Doc2Vec로도 불리는 Paragraph Vector를 소개하는 논문입니다. Word2Vec의 컨셉을 유지하면서 word vector뿐만 아닌 문장 혹은 문서 전체를 대표하는 또 다른 vector를 하나 추가하여 전체적인 의미를 포함하는 vector를 학습합니다.
[Abstract]
Text fixed-length feature의 대표적인 방법은 bag-of-words입니다. Bag-of-words는 2가지 단점이 있습니다. 첫째, 단어의 순서를 무시합니다. 둘째, 단어의 의미를 무시합니다. 해당 논문에서는 Paragraph Vector라는 이름의 unsupervised 알고리즘을 소개합니다. Paragraph Vector는 문장, 문단, 문서와 같이 다양한 길이의 text들을 fixex-length feature 표현을 학습합니다. 해당 알고리즘은 문서 내의 단어를 예측하는 학습을 통해 문서를 dense vector로 표현합니다.
1. Introduction
문서 검색, web search, spam filtering에서 text classification과 clustering은 중요한 역할을 합니다. 해당 작업을 위해 대표적인 알고리즘으로 logistic regression, K-means 등이 활용되는데 이 알고리즘들은 fixed-length vector로 표현된 text를 input으로 사용합니다. Text fixex-length vector representation의 주로 사용되는 방법은 bag-of-words나 bag-of-n-grams입니다. 두 알고리즘은 단순하며 효율적이고 때로 좋은 정확도를 갖습니다.
하지만 bag-of-words는 단어의 순서를 잃어버린다는 단점이 있습니다. 따라서 만일 같은 단어들을 사용했지만 순서가 다른 문장이더라도 모두 똑같은 결과를 갖습니다. Bag-of-n-grams는 단어의 순서 정보는 갖더라도 data sparsity와 high dimensionality 문제를 갖습니다. 또한 두 알고리즘 모두 단어의 의미를 제대로 반영하지 못합니다.
해당 논문에서는 text의 continuous distributed vector representaion을 학습하는 unsupervised 방법인 Paragraph Vector를 소개합니다. Paragraph Vector라는 명칭은 구, 문장뿐만 아니라 문서처럼 다양한 길이의 text를 다룰 수 있는 방법이라는 점을 강조합니다.
Paragraph Vector는 paragraph 내의 단어 예측을 통해 학습됩니다. 좀 더 상세히 표현하자면 paragraph의 몇 개의 word vector와 paragraph vector를 concatenate하여 주어진 문맥에서 다음에 등장하는 단어를 예측합니다. Paragraph vector는 paragraph 사이에서 유일하며, word vector는 모두 공유됩니다.
문서 representation을 위해 해당 문서의 모든 단어들을 weighted average을 하거나 matrix-vector operation을 사용하여 parse tree of sentence를 통해 word vector를 순서대로 합칩니다. Weigthed average는 단어의 순서 정보를 잃는 단점을, parse tree를 활용하는 방법은 문장에서만 제대로 된 결과를 얻는 다는 단점을 보였스빈다.
Paragraph Vector는 다양한 길이의 input sequence의 representaion을 표현할 수 있습니다. 기존의 방법들과는 달리 문장, 단락, 문서 등 길이에 상관없이 general하게 적용할 수 있습니다.
2. Algorithms
2.1 Learning Vector Representation of Words
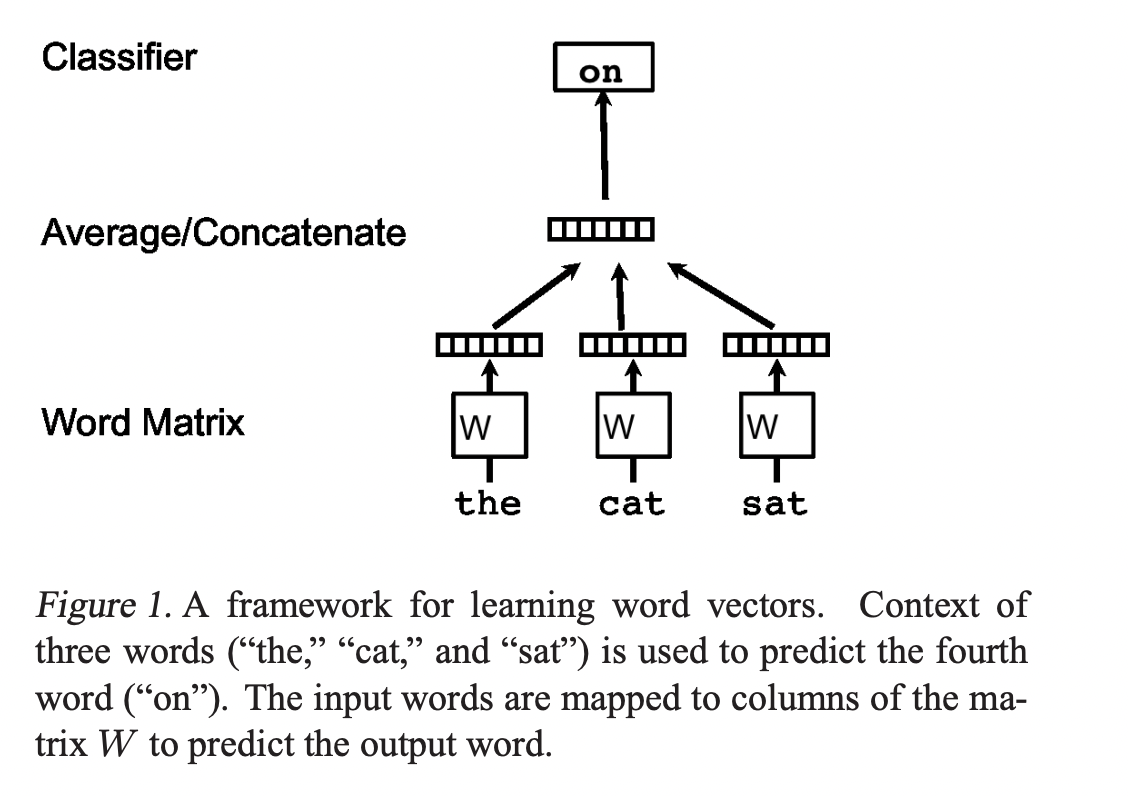
모든 단어들은 W 행렬의 column 값인 unique vecotr로 mapping됩니다.
Training words들이 주어졌을 때 objective word vector는 아래 확률을 최대로 만듭니다.
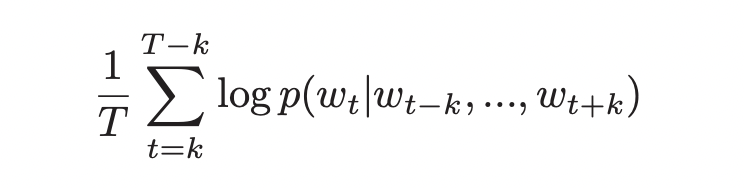
Prediction task는 softmax와 같은 multiclass classifier를 통해 이루어집니다.

위와 같은 방법을 사용하여 유사한 의미의 단어들은 유사한 공간으로 mapping됩니다.
2.2 Paragraph Vector: A distributed memory model
Paragraph vector를 학습하는 방식은 word vector를 학습하는 방식에서 차용되었습니다. 차용된 방식은 word vector는 문장 내의 다음 단어를 예측하는 방식으로 학습되는 방식입니다. 해당 방식을 통해 처음에는 random으로 초기화된 word vector들이 prediction task를 수행하며 부수적으로 단어의 의미를 vector에 녹여내게 됩니다. Paragraph vector는 paragraph에서 추출된 여러개의 context에서 다음 단어 prediction task를 수행합니다.
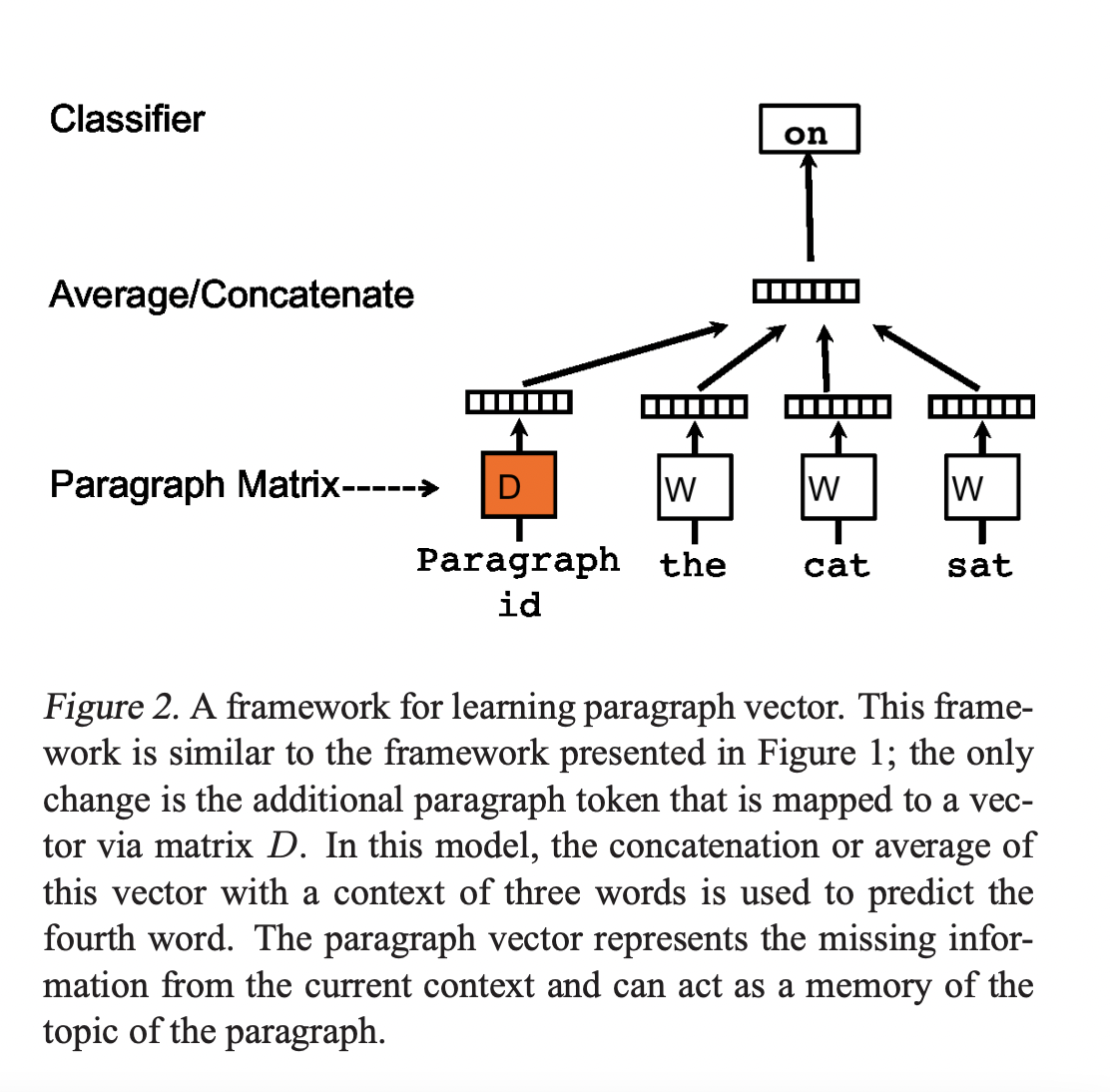
모든 paragraph들은 행렬 D의 column 값인 unique vector로 mapping됩니다. 단어는 이전과 마찬가지로 행렬 W의 column 값인 unique vector로 mapping됩니다. Paragraph vector와 word vector는 concatenate되거나 average되어 다음 단어를 예측하는 데 사용합니다. 해당 논문에서는 concatenate하여 vector들을 결합합니다.
Paragraph token은 또 다른 하나의 단어로 생각할 수 있습니다. Paragraph token은 paragrph의 주제, 맥락을 담고 있는 memory 역할을 합니다. 그렇기 때문에 Distributed Memory Model of Paragraph Vectors(PV-DM)으로 부릅니다.
Paragraph는 여러개의 context(word의 집합)로 이루어져 있습니다. 하나의 paragraph에서는 여러개의 context에 따라 동일한 paragraph vector를 사용합니다. 하지만 paragraph가 변하면 paragraph vector 역시 변합니다. Word vector는 paragraph가 다르더라도 모두 동일한 값을 사용합니다.

학습이 끝나면 paragraph vector는 paragrph의 feature로써 사용될 수 있습니다. 해당 feature를 input으로 logistic regression, K-means 등 사용할 수 있습니다.
- Unspervised training to get word vectors W
- Inference stage to get paragraph vectors D
- Turn D to make a prediction about some particular labels using a standard classifier
Advantages of paragraph vectors
가장 큰 장점은 unlabeled data에서 학습이 된다는 것입니다. 따라서 labeled data가 적어도 좋은 결과를 보입니다.
Paragraph vectors는 bag-of-words의 단점을 보완합니다.
- Word vector의 중요한 특징인 의미를 내포하고 있습니다.
- 단어의 순서를 고려합니다.
2.3 Paragrph Vector without word ordering: Distributed bag of words
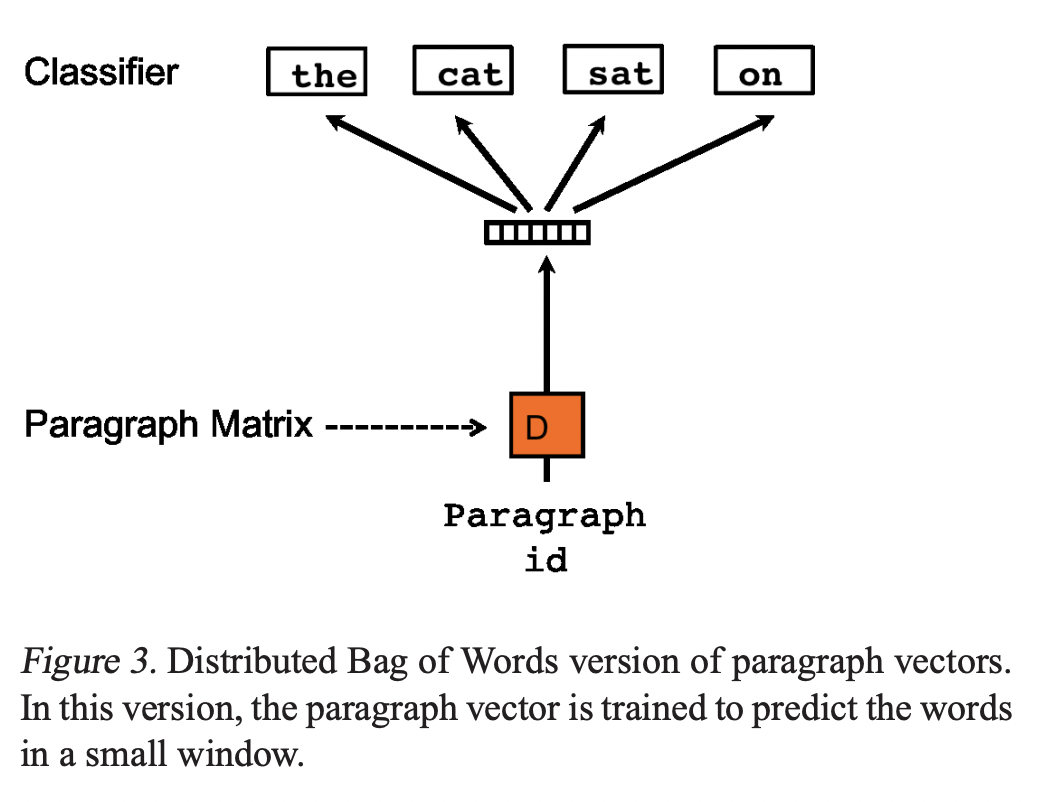
또 다른 방법은 input에 context words를 넣지 않고 모델이 output으로 paragraph에서 임의로 뽑힌 단어들을 예측하게 합니다. Skip-gram과 유사한 이와 같은 방법을 Distributed Bag of Words version of Paragraph Vector(PV-DBOW)라고 합니다.
3. Experiments
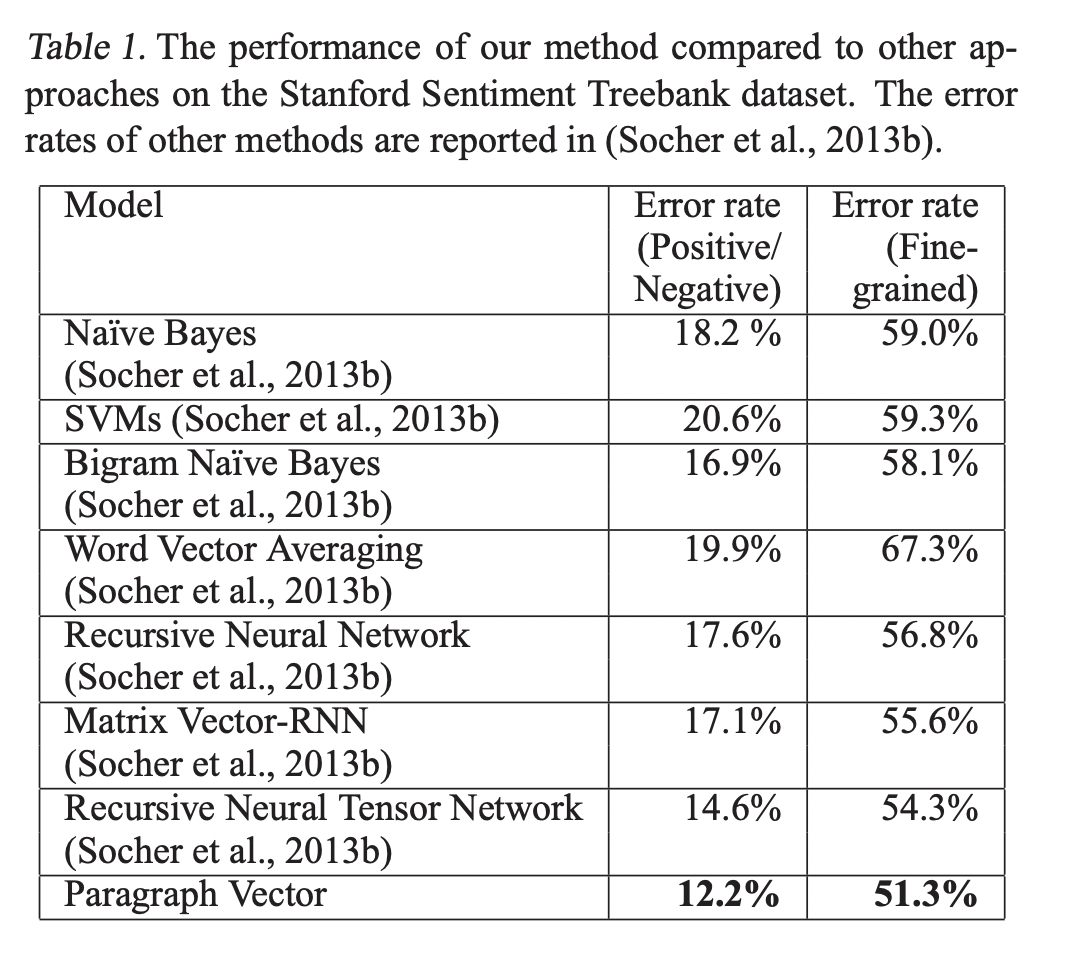
3.1 Sentiment Analysis with the Stanford Sentiment Treebank Dataset
Results
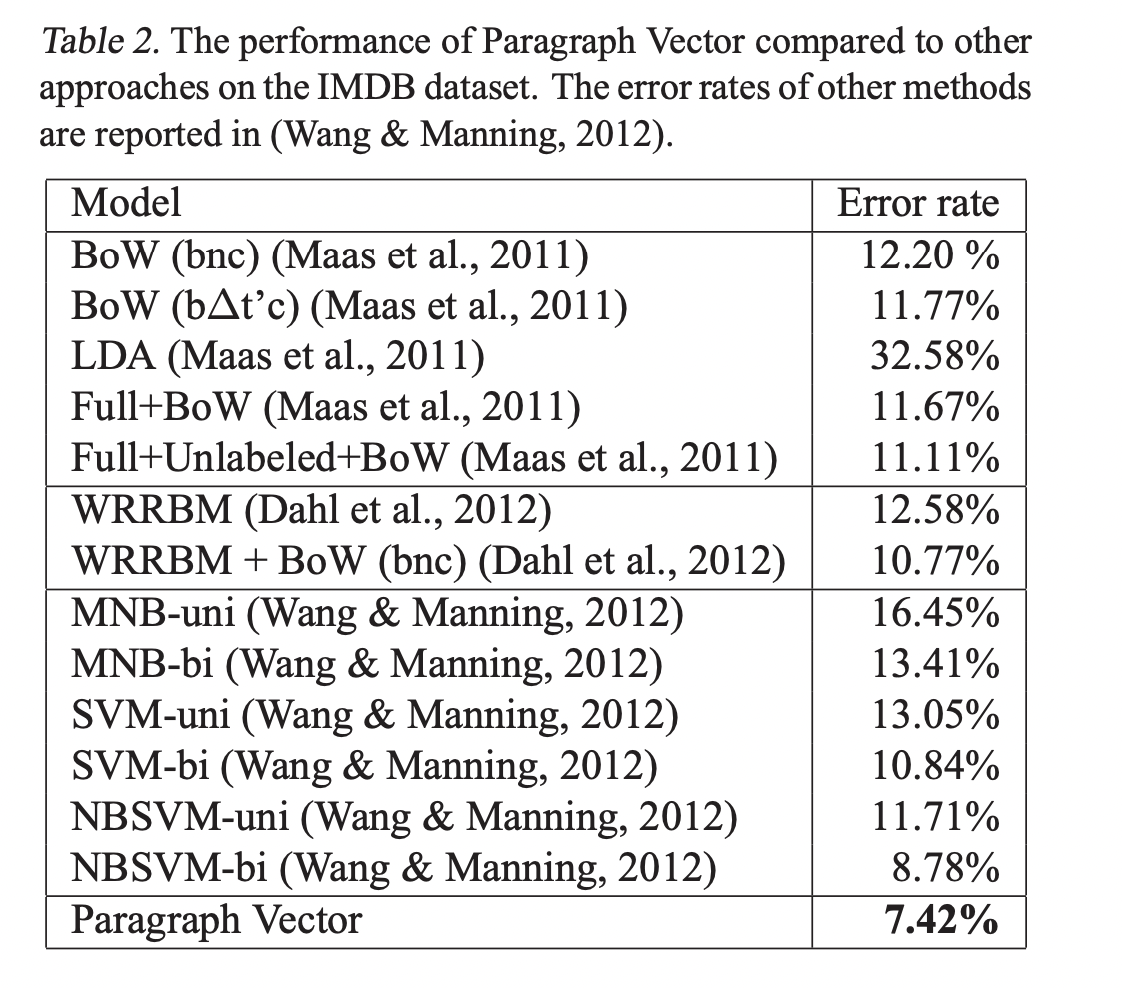
3.2 Beyond One Sentence: Sentiment Analysis with IMDB dataset
Paragraph Vector는 parsing을 필요로하지 않기 때문에 긴 문서의 representaion도 만들 수 있습니다.
Results
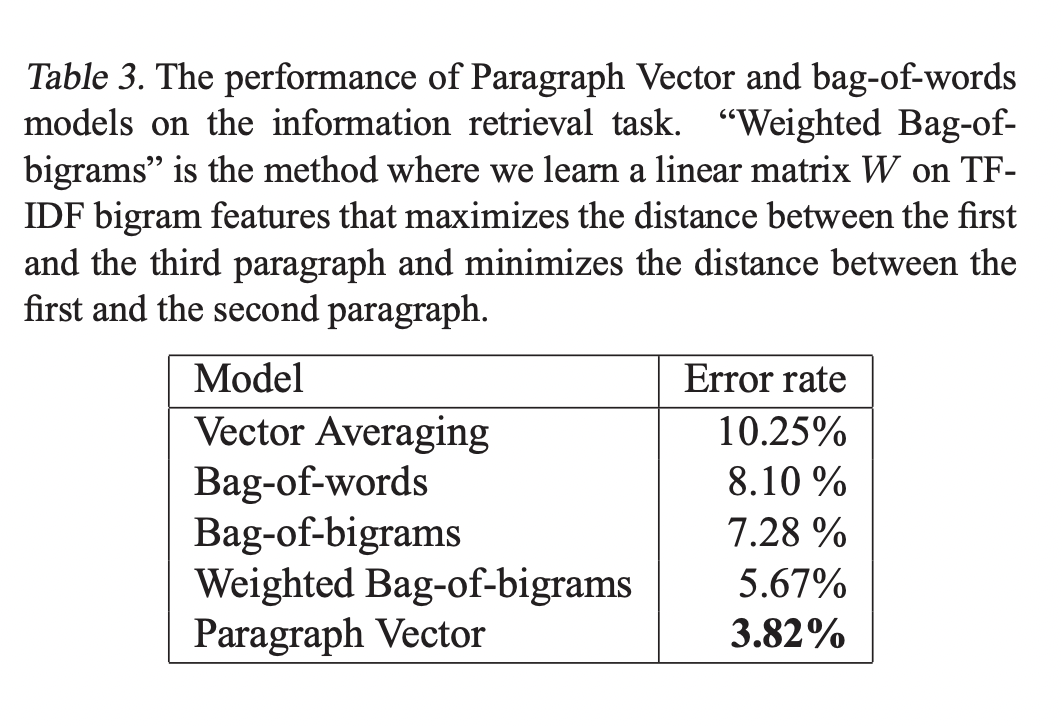
3.3 Information Retrieval with Paragraph Vectors
Results
3.4 Some further observations
- Consistently "PV-DM > PV-DBOW"
- "Concatenation > Sum" in PV-DM
- 5 ~ 12 window size가 좋은 성능을 보임
- Paragraph Vector can be expensive, but it can be done in parallel at test time
4. Related Work
5. Discussion
해당 논문은 Paragraph Vector라는 문장과 문서같은 다양한 길이의 text representation을 학습하는 unsupervised 알고리즘을 소개했습니다. Paragraph Vector는 하나의 paragraph에서 뽑힌 context 안의 주변 단어들을 예측하면서 학습되었습니다.
Paragraph Vector가 좋은 성능을 보인 이유는 paragraph의 전체적인 의미를 내포하고 있기 때문이라고 설명할 수 있습니다. 또한 Paragraph Vector는 bag-of-words model들의 단점을 보완합니다.
해당 방법은 text뿐만 아닌 다른 형태의 sequential data representation에도 적용할 수 있습니다. Parsing이 불가능한 non-text domain에서도 Paragraph Vector가 bag-of-words와 bag-of-n-gram model의 좋은 대체재가 될 수 있다고 예상합니다.
