Factorization meets the neighborhood: a multifaceted collaborative filtering model
Paper_review
Neighborhood model과 latent factor model을 통합한 model을 제안하고 이 과정에서 발전된 negihborhood model과 Asymmetic-SVD, SVD++와 같은 모델을 제안하는 논문입니다.
[Abstract]
추천시스템은 사용자에게 개인화된 제안을 통해 제품과 서비스를 제공합니다. 추천시스템은 주로 사용자와 제품간의 관계를 만들어내기 위해 과거 거래를 분석하는 Collaborating Filtering(CF)를 사용합니다. CF의 성공을 이룬 2가지 접근법은 latent factor model와 neighborhood model입니다. 해당 논문에서는 latent factor model과 neighborhood model을 통합하는 새로운 방식을 소개합니다. 사용자의 explict, implict feedback 모두를 활용하여 더 높은 정확도를 갖도록 합니다.
1. Introduction
추천 시스템은 과거 사용자의 행동(과거 거래 내역, 평점)에 의존하는 Collaborative Filtering(CF)를 기반으로 합니다. CF는 domain 지식이 필요하지 않고, 많은 양의 data 수집을 할 필요도 없습니다.
CF system은 근본적으로 다른 2개의 대상(제품 - 사용자)을 비교해야만 했습니다. Neighborhood 접근법과 latent factor model 2가지 방식은 CF의 이를 위한 주된 방식입니다.
Neighborhood 방식은 제품간 혹은 사용자 간의 관계를 계산합니다. 이러한 방식은 사용자를 제품 공간으로 이동시킵니다. 이를 통해 더 이상 사용자와 제품을 비교할 필요가 없고 단지 제품간의 비교만 이루어지면 됩니다.
SVD와 같은 latent factor model은 제품과 사용자를 동일한 latent factor space로 이동시키는 접근법을 활용하여 제품과 사용자를 직접적으로 비교할 수 있도록 해줍니다.
Neighborhood model은 지엽적인 관계를 잡아낼 때 효과적입니다. 해당 모델은 주된 neighborhood 관계에 의존하여 때떄로 사용자에 의한 평가를 무시할 때도 있습니다. Latent factor model은 일반적으로 거시적인 관계를 잡아낼 때 효과적입니다. 하지만 해당 모델은 관련 있는 제품들 간의 강력한 연관성을 찾아내기에 한계가 있습니다.
해당 논문에서는 예측 정확도를 높이기 위해 neighborhood model과 latent factor model의 장점을 이용합니다. 하나의 모델에서 두 방식을 통합하는 시도는 해당 논문이 최초입니다.
Netflix Prize 대회에서 얻을 수 있는 교훈은 다른 종류의 사용자 input을 model에 어떻게 잘 녹일 수 있느냐는 것입니다. 추천 시스템에서 가장 쉽게 활용할 수 있는 것은 양질의 explicit feedback(ex. 평점)입니다. 하지만 explicit feedback을 항상 사용가능한 것은 아닙니다. 따라서 추천 시스템은 사용자의 행동 관찰을 통해 간접적으로 의견을 반영하는 많은 양의 implicit feedback(ex. 과거 구매이력, 검색 이력, 검색 패턴 등)을 사용하여 사용자의 선호도를 추정할 수 있어야 합니다. 해당 논문의 모델은 explicit feedback과 implicit feedback을 합칩니다.
2. Preliminaries
- 사용자 : u, v
- 제품 : i, j
- r_ui : 사용자 u의 제품 i에 대한 평가, 클수록 선호도가 높음
- r_ui hat : r_ui의 추정값
Sparse data의 overfitting을 방지하기 위해 모델은 regularize를 활용합니다.
2.1 Baseline estimates
- mu : 전체 rating 평균
- b_ui : r_ui의 baseline estimate
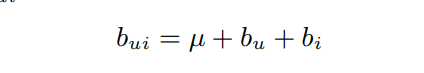
- b_u : 사용자 u의 deviation from average
- b_i : 제품 i의 deviation from average
b_u, b_i를 추정하기 위해 least squre estimator를 활용합니다.
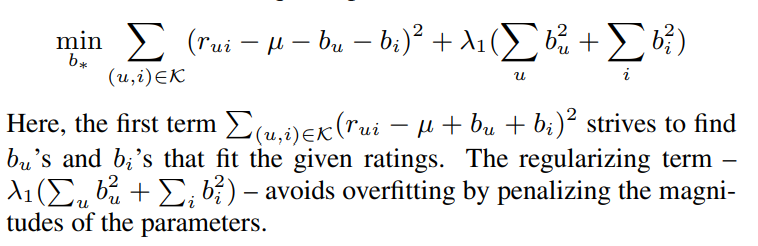
2.2 Neighborhood models
User-oriented 방법은 유사한 사용자의 평점을 통해 unknown 평점을 추정합니다. Item-oriented 방법에서는 같은 사용자가 유사한 다른 제품에 내린 평점을 기반으로 활용합니다. Item-oriented 방식을 해당 논문의 주된 관심사로 사용합니다.
Item-oriented 방식의 중심은 제품 간의 유사도를 측정하는 방식입니다. 이를 위해 주로 Pearson correlation coefficient p_ij(사용자가 i,j에 유사한 평가를 내릴 경향성)를 활용합니다. 많은 사용자가 평점을 매길 경우 유사도의 신뢰도는 더욱 높아집니다.
- s_ij : shrunk correlation coefficent
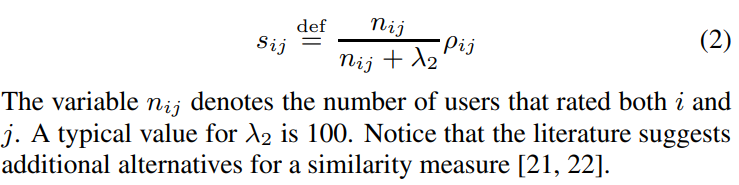
사용자 u가 제품 i에 매길 r_ui를 예측하는 것이 주된 목표입니다. 유사도 측정방식을 활용하여, 사용자 u가 평점을 매긴 제품 i와 유사한 k개의 제품을 추출합니다. r_ui의 예측값은 유사한 제품들의 평점들의 가중평균으로 구해집니다.
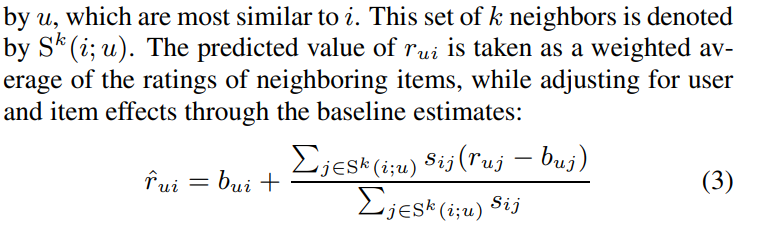
Neighborhood-based 방식은 직관적이고 쉽게 사용할 수 있기에 유명세를 얻었습니다. 하지만 formal model로 justify하기 어렵다는 단점이 있습니다. 또한 neighborhood 정보가 없을 때(ex. 사용자가 제품 i와 유사한 제품에 대한 평가를 하지 않음) 조차 가중평균에 의지할 수 밖에 없습니다.
이러한 단점을 극복하기 위해 interpolation weights를 활용합니다.

2.3 Latent factor models
Latent factor model은 관측된 평점들을 설명하는 latent feature를 발견하는 것을 전체적인 목표로합니다. 해당 논문에서는 사용자-제품 평점 matrix에 Singular Value Decomposition(SVD)를 통해 얻어지는 모델에 집중합니다. SVD 모델은 정확도와 scalability 덕분에 유명세를 얻었습니다.
- p_u : 사용자 u의 user factor vector
- q_i : 제품 i의 item factor vector
예측은 내적을 통해 이루어집니다.
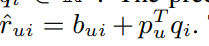
하지만 평점 결측치들이 많기 때문에 SVD를 적용하기에 어려움이 있습니다.


2.4 The Netflix data
2.5 Implicit feedback
해당 논문의 중요 목표는 explicit feedback와 implicit feedback을 통합하는 것입니다.
- R(u) : 사용자 u가 실제 평가한 모든 제품
- N(u) : 사용자 u가 implicit preference를 제공한 제품
3. A Neighborhood Model
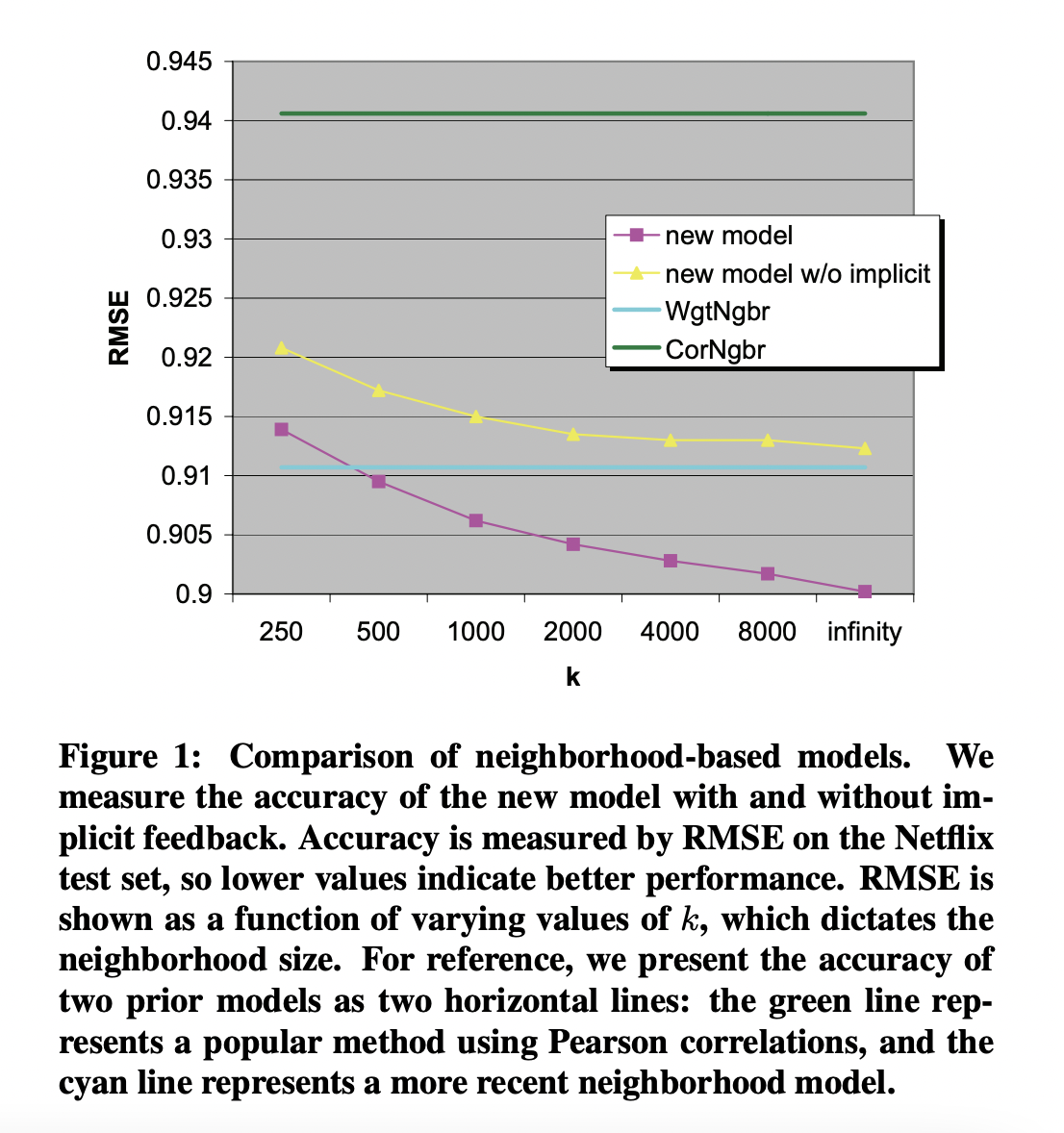
이번 섹션에서는 새로운 neighborhood model을 소개합니다. 이 모델은 정확도를 올렸을 뿐 아니라, implicit user feedback을 포함할 수 있습니다.
직전 모델들에서는 user를 기준으로 제품 i와 유사한 제품들의 관계를 활용하는 user-specific interploation weight를 중심으로 하여 모델을 전개하였습니다.
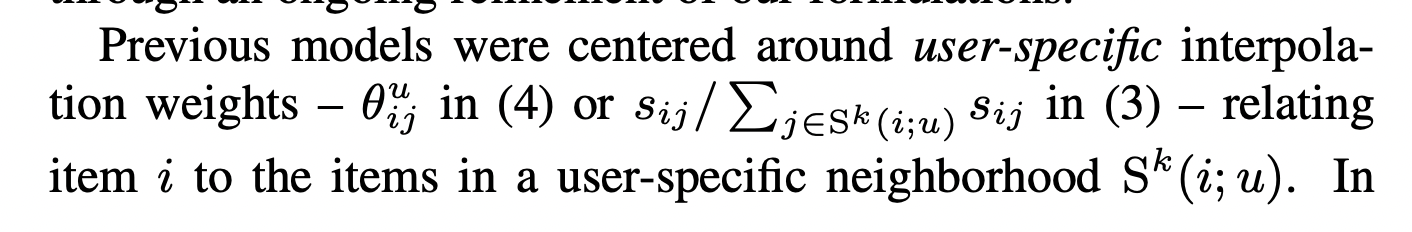
Global optimization을 활용하기 위해, user-specific weight는 사용하지 않습니다. w_ij로 표현되는 j와 i 사이의 weight는 최적화를 통해 data에서 학습됩니다.
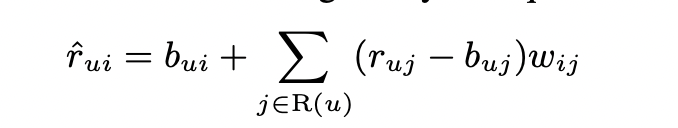
w_ij가 user specific하지 않다는 점을 제외하고는 바로 위의 식은 (4)식과 차이가 없습니다. 또한, 사용자 u와 관련있는 모든 제품들을 사용하였다는 점이 다릅니다.
일반적으로 neighborhood model에서 weight는 알지 못하는 rating과 존재하는 rating의 interpolation coeffients를 나타냅니다. 또 다른 관점에서는 weight는 baseline 추정치와의 차이를 줄이는 역할을 합니다.


Weight를 global offset의 관점으로 보게되었을 때, missing rate의 영향을 강조하게 되고 이는 곧, 사용자의 의견은 평가를 한 것뿐만 아니라, 평가를 하지 않은 것들의 영향을 받게됩니다.

b_uj는 상수이지만, b_u와 b_i는 w_ij, c_ij와 같이 학습을 통해 갱신이 되는 parameter들입니다.
현재 방식의 특징 중 하나는 많은 평가를 했거나, 다양한 implicit feedback이 존재하는 사용자들은 baseline estimator와 멀어지도록 합니다. 즉, 많은 input을 제공한 사용자들에게는 더 큰 risk를 취해 예상치 못한 독특한 추천 결과를 제공합니다. 적은 양의 input을 제공한 사용자들에게는 baseline 값 근처의 안전한 추천 결과를 제공합니다.
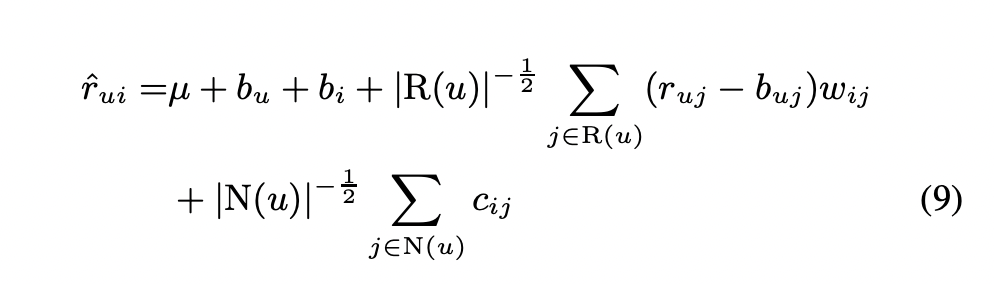
모델의 복잡도는 pruning parameter를 통해 줄어듭니다.
S^k(i)는 s_ij 유사도 지표롤 정해진 i와 유사한 k개의 제품 집합을 의미합니다.



4. Latent Factor Models Revisited

제품 i들은 3개의 factor vector q_i, x_i, y_i와 관련이 있습니다. 사용자의 explicit parameterization 대신 사용자들이 선호하는 제품을 통해 사용자를 표현합니다.
그렇기 때문에 user factor p_i는 아래 식으로 표현됩니다.
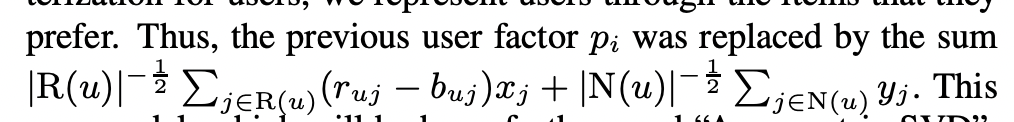
이러한 새로운 모델을 Asymmetric-SVD(user를 item으로 표현)라고 합니다.
- Fewer parameters : 일반적으로 사용자의 수는 제품을 수보다 훨씬 많습니다. 그렇기 때문에 사용자 Parameter를 제품 parameter로 변환 시 모델의 복잡도를 낮출 수 있습니다.
- New users : Asymmetric-SVD는 사용자를 parameterize하지 않기 때문에 새로운 사용자를 feedback을 제공하는 순간에 모델의 재학습이나 parameter 추정 없이 바로 다룰 수 있습니다. 하지만, 새로운 제품에 대해서는 새로운 parameter를 학습해야 합니다.
- Explainablility
- Efficient integration of implicit feedback
(13) 식의 학습을 위해 아래의 loss를 최소화 시키는 방향을 학습을 진행한다.
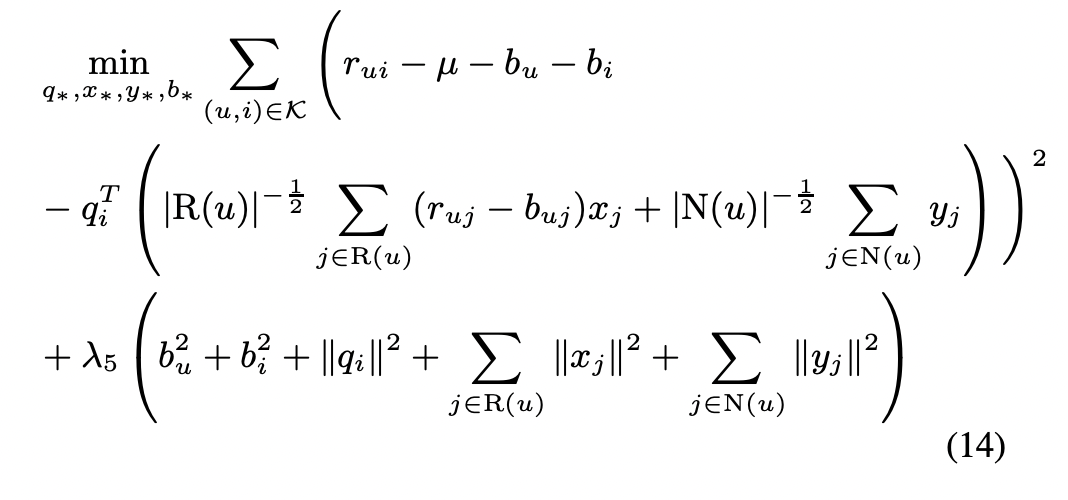
SVD++라고 불리는 모델은 아래와 같습니다.

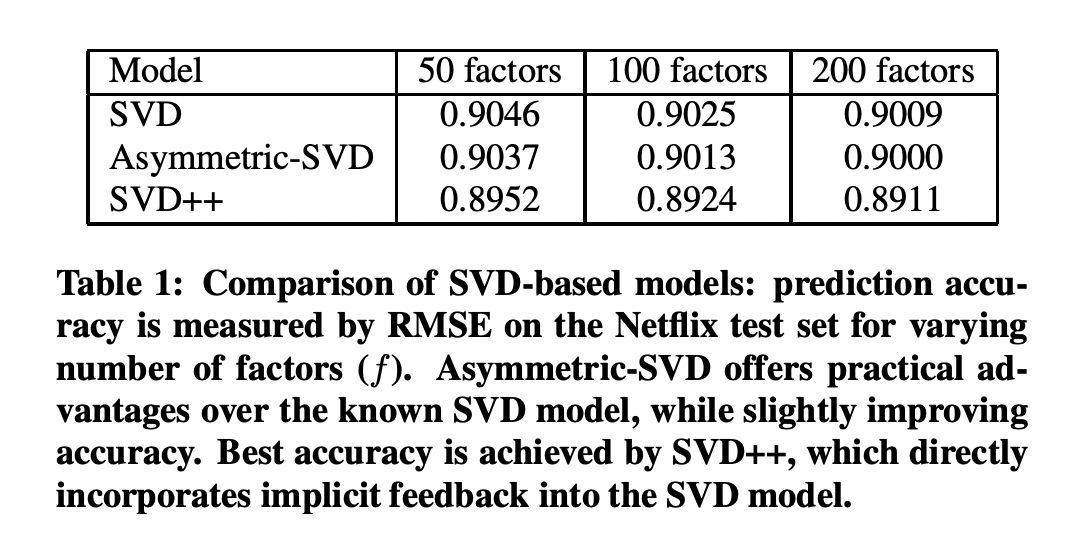
SVD++ 모델은 Asymmetric-SVD의 장점인 적은 parameter, 설명력, new-user를 처리하기 쉬움 등을 활용할 수 없습니다. SVD++에서는 사용자를 factor vector를 통해 추상화하기 때문입니다. 하지만 SVD++는 정확도 측면에서 큰 이점이 있습니다.
5. An Integrated Model
해당 섹션에서는 neighborhood model와 SVD++ model을 통합합니다.

위의 식은 3개 부분으로 나눠서 볼 수 있습니다.



SVD++와 달리 neighborhood model과 Asymmetric-SVD는 추천에 대한 직접적인 설명이 가능하고, 새로운 사용자에 대해 재학습이 필요하지 않습니다. 그렇기 때문에 정확도보다 설명력이 더욱 필요할 경우 neighborhood model에 SVD++를 통합하는 것이 아닌 Asymmetric-SVD를 통합하는 것을 고려해볼 수도 있습니다.
6. Evaluation through a Top-K Recommender
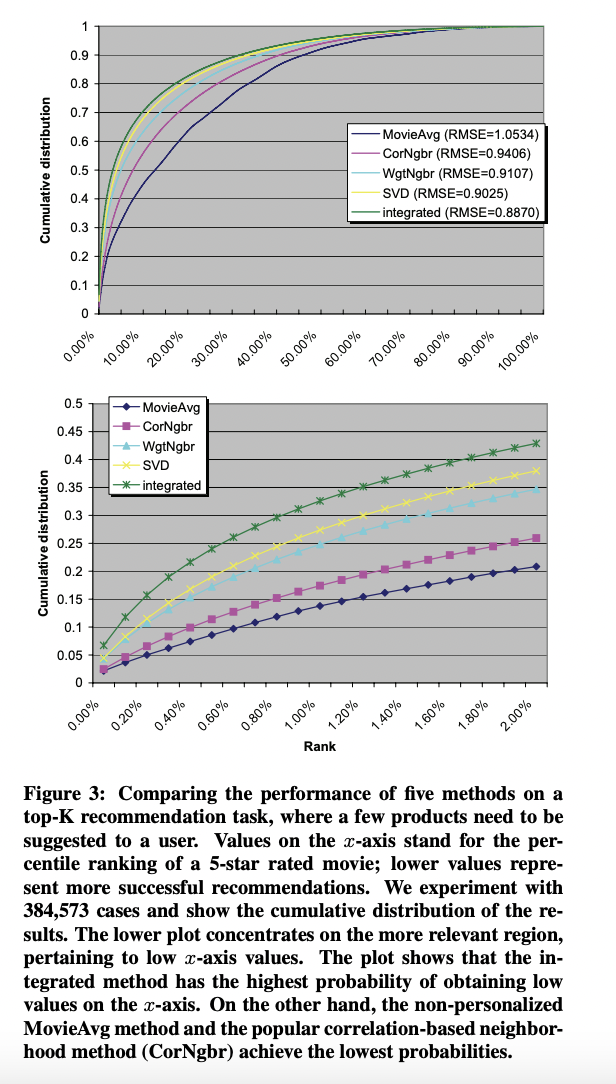
7. Discussion
해당 논문에서는 CF의 대표적인 2가지 접근법의 성능 향상 방법을 제안했습니다. 먼저 새로운 neighborhood based model을 제안했습니다. 이 모델은 예측 설명력과 재학습 없이 새로운 새용자를 다룰 수 있다는 장점을 살린 채로 예측 정확도를 향상시켰습니다. 두번째로 implicit feedback을 모델에 통합한 SVD-based latent factor model의 확장버전을 소개했습니다. Asymmetric-SVD 모델은 설명력, 재학습이 필요 없다는 neighborhood model와 유사한 장점을 공유했습니다. 여기에 더해 새로운 neighborhood model은 최초로 neghiborhood model과 latent factor model을 통합할 수 있게 해주었습니다.
또한 해당 논문에서는 top-K recommeder의 결과를 맞추는 창의적인 평가 지표를 제안하였습니다.
해당 논문을 통해서는 서로 다른 종류의 data를 성공적으로 다뤄 추천의 질을 증진시켰다는 insight을 얻을 수 있습니다.
