Doc2Vec인 Paragraph Vector의 성능을 감성분석 이외의 task에서 수행합니다. LDA를 비교대상으로 삼아 비교 결과를 제시하는 논문입니다.
[Abstract]
Paragraph Vectors는 pieces of texts의 distributed representations를 학습하는 unsupervised method로 제시되었습니다. 해당 논문에서는 기존 논문의 감성 분석 외의 다른 task들을 수행하여 LDA(Latent Dirichlet Allocation)과 같은 document modelling 알고리즘과 결과를 비교합니다. 해당 논문에서는 Paragraph Vectors 방법이 다른 방법들과 비교하였을 때 좋은 성능을 보이고, embedding quality의 향상을 보여줍니다. Paragraph Vectors에 vector 연산은 의미있는 의미적 결과를 보여줍니다.
1. Introduction
많은 language understanding problem의 중심에는 knowledge representation(어떻게 문서의 의미를 기계가 이해할 수 있도록 표현할 수 있을까?)이 있습니다. 해당 의문의 대표적인 방법으로 bag of words(bag of n-gram)과 Latent Dirichlet Allocation(LDA)가 있습니다.
최근에는 문서와 단어의 distributed representation을 사용하는 것이 주된 패러다임입니다. Paragraph Vector는 dense vector를 사용하여 문서의 의미를 표현합니다. Paragraph Vector를 처음 소개한 논문에서는 이를 활용하여 영화 리뷰의 분류와 웹 페이지 검색을 수행했습니다.
해당 논문에서는 2개의 task에서 Paragraph Vecotrs를 다른 baseline과 비교를 수행합니다.
- Wikipedia browsing : what are the nearest articles that the audience should browe next
- Finding related article on arXiv
Skip gram model을 활용하는 word embedding과 동시에 학습을 했을 때 paragraph vector의 quality가 좋아집니다.
2. Model
Paragraph Vector는 이 논문에서 처음 소개되었습니다.
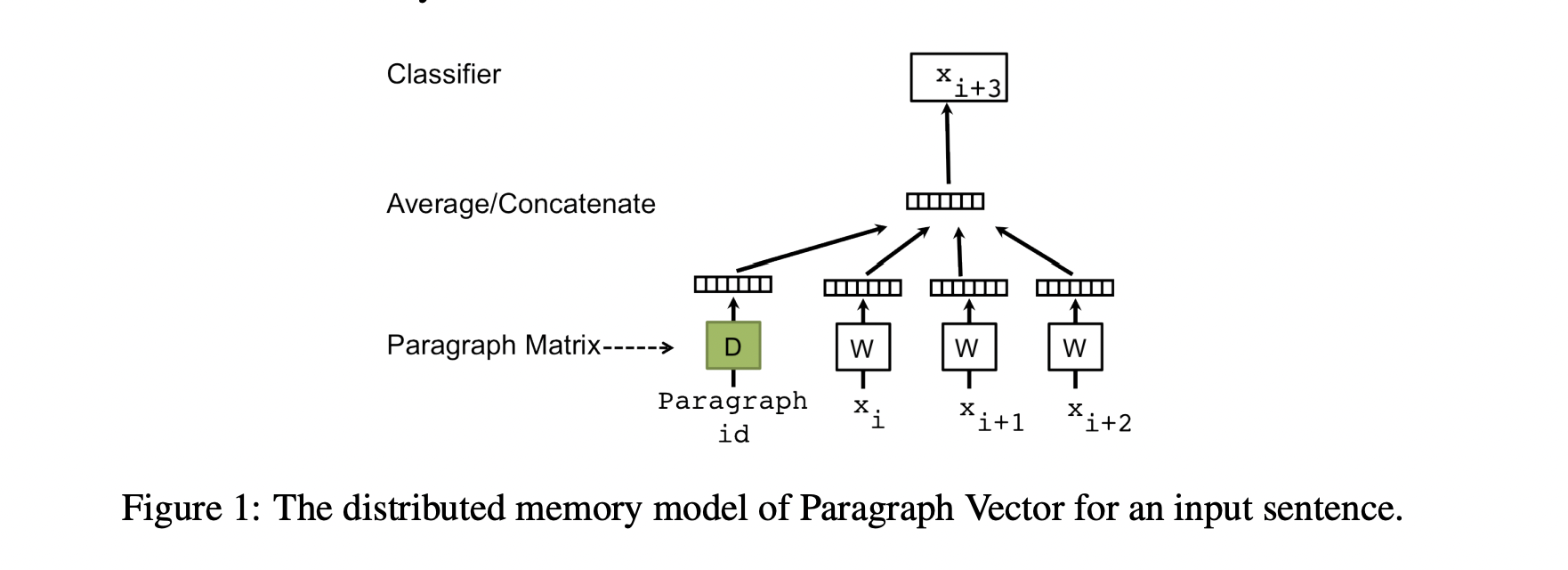
Distributed Memory - 문서의 주제를 잡아내기 위해 memory vector를 사용합니다.
Distributed Bag of Words
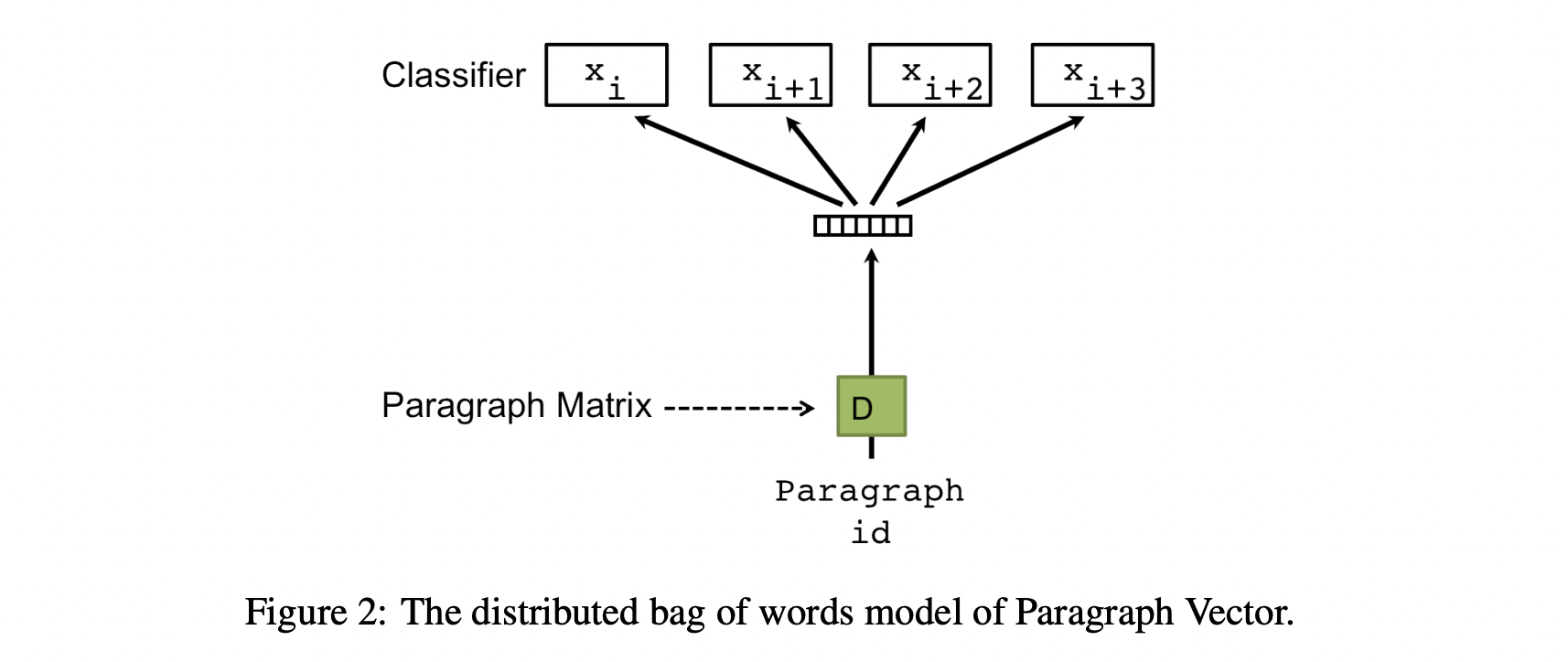
Distributed bag of words 모델이 더욱 효율적이기 때문에 해당 논문의 실험에서 Paragraph Vector로 사용합니다.
3. Experiments
Wikipedia와 arXiv의 corpus를 활용합니다.
모든 단어는 lower-cased 처리를 합니다.
Paragraph Vectors의 quality를 높이기 위해 word embedding과 paragraph vectors를 동시에 학습시킵니다.
3.1 Performance of Paragraph Vectors on Wikipedia entries
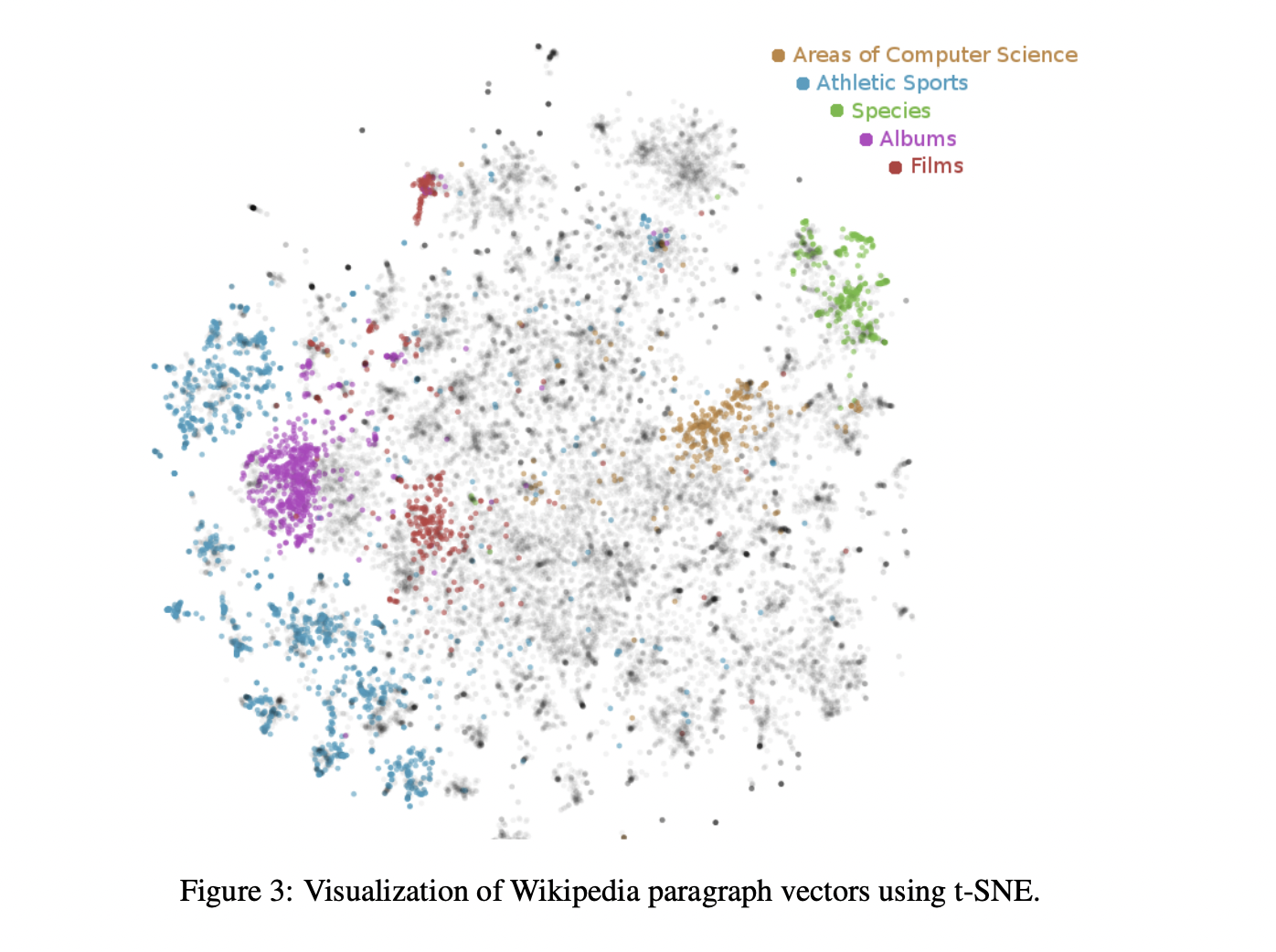
그림에서 확인할 수 있듯이 같은 categroy 문서들은 유사한 곳에 위치해 있습니다.
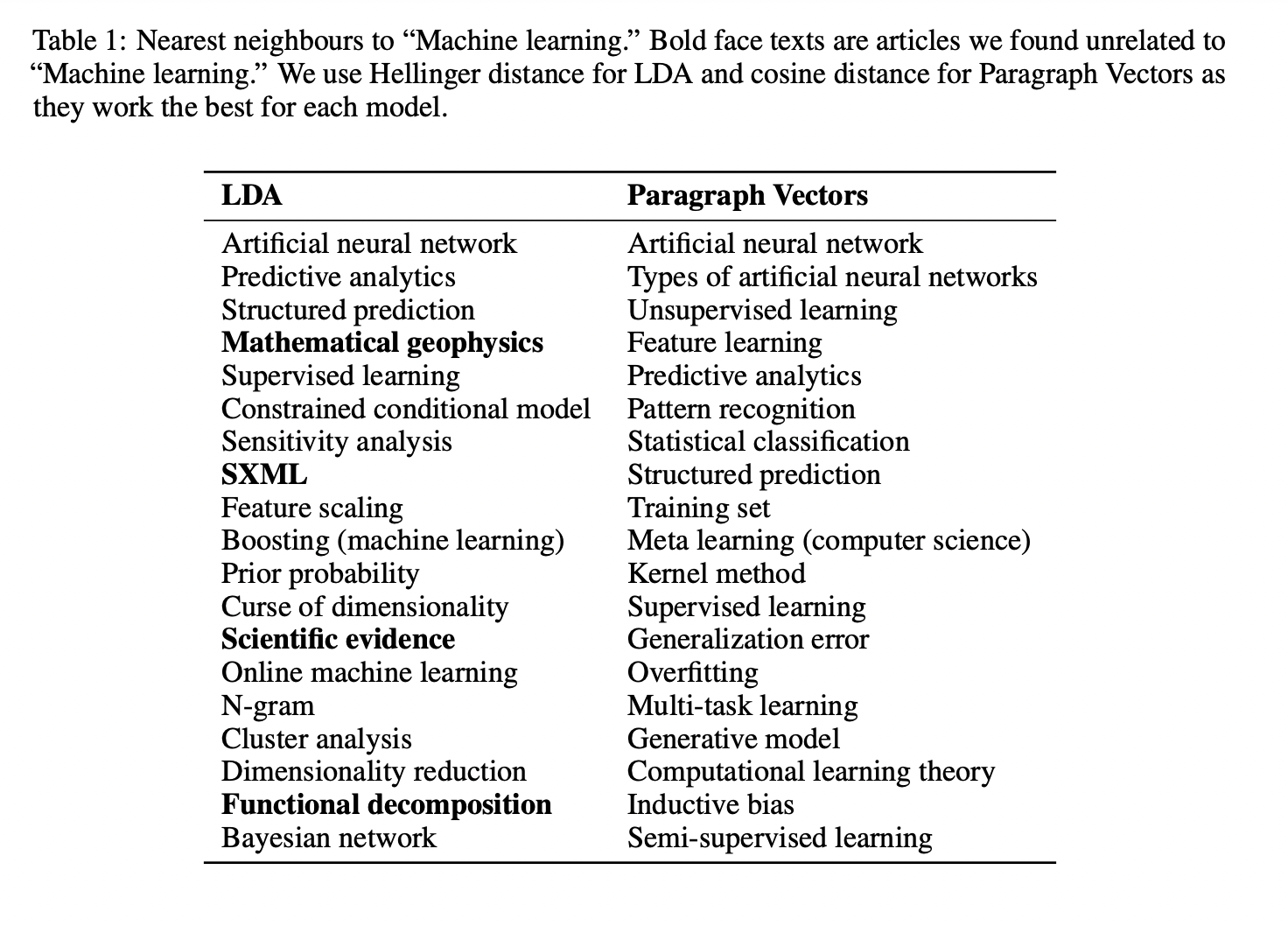
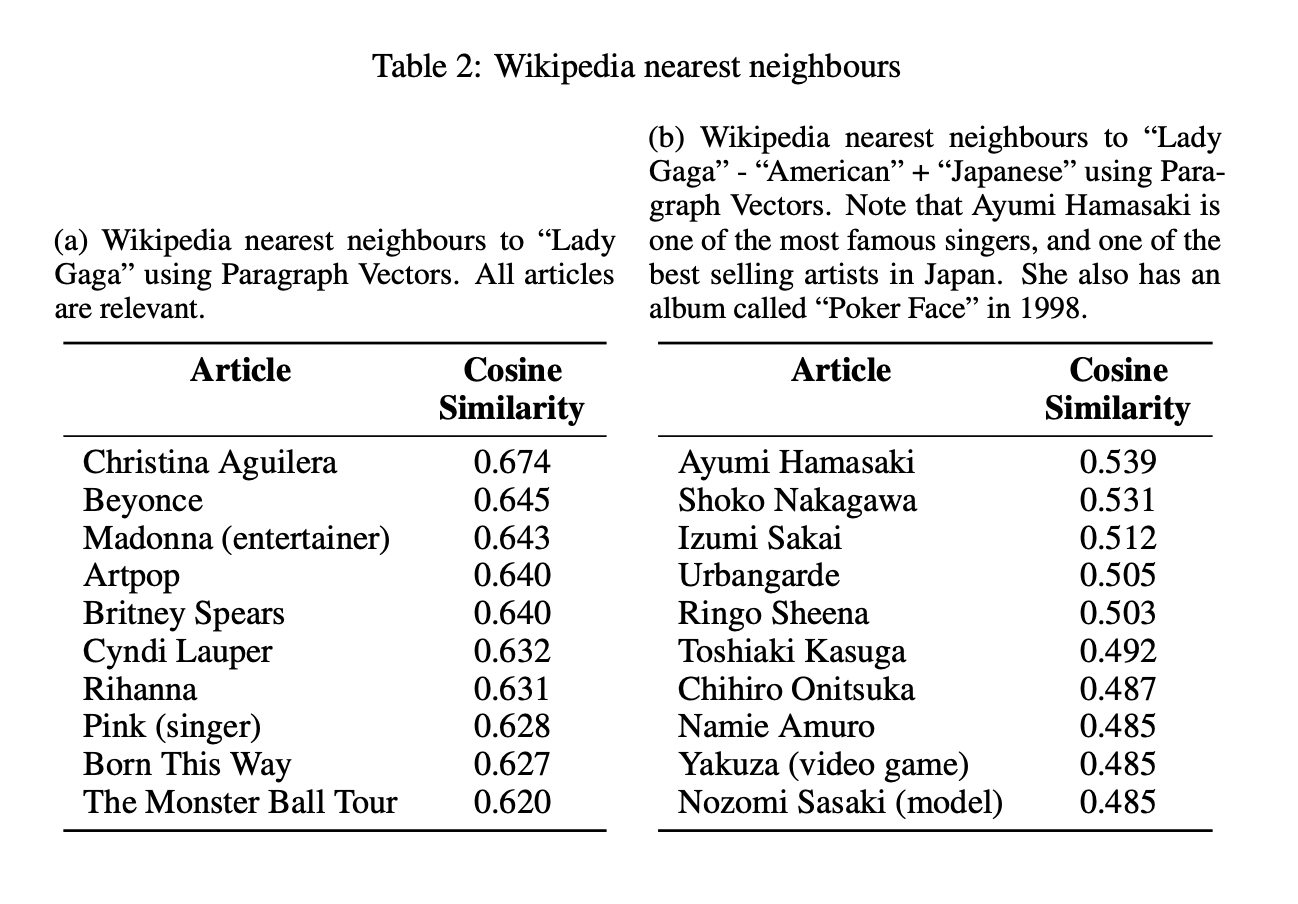
Table2 (b)는 Paragraph vector("Lady Gaga") - Word vector("American") + Word vector("Japanese")의 결과를 보여줍니다.
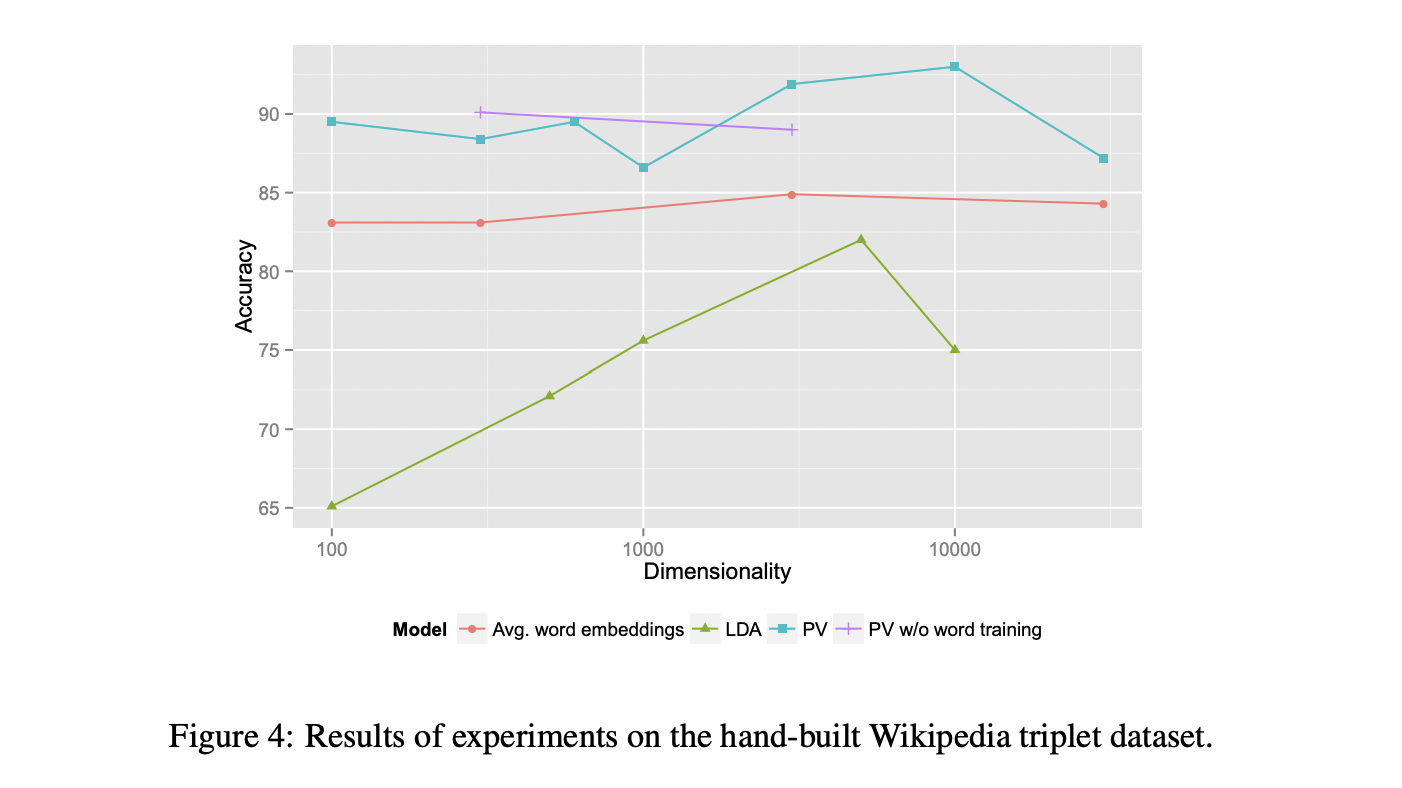

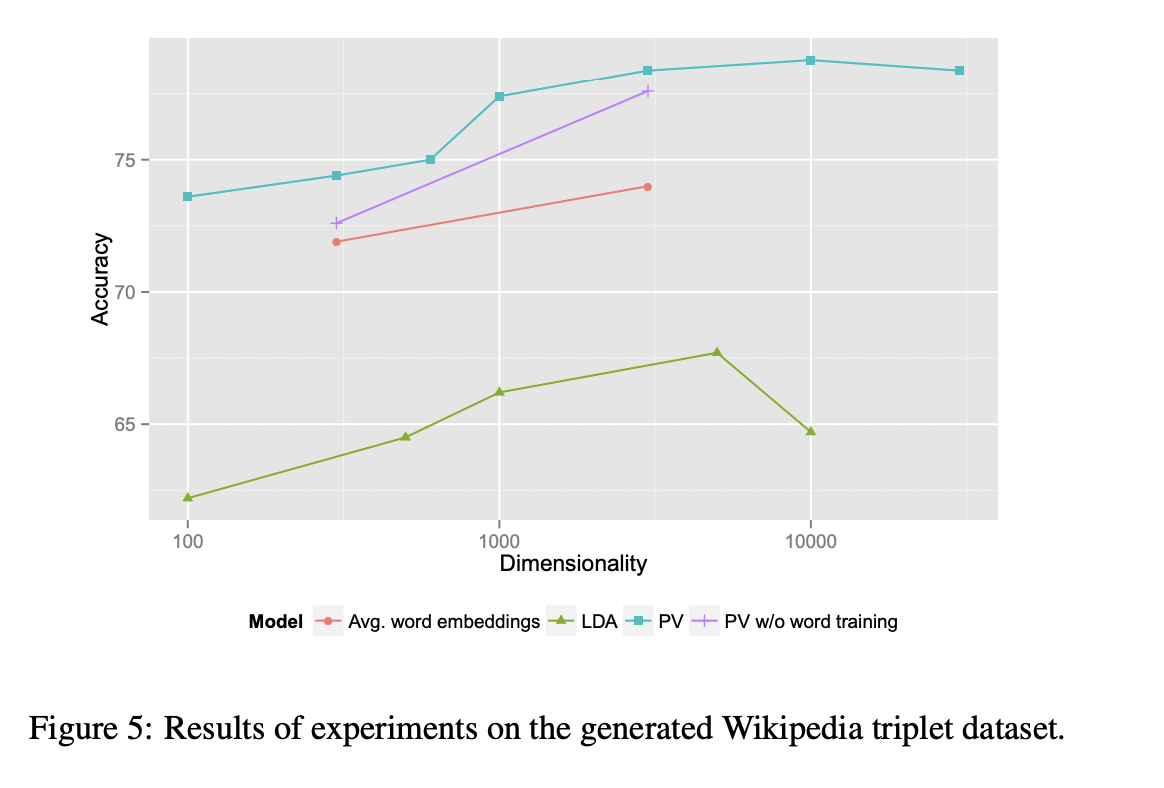
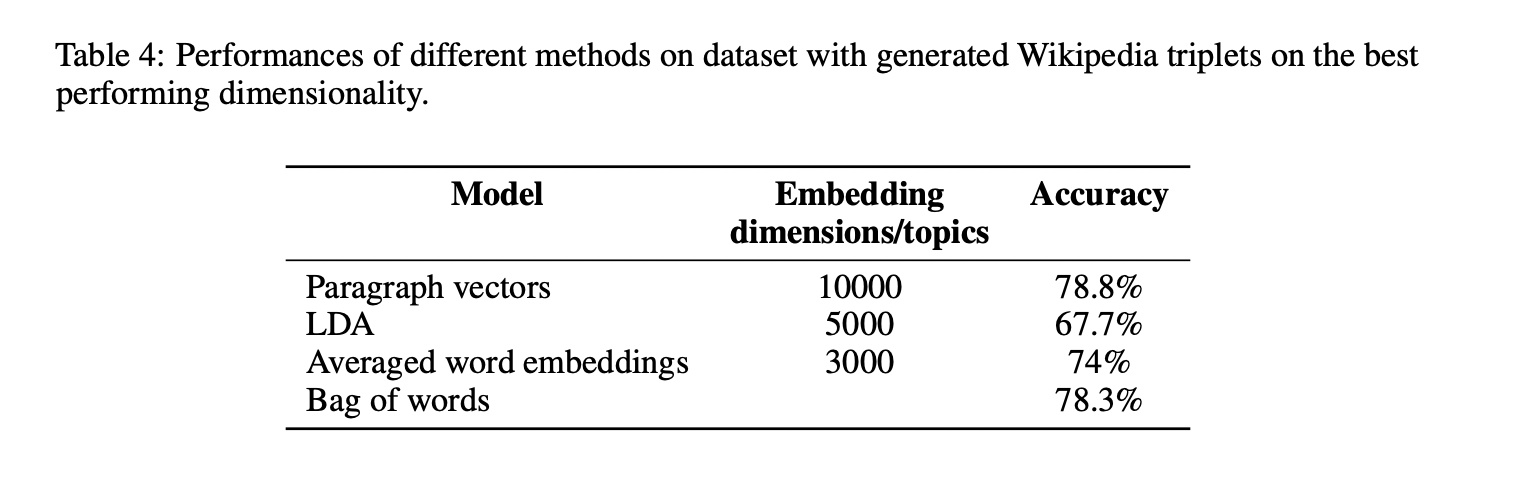
Table3과 Table4의 결과에서 볼 수 있는 것처럼 Paragraph Vector의 성능이 LDA보다 좋았습니다.
Figure4와 Figure5를 통해서 word vector와 함께 학습하는 것이 Paragrph vector의 quality를 높여주는 것을 확인할 수 있습니다.
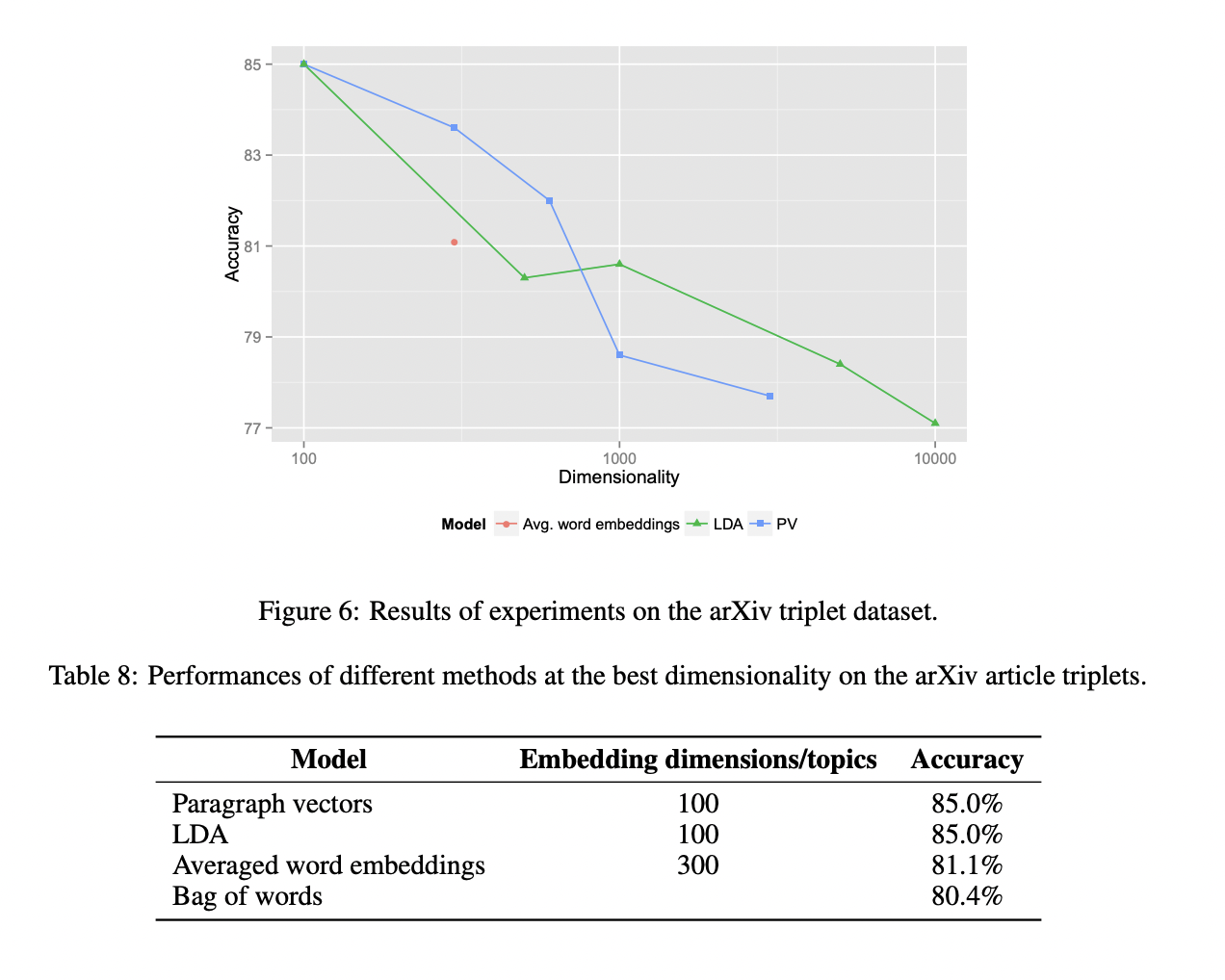
3.2 Performance of Paragraph Vectors on arXiv articles


4. Discussion
해당 논문에서는 Paragraph Vectors가 long pieces of texts들 간의 의미적 유사도를 측정하기위해 효과적으로 사용될 수 있다는 것을 보임으로써 새로운 결과를 얻었습니다. Paragraph Vectors는 Wikipedia data에서는 LDA보다 의미적 유사도를 측정하는데 좋은 성능을 보여주었습니다. arXiv data에서는 LDA와 좋은 성능이 동일하였습니다.
Paragraph Vectors는 word vector와 마찬가지로 vector operation이 가능했습니다. 이를 활용하여 추천 등에 활용할 수 있습니다.
