
드디어 마지막 Chapter다.
마지막까지 힘내서 완독해보자~!

14-1. 그래프의 이해와 종류
그래프의 역사
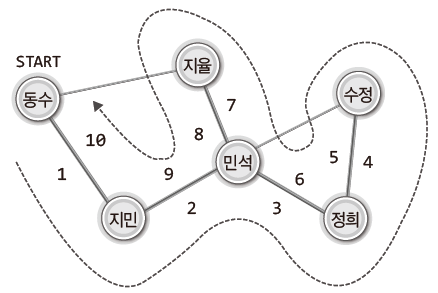
버스와 지하철 노선도와 같이 출발지와 목적지를 정해 최적의 경로를 알 수 있는 것이 있다.
이러한 프로그램의 구현에 사용되는 것이 바로 그래프 알고리즘이다.
그래프 알고리즘은 수학자 오일러(Euler)에 의해 고안되었다.
오일러는 1736년도 '쾨니히스베르크의 다리 문제'를 풀기 위해 그래프 이론을 사용하였다.
쾨니히스베르크의 다리 문제는 다음과 같다.
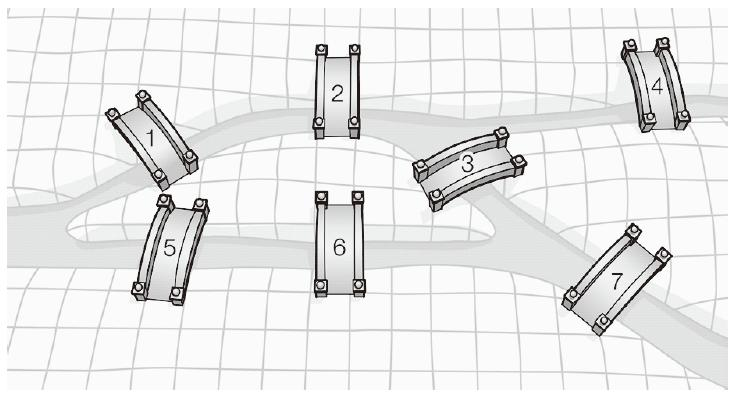
위 그림을 보고 "모든 다리를 한 번씩만 건너서 처음 출발했던 장소로 돌아올 수 있는가?"라는 질문에 답을 하는 것이 쾨니히스베르크의 다리 문제다.
이것이 가능하기 위한 필요충분 조건이 정점 별로 연결된 간선의 수가 모두 짝수여야 간선을 한 번씩만 지나서 처음 출발했던 정점으로 돌아올 수 있는데 이를 만족시키지 못하기 때문에 불가능하다.
여기서 처음 언급된 용어 2가지(정점, 간선)에 대해 설명하면 다음과 같다.
- 간선(edge): 다리
- 정점(vertex): 다리가 연결하는, 강으로 구분되는 땅
그럼 다시 위 그림을 살펴보면 정점에 연결된 간선의 수가 짝수가 아니라 문제를 해결할 수 없다는 것이 이해가 될 것이다.
이제 위와 같은 그래프를 구현까지 해보자.
그래프의 이해와 종류
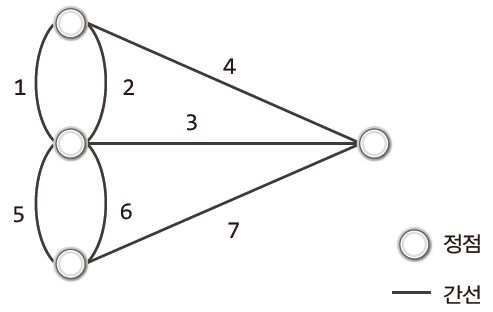
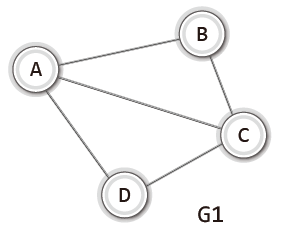
그래프의 이해를 위해 예시로 5학년 3반의 비상연락망 구조를 표현한 그래프를 살펴보자.
학생의 이름이 정점이고, 연결하는 선이 간선이다.
정점은 연결의 대상이 되는 개체 또는 위치를 의미하고
간선은 이들 사이의 연결을 의미한다.
| Type | |
|---|---|
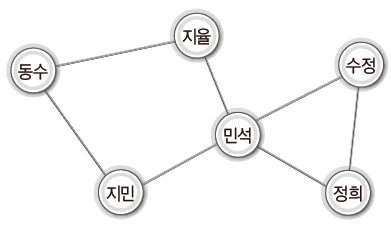 <무방향 그래프(undirected graph)> | - 방향성 X |
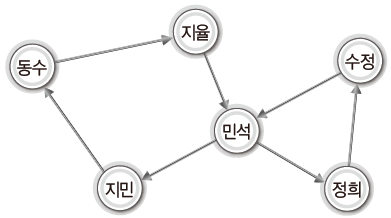 <방향 그래프(directed graph, digraph)> | - 방향 정보 포함 - 다이그래프 |
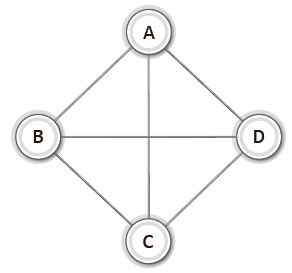 <무방향 완전 그래프(complete undirected graph)> | - 각각의 정점에서 다른 모든 정점을 연결한 그래프 |
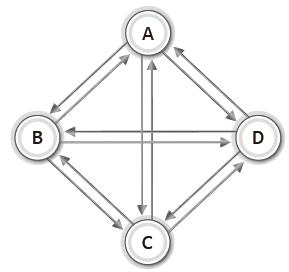 <방향 완전 그래프(complete directed graph)> | - 각각의 정점에서 다른 모든 정점을 방향 정보 포함하여 연결한 그래프 - 방향 그래프의 간선의 수 = 무방향 그래프의 간선의 수 X 2 |
가중치 그래프(Weight Graph)와 부분 그래프(Sub Graph)
간선에 가중치 정보를 두어 그래프를 구성할 수도 있다.
그리고 이러한 유형의 그래프를 가리켜 '가중치 그래프(Weight Graph)'라 한다.
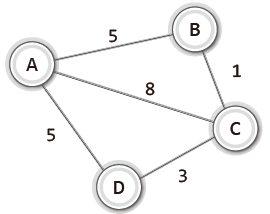 | 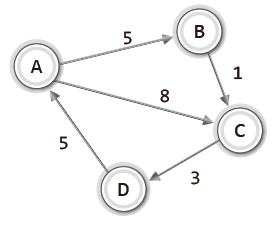 |
|---|---|
| <무방향 가중치 그래프> | <방향 가중치 그래프> |
가중치는 두 정점 사이의 거리라던지 두 정점을 이동하는데 걸리는 시간과 같은 정보가 될 수 있다.
예를 들어 위 그래프에서 가중치가 시간을 의미하고 A에서 C로 이동하는 가장 빠른 길을 찾는다면 정점A → 정점B → 정점C가 될 것이다.
그리고 부분 집합과 유사한 개념으로 '부분 그래프(Sub Graph)'가 있다.
부분 집합이 원 집합의 일부 원소로 이뤄진 집합인 것처럼,
부분 그래프는 원 그래프의 일부 정점 및 간선으로 이뤄진 그래프를 뜻한다.
위 무방향 가중치 그래프의 부분 그래프는 다음과 같다.
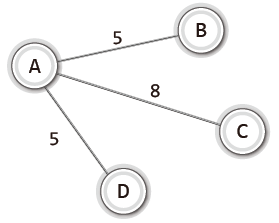 | 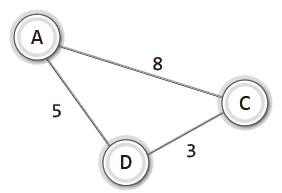 |
|---|
그래프의 집합 표현
그래프는 정점과 간선의 집합이다.
따라서 집합의 표기법을 이용해서 표현할 수 있다.
그래프는 정점과 간선으로 이뤄지므로, 정점의 집합과 간선의 집합을 다음과 같이 나눠서 표현한다.
아래 그림의 무방향 그래프를 집합의 표기법으로 표현하면 다음과 같다.
| 무방향 그래프 | 집합의 표기법 |
|---|---|
 | 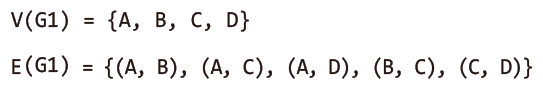 |
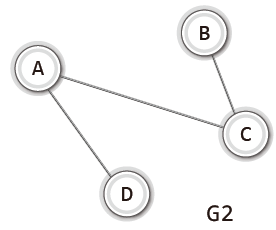 | 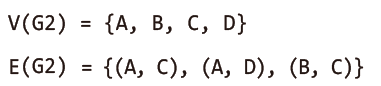 |
정점A와 정점B를 연결하는 간선을 (A, B)로 표현했다.
무방향 그래프의 간선에는 방향성이 없으므로 (A, B)와 (B, A) 는 같은 간선을 나타낸다.
방향 그래프의 집합 표현법은 다음과 같다.
| 방향 그래프 | 집합의 표기법 |
|---|---|
 | 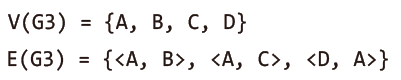 |
 | 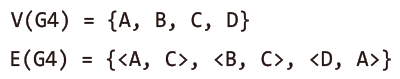 |
무방향 그래프의 집합 표현과의 유일한 차이점은 방향성이 있는 간선의 표시법에 있다.
두 그래프 모두 정점A가 정점C를 가리키는데, 이 간선을 <A, C>와 같이 표현한다.
이로써 그래프의 종류, 용어 및 표기법에 대해 알아봤다.
이제 그래프를 구현하기 위한 ADT에 대해 알아보자.
그래프의 ADT
그래프의 ADT를 정의하기에 앞서 다음과 같이 모든 유형의 그래프를 생성할 수 있고, 또 그 구조에 유연성을 부여할 수 있는 형태의 ADT를 기대할 수 있다.
"그래프를 생성 및 초기화 할 때 간선의 방향성 여부를 선택할 수 있고, 가중치의 부여 여부도 선택할 수 있다.
뿐만 아니라, 이후에는 얼마든지 그리고 언제든지 정점과 간섭을 삽입하고 삭제할 수 있다."
그래프의 구성이 실질적인 목표가 아니기 때문에 위와 같은 그래프 보다는 다음 ADT와 같이 필요한만큼 제한적으로 정의한 그래프를 구현할 예정이다.
👉🏻그래프 자료구조의 ADT
✅Operations:
-
void GraphInit(UALGraph * pg, int nv);
- 그래프의 초기화 진행
- 두 번째 인자로 정점의 수 전달
-
void GraphDestory(UALGraph * pg);
- 그래프 초기화 과정에서 할당한 리소스 반환
-
void AddEdge(UALGraph * pg, int fromV, int toV);
- 매개변수 fromV와 toV로 전달된 정점을 연결하는 간선을 그래프에 추가
-
void ShowGraphEdgeInfo(UALGraph * pg);
- 그래프의 간선정보를 출력
위 ADT에서 보이듯이 그래프의 초기화 과정에서 정점의 수를 결정하도록 정의했다.
뿐만 아니라 간선을 추가하되 삭제는 불가능하게 정의했다.
이 정도로도 그래프의 구성 이후의 주제를 논의하기에 충분하다.
실제로 응용 프로그램을 개발하는 경우에도 이 정도 수준의 그래프를 구성하는 경우가 흔하다.
정점에 이름을 어떻게 부여할까?
AddEdge 함수의 두 번째, 세 번째 인자로 무엇을 전달해야 할까?
그래프의 헤더파일에 enum {A, B, C, D, E, F, G, H, I, J};와 같이 정점의 이름을 열거형 상수로 선언할 것이고 이는 정점의 이름을 상수화한 것이다.
따라서 GraphInit 함수의 두 번째 인자로 5가 전달되면 정점A, B, C, D, E로 이뤄진 그래프가 형성된다.
그리고 이 상수들이 AddEdge 함수의 인자로 전달될 것이다.
실제 프로그램 개발에 활용한다면, enum {SEOUL, INCHEON, DAEGU, BUSAN, KWANJU};와 같이 의미있는 이름을 부여해야 한다.
그래프의 헤더파일을 정의하는데 앞서 그래프의 구현방법에 대해 결정해야 한다.
구현방법에 따라서 헤더파일의 내용도 달라지기 때문이다.
그래프 구현 방법
그래프를 구현하는 방법도 배열을 이용하는 방법과 연결 리스트를 이용하는 방법으로 나뉜다.
하지만, 그래프에서는 이들을 각각 다음과 같이 표현한다.
- 인접 행렬(adjacent matrix) 기반 그래프 : 정방 행렬 활용
- 인접 리스트(adjacent list) 기반 그래프 : 연결 리스트 활용
정방 행렬은 가로세로의 길이가 같은 행렬을 의미한다.
이러한 행렬은 2차원 배열로 표현한다.
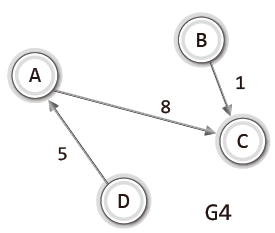
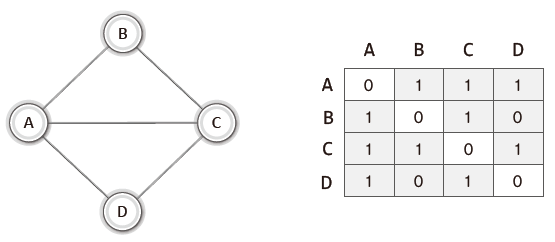
인접 행렬을 기반으로 무방향 그래프와 방향 그래프를 표현하는 방법은 다음과 같다.
| 예시 | |
|---|---|
| <무방향 그래프의 인접 행렬 표현> | |
 | |
| <방향 그래프의 인접 행렬 표현> | |
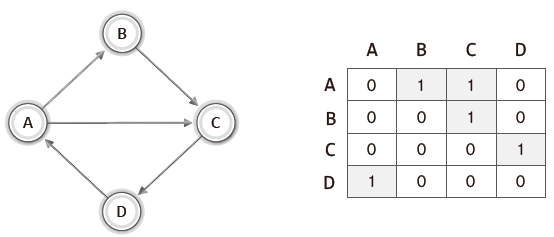 |
정점이 4개면 가로세로 길이가 4인 2차 배열을 선언한다.
두 정점이 연결되어 있으면 1로, 연결되어 있지 않으면 0으로 표시한다.
단, 무방향 그래프의 경우 대각선을 기준으로 대칭을 이루고,
방향 그래프의 경우 대칭을 이루지 않는다.
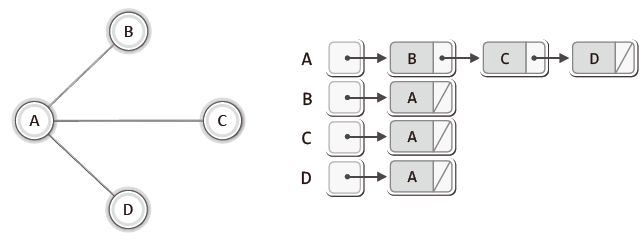
인접 리스트 기반의 그래프 표현방법에 대해 살펴보자.
| 예시 | |
|---|---|
| <무방향 그래프의 인접 리스트 표현> | |
 | |
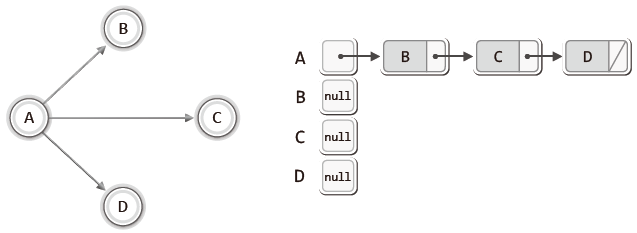
| <방향 그래프의 인접 리스트 표현> | |
 |
각각의 정점은 자신과 연결된 정점의 정보를 담기 위해서 하나의 연결 리스트를 갖는다.
그리고 각각의 정점에 연결된 간선의 정보는 각각의 연결리스트에 담아야 한다.
방향 그래프에서는 각 정점 별로 가리키는 정점의 정보만을 연결 리스트에 담는다.
따라서 무방향 그래프에 비해서 추가되는 노드의 수가 반으로 준다.
14-2. 인접 리스트 기반의 그래프 구현
그래프를 인접 행렬로 구현하는 방법과 인접 리스트로 구현하는 방법 중 인접 리스트 기반으로 구현하는 방법에 대해 배울 것이다.
그래프의 구현 관점에서 무방향 그래프와 방향 그래프의 유일한 차이점은 연결 리스트에 추가하는 노드의 수에 있기 때문에, 이 둘의 구현방법에는 차이가 없다고 볼 수 있다.
그러나 굳이 따지자면 무방향 그래프의 구현이 조금 더 복잡하다 할 수 있다.
연결 리스트에 추가해야 하는 노드의 수가 방향 그래프에 비해 두 배 더 많기 때문이다.
따라서 조금 더 복잡한 무방향 그래프의 구현에 대해 알아보자.
1) 헤더파일 정의 - ALGraph.h
인접 리스트 기반의 구현이므로 핵심은 연결 리스트에 있다.
그래서 이전에 구현한 연결 리스트를 사용할 것이고, DLinkedList.h과 DLinkedList.c가 필요하다.
헤더파일은 다음과 같다.
#ifndef __AL_GRAPH__
#define __AL_GRAPH__
#include "DLinkedList.h"
// 정점의 이름을 상수화
enum {A, B, C, D, E, F, G, H, I, J};
typedef struct _ual
{
int numV; // 정점의 수
int numE; // 간선의 수
List * adjList; // 간선의 정보
} ALGraph;
// 그래프의 초기화
void GraphInit(ALGraph * pg, int nv);
// 그래프의 리소스 해제
void GraphDestroy(ALGraph * pg);
// 간선의 추가
void AddEdge(ALGraph * pg, int fromV, int toV);
// 간선의 정보 출력
void ShowGraphEdgeInfo(ALGraph * pg);
#endif필요한 정점의 수가 10개를 넘으면 이름을 더 추가하면 되고, 또한 프로그램의 성격에 따라서 이름을 바꿀 수 있다.
2) 소스파일 정의 - ALGraph.c
먼저, GraphInit 함수를 보자.
이 함수를 보면 구현의 방식이 전체적으로 머릿속에 그려진다.
void GraphInit(ALGraph * pg, int nv)
{
int i;
pg->adjList = (List*)malloc(sizeof(List)*nv); // 간선정보를 저장할 리스트 생성
pg->numV = nv; // 정점의 수는 nv에 저장된 값으로 결정
pg->numE = 0; // 초기의 간선 수는 0개
// 정점의 수만큼 생성된 리스트들 초기화
for(i=0; i<nv; i++)
{
ListInit(&(pg->adjList[i]));
SetSortRule(&(pg->adjList[i]), WhoIsPrecede);
}
}여기서 SetSortRule(&(pg->adjList[i]), WhoIsPrecede); 를 통해 생성된 연결 리스트에 정렬기준을 설정하고 있는데,
사실 이는 그래프의 표현에 있어서 불필요한 것이다.
다만, 출력의 형태를 보기 좋게 하기 위해 알파벳 순으로 출력을 유도하기 위해서 정렬기준을 설정했다.
다음은 GraphDestroy 함수다.
void GraphDestroy(ALGraph * pg) // 그래프의 리소스 해제
{
if(pg->adjList != NULL)
free(pg->adjList); // 동적 할당된 연결 리스트 소멸
}보다 간단하게 함수를 정의할 수 있다.
다음은 간선의 추가를 담당하는 AddEdge 함수다.
void AddEdge(ALGraph * pg, int fromV, int toV) // fromV, toV 연결하는 간선 추가
{
// 정점 fromV의 연결 리스트에 정점 toV의 정보 추가
LInsert(&(pg->adjList[fromV]), toV);
// 정점 toV의 연결 리스트에 정점 fromV의 정보 추가
LInsert(&(pg->adjList[toV]), fromV);
pg->numE += 1;
}무방향 그래프의 간선을 추가하는 것이므로 위의 함수에서는 LInsert 함수를 두 번 호출했다.
만약에 구현하는 것이 방향 그래프였다면 LInsert 함수는 한번만 호출해도 충분하다.
그리고 연결 리스트를 지정하는 인덱스 값으로 fromV와 toV가 사용되었다.
fromV와 toV가 각각 A, B에 전달되면, LInsert 함수의 호출형태는 다음과 같아진다.
LInsert(&(pg->addjList[A]), B); LInsert(&(pg->adjList[B]), A);
이렇듯 정점의 이름이 바로 사용될 수 있는 이유는, 정점의 이름이 의미하는 바가 상수고, 그 값이 0부터 시작해서 1씩 증가하기 때문이다.
마지막으로 ShowGraphEdgeInfo 함수에서 문자의 출력을 위해 65를 더한 것은 아스키 코드로 변환하기 위함이다.
소스파일을 하나로 정리하면 다음과 같다.
#include <stdio.h>
#include <stdlib.h>
#include "ALGraph.h"
#include "DLinkedList.h"
int WhoIsPrecede(int data1, int data2);
// 그래프의 초기화
void GraphInit(ALGraph * pg, int nv)
{
int i;
pg->adjList = (List*)malloc(sizeof(List)*nv);
pg->numV = nv;
pg->numE = 0; // 초기의 간선 수는 0개
for(i=0; i<nv; i++)
{
ListInit(&(pg->adjList[i]));
SetSortRule(&(pg->adjList[i]), WhoIsPrecede);
}
}
// 그래프 리소스의 해제
void GraphDestroy(ALGraph * pg)
{
if(pg->adjList != NULL)
free(pg->adjList);
}
// 간선의 추가
void AddEdge(ALGraph * pg, int fromV, int toV)
{
LInsert(&(pg->adjList[fromV]), toV);
LInsert(&(pg->adjList[toV]), fromV);
pg->numE += 1;
}
// 유틸리티 함수 : 간선의 정보 출력
void ShowGraphEdgeInfo(ALGraph * pg)
{
int i;
int vx;
for(i=0; i<pg->numV; i++)
{
printf("%c와 연결된 정점: ", i + 65);
if(LFirst(&(pg->adjList[i]), &vx))
{
printf("%c ", vx + 65);
while(LNext(&(pg->adjList[i]), &vx))
printf("%c ", vx + 65);
}
printf("\n");
}
}
int WhoIsPrecede(int data1, int data2)
{
if(data1 < data2)
return 0;
else
return 1;
}3) 실행파일 정의 - ALGraphMain.c
#include <stdio.h>
#include "AlGraph.h"
int main()
{
ALGraph graph; // 그래프 생성
GraphInit(&graph, 5); // 그래프의 초기화
AddEdge(&graph, A, B); // 정점 A와 B를 연결
AddEdge(&graph, A, D); // 정점 A와 D를 연결
AddEdge(&graph, B, C); // 정점 B와 C를 연결
AddEdge(&graph, C, D); // 정점 C와 D를 연결
AddEdge(&graph, D, E); // 정점 D와 E를 연결
AddEdge(&graph, E, A); // 정점 E와 A를 연결
ShowGraphEdgeInfo(&graph); // 그래프 간선정보 출력
GraphDestroy(&graph); // 그래프의 리소스 소멸
return 0;
}
> gcc .\ALGraph.c .\ALGraphMain.c .\DLinkedList.c
> .\a.exe
> 출력
A와 연결된 정점: B D E
B와 연결된 정점: A C
C와 연결된 정점: B D
D와 연결된 정점: A C E
E와 연결된 정점: A D그래프의 생성 및 초기화는 ALGraph graph; GraphInit(&graph, 5); 이 두 문장에 의해 이뤄진다.
특히 GraphInit 함수의 호출문에서 두 번째 인자로 5를 전달하였는데 이는 정점의 수를 의미한다.
즉, 저 두 문장으로 5개의 정점으로 이뤄진 그래프가 형성되는 것이다.
그리고 이때 생성되는 정점의 이름은 A, B, C, D, E가 된다.
이후에 AddEdge 함수의 호출을 통해서 총 6개의 간선을 추가하는데 정점의 이름을 인자로 전달하고 있다.
그리하여 형성된 그래프의 모양은 다음과 같다.
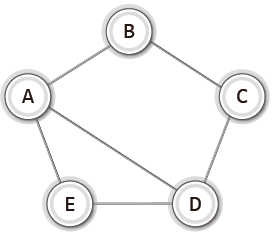
위 그림대로 그래프가 형성되었는지 ShowGraphEdgeInfo를 통해 각각의 정점에 연결된 정점들의 정보를 출력한다.
따라서 출력 결과를 통해 그래프의 구조를 유추할 수 있다.
마지막으로 GraphDestroy 함수를 호출하고 있고 이 함수가 호출되면서 할당된 별도의 메모를 소멸한다.
14-3. 그래프의 탐색
연결 리스트는 노드의 연결 방향이 명확하기 때문에 탐색하는 것이 어렵지 않다.
반면 트리는 노드의 연결 방향이 일정하지 않아서 탐색을 진행하는 것이 복잡한 편이다.
하지만 이진 탐색 트리의 경우 노드의 연결에 규칙이 있기 때문에 비교적 간단한 편이었다.
그래프의 탐색은 어떨까?
그래프의 모든 정점을 돌아다니려면(탐색하려면) 어떤 방법이 있을까?
그래프의 탐색은 어떤 자료구조보다도 탐색이 복잡한 편이다.
그래프느 정점의 구성뿐만 아니라, 간선의 연결에도 규칙이 존재하지 않기 때문이다.
그래서 그래프의 탐색을 위한(그래프의 모든 정점을 돌아다니기 위한) 별도의 알고리즘 두 가지에 대해 알아보자.
- 깊이 우선 탐색 (Depth First Search: DFS)
- 너비 우선 탐색 (Breadth First Search: BFS)
1) 깊이 우선 탐색(Depth First Search: DFS)
깊이 우선 탐색의 설명을 위해 5학년 3반 어린이들의 비상연락망을 예시로 살펴보자.
<DFS의 과정>
| Pic. | Expl. |
|---|---|
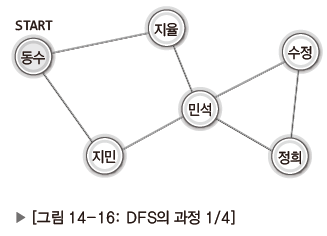 | 동수에게 비상 메시지 전달(시작) 한 사람에게만 전달한다고 가정하고 지민에게만 연락 |
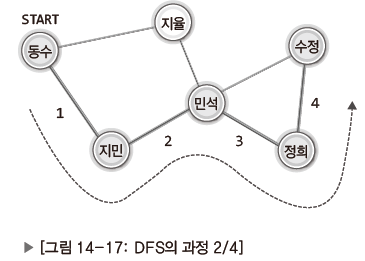 | 지민부터 지민-민석-정희-수정 순으로 수정에게 전달 |
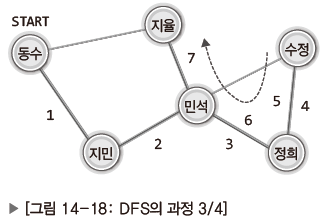 | 수정이 연결된 애들 중에서 연락을 받지 못한 사람이 있는지 역으로 되돌아 가면서 연락 취할 곳을 찾기 |
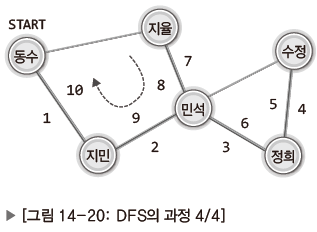 | 모든 사람이 연락을 받음 연락을 처음 취한 '동수'에게 다시 연락이 가야 종료. |
 | '동수'에서 시작해 '동수'로 끝나는 메시지 전달과정 최종 |
여기서 DFS의 핵심 3가지는 다음과 같다.
- 한 사람에게만 연락한다.
- 연락할 사람이 없으면, 자신에게 연락한 사람에게 이를 알린다.
- 처음 연락을 시작한 사람의 위치에서 연락이 끝난다.
2) 너비 우선 탐색(Breadth First Search: BFS)
DFS가 한 사람에게 연락하는 방식이라면 BFS는 자신에게 연결된 모든 사람에게 연락하는 방식이다.
BFS의 B는 Breadth의 약자로 폭, 너비를 뜻한다.
BFS에서 폭의 의미는 한 사람을 기준으로 메시지를 전달하는 사람의 수(폭)을 나타낸다.
그리고 BFS는 이러한 폭을 우선시로 넓히는 방식이다.
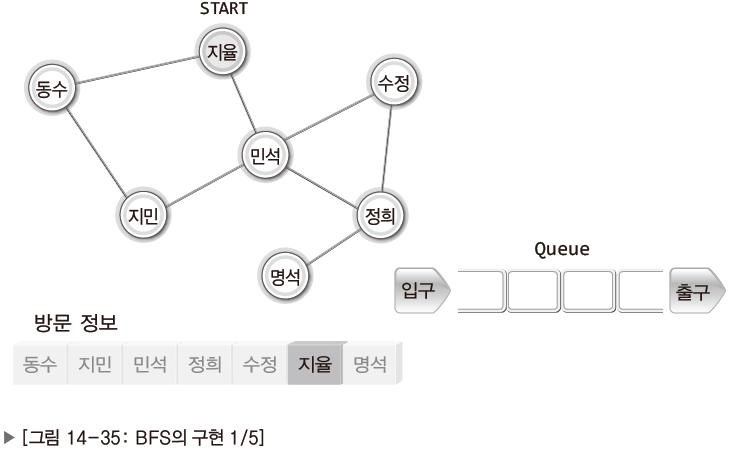
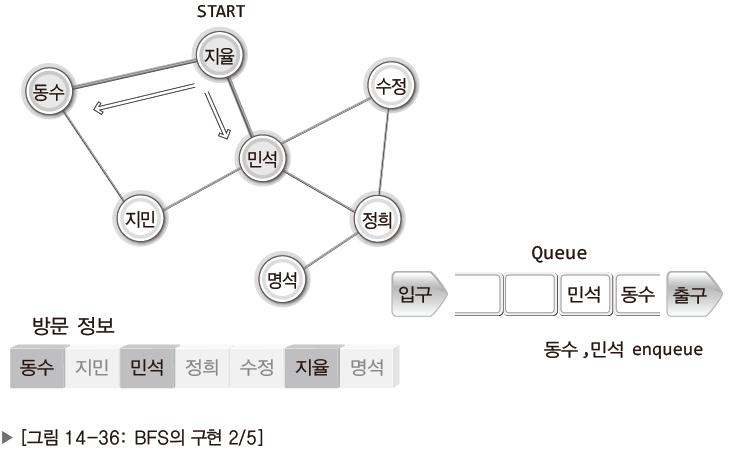
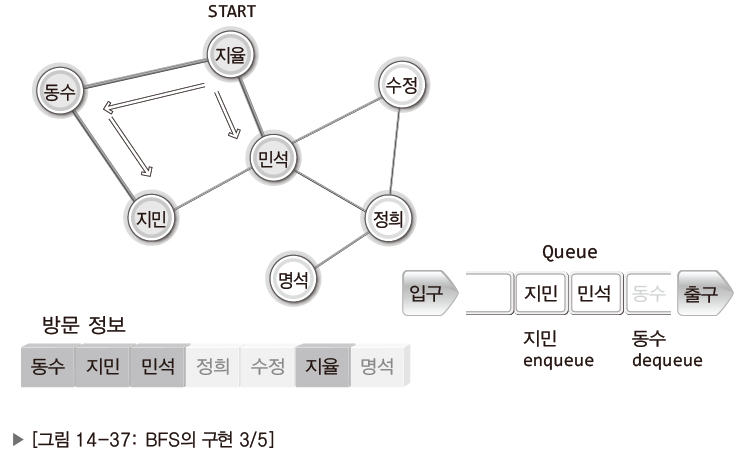
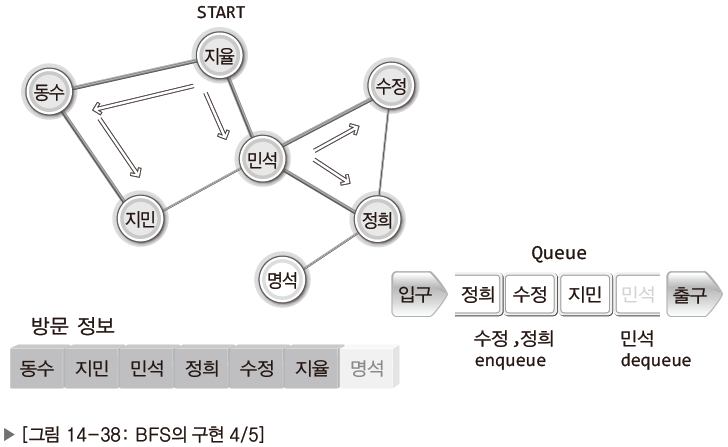
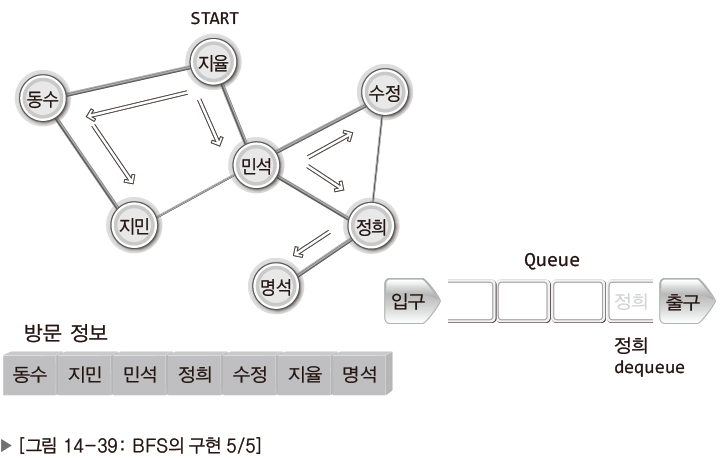
<BFS의 과정>
| Pic. | Expl. |
|---|---|
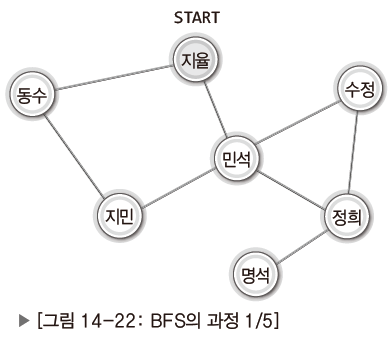 | 지율을 기준으로 시작. |
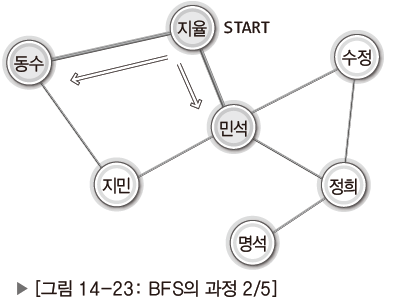 | 지율과 연결된 동수와 민석 두 사람 모두에게 연락. 동수와 민석도 자신에게 연결된 모든 사람에게 연락. 누가 먼저 연락을 취하느냐 문제되지 않음. |
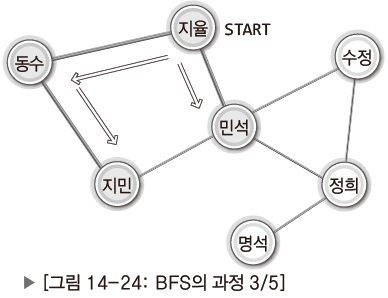 | 동수가 먼저 주변인에게 연락을 취한다고 가정. 이어서 민석이 주변인에게 연락 취함. |
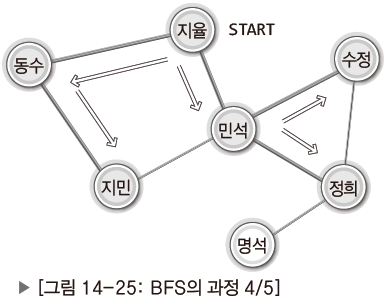 | 동수에 이어 민석이 연락이 취한뒤 상황. 지민, 수정은 주변인이 모두 연락을 받음. |
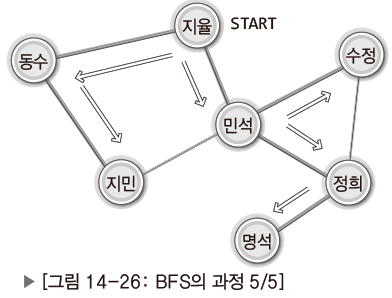 | 정희만 명석에게 연락 취하기. 명석이 연락을 취할 기회를 가지며 BFS 종료. |
BFS는 약간 소문이 퍼저가는 상황과 비슷하다고 할 수 있다.
깊이 우선 탐색(DFS) 구현
위에서 배운 DFS를 구현해보자.
1) 모델 및 이해
DFS 구현을 위해 필요한 2가지는 다음과 같다.
- 스택: 경로 정보의 추적을 목적으로
- 배열: 방문 정보의 기록을 목적으로
DFS에서는 갔던 길을 되돌아 오는 상황이 존재한다. (전달할 사람이 없을 경우)
그리고 각 정점별 방문의 상태를 표시하기 위해 배열이 필요하다.
| Pic. | Expl. |
|---|---|
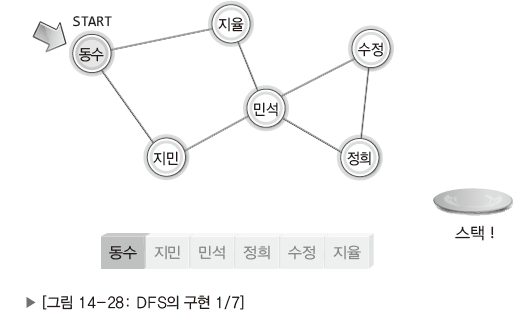 | 동수는 시작과 동시에 방문한 상태로 표시. |
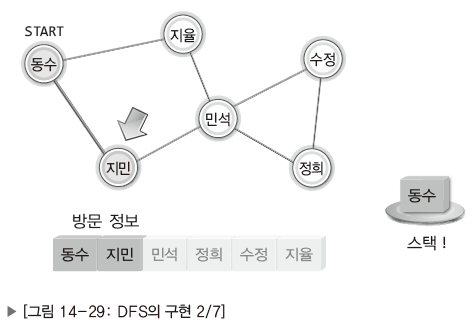 | 동수를 떠나 지민에게 방문할 때, 떠나는 동수의 이름(정보)을 스택으로 옮기기. 방문한 정점을 떠날 때에는 떠나는 정점의 정보를 스택에 쌓기. |
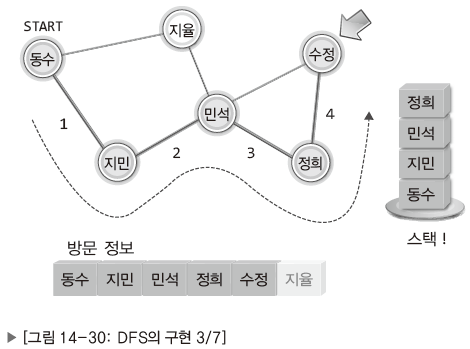 | 동수를 시작으로 수정까지 방문한 결과. 수정과 연락된 사람들 모두 연락을 받았으니 자신에게 연락한 사람에게 기회 넘기기. 자신에게 연락한 사람의 정보는 스택에서 확인 가능. |
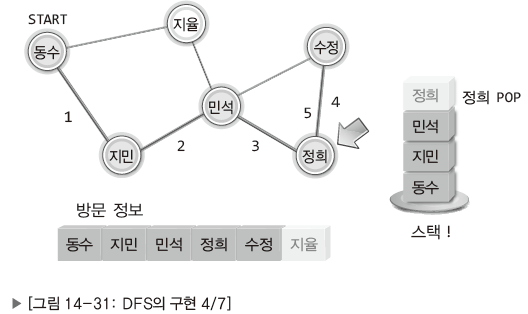 | 스택의 가장 맨 위에 있는 정희로 되돌아오기. 정희 역시 연결된 모든 이에게 연락을 취했으니 스택에서 다음 이름을 꺼내 그 사람에게 기회 넘기기. |
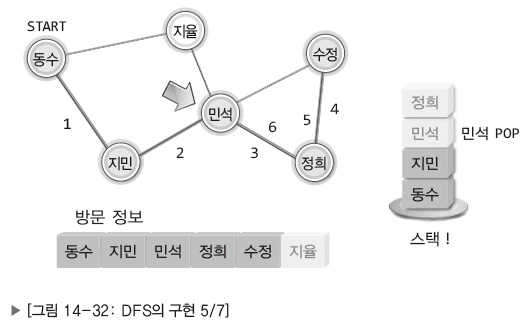 | 민석에게로 연락의 기회 되돌아오기. 민석이 연락할 수 있는 대상인 지율에게 연락. |
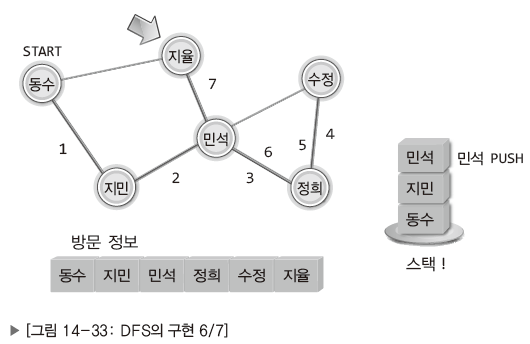 | 지율에게 연락하면서 민석의 이름이 다시 스택으로 옮겨짐. 시작점으로 되돌아가는 일만 남음. |
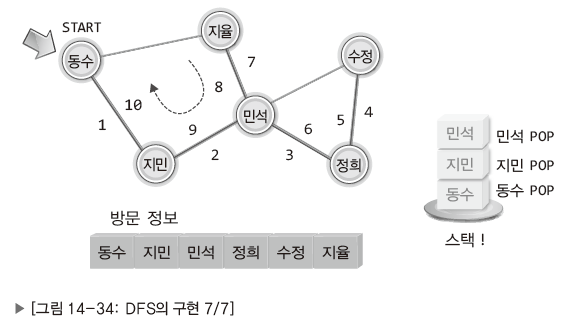 | 스택에 쌓여 있는 정점의 정보를 꺼내 이동. |
DFS 알고리즘의 요구대로 정점을 이동하는데 있어 스택은 매우 중요한 역할을 한다.
2) 실제 구현
DFS 알고리즘 구현을 위해 필요한 파일은 다음과 같다.
- ALGraphDFS.h, ALGraphDFS.c : DFS 알고리즘 관련 그래프 함수의 선언과 정의 관련
- ArrayBaseStack.h, ArrayBaseStack.c : 스택 관련 (Chapter 06에서 구현)
- DLinkedList.h, DLinkedList.c : 연결 리스트 관련 (Chapter 04에서 구현)
- DFSMain.c: main 함수 관련
-헤더파일 (ALGraphDFS.h)
DFS 알고리즘을 근거로 그래프의 모든 정점 정보를 출력하는 함수는 void DFSowGraphVertex(ALGraph * pg, int startV);이다.
이 함수의 선언이 추가된 헤더파일 ALGraphDFS.h 파일을 먼저 살펴보자.
#ifndef __AL_GRAPH_DFS__
#define __AL_GRAPH_DFS__
#include "DLinkedList.h" // 연결 리스트 사용용
// 정점의 이름들을 상수화화
enum {A, B, C, D, E, F, G, H, I, J};
typedef struct _ual
{
int numV; // 정점의 수
int numE; // 간선의 수
List * adjList; // 간선의 정보보
int * visitInfo;
} ALGraph;
// 그래프의 초기화화
void GraphInit(ALGraph * pg, int nv);
// 그래프의 리소스 해제제
void GraphDestroy(ALGraph * pg);
// 간선의 추가가
void AddEdge(ALGraph * pg, int fromV, int toV);
// 간선의 정보 출력력
void ShowGraphEdgeInfo(ALGraph * pg);
// 정점의 정보 출력: Depth First Search_DFS 기반
void DFShowGraphVertex(ALGraph * pg, int startV);
#endifALGraph.h에서 정의된 그래프를 표현한 구조체는 다음과 같다.
typedef struct _ual
{
int numV;
int numE;
List * adjList;
} ALGraph;하지만 위 헤더파일에서는 구조체에 int * visitInfo; 라는 멤버가 하나 더 추가되었다.
이 멤버를 추가한 이유는 DFS 기분의 탐색과정에서 탐색이 진행된 정점의 정보를 담기 위함이다.
-소스파일 (ALGraphDFS.c)
위 헤더파일과 새로운 구조체 멤버를 바탕으로 ALGraphDFS.c에 정의된 다음 두 함수에는 새로운 구조체 멤버와 관련된 문장이 추가된다.
GraphInit: visitInfo 관련 초기화를 함께 진행GraphDestroy: visitInfo 관련 리소스의 해제도 함께 진행
함수에 추가된 문장들을 구분하여 보며 이를 통해 visitInfo가 가리키는 대상이 무엇인지 확인해보자.
// 그래프의 초기화
void GraphInit(ALGraph * pg, int nv)
{
....
// 정점의 수를 길이로 하여 배열을 할당
pg->visitInfo = (int *)malloc(sizeof(int) * pg->numV);
// 배열의 모든 요소를 0으로 초기화
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
}
// 그래프의 리소스 해제
void GraphDestroy(ALGraph * pg)
{
....
// 할당된 배열의 소멸
if(pg->visitInfo != NULL)
free(pg->visitInfo);
}정리하면 visitInfo가 가리키는 것은 들렀던 정점의 정보를 위한 배열이고,
이를 동적으로 할당했다가 소멸하는 문장이 추가된 것이다.
그리고 새로 추가된 핵심이라 할 수 있는 두 함수를 살펴보자.
void DFShowGraphVertex(ALGraph * pg, int startV);: 그래프의 정정 정보 출력int VisitVertex(ALGraph * pg, int visitV);: 정점의 방문을 진행
이 중에서 VisitVertex 함수는 DFShowGraphVertex 함수 내에서 호출되는 함수다.
// 두 번째 매개변수로 전달된 이름의 정점에 방문
int VisitVertex(ALGraph * pg, int visitV)
{
if(pg->visitInfo[visitV] == 0) // visitV에 처음 방문일 때 '참'인 if문
{
pg->visitInfo[visitV] = 1; // visitV에 방문한 것으로 기록
printf("%c ", visitV + 65); // 방문한 정점의 이름을 출력
return TRUE; // 방문 성공
}
return FALSE; // 방문 실패
}위 함수에서 볼 수 있듯, 방문이 이뤄지면 해당 정점의 이름을 인덱스 값으로 하는 배열의 요소에 1을 저장하여 방문이 이뤄졌음을 기록하고, 또 방문한 정점의 이름을 출력한다.
이제 DFShowGraphVertex 함수를 살펴보자.
// DFS 기반으로 정의된 함수: 정점의 정보 출력
void DFShowGraphVertex(ALGraph * pg, int startV)
{
Stack stack;
int visitV = startV;
int nextV;
// DFS를 위한 스택의 초기화
StackInit(&stack);
// 시작 정점을 방문
VisitVertex(pg, visitV);
// 시작 정점의 정보를 스택으로
SPush(&stack, visitV);
// visitV에 담긴 정점과 연결된 정점의 방문을 시도하는 while문
while(LFirst(&(pg->adjList[visitV]), &nextV) == TRUE)
{
// visitV와 연결된 정점의 정보가 nextV에 담긴 상태에서 이하를 진행
int visitFlag = FALSE;
if(VisitVertex(pg, nextV) == TRUE) // 방문에 성공했다면
{
SPush(&stack, visitV); // visitV에 담긴 정점의 정보를 PUSH
visitV = nextV;
visitFlag = TRUE;
}
else // 방문에 실패했다면, 연결된 다른 정점을 찾기
{
while(LNext(&(pg->adjList[visitV]), &nextV) == TRUE)
{
if(VisitVertex(pg, nextV) == TRUE)
{
SPush(&stack, visitV);
visitV = nextV;
visitFlag = TRUE;
break;
}
}
}
if(visitFlag == FALSE) // 추가로 방문한 정점이 없었다면
{
// 스택이 비면 탐색의 시작점으로 되돌아 온 것
if(SIsEmpty(&stack) == TRUE) // 시작점으로 되돌아 옴
break;
else
visitV = SPop(&stack); // 길 되돌아 가기
}
}
// 이후의 탐색을 위해서 탐색 정보 초기화
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
}위 함수의 정의가 이해되지 않는다면 반복문과 기타 제어문을 중심으로 함수를 설명하는 아래 내용을 다시 한번 살펴보자.
void DFShowGraphVertex(ALGraph * pg, int startV)
{
// - 함수의 앞 부분에서 시작 정점의 방문이 이뤄짐.
// - 아래 while문에서 모든 정점의 방문이 이뤄짐.
while(LFirst(&(pg->adjList[visitV]), &nextV) == TRUE)
{
// - 위의 LFirst 함수호출을 통해서 visitV에 연결된 정점 하나를 얻기.
// - 이렇게 해서 얻은 정점의 정보는 nextV에 저장.
// - nextV에 담긴 정점의 정보를 가지고 방문 시도.
if(VisitVertex(pg, nextV) == TRUE) // 방문에 성공했다면
{
// - nextV의 방문에 성공, visitV의 정보는 스택에 PUSH
// - nextV에 담긴 정보를 visitV에 담고서 while문 다시 시작
// - while문을 다시 시작하는 것은 또 다른 정점의 방문을 시도하는 것
}
// - LFirst 함수호출을 통해서 얻은 정점의 방문에 실패한 경우 else 구문 실행
else
{
// - 아래의 while문은 visitV에 연결된 정점을 찾을 때까지 반복
while(LNext(&(pg->adjList[visitV]), &nextV) == TRUE)
{
// - 위의 LNext 함수호출을 통해서 visitV에 연결된 정점 하나 얻기.
// - 이렇게 해서 얻은 정점의 정보는 nextV에 저장.
// - nextV에 담긴 정점의 정보를 가지고 방문 시도
if(VisitVertex(pg, nextV) == TRUE)
{
// - nextV의 방문에 성공, visitV의 정보는 스택에 PUSH
// - nextV에 담긴 정보를 visitV에 담고서 Break
}
}
// - 정점 방문에 실패했다면 그에 따른 처리 진행
if(visitFlag == FALSE)
{
// - 길을 되돌아 가거나 시작 위치로 되돌아와서 프로그램 종료
}
}
}
}위에서 설명한 함수들을 모두 정리한 소스파일(ALGraphDFS.c)은 다음과 같다.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "ALGraphDFS.h"
#include "DLinkedList.h"
#include "ArrayBaseStack.h"
int WhoIsPrecede(int data1, int data2);
// 그래프의 초기화
void GraphInit(ALGraph * pg, int nv)
{
int i;
pg->adjList = (List*)malloc(sizeof(List)*nv);
pg->numV = nv;
pg->numE = 0; // 초기의 간선 수는 0개
for(i=0; i<nv; i++)
{
ListInit(&(pg->adjList[i]));
SetSortRule(&(pg->adjList[i]), WhoIsPrecede);
}
// visitInfo 멤버 관련 추가 문장
pg->visitInfo= (int *)malloc(sizeof(int) * pg->numV);
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
}
// 그래프 리소스의 해제
void GraphDestroy(ALGraph * pg)
{
if(pg->adjList != NULL)
free(pg->adjList);
// visitInfo 멤버 관련 추가 문장
if(pg->visitInfo != NULL)
free(pg->visitInfo);
}
// 간선의 추가
void AddEdge(ALGraph * pg, int fromV, int toV)
{
LInsert(&(pg->adjList[fromV]), toV);
LInsert(&(pg->adjList[toV]), fromV);
pg->numE += 1;
}
// 유틸리티 함수 : 간선의 정보 출력
void ShowGraphEdgeInfo(ALGraph * pg)
{
int i;
int vx;
for(i=0; i<pg->numV; i++)
{
printf("%c와 연결된 정점: ", i + 65);
if(LFirst(&(pg->adjList[i]), &vx))
{
printf("%c ", vx + 65);
while(LNext(&(pg->adjList[i]), &vx))
printf("%c ", vx + 65);
}
printf("\n");
}
}
int WhoIsPrecede(int data1, int data2)
{
if(data1 < data2)
return 0;
else
return 1;
}
// 두 번째 매개변수로 전달된 이름의 정점에 방문
int VisitVertex(ALGraph * pg, int visitV)
{
if(pg->visitInfo[visitV] == 0)
{
pg->visitInfo[visitV] = 1;
printf("%c ", visitV + 65);
return TRUE;
}
return FALSE;
}
// 정점의 정보 출력: Depth First Search(DFS) 기반
void DFShowGraphVertex(ALGraph * pg, int startV)
{
Stack stack;
int visitV = startV;
int nextV;
// DFS를 위한 스택의 초기화
StackInit(&stack);
VisitVertex(pg, visitV); // 시작 정점을 방문
SPush(&stack, visitV); // 시작 정점의 정보를 스택으로
// visitV에 담긴 정점과 연결된 정점의 방문을 시도하는 while문
while(LFirst(&(pg->adjList[visitV]), &nextV) == TRUE)
{
// visitV와 연결된 정점의 정보가 nextV에 담긴 상태에서 이하를 진행
int visitFlag = FALSE;
if(VisitVertex(pg, nextV) == TRUE) // 방문에 성공했다면
{
SPush(&stack, visitV); // visitV에 담긴 정점의 정보를 PUSH
visitV = nextV;
visitFlag = TRUE;
}
else // 방문에 실패했다면, 연결된 다른 정점을 찾기
{
while(LNext(&(pg->adjList[visitV]), &nextV) == TRUE)
{
if(VisitVertex(pg, nextV) == TRUE)
{
SPush(&stack, visitV);
visitV = nextV;
visitFlag = TRUE;
break;
}
}
}
if(visitFlag == FALSE) // 추가로 방문한 정점이 없었다면
{
// 스택이 비면 탐색의 시작점으로 되돌아 온 것
if(SIsEmpty(&stack) == TRUE) // 시작점으로 되돌아 옴
break;
else
visitV = SPop(&stack); // 길 되돌아 가기
}
}
// 이후의 탐색을 위해서 탐색 정보 초기화
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
}-실행파일 (DFSMain.c)
위에서 구현한 함수들을 실제로 잘 작동하는지 확인할 수 있는 실행파일(Main 함수)는 다음과 같다.
include <stdio.h>
#include "ALGraphDFS.h"
int main(void)
{
ALGraph graph;
GraphInit(&graph, 7); // A, B, C, D, E, F, G 정점 생성성
AddEdge(&graph, A, B);
AddEdge(&graph, A, D);
AddEdge(&graph, B, C);
AddEdge(&graph, D, C);
AddEdge(&graph, D, E);
AddEdge(&graph, E, F);
AddEdge(&graph, E, G);
ShowGraphEdgeInfo(&graph);
DFShowGraphVertex(&graph, A); printf("\n");
DFShowGraphVertex(&graph, C); printf("\n");
DFShowGraphVertex(&graph, E); printf("\n");
DFShowGraphVertex(&graph, G); printf("\n");
GraphDestroy(&graph);
return 0;
}
> gcc .\ALGraphDFS.c .\ArrayBaseStack.c .\DFSMain.c .\DLinkedList.c
> .\a.exe
> 출력
A와 연결된 정점: B D
B와 연결된 정점: A C
C와 연결된 정점: B D
D와 연결된 정점: A C E
E와 연결된 정점: D F G
F와 연결된 정점: E
G와 연결된 정점: E
A B C D E F G
C B A D E F G
E D A B C F G
G E D A B C F 실행 결과 어디서 시작을 하든지 모든 정점에 방문함을 볼 수 있다.
실행결과를 참조해서 main 함수에서 형성한 그래프의 모습을 그려볼 수도 있어 DFS를 기반으로 한 정점의 방문에 문제가 없었는지 대략적 검토가 가능하다.
너비 우선 탐색(BFS) 구현
1) 모델 및 이해
BFS의 구현을 위해서 필요한 2가지는 다음과 같다.
- 큐: 방문 차례의 기록을 목적으로
- 배열: 방문 정보의 기록을 목적으로
BFS의 구현을 그림을 통해 먼저 이해해보자.
| Pic. | Expl. |
|---|---|
 | 큐에는 다음 단계에서 연락을 받은 두 사람의 이름(정보)이 순서대로 들어감. |
 | 동수는 연락을 받기만 했을 뿐 아직 연락을 취하지 않는 대상. 큐에서 이름을 하나 꺼내 그 이름의 정점에 연결된 모든 사람에게 연락. |
 | 동수를 꺼내 동수를 기준으로 연락. 이때 연락을 받은 지민이 큐에 들어감. BFS에 있어서 큐는 연락을 취할 정점의 순서를 기록하기 위한 것. |
 | 큐에서 꺼낸 이름 민석을 중심으로 연결된 수정과 정희가 큐에 들어감. 다음 차례인 지민과 수정의 이름을 큐에서 순서대로 꺼내는데 이 둘은 연락을 취할 대상이 없음. |
 | 마지막으로 정희의 이름까지 꺼내 명석에게 연락. 이때 명석이 큐에 들어갔다가 연락할 대상이 없어 큐에서 빠져나와 종료. |
2) 실제 구현
BFS 구현을 위해 필요한 파일은 다음과 같다.
- ALGraphBFS.h, ALGraphBFS.c : BFS 알고리즘 관련 그래프 함수의 선언과 정의 관련
- CircularQueue.h, CircularQueue.c : 큐 관련 (Chapter 07에서 구현)
- DLinkedList.h, DLinkedList.c : 연결 리스트 관련 (Chapter 04에서 구현)
- BFSMain.c : main 함수 관련
-헤더파일 (ALGraphBFS.h)
DFS와 마찬가지로 BFS에서도 구현결과를 void BFShowGraphVertex(ALGraph * pg, int startV); 에 담을 것이다.
이 함수의 선언이 추가된 헤더파일 ALGraphBFS.h을 먼저 살펴보자.
#ifndef __AL_GRAPH_BFS__
#define __AL_GRAPH_BFS__
#include "DLinkedList.h"
// 정점의 이름들을 상수화화
enum {A, B, C, D, E, F, G, H, I, J};
typedef struct _ual
{
int numV; // 정점의 수
int numE; // 간선의 수
List * adjList; // 간선의 정보
int * visitInfo;
} ALGraph;
// 그래프의 초기화
void GraphInit(ALGraph * pg, int nv);
// 그래프의 리소스 해제
void GraphDestroy(ALGraph * pg);
// 간선의 추가
void AddEdge(ALGraph * pg, int fromV, int toV);
// 그래프의 간선 정보 출력
void ShowGraphEdgeInfo(ALGraph * pg);
// 정점의 정보 출력: Breadth First Search(BFS) 기반
void BFShowGraphVertex(ALGraph * pg, int startV);
#endif-소스파일 (ALGraphBFS.c)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "ALGraphBFS.h"
#include "DLinkedList.h"
#include "CircularQueue.h"
int WhoIsPrecede(int data1, int data2);
// 그래프의 초기화
void GraphInit(ALGraph * pg, int nv)
{
int i;
pg->adjList = (List*)malloc(sizeof(List)*nv);
pg->numV = nv;
pg->numE = 0; // 초기의 간선 수는 0개
for(i=0; i<nv; i++)
{
ListInit(&(pg->adjList[i]));
SetSortRule(&(pg->adjList[i]), WhoIsPrecede);
}
// visitInfo 멤버 관련 추가 문장
pg->visitInfo= (int *)malloc(sizeof(int) * pg->numV);
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
}
// 그래프 리소스의 해제
void GraphDestroy(ALGraph * pg)
{
if(pg->adjList != NULL)
free(pg->adjList);
if(pg->visitInfo != NULL)
free(pg->visitInfo);
}
// 간선의 추가
void AddEdge(ALGraph * pg, int fromV, int toV)
{
LInsert(&(pg->adjList[fromV]), toV);
LInsert(&(pg->adjList[toV]), fromV);
pg->numE += 1;
}
// 유틸리티 함수 : 간선의 정보 출력
void ShowGraphEdgeInfo(ALGraph * pg)
{
int i;
int vx;
for(i=0; i<pg->numV; i++)
{
printf("%c와 연결된 정점: ", i + 65);
if(LFirst(&(pg->adjList[i]), &vx))
{
printf("%c ", vx + 65);
while(LNext(&(pg->adjList[i]), &vx))
printf("%c ", vx + 65);
}
printf("\n");
}
}
int WhoIsPrecede(int data1, int data2)
{
if(data1 < data2)
return 0;
else
return 1;
}
// 두 번째 매개변수로 전달된 이름의 정점에 방문
int VisitVertex(ALGraph * pg, int visitV)
{
if(pg->visitInfo[visitV] == 0)
{
pg->visitInfo[visitV] = 1;
printf("%c ", visitV + 65); // �湮 ���� ���
return TRUE;
}
return FALSE;
}
// 정점의 정보 출력: Breadth First Search(BFS) 기반
void BFShowGraphVertex(ALGraph * pg, int startV)
{
Queue queue;
int visitV = startV;
int nextV;
QueueInit(&queue);
// 시작 정점 탐색색
VisitVertex(pg, visitV);
// while문에서 visitV와 연결된 모든 정점에 방문문
while(LFirst(&(pg->adjList[visitV]), &nextV) == TRUE)
{
if(VisitVertex(pg, nextV) == TRUE)
Enqueue(&queue, nextV); // nextV에 방문했으니 큐에 저장
while(LNext(&(pg->adjList[visitV]), &nextV) == TRUE)
{
if(VisitVertex(pg, nextV) == TRUE)
Enqueue(&queue, nextV); // nextV에 방문했으니 큐에 저장
}
if(QIsEmpty(&queue) == TRUE) // 큐가 비면 BFS 종료료
break;
else
visitV = Dequeue(&queue); // 큐에서 하나 꺼내어 while문 다시 시작작
}
// 탐색 정보 초기화
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
}내용은 다르지만 코드의 성경 상당부분이 DFShowGraphVertex 함수와 유사하기 때문에 주석으로 충분이 이해할 수 있는 코드일 것이다.
-실행파일 (BFSMain.c)
위에서 구현한 함수들이 실제로 잘 작동하는지 확인할 수 있는 실행파일(Main 함수)는 다음과 같다.
#include <stdio.h>
#include "ALGraphBFS.h"
int main(void)
{
ALGraph graph;
GraphInit(&graph, 7);
AddEdge(&graph, A, B);
AddEdge(&graph, A, D);
AddEdge(&graph, B, C);
AddEdge(&graph, D, C);
AddEdge(&graph, D, E);
AddEdge(&graph, E, F);
AddEdge(&graph, E, G);
ShowGraphEdgeInfo(&graph);
BFShowGraphVertex(&graph, A); printf("\n");
BFShowGraphVertex(&graph, C); printf("\n");
BFShowGraphVertex(&graph, E); printf("\n");
BFShowGraphVertex(&graph, G); printf("\n");
GraphDestroy(&graph);
return 0;
}
> gcc .\ALGraphBFS.c .\BFSMain.c .\CircularQueue.c .\DLinkedList.c
> .\a.exe
A와 연결된 정점: B D
B와 연결된 정점: A C
C와 연결된 정점: B D
D와 연결된 정점: A C E
E와 연결된 정점: D F G
F와 연결된 정점: E
G와 연결된 정점: E
A B D C E F G
C B D A E F G
E D F G A C B
G E D F A C B14-4. 최소 비용 신장 트리 (Minimum Cost Spanning Tree)
사실 트리는 그래프의 한 유형이다...!
사이클(Cycle)을 형성하지 않는 그래프
다음 그래프를 보고 정점B에서 정점D에 이르는 모든 경로(path)를 찾아서 열거해보자.
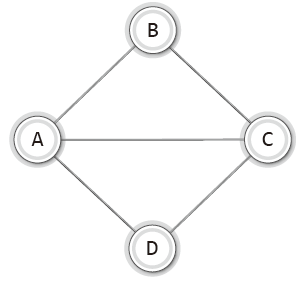
경로는 총 4개며 다음과 같다.

이렇든 두 개의 정점을 잇는 간선을 순서대로 나열한 것을 경로라 한다.
즉, 위의 네 경로는 정점B에서 정점D에 이르는 경로가 된다.
그리고 위 네 경로와 같이 동일한 간선을 중복하여 포함하지 않는 경로를 가리켜 '단순 경로(simple path)'라 한다.
단순 경로가 아닌 예시는 B–A–C–B–A–D (B와 A를 잇는 간선이 두 번 포함됨)와 같은 것이 있다.
A-B-C-A와 같은 경로도 단순 경로로, 중복된 간선이 포함되어 있지 않고, 시작과 끝이 같은 경로로 '사이클(cycle)'이라 한다.
이번에 구성할 그래프는 다음 그림의 예시들과 같이 사이클을 형성하지 않는 그래프이다.
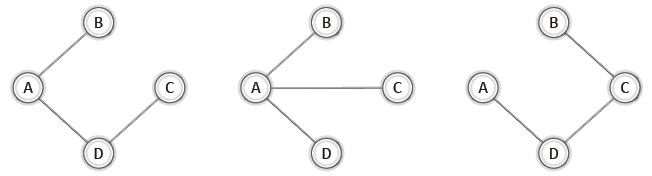
이러한 종류의 그래프를 가리켜 '신장 트리(spanning tree)'라고 한다.
위 그래프를 회전시켜 살펴보면 트리라고 하는 이유를 더 잘 알 수 있다.
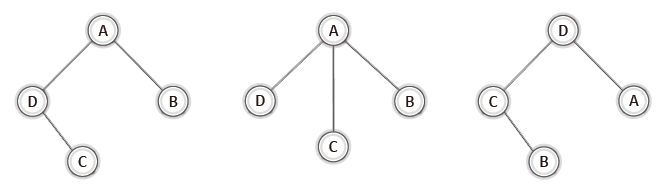
최소 비용 신장 트리의 이해와 적용
신장 트리의 특징 2가지는 다음과 같다.
- 그래프의 모든 정점이 간선에 의해서 하나로 연결되어 있다.
- 그래프 내에서 사이클을 형성하지 않는다.
물론 다음과 같이 가중치 그래프를 대상으로도, 그리고 그림으로는 보이지 않지만 간선에 방향성이 부여된 방향 그래프를 대상으로도 신장 트리를 구성할 수 있다.
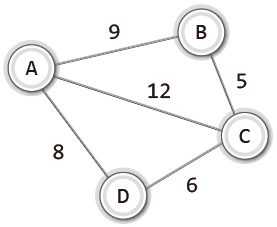
그리고 신장 트리의 모든 간선의 가중치 합이 최소인 그래프를 가리켜 '최소 비용 신장 트리(minimum cost spanning tree)' 또는 '최소 신장 트리(minimum spanning tree)'라 한다.
즉, 위 그래프의 최소 비용 신장 트리는 다음의 형태가 된다.
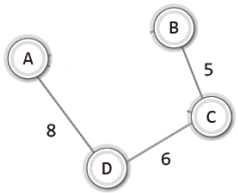
이렇듯 줄여서 MST라 표현되는 '최소 비용 신장 트리'는 개념적으로 간단하다.
MST를 활용한 예시로, 강원, 경기, 경북, 울산, 전북을 직선으로 연결하는 물류에 특화된 도로를 건설한다고 가정해보자.
그렇다면 다음과 같은, 모든 지역이 직선으로 연결된 이상적인 환경을 기대할 수 있다.
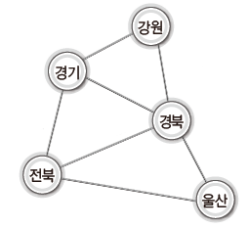
하지만 직선으로 연결하는 도로 건설에는 비용이 많이 드니 다섯 개의 지역이 모두 연결되게 하되, 그 거리를 최소화하는 형태로 도로를 건설한다고 생각해보자.
그리고 이를 목적으로 지역간 직선거리를 조사하여 다음과 같이 그림이 완성되었다.
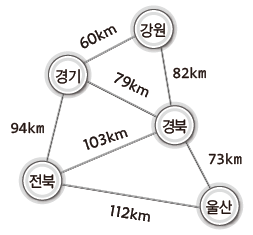
이렇게 보니 무방향 가중치 그래프와 모습이 동일하다.
위 그래프를 대상으로 최소 비용 신장 트리를 구하면 된다.
그리고 그 모습은 다음과 같다.
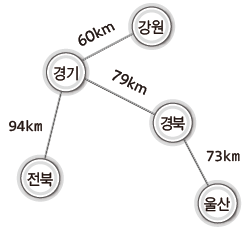
최소 비용 신장 트리의 구성을 위한 알고리즘 - 크루스칼(Kruskal) 알고리즘
최소 비용 신장 트리의 구성에 사용되는 대표적인 알고리즘 2가지는 다음과 같다.
-
크루스칼(Kruskal) 알고리즘
: 가중치를 기준으로 간선을 정렬한 후에 MST가 될 때까지 간선을 하나씩 선택 또는 삭제해 나가는 방식 -
프림(Prim) 알고리즘
: 하나의 정점을 시작으로 MST가 될 때까지 트리를 확장해 나가는 방식
물론 이 2가지 알고리즘 말고도 다른 알고리즘이 더 있다.
하지만 하나의 알고리즘을 정확하게 이해하고 이를 구현하는 것이 더 의미있고 이 경험이 중요하기 대문에 이 2가지 중 MST를 보다 더 대표하는 크루스칼 알고리즘에 대해 더 알아보고 이를 이용해 구현하려한다.
1) 이해 - 모델 1
크루스칼 알고리즘의 핵심은 가중치를 기준으로 간선을 정렬한다는 것에 있다.
예시 그래프 하나를 크루스칼 알고리즘을 활용해 MST가 되게 하려고 한다.
| Pic. | Expl. |
|---|---|
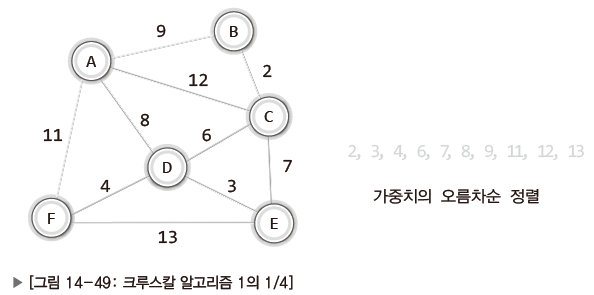 | 가중치를 기준으로 간선을 오름차순으로 정렬. 간선의 가중치가 중복되지 않기 때문에 가중치 정보만을 오름차순으로 정렬. |
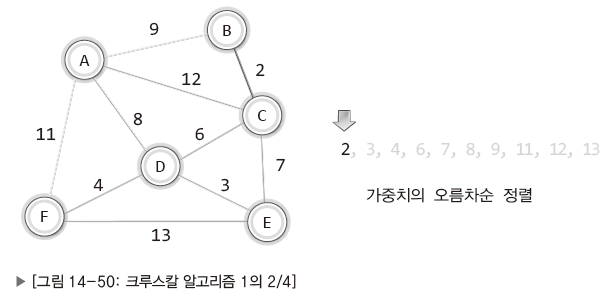 | 가중치가 가장 낮은 가중치 2 간선(B-C)를 추가. |
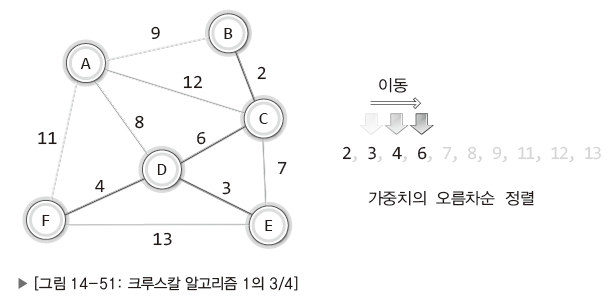 | 그 다음으로 가중치가 낮은 간선 추가. (D-E),(D-F),(C-D) |
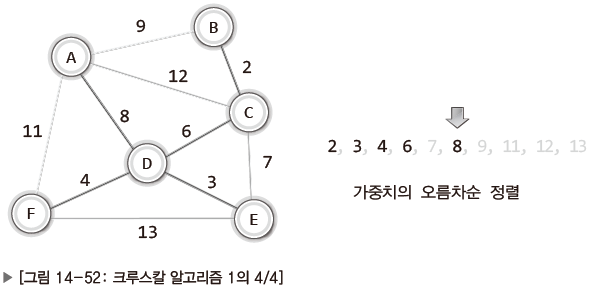 | 그 다음 가중치가 낮은 가중치 7 간선 추가하려 했으나, 그래프 내에서 사이클이 발생. 해당 간선 건너뛰고 그 다음 간선 추가. |
이로써 추가된 간선의 수가 정점의 수보다 하나 작은 5개가 되었고 알고리즘이 종료된다.
MST는 라는 식을 만족하기 때문이다.
따라서 위 그래프의 MST는 다음과 같이 형성된다.
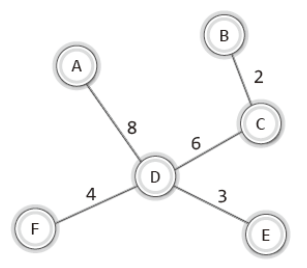
지금까지 배운 크루스칼 알고리즘의 흐름에 있어 핵심되는 사항은 다음과 같다.
- 가중치를 기준으로 간선을 오름차순으로 정렬
- 낮은 가중치의 간선부터 시작해서 하나씩 그래프에 추가
- 사이클을 형성하는 간선은 추가하지 않기
- 간선의 수가 정점의 수보다 하나 적을 때 MST 완성
앞서 언급했듯이 크루스칼 알고리즘의 핵심은 가중치를 기준으로 간선을 정렬한다는데 있다.
하지만 반드시 오름차순으로 정렬해야 하는 것은 아니다.
크루스칼 알고리즘에는 내림차순으로 정렬된 상황에서 적용할 수 있는 모델도 있기 때문이다.
2) 이해 - 모델 2
간선을 내림차순으로 정렬하면 낮은 가중치의 간선을 하나씩 추가하는 방식이 아니라 높은 가중치의 간선을 하나씩 빼는 방식으로 알고리즘이 전개된다.
그래서 모델 1과 2로 구분하기도 한다.
그럼 다음 예시로 크루스칼 알고리즘의 다른 적용 모델에 대해 알아보자.
| Pic. | Expl. |
|---|---|
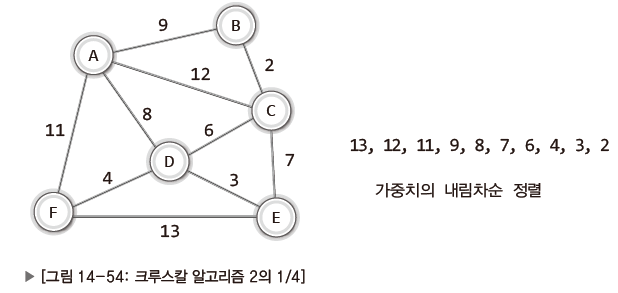 | 내림차순으로 가중치를 정렬. |
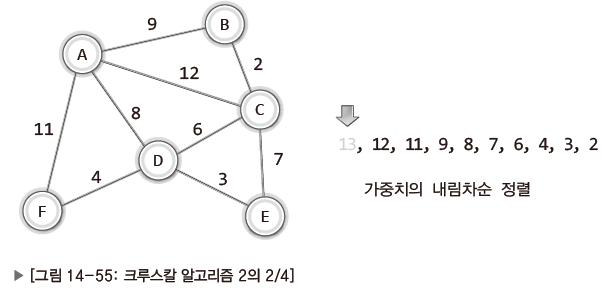 | 가중치가 가장 높은 가중치 13 간선(E-F) 삭제. |
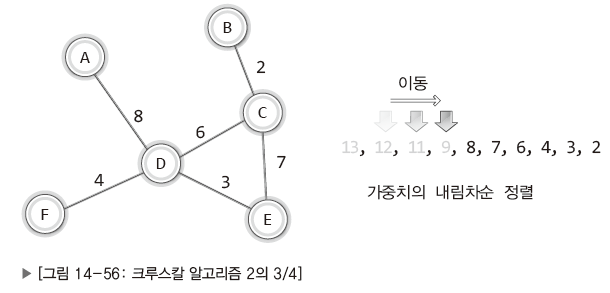 | 그 다음으로 가중치가 높은 간선 삭제. (A-C), (A-F), (A-B) 그 다음으로 가중치가 높은 간선인 가중치 8 간선 삭제. 이 간선을 삭제시 문제 발생. |
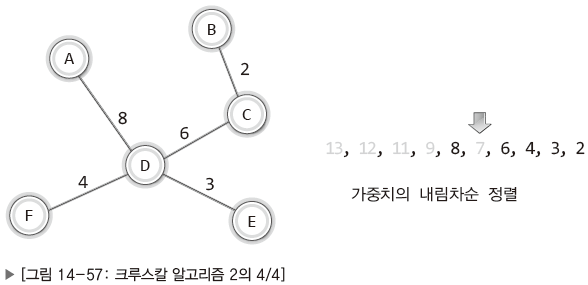 | 가중치 8 간선을 삭제시 정점A와 정점D를 잇는 경로가 없음. (단, 직접적인 경로가 아니더라도 다른 경로를 통해 연결되어 있는 경우에는 삭제 가능.) 그 다음으로 가중치가 큰 가중치 7 간선(C-E) 삭제. |
이로써 MST가 완성되었다. (정점의 수가 간선의 수보다 하나 더 많은 상황이기 때문)
두 번째 크루스칼 알고리즘의 핵심되는 사항은 다음과 같다.
- 가중치를 기준으로 간선을 내림차순으로 정렬
- 높은 가중치의 간선부터 시작해서 하나씩 그래프에서 제거
- 두 정점을 연결하는 다른 경로가 없을 경우 해당 간선은 제거하지 않기
- 간선의 수가 정점의 수보다 하나 적을 때 MST 완성
3) 구현을 위한 계획
이전에 구현한 것들을 최대한 활용해서 크루스칼 알고리즘을 구현하려고 한다.
구현할 알고리즘은 가중치를 기준으로 간선을 내림차순으로 정렬한 다음 높은 가중치의 간선부터 시작해서 하나씩 그래프에서 제거하는 방식을 따라갈 것이다.
이를 위해서 DFS의 구현결과인 다음 파일들을 활용할 것이다.
- DLinkedList.h, DLinkedList.c : 연결 리스트
- ArrayBaseStack.h, ArrayBaseStack.c : 배열 기반 스택
- ALGraphDFS.h, ALGraphDFS.c : 깊이 우선 탐색을 포함하는 그래프
이 중에서 ALGraphDFS.h와 ALGraphDFS.c에 담겨있는 대표적인 기능은 '그래프의 구성', 'DFS 기반의 정점 정보 출력'이다.
크루스칼 알고리즘의 구현을 위해서는 먼저 그래프를 구성해야 하기 때문에 이는 유용하게 활용된다.
하지만 가중치 그래프를 구성해야 하기 때문에 ALGraphDFS.h와 ALGraphDFS.c은 활용은 하되 많은 부분이 수정되어야 한다. 그래서 이 두 파일을 수정하고 확장하여 ALGraphKruskal.h과 ALGraphKruskal.c로 파일명을 변경해 사용할 것이다.
크루스칼 알고리즘을 구현하기 위해서는 간선을 삭제해도 이 간선에 의해 연결된 두 정점을 연결하는 경로가 있는지 확인을 해야하는데 이는 DFS 알고리즘을 활용해 확인할 것이다.
가중치를 기준으로 간선을 정렬할 수 있어야하는데, 이 부분을 위해서는 우선순위 큐를 활용할 것이다.
- PriorityQueue.h, PriorityQueue.c : 우선순위 큐
- UsefulHeap.h, UsefulHeap.c : 우선순위 큐의 기반이 되는 힙
그리고 가중치 그래프의 표현을 위해서는 가중치가 포함된 간선의 정보를 담을 수 있어야하기 때문에 다음과 같은 헤더파일이 추갈 필요하다.
- ALEdge.h : 가중치가 포함된 간선의 표현을 위한 구조체 정의
정리하자면 다음과 같은 파일들이 크루스칼 알고리즘 구현에 필요하고 하나로 묶여야 한다.
(여태까지 배운 것의 총집합이라 할 수 있다.)
- DLinkedList.h, DLinkedList.c : 연결 리스트
- ArrayBaseStack.h, ArrayBaseStack.c : 배열 기반 스택
- ALGraphDFS.h, ALGraphDFS.c : 깊이 우선 탐색을 포함하는 그래프
- PriorityQueue.h, PriorityQueue.c : 우선순위 큐
- UsefulHeap.h, UsefulHeap.c : 우선순위 큐의 기반이 되는 힙
- ALEdge.h : 가중치가 포함된 간선의 표현을 위한 구조체 정의
4) 구현
-헤더파일 (ALEdge.h, ALGraphKruskal.h)
우선 추가되는 헤더파일인 ALEdge.h 다음과 같다.
#ifndef __AL_EDGE__
#define __AL_EDGE__
typedef struct _edge
{
int v1; // 간선이 연결하는 첫 번째 정점
int v2; // 간선이 연결하는 두두 번째 정점
int weight; // 간선의 가중치
} Edge;
#endif이 구조체의 목적은 간선 정보의 저장이 아니다.
이 구조체의 실질적인 목적은 간선의 가중치 정보를 저장한다는 것에 잇다.
간선의 가중치 정보를 별도로 저장하는 이유는 이 정보를 대상으로 크루스칼 알고리즘의 핵심인 가중치 기반의 정렬을 진행하기 위함이다.
다음으로 ALGraphDFS.h을 약간 변형한 ALGraphKruskal.h을 살펴보자.
#ifndef __AL_GRAPH_KRUSKAL__
#define __AL_GRAPH_KRUSKAL__
#include "DLinkedList.h"
#include "PriorityQueue.h"
#include "ALEdge.h"
enum {A, B, C, D, E, F, G, H, I, J};
typedef struct _ual
{
int numV;
int numE;
List * adjList;
int * visitInfo;
PQueue pqueue; // 간선의 가중치 정보 저장
} ALGraph;
// 이전 함수의 정의와 차이가 있음
void GraphInit(ALGraph * pg, int nv);
// 이전 함수와 동일
void GraphDestroy(ALGraph * pg);
// 이전 함수의 정의와 차이가 있음
void AddEdge(ALGraph * pg, int fromV, int toV, int weight);
// 이전 함수와 동일
void ShowGraphEdgeInfo(ALGraph * pg);
// 이전 함수와 동일
void DFShowGraphVertex(ALGraph * pg, int startV);
// 새로 추가된 함수
// 최소 비용 신장 트리의 구성성
void ConKruskalMST(ALGraph * pg);
// 가중치 정보 출력력
void ShowGraphEdgeWeightInfo(ALGraph * pg);
#endif구조체 ALGraph에서 PQueue pqueue;라는 멤버가 하나 추가되었다.
-주요 함수 정의
구조체에서 우선순위 큐가 멤버로 추가되었고 이는 간선의 가중치 정보를 나타내는 구조체인 Edge의 변수를 저장하기 위함이다.
이로 인해서 GraphInit 함수에는 우선순위 큐의 초기화를 위한 문장이 추가되어야 한다.
void GraphInit(ALGraph * pg, int nv)
{
....
// 우선순위 큐의 초기화
PQueueInit(&(pg->pqueue), PQWeightComp);
}그리고 우선순위 큐의 우선순위 비교기준인, PQueueInit 함수의 인자로 전달된 PQWeightComp 함수도 정의되어야 한다.
int PQWeightComp(Edge d1, Edge d2)
{
return d1.weight - d2.weight;
}첫 번째 인자로 전달된 간선의 가중치가 클 때 양수가 반환되도록 정의되었다.
따라서 가중치를 기준으로 내림차순으로 간선의 정보를 꺼낼 수 있게 되었다.
(이는 크루스칼 알고리즘의 구현을 위한 것이다.)
이어서 간선을 추가할 때 호출하는 AddEdge 함수를 보자.
간선에 가중치 정보가 포함되었기 때문에 다음과 같이 변경되어야 한다.
void AddEdge(ALGraph * pg, int fromV, int toV, int weight)
{
Edge edge = {fromV, toV, weight}; // 간선의 가중치 정보를 담음
LInsert(&(pg->adjList[fromV]), toV);
LInsert(&(pg->adjList[toV]), fromV);
pg->numE += 1;
// 간선의 가중치 정보를 우선순위 큐에 저장장
PEnqueue(&(pg->pqueue), edge);
}이렇듯 AddEdge 함수에 간선의 가중치 정보를 우선순위 큐에 담는 문장이 추가되었고 가중치 정보가 더불어 전달되도록 매개변수의 수도 하나 늘었다.
물론 우선순위 큐의 저장 대상이 구조체 Edge의 변수이므로 UsefulHeap.h에 다음 #include문을 포함시키고, typedef 선언도 변경해야 한다.
#include "ALEdge.h"
typedef Edge HData;마지막으로 크루스칼 알고리즘의 실질적인 구현결과를 나타내줄 함수는 void ConKruskalMST(ALGraph * pg);이다.
이 함수를 호출하면서 그래프의 주소 값을 전달하면, 전달된 주소 값의 그래프는 최소 비용 신장 트리가 된다.
// 크루스칼 알고리즘 기반 MST의 구성
void ConKruskalMST(ALGraph * pg)
{
Edge recvEdge[20]; // 복원할 간선의 정보 저장
Edge edge;
int eidx = 0;
int i;
// MST를 형성할 때까지 아래의 while문 반복복
while(pg->numE+1 > pg->numV) // MST 간선의 수 + 1 == 정점의 수
{
// 우선순위 큐에서 가중치가 제일 높은 간선의 정보를 꺼냄
edge = PDequeue(&(pg->pqueue));
// 우선순위 큐에서 꺼낸 간선을 실제로 그래프에서 삭제
RemoveEdge(pg, edge.v1, edge.v2);
// 간선을 삭제하고 나서도 두 정점을 연결하는 경로가 있는지 확인
if(!IsConnVertex(pg, edge.v1, edge.v2))
{
// 경로가 없다면 삭제한 간선을 복원
RecoverEdge(pg, edge.v1, edge.v2, edge.weight);
// 복원한 간선의 정보를 별도로 저장
recvEdge[eidx++] = edge;
}
}
// 우선순위 큐에서 삭제된 간선의 정보를 회복
for(i=0; i<eidx; i++)
PEnqueue(&(pg->pqueue), recvEdge[i]);
}위 함수에서는 아직 소개하지 않은 함수를 호출하고 있는데, 그 함수들의 기능을 정리하면 다음과 같다.
- RemoveEdge : 그래프에서 간선을 삭제
- IsConnVertex : 두 정점이 연결되어 있는지 확인
- RecoverEdge : 삭제된 간선을 다시 삽입
그리고 ConKruskalMST 함수에서 복원한 간선의 정보를 우선순위 큐에 넣지 않고 별도로 저장하는 이유는 우선순위 큐에 다시 넣으면 PDequeue 함수 호출 시 다시 꺼내게 되기 때문이다.
크루스칼 알고리즘에서는 한번 검토가 이뤄진 간선은 재검토하지 않는다.
따라서 복원된 간선을 우선순위 큐에 다시 넣으면 안된다.
그리고 이렇게 별도로 저장한 간선의 정보는 반복문을 빠져나간 후에 다음과 같이 for문으로 우선순위 큐에 다시 넣는다.
때문에 위의 반복문까지 실행되면 우선순위 큐에는 MST를 이루는 간선의 정보만 남게 된다.
그리고 이렇게 우선순위 큐에 남은 간선의 가중치 정보를 출력하기 위해 void ShowGraphEdgeWeightInfo(ALGraph * pg);라는 함수를 선언 및 정의했다.
void ShowGraphEdgeWeightInfo(ALGraph * pg)
{
PQueue copyPQ = pg->pqueue;
Edge edge;
while(!PQIsEmpty(©PQ))
{
edge = PDequeue(©PQ);
printf("(%c-%c), w:%d \n", edge.v1+65, edge.v2+65, edge.weight);
}
}이제 남은 함수는 위에서 정리한 RemoveEdge, IsConnVertex, RecoverEdge 함수의 정의를 살펴보자.
// 간선의 소멸
void RemoveEdge(ALGraph * pg, int fromV, int toV)
{
RemoveWayEdge(pg, fromV, toV);
RemoveWayEdge(pg, toV, fromV);
(pg->numE)--;
}
// 한쪽 방향의 간선 소멸
void RemoveWayEdge(ALGraph * pg, int fromV, int toV)
{
int edge;
if(LFirst(&(pg->adjList[fromV]), &edge))
{
if(edge == toV)
{
LRemove(&(pg->adjList[fromV]));
return;
}
while(LNext(&(pg->adjList[fromV]), &edge))
{
if(edge == toV)
{
LRemove(&(pg->adjList[fromV]));
return;
}
}
}
}구현하는 그래프가 무방향 그래프이다 보니 소멸시킬 간선의 정보가 두개다.
그래서 각각의 소멸을 위한 RemoveWayEdge 함수를 정의하고 RemoveEdge 함수가 이를 두 번 호출하는 형태로 정의되었다.
다음은 RecoverEdge 함수다.
// 삭제된 간선을 다시 삽입
void RecoverEdge(ALGraph * pg, int fromV, int toV)
{
LInsert(&(pg->adjList[fromV]), toV);
LInsert(&(pg->adjList[toV]), fromV);
(pg->numE)++;
}이는 분명 AddEdge 함수와 다르다.
위 함수들은 어디까지나 ConKruskalMST 함수를 위해서 정의한, ConKruskalMST 함수를 돕는 함수일 뿐이다.
간선의 삽입과 삭제의 과정에서 해당 간선의 가중치 정보를 고려하지 않은 점에서 이를 알 수 있다.
마지막으로 두 정점의 연결을 확인하는 IsConnVertex 함수를 살펴보자.
이는 앞에서 얘기한 DFShowGraphVertex 함수를 수정한 것이다.
// 인자로 전달된 두 정점이 연결되어 있다면 TRUE, 그렇지 않다면 FALSE 반환
int IsConnVertex(ALGraph * pg, int v1, int v2)
{
Stack stack;
int visitV = v1;
int nextV;
StackInit(&stack);
VisitVertex(pg, visitV);
SPush(&stack, visitV);
while(LFirst(&(pg->adjList[visitV]), &nextV) == TRUE)
{
int visitFlag = FALSE;
// 정점을 돌아다니는 도중에 목표를 찾는다면 TURE를 반환
if(nextV == v2)
{
// 함수가 반환하기 전에 초기화 진행
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
return TRUE; // 목표를 찾았으니 TRUE 반환
}
if(VisitVertex(pg, nextV) == TRUE)
{
SPush(&stack, visitV);
visitV = nextV;
visitFlag = TRUE;
}
else
{
while(LNext(&(pg->adjList[visitV]), &nextV) == TRUE)
{
// 정점을 돌아다니는 도중에 목표를 찾는다면 TRUE를 반환
if(nextV == v2)
{
// 함수가 반환하기 전에 초기화를 진행
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
return TRUE;
}
if(VisitVertex(pg, nextV) == TRUE)
{
SPush(&stack, visitV);
visitV = nextV;
visitFlag = TRUE;
break;
}
}
}
if(visitFlag == FALSE)
{
if(SIsEmpty(&stack) == TRUE)
break;
else
visitV = SPop(&stack);
}
}
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
return FALSE; // 목표 찾지 못함.
}위에서 설명한 함수들을 정리한 소스파일은 다음과 같다.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "ALGraphKruskal.h"
#include "DLinkedList.h"
#include "ArrayBaseStack.h"
int WhoIsPrecede(int data1, int data2);
int PQWeightComp(Edge d1, Edge d2);
void GraphInit(ALGraph * pg, int nv)
{
int i;
pg->adjList = (List*)malloc(sizeof(List)*nv);
pg->numV = nv;
pg->numE = 0;
for(i=0; i<nv; i++)
{
ListInit(&(pg->adjList[i]));
SetSortRule(&(pg->adjList[i]), WhoIsPrecede);
}
pg->visitInfo= (int *)malloc(sizeof(int) * pg->numV);
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
// 우선순위 큐의 초기화
PQueueInit(&(pg->pqueue), PQWeightComp);
}
void GraphDestroy(ALGraph * pg)
{
if(pg->adjList != NULL)
free(pg->adjList);
if(pg->visitInfo != NULL)
free(pg->visitInfo);
}
void AddEdge(ALGraph * pg, int fromV, int toV, int weight)
{
Edge edge = {fromV, toV, weight}; // 간선의 가중치 정보를 담음
LInsert(&(pg->adjList[fromV]), toV);
LInsert(&(pg->adjList[toV]), fromV);
pg->numE += 1;
// 간선의 가중치 정보를 우선순위 큐에 저장
PEnqueue(&(pg->pqueue), edge);
}
// 삭제된 간선을 다시 삽입 : ConKruskalMST Helper function
void RecoverEdge(ALGraph * pg, int fromV, int toV)
{
LInsert(&(pg->adjList[fromV]), toV);
LInsert(&(pg->adjList[toV]), fromV);
(pg->numE)++;
}
// 한쪽 방향의 간선 소멸 : ConKruskalMST Helper function
void RemoveWayEdge(ALGraph * pg, int fromV, int toV)
{
int edge;
if(LFirst(&(pg->adjList[fromV]), &edge))
{
if(edge == toV)
{
LRemove(&(pg->adjList[fromV]));
return;
}
while(LNext(&(pg->adjList[fromV]), &edge))
{
if(edge == toV)
{
LRemove(&(pg->adjList[fromV]));
return;
}
}
}
}
// 그래프에서 간선을 삭제 : ConKruskalMST Helper function
void RemoveEdge(ALGraph * pg, int fromV, int toV)
{
RemoveWayEdge(pg, fromV, toV);
RemoveWayEdge(pg, toV, fromV);
(pg->numE)--;
}
void ShowGraphEdgeInfo(ALGraph * pg)
{
int i;
int vx;
for(i=0; i<pg->numV; i++)
{
printf("%c와 연결된 정점: ", i + 65);
if(LFirst(&(pg->adjList[i]), &vx))
{
printf("%c ", vx + 65);
while(LNext(&(pg->adjList[i]), &vx))
printf("%c ", vx + 65);
}
printf("\n");
}
}
// 간선의 가중치 정보 출력
void ShowGraphEdgeWeightInfo(ALGraph * pg)
{
PQueue copyPQ = pg->pqueue;
Edge edge;
while(!PQIsEmpty(©PQ))
{
edge = PDequeue(©PQ);
printf("(%c-%c), w:%d \n", edge.v1+65, edge.v2+65, edge.weight);
}
}
int WhoIsPrecede(int data1, int data2)
{
if(data1 < data2)
return 0;
else
return 1;
}
int PQWeightComp(Edge d1, Edge d2)
{
return d1.weight - d2.weight;
}
int VisitVertex(ALGraph * pg, int visitV)
{
if(pg->visitInfo[visitV] == 0)
{
pg->visitInfo[visitV] = 1;
// printf("%c ", visitV + 65);
return TRUE;
}
return FALSE;
}
void DFShowGraphVertex(ALGraph * pg, int startV)
{
Stack stack;
int visitV = startV;
int nextV;
StackInit(&stack);
VisitVertex(pg, visitV);
SPush(&stack, visitV);
while(LFirst(&(pg->adjList[visitV]), &nextV) == TRUE)
{
int visitFlag = FALSE;
if(VisitVertex(pg, nextV) == TRUE)
{
SPush(&stack, visitV);
visitV = nextV;
visitFlag = TRUE;
}
else
{
while(LNext(&(pg->adjList[visitV]), &nextV) == TRUE)
{
if(VisitVertex(pg, nextV) == TRUE)
{
SPush(&stack, visitV);
visitV = nextV;
visitFlag = TRUE;
break;
}
}
}
if(visitFlag == FALSE)
{
if(SIsEmpty(&stack) == TRUE)
break;
else
visitV = SPop(&stack);
}
}
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
}
// 두 정점이 연결되어 있는지 확인 : ConKruskalMST Helper function
// 인자로 전달된 두 정점이 연결되어 있다면 TRUE, 그렇지 않다면 FALSE 반환
int IsConnVertex(ALGraph * pg, int v1, int v2)
{
Stack stack;
int visitV = v1;
int nextV;
StackInit(&stack);
VisitVertex(pg, visitV);
SPush(&stack, visitV);
while(LFirst(&(pg->adjList[visitV]), &nextV) == TRUE)
{
int visitFlag = FALSE;
if(nextV == v2)
{
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
return TRUE;
}
if(VisitVertex(pg, nextV) == TRUE)
{
SPush(&stack, visitV);
visitV = nextV;
visitFlag = TRUE;
}
else
{
while(LNext(&(pg->adjList[visitV]), &nextV) == TRUE)
{
if(nextV == v2)
{
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
return TRUE;
}
if(VisitVertex(pg, nextV) == TRUE)
{
SPush(&stack, visitV);
visitV = nextV;
visitFlag = TRUE;
break;
}
}
}
if(visitFlag == FALSE)
{
if(SIsEmpty(&stack) == TRUE)
break;
else
visitV = SPop(&stack);
}
}
memset(pg->visitInfo, 0, sizeof(int) * pg->numV);
return FALSE;
}
// 크루스칼 알고리즘 기반 MST의 구성
void ConKruskalMST(ALGraph * pg)
{
Edge recvEdge[20]; // 복원할 간선의 정보 저장
Edge edge;
int eidx = 0;
int i;
// MST를 형성할 때까지 아래의 while문 반복복
while(pg->numE+1 > pg->numV) // MST 간선의 수 + 1 == 정점의 수
{
edge = PDequeue(&(pg->pqueue));
RemoveEdge(pg, edge.v1, edge.v2);
if(!IsConnVertex(pg, edge.v1, edge.v2))
{
RecoverEdge(pg, edge.v1, edge.v2, edge.weight);
recvEdge[eidx++] = edge;
}
}
// 우선순위 큐에서 삭제된 간선의 정보를 회복
for(i=0; i<eidx; i++)
PEnqueue(&(pg->pqueue), recvEdge[i]);
}-실행파일 (KruskalMain.c)
구현 결과의 확인을 위한 main 함수는 다음과 같다.
#include <stdio.h>
#include "ALGraphKruskal.h"
int main(void)
{
ALGraph graph;
GraphInit(&graph, 6);
AddEdge(&graph, A, B, 9);
AddEdge(&graph, B, C, 2);
AddEdge(&graph, A, C, 12);
AddEdge(&graph, A, D, 8);
AddEdge(&graph, D, C, 6);
AddEdge(&graph, A, F, 11);
AddEdge(&graph, F, D, 4);
AddEdge(&graph, D, E, 3);
AddEdge(&graph, E, C, 7);
AddEdge(&graph, F, E, 13);
ConKruskalMST(&graph);
ShowGraphEdgeInfo(&graph);
ShowGraphEdgeWeightInfo(&graph);
GraphDestroy(&graph);
return 0;
}
> gcc .\ALGraphKruskal.c .\ArrayBaseStack.c .\DLinkedList.c .\KruskalMain.c .\PriorityQueue.c .\UsefulHeap.c
> .\a.exe
> 출력
A와 연결된 정점: D
B와 연결된 정점: C
C와 연결된 정점: B D
D와 연결된 정점: A C E F
E와 연결된 정점: D
F와 연결된 정점: D
(A-D), w:8
(D-C), w:6
(F-D), w:4
(D-E), w:3
(B-C), w:2출력결과를 담당하고 있는 VisitVertex 함수를 살펴보면 printf("%c ", visitV + 65); 문장이 주석처리 되어있다.
이는 방문한 정점의 이름을 출력하기 위한 문장으로 다 보여주면 너무 많아서 주석처리 했다.
<Review>
이로써 c언어로도 자료구조 배우기를 끝냈다...!

사실 뒤로 갈 수록 지치기도 하고 (다른 일이 많기도 하고)
왜 C언어를 안쓰는지 알게 된기도 한거 같다.(?)
마지막 크루스칼 알고리즘은 여태 배운 것을 총망라 한 느낌을 받아서 더 머리에 안들어온거 같다...
(앞에서 한 내용이 기억에 잘 안났달까...)

아무튼 여기까지 달려온 나에게 고생했다고 얘기하고 싶다.
같이 여기까지 함께해준 스터디원들에게도 감사하다고 말하고 싶다.

9월부터 12월까지 약 4개월을 함께 달려왔고 앞으로 코딩쪽으로 더 멋진 성장과 활동 할 수 있길 응원한다..!
다음에는 다른 학습 또는 도전으로 velog를 찾아올 예정이다.
다음에 봐용~!

