다양한 길이의 문장을 CNN과 Dynamic k-max pooling 을 통해 embedding 시킵니다. 하나의 네트워크에서 다양한 input을 한 번에 다룰 수 있는 것이 다양하게 활용할 수 있을 것으로 보입니다.
[Abstract]
문장을 정확하게 표현하는 능력은 언어 이해에 있어 주된 역량입니다. 문장의 의미 모델링 구조인 Dynamic Convolutional Neural Netword(DCNN)을 해당 논문에서 소개합니다. DCNN은 Dynamic k-Max Pooling을 사용합니다. DCNN은 가변 길이의 문장을 다룰 수 있고, 가깝거나 먼 거리에 있는 관계를 명확하게 잡아낼 수 있는 feature graph를 만듭니다.
1. Introduction
Sentence model의 목적은 분류나 생성의 목적을 위해 문장을 분석하거나 의미 관계를 제대로 표현하는 것입니다.
개별 문장들은 거의 관찰할 수 없고, 전체를 볼 수도 없기 떄문에 문장 내에서 자주 등장하는 단어들이나, 짧은 n-gram을 특징으로 삼아 문장을 표현합니다. Sentence model의 핵심은 단어나 n-gram의 특징으로부터 추출되는 문장의 특징을 뽑아내느 과정을 정희하는 feature funcion을 포함합니다.
Composition based 방법은 long phrase의 vector를 얻기 위해 사용되는 co-occurrence 통계량으로부터 얻어지는 단어 vector를 활용합니다.
또 다른 방법으로는 자동으로 논리적인 형태를 추출하여 문장의 의미를 표현하는 방식입니다. 이런 방식은 neural network를 주로 활용합니다. 기본적인 neural bag-of-words나 bag-of-n grams 모델부터 좀 더 구조적인 recursive neural network와 convolution 연산 기반의 time-delay neural network를 포함합니다. Neural sentence model은 장점들이 있습니다. Neural sentence model은 단어나 구들이 등장하는 주면 문맥을 예측하는 방식으로 단어와 구의 일반화된 vector를 학습합니다.
해당 논문은 convolutional neural network 구조를 정의하고 문장의 의미 modeling에 적용합니다. 소개하는 network는 가변적인 길이의 문장을 input으로 사용할 수 있습니다. Network의 층은 one-dimensional convolutional layer와 dynamic k-max pooling layer로 구성되어 있습니다. Dynamic k-max pooling은 max pooing의 일반화된 버전입니다. 일반화는 2단계를 거쳐 이루어집니다. 첫째, k-max pooling은 하나의 최대값 대신 k개의 최대값을 반환합니다. 둘째, network나 input에 따라 k의 값이 정해집니다.
문장 안세어 모든 지점에서 n-gram들이 같은 filter를 통해 convolving 연산하는 과정은 문장 내에서 그들의 위치에서 독립적으로 feature가 뽑힐 수 있도록 합니다. Convolutional layer 뒤에 dynamic pooling layer와 non-linearity가 나오고 이는 feature map을 만듭니다. Object detection의 convolutional network와 마찬가지로 해당 논문에서는 input sentence에 서로 다른 filter를 통해 multiple feature map을 만듭니다. 결과적으로 얻는 이런한 architectur를 Dynamic Convolutinal Neural Network라고 합니다.
Convolutioanl 과 dynamic pooling 연산의 여러겹 layer들은 input sentence의 구조화된 feature graph를 만듭니다.
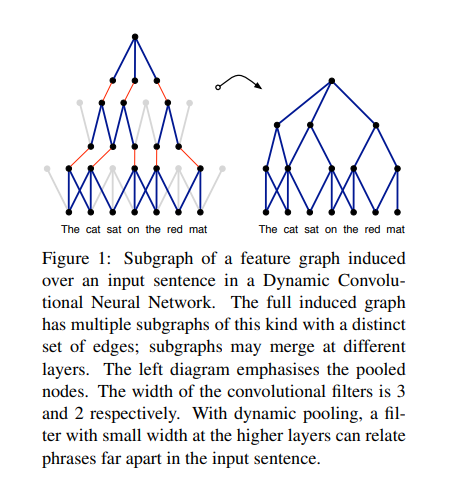
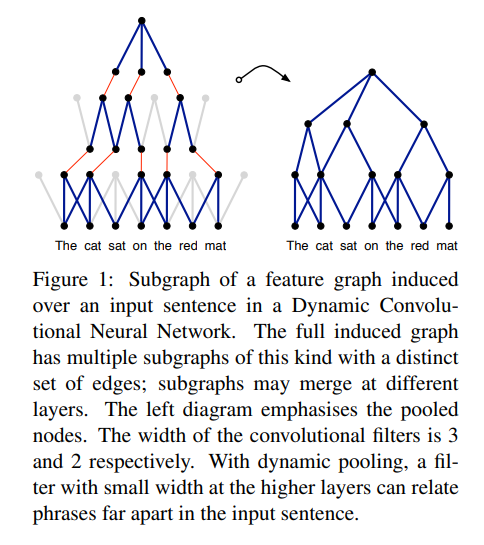
Higer layer의 small filter는 input sentence에서 멀리 떨어진 연속적이지 않은 구들의 문법적, 의미적 관계를 잡아냅니다.
2. Background
DCNN의 layer는 convolution 연산과 그 뒤의 pooling 연산으로 이루어졌습니다.
2.1 Related Neural Sentence Models
기본적인 sentence model은 Neural Bag-of Words(NBoW) model 입니다. 이 모델은 단어나, sub-word, n-gram을 높은 차원의 embedding vector로 projection시키는 layer로 이루어졌습니다. Recursive Neural Network(RecNN)와 Reccurent Neural Network(RNN) 역시 대표적입니다. 마지막으로 convolution 연산을 기반으로 하는 neural sentence model로는 TDNN이 있습니다.
2.2 Convolution
One-dimensional convolution은 weight vector(m)와 input vector(s)의 연산입니다. m은 convolution의 filter입니다. s는 input 문장으로 생각할 수 있으며 s의 각각의 원소들은 해당 위치에 해당하는 단어들의 특징을 1차원으로 표현한 것입니다. one-dimensional covolution은 또 다른 vector c를 얻기 위해 문장 s에 m-gram 단위로 dot product를 수행하는 것으로 볼 수 있습니다.
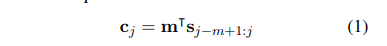
Narrow convolution은 s의 크기가 m보다 커야하며, j의 값이 m부터 s까지입니다. Wide convolution은 s와 m의 크기의 제약을 받지 않으며, j의 값이 1부터 s+m-1까지입니다. S의 범위를 벗어나는 곳은 모두 0으로 처리르 합니다(Padding) Narrow convolution의 결과는 wide convolution 결과의 부분집합니다.
필터 m의 학습된 가중치는 특정 n-gram을 인식할 수 있도록 학습된 feature dectector입니다.
Wide convolution은 filter의 모든 가중치들이 양 끝에 존재하는 단어를 포함한 모든 문장에 영향을 받습니다. 이는 M의 값이 8, 10처럼 매우 클 때 중요합니다.
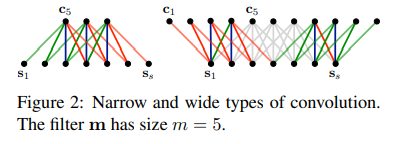
2.3 Time-Delay Neural Networks
TDNN은 input s를 weight m에 convolve합니다. s는 time dimension을 갖는다고 여겨지며, convolution은 time dimension을 넘어 적용됩니다. s의 원소들은 단일 값이 아닌 vector의 형태입니다. weight m의 각 행들은 s의 행들과 convolve되며 convolution 연산은 narrow type으로 수행됩니다.
Max TDNN sentence model에서 sentence matrix s에 narrow type convolutional layer가 적용되며 sentence matrix s의 각 열은 문장 내의 각 단어들의 feature vector입니다.
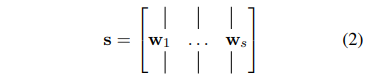
가변 길이 문장을 다루기 위해 Max TDNN은 resulting matrix c의 각 행마다 maximum 값을 얻습니다.
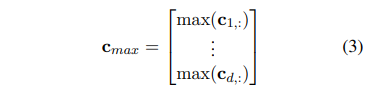
이는 가장 관련있는 feature를 얻기 위함입니다. 고정된 길이의 c_max는 분류를 위한 fully connected layer의 input으로 활용됩니다.
Max TDNN은 문장 내의 단어 순서에 민감하고 external language-specific feature에 의존하지 않습니다. 또한 문장 내의 모든 단어들로부터 동일한 중요도를 제공합니다. 단점 역시 존재합니다. feature detector의 범위는 weight의 span m으로 제한됩니다.
3. Convolutional Neural Networks with Dynamic k-Max Pooling
해당 논문에서는 dynamic k-max pooling을 사용하는 dynamic pooling layer를 사용하는 wideconvolutional layer를 활용하는 convolutional architecture를 활용하여 문장을 모델링합니다. Network 중간 layer의 width는 input sentence의 크기에 의존하여 결정됩니다.
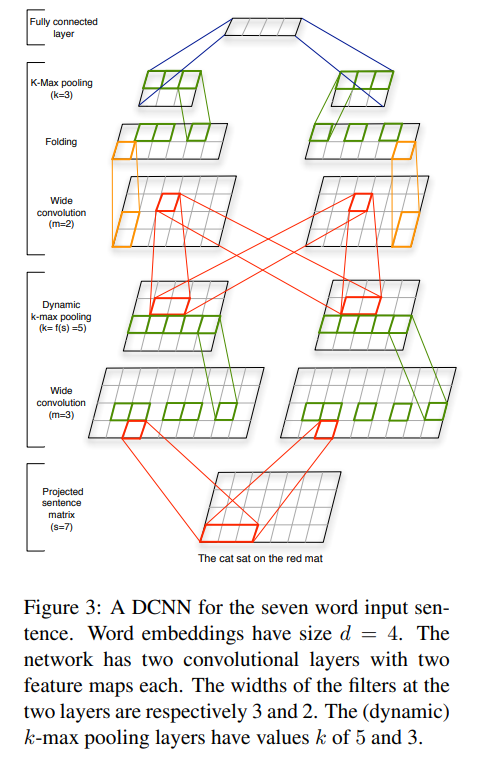
3.1 Wide Convolution
Input 문장이 주어졌을 때 DCNN의 첫번째 layer를 얻기 위해 문장 내부의 단어들의 embedding vector w_i를 활용하여 sentence matrix를 얻습니다. 각 w_i들은 학습 과정에서 최적화되는 파라미터입니다.
3.2 k-max pooling
k 값과 k보다 큰 p 차원의 벡터가 주어졌을 떄, k-max pooling은 p 차원의 벡터에서 k번쨰 큰 값까지만을 갖는 k 차원의 벡터의 부분 집합을 뽑습니다. 부분집합의 원소 순서는 기존 벡터에서의 원소 순서와 동일합니다.
k-max pooling 연산은 위치상으로 멀리 떨어진 k개의 가장 active한 feature들의 pool을 가능하게 합니다. feature들 간의 순서를 지키지만 각각의 위치에는 크게 영향을 받지 않습니다. k-max pooling 연산은 topmost convolutional layer 이후에 적용됩니다. 이는 input sentence 길이와 상관없이 fully connected layer input 크기를 보장해줍니다. 하지만 중간에 존재하는 convolutional layer 이후에 적용되는 k 값은 고정되어 있지 않으며, higher order와 longer range feature의 extraction을 위해 유동적으로 정해집니다.
3.3 Dynamic k-max pooling
Dynamic k-max pooling은 k값이 문장의 길이와 network 깊이의 함수인 k-max polling입니다.

3.4 Non-linear Feature Function
Convolution 연산 결과에 dynamic k-max pooling을 적용한 후 bias와 non linear 함수 g가 component-wise하게 적용됩니다.
3.5 Multiple Feature Maps
Convolution + dynamix k-max poolig + non-linear function 3개의 연산들을 반복하여 network의 깊이를 깊게 합니다. Object recognition처럼 특정 order의 feature detector의 수를 늘리기위해 multiple fearue maps이 같은 layer에서 계산됩니다.
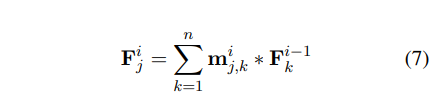
3.6 Folding
Convolution 연산과 dynamic k-max pooling 사이에 feature map의 2개의 행을 component wise하게 합을 합니다. 이를 통해 feature map의 row dimension이 절반으로 줄어들게됩니다.
4. Properties of the Sentence Model
Feature grapn의 개념에 대해 소개합니다.
4.1 Word and N-gram Order
기본적인 특징 중 하나는 input sentence의 단어 순서에 민감하다는 것입니다. 모델이 input에서 특정한 n-gram이 등장하는 지 여부를 판별할 수 있는 것은 큰 도움이 됩니다. 마찬가지로 모델이 가장 관련있는 n-gram의 상대적인 위치를 알려줄 수 있는 것도 도움이 됩니다. 첫번 째 layer의 wide convolution의 filter m은 필터 크기 m보다 작거나 같은 n-gram을 인식하는 것을 학습합니다. 첫 번째 layer의 m은 때때로 10과 같이 상대적으로 큰 값으로 설정합니다.
NBoW 모델에서는 정의에서 알 수 있듯이 단어 순서에 민감하지 않습니다. Recurrent neural network 기반의 sentence model은 단어 순서에 민감합니다.
4.2 Induced Feature Graph
DCNN에서 convolution과 pooling layer는 internal feature graph를 만듭니다.
5. Experiments
5.1 Training
Network의 top layer는 fully connected layer를 갖고 있으며 확률분포 추정을 위해 softmax non-linearity를 적용합니다.
Loss function으로 cross-entropy를 활용하며 L2 regularisation도 사용합니다.
학습에 Mini-batch, Adagrad, Fast Fourier Transform을 활용합니다.
5.2 Sentiment Prediction in Movie Reviews
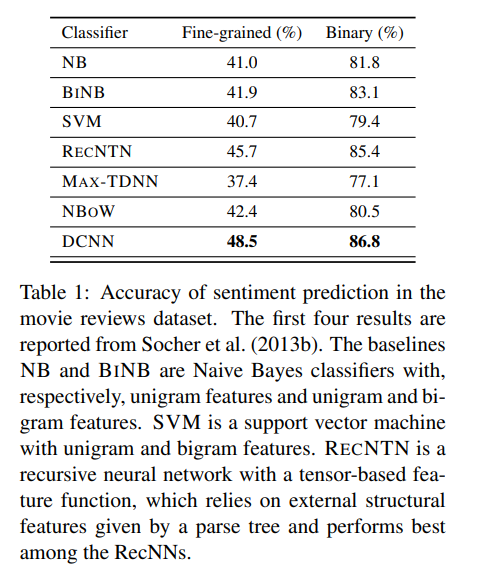
5.3 Question Type Classification
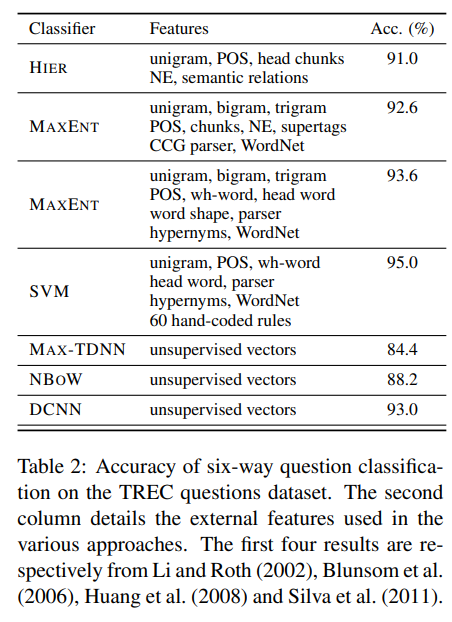
5.4 Twitter Sentiment Prediction with Distant Supervision
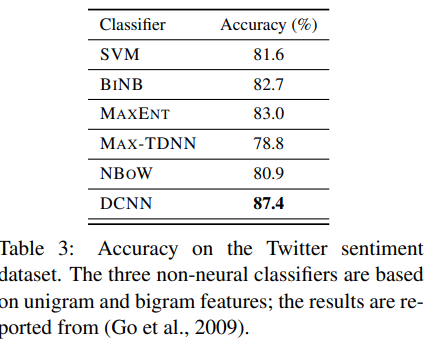
5.5 Visualising Feature Detectors

6. Conclusion
해당 논문에서는 dynamic k-max pooling을 활용한 dynamic convolutional neural network를 소개했습니다. 이를 통해 얻어지는 feature graph는 가변 크기의 단어 사이의 관계를 잡아낼 수 있습니다.
