신경망을 활용하여 단어를 continous vector 인 feature vector로 나타내는 NPLM 논문입니다. Word embedding에 신경망을 활용하는 대표적인 초기 방법입니다.
[Abstract]
Statistical language modeling의 목표는 단어들의 sequence의 joint probability function(결합확률함수)를 학습하는 것입니다. 하지만 이는 차원의 저주(curse of dimensionality)때문에 어렵습니다. n-gram을 기반에 둔 전통적이지만 성공적인 접근법은 training set에서 볼 수 있는 짧은 overlapping sequence들을 이어붙여 일반화를 할 수 있었습니다. 차원의 저주를 극복하기위한 방법으로 해당 논문에서는 distributed represention for words를 학습하는 방법을 제안합니다. 이 방법은 학습 문장들이 model에 의미적으로 가까운 문장들이 무엇인지 알려주게 됩니다. 해당 model은 동시에 각 단어들의 distributed representation과 word sequence들의 probability 함수를 학습합니다. 일반화(generalization)는 이전에 한 번도 등장하지 않았던 단어들의 sequence들은 이미 등장했던 문장들을 구성하는 단어들과 유사한 것들로 이루어져 있다면 높은 확률을 지닐 것이기 때문에 가능합니다. 해당 논문에서는 probability function을 구하기 위해 neural networks를 사용하였습니다.
1. Introduction
차원의 저주는 language modeling과 다른 learning problem들을 어렵게 하는 원인 중 하나입니다. 차원의 저주는 많은 discrete random variable 사이의 joint distribution을 modeling 하고자 할 때 빈번히 발생합니다. 하지만 continuous variables를 modeling할 때는, 손쉽게 일반화(generalization)을 할 수 있습니다. 왜냐하면 학습하고자 하는 함수가 local smootheness properties을 가질 것이라고 생각되기 떄문입니다. Discrete space에서는 generlization sutructure는 명확하지 않습니다. Discrete variable들의 변화는 추정된 함수의 값에 큰 변화를 줄 수 있기 때문입니다. 또한, discrete variable이 큰 값을 갖는 것들이 많아지면 hamming distance에서 최대한으로 멀어질 수 있게 됩니다.
높은 차원에서 각각의 training point에서 모든 방향에대해 probability mass가 일정한것보다는 중요한 곳에서는 제대로 분배될 수 있도록하는 것이 중요합니다.
해당 논문에서 제안하는 방법은 기존의 state-of-the-art statistical language modeling이 일반화하는 방법과는 다른 일반화를 보여줍니다.
Statistical model of language는 이전의 모든 단어들이 주어졌을 때 다음 단어의 조건부 확률을 통해 표현됩니다.
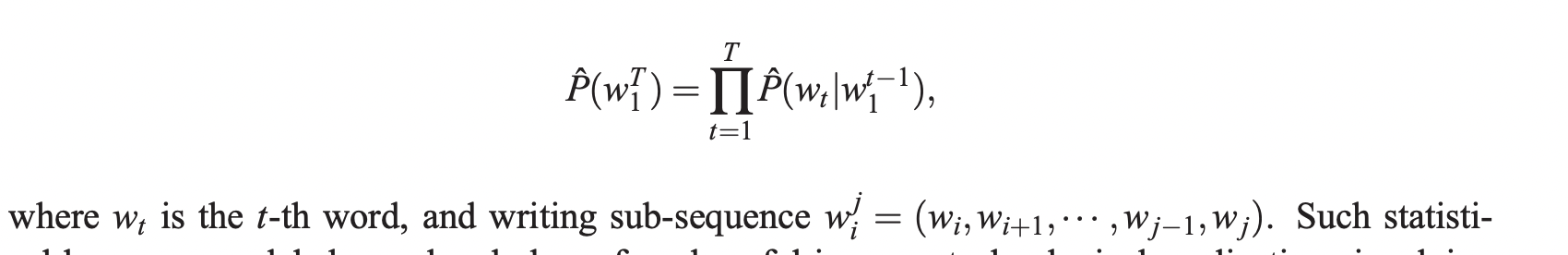
누군가는 modeling problem의 어려움을 단어의 순서를 활용하고 word sequence에서 인접한 단어들끼리는 통계적으로 more dependent 하다는 사실을 활용하여 줄일 수 있었습니다. N-gram model은 다음 단어의 조건부 확률을 직전 (n-1)개의 단어들의 조합인 contexts를 통해서 만들어 냈습니다.
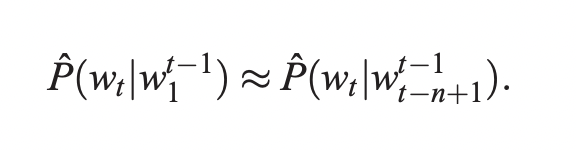
실제로 training corpus에서 등장한 적 있는 단어들의 연속적인 조합들만을 고려하게 됩니다. 만일 training corpus에서 등장한 적이 없는 조합이 등장하게되면 어떻게 될까? 해당 case에 0의 값을 갖는 확률을 부여하고 싶지는 않을 것입니다. 왜냐하면 새로운 조합은 충분히 언제든지 발생할 수 있고, larger context size에 대해서 빈번히 등장할 수 있기 때문입니다.
Back-off trigram model, smoothed trigram model들을 활용하여 문제를 해결할 수 있습니다.
본질적으로 새로운 sequence of words는 training data에서 자주 확인할 수 있는 길이가 1~n 단어들의 조각들을 통해서 만들어집니다. Next piece의 확률을 구하는 방법은 back-off나 interpolated n-gram algorithm의 특징이 함축되어 있습니다. 당연히도 예측하고자 하는 단어의 바로 직전에 등장하는 단어들의 sequence가 이전 아무때나 등장한 단어들의 조합들보다 많은 정보를 담고 있습니다.
1.1 Fighting the Curse of Dimensionality with Distributed Representations

Feature vector는 단어들의 다른 aspects를 표현합니다: 각각의 단어는 vector space의 특정 point와 관련있습니다. Probability function은 직전 단어가 주어졌을 때 다음 단어의 조건부 확률들의 곱으로써 표현됩니다. 이러한 함수는 training data의 log-likelihood를 최대화하거나 regularzied criterion을 만족하기위해 반복적으로 교정되는 parameter들을 갖습니다.
제안된 모델에서는 유사한 단어들은 유사한 feature vector를 가질 것으로 기대되기 때문에 일반화할 수 있습니다. 그리고 probability function은 이러한 feature value들의 smooth function이기 때문에 feature의 작은 변화는 확률의 작은 변화만을 일으킵니다.
1.2 Relation to Previous Work

해당 논문에서는 문장과 같이 길이가 변하는 data를 다루어야 합니다. 따라서 사진에서 제안된 방법을 사용합니다. 큰 차이는 여기서는 모든 Z_i들이 같은 종류의 object를 의미합니다. 논문에서 제안되는 모델은 parameter를 공유합니다 - same g_i is used across time
해당 논문에서 제안한 모델에서는 각 단어들 사이의 유사도를 구하기 위해 학습된 distributed feature vector인 continuous real-vector를 사용합니다. 해당 논문에서는 단어의 representation을 word sequence의 probability distribution을 compactly 표현하는 것을 돕기 위해 사용합니다.
2. A Neural Model

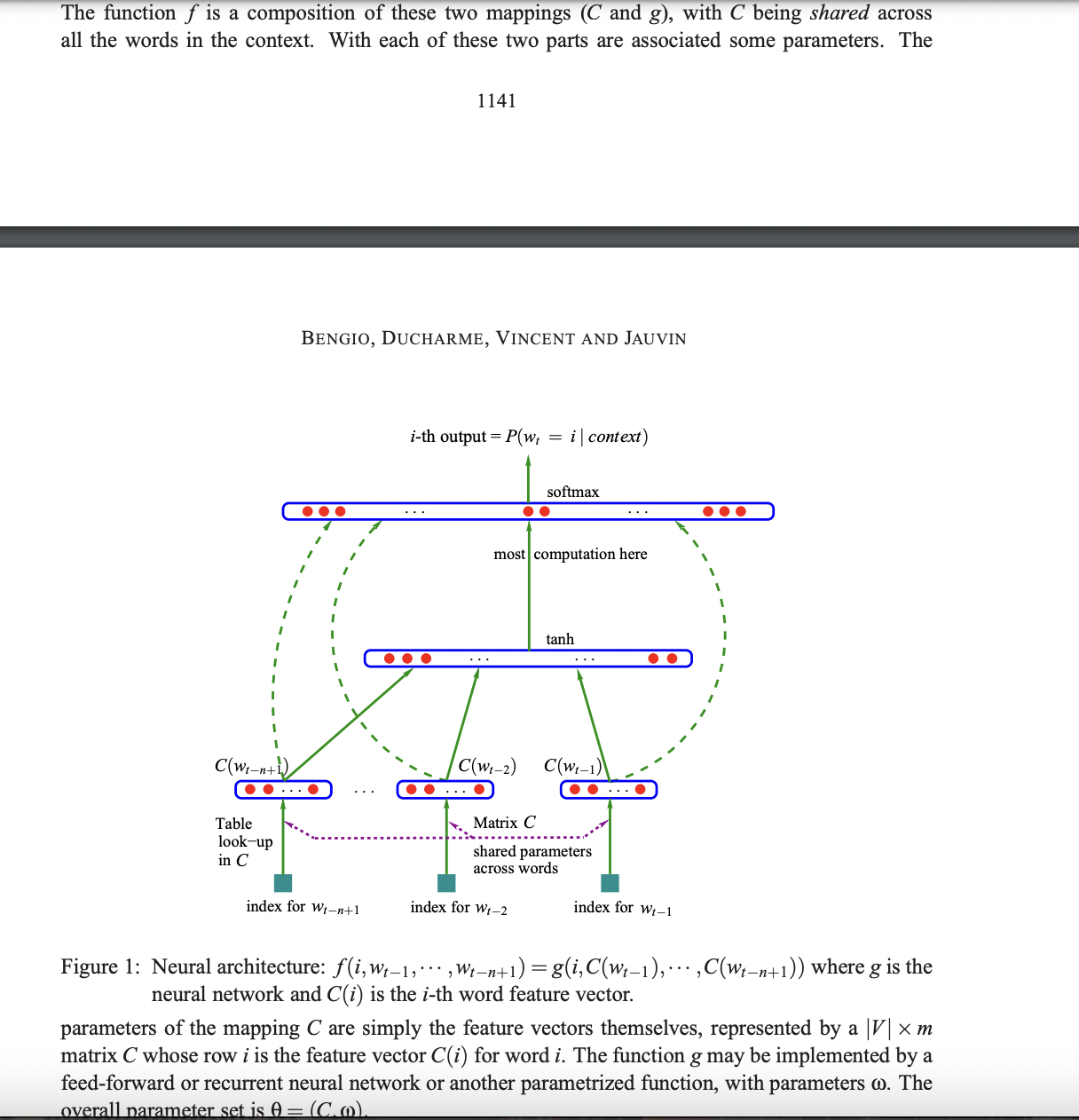
C는 feature vector를 mapping하는 역할을 한다. C 행렬의 i번째 행은 i번째 단어의 feature vector가 된다.

학습은 penalized log-likelihood를 최대화하는 theta를 찾는 방향으로 이루어집니다.
Free parameter는 오직 단어의 수인 V에 linearly하게 증가하거나 order n에 linearly하게 증가합니다.


3. Parallel Implementation
많은 계산량을 효율적으로 빠르게 하기 위한 방법을 설명합니다.
최근에는 gpu 등 pc 성능이 월등히 좋아졌기에 크게 중요치 않아 넘어갑니다.


4. Experimental Results
다양한 영어 자료들로 구성된 1,181,041 단어로 이루어진 Brown corpus를 활용하여 실험을 진행하였다. Train, Validation, Test set으로 데이터를 나누고 빈도수가 3이하인 단어들은 하나의 symbol로 통합하여 총 단어의 수를 줄였습니다.
4.1 N-Gram Models
첫 번째 benchmark는 interpolated or smoothed trigram model입니다.

주어진 식에서 alpha 값들은 EM algorithm을 사용하여 추정됩니다.
또 다른 비교 모델은 back-off n-gram models with the Modified Kneser-Ney algorithm 입니다. 이는 class-based n-gram model로도 잘 알려져 있습니다.
4.2 Results
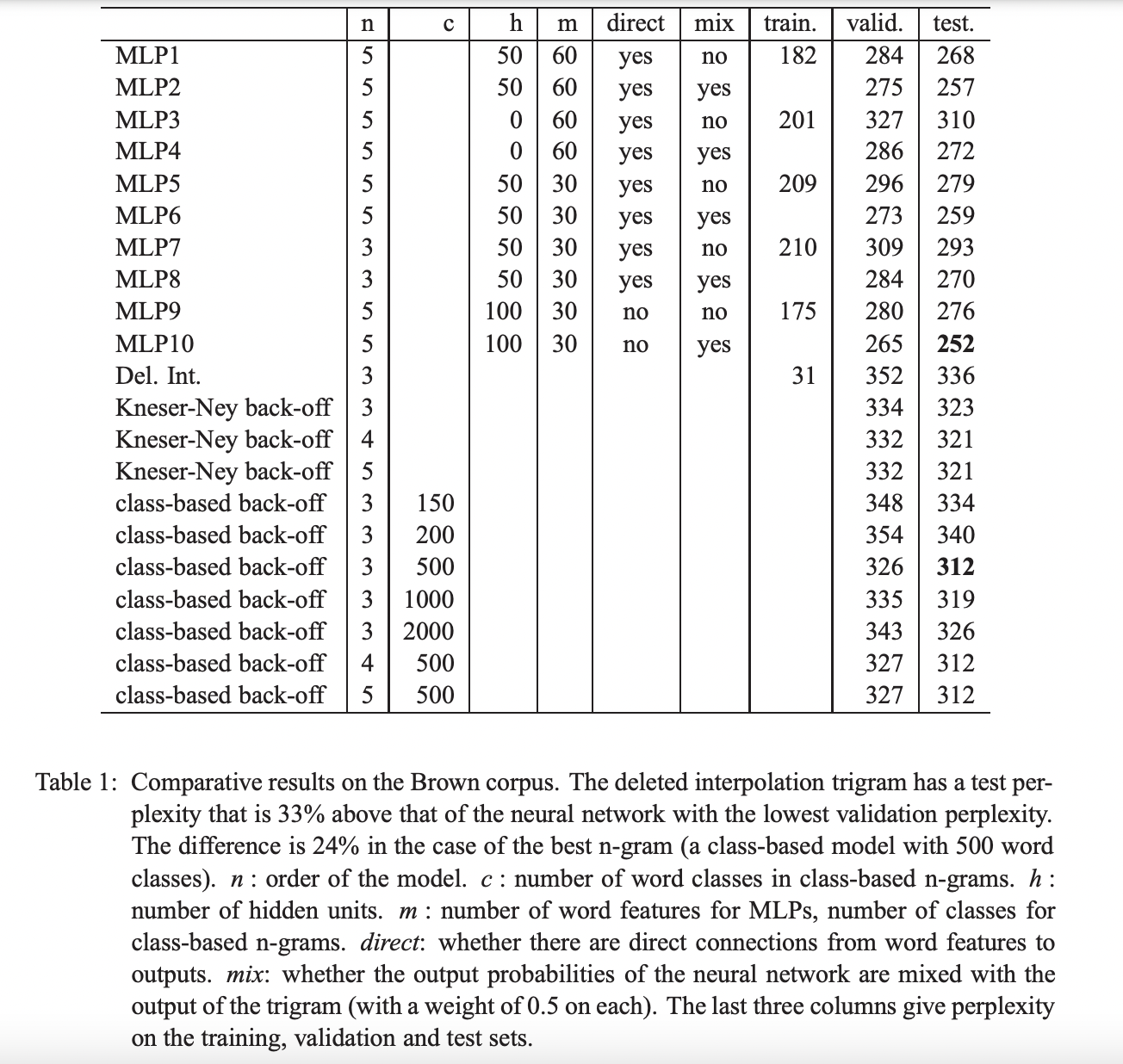

주된 결과는 neural network를 사용했을 때 n-gram과 비교했을 때보다 항상 좋은 결과를 얻을 수 있다는 점입니다. 또 다른 결과는 neural network는 더 많은 Context 정보의 이점을 얻을 수 있다는 것입니다. 또한 hidden units는 유용했으며 neural network의 output 확률을 interpolated trigram과 합쳤을 때 더 좋은 성능을 보였습니다.
5. Extensions and Future Work
5.1 An Energy Minimization Network
Neural network의 변형 중 하나는 Hinton이 제안한 energy mininization model로 해석될 수 있습니다. Neural network에서 distributed word feature는 input에만 사용되지 output에는 사용되지 않습니다. 더 나아가 많은 수의 parameter들은 output layer로 확장됩니다. 여기서 설명하는 변형에서는 output도 feature vector로 표현됩니다.
network는 feature vectorfh 표현된 단어들의 sub-sequence를 input으로 삼고 likely sub-sequence에서 나온 단어일 때는 낮은 값을 갖고, 그렇지 않을 때는 높은 값을 갖는 energy function E를 output으로 갖습니다.

Out-of-vocabulary-words
제안된 architecture가 갖는 장점 중 하나는 out-of-vocabulary words를 다룰 수 있다는 점이고 심지어 확률까지 구할 수 있습니다.
5.2 Other Future Work
- Decomposing the network in sub-networks
- Representing the conditional probability with a tree structure where a neural network is applied at each node, and each node represents the probability of a word class given the context and the leaves represent the probability of words given the context
- Propagating gradients only from a subset of the ouput words
- Introduction a-priori knowledge. The effect of longer term context could be captured by introducing more structure and parameter sharing in the neural network
- Interpreting the word feature representation learned by the neural network
- Polysemous words
6. Conclusion
논문에서 제안된 방법은 기존의 SOTA들보다 더 좋은 결과를 보였습니다.
제안한 방식이 learned distributed representation을 활용해서 차원의 저주를 해결했기 때문에 성능의 향상이 있었다고 생각합니다.
해당 논문은 tables of conditional probabilities을 많은 conditioning 변수를 사용하는 distributed representation을 바탕으로 더욱 compact하고 smooth한 representation으로 대체하여 statistical language model의 발전할 수 있는 발판을 마련하였습니다.
