Distilling Structured Knowledge into Embeddings for Explainable and Accurate Recommendation
Paper_review
해당 논문에서는 embedding-based recommendation model과 path-based recommendation model의 장점을 결합한 end-to-end joint learning framework를 소개합니다.
[Abstract]
학계와 산업계에서 지니고 있는 효율성과 유연성으로 인해 matrix factorization, deep model과 같은 embedding-based recommendation model들이 유명세를 얻고 있습니다. 하지만 부족한 설명력과 data sparsity 문제를 지니고 있습니다. 해당 논문에서는 path-based recommendation model에서 distilling structured knowledge를 통해 단점을 해결하는 end-to-end joint learning framework를 제안합니다.
1. Introduction
Matrix factorirization, fatorization maxchine과 같은 user와 item을 latent vector로 표현하는 embedding-based recommendation system은 많은 주목을 받기 시작했습니다. 주목을 받은 이유는 좋은 성능과 유연성 덕분이었습니다. 하지만 요즘에는 다양한 계층에서 추천이 되는 이유에 관심이 높아지고 있습니다. Black-box model에서는 추천이 되는 이유를 알 수 없었습니다. 뿐만 아니라, embedding-based model들은 data sparsity 문제와 over-fitting 문제를 지니고 있었습니다.
Meta-path로 대표되는 다른 추천 신호들을 조합하는 path-based model로 불리는 또 다른 분야도 있습니다.

Path-based model은 사람들이 이해하기 쉬운 path를 활용하고 있으며 그래프 구조의 도움을 통해 sparse data에서도 robust한 성능을 보였기에 많은 주목을 끌고 있습니다. 그럼에도 불구하고 path-based model들은 최근의 SOTA embedding-based model의 성능에는 미치지 못했습니다. 그렇기때문에 path-based model에 embedding-based 방법을 통합하려는 노력이 많아졌습니다. Path-based model에 embedding-based 방법을 단순하게 넣었을 때는 설명력과 robust한 성질에 악영향을 주었습니다.
해당 논문에서는 두 가지 방법의 장점과 단점을 보완하는 end-to-end joint learning framework를 제안합니다.
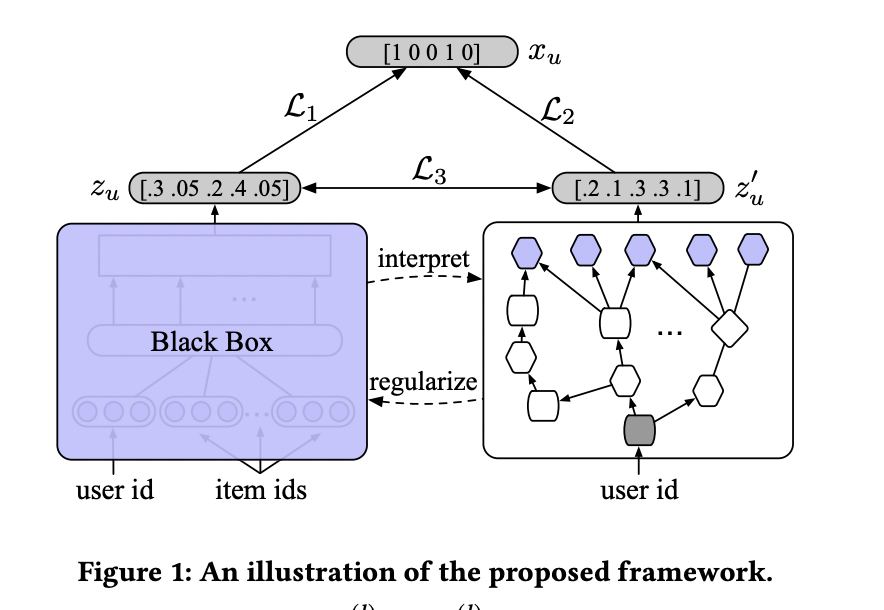
사진 1에서 볼 수 있듯이 black-box로 embedding model이 존재한 채로 또 다른 path-based model을 함께 학습합니다. Parameter를 공유하는 기존의 joint training 방법론과 달리 해당 논문의 framework에서는 objection function에 mutual regularization term을 두어 두 model을 결합시킵니다. 한 방향으로부터 embedding-based model은 path-based model에 내재된 graph-structured knowledge로 regularized되어 local minima에 빠지는 것을 막아 정확한 추천을 제공합니다. 반대 방향으로 interpretaion을 얻기 위해 path를 학습합니다.
이러한 방식은 knowledge distillation으로 볼 수 있지만 teacher와 student model이 동시에 각자를 통해 학습됩니다. 즉, student인 embedding-based model은 path-based model로부터 얻은 구조화된 knowledge를 distll 하게 됩니다. 동시에 teache인 path-based model은 embedding-based model에서 만든 예측을 합하여 knowledge의 성능을 높입니다.
2. Methodology
2.1 Problem Formulation and Preliminaries
해당 논문에서는 implicit feedback top-N recommendation task에 집중합니다. U는 user, I는 item의 set입니다. User-item interaction은 D로 표현합니다. Lu, L는 메타데이터로서 user와 item의 특징을 보여줍니다.
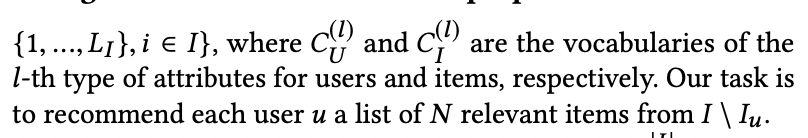
해당 논문에서는 user u가 item 클릭 여부를 0, 1로 표현합니다. Recommendation algorithm f(x)는 item과 user의 관계를 찾기 위해 확류분포 z_u를 만듭니다. x_u는 unnormalized empirical distribution으로 생각할 수 있습니다. x_u는 z_u보다 더욱 sparser합니다.

Embedding-based model 학습을 위해 cross-entropy 를 활용합니다.
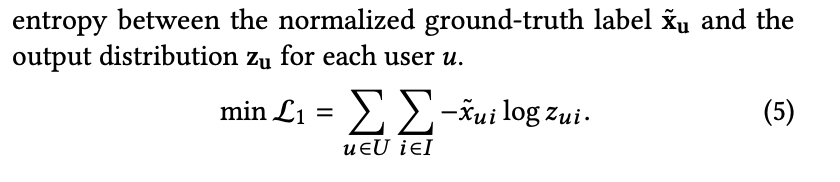
하지만 이는 2가지 이유로 문제가 있습니다. 첫째, sparse한 x_u는 관측되지 않은 모든 item들을 동일시하지만 실제로는 이러한 관측되지 않은 모든 item들이 user와 관련이 없는 것이 아닙니다. 더 심각한 문제는 over-fitting이 될 수 있다는 것입니다.
2.2 Model Framework
2.2.1 Differentiable Path-based model
Differentiable path-based model은 embedding-based model에 설명력과 structure learning에 도움을 줍니다. 기존의 방식들과 달리 해당 논문에서는 path-based model과 embedding-based model을 분리시킵니다.
논문에서는 먼저 meta data들을 서로 다른 type의 node로 표현하고 node들 간의 관계를 edge로 표현하는 heterogeneous information netword(HIN)을 만듭니다. 그 후 몇 개의 meta-path들을 정의합니다.

Meta-path에 존재하는 모든 single-step들은 서로 다른 type의 node들 사이의 transition matrix를 통해 표현할 수 있습니다.

실질적으로 transition matrix가 probability matrix가 되도록 제한을 두고 있지는 않습니다. 하지만 Relu나 softplus 등의 함수를 통해 non-negative 값을 가지는 제한을 둡니다.
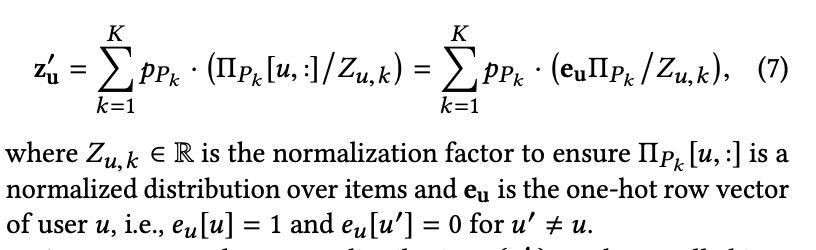
Item node를 도착지로 갖고, user node를 출발지로 갖는 meta path는 각 transition matrix들의 연산을 통해 표현됩니다.

미분가능하기 때문에 meta-path를 활용한 model 역시 gradient-based optimizers를 통해 학습할 수 있습니다.
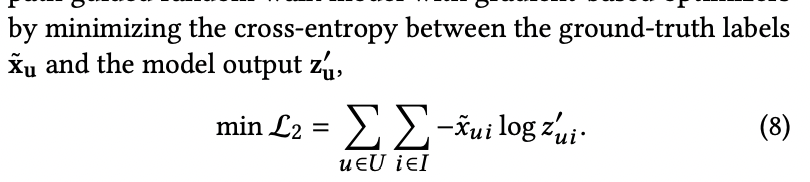
2.2.2 End-to-end Joint learning Framework
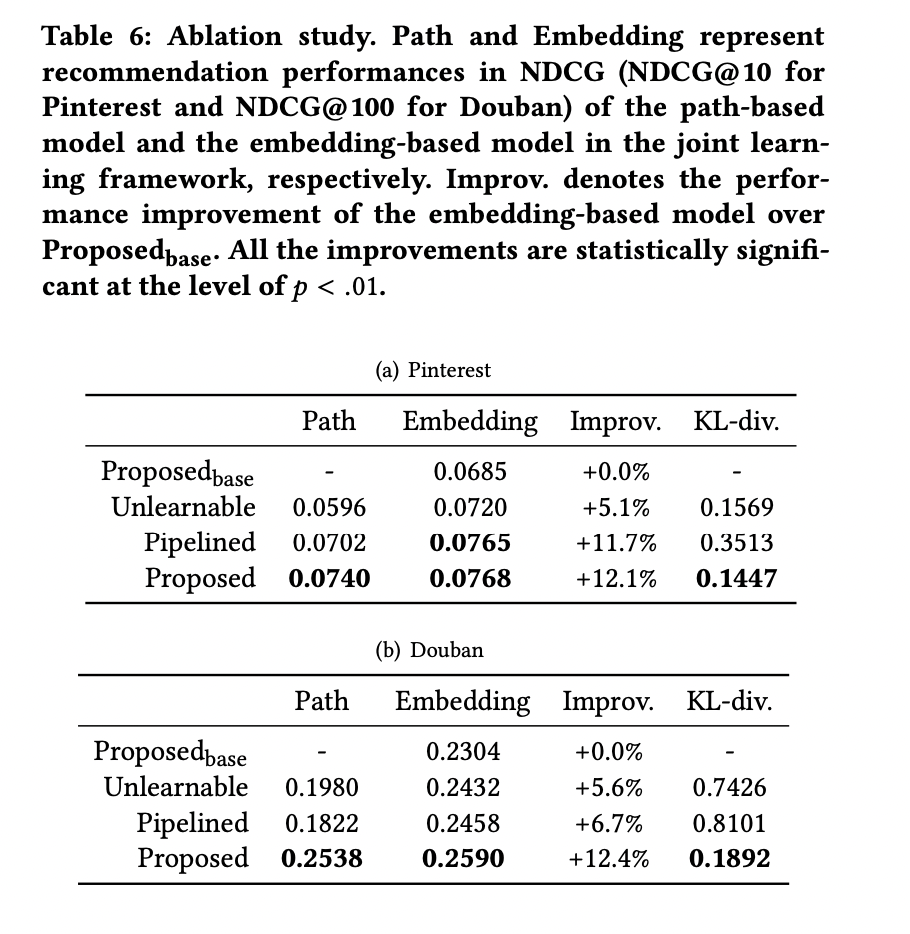
Emgedding-based model의 한계를 극복하기 위한 differential path-based model과의 end-to-end joint learning framework를 소개합니다. 각 모델의 cross-entropy를 최소화 하는 것에 더해, 두 model을 통해 얻어지는 각각의 output distribution의 KL-divergence 역시 최소화 시킵니다.
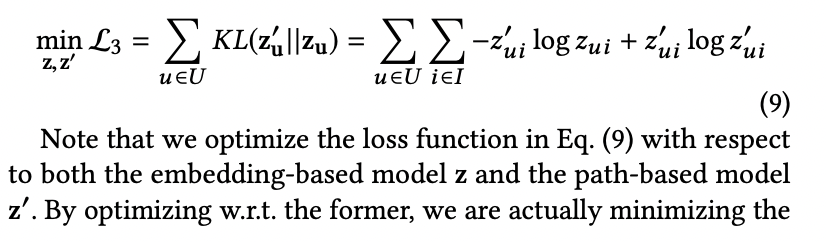
이를 통해 embedding-based model은 실제 라벨, meta-path를 통해 얻은 pseudo-label 2가지로부터 학습을 진행합니다. 또한 path-based model의 projection을 찾고자 하여 2개의 모델은 유사한 결과를 얻게됩니다. 이런 방식으로 embedding-based model의 설명력을 얻을뿐만 아니라 path-based model에서 더욱 정확한 psuedo-label을 얻게됩니다.
이러한 방식은 knowledge distillation으로 볼 수 있습니다. Differential path-based model은 teacher 역할을 합니다. Student model에게 더 많은 정보가 담긴 학습 label을 제공하기 위해 meta-path에 담긴 domain knowledge를 고도화시키기 위해 training label을 합성합니다. 그러는 동안 student인 embedding-based model은 embedding parameter에 teacher model의 knowledge를 distill합니다. 큰 차이점은 해당 논문에서는 각자의 장점을 모두 살리기 위해 한 쪽방향으로만 학습이 되는 것이 아닌 teacher model과 student model가 서로 상호학습합니다.
2.2.3 Model Training
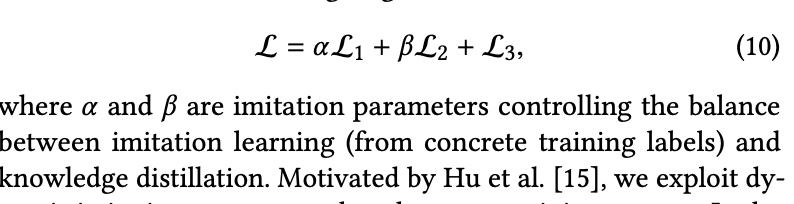
학습이 진행됨에 따라 변하는 dynamic imitation parameter를 이용합니다. 시작할 때는 상대적으로 큰 imitation parameter를 사용합니다. 학습이 진행됨에 따라 imitation parameter를 줄여 student model이 그들의 parameter에 structured knowledge를 distll할 수 있도록 합니다. 간단하게 할 수 있는 방법으로는 T_0 반복 까지는 큰 값을 사용하고 그 이후부터는 작은 값을 사용하면 됩니다. T_0 값을 정할 수 있는 가장 좋은 방법은 validation loss와 train loss가 유사해질 때입니다. 이는 곧 training label이 더이상 informative하지 않다는 것을 의미합니다.
제안하고 있는 proposed joint learning 방식은 DML(Deep Mutual Learning)과 유사한 아이디어를 공유합니다.
2.2.4 Complexity and Scalability
주된 time complexity는 path-based model에서 발생합니다.
2.3 Explainable Recommendation
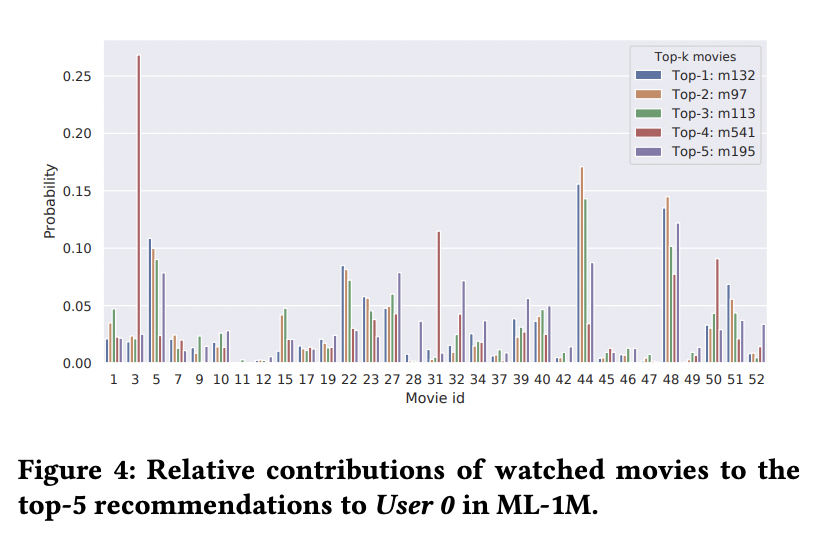
User u에게 item i가 추천되었을 때 해당 논문을 통해 각 meta-path 에서 어떤 값이 가장 크게 영향을 주었는지 알려줄 수 있습니다.

3. Experiments
3.1 Overview

3.2 Experimental Setup
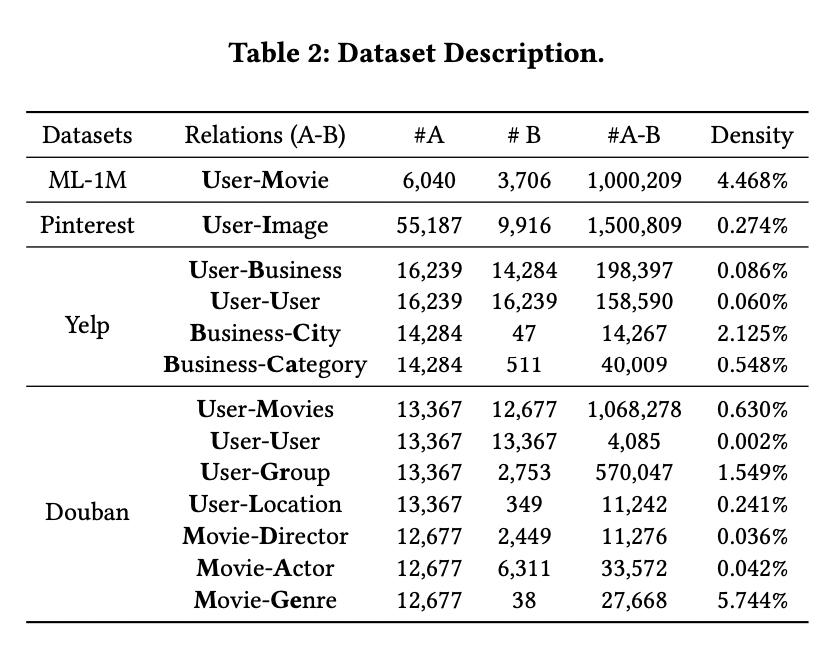
3.2.1 Datasets
- MovieLens-1M(ML-1M)
- Yelp
- Douban
3.2.2 Baseline Methods
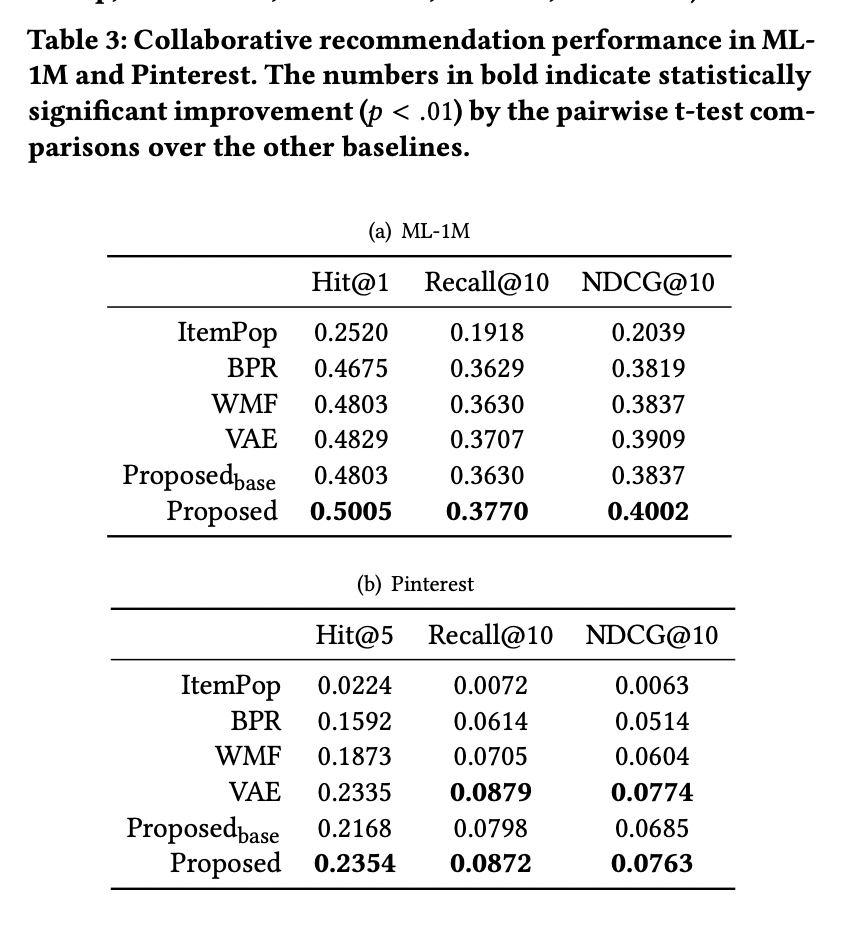
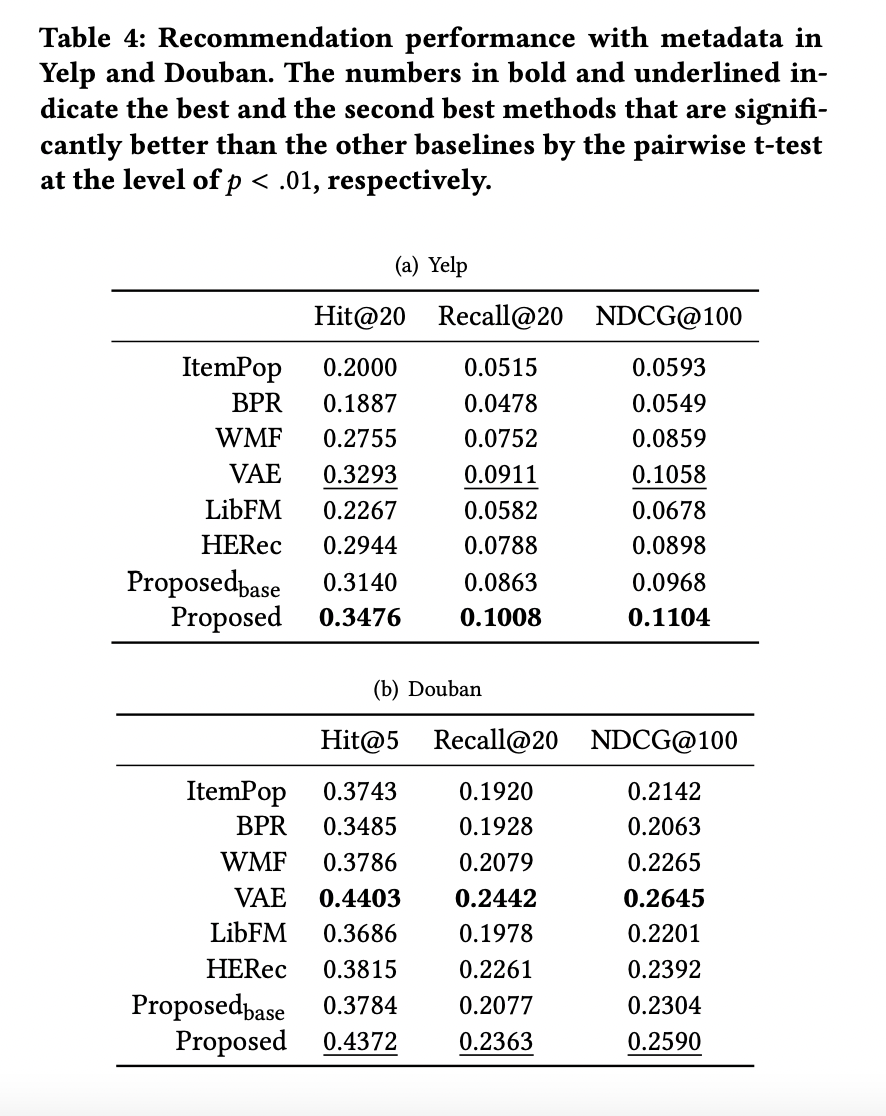
- collaborative recommendation methods : ItemPop, BPR, WMF, VAE
- hybird models : LibFM, HERec, Proposed_base
3.2.3 Evaluation Metrics

3.3 Recommendation Performance
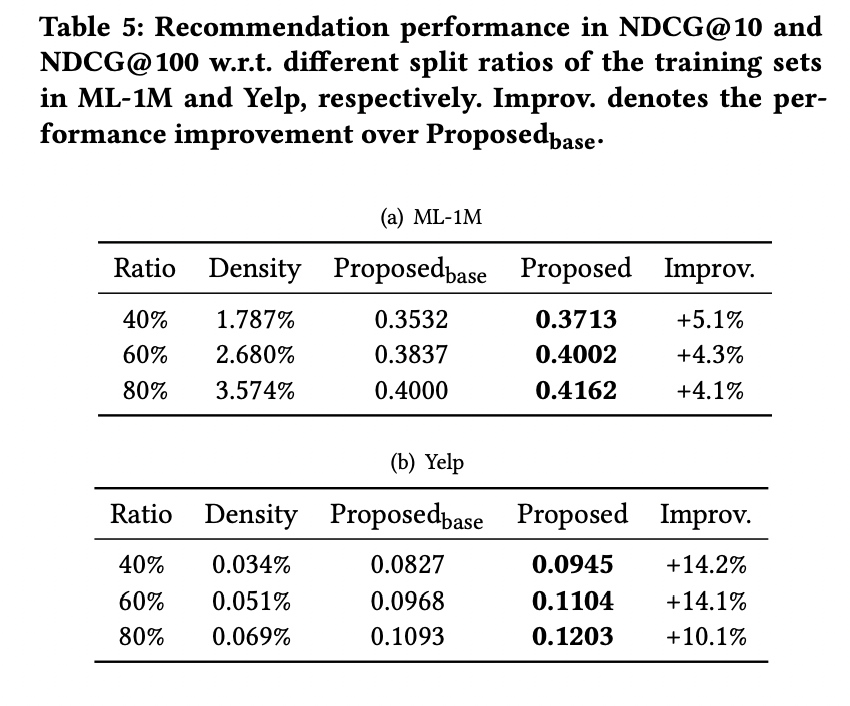
3.4 Evaluation of the Joint Learning Process
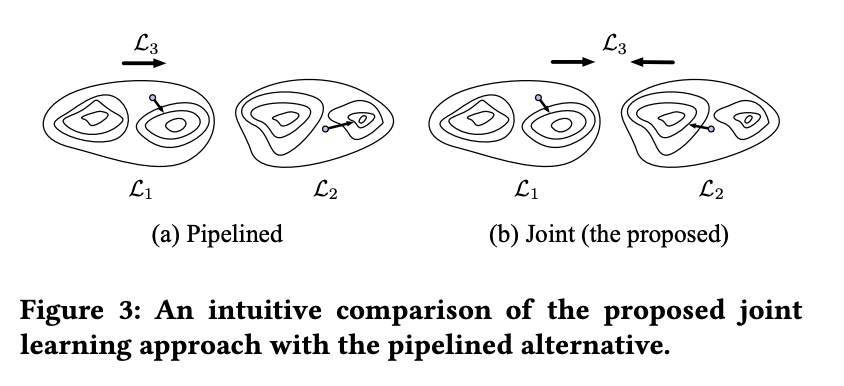
3.5 Case Study
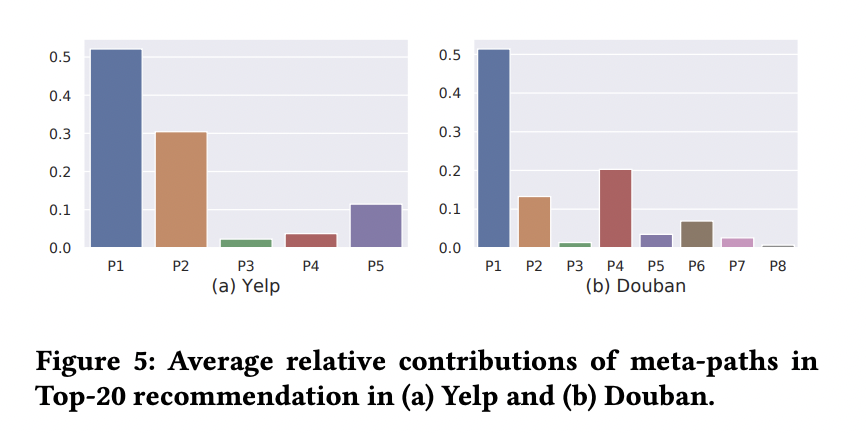

4. Related work
- Path-based Recommendation
- Interpretable Machine Learning
- Explainable Recommendation
5. Conclusion
해당 논문에서는 embedding-based recommendation model과 path-based recommendation model의 장점을 결합한 end-to-end joint learning framework를 소개합니다.
