초기 Word Embedding 방법 중 하나인 Word2Vec을 소개하는 논문입니다. CBOW와 Skip-gram을 소개하고 각 모델의 성능을 기존의 모델들과 비교합니다.
[Abstract]
논문에서는 매우 큰 data set에서 나온 단어들의 continuous vector representation을 계산하는 새로운 2가지 model architecture를 소개합니다. Representation은 word similarity task를 통해 quality가 측정됩니다. 새로운 방식은 기존의 다른 방식들과 비교하였을 때 높은 정확도 향상과 낮은 계산 비용을 보였습니다.
1. Introduction
최근 많은 NLP system과 기술에서 단어를 atomic units으로 다룹니다 - 단어 사이에는 유사도 개념이 없다고 생각합니다. 이러한 방식은 simplicity, robustness와 같은 이유를 들어 합리적이라고 여겨졌습니다. 대표적인 방식이 statistical language modeling에서 사용되는 N-gram model입니다.
Machine learning 기술이 발전해감에따라 많은 data set에 대해 복잡한 모델을 학습시킬 수 있게되었고 simple model의 성능을 넘어서게 되었습니다. 가장 성공적인 방법은 단어의 distributed representation을 사용하는 것입니다. 예를 들어, language model을 기반으로 한 neural network는 N-gram model의 성능을 넘어섰습니다.
1.1 Goals of the Paper
논문의 주된 목표는 사전에 있는 사전에 있는 수백만개의 단어들이 수십억개 포함되어 있는 거대한 data set으로부터 high-quality word vector를 학습하는데 활용할 수 있는 방법을 소개하는 것입니다. 이전에 제시된 방법들로는 수천만개의 단어들을 50-100차원의 word vector로 학습하는 것이 불가능했습니다.
논문에서는 resulting vector representation의 quality를 유사한 단어는 서로 가까울 뿐만 아니라 multiple degrees of similarity를 가질 것이라는 기대를 바탕으로 측정합니다.
놀랍게도 word representation의 유사도는 단순한 문법론적인 제약을 넘어섭니다. 단순한 사칙연산을 word vector에 사용하여 vector("King") - vector("Man") + vector("Woman")의 결과 vector가 "Queen" 단어의 vector와 가장 근접하다는 것을 보였습니다.
해당 논문은 단어들 사이의 linear regularity를 유지할 수 있는 새로운 model architecture를 만들어 vector operation의 정확도를 최대화하는 것을 목표로 했습니다. 논문에서는 syntactic과 semantic regularity를 모두 측정할 수 있는 방법을 고안하였고 높은 정확도로 그러한 regularity가 학습되는 것을 보였습니다.
1.2 Previous Work
단어를 continuous vector로 표현하는 것은 역사가 깊습니다. Neural network language model(NNLM)을 estimate하는 대표적인 모델이 제안되기도 했었습니다. 해당 모델은 feedforward neural network로써 linear projection layer와 non-linear hidden layer가 word vector representation을 학습하기 위해 사용되었습니다.
단어 vector가 하나의 hidden layer를 사용하여 학습되는 NNLM의 또 다른 architecture가 소개되기도 하였습니다.
Word vector는 다양한 NLP분야를 눈에 띄게 발전시키고 단순화 시키는데 활용되었습니다. 하지만 이러한 architecture들은 계산 비용이 너무 많았습니다.
2. Model Architectures
다양한 type의 모델들이 continuous representing of words를 추정하기 위해 제안되었습니다. 대표적인 예시로 Latent Semantic Analysis(LSA), Latent Dirichlet Allocation(LDA) 등이 있습니다. 논문에서는 neural network로 학습되는 distributed representation of word에 초점을 맞추고 있습니다. neural network로 학습된 결과가 LSA에 비해 단어들 사이의 linear regularity를 보존하면서 좋은 성능을 보였기 때문입니다.
Model architecture들의 비교를 위해 모델의 computational complex를 모델이 full train될때 필요한 parameter의 수로 정의합니다. 그 후 computational complexity를 줄이는 동시에 accuracy를 최대화합니다.

2.1 Feedforward Neural Net Language Model(NNLM)
Probabilistic feedforward neural network language model이 제안되었다. 해당 모델은 input, projection, hidden, ouput layer를 포함한다. Input layer에서는 N개의 previous word들이 사전의 크기인 V 차원의 벡터(1 of V coding)으로 encode된다. Input layer는 projection layer P로 project되며 P는 N x D 행렬로 모든 input에 대해 공유됩니다.
NNLM architecture는 projection layer의 값들이 dense 하기 때문에 projection과 hidden layer 사이의 계산에서 복잡도가 올라갑니다. Hidden layer는 사전의 모든 단어에 대해 probability distribution을 계산하기 위해 사용되며 결과적으로 V차원의 output layer를 갖습니다.
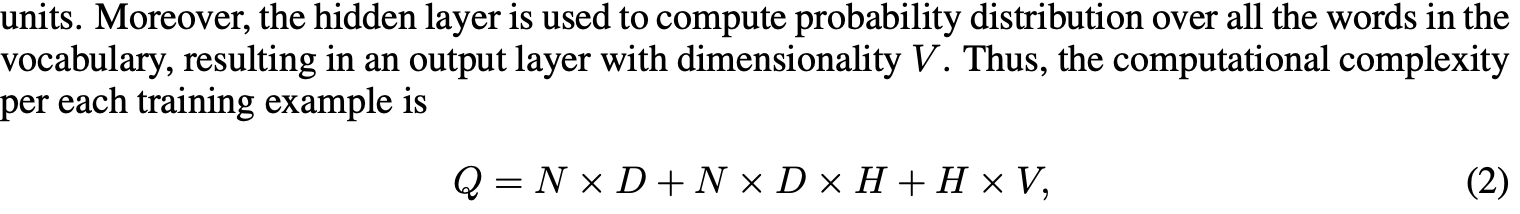
H x V를 피하기 위해 hierarchical version of softmax를 활용하거나 normalized model을 피하는 모델이 제안되었습니다.
논문에서 사용한 모델은 hierarchical softmax를 활용하고 vocabulary는 Huffman binary tree로 표현되어 있습니다.
2.2 Recurrent Neural Net Language Model(RNNLM)
Recurrent neural network based language model은 feedforward NNLM의 단점(the need to specify the context length(the order of the model N))을 극복하기 위해 제안되었습니다. 또한 이론적으로 RNN은 복잡한 패턴을 더욱 효과적으로 표현할 수 있었습니다. RNN model은 projection layer 없이 input, hidden, output layer로만 구성되어 있습니다.

2.3 Parallel Training of Neural Networks

3. New Log-linear Models
논문에서는 computational complexity를 최소화하며 단어의 distributed representation을 학습할 수 있는 2가지 새로운 model architecture를 제안합니다. 앞선 내용에서 알 수 있듯이 model의 non-linear hidden layer가 model complexity의 대부분을 차지합니다. non-linear layer는 neural network를 매력적으로 만들어주지만 논문에서는 data를 neural network만큼 정밀하게 표현하는 것이 가능하지는 않더라도 data를 효율적으로 학습할 수 있는 단순한 모델을 제안합니다.
Neural network language model은 2단계로 학습됩니다.
- 단순한 모델을 사용하여 continuous word vector를 학습한다.
- N-gram NNLM이 단어의 distributed represention의 가장 위에서 학습된다.
3.1 Continuous Bag-of-Words Model
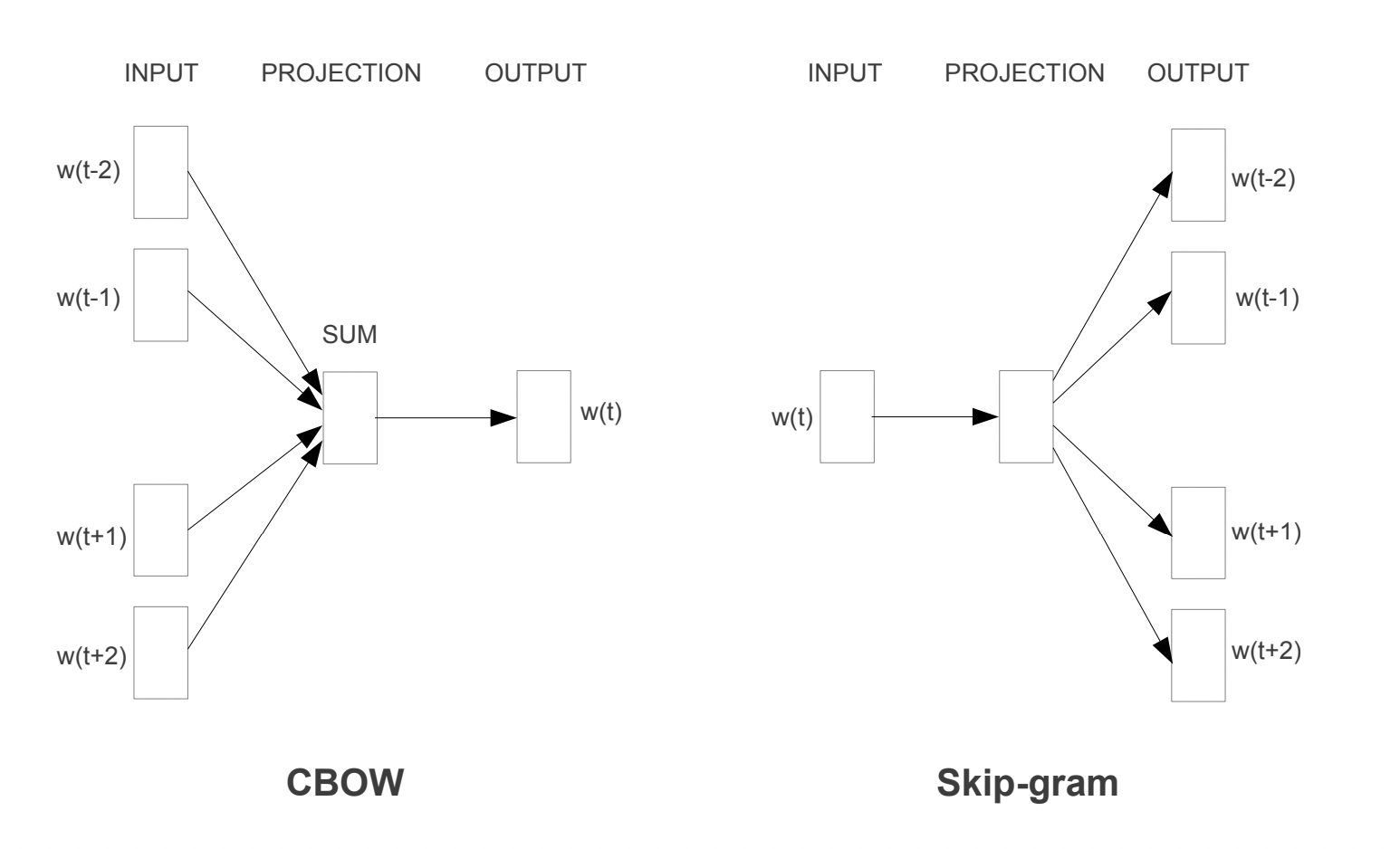
새로운 모형 중 하나는 feedforward NNLM과 유사하지만 non-linear hidden layer가 제거되고 projection layer를 모든 단어들에의해 공유됩니다. 따라서 모든 단어들은 same position에 projected됩니다.(their vectors are averaged) 이 모델은 단어의 순서가 projection에 영향을 미치지 않기 때문에 Bag-of-words model이라고 합니다. 더 나아가 뒤에 등장하는 단어를 활용합니다.

이러한 모델을 CBOW라고 하며 standard bag-of-words model과는 다르게 CBOW는 문맥의 continuous distributed representation을 사용합니다. Input과 projection layer 사이의 weight matrix는 all word position에서 공유되어 사용됩니다.
3.2 Continuous Skip-gram Model
또 다른 모형은 CBOW와 유사하지만 문맥을 통해 현재 단어를 예측하는 대신, 동일한 문장 내에서 다른 단어들을 바탕으로 단어의 classification을 최대화하는 것을 목표로 합니다. 자세하게는 current word를 continuous projection layer를 가진 log-linear classifier의 input으로 사용하며 current word 앞, 뒤에 있는 단어를 예측합니다. 예측 범위를 늘리면 word vector의 quality가 증가하지만 computational complexity 또한 늘어나게 됩니다. 가까이 있는 단어보다 멀리 있는 단어는 현재 단어와 관계가 적기 때문에 멀리 떨어진 단어는 samplig이 덜 될 수 있도록 낮은 가중치를 부여합니다.
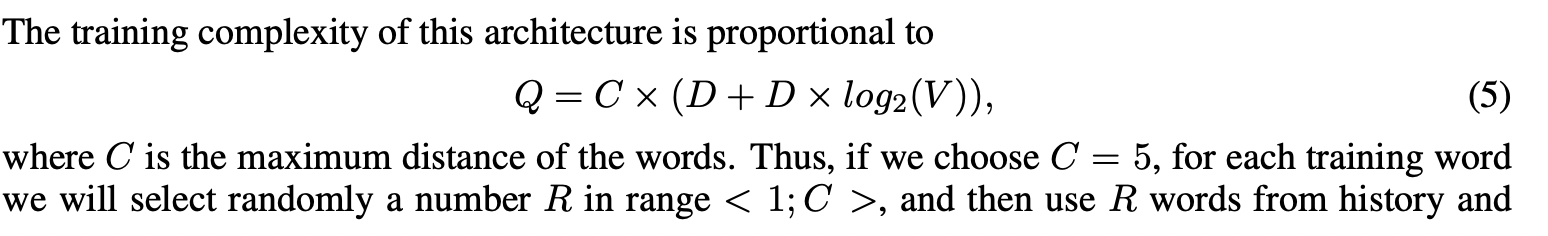
4. Results
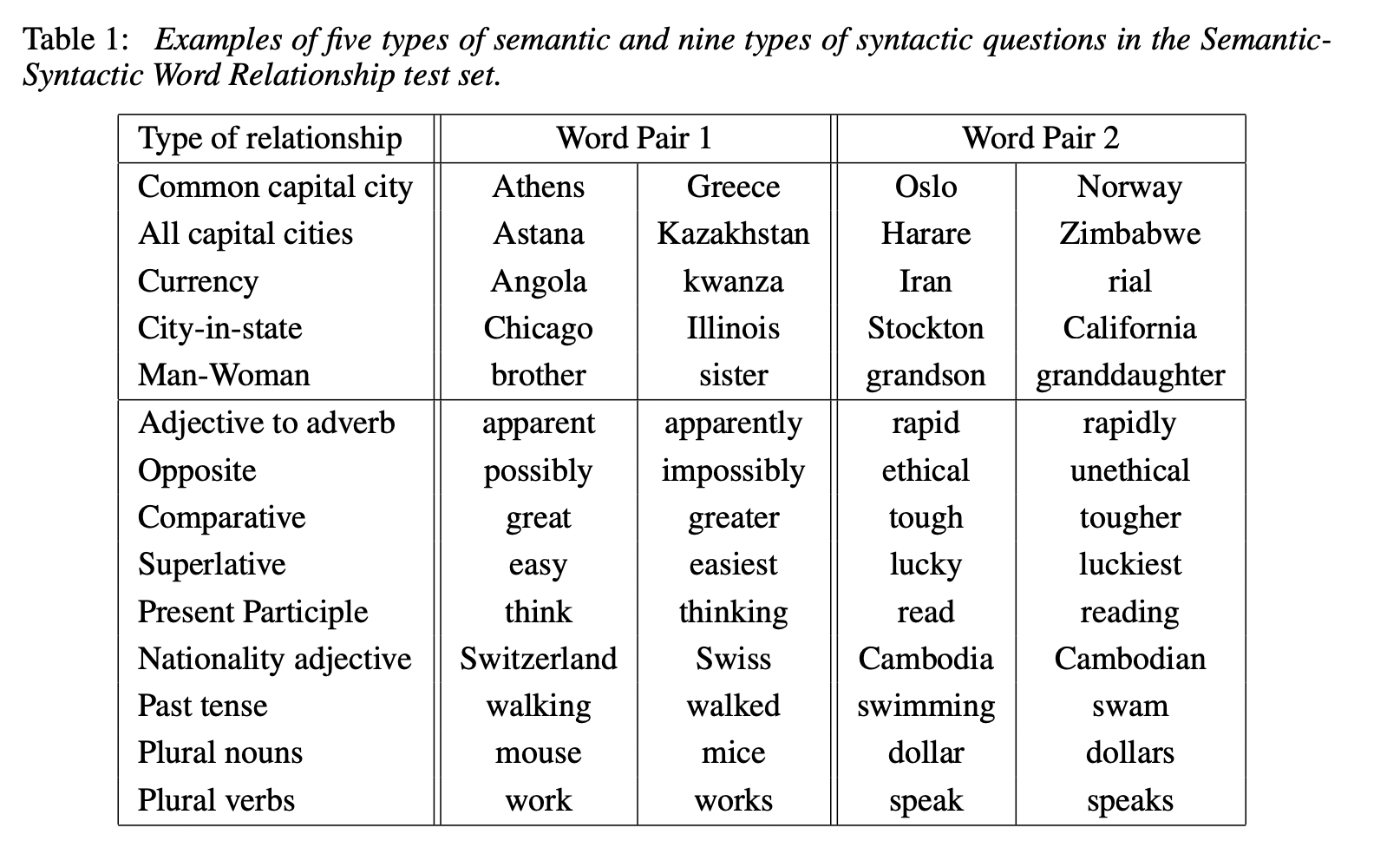
단어 사이에는 다양한 종류의 similarity가 있습니다. 예를 들어, small이 smaller와 유사한 것처럼 big과 bigger는 유사합니다. 이러한 관계는 big-biggest와 small-smallest 쌍은 또 다른 예시가 될 수 있습니다. 논문에서는 "What is the word that is simliar to small in the same sense as biggest is similar to big?" 의 질문에 대한 답을 찾습니다.
위의 질문은 단어의 vector representation 간의 사칙연산을 통해 답을 할 수 있습니다. biggest와 big이 유사한 방식을 small에 적용하였을 때 얻을 수 있는 단어를 찾기 위해 vector X = vector("biggest") - vector("big") + vector("small")을 계산할 수 있습니다. 계산된 X와 코사인 유사도를 활용하여 가장 가까운 단어 vector를 찾고 해당 vector를 질문의 답으로 사용할 수 있습니다.
많은 양의 data에서 높은 차원의 word vector를 학습하게 되면 결과로 구한 vector는 단어들 사이의 subtle semantic relation을 답하는 데 사용할 수 있습니다. 단어 vector들의 semantic 관계는 다양한 NLP 분야의 발전에 도움을 줄 수 있습니다.
4.1 Task Description
4.2 Maximization of Accuracy
더 많은 data와 높은 차원의 단어 vector를 사용하게되면 정확도가 증가하게 된다는 기대를 하기 때문에 time constrained optimization problem에 직면하게됩니다.
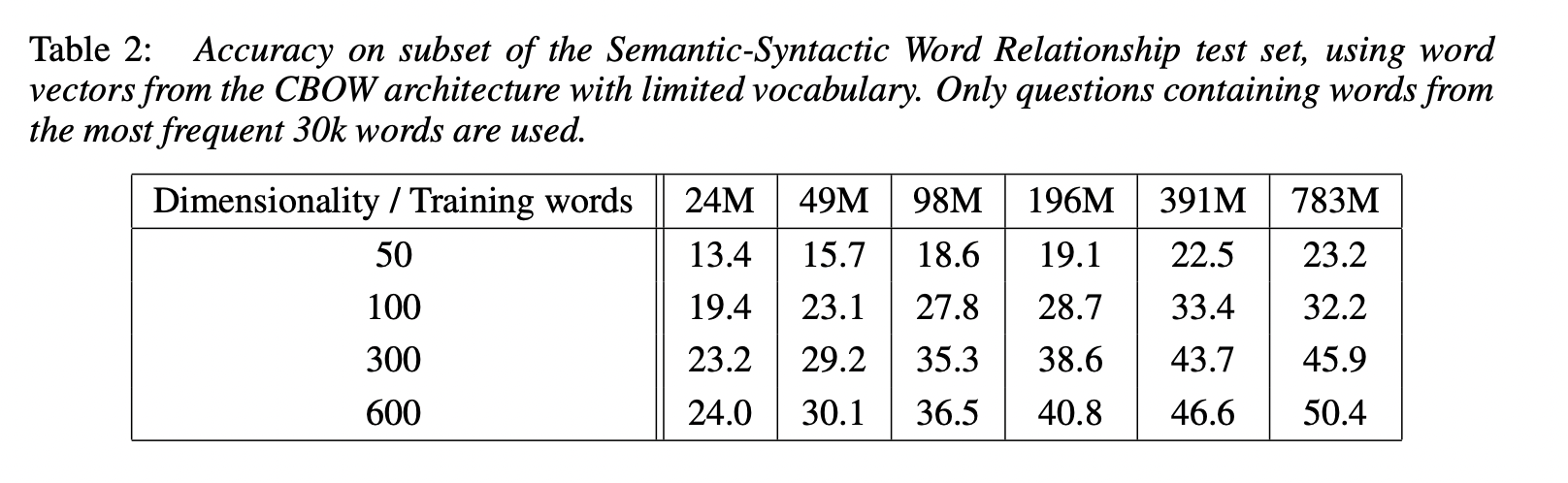
높은 차원을 추가하거나 더 많은 데이터를 사용하게되면 성능의 증가가 점차 감소합니다. 따라서 vector의 차원과 학습데이터의 양을 동시에 늘려야합니다.
4.3 Comparison of Model Architectures
서로 다른 model architecture들 비교를 위해서 같은 학습 data와 같은 word vector의 차원을 사용하였습니다.
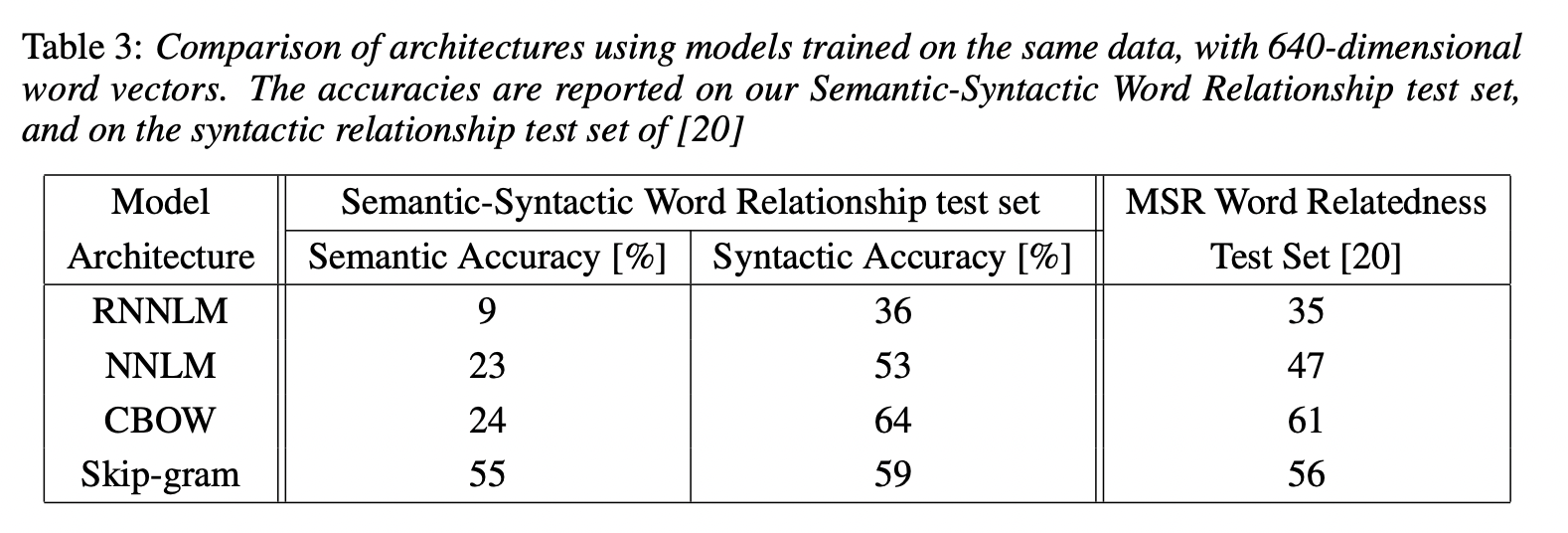
Syntactic question에서 RNN으로 만들어진 word vector의 성능이 좋은 것을 확인할 수 있습니다. NNLM vector는 RNN vector보다 성능이 좋았습니다. - RNNLM은 non-linear hidden layer로 연결되어 있기 때문에 이것은 놀라운 결과가 아닙니다. CBOW는 NNLM보다 syntactic task에서 좋은 결과를 보였고 semantic task도 마찬가지였습니다. Skip-gram은 syntactic task에서는 CBOW보다는 성능이 좋지 못하지만 sematic task에서는 성능이 좋았습니다.
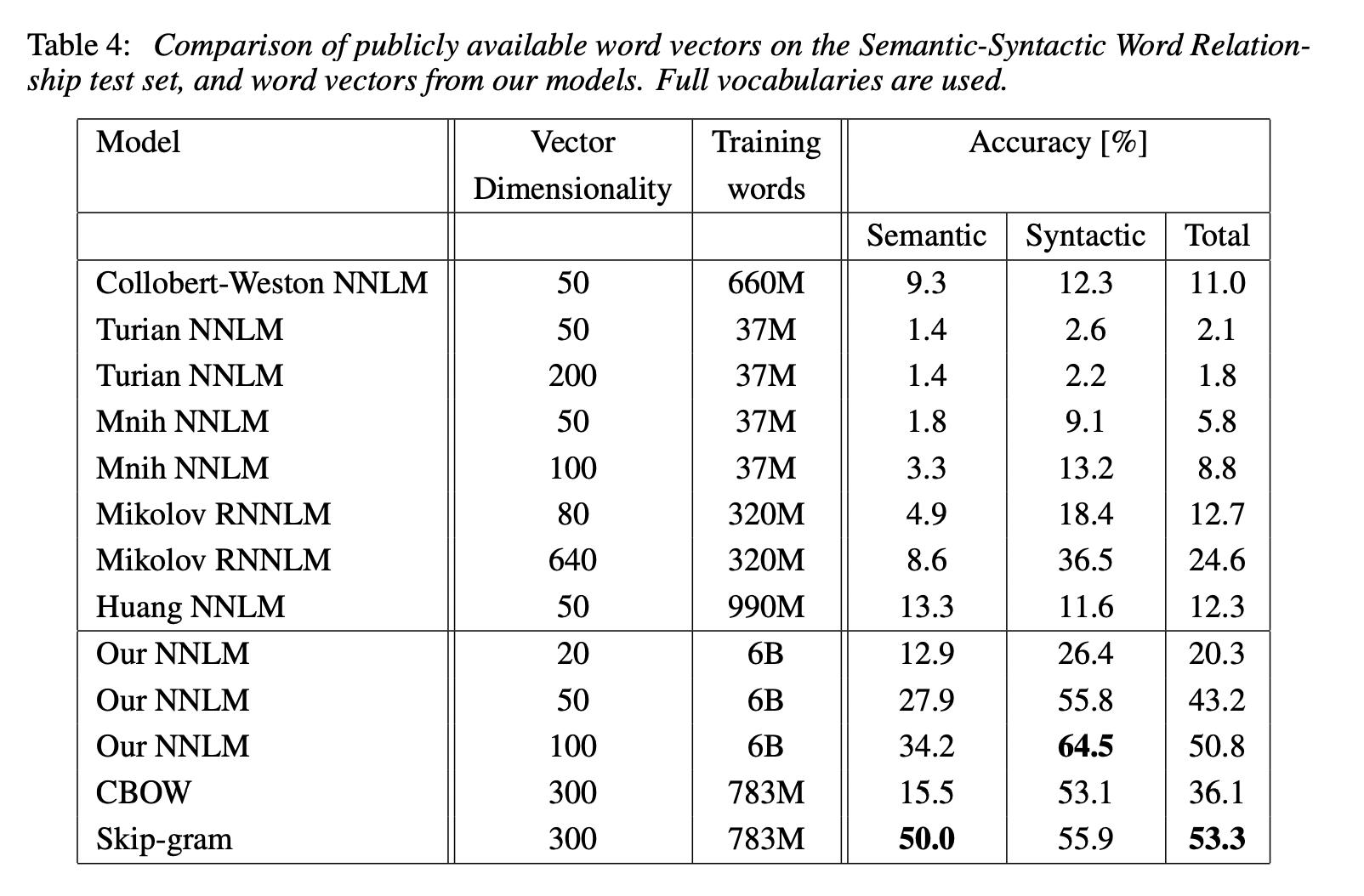
4.4 Large Scale Parallel Training of Models
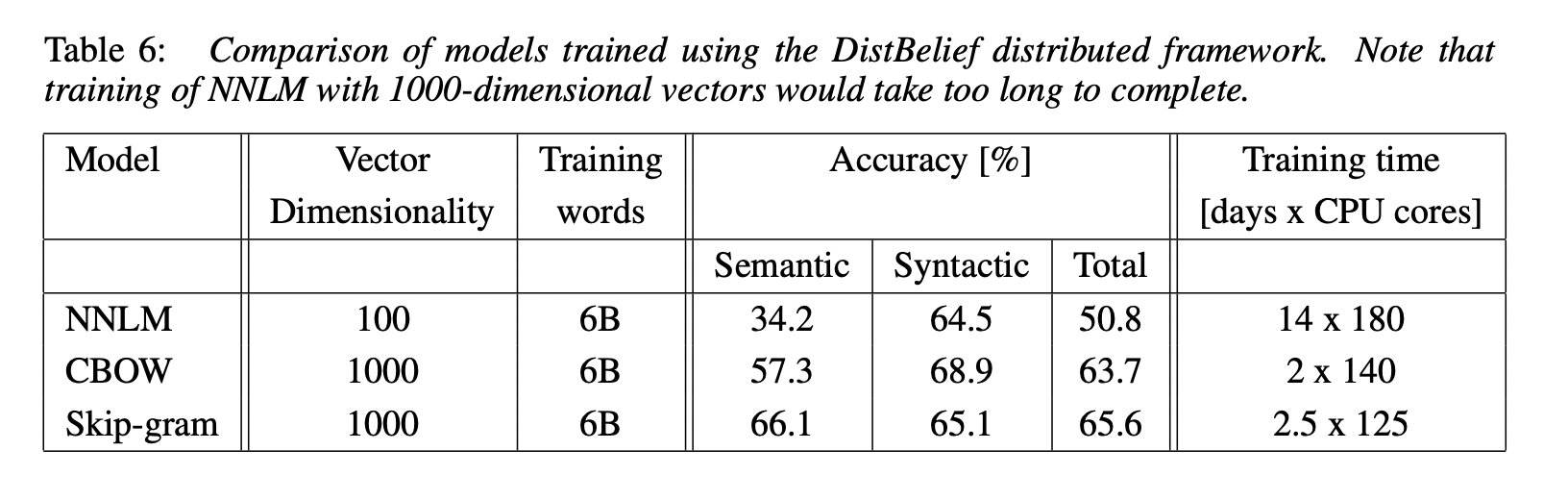
4.5 Microsoft Research Sentence Completion Challenge
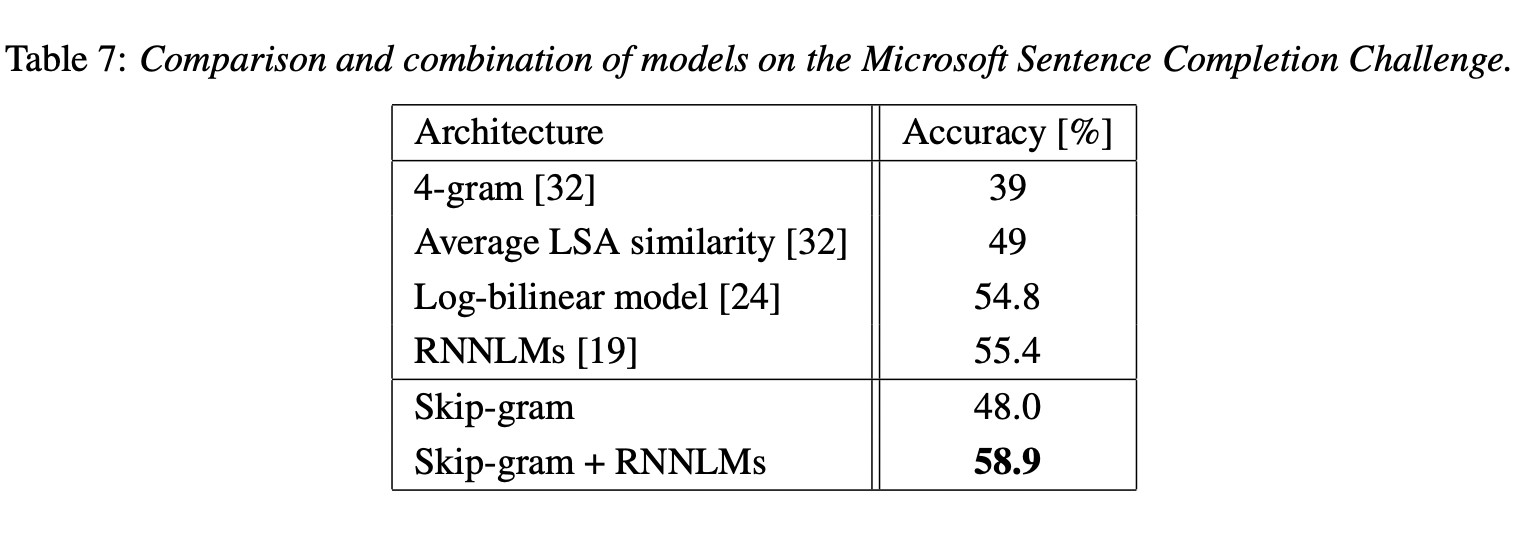
5. Examples of the Learned Relationships
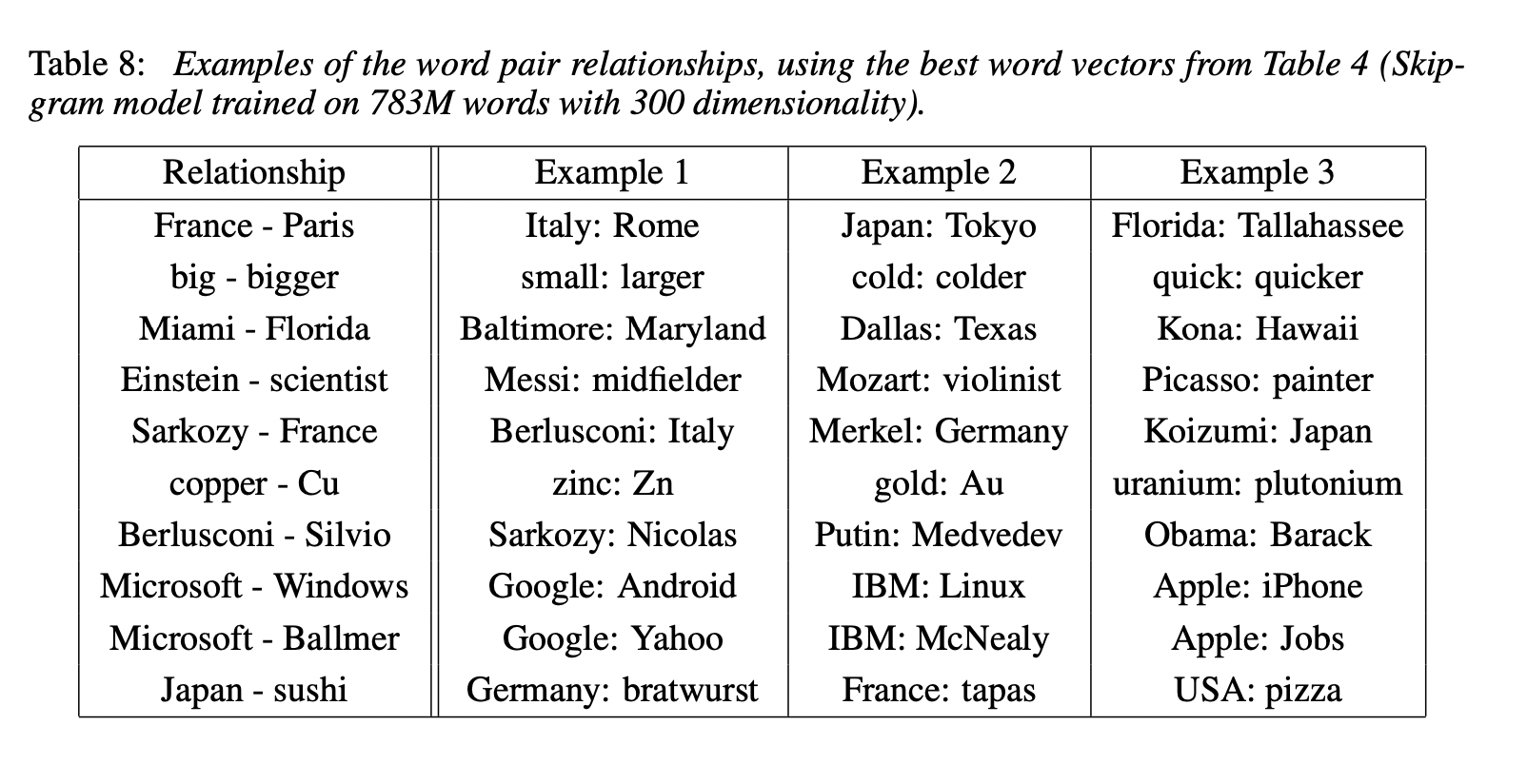
두 단어 vector의 차를 구한 후 다른 단어 vector와 더해줍니다. 예를 들면 Paris - France + Italy = Rome 입니다. 많은 data set을 활용해서 높은 차원으로 학습을 할 때 성능이 좋았습니다.
6. Conclusion
해당 논문에서 syntactic, semantic language task들을 통해서 다양한 모델들에서 나온 vector representation of word의 quality를 비교했습니다. 기존의 잘 알려진 neural netword model(feedforward and recurrent)와 비교하였을 때 단순한 model architecture를 통해 학습된 word vector 역시 좋은 성능을 보일 수 있다는 것을 발견했습니다. Computational complexity가 작아진 덕분에 매우 큰 data set으로부터 높은 차원의 word vector를 얻을 수 있게 되었습니다.

