Word2Vec를 소개한 논문과 연이어 나온 논문입니다. Skip-gram 모델을 바탕으로 Negative sampling, Subsampling method, 관용구 학습 아이디어 등을 소개합니다.
[Abstract]
Skip-gram model은 단어들 간의 세밀한 syntactic, semantic 관계를 포착하는 high-quality distributed vector representation을 학습하는 효율적인 방법입니다. 해당 논문에서는 vector의 quality와 학습 속도 향상에 도움을 줄 수 있는 extension을 소개합니다. 자주 등장하는 단어의 subsampling을 통해서 눈에 띄는 속도 향상을 얻을 수 있고 더욱 정확한 word representation을 학습할 수 있습니다. 또한 negative sampling으로 불리는 hierarchical softmax의 대체를 소개합니다.
Word representaion의 내재된 한계점은 단어의 순서를 고려하지 않는다는 것과 관용구를 표현하는 것이 불가능하다는 것입니다. 이를 해결하기 위해 관용구를 학습하기 위한 간단한 방법 역시 소개합니다.
1. Introduction
벡터 공간에 표현되 단어의 distributed representation은 유사한 단어들을 그룹화하여 NLP task에서 좋은 성능을 갖는 알고리즘을 학습하는 것을 도웁니다.
Skip-gram model은 구조화되지 않은 많은 양의 text data로부터 high-quality vector representaion을 학습하는 효율적인 방법입니다. Skip-gram model의 학습은 dense matrix multiplication을 포함하고 있지 않습니다. 이는 학습을 효율적으로 만들어줍니다.
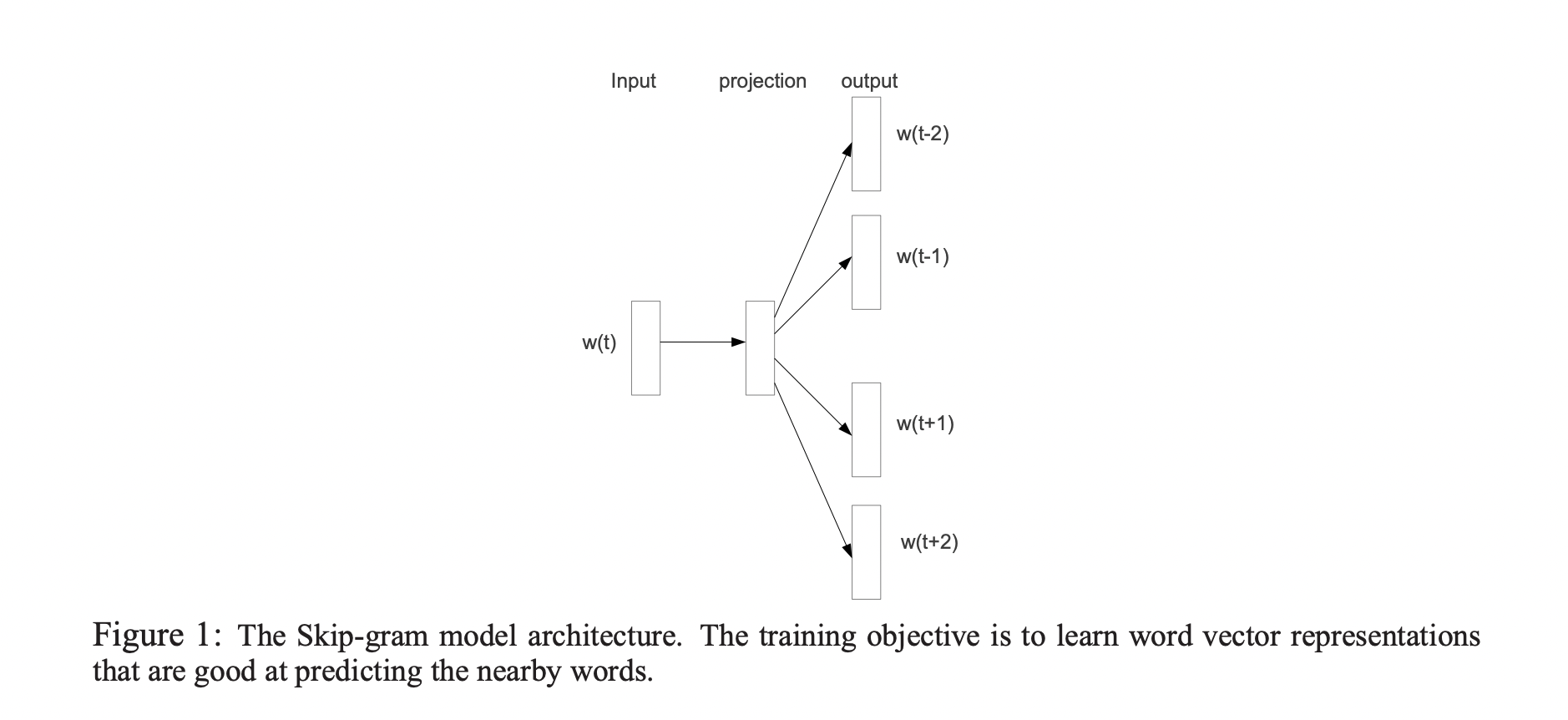
Neural network를 사용하여 계산된 word representation은 학습된 vector가 다양한 언어적인 regularity와 pattern들을 encode하고 있기 때문에 흥미로운 방법입니다. 다소 놀랍게도 이러한 pattern들은 대다수는 linear translation으로 표현될 수 있습니다. 예를 들어, Vector("Madrid") - Vector("Sapin") + Vector("France")의 결과는 Vector("Paris")와 가장 가깝습니다.
해당 논문에서는 Skip-gram model의 몇가지 extension들을 소개합니다. 학습 중 자주 등장하는 단어들의 sub-sampling이 속도 향상과 자주 등장하지 않는 단어들의 representation의 accuracy를 높여주는 것을 보여줍니다. 또한 해당 논문은 이전 논문에서 활용된 복잡한 hierarchical softmax와 비교하였을 때보다 학습 속도가 빠르고 vector representaion 결과가 좋은 Noise Contrastive Estimation(NCE)의 변형을 소개합니다.
Word representaion은 개별 단어들의 단순 결합으로 보기 힘든 관용구들을 표현하지 못한다는 한계가 있습니다. 관용구를 표현할 수 있는 vector를 활용한다면 Skip-gram model이 더욱 효율적이게 될 수 있습니다.
관용구를 위한 extension은 간단합니다. 첫째 data-driven approach를 사용하여 다양한 관용구를 파악한 후 파악된 관용구들을 학습 시 하나의 token으로 바꾸어 다룹니다.
마지막으로 벡터간의 단순합이 때때로 의미있는 결과를 만들어내는 것을 보여줍니다. 예를들어 Vector("Germany") + Vector("capital")는 Vector("Berlin")과 가깝습니다. 이는 word vector representation의 단순한 수학적 연산을 사용하여 일정 부분의 언어 이해를 했다고도 고려해볼 수 있습니다.
2. The Skip-gram Model
Skip-gram model의 학습 목표는 문장이나 문서의 주변 단어를 예측하는 데 사용할 수 있는 word representation을 찾는 것입니다.


2.1 Hierarchical Softmax
Full softmax의 계산 효율을 위한 approximation이 hierarchical softmax입니다. 주된 장점은 probability distribution을 구하기 위해 neural network의 W개의 output nodes를 계산하는 대신 오직 log2(W) 개의 node만 계산을 필요로 합니다.
Hierarchical softmax는 output layer로 W개 단어를 leaf로 사용하고 각각의 node에 chile node들의 상대적인 확률을 표현하는 binary tree representation을 사용합니다.

Hierarchical softmax가 사용하는 tree 구조는 학습 시간과 모델 정확도에 상당한 효과를 주었습니다.
2.2 Negative Sampling
Hierarchical softmax의 대체제 중 하나는 Noise Contrastive Estimation(NCS)입니다.NCE는 좋은 모델이라면 logistic regression의 평균으로 nosie로부터 나온 data를 잘 구분할 수 있어야한다고 받아들입니다.
Negative sampling(NEG)를 다음과 같은 objective를 통해 정의합니다.
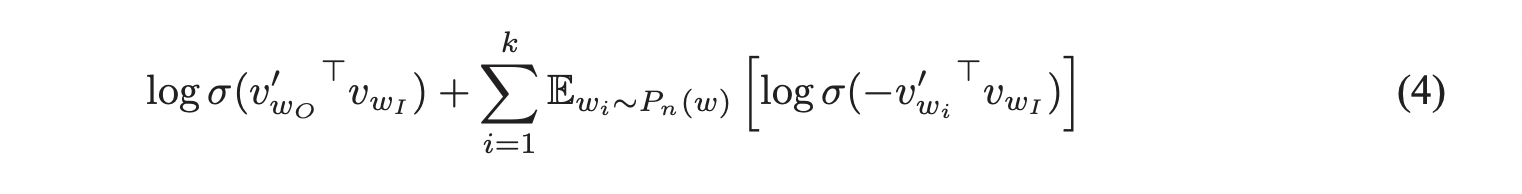
해당 task는 각 data sample마다 k개의 negative sample을 만들고 logistic regression을 활용하여 nosie distribution P_n(w)에서 나온 negative sample을 target word w_o와 구분하는 것입니다. Negative sampling과 NCE의 차이점은 NCE는 sample과 noise distribution의 numerical probability를 모두 알고 있어야 하지만 negative sampling은 sample만 있으면 됩니다.

2.3 Subsampling of Frequent Words
매우 큰 corpora에서 가장 많이 등장하는 단어('a', 'the', 'in' 등)는 수억번도 등장할 수 있습니다. 이러한 단어는 자주 등장하지 않는 단어에 비해 중요한 정보를 담고 있지 않을 수 있습니다. Skip-gram model에서 'France'와 'Paris'가 동시에 등장한다면 중요한 정보를 얻을 수 있겠지만 'France'와 'the'가 동시에 등장하는 정보는 크게 중요하지 않습니다.
자주 등장하지 않는 단어와 자주 등장하는 단어의 불균형을 해소하기 위하여 간단한 subsampling 방법을 사용합니다.
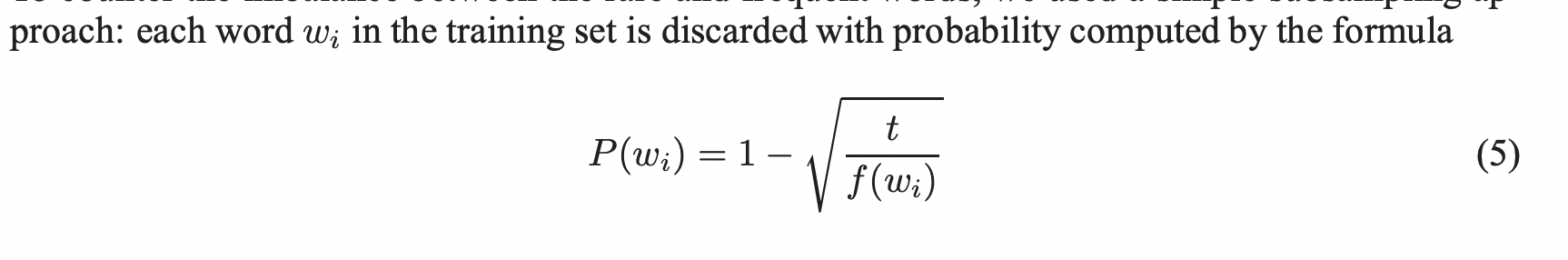
해당 subsampling 방법은 학습 속도를 빠르게 해줬고 자주 등장하지 않는 단어들의 vector의 정확도를 높여줬습니다.
3. Empirical Results
Cosine distance를 활용하여 Vector("Berlin") - Vector("Germany") + Vector("France")의 결과와 가장 근접한 Vector(x)를 찾는 것이 주된 task입니다.
Skip-gram 모델 학습을 위해 다양한 뉴스 기사를 포함한 data로 학습을 진행하였으며 5번 미만으로 등장한 단어들은 제외했습니다.
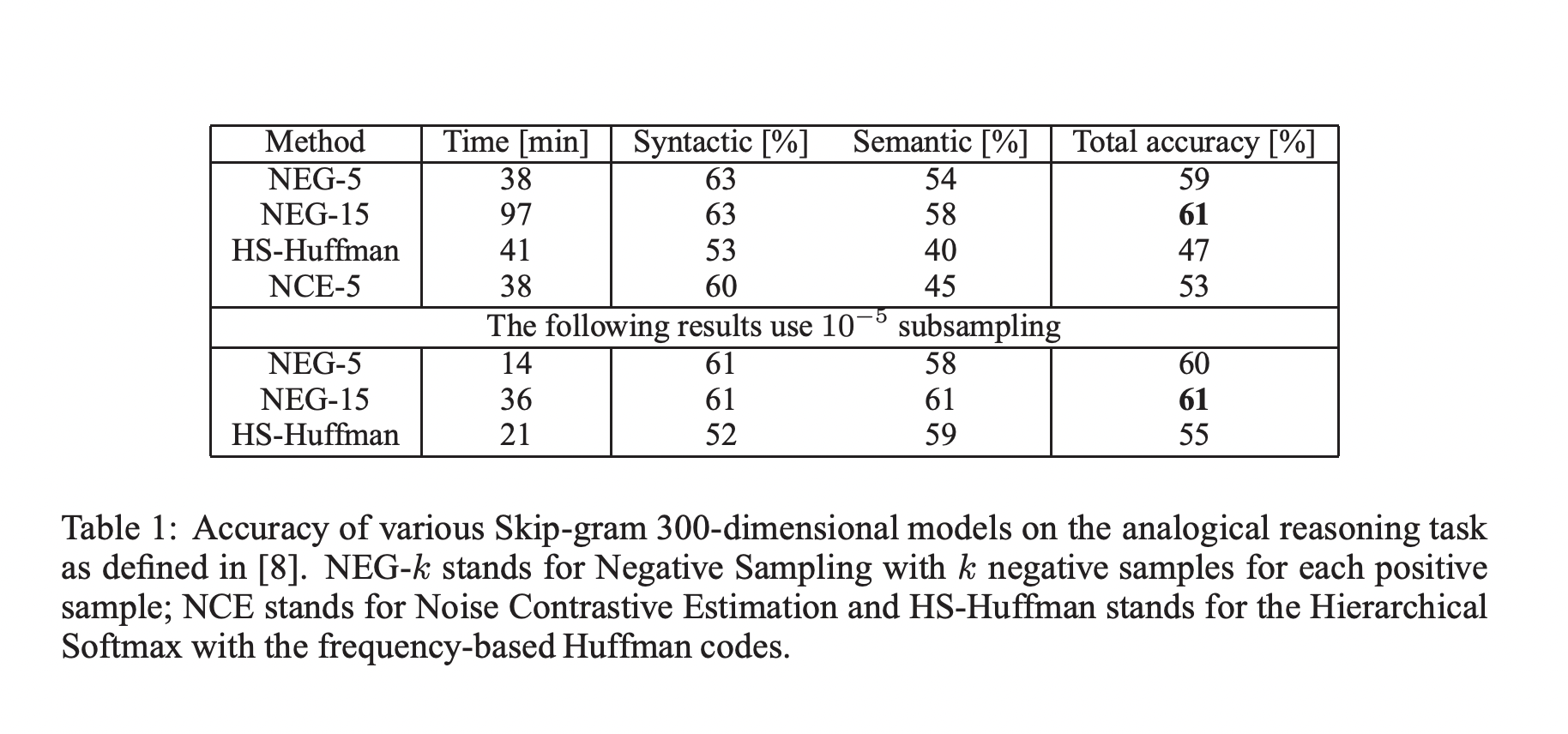
Negative sampling은 hierarchical softmax보다 analogical reasoning task에서 성능이 좋았으며 NCE보다도 성능이 좋았습니다. Subsampling 방법을 활용하였을 때 학습 속도가 개선되었고 word representation도 더욱 정확해졌습니다.
4. Learning Phrases
대다수의 관용어구들은 개별 단어들의 단순한 결합으로서 의미를 파악하기 힘듭니다. 관용어구들의 vector representation을 학습하기 위해 함께 자주 등장하는 단어들과 다른 문맥에서는 자주 등장하지 않는 단어들을 파악합니다.
Data-driven 방법을 통해 다음과 같이 관용어구의 score를 계산합니다.
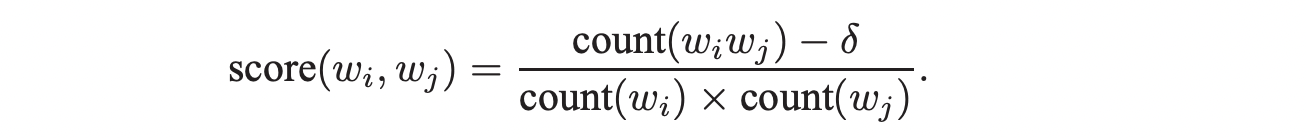
해당 score가 특정 값을 넘었을 때 관용어구로 생각합니다.
4.1 Phrase Skip-Gram Results
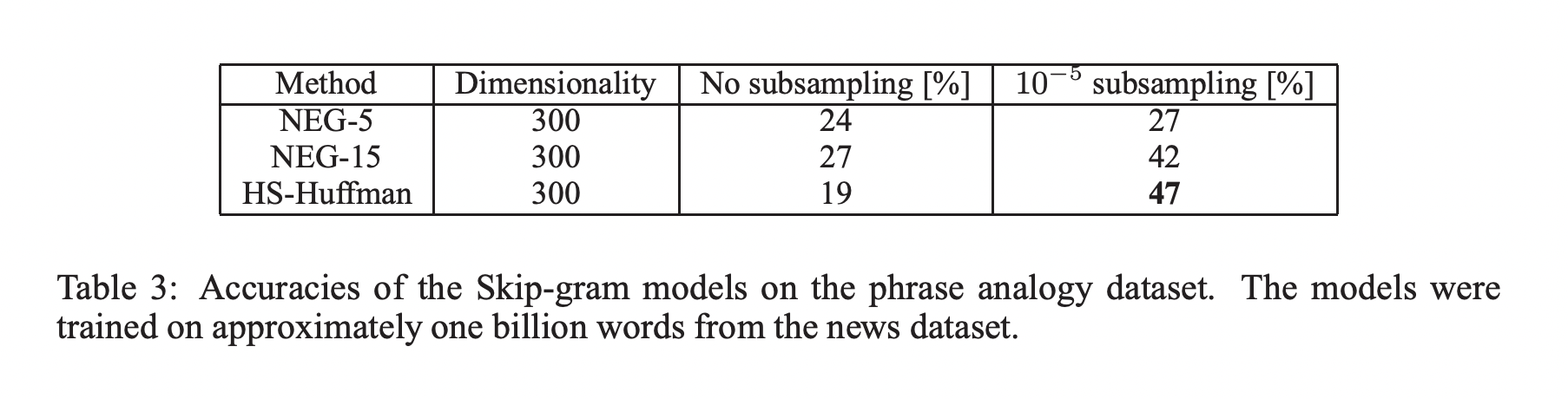
Subsampling을 사용하였을 때 학습속도가 빠르고 정확도가 올랐습니다.

5. Additive Compositionality
Skip-gram model을 통해 학습된 word and phrase representaion은 간단한 벡터간의 연산을 통해 정교한 유추가 가능하게 해주는 linear structure를 보여줍니다. Skip-gram representation은 각각 vector들의 element-wise 합을 통해 의미적으로 단어를 결합하는 것을 가능하게 해주는 또 다른 linear structure를 보여줍니다.

문장에서 주변 단어를 예측할 수 있도록 word vector가 학습되었기 때문에 vector는 해당 word가 등장한 주변 문맥의 정보를 포함하고 있습니다. 그래서 두 vector의 합은 두 문맥의 정보를 담고 있을 수 있습니다.
6. Comparison to Published Word Representaions
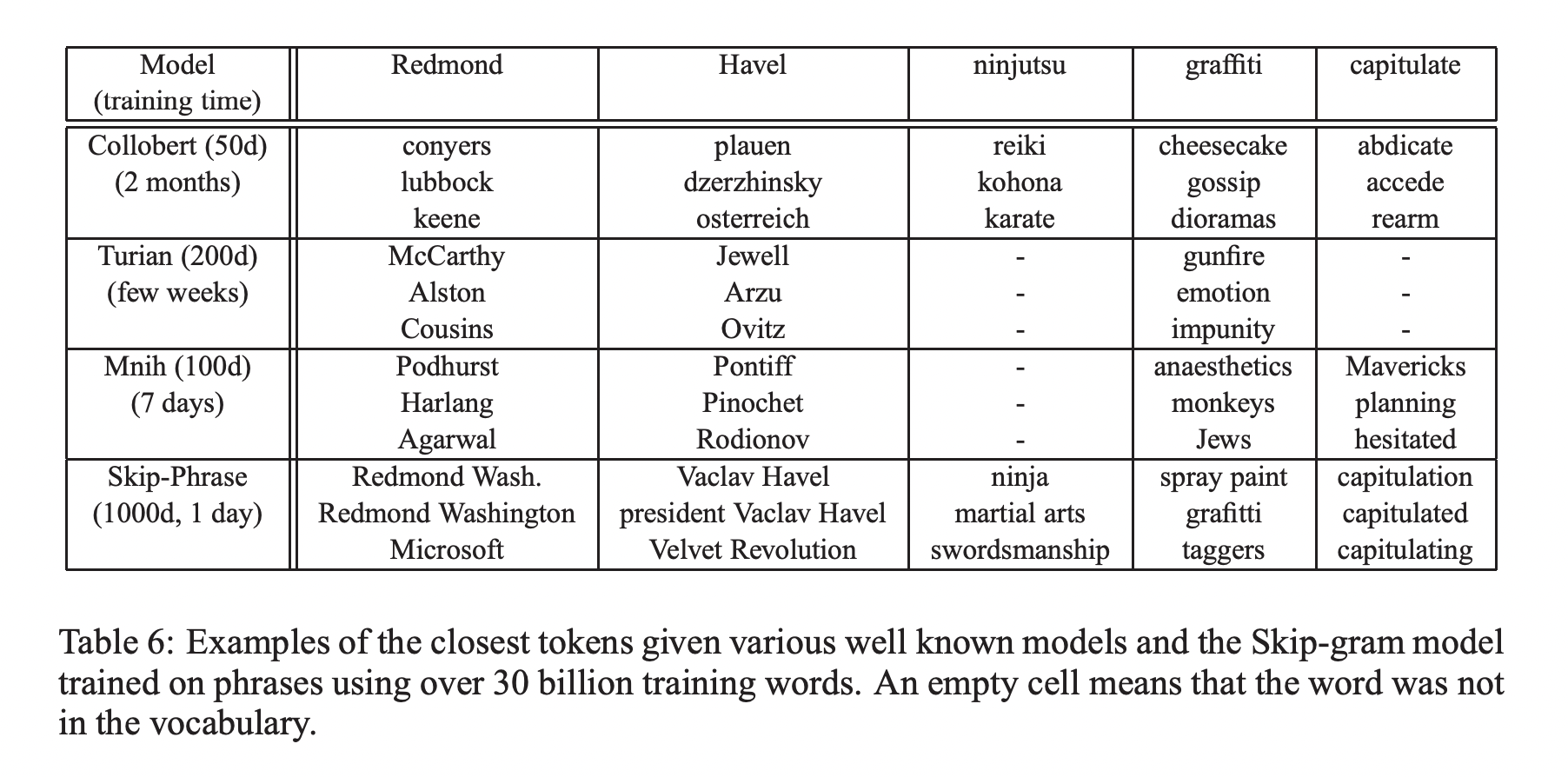
큰 corpus로 학습된 big Skip-gram model은 다른 모델들에 비해 가장 좋은 성능을 보였습니다.
7. Conclusion
해당 논문은 Skip-gram을 활용하여 word와 phrase의 distributed representation을 학습하는 방법을 보이고 해당 representation이 정교한 유추가 가능한 linear structure라는 것을 설명했습니다. 해당 논문에서 소개한 방법은 CBOW 학습에도 활용할 수 있습니다.
Subsampling은 학습 속도와 자주등장하지 않는 단어의 representation 성능 향상에 모두 도움을 주었습니다. Negative sampling은 자주 등장하는 단어들에 대해 더 좋은 representation을 부여할 수 있는 단순한 학습 방법을 제공하였습니다.
해당 논문의 가장 흥미로운 결과 중 하나는 단순한 vector들의 합을 사용하여 word vector가 결합될 수 있다는 것이었습니다. 관용어구의 representation을 학습하기 위해서는 관용어구를 하나의 또 다른 token으로 처리하는 것이 제안되었습니다. 이 두 가지 방법의 결합을 통해 계산 복잡도를 최소화하는 동시에 longer pieces of text를 표현하는 단순하지만 강력한 접근 방법을 얻을 수 있었습니다.
