Word2Vec으로 알려진 Skip-gram with Negative sampling 방식을 추천시스템에 적용한 Item2vec을 소개하는 논문입니다.
[Abstract]
많은 Collaborative Filtering(CF) 알고리즘은 item 유사도를 구하기위해 item-item 관계를 분석하는 측면에서 item-based입니다. NLP에서 word latent representation을 위한 방법으로 word2vec이라고 불리는 Skip-gram with negative sampling(SGNS)가 좋은 성능을 보이고 있습니다. 해당 논문에서는 item-based CF에서도 같은 방법을 사용할 수 있는지 보여줍니다. SGNS에 영향을 받아 item을 latent space에 embedding시키는 item2Vec을 소개합니다. 이 방법은 user 정보가 없더라고 item-item 관계를 추론할 수 있습니다.
1. Introduction and Related Work
Item 유사도를 계산하는 것은 현대 recommender system의 중요한 부분입니다. 많은 recommendation 알고리즘들이 user와 item을 낮은 차원으로의embedding을 학습하는 것에 집중하고 있지만 item 유사도를 계산하는 것이 그 목적입니다. 해당 논문은 낮은 차원의 공간으로 item을 embedding하면서 간과된 item 유사도를 학습을 다룹니다.
Single item recommendation은 전통적인 user-to-item recommendation과 차이가 있습니다. 왜냐하면 주로 특정 item의 explicit user interest에서 다뤄지거나 구매하고자 하는 explict user intent에서 다뤄지기 때문입니다. 그러므로 item 유사도를 기반에 둔 single item recommendation은 떄떄로 높은 Click-Through Rates(CTR)을 갖고 판매와 수익의 많은 부분을 담당하고 있습니다.
Item 유사도는 item-item 관계로부터 representation을 학습하는 것을 목표로하는 item-based CF 알고리즘의 또 다른 핵심입니다.
NLP에서 neural embedding 방법들의 발전이 있었습니다. Word2Vec으로 알려진 Skip-gram with negative sampling(SGNS)는 단어나 관용구를 낮은 차원으로 mapping하고 단어들 사이의 의미적 관계를 잡아냅니다.
해당 논문에서는 SGNS를 item-based CF에 적용하는 방법을 제안합니다. 다른 분야에서 성공적인 결과를 보였기에 약간의 수정을 거친 SGNS는 collaborative filtering dataset에서 서로 다른 item 사이의 관계를 잡아낼 수 있다고 제안합니다. 해당 방법은 item2vec으로 이름 붙이고 item2vec이 SVD를 기반에 둔 item-based CF 방법과 견줄만한 유사도를 만들어 내는 것을 보여줍니다.
2. Skip-gram with Negative Sampling
SGNS는 단어와 문장 내 해당 단어의 주변 단어들과의 관계를 포착하는 것을 목표로 합니다.



SGNS 관련 자세한 내용은 SGNS 소개 paper 에서 확인할 수 있습니다.
3. Item2Vec - SGNS for Item Similarity
해당 논문은 item-based CF에 SGNS를 적용합니다. CF data에 SGNS를 적용은 sequence of words가 set or basket of items과 동일하다는 점을 고려했을 때 직관적으로 와닿습니다. 지금부터 word 대신 item을 사용합니다.
Sequence에서 set으로 옮겨갔기 때문에 공간 / 시간 정보는 잃게됩니다. 이러한 정보를 버리기로 선택했기 때문에 동일한 set을 공유하는 item들은 static environment에서 동일하다고 여깁니다.
공간 정보를 무시하기 때문에 동일한 set의 item pair를 positive sample로 고려합니다.
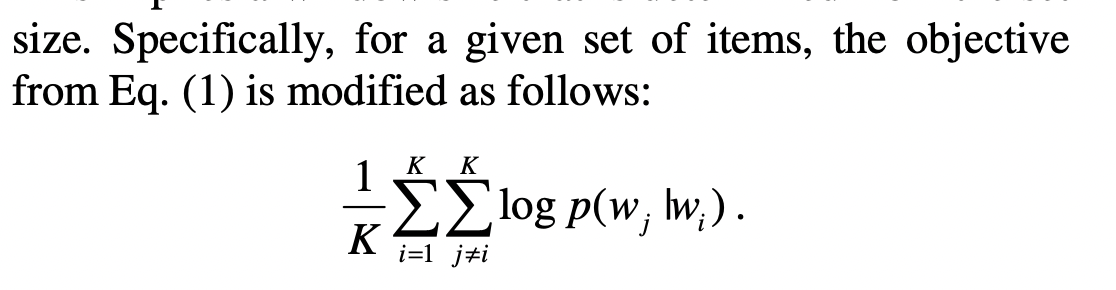
해당 논문에서 u_i를 i번째 item의 representation으로 사용하고 item간의 유사도는 cosine similarity를 사용합니다.
4. Experimental Setup and Results
실험 결과 비교를 위한 baseline으로 item-item SVD를 사용합니다.
4.1 Datasets
- User-artist data -> Microsoft Xbox Music service
- Orders of products -> Microsoft Store
4.2 System and Parameters
모든 dataset에 item2vec을 활용합니다.
Stochastic gradient decent & 20 epochs & negative sampling value = 20 & dimension parameter = 100(music) and 40(store)
4.3 Experiments and Results

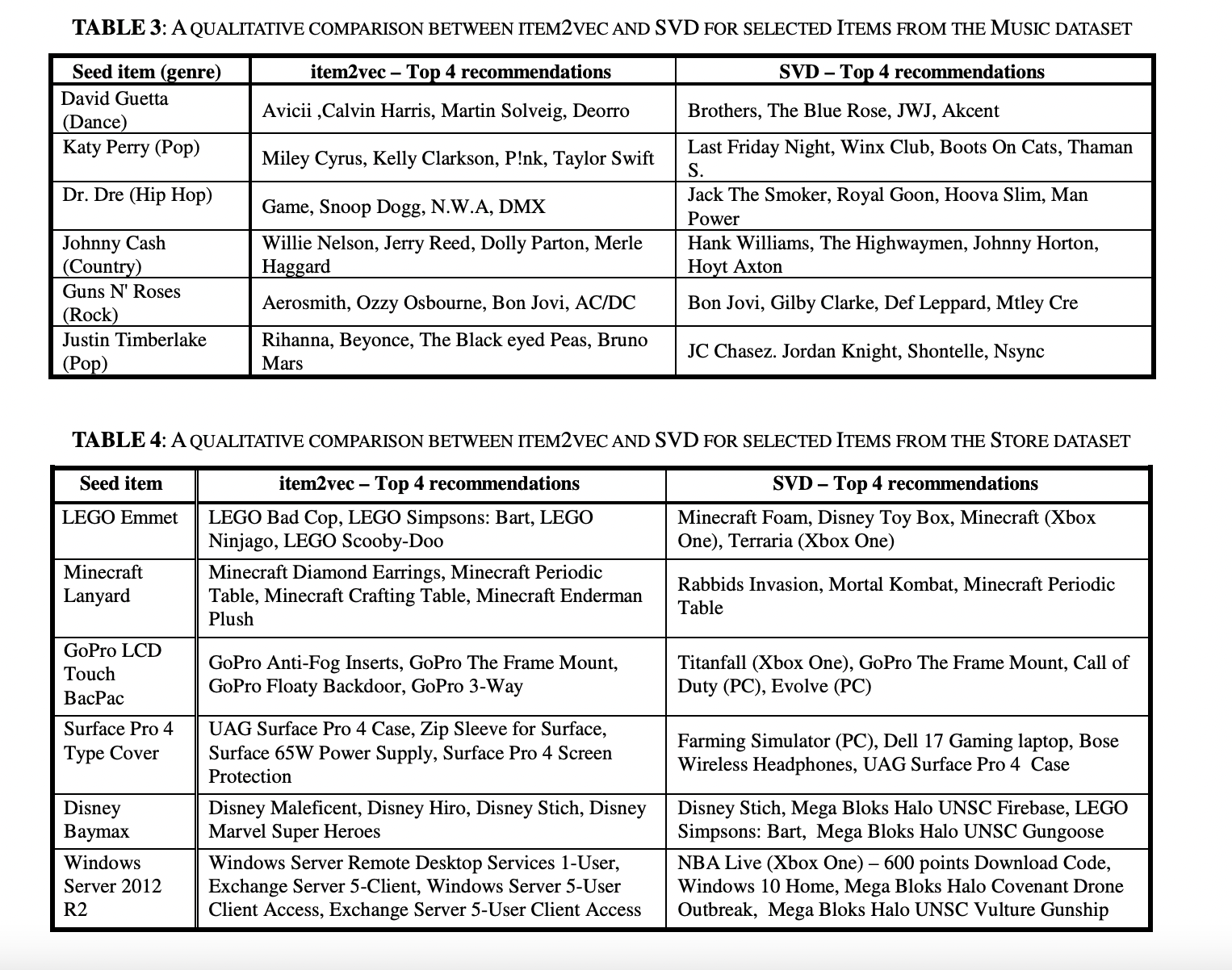
그림에서 볼 수 있듯이 item2vec이 svd보다 좋은 clustering 결과를 갖습니다.
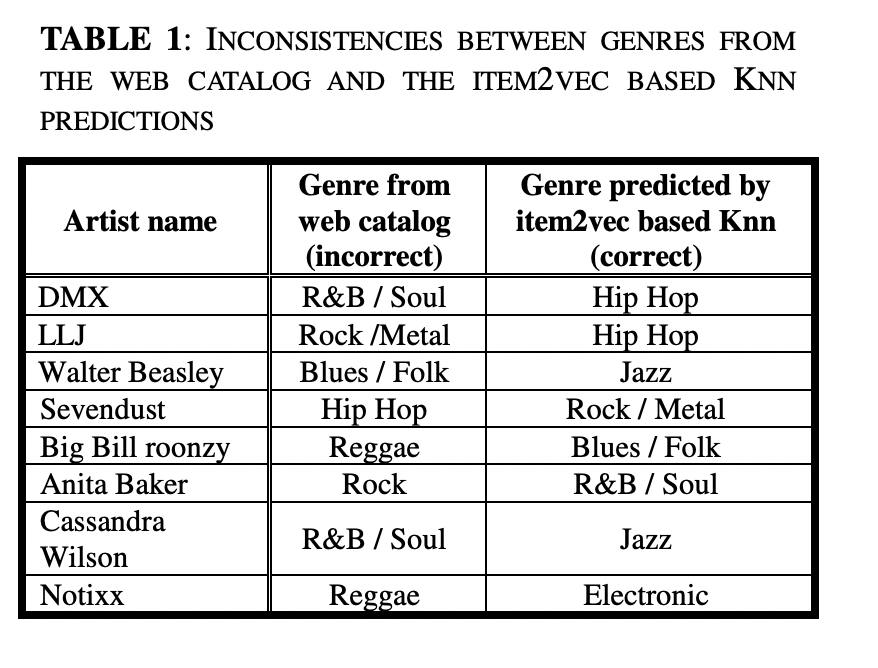
Table1은 검색을 했을 때 artist의 장르가 일정하지 않은 예시입니다. 이런 예시들에 대해 Item2vec을 활용하여 knn을 사용했을 때 적절한 장르를 제시할 수 있습니다.
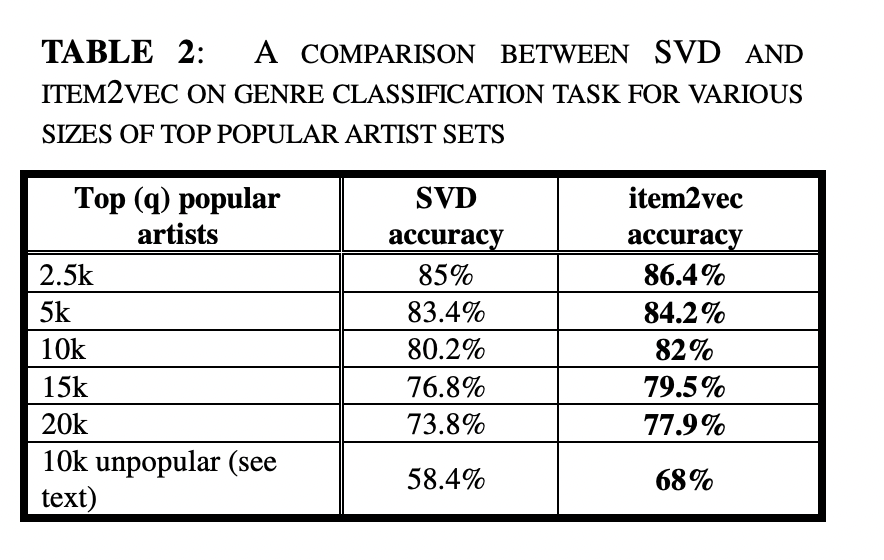
Table2는 knn의 k 값을 8로 두었을 때 item2vec의 결과가 SVD보다 좋은 것을 보여줍니다.
5. Conclusion
해당 논문은 item-based collaborative filtering을 위한 neural embedding 알고리즘은 item2vec을 소개합니다. Item2vec은 SGNS의 약간 수정된 버전으로 볼 수 있습니다.
SVD-based item similarity model과 비교하였을 때 item2vec은 정성, 정량적으로 모두 뛰어난 결과를 보였습니다. Item2vec이 subsampling과 negative sampling을 모두 사용하였기때문에 좋은 성능을 보였다고 해당 논문은 이야기합니다.
