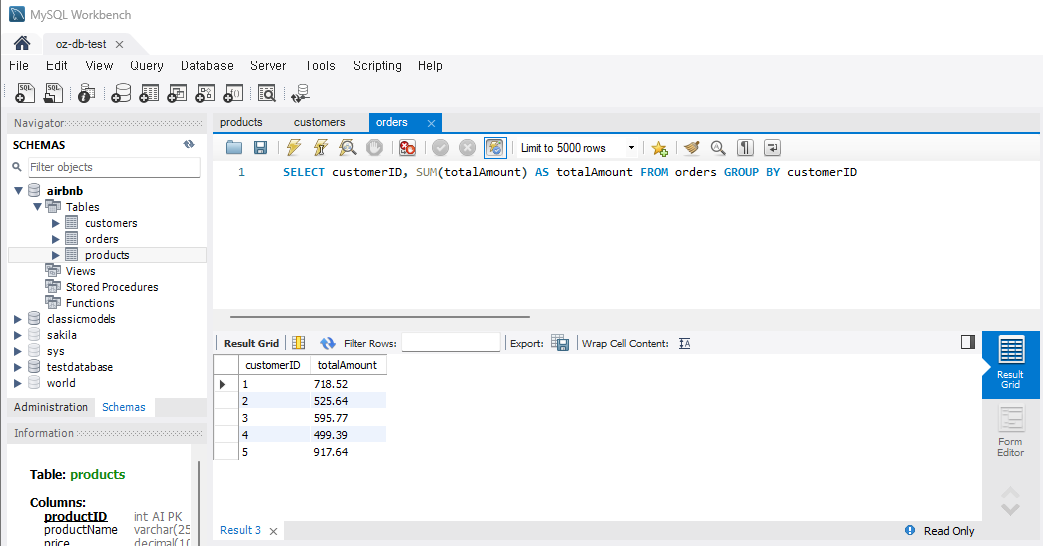
# 문제 4 - 고객별 총 주문 금액 계산
sql = "SELECT customerID, SUM(totalAmount) AS totalAmount FROM orders GROUP BY customerID"
cursor.execute(sql)
data = cursor.fetchall()
print(data)실행하면
문제 5 - 고객 이메일 업데이트
고객의 이메일 주소를 업데이트하는 Python 스크립트를 작성해본다.
고객 ID를 입력받고, 새로운 이메일 주소로 업데이트한다.
# 문제 5 - 고객 이메일 업데이트
sql = "UPDATE customers SET email = %s WHERE customerID = %s"
cursor.execute(sql, ('update@email.com', 1))
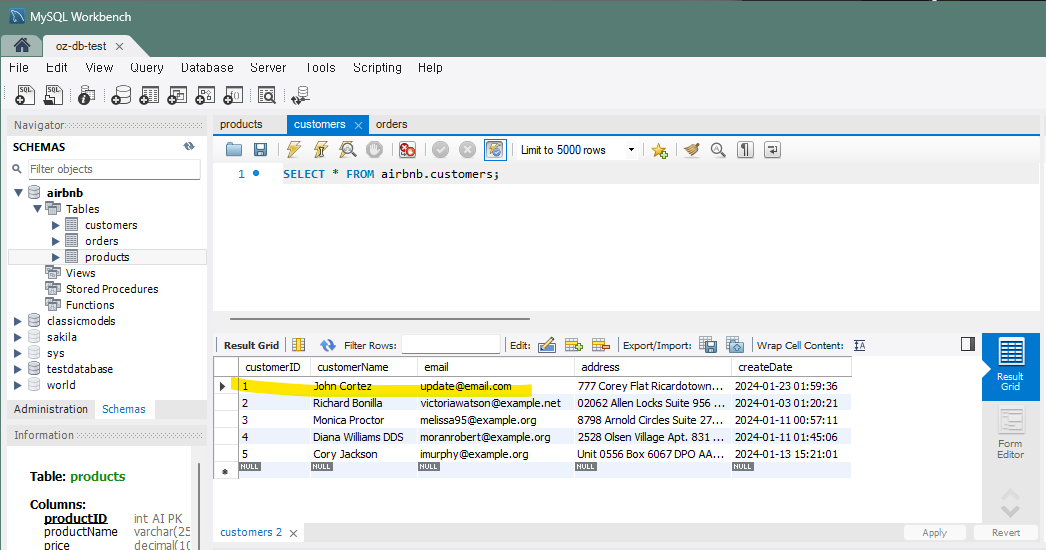
connection.commit()customerID가 1인 고객의 이메일을 'update@email.com'으로 업데이트 한다.
실행하면
잘 실행 됐고, 기존의 customerID가 1이었던 John Cortez 의 portervalerie@example.net 이메일이 변경된 것을 확인할 수 있다.
문제 6 - 주문 취소
주문을 취소하는 Python 스크립트를 작성해본다.
주문 ID를 입력받아 해당 주문을 'Orders' 테이블에서 삭제한다.
나는 15번째 주문을 삭제했다.
# 문제 6 - 주문 취소
sql = "DELETE FROM orders WHERE orderID = %s"
cursor.execute(sql, (15))
connection.commit()실행하면
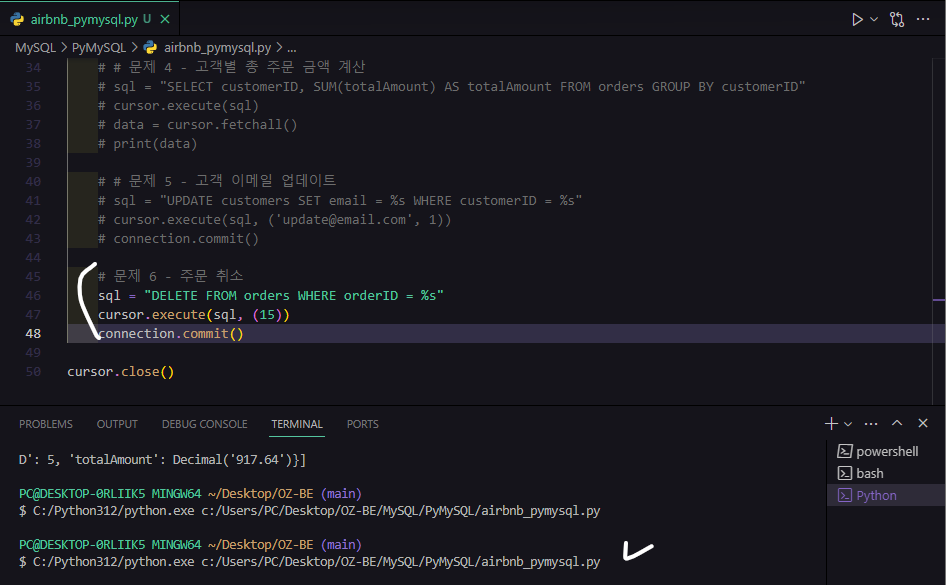
잘 실행 됐고 기존에 주문수가 15개였던 것이 14개로 반영된 것을 확인할 수 있다.
문제 7 - 특정 제품 검색
제품 이름을 기반으로 'Products' 테이블에서 제품을 검색하는 Python 스크립트를 작성해본다.
여기서 '='기호를 작성하면 내가 입력한 것과 완전히 동일한 데이터만 찾게 되므로 LIKE를 사용해서 내가 입력한 값을 포함하는 데이터를 찾아보았다.
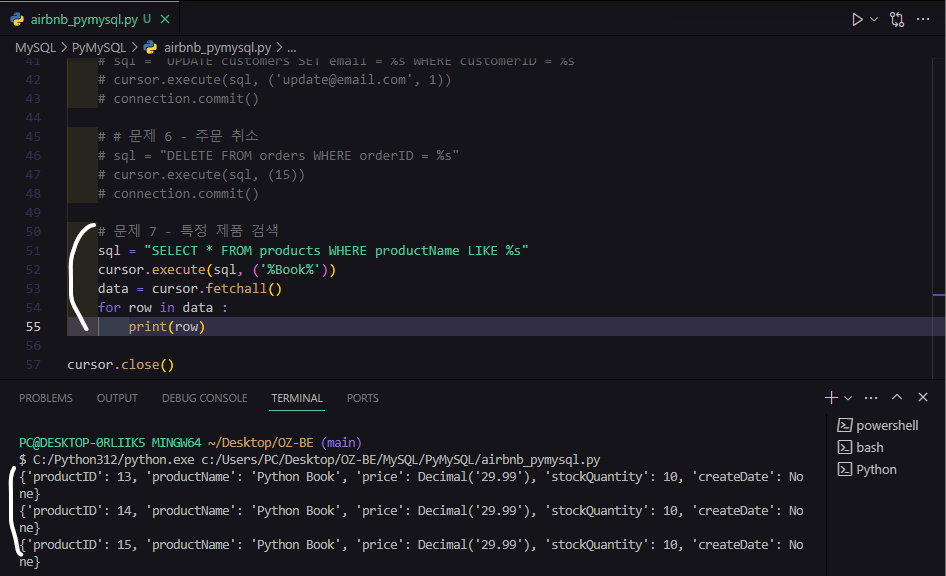
# 문제 7 - 특정 제품 검색
sql = "SELECT * FROM products WHERE productName LIKE %s"
cursor.execute(sql, ('%Book%'))
data = cursor.fetchall()
for row in data :
print(row)나는 Book을 포함하는 상품을 검색하는 코드를 작성했고 실행하면
문제 8 - 특정 고객의 모든 주문 조회
고객 ID를 기반으로 그 고객의 모든 주문을 조회하는 Python 스크립트를 작성해본다.
나는 customerID가 1인 고객의 모든 주문을 조회했다.
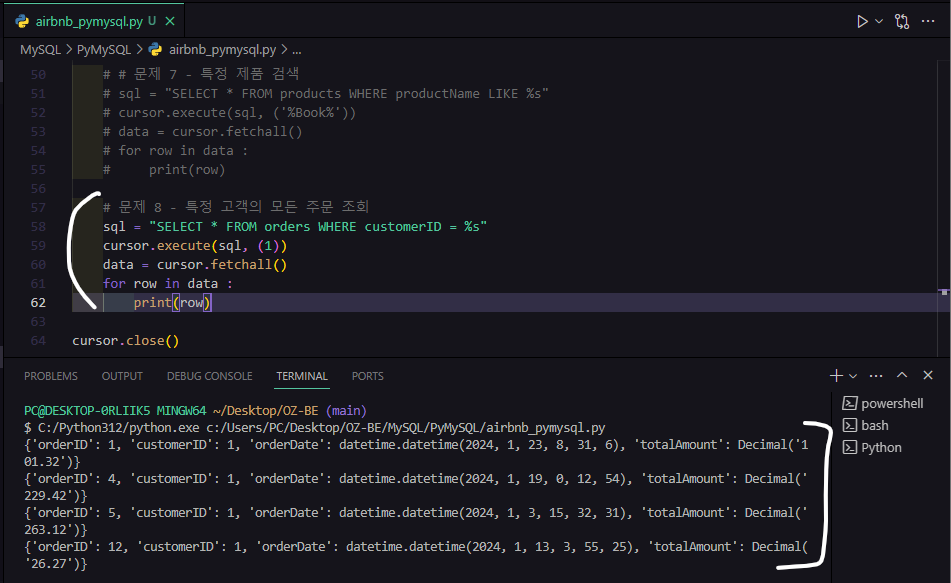
# 문제 8 - 특정 고객의 모든 주문 조회
sql = "SELECT * FROM orders WHERE customerID = %s"
cursor.execute(sql, (1))
data = cursor.fetchall()
for row in data :
print(row)실행하면
문제 9 - 가장 많이 주문한 고객 찾기
'Orders' 테이블을 사용하여 가장 많은 주문을 한 고객을 찾는 Python 스크립트를 작성해본다.
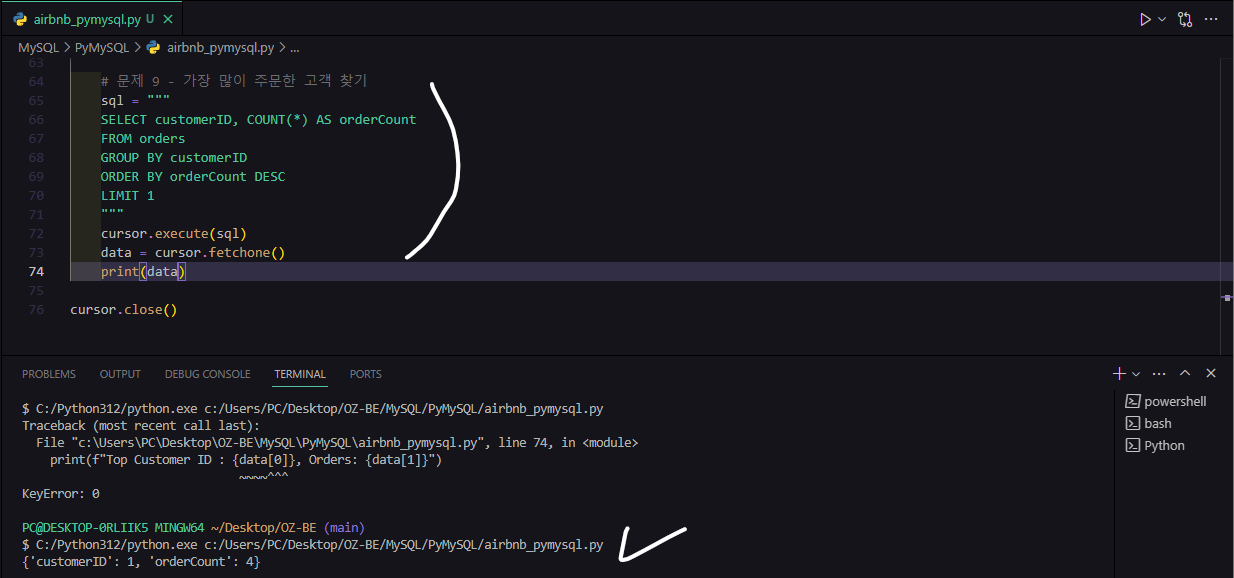
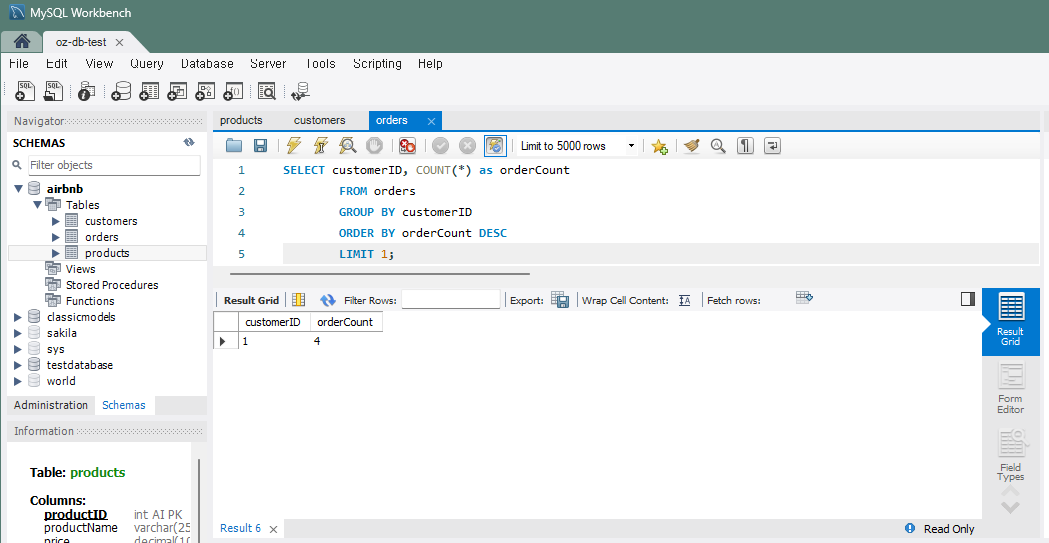
# 문제 9 - 가장 많이 주문한 고객 찾기
sql = """
SELECT customerID, COUNT(*) AS orderCount
FROM orders
GROUP BY customerID
ORDER BY orderCount DESC
LIMIT 1
"""
cursor.execute(sql)
data = cursor.fetchone()
print(data)실행하면 VS Code와 MySQL 동일하게 결과를 확인할 수 있다.
전체 코드
import pymysql
# 데이터 베이스 연결
connection = pymysql.connect(
host='localhost',
user='root',
password='비밀번호',
db='airbnb',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
with connection.cursor() as cursor :
# 문제 1 - 새로운 제품 추가
sql = "INSERT INTO products (productName, price, stockQuantity) VALUES (%s, %s, %s)"
cursor.execute(sql,('Python Book', 29.99, 10))
connection.commit()
# 문제 1 확인
cursor.execute("SELECT * FROM products")
for book in cursor.fetchall() :
print(book)
# 문제 2 - 고객 목록 조회
sql = "SELECT * FROM customers"
cursor.execute(sql)
for row in cursor.fetchall():
print(row)
# 문제 3 - 제품 재고 업데이트
sql = "UPDATE products SET stockQuantity = stockQuantity - %s WHERE productID = %s"
cursor.execute(sql, (1, 1))
connection.commit()
# 문제 4 - 고객별 총 주문 금액 계산
sql = "SELECT customerID, SUM(totalAmount) AS totalAmount FROM orders GROUP BY customerID"
cursor.execute(sql)
data = cursor.fetchall()
print(data)
# 문제 5 - 고객 이메일 업데이트
sql = "UPDATE customers SET email = %s WHERE customerID = %s"
cursor.execute(sql, ('update@email.com', 1))
connection.commit()
# 문제 6 - 주문 취소
sql = "DELETE FROM orders WHERE orderID = %s"
cursor.execute(sql, (15))
connection.commit()
# 문제 7 - 특정 제품 검색
sql = "SELECT * FROM products WHERE productName LIKE %s"
cursor.execute(sql, ('%Book%'))
data = cursor.fetchall()
for row in data :
print(row)
# 문제 8 - 특정 고객의 모든 주문 조회
sql = "SELECT * FROM orders WHERE customerID = %s"
cursor.execute(sql, (1))
data = cursor.fetchall()
for row in data :
print(row)
# 문제 9 - 가장 많이 주문한 고객 찾기
sql = """
SELECT customerID, COUNT(*) AS orderCount
FROM orders
GROUP BY customerID
ORDER BY orderCount DESC
LIMIT 1
"""
cursor.execute(sql)
data = cursor.fetchone()
print(data)
cursor.close()03. Mini Project -1
YES24 베스트 셀러 데이터를 수집 후 데이터를 분석해본다.
git & Github 수업 이후에 Crawling에 대해서 배웠는데 이번엔 크롤링을 이용하여 데이터를 가져와야해서 사용하게 되었다.
0. Crawling (크롤링)
크롤링은 크게 두가지로 나뉘어져 있다.
- 정적 크롤링
- 동적 크롤링
1. 정적 크롤링
정적 크롤링이란 정적 페이지를 크롤링하는 것을 말한다. 보통 beautifulSoup4를 이용한다.
-
정적 page 예시
: 정부 페이지, 기업 페이지
(모두에게 동일한 정보를 제공하는 페이지들) -
특징
- 페이지가 바뀌면 한번 더 requests를 해서 해당 페이지에 대한 데이터를 받아야한다. (스크롤도 동일)
- 페이지를 실행하지 않아도 데이터를 가져온다. (그래서 정보 처리 빠름)
- 코드로 처리하는 거라 오류를 발견하면 알려준다.
-
방법
- 원하는 페이지의 url 입력 (변수로 저장)
- get으로 서버에게 페이지의 자원(resource) 요청
(requests 함수는 처음에 사용되고 이후에 잘 사용되지 않음.
정적 page에서는 코드가 변하지 않기 때문에) - html 문자로 받아오기
(get 방식을 통해서 가져온 많은 데이터 중
우리가 필요한건 텍스트 형태의 데이터이며
이것을 html이라는 변수에 저장.
이때는 컴퓨터가 이해하지 못하는 문서) - 받은 html 파일을 perser.(파싱)
(BeautifulSoup 함수에는 2가지 파라미터 필요.
<html과 html.parser> 넣으면 파서 진행.
이렇게 해야 컴퓨터가 이해하는 문서(트리구조)로 변경) - 원하는 정보의 id를 찾아서 query 변수로 넣어줌.
(select_one은 class, id, 태그 찾아준다.)
이렇게 글로 봐서는 이해가 잘 안된다.
아래 코드는 네이버 검색에서 크롤링한 예시를 보여준다.
import requests
from bs4 import BeautifulSoup
header_user = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"}
base_url = "https://search.naver.com/search.naver?where=view&sm=tab_jum&query="
search_url = input("검색어를 입력해주세요 : ")
url = base_url + search_url
req = requests.get(url, headers=header_user)
html = req.text
soup = BeautifulSoup(html, "html.parser")
areas = soup.select(".view_wrap")
for i in areas:
ad = i.select_one(".link_ad")
if ad :
continue
else :
title = i.select_one(".title_link._cross_trigger")
name = i.select_one(".name")
print(f'제목 : {title.text}')
print(f'작성자 : {name.text}')
print(f'링크 : {title['href']}')2. 동적 크롤링
동적 크롤링이란 동적 페이지를 크롤링하는 것을 말한다. 보통 selenium을 이용한다.
-
동적 page 예시
: 유튜브, 넷플릭스, 쇼핑몰(지그재그, 에이블리, 무신사)
(사용자의 취향, 기기에 맞춰서 반응하는 웹들) -
특징
- 알아서 스크롤을 해서 동적으로 데이터를 가져옴. (정보 처리 느림)
- 페이지를 실행해야지 데이터를 가져올 수 있다.
- 모바일 형태로도 접속할 수 있다...!
- 어느정도 사람의 개입이 필요하다. (아무리 자동화라고 해도 사람이 지켜보면서 오류 확인해야함.)
-
방법
- 원하는 페이지의 url 입력 (변수로 저장)
- get으로 서버에게 페이지의 자원(resource) 요청
- time을 설정해서 페이지가 나타나는 시간 설정.
- html 파일 얻고 (driver.page_source) BeautifulSoup으로 파싱.
(셀레니움 자체에는 파싱하는 기능이 없어 BeautifulSoup을 이용해서 ) - 원하는 정보의 id를 찾아서 query 변수로 넣어줌.
(select_one은 class, id, 태그 찾아준다.)
이것도 이렇게 읽기만 하면 잘 이해가 안되니 melon(모바일 버전)과 kream을 크롤링할 때 사용했던 코드를 참고용으로 적어놓겠다.
<Melon 모바일 버전 크롤링>
# selenium 이용
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import time
# 기본 옵션
options = Options()
# 모바일 버전 user-agent.
user = "Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604.1"
options.add_argument(f'User-Agent={user}')
options.add_experimental_option("detach", True)
options.add_experimental_option("excludeSwitches",["enable-automation"])
driver = webdriver.Chrome(options=options)
# 크롤링 코드
url = "https://m2.melon.com/index.htm"
driver.get(url)
time.sleep(3)
# 이벤트 페이지 닫기
if driver.current_url != url:
driver.get(url)
# 팝업 페이지 닫기
driver.find_element(By.LINK_TEXT, "닫기").click()
time.sleep(0.2)
# 멜론 차트 보기
driver.find_element(By.LINK_TEXT, "멜론차트").click()
time.sleep(0.4)
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
# 더보기 버튼 클릭 (2번째 요소 선택 - 리스트 형이라 가능한 부분)
more_btn = driver.find_elements(By.CSS_SELECTOR, "#moreBtn")[1].click() #.service_list_more.noline.sprite.hide
items = soup.select(".list_item")
num = 1
for i in items :
singer = i.select_one(".name.ellipsis")
title = i.select_one(".title.ellipsis")
print('멜론차트 TOP100')
print(f'<{num} 위>')
print(f'가수 : {singer.text}')
print(f'제목 : {title.text.strip()}')
print()
num += 1
driver.quit()<Kream 웹 크롤링>
# selenium 이용
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import time
import urllib.request
# 기본 옵션
options = Options()
user = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
options.add_argument(f'User-Agent={user}')
options.add_experimental_option("detach", True)
options.add_experimental_option("excludeSwitches",["enable-automation"])
driver = webdriver.Chrome(options=options)
# 크롤링 코드
url = "https://kream.co.kr/"
driver.get(url)
# 다양한 기능 넣어주기
# 1. 돋보기 누르기
driver.find_element(By.CSS_SELECTOR, ".btn_search").click()
time.sleep(0.5) # 인간미 넣어주기 (트래픽감지 방지)
# 2. 브랜드 검색 * 추후 여러개 브랜드 넣을 예정
driver.find_element(By.CSS_SELECTOR, ".input_search.show_placeholder_on_focus").send_keys("슈프림") # 브랜드명 입력
time.sleep(0.3)
driver.find_element(By.CSS_SELECTOR, ".input_search.show_placeholder_on_focus").send_keys(Keys.ENTER) # enter 실행
# enter를 입력해도 좋지만 \n로 브랜드명에 같이 넣어줘도 작동함.
time.sleep(0.1)
# 3. 스크롤 계속 내려서 정보 가져오기_키보드 키 이용, 반복 작업(for문)
for i in range(10): # 20번 반복
driver.find_element(By.TAG_NAME, "body").send_keys(Keys.PAGE_DOWN) # 키보드 키 이용해서 스크롤
time.sleep(0.5)
# 4. 각 상품 정보 가져오기
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
items = soup.select(".product_card")
num = 1
for i in items :
product_name = i.select_one(".translated_name")
brand = i.select_one(".product_info_brand.brand")
product_price = i.select_one(".amount")
deal = i.select_one(".status_value")
star = i.select_one(".wish_figure")
review = i.select_one(".review_figure")
if "후드" in product_name.text :
print(f'<{num}>')
print(f'브랜드 : {brand.text}')
print(f'제품명 : {product_name.text}')
print(f'가격 : {product_price.text}')
print(f'{deal.text}')
print(f'위시량 : {star.text}')
print(f'리뷰 : {review.text}')
print()
num += 1
# 5. 상품 사진 저장하기
images = driver.find_element(By.CSS_SELECTOR,".image.full_width").get_attribute("src")
urllib.request.urlretrieve(images, "img.png")
driver.quit()*여기서 사진 저장은 아직 잘 구현하지 못했다,,,
🌟크롤링시 주의사항
: user agent 는 기종마다 상이하므로 구글링을 통해 얻을 수 있다.
또는 개발자 도구(F12) Network에서 최상단에 페이지주소로 되어있는 정보를 누르면 User-Agent에서 확인할 수 있다.
1. 크롤링 준비
1. 설치
크롬 드라이버와 selenium을 설치한다
명렁 프롬프터나 터미널에서 아래 코드를 작성하여 설치하면 된다.
크롬 드라이버 설치 이유는 Python Selenium을 통해 크롬 드라이버에 접근하고 크롬 드라이버로 크롬 브라우저를 컨트롤 할 수 있기 때문이다.
pip install webdriver-manager
pip install selenium2. Import
<크롬 드라이버 import>
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
ChromeDriverManager().install()
browser = webdriver.Chrome()<selenium 사용>
from selenium import webdriver
(1) 상대경로
path = "./chromedriver"
(2) 절대경로
import os
path = os.getcwd() + "/chromedriver"
browser = webdriver.Chrome() # 경로지정
browser.get("http://naver.com")
(3) 기본함수
browser.back() # 뒤로가기
browser.forward() # 앞으로가기
browser.refresh() # 새로고침그리고 python 가상환경을 만들어(?)놔야하는데 방법은 아래 링크를 따라하면 잘 된다 ㅎㅎ MAC과 Window는 명령어에 차이가 있으니 참고!!
3. 요소 가져오기 - By
By.CLASS_NAME 태그의 클래스명으로 추출
By.TAG_NAME 태그 이름으로 추출
By.ID 태그의 id값으로 추출
By.XPATH 태그의 경로로 추출- 요소를 가져올 때 주의점.
- 중복되는 값이 존재하면 첫 번째 값만 가져온다.
- 만약, 중복되는 값을 여러개 동시에 가져오려면 find_elements 함수를 통해서 가져온다.
4. 요소 선택하기 - Keys
- keys에 사용할 수 있는 버튼들은 아래 링크를 참고하면 된다.
: https://www.geeksforgeeks.org/special-keys-in-selenium-python/
- 요소를 하나씩 클릭하는 방법
from selenium.webdriver.common.by import By
browser.find_element(By.ID, 'query').click()
browser.find_element(By.ID, 'query').send_keys("날씨") # 검색어 입력
browser.find_element(By.ID, 'search_btn').click() # 검색 버튼 클릭- Keys 라이브러리 사용
from selenium.webdriver.common.keys import Keys
elem = browser.find_element(By.ID, 'query') # 요소 지정
elem.send_keys("검색원하는 단어")
elem.send_keys(Keys.ENTER)4. 요소 선택하기 - element / elements
- 하나의 요소만 가져오고 싶을 때 → element
- 여러개의 요소를 가져오고 싶을 때 → elements
element(단일) -> ELEMENT(요소) 리턴
elements(복수)-> List를 리턴2. 크롤링 사용하여 데이터 수집하기
Yes24 베스트셀러 페이지에서 다음과 같은 정보를 수집하려 한다.
1) 필요한 정보들
- 책 제목 (title)
- 저자 (author)
- 출판사 (publisher)
- 출판일 (publishing)
- 평점 (rating)
- 리뷰 (review)
- 판매지수 (sales)
- 가격 (price)
- 국내도서랭킹 (ranking)
- 국내도서TOP100 (ranking_weeks)
2. 데이터 가져오는 방법
VS Code에서 주피터 파일을 이용하여 Python 코드로 크롤링하는 연습을 먼저 해본다.
코드는 아래와 같다.
# webdriver-manager 라이브러리 불러오기
from webdriver_manager.chrome import ChromeDriverManager
ChromeDriverManager().install()
# selenium 사용
from selenium import webdriver
browser = webdriver.Chrome()
# 1개의 페이지의 링크 데이터 전부 수집
url = 'https://www.yes24.com/Product/category/bestseller?CategoryNumber=001&sumgb=06'
browser.get(url)
### 한 개의 베스트 셀러 링크 데이터 수집
browser.find_element(By.CLASS_NAME, 'gd_name').get_attribute('href')
### 1 페이지 전체의 링크 데이터 수집
datas = browser.find_elements(By.CLASS_NAME, 'gd_name')
for i in datas :
print(i.get_attribute('href'))
# 3페이지까지의 링크 데이터 전부 수집
import time
link_list = []
for i in range(1, 4) :
print("*" * 10, f"현재 {i} 페이지 수집 중입니다.", "*" * 10)
url = f'https://www.yes24.com/Product/Category/BestSeller?categoryNumber=001&pageNumber={i}&pageSize=24'
browser.get(url)
browser.find_element(By.CLASS_NAME, 'gd_name').get_attribute('href')
datas = browser.find_elements(By.CLASS_NAME, 'gd_name')
for i in datas :
link = i.get_attribute('href')
link_list.append(link)
time.sleep(3)
print(link_list)총 3페이지의 베스트 셀러 링크 데이터들을 가져올 예정이다.
각 도서의 자세한 사항은 각 도서 링크를 타고 들어가서 원하는 데이터들을 가져와야하는데 (책 제목, 저자, 출판사 등등) 그 방법은 아래와 같다.
# 데이터 한개로 시범 운영
browser.get(link_list[0])
title = browser.find_element(By.CLASS_NAME, 'gd_name').text
author = browser.find_element(By.CLASS_NAME, 'gd_auth').text
publisher = browser.find_element(By.CLASS_NAME, 'gd_pub').text
publishing = browser.find_element(By.CLASS_NAME, 'gd_date').text
rating = browser.find_element(By.CLASS_NAME, 'yes_b').text
review = browser.find_element(By.CLASS_NAME, 'gd_reviewCount').text
sales = browser.find_element(By.CLASS_NAME, 'gd_sellNum').text.split(" ")[2] # 숫자만 가져오기
price = browser.find_element(By.CLASS_NAME, 'yes_m').text[:-1] #'원' 제거
ranking = browser.find_element(By.CLASS_NAME, 'gd_best').text.split(" | ")[0]
ranking_weeks = browser.find_element(By.CLASS_NAME, 'gd_best').text.split(" | ")[1]이제 이 데이터를 여러 책에 대입해서 데이터를 받아와야한다!
근데 ranking 변수와 ranking_weeks 변수가 좀 더러워서 최종 코드에서는 다른 방법으로 데이터를 얻어왔다. 리뷰가 없어서 평점이랑 리뷰 수가 없는 데이터 때문에 살짝 애를 먹었지만,,, 그래도! 덕분에 공부가 됐다.
# 상세 페이지 이동 후 데이터 크롤링
# 데이터 베이스 연동 후 → 수집한 데이터 DB에 저장 (scv)
import pymysql
import time
import re
from datetime import datetime
conn = pymysql.connect(
host='localhost',
user='root',
password='alswjd6984!',
db='yes24',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
with conn.cursor() as cur :
for link in link_list :
browser.get(link)
title = browser.find_element(By.CLASS_NAME, 'gd_name').text
author = browser.find_element(By.CLASS_NAME, 'gd_auth').text
publisher = browser.find_element(By.CLASS_NAME, 'gd_pub').text
# 2023년 09월 07일 → 2023-09-07
publishing = browser.find_element(By.CLASS_NAME, 'gd_date').text
match = re.search(r'(\d+)년 (\d+)월 (\d+)일', publishing)
if match :
year, month, day = match.groups()
date_obj = datetime(int(year), int(month), int(day))
publishing = date_obj.strftime('%Y-%m-%d')
else :
publishing = '2023-01-01'
rating = browser.find_element(By.CLASS_NAME, 'yes_b').text
if rating == '' :
rating = 0
review = browser.find_element(By.CLASS_NAME, 'gd_reviewCount').text
if len(review) == 15 :
review = 0
else :
review = review.split("(")[1][:-2]
review = int(review.replace(",",""))
sales = browser.find_element(By.CLASS_NAME, 'gd_sellNum').text.split(" ")[2]
sales = int(sales.replace(",",""))
price = browser.find_element(By.CLASS_NAME, 'yes_m').text[:-1]
price = int(price.replace(",",""))
full_text = browser.find_element(By.CLASS_NAME, 'gd_best').text
parts = full_text.split(" | ")
if len(parts) == 1 :
ranking, ranking_weeks = 0, 0
# ranking
try :
ranking_parts = parts[0]
ranking = ''.join(filter(str.isdigit, ranking_parts)) # 문자열에서 숫자만 추출.
except :
ranking = 0
#ranking_weeks
try :
ranking_weeks_parts = parts[1]
ranking_weeks = ''.join(filter(str.isdigit, ranking_weeks_parts.split()[-1])) # 문자열에서 마지막 숫자만 추출.
except :
ranking_weeks = 0
sql = """
INSERT INTO books
(title, author, publisher, publishing, rating, review, sales, price, ranking, ranking_weeks)
VALUES
(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
cur.execute(sql, (title, author, publisher, publishing, rating, review, sales, price, ranking, ranking_weeks))
conn.commit()
time.sleep(2)이 코드 실행은 이번 프로젝트 Schema와 테이블을 생성하고 난 뒤 실행하면 된다! 테이블 생성 코드는 아래와 같다.
3) 해당 테이블 생성
CREATE TABLE Books (
bookID INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
author VARCHAR(255),
publisher VARCHAR(255),
publishing DATE,
rating DECIMAL(3, 1),
review INT,
sales INT,
price DECIMAL(10, 2),
ranking INT,
ranking_weeks INT
);위에 코드가 복잡했던 이유는 각 컬럼마다 자료형이 달라서 해당 자료형에 맞춰줘야 데이터가 들어가기 때문에 맞춰준 것이다.
3. 수집한 데이터 분석하기
MySQL Workbench를 이용해서 작업했다.
코드 실행시 테이블 이름 Books를 books로 작성해주길 바란다.
1) 기본 조회 및 필터링
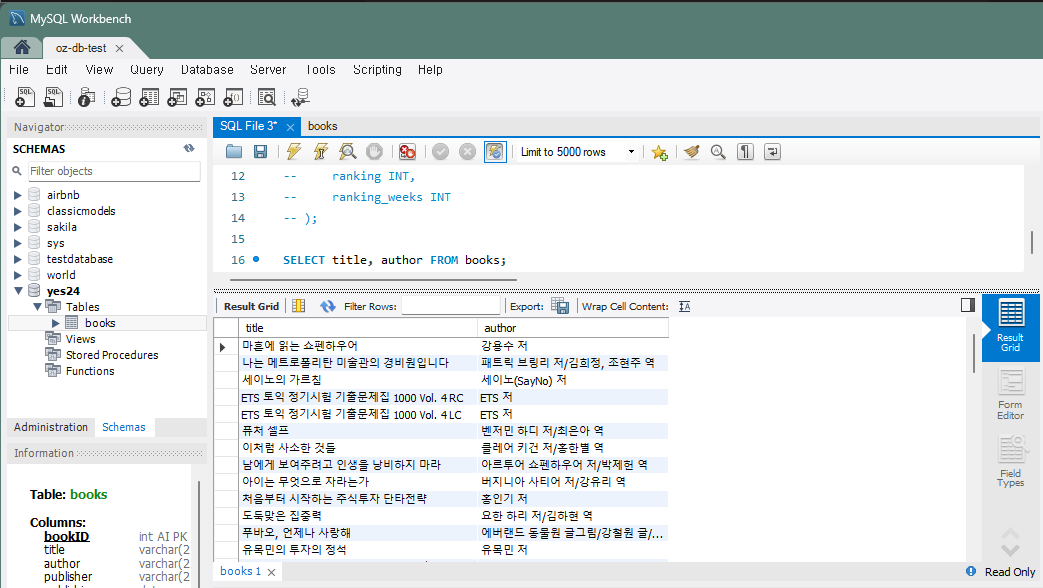
문제 1) 모든 책의 제목과 저자를 조회하세요.
SELECT title, author FROM Books;실행하면
문제 2) 평점이 8 이상인 책 목록을 조회하세요.
SELECT title, rating FROM Books WHERE rating >= 4;실행하면
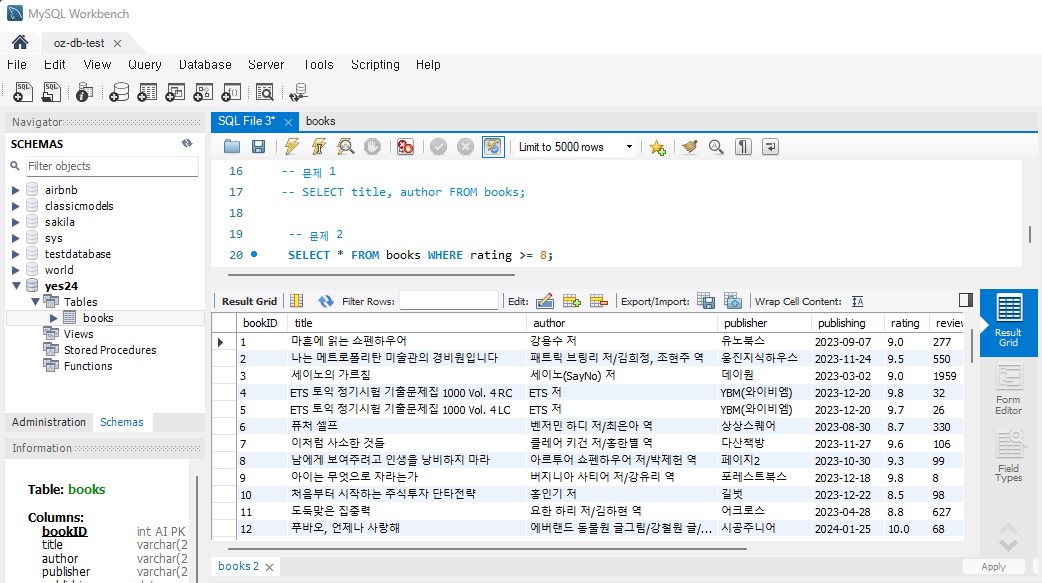
리뷰가 없거나 평점이 8점 이하인 책은 제외되어 보여준다.
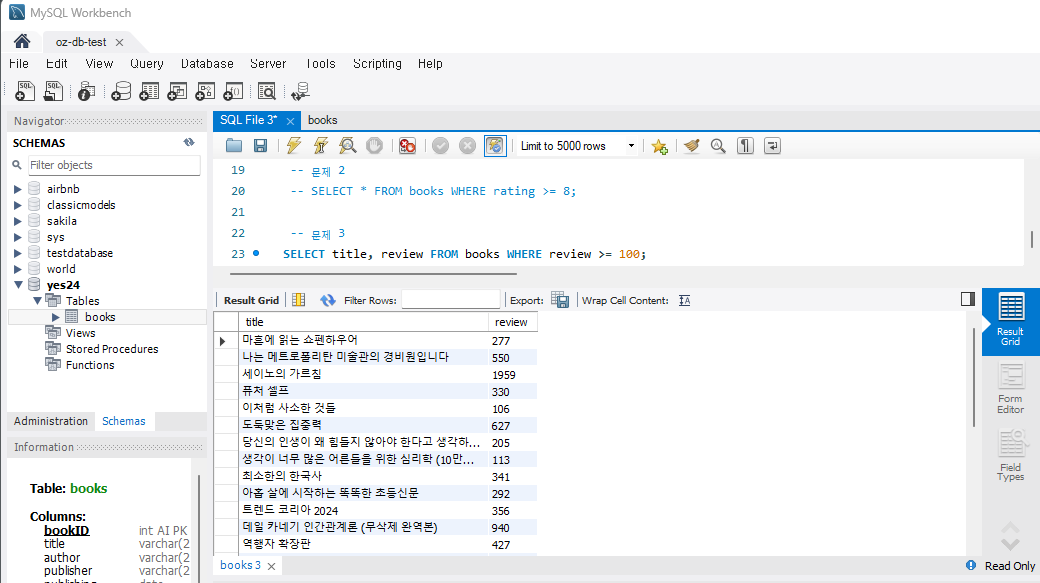
문제 3) 리뷰 수가 100개 이상인 책들의 제목과 리뷰 수를 조회하세요.
SELECT title, review FROM Books WHERE review >= 100;
-- 내림차순(리뷰 많은 순)을 원한다면 뒤에 'ORDER BY review DESC를 추가하면 된다.실행하면
문제 4) 가격이 20,000원 미만인 책들의 제목과 가격을 조회하세요.
SELECT title, price FROM Books WHERE price < 20000;실행하면
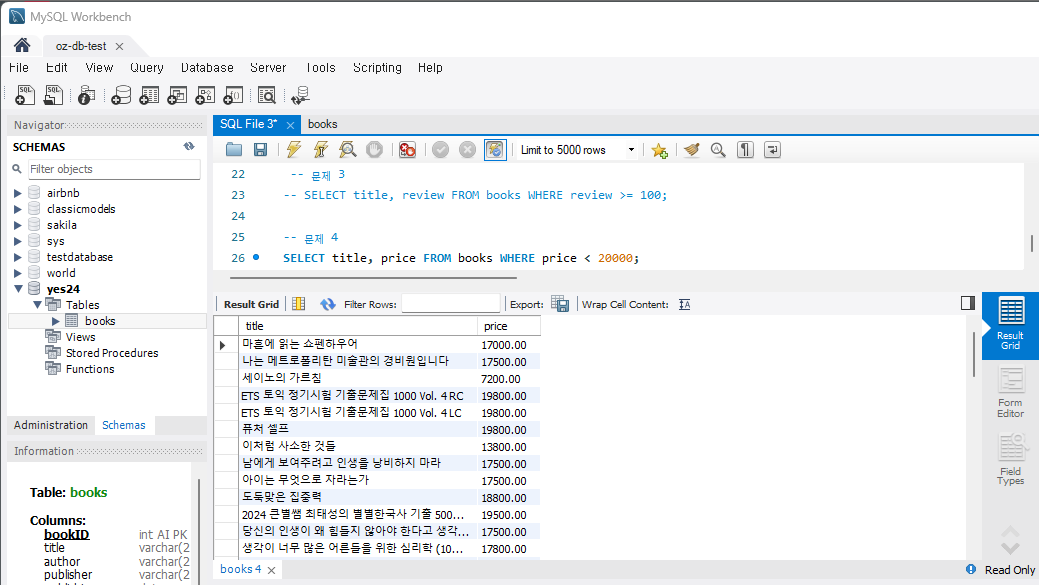
사실 데이터를 끌어올 때 페이지에 나와있는 값이랑 가져온 값이 달랐다. 확인해보니 할인율이 적용이 안되서 원가 데이터를 가져온 것이다. 만약 할인율을 적용했더라면 다른 결과를 가져왔을 수도 있다.
문제 5) 국내도서TOP100에 4주 이상 머문 책들을 조회하세요.
SELECT title, ranking_weeks FROM Books WHERE ranking_weeks >= 4;실행하면
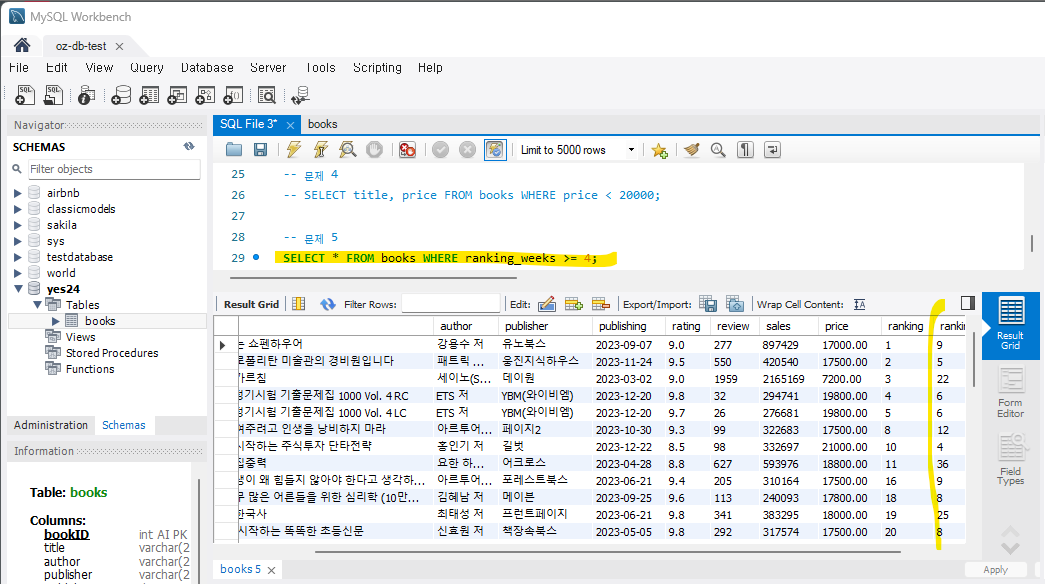
이것도 문제 3번과 동일하게 내림차순으로 정렬하여 4주 이상 국내도서 TOP100에 머문 것 중 가장 오래된 책을 확인할 수 있다.
문제 6) 특정 저자의 모든 책을 조회하세요.
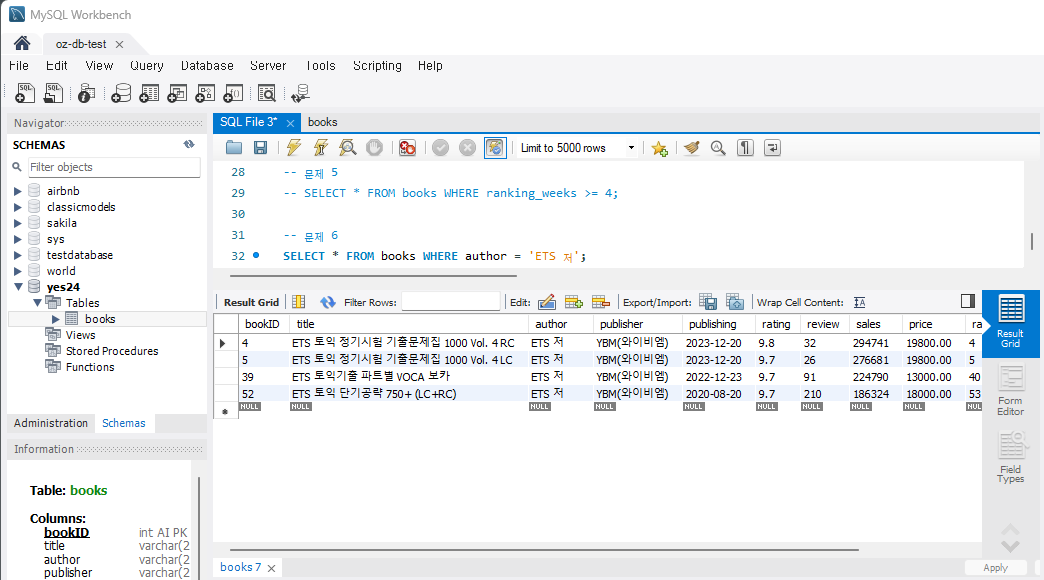
SELECT title FROM Books WHERE author = '저자명';난 'ETS 저'를 조회했는데 실행하면
문제 7) 특정 출판사가 출판한 책들을 조회하세요.
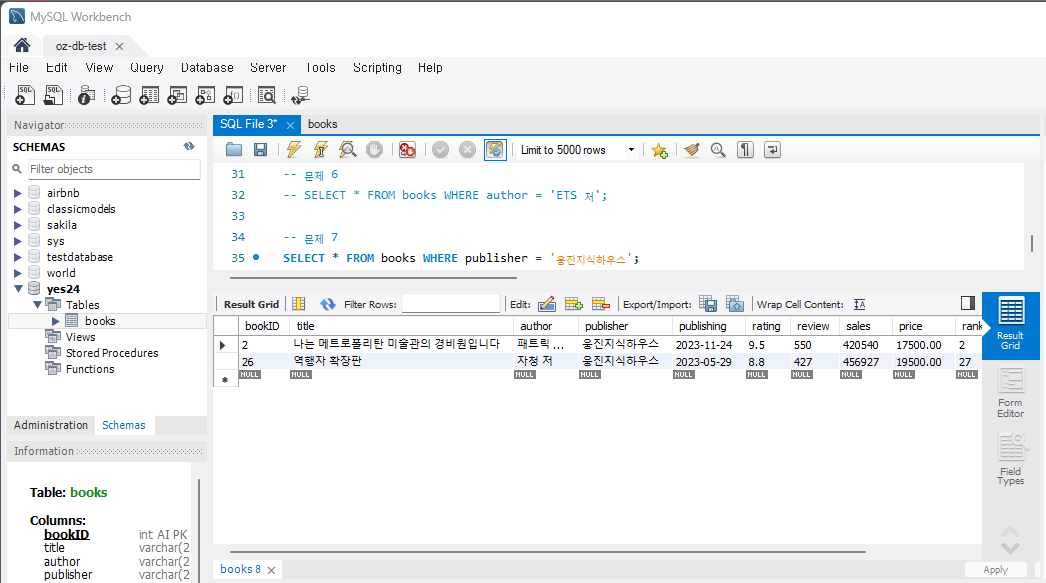
SELECT title FROM Books WHERE publisher = '출판사';나는 '웅진지식하우스'를 조회했다. 실행하면
2) 조인 및 관계
문제 1) 저자별로 출판한 책의 수를 조회하세요.
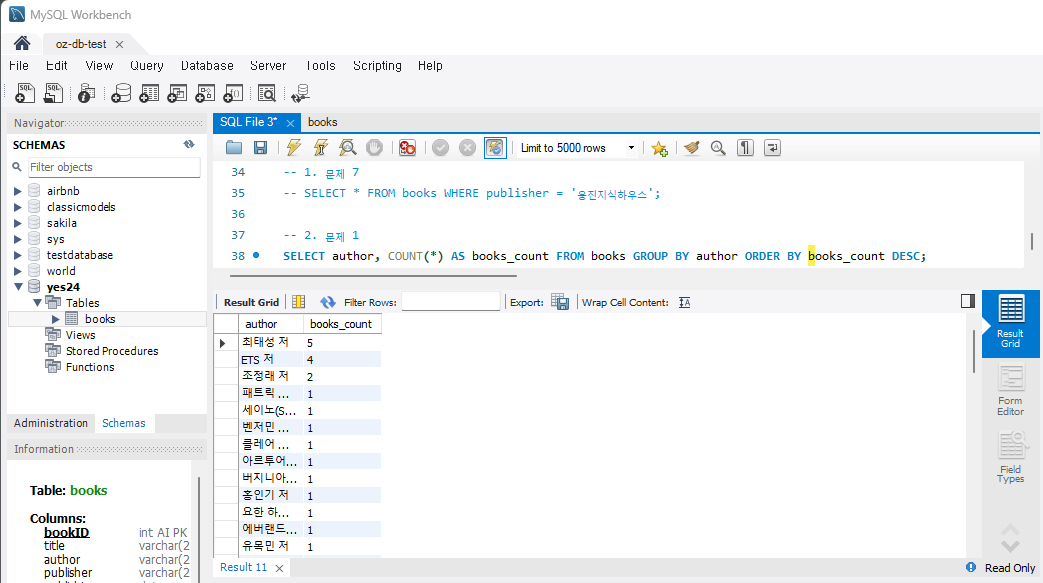
SELECT author, COUNT(*) AS books_count FROM books GROUP BY author ORDER BY books_count DESC;'저자별'이기 때문에 GROUP BY로 묶어준다. 실행하면
이것도 뒤에 ORDER BY author DESC 를 추가하면 내림차순으로 확인가능하다.
문제 2) 가장 많은 책을 출판한 출판사를 찾으세요.
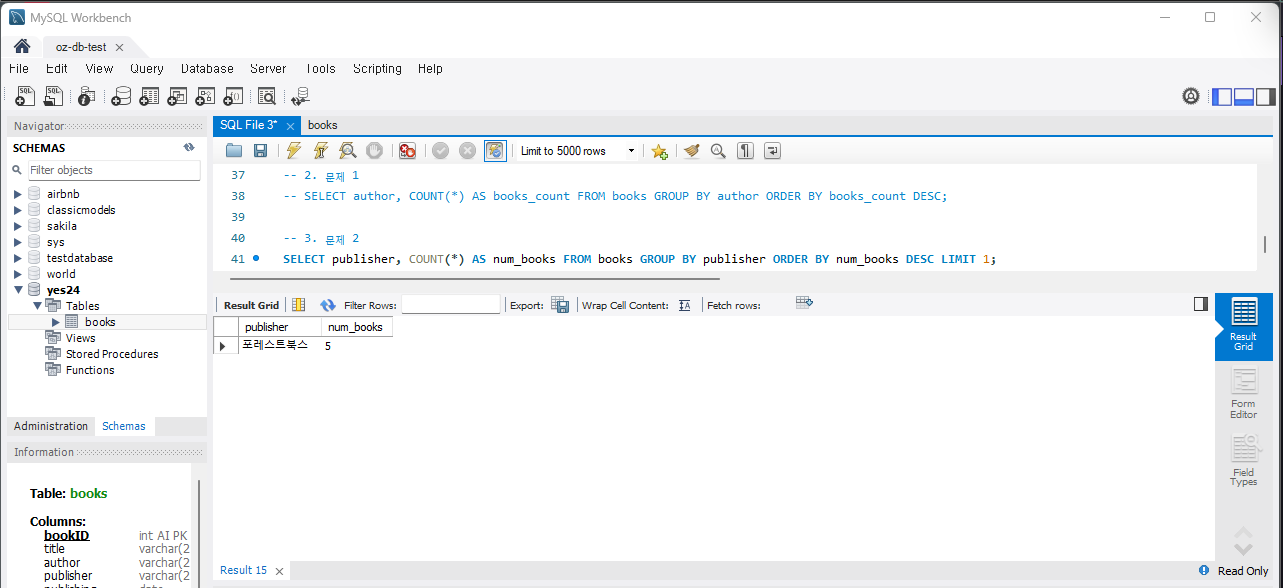
SELECT publisher, COUNT(*) AS num_books FROM Books GROUP BY publisher ORDER BY num_books DESC LIMIT 1;실행하면
문제 3) 가장 높은 평균 평점을 가진 저자를 찾으세요.
SELECT author, AVG(rating) AS avg_rating FROM Books GROUP BY author ORDER BY avg_rating DESC LIMIT 9;우선 LIMIT 없이 조회했을 때 동율이 사람의 수를 확인하고 보여주는 데이터의 수를 조절할 수 있다. 실행하면

문제 4) 국내도서랭킹이 1위인 책의 제목과 저자를 조회하세요.
SELECT title, author FROM Books WHERE ranking = 1;실행하면
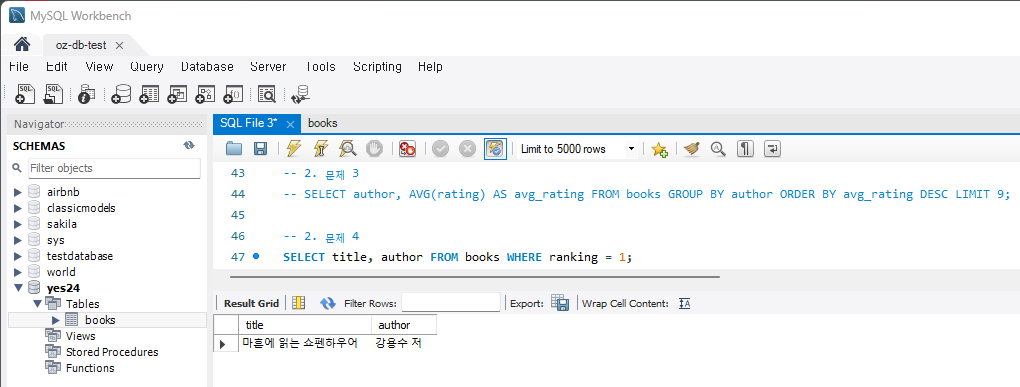
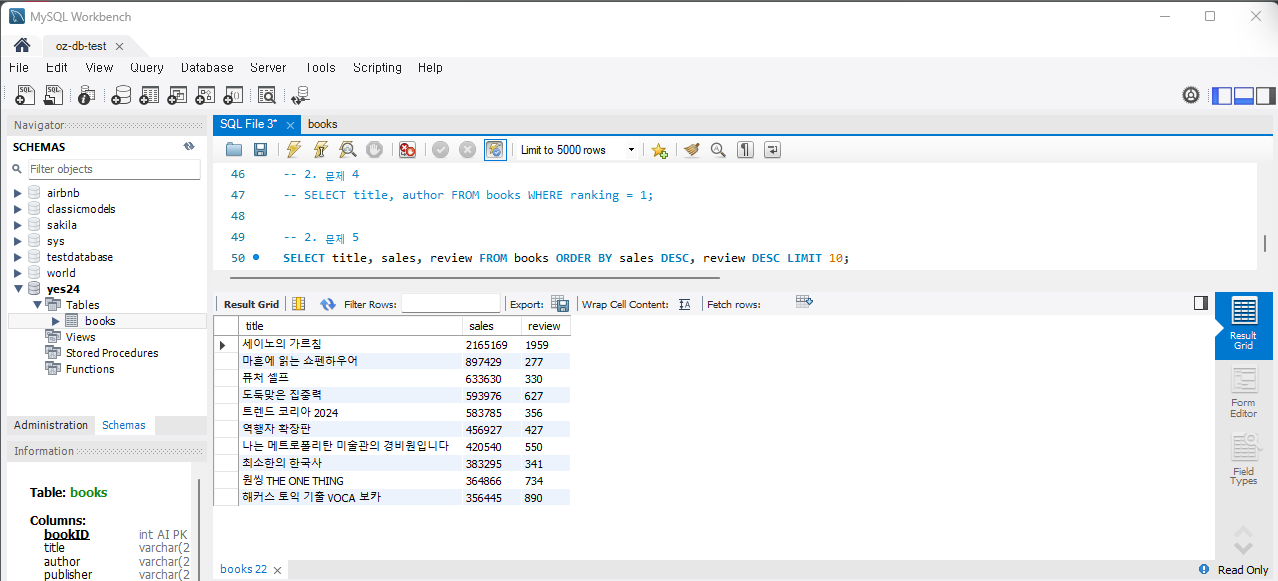
문제 5) 판매지수와 리뷰 수가 모두 높은 상위 10개의 책을 조회하세요.
SELECT title, sales, review FROM Books ORDER BY sales DESC, review DESC LIMIT 10;실행하면
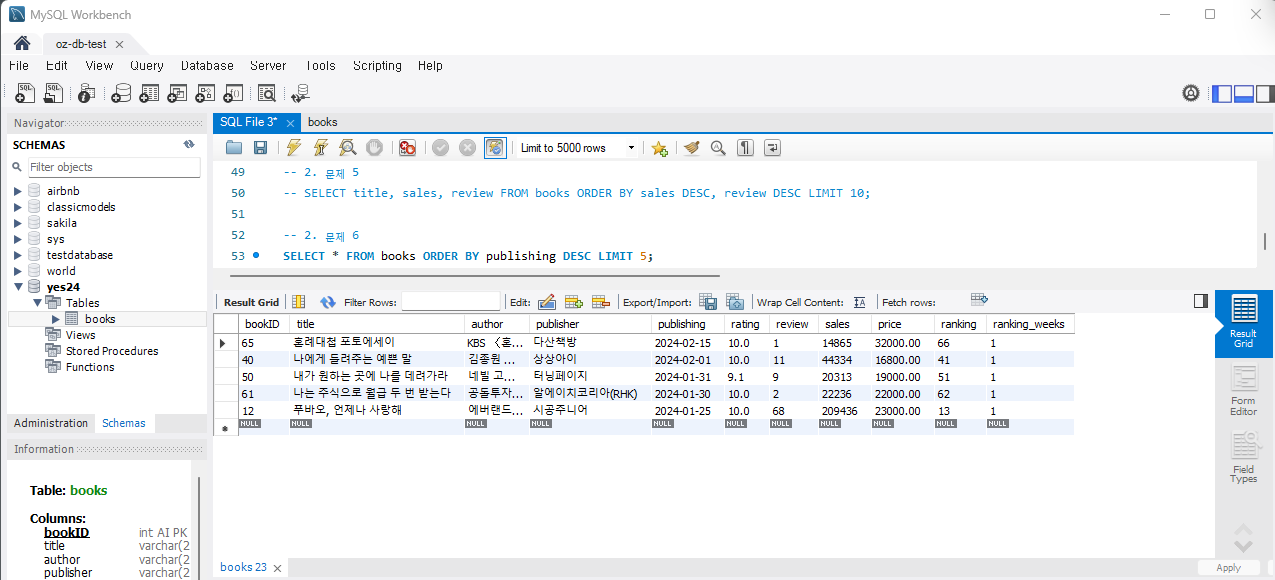
문제 6) 가장 최근에 출판된 5권의 책을 조회하세요.
SELECT title, publishing FROM Books ORDER BY publishing DESC LIMIT 5;실행하면
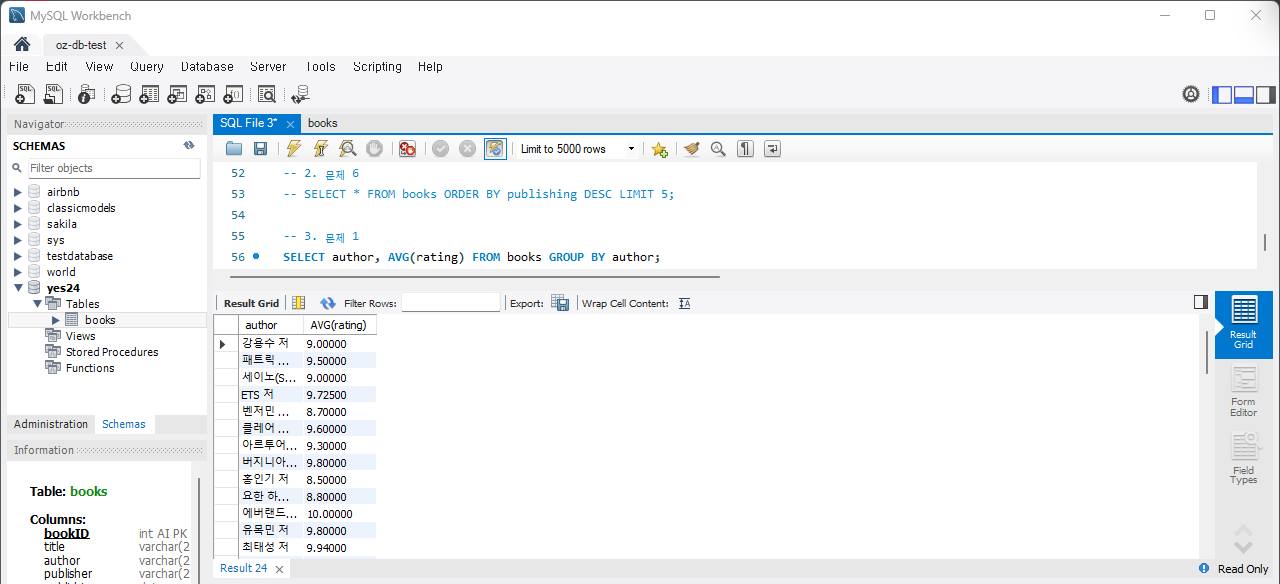
3) 집계 및 그룹화
문제 1) 저자별 평균 평점을 계산하세요.
SELECT author, AVG(rating) FROM Books GROUP BY author;실행하면
문제 2) 출판일별 출간된 책의 수를 계산하세요.
SELECT publishing, COUNT(*) FROM Books GROUP BY publishing;실행하면
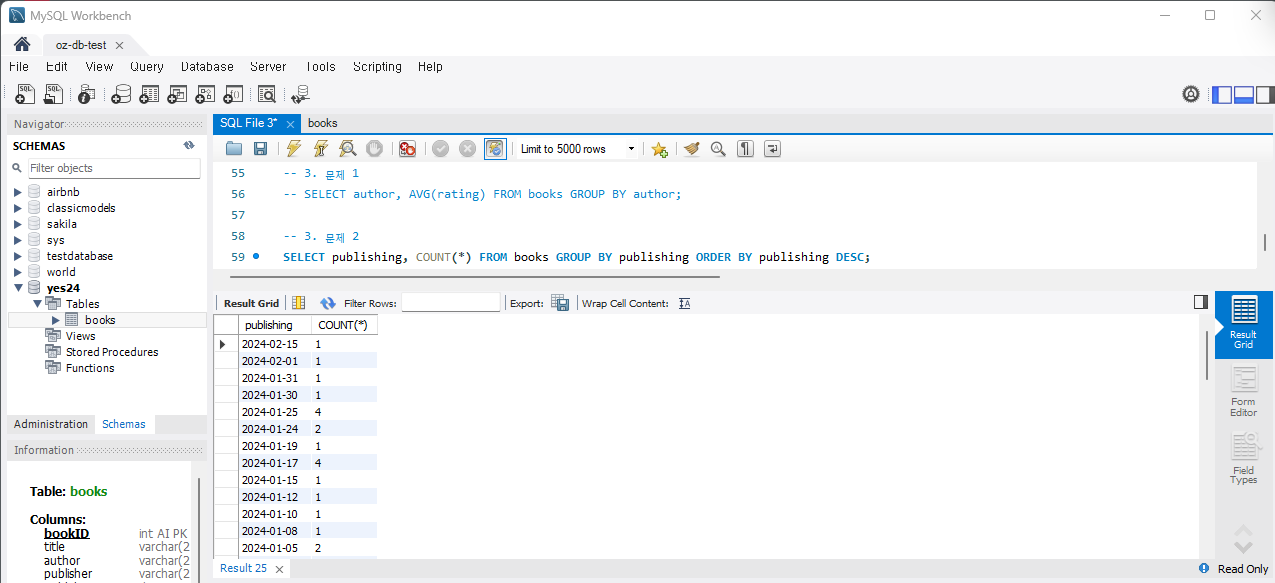
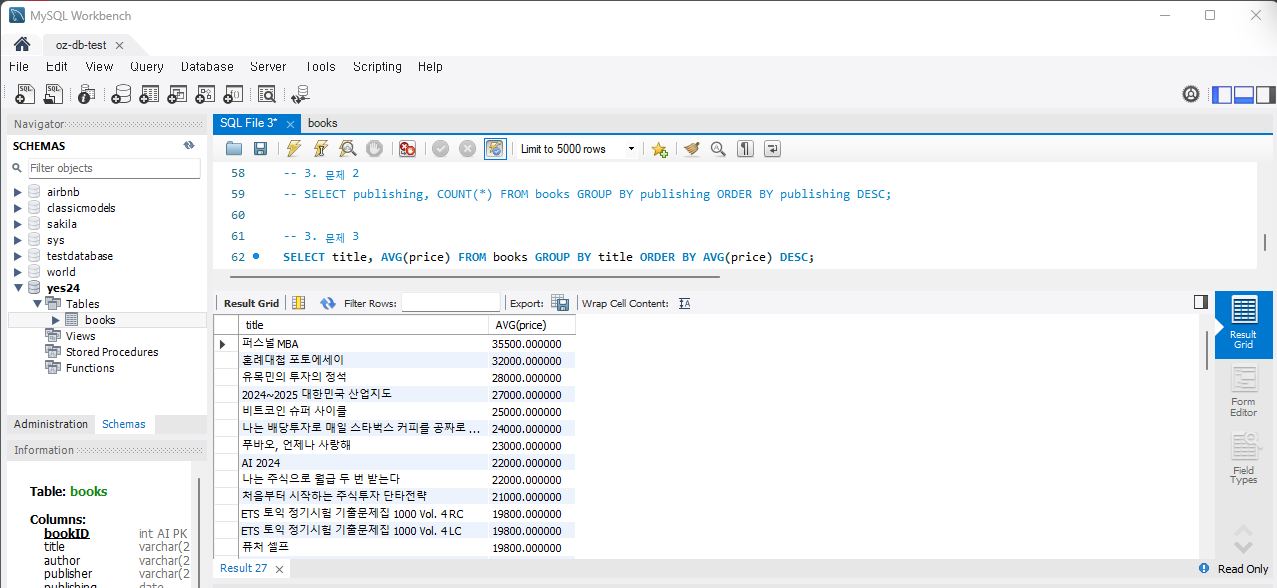
문제 3) 책 제목별 평균 가격을 조회하세요.
SELECT title, AVG(price) FROM Books GROUP BY title;책이 다 1권씩이라 평균을 하면 무슨 의미가 있겠냐만,,,실행하면
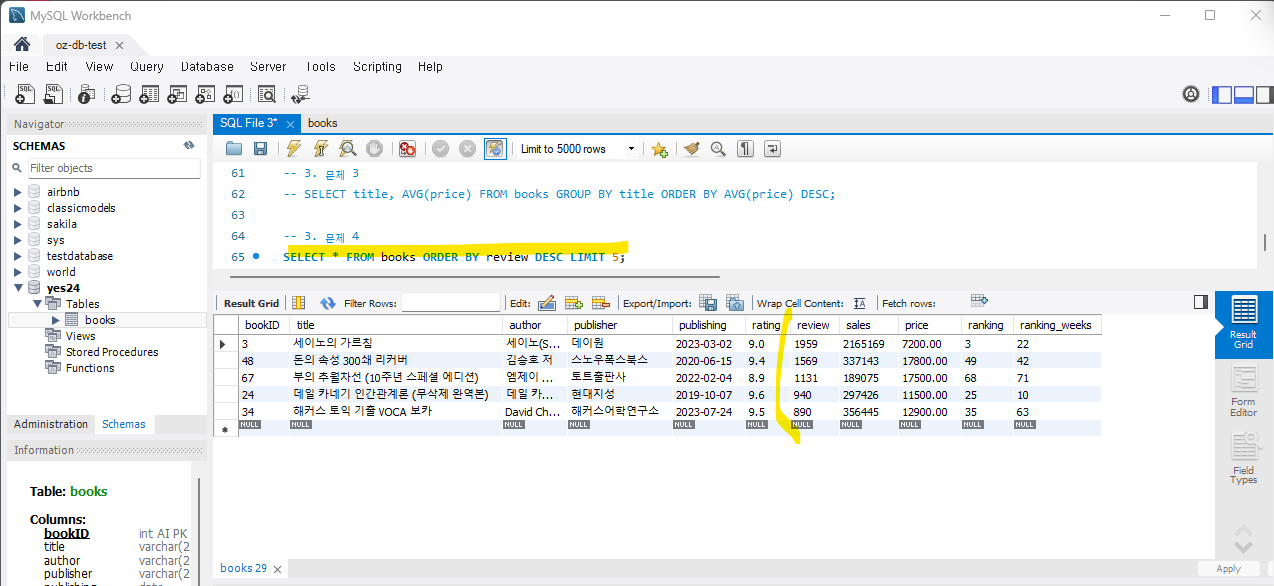
문제 4) 리뷰 수가 가장 많은 상위 5권의 책을 찾으세요.
SELECT title, review FROM Books ORDER BY review DESC LIMIT 5;실행하면
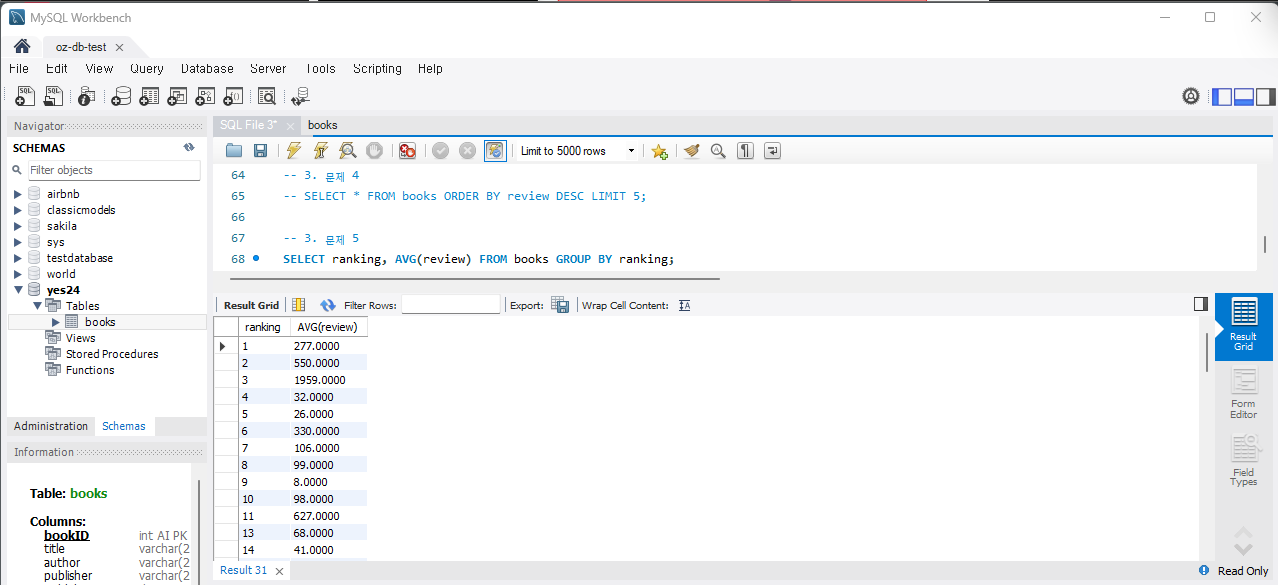
문제 5) 국내도서랭킹 별 평균 리뷰 수를 계산하세요.
SELECT ranking, AVG(review) FROM Books GROUP BY ranking;실행하면
4) 서브쿼리 및 고급 기능
문제 1) 평균 평점보다 높은 평점을 받은 책들을 조회하세요.
SELECT title, rating FROM Books WHERE rating > (SELECT AVG(rating) FROM Books);실행하면
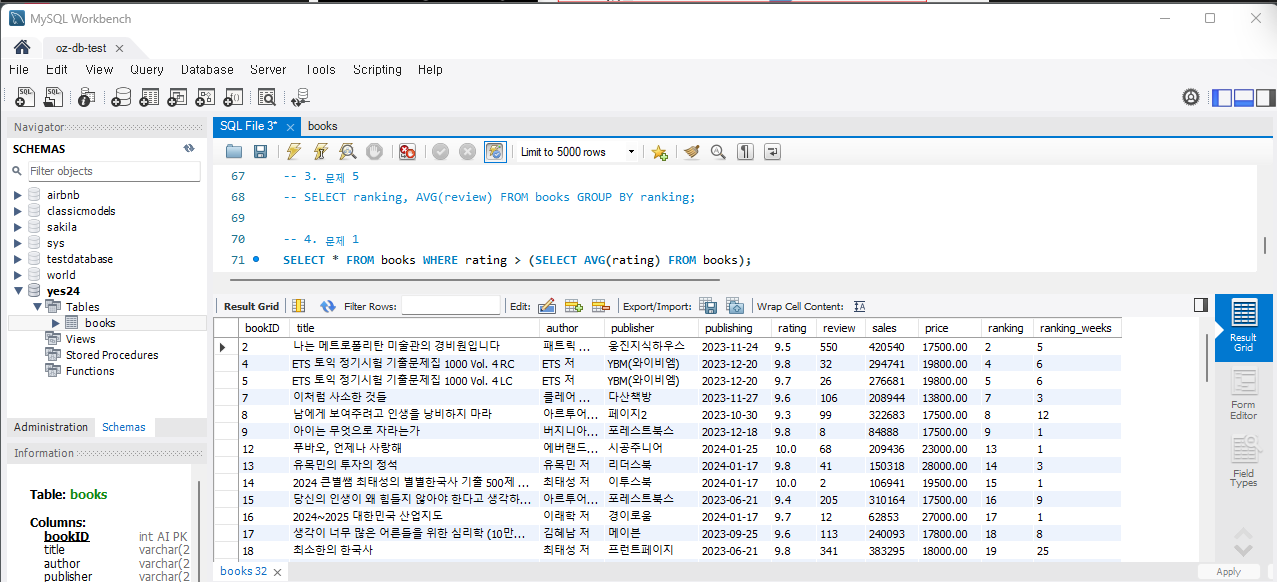
문제 2) 평균 가격보다 비싼 책들의 제목과 가격을 조회하세요.
SELECT title, price FROM Books WHERE price > (SELECT AVG(price) FROM Books);실행하면
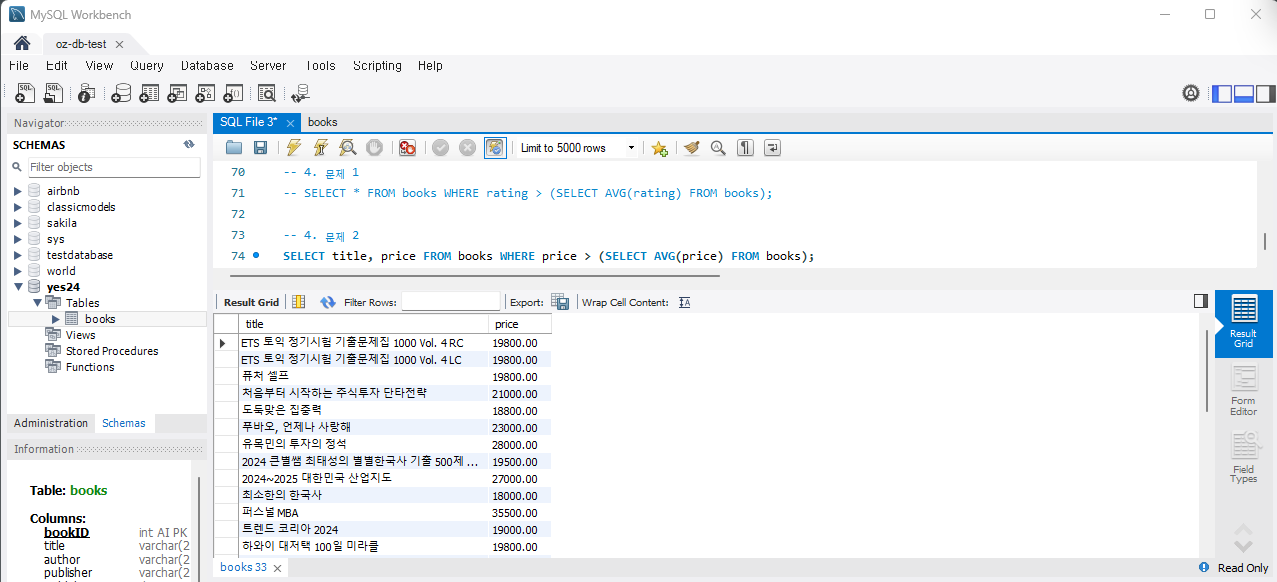
문제 3) 최댓값 리뷰를 받은 책보다 많은 리뷰를 받은 다른 책들을 조회하세요.
SELECT title, review FROM Books WHERE review > (SELECT MAX(review) FROM Books);
-- 여기서는 말이 안되는데 통계학에서 MAX를 말하는 것이다!실행하면
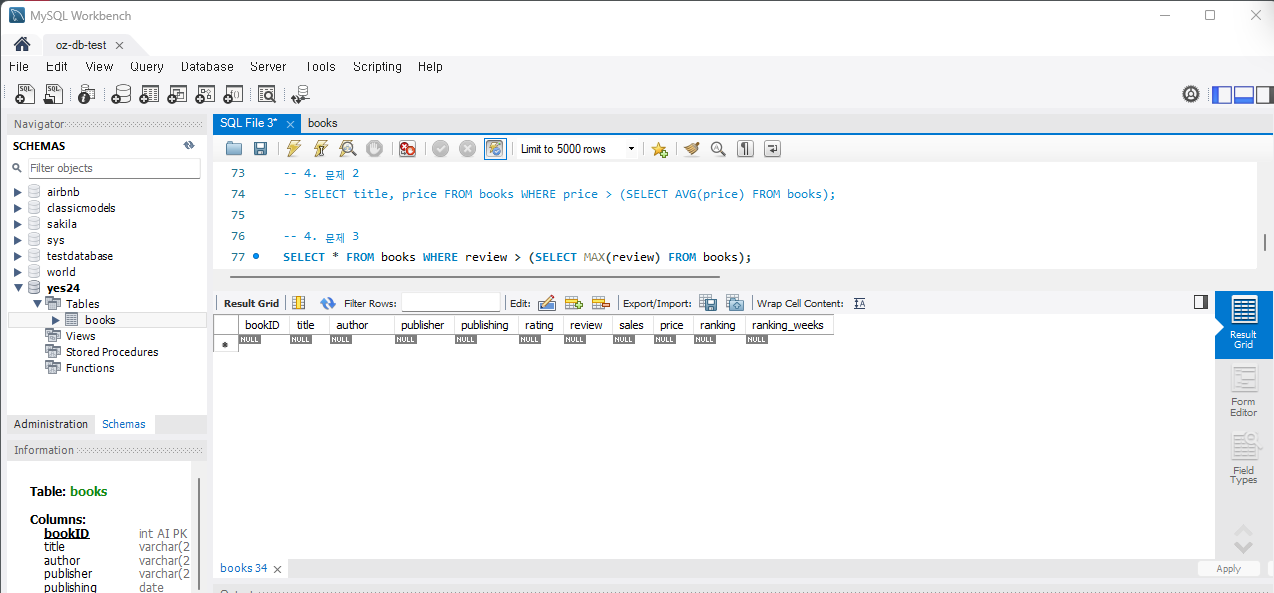
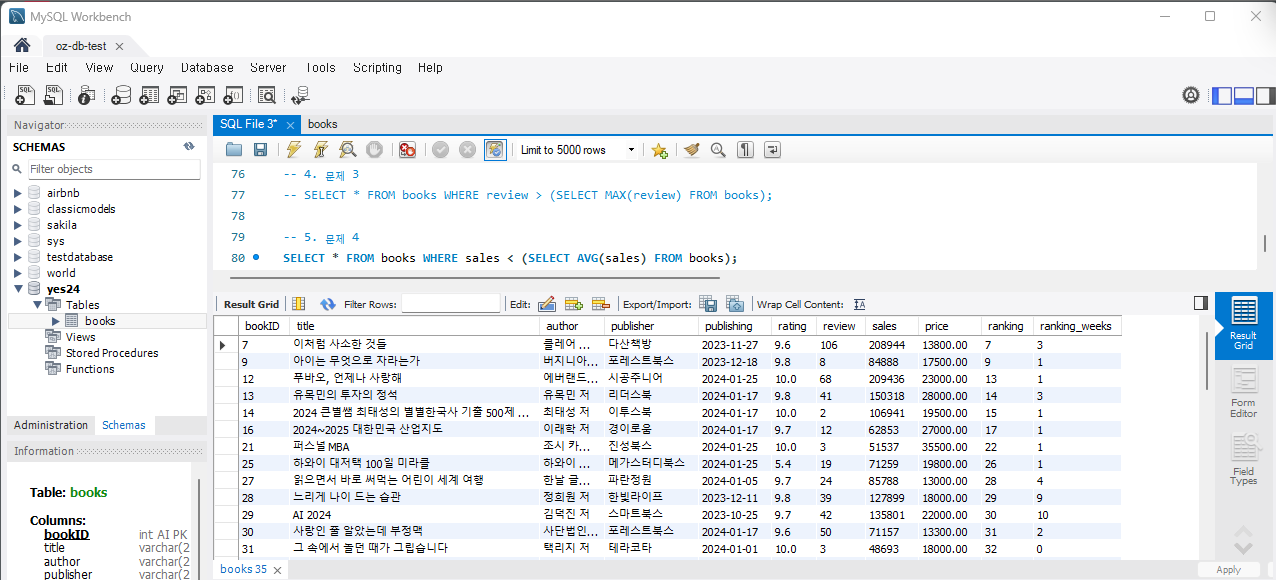
문제 4) 평균 판매지수보다 낮은 판매지수를 가진 책들을 조회하세요.
SELECT title, sales FROM Books WHERE sales < (SELECT AVG(sales) FROM Books);실행하면
문제 5) 가장 많이 출판된 저자의 책들 중 최근에 출판된 책을 조회하세요.
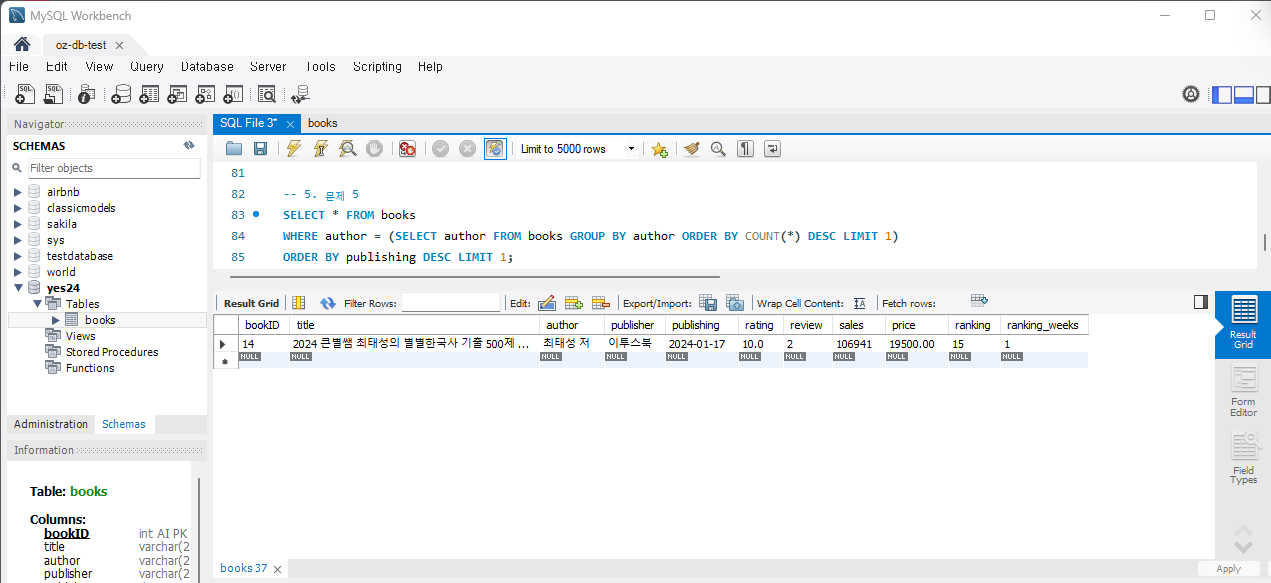
SELECT title, publishing FROM Books WHERE author = (SELECT author FROM Books GROUP BY author ORDER BY COUNT(*) DESC LIMIT 1) ORDER BY publishing DESC LIMIT 1;복잡해 보이지만
1)가장 많이 출판된 저자의 책들
2) 그리고 그 저자의 출판된 책 출판일로 정렬 하면 쉽게 찾을 수 있다.
실행하면
5) 데이터 수정 및 관리
UPDATE 문은 실행하려고하면 경고가 떠서 따라하기만 해보았다.
(경고 없이 진행하고 싶으신 분은 아래 코드를 작성한 후 따라해보길 바란다.)
-- SQL 안전모드 해제
SET SQL_SAFE_UPDATES = 0;문제 1) 특정 책의 가격을 업데이트하세요.
UPDATE Books SET price = 30000 WHERE title = 'New Book Title';문제 2) 특정 저자의 책 제목을 변경하세요.
UPDATE Books SET title = 'Updated Title' WHERE author = '홍길동';문제 3) 판매지수가 가장 낮은 책을 데이터베이스에서 삭제하세요.
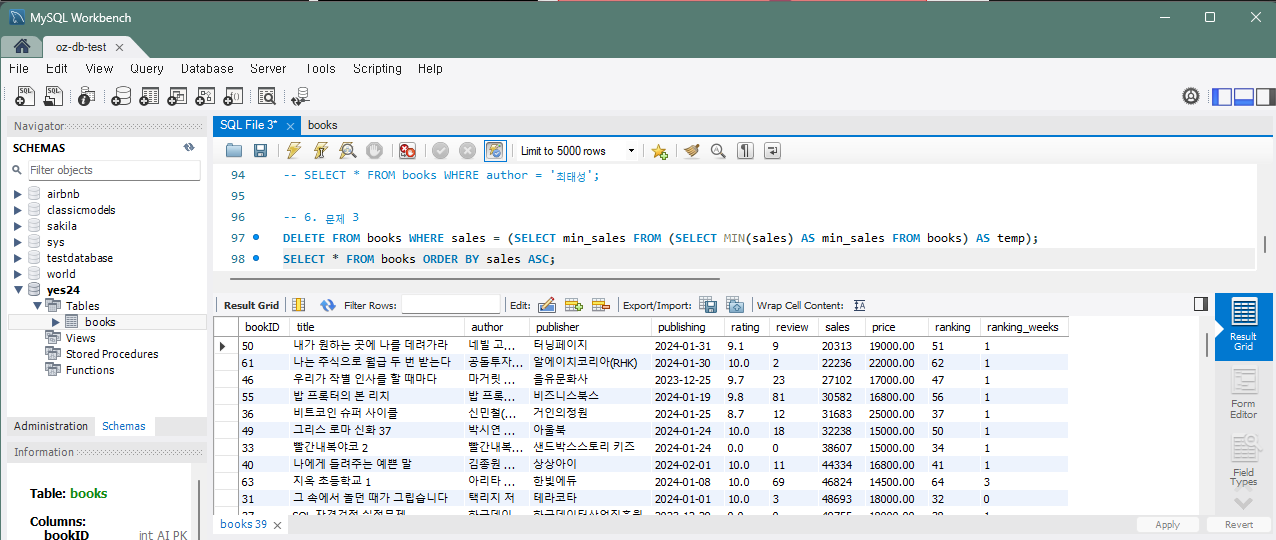
데이터 베이스에서 삭제하려면 한번에 삭제할 수 없다. 중간 테이블을 작성하여 삭제하여야 한다.
DELETE FROM Books WHERE sales = (SELECT MIN(sales) FROM Books);실행 전 판매지수가 가장 낮은 책은 '혼례대첩 포토에세이'였는데 실행하면 사라진 것을 확인할 수 있다.
문제 4) 특정 출판사가 출판한 모든 책의 평점을 1점 증가시키세요.
UPDATE Books SET rating = rating + 1 WHERE publisher = '민음사';6) 데이터 분석 예제
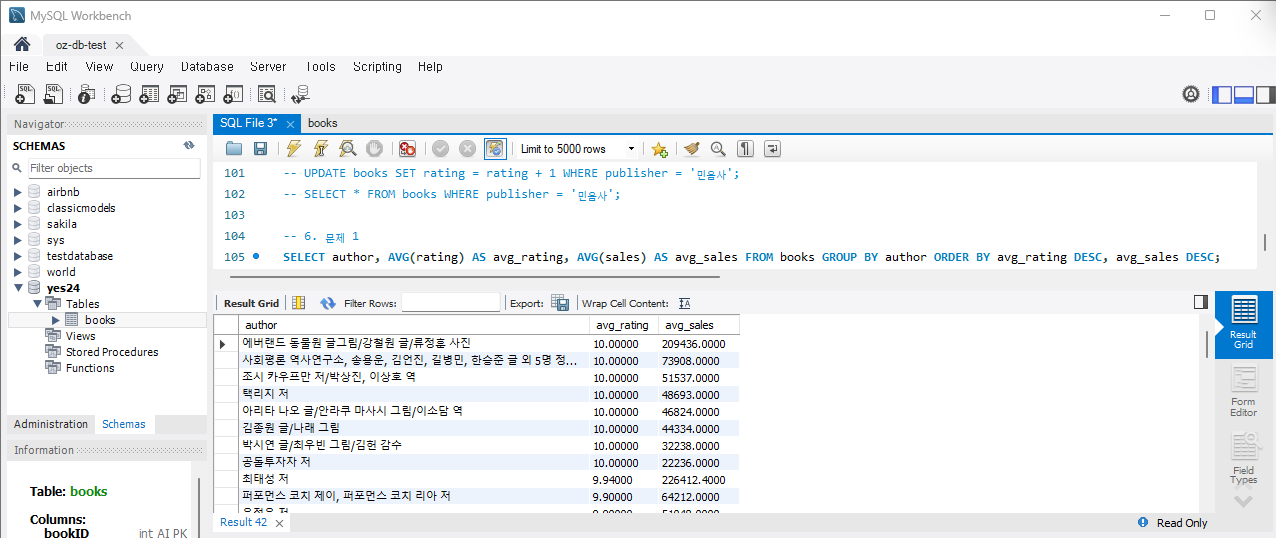
문제 1) 저자별 평균 평점 및 판매지수를 분석하여 인기 있는 저자를 확인합니다.
SELECT author, AVG(rating) as avg_rating, AVG(sales) as avg_sales FROM Books GROUP BY author;난 평점과 판매지수를 내림차순하였다. 실행하면
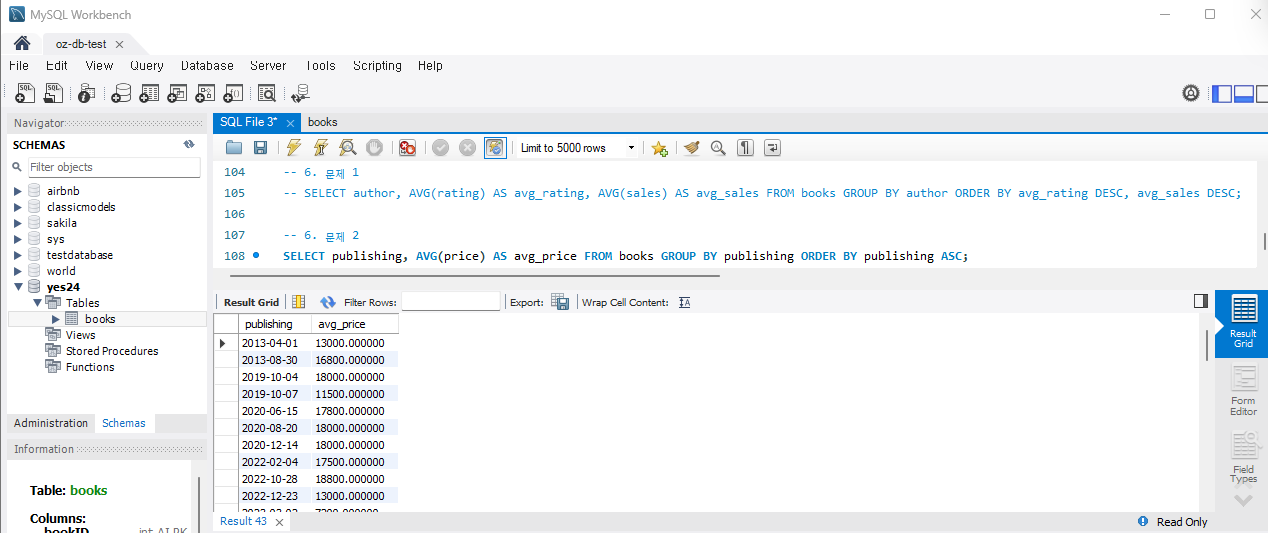
문제 2) 출판일에 따른 책 가격의 변동 추세를 분석합니다.
SELECT publishing, AVG(price) as avg_price FROM Books GROUP BY publishing;나는 출판일 순으로 오름차순 정렬하였다. 실행하면
문제 3) 출판사별 출간된 책의 수와 평균 리뷰 수를 비교 분석합니다.
SELECT publisher, COUNT(*) as num_books, AVG(review) as avg_review FROM Books GROUP BY publisher;나는 출판사별 출간된 책의 수를 내림차순으로 정렬했다. 실행하면
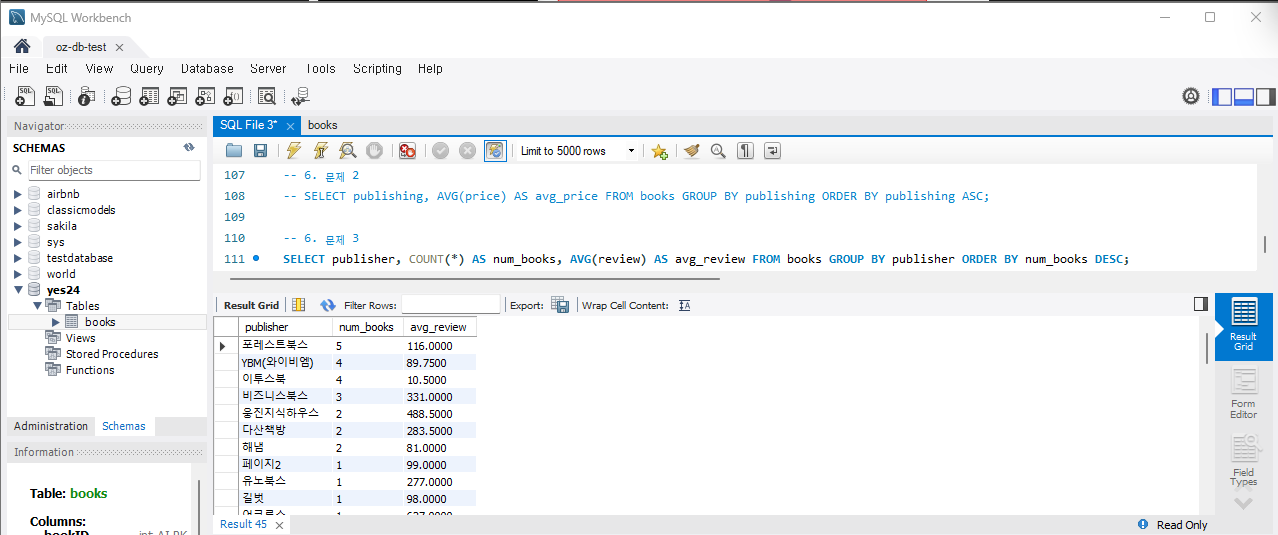
문제 4) 국내도서랭킹과 판매지수의 상관관계를 분석합니다.
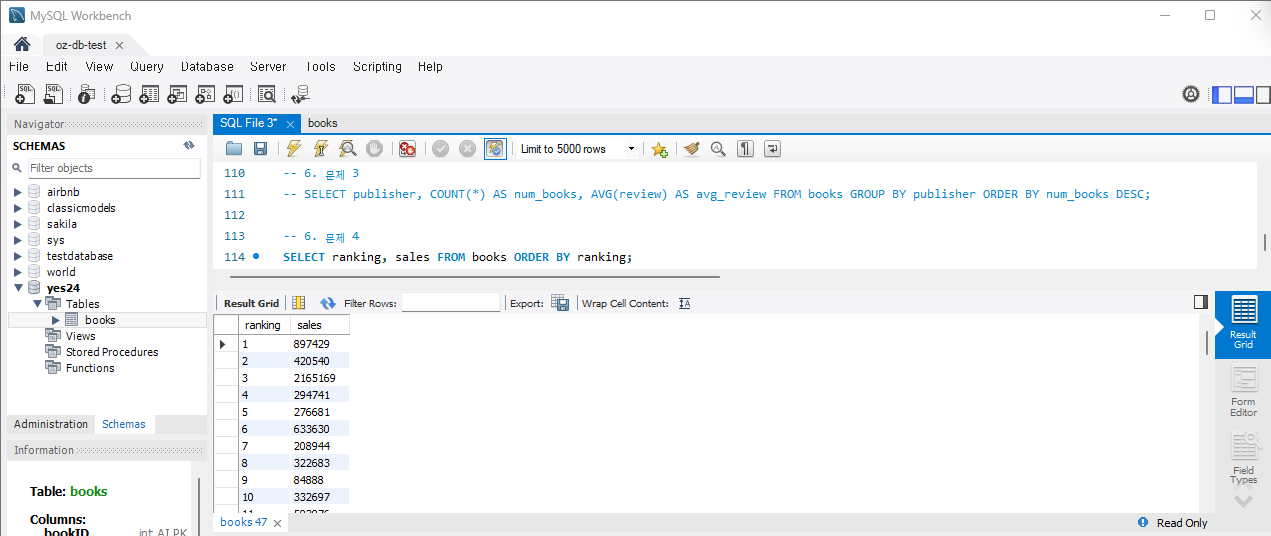
SELECT ranking, AVG(sales) as avg_sales FROM Books GROUP BY ranking;
-- SELECT ranking, sales FROM books ORDER BY ranking; 이거와 동일.실행하면
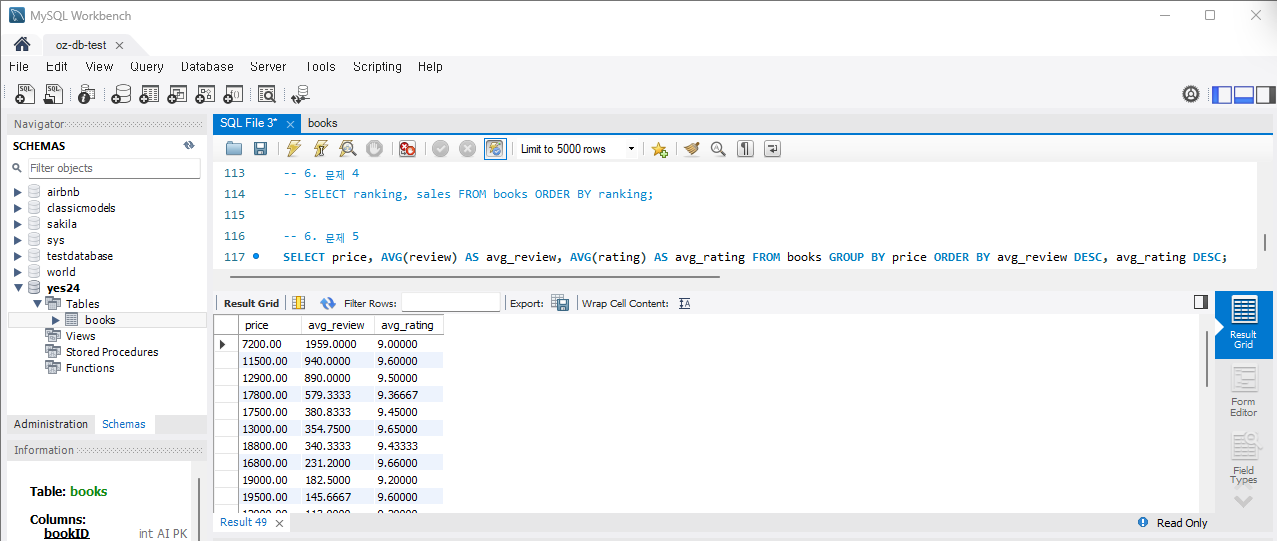
문제 5) 가격 대비 리뷰 수와 평점의 관계를 분석하여 가성비 좋은 책을 찾습니다.
SELECT price, AVG(review) as avg_review, AVG(rating) as avg_rating FROM Books GROUP BY price;나는 평균 리뷰수와 평균 평점을 기준으로 내림차순 정렬하였다. 실행하면
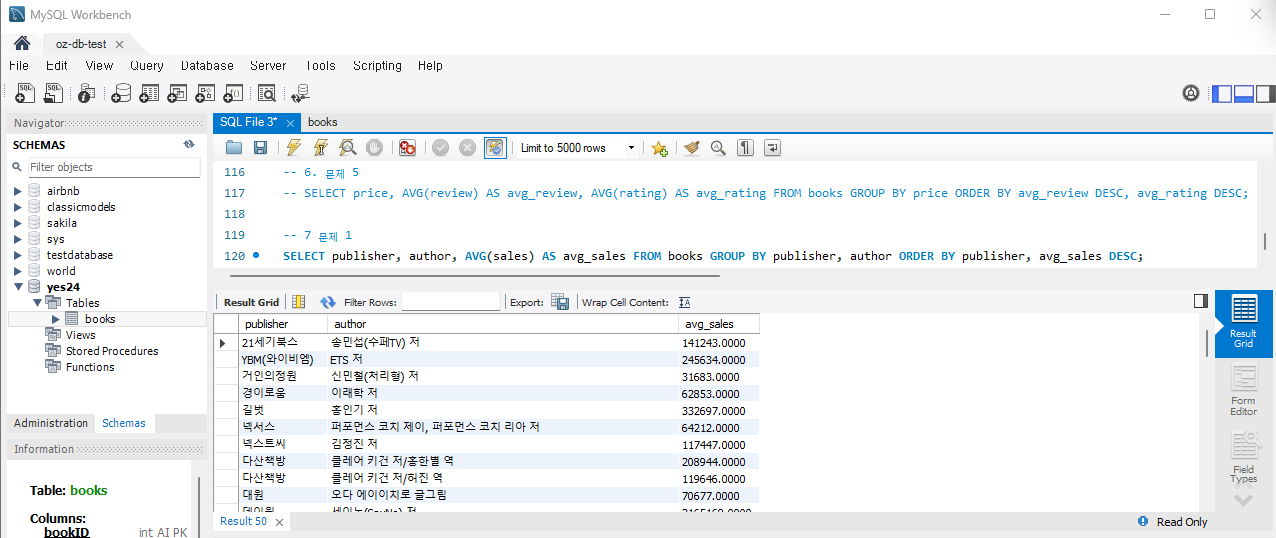
7) 난이도 있는 문제
문제 1 ) 출판사별 평균 판매지수가 가장 높은 저자 찾기
각 출판사별로 평균 판매지수가 가장 높은 저자의 이름과 그 평균 판매지수를 조회하세요.
SELECT publisher, author, AVG(sales) as avg_sales
FROM Books
GROUP BY publisher, author
ORDER BY publisher, avg_sales DESC실행하면
문제 2) 리뷰 수가 평균보다 높으면서 가격이 평균보다 낮은 책 조회
리뷰 수와 가격의 전체 평균을 계산한 후, 이보다 리뷰 수는 높고 가격은 낮은 책들을 조회하세요.
SELECT title, review, price
FROM Books
WHERE review > (SELECT AVG(review) FROM Books) AND price < (SELECT AVG(price) FROM Books);실행하면
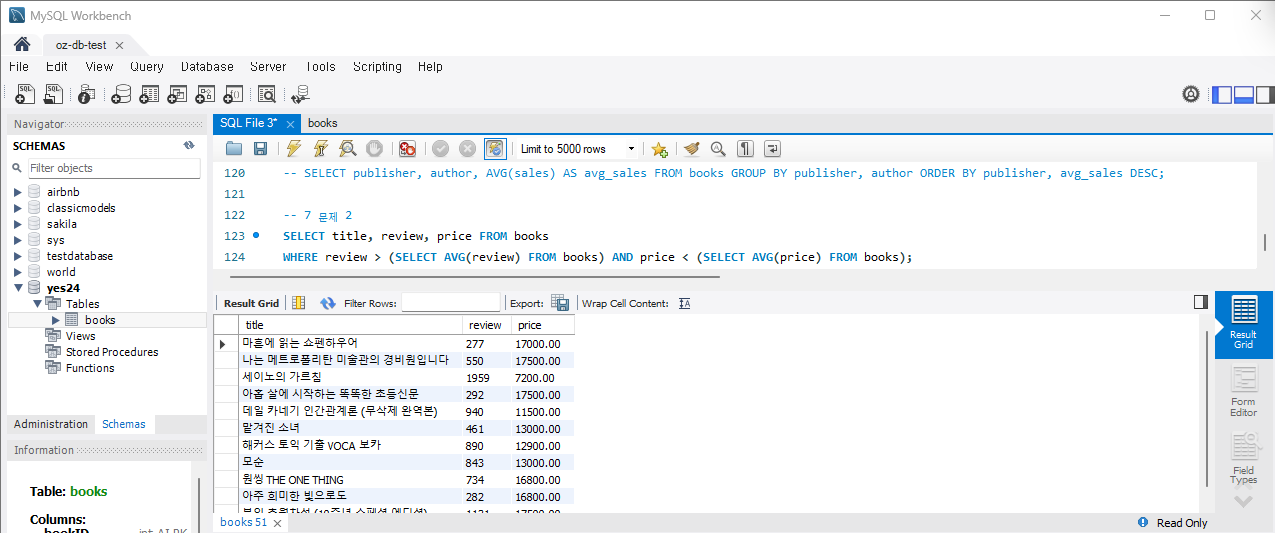
문제 3) 가장 많은 종류의 책을 출판한 저자 찾기
서로 다른 제목의 책을 가장 많이 출판한 저자를 찾으세요.
SELECT author, COUNT(DISTINCT title) as num_books
FROM Books
GROUP BY author
ORDER BY num_books DESC
LIMIT 1;실행하면
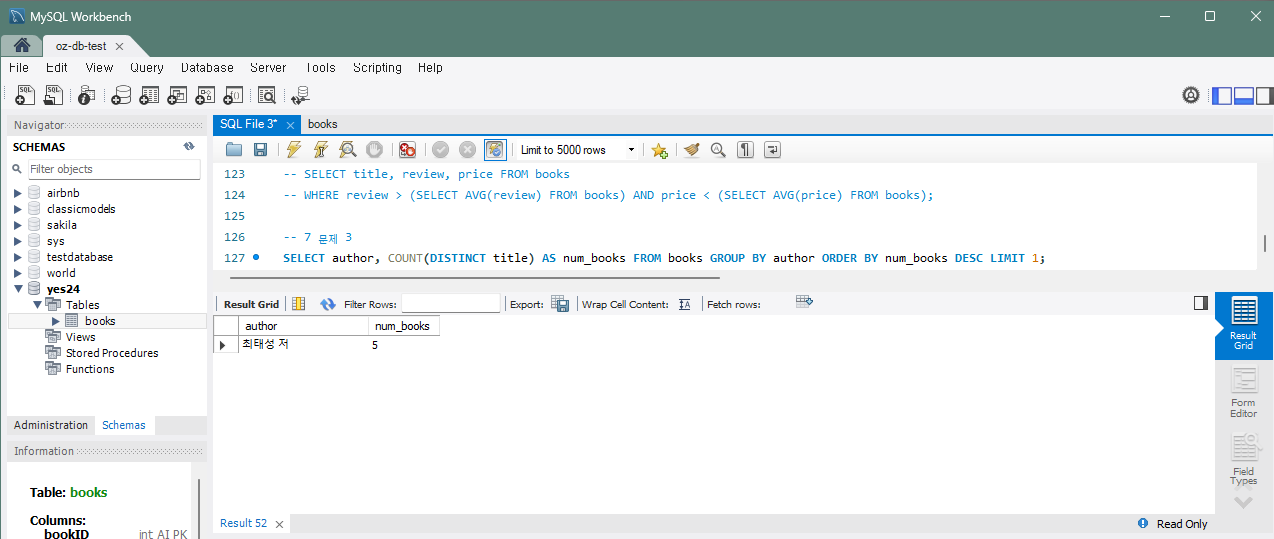
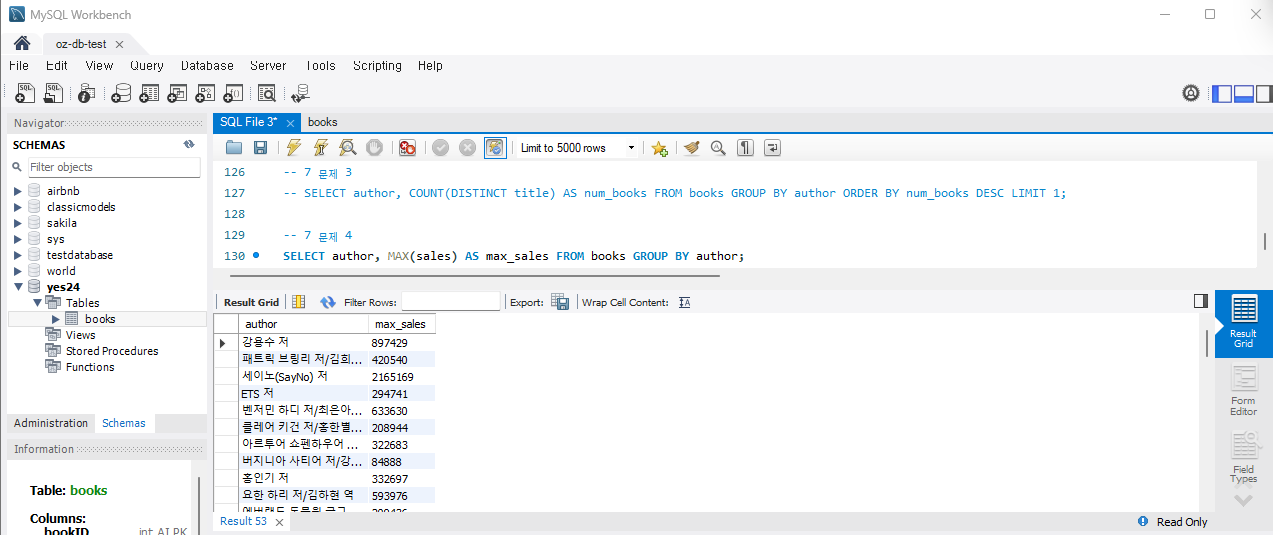
문제 4) 각 저자별로 가장 높은 판매지수를 기록한 책 조회
각 저자별로 가장 높은 판매지수를 기록한 책의 제목과 그 판매지수를 조회하세요.
SELECT author, MAX(sales) as max_sales
FROM Books
GROUP BY author;책 제목까지 보려면 다른 테이블로 만들어서 JOIN 이런것을 해야하는데 현재는 테이블이 하나이기 때문에 볼 수 없다. 실행하면
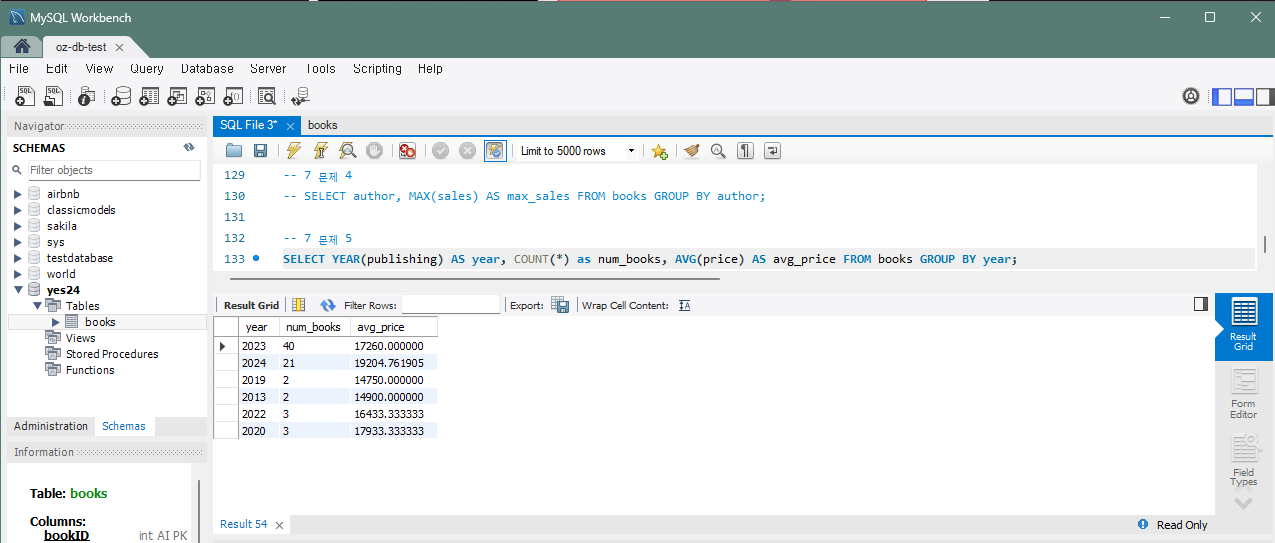
문제 5) 연도별 출판된 책 수와 평균 가격 비교
연도별로 출판된 책의 수와 그 해 출판된 책들의 평균 가격을 비교 분석하세요.
SELECT YEAR(publishing) as year, COUNT(*) as num_books, AVG(price) as avg_price
FROM Books
GROUP BY year;실행하면
문제 6) 출판사가 같은 책들 중 평점 편차가 가장 큰 출판사 찾기
같은 출판사에서 출판된 책들 중 평점 편차가 가장 큰 출판사와 그 편차를 조회하세요.
SELECT publisher, MAX(rating) - MIN(rating) as rating_difference
FROM Books
GROUP BY publisher
ORDER BY rating_difference DESC
LIMIT 1;실행하면
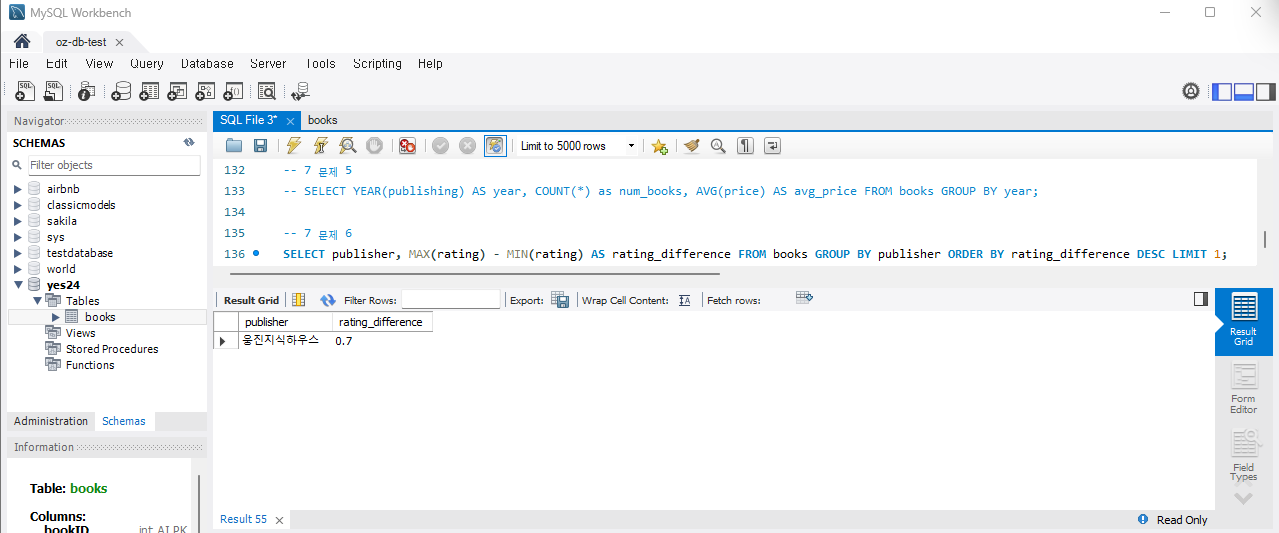
문제 7) 특정 저자의 책들 중 판매지수 대비 평점이 가장 높은 책 찾기
특정 저자의 책들 중 판매지수 대비 평점이 가장 높은 책의 제목과 그 비율을 조회하세요.
SELECT title, rating / sales as ratio
FROM Books
WHERE author = '특정 저자'
ORDER BY ratio DESC
LIMIT 1;나는 '최태성 저'를 조회했다. 실행하면
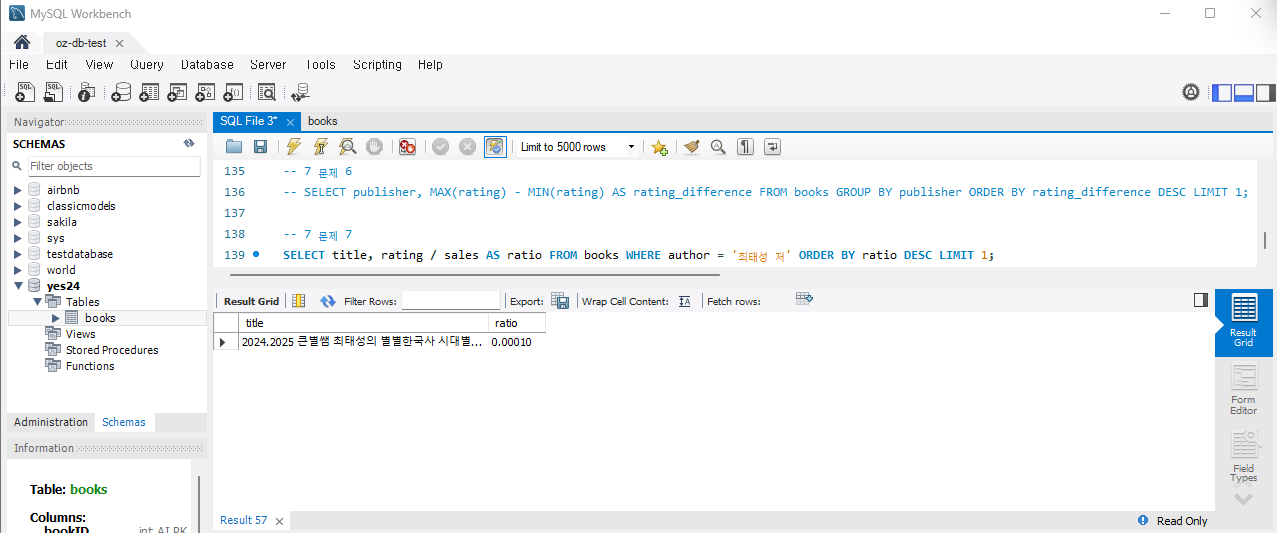
04. Mini Project -2
MySQL에서 제공하는 Sakila Example 을 가지고 SQL 분석을 한다.
MySQL에서 제공하는 샘플 데이터 셋으로 DVD 대여점에 관한 데이터다. 영화, 배우, 직원, 고객 등에 대한 테이블을 포함되어 있다.
1. 데이터 조회 및 필터링
문제 1) 특정 배우가 출연한 영화 목록 조회
- 문제 :
배우 'GUINESS PENELOPE'가 출연한 모든 영화의 제목을 조회하시오.
- 힌트 :
actor테이블에서 'GUINESS PENELOPE'의actor_id를 찾습니다.film_actor테이블과film테이블을 조인하여 해당 배우의film_id를 찾고, 이를 통해 영화 제목을 가져옵니다.
- 코드 :
SELECT f.title FROM film f JOIN film_actor fa ON f.film_id = fa.film_id JOIN actor a ON fa.actor_id = a.actor_id WHERE a.first_name = 'PENELOPE' AND a.last_name = 'GUINESS';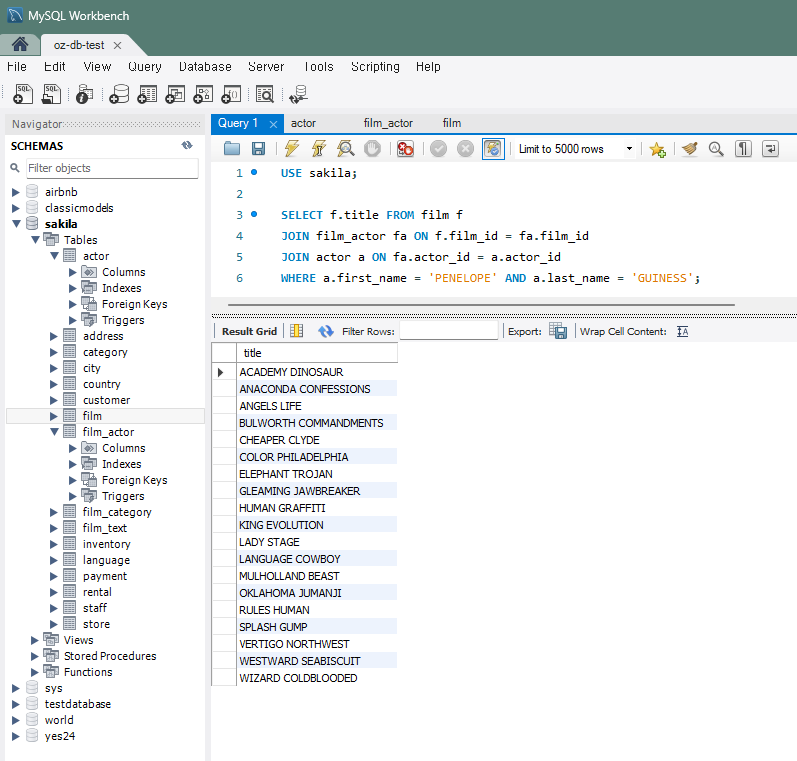
문제 2) 모든 카테고리와 해당 카테고리의 영화 수 조회
- 문제 :
각 카테고리별로 몇 개의 영화가 있는지 조회하시오.
- 힌트 :
category테이블과film_category테이블을 조인합니다.- 집계 함수(
COUNT)를 사용하여 각category_id별 영화 수를 세어 집계합니다.
- 코드 :
SELECT c.name, COUNT(fc.film_id) as number_of_films FROM category c JOIN film_category fc ON c.category_id = fc.category_id GROUP BY c.name;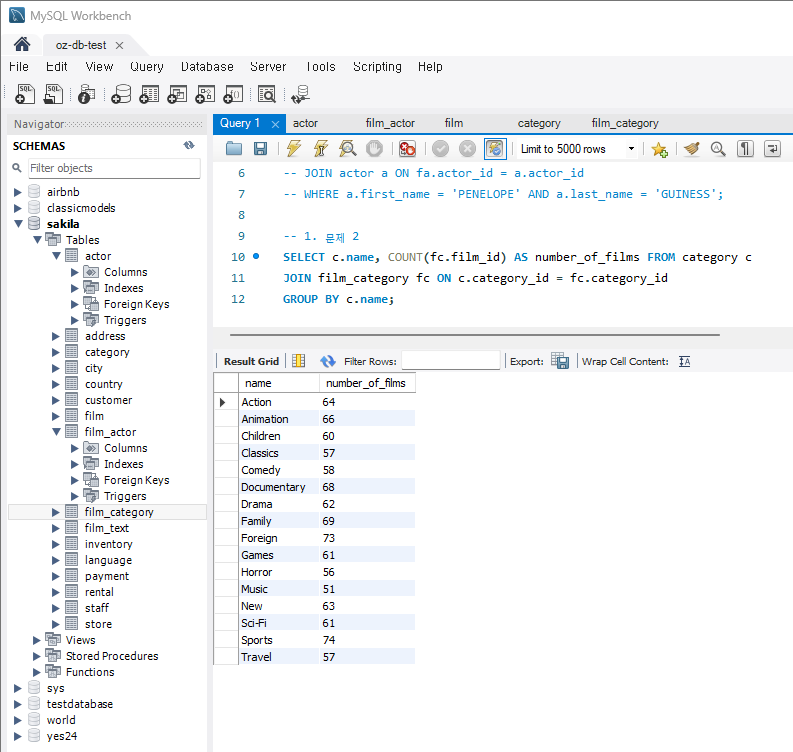
문제 3) 특정 고객의 대여 기록 조회
-
문제 :
고객 ID가 5인 고객의 모든 대여 기록을 조회하시오.
-
힌트 :
customer테이블에서customer_id가 5인 고객을 찾습니다.rental테이블과 조인하여 해당 고객의 대여 기록을 조회합니다. (여기까지만 하면 기록만 볼 수 있다.)- 대여한 영화 제목까지 보기위해서
rental테이블과inventory테이블을 조인해서 연결해주고inventory테이블과film테이블을 조인하여 해당 영화의 제목을 조회한다.
-
코드 :
SELECT r.rental_date, f.title FROM rental r JOIN inventory i ON r.inventory_id = i.inventory_id JOIN film f ON i.film_id = f.film_id WHERE r.customer_id = 5;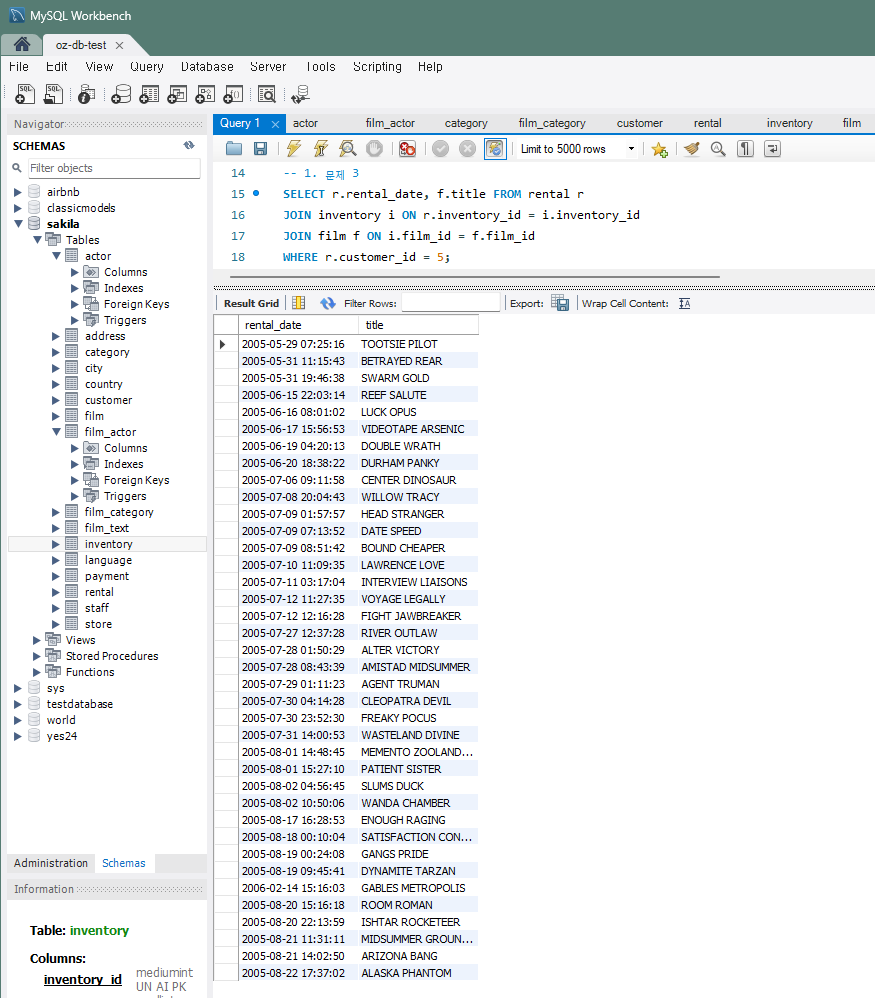
2. 조인 및 관계
문제 1) 특정 영화에 출연한 배우 목록 조회
-
문제 :
'ACADEMY DINOSAUR' 영화에 출연한 모든 배우의 이름을 조회하시오.
-
힌트 :
film테이블에서 'ACADEMY DINOSAUR'의film_id를 찾습니다.film_actor테이블과actor테이블을 조인하여 해당 영화에 출연한 배우들의 이름을 조회합니다.
-
코드 :
SELECT a.first_name, a.last_name FROM actor a JOIN film_actor fa ON a.actor_id = fa.actor_id JOIN film f ON fa.film_id = f.film_id WHERE f.title = 'ACADEMY DINOSAUR';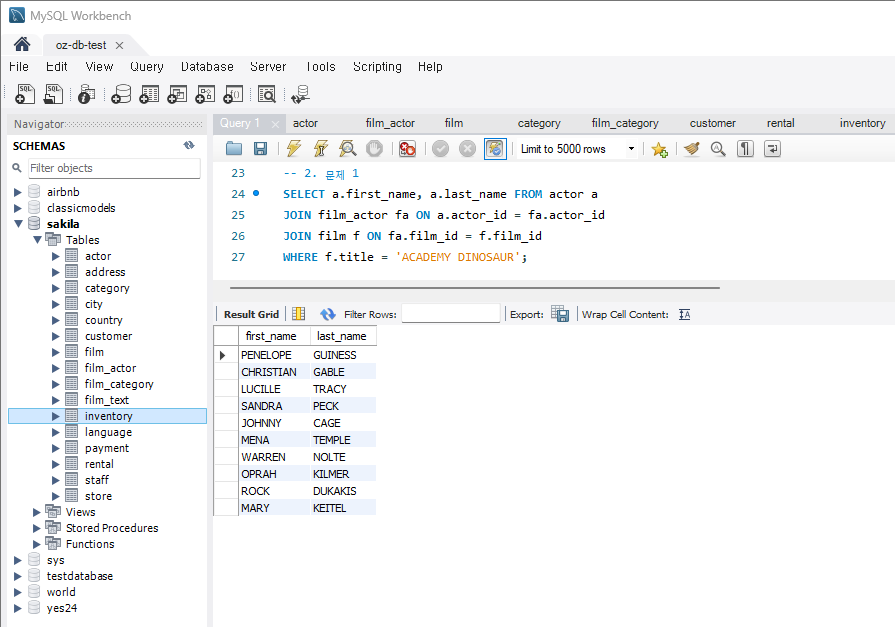
문제 2) 특정 영화를 대여한 고객 목록 조회
-
문제 :
'ACADEMY DINOSAUR' 영화를 대여한 모든 고객의 이름을 조회하시오.
-
힌트 :
film과inventory테이블을 조인하여 'ACADEMY DINOSAUR'의inventory_id를 찾습니다.rental과customer테이블을 조인하여 해당inventory_id에 해당하는 대여 기록을 찾고 고객의 이름을 조회합니다.
-
코드 :
SELECT DISTINCT c.first_name, c.last_name FROM customer c JOIN rental r ON c.customer_id = r.customer_id JOIN inventory i ON r.inventory_id = i.inventory_id JOIN film f ON i.film_id = f.film_id WHERE f.title = 'ACADEMY DINOSAUR';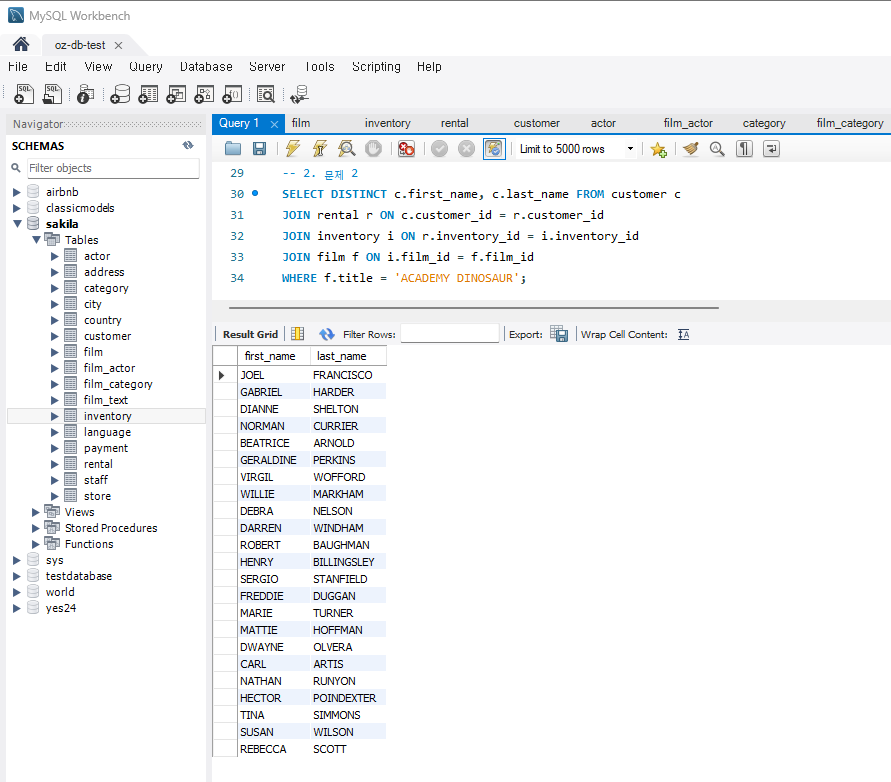
문제 3) 모든 고객과 그들이 가장 최근에 대여한 영화 조회
-
문제 :
각 고객별로 가장 최근에 대여한 영화의 제목을 조회하시오.
-
힌트 :
rental,inventory,film,customer테이블을 조인합니다.- 각 고객별(
customer.customer_id)로 가장 최근의 대여 날짜(rental.rental_date)를 기준으로 한번 그룹하고 조회합니다.
-
코드 :
SELECT c.customer_id, c.first_name, c.last_name, r.last_rental_date, f.title FROM customer c JOIN ( SELECT r.customer_id, MAX(r.rental_date) AS last_rental_date FROM rental r GROUP BY r.customer_id ) r ON c.customer_id = r.customer_id JOIN rental rr ON r.customer_id = rr.customer_id AND r.last_rental_date = rr.rental_date JOIN inventory i ON rr.inventory_id = i.inventory_id JOIN film f ON i.film_id = f.film_id;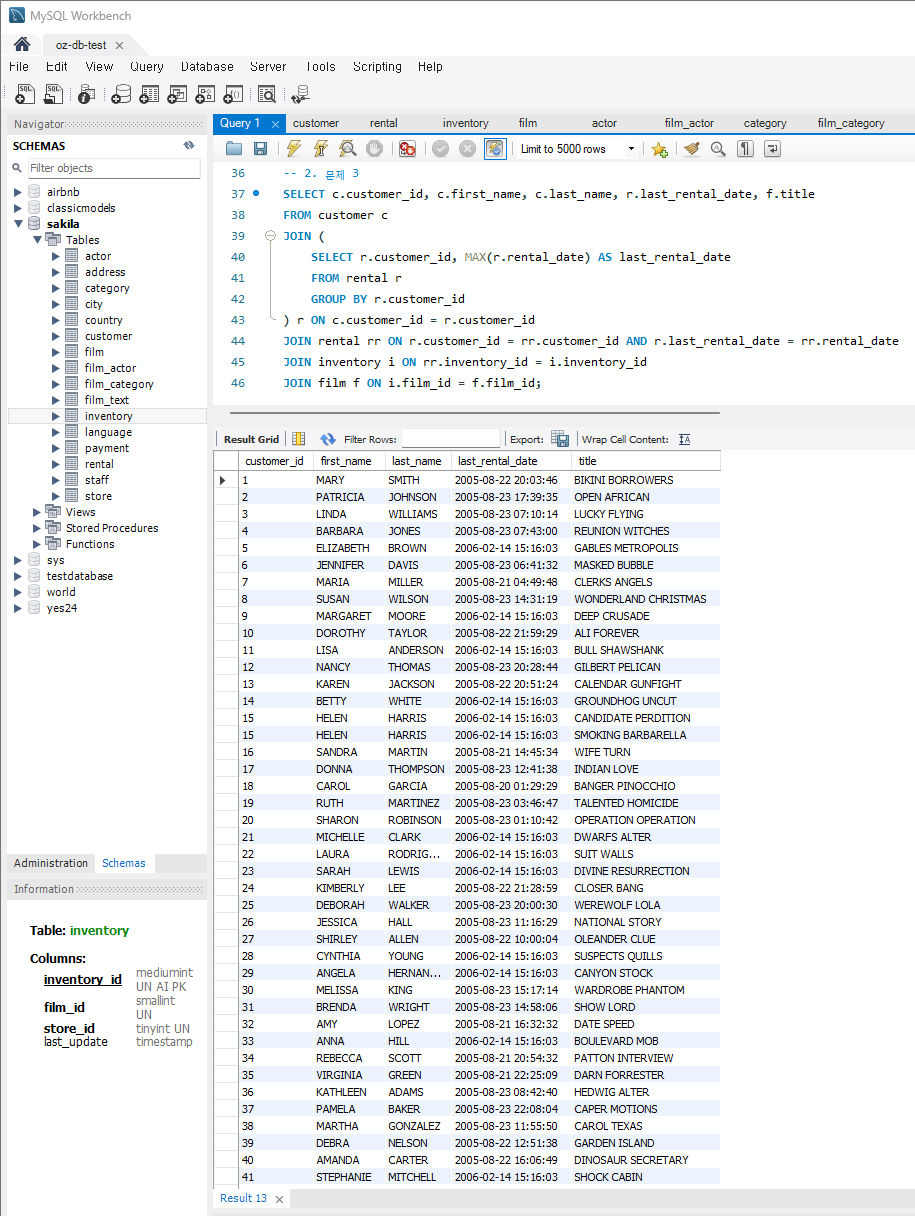
문제 4) 각 영화별 평균 대여 기간 조회
-
문제 :
각 영화별 평균 대여 기간을 일 단위로 계산하시오.
-
힌트 :
rental,inventory,film테이블을 조인합니다.rental테이블에서rental_date와return_date를 사용하여 각 영화별 평균 대여 기간을 계산합니다.- 날짜 차이를 계산할 때는
DATEDIFF함수를 사용한다.
-
코드 :
SELECT f.title, AVG(DATEDIFF(r.return_date, r.rental_date)) as avg_rental_period FROM film f JOIN inventory i ON f.film_id = i.film_id JOIN rental r ON i.inventory_id = r.inventory_id GROUP BY f.title ORDER BY avg_rental_period DESC;
3. 집계 및 그룹화
문제 1) 가장 많이 대여된 영화 조회
-
문제 :
가장 많이 대여된 영화의 제목과 대여 횟수를 조회하시오.
-
힌트 :
rental과inventory테이블을 조인하여 각 영화의 대여 횟수를 계산합니다.film테이블과 조인하여 영화 제목을 가져옵니다.- 대여 횟수를 기준으로 정렬하여 가장 많이 대여된 영화를 찾습니다.
-
코드 :
SELECT f.title, COUNT(r.rental_id) as rental_count FROM film f JOIN inventory i ON f.film_id = i.film_id JOIN rental r ON i.inventory_id = r.inventory_id GROUP BY f.title ORDER BY rental_count DESC LIMIT 1;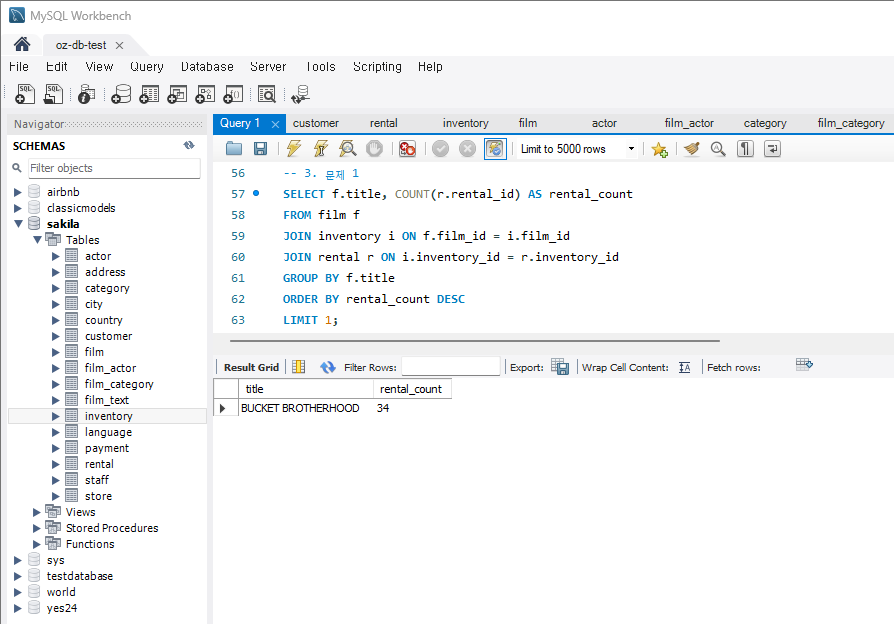
문제 2) 각 카테고리별 평균 대여 요금 조회
-
문제 :
각 카테고리별 평균 대여 요금을 계산하시오.
-
힌트 :
category,film_category,film테이블을 조인하여 각 카테고리별 영화 정보를 가져옵니다.film.rental_rate를 사용하여 카테고리별 평균 대여 요금을 계산합니다.
-
코드 :
SELECT c.name, AVG(f.rental_rate) as average_rental_rate FROM category c JOIN film_category fc ON c.category_id = fc.category_id JOIN film f ON fc.film_id = f.film_id GROUP BY c.name;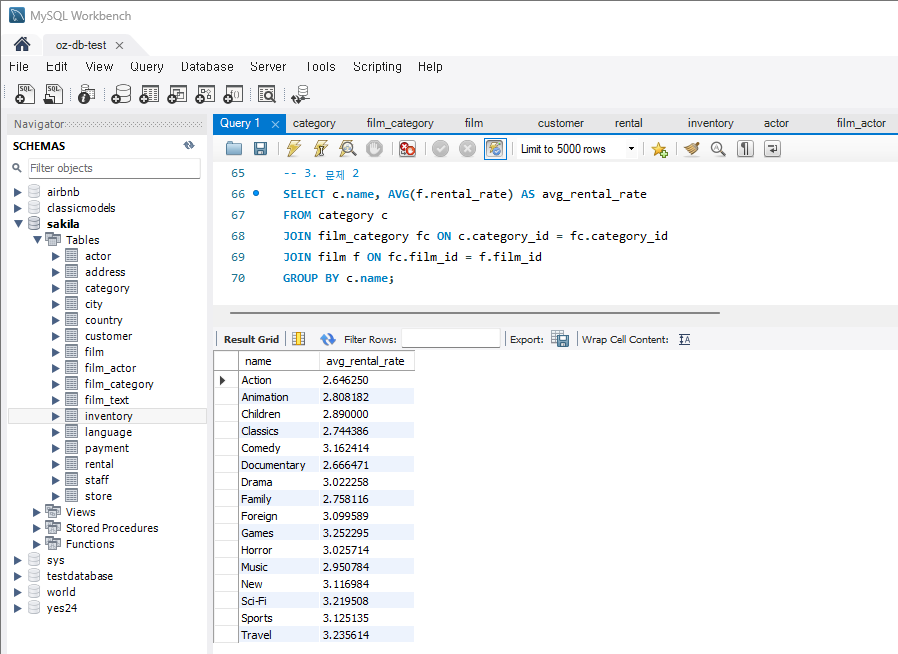
문제 3) 월별 총 매출 조회
-
문제 :
각 월별로 총 매출액을 계산하시오.
-
힌트 :
payment테이블에서amount와payment_date를 사용합니다.- 월별로 그룹화하여 총 매출액을 집계합니다.
-
코드 :
SELECT YEAR(p.payment_date) as year, MONTH(p.payment_date) as month, SUM(p.amount) as total_sales FROM payment p GROUP BY YEAR(p.payment_date), MONTH(p.payment_date);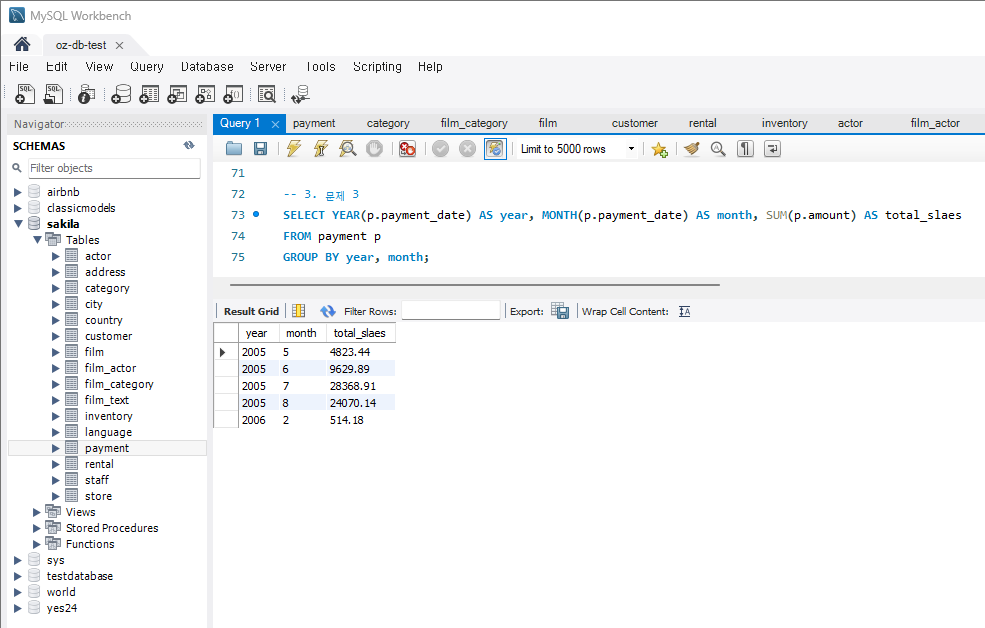
문제 4) 각 배우별 출연한 영화 수 조회
- 문제 :
각 배우별로 출연한 영화 수를 계산하시오.
- 힌트 :
actor와film_actor테이블을 조인합니다.- 각 배우별(
actor_id)로film_id의 수를 세어 집계합니다. - 추가로 출연 영화 수 순으로 정렬해주었다.
- 코드 :
SELECT a.first_name, a.last_name, COUNT(fa.film_id) as number_of_films FROM actor a JOIN film_actor fa ON a.actor_id = fa.actor_id GROUP BY a.first_name, a.last_name ORDER BY number_of_films DESC;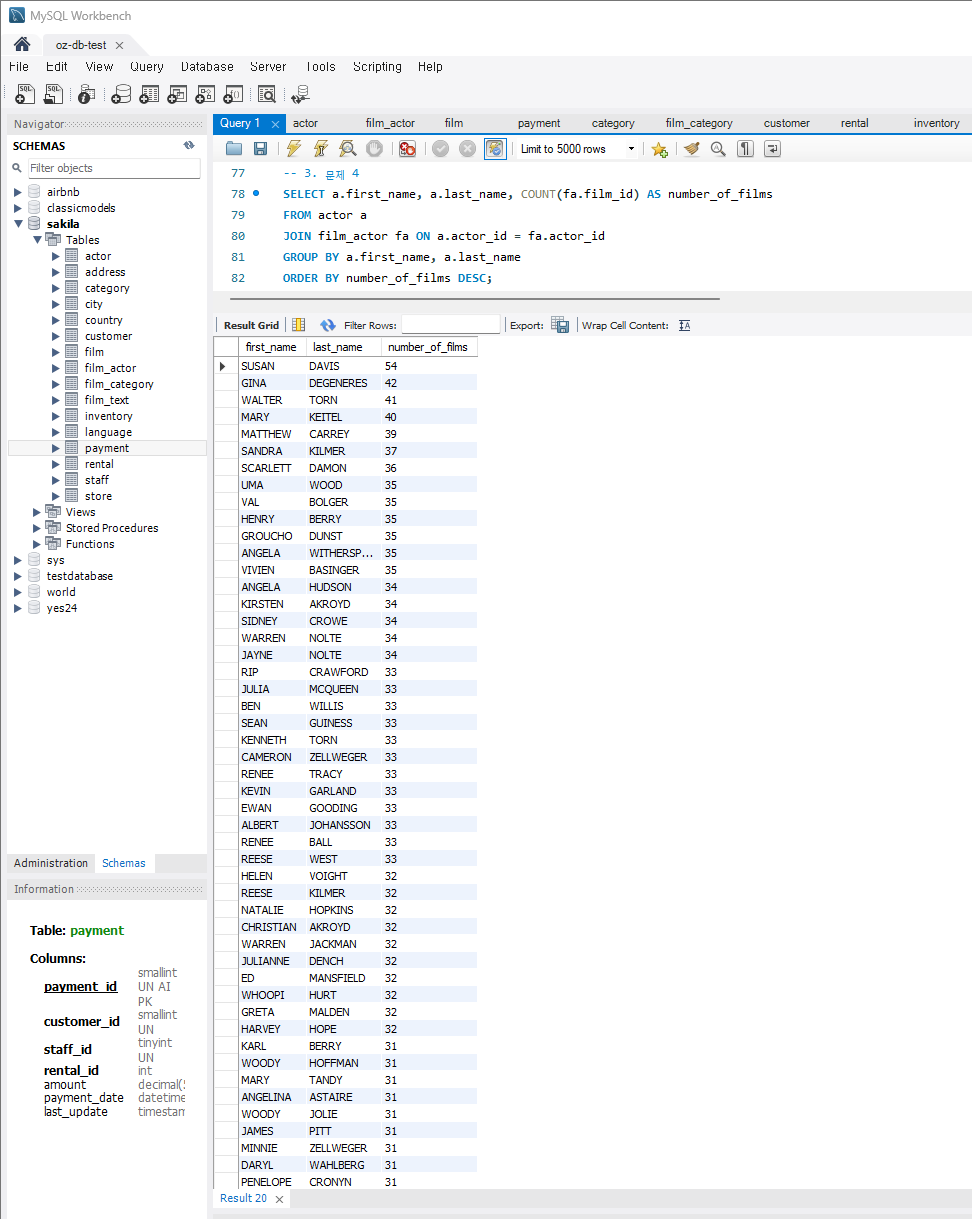
4. Sub-Query 및 고급 기능
문제 1) 가장 수익이 많은 영화 조회
-
문제 :
가장 많은 수익을 낸 영화의 제목과 수익을 조회하시오.
-
힌트 :
payment,rental,inventory,film테이블을 조인합니다.- 각 영화별로 총 수익을 계산하고, 가장 높은 수익을 낸 영화를 찾습니다.
-
코드 :
SELECT f.title, SUM(p.amount) AS total_revenue FROM film f JOIN inventory i ON f.film_id = i.film_id JOIN rental r ON i.inventory_id = r.inventory_id JOIN payment p ON r.rental_id = p.rental_id GROUP BY f.title ORDER BY total_revenue DESC LIMIT 1;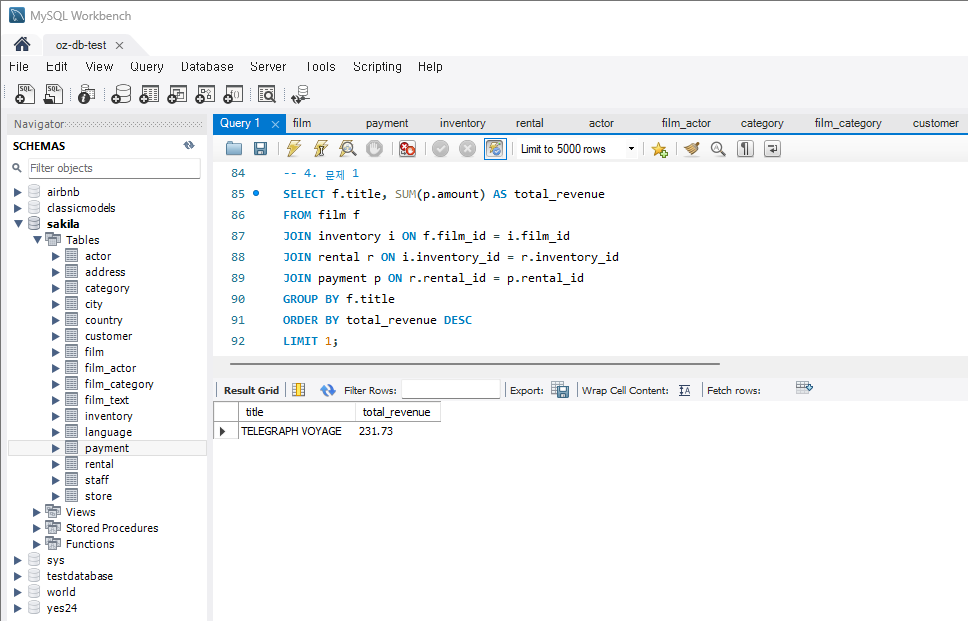
문제 2) 평균 대여 요금보다 높은 요금의 영화 조회
- 문제 :
평균 대여 요금보다 높은 요금의 영화 제목과 요금을 조회하시오.
- 힌트 :
film테이블에서 평균 대여 요금(rental_rate)을 계산합니다.- 평균보다 높은 대여 요금을 가진 영화를 찾습니다.
- 평균은 2.98이다.
- 코드 :
SELECT f.title, f.rental_rate FROM film f WHERE f.rental_rate > (SELECT AVG(rental_rate) FROM film);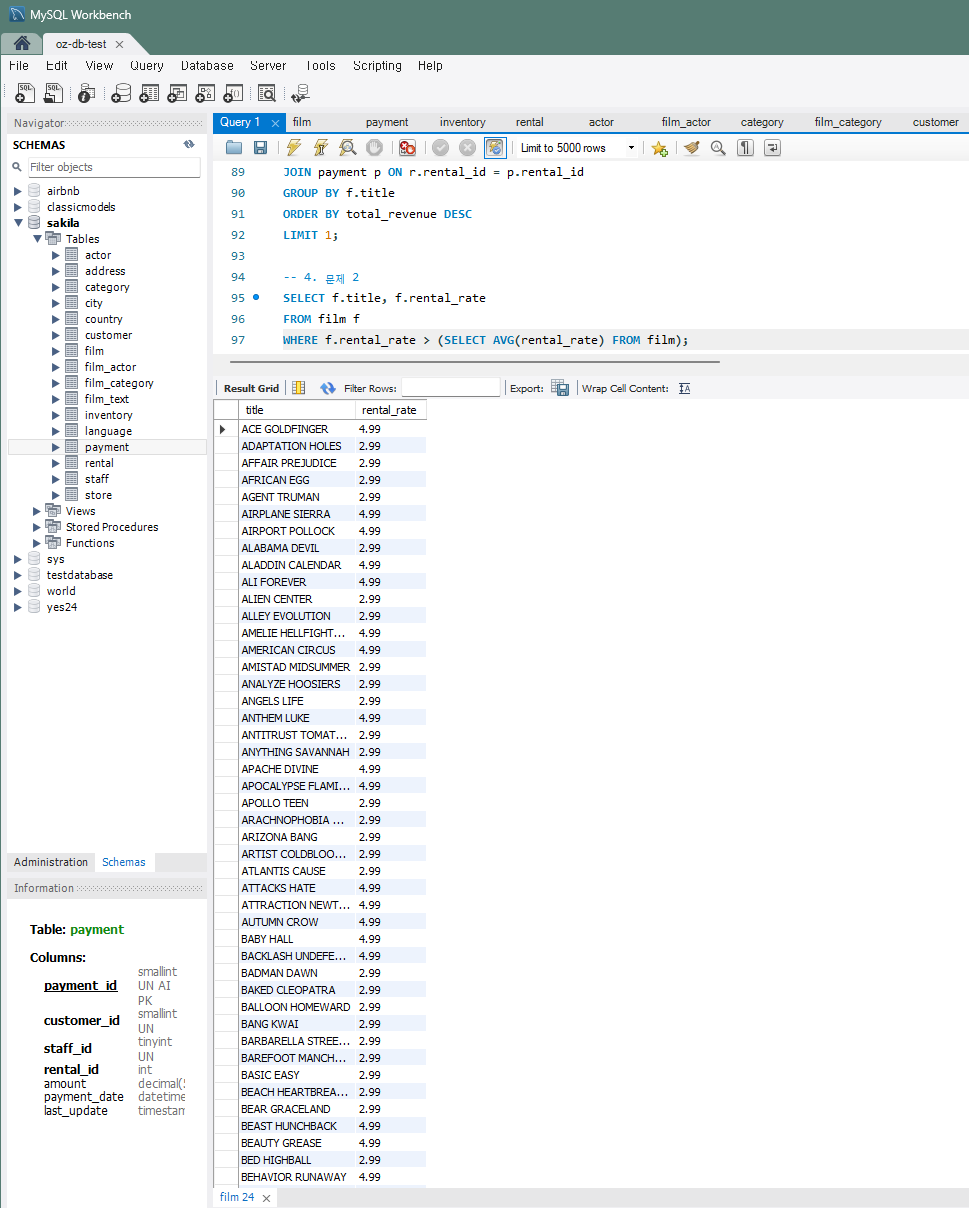
문제 3) 가장 활동적인 고객 조회
-
문제 :
가장 많은 영화를 대여한 고객의 이름과 대여 횟수를 조회하시오.
-
힌트 :
rental과customer테이블을 조인합니다.- 각 고객별로 대여 횟수를 계산하고 가장 많이 대여한 고객을 찾습니다.
-
코드 :
SELECT c.customer_id, c.first_name, c.last_name, COUNT(r.rental_id) AS rental_count FROM customer c JOIN rental r ON c.customer_id = r.customer_id GROUP BY c.customer_id ORDER BY rental_count DESC LIMIT 1;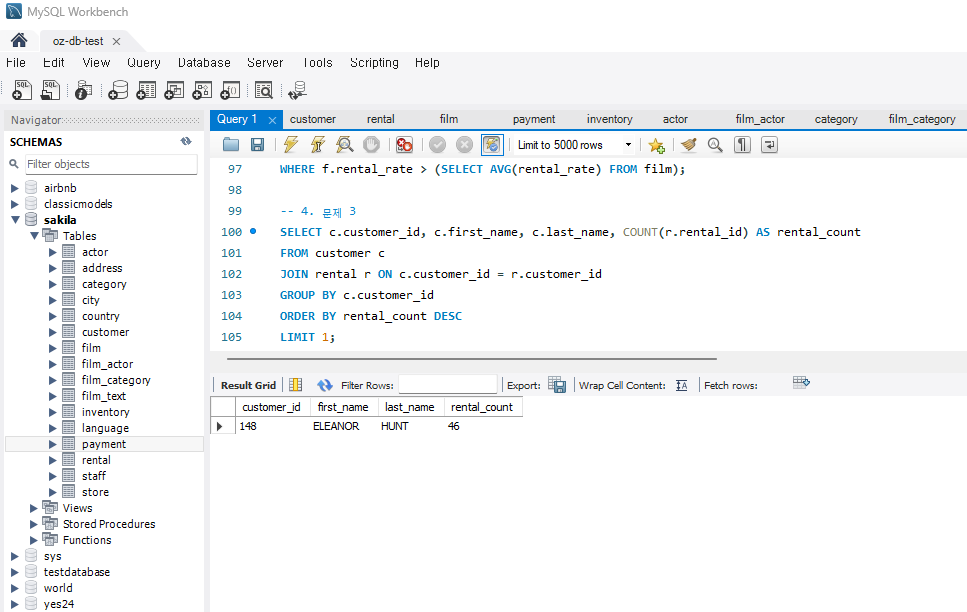
문제 4) 특정 배우가 출연한 영화 중 가장 인기 있는 영화 조회
-
문제 :
배우 'PENELOPE GUINESS'가 출연한 영화 중 가장 많이 대여된 영화의 제목과 대여 횟수를 조회하시오.
-
힌트 :
actor,film_actor,inventory,rental,film테이블을 조인합니다.- 해당 배우가 출연한 영화들의 대여 횟수를 계산하고 가장 많이 대여된 영화를 찾습니다.
-
코드 :
SELECT f.title, COUNT(r.rental_id) AS rental_count FROM film f JOIN film_actor fa ON f.film_id = fa.film_id JOIN actor a ON fa.actor_id = a.actor_id JOIN inventory i ON f.film_id = i.film_id JOIN rental r ON i.inventory_id = r.inventory_id WHERE a.first_name = 'PENELOPE' AND a.last_name = 'GUINESS' GROUP BY f.title ORDER BY rental_count DESC LIMIT 1;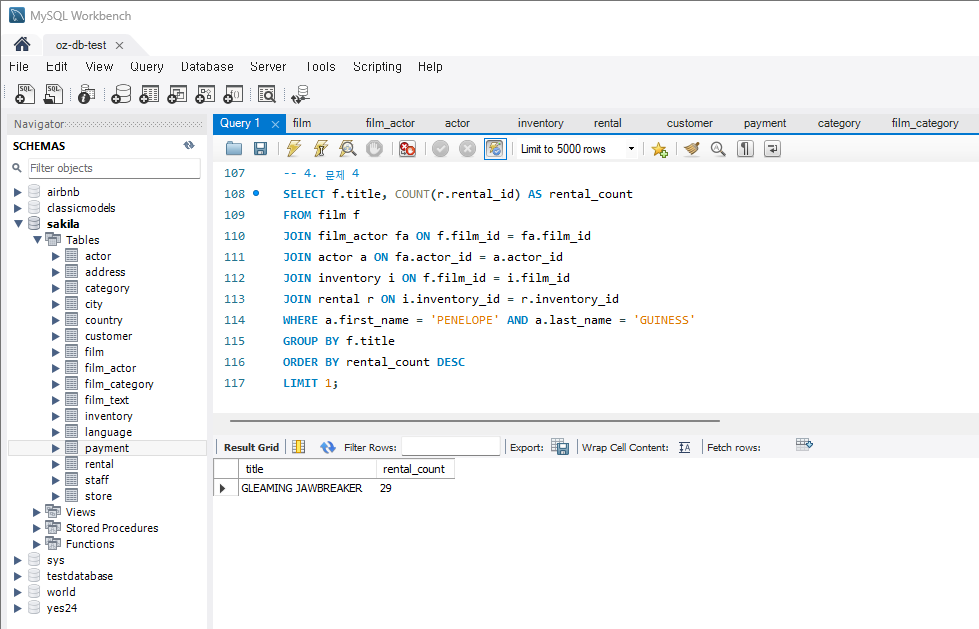
5. 데이터 수정 및 관리
문제 1) 새로운 영화 추가
-
문제 :
'film' 테이블에 'New Adventure Movie'라는 새로운 영화를 추가하시오.
-
힌트 :
INSERT INTO구문을 사용하여film테이블에 새로운 레코드를 추가합니다.- 모든 필요한 필드에 대한 값을 명시합니다.
-
코드 :
INSERT INTO film (title, description, release_year, language_id, rental_duration, rental_rate, length, replacement_cost, rating, special_features) VALUES ('New Adventure Movie', 'A thrilling adventure of the unknown', 2023, 1, 3, 4.99, 120, 19.99, 'PG', 'Trailers,Commentaries');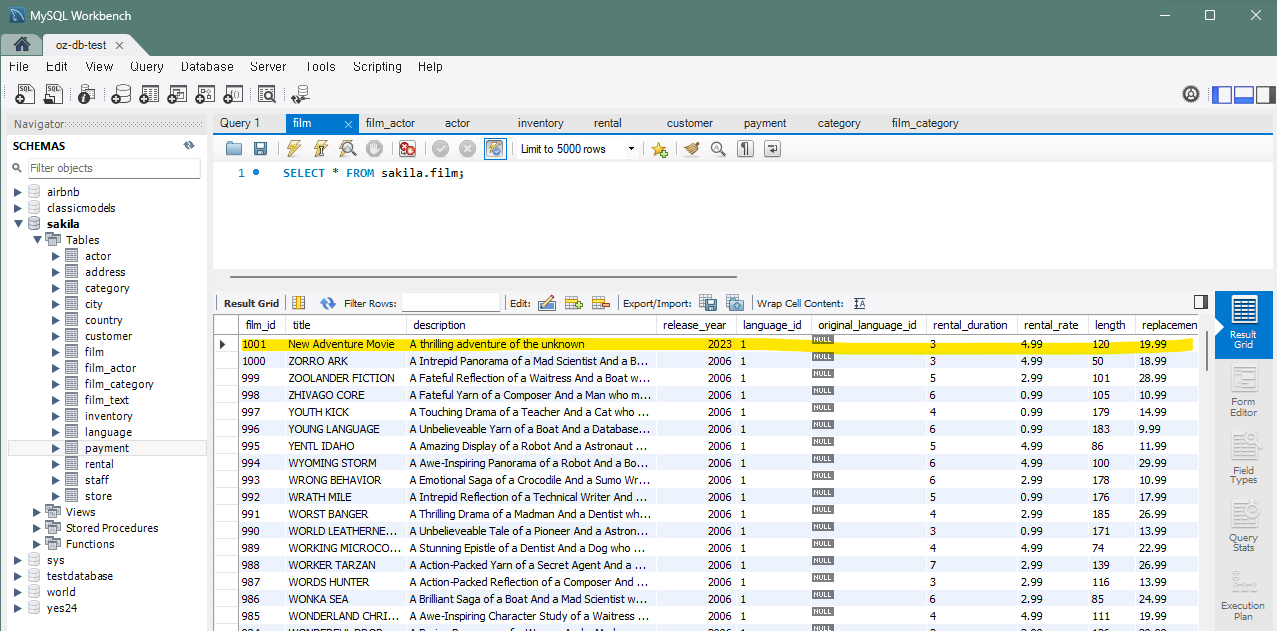
문제 2) 고객 정보 업데이트
-
문제 :
고객 ID가 5인 고객의 주소를 '123 New Address, New City'로 변경하시오.
-
힌트 :
UPDATE구문을 사용하여customer테이블의 레코드를 업데이트합니다.customer_id를 사용하여 특정 고객을 식별하고,address_id를 찾은 다음address테이블에서 해당 주소를 업데이트합니다.
-
코드 :
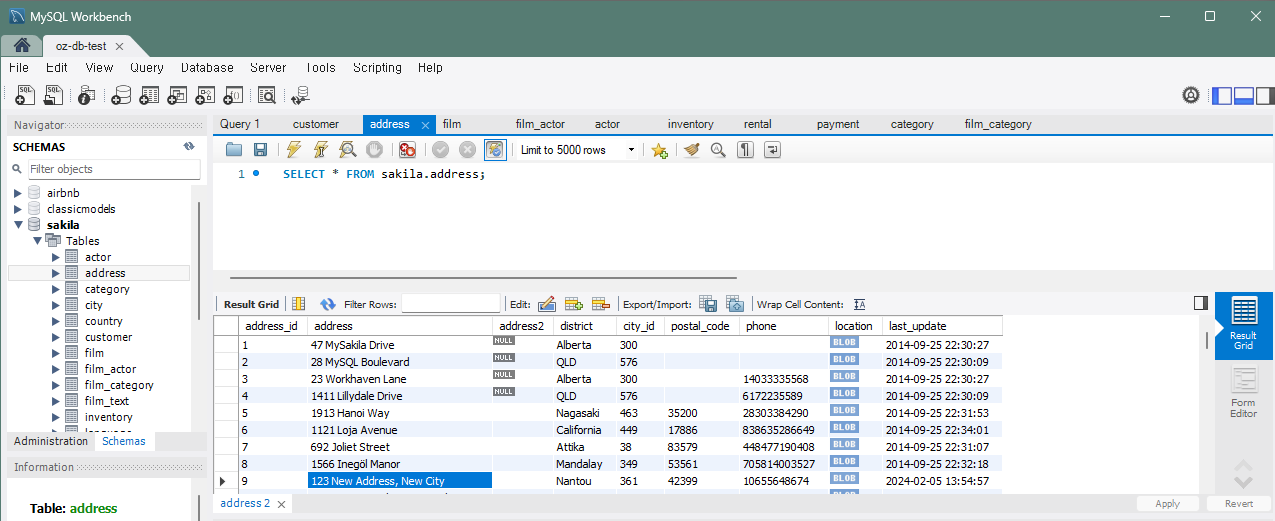
UPDATE address SET address = '123 New Address, New City' WHERE address_id = (SELECT address_id FROM customer WHERE customer_id = 5);기존의 고객 ID가 5인 고객의 주소는 주소 ID가 9 였고 그 주소 ID 원래 주소는 '53 Idfu Parkway' 였다. 코드를 실행하면
문제 3) 영화 대여 상태 변경
-
문제 :
대여 ID가 200인 대여 기록의 상태를 'returned'로 변경하시오.
-
힌트 :
UPDATE구문을 사용하여rental테이블의 레코드를 업데이트합니다.rental_id를 사용하여 특정 대여 기록을 식별하고,return_date를 현재 날짜/시간으로 설정합니다.
-
코드 :
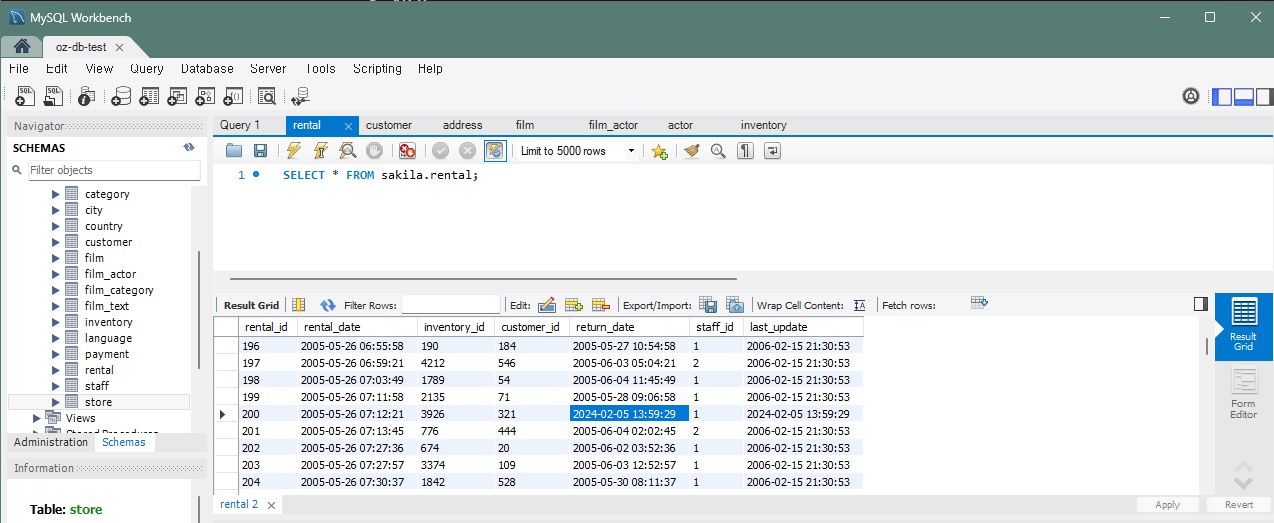
UPDATE rental SET return_date = NOW() WHERE rental_id = 200;기존의 return_date가 '2005-05-31 12:07:21'였는데 오늘 날짜로 변경하였다. 코드를 실행하면
문제 4) 배우 정보 삭제
-
문제 :
배우 ID가 10인 배우의 정보를 삭제하시오.
-
힌트 :
DELETE FROM구문을 사용하여actor테이블에서 특정 레코드를 삭제합니다.- 삭제하기 전에
film_actor테이블에서 해당 배우와 관련된 모든 레코드를 삭제하거나 확인합니다.
-
코드 :
DELETE FROM actor WHERE actor_id = 10;
[DB 3일차 후기]
VS Code에 주피터 파일을 작성해서 크롤링하는 것이 신기했는데
강사님이 알려주신 코드랑 실제로 작동했을 때 작동되지 않아서 발생하는 점들이 곤혹스러웠다.
하지만 이 또한 기회로 삼기! Python 공부를 한다고 생각하고 코드를 하나하나 수정하니 원하는 데이터들을 MySQL로 저장할 수 있어서 기분이 좋았다 ㅎㅎ
각 데이터들을 연결하고 찾아내고 분류하는 것이 백엔드 개발자의 기본 소양이라니,,, 앞으로 하는 일이나 수업들이 재밌을거 같다!
[참고 자료]
- [오즈스쿨 스타트업 웹 개발 초격차캠프 백엔드 데이터베이스 강의]
- https://extbrain.tistory.com/78
