Text classification, Document Embedding과 같은 NLP task 뿐만 아니라 recommendation, knowledge graph에도 폭 넓게 활용할 수 있으며 좋은 성능을 보이는 Embedding model인 StarSpace를 소개하는 논문입니다.
[Abstract]
논문에서는 StarSpace로 이름지어진 다양한 종류의 문제를 해결할 수 있는 general-purpose neural embedding model을 소개합니다. StarSpace는 주어진 문제에따라 dicrete feature들로 이루어진 entity들을 embedding하고 각각을 비교합니다. StarSpace는 경쟁력있는 현재의 다양한 모델들과 비교했을 때 뒤쳐지지 않는 오히려 더 뛰어난 성능을 보였습니다.
1. Introduction
해당 논문에서 StarSpace를 소개합니다. StarSpace는 아래 예시와 같은 다양하고 넓은 분야의 문제를 해결할 수 있는 neural embedding model입니다.
- Text classification or other Labeling tasks
- Ranking of sets of entities
- Collaborative filtering-based recommendation
- Content-based recommendation where content is defined with discrete features
- Embedding graphs
- Learning word, sentence or document embeddings
실험을 통해 좋은 효과를 보이는 모델들과 비교했을 때 유사하거나 더 좋은 성능을 StarSpace는 보여줬습니다.
StarSpace는 task of ranking이나 classification of interest를 위한 entity들의 집합들 사이의 관계로부터 discrete feature representation를 통해 entity embedding을 학습하는 방식으로 동작합니다. 일반적인 경우에 StarSpace는 서로 다른 종류의 entity들을 vectorial embedding space에 embedding시킵니다. StarSpace의 이름대로 star("*")는 모든 타입을 의미하고, space는 하나의 공통적인 공간을 의미하여 모든 타입을 해당 공간에서 비교할 수 있게됩니다. StarSpace는 query entity, document, object가 주어졌을 때 각각의 rank를 학습합니다.
해당 논문에서는 6가지 서로 다른 task를 통해 StarSpace의 성능을 확인합니다.
2. Related Work
Embedding(Latent text representation)은 큰 말뭉치에서 비지도방법을 통해 학습되는 word, document들의 vectorial representation입니다. 해당 분야에서는 neural embedding은 NLPM, Word2Vec, FastText 등을 통해 연구되고 있습니다.
Supervised embedding 분야에서는 SSI, WSABIE, TagSpace, FastText와 같은 방법들이 NLP와 검색에서 좋은 성능을 보였습니다.
Recommendation 분야에서는 embedding은 SVD, SVD++ 등을 통해서 큰 성공을 보였습니다. 관련된 방법의 대부분은 주로 user id와 movie id들이 각각의 embedding 값을 갖는 collaborative filtering setup에 집중하였습니다. 그로인해 새로운 사용자나 아이템들은 포함될 수 없었습니다. 해당 논문에서는 StarSpace가 collaborative filtering setup과 사용자와 아이템이 feature들로 표현되어 고정된 set만 다루는 것이 아닌 out-of-sample extenstion이 가능한 content-based setting을 동시에 어떻게 다루는지 보여줍니다.
또한, StarSpace가 knowledge based의 link prediction에서도 좋은 성는을 갖는다는 것을 보여줍니다.
3. Model
StarSpace는 fixed-length dictionary에서 나오는 discrete feature set들로 표현되는 entitiy들을 학습하는 과정들로 구성되어 있습니다. 예를들어, document나 sentence와 같은 entity는 bag-of-word나 n-gram을 통해서 표현되며 user는 해당 사용자가 선호도를 보인 documents, movie, item의 집합을 통해 표현됩니다. 중요한 점은 StarSpace는 다른 종류의 entity들 간의 비교에 있어 자유롭다는 것입니다. user entity를 item entity와 비교하면 recommendation이 되고 document entity를 label entity와 비교하면 text classification이 됩니다. 이런 비교가 가능한 이유는 각각의 entity를 모두 동일한 space로 embeding하는 것을 학습하기 때문입니다.

StarSpace는 다른 embedding 모델들과 동일하게 각각의 discrete feature에 d-차원 vector를 assign하는 것을 시작으로합니다.

- Positive entity pairs (a,b)는 E+ set에서 뽑힙니다.
- Negative entity b_i-는 E- set에서 뽑힙니다. 해당 논문에서는 k-negative samplig 전략을 사용합니다. k 개의 negative pair들을 통해 각각 batch마다 update를 진행합니다.
- sim(,)인 similarity function으로는 cosine similarity와 inner product를 사용합니다. 적은 수의 label feature에서는 두 방식의 차이가 없지만 수가 많을 때는 cosine similarity가 효과가 좋았습니다.
- loss function L_batch는 positive pari와 negative pair를 비교합니다. Margin ranking loss나 negative log loss of softmax를 사용합니다.
Adagrad를 사용하여 SGD(Stochastic gradient descent)를 통해 optimize를 해줍니다.
누군가는 학습된 sim(,)를 entity간의 유사도를 측정하기위해 활용할 수 있습니다. 또는 일반적으로, 유사도를 통해 entity를 정렬하여 ranking으로 활용합니다. 또 다른 방식으로는 또 다른 downstream task를 위해 embedding vector를 직접 활용할 수도 있습니다.
- Multiclass Classification : Positive pair는 문서와 해당 문서의 label(singleton feature)이되며, negative pair는 해당 문서의 label이 아닌 다른 label이 됩니다.
- Multilabel Classification : 각각의 문서와 해당하는 여러개의 positive label 중 하나가 뽑힙니다.
- Collaborative Filtering-based Recommendation : 사용자와 해당 사용자가 선호하는 아이템이 positive pair로 뽑히고 다른 관련 없는 아이템이 negative pair로 뽑힙니다.
- Collaborative Filtering-based Recommendation with out-of-sample user extension : Positive pair는 한 명의 사용자에 대해 해당 사용자의 아이템 중 하나를 제외한 나머지와 제외된 하나가 뽑히게 된다.
- Content-based Recommendation : 사용자를 특정할 수 있는 아이템들(다양한 feature들을 통해 표현됨) 중 하나를 제외한 것들과 제외된 하나를 통해서 학습을 진행한다.
- Multi-Relational Knowledge Graphs
- Information Retrieval and Document Embeddings : Supervised인 검색에서는 검색 단어와 해당 단어와 관련있는 문서를 positive pair로 관련없는 문서를 negative pair로 뽑는다. Unsupervised에서는 문서에서 임의의 키워드를 뽑고 해당 문서의 나머지 단어 중 하나를 positive pair로 정한다. 2가지 모두 document embedding을 학습하는 데 사용된다.
- Learning Word Embeddings : Word2Vec과 유사한 방식을 통해서 StarSpace는 word embedding을 학습할 수 있습니다.
- Learning Sentence Embeddings : Sentence embedding이 가능하면 학습된 word embedding 결과를 통해서 sentence embedding을 만들어내는 것은 비효율적입니다. 같은 문서에서 나오는 문장을 Positive pair로 정하고 다른 문서에서 나온 문장을 negative pair로 정합니다. 같은 문서에서는 의미적 유사도가 높을거라는 가정하에서 출발되는 것입니다.
- Multi-Task Learning
4. Experiments
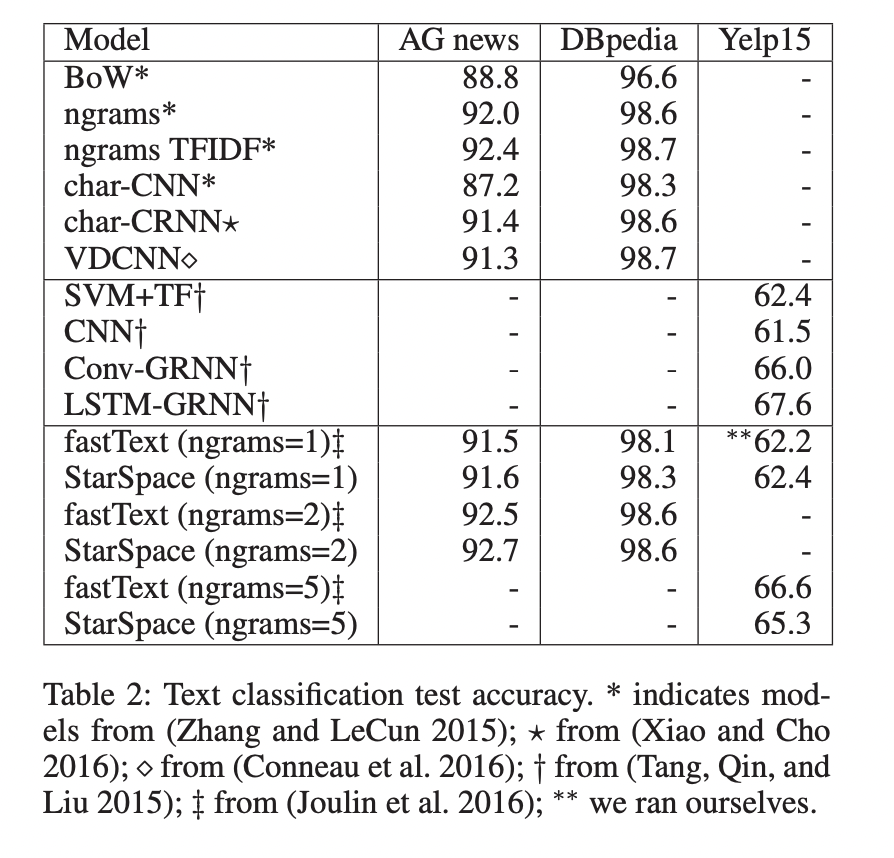
Text Classification
Text Classification을 위해 StarSpace를 사용하고 결과를 fastText를 비롯한 좋은 성능을 보이는 다른 모델들과 비교하였습니다. 공정한 비교를 위해 fastText와 동일한 사전을 사용하고 같은 n-gram과 pruning을 활용하였습니다. Embedding vector의 차원은 10으로 통일했습니다.

Content-based Document Recommendation
과거 선호하는 문서 내역을 가진 사용자에게 새로운 문서를 추천하는 task를 수행합니다. (n-1)개의 클릭한 자료를 바탕으로 10,000개의 후보들 중에서 순위를 정하여 n번째 클릭할 자료를 예측합니다.
이러한 task는 분류 task가 아니기때문에 supervised classification model을 직접 활용할 수 없습니다. 하지만 StarSpace는 직접적으로 활용할 수 있으며 이는 StarSpace의 큰 장점 중 하나입니다.
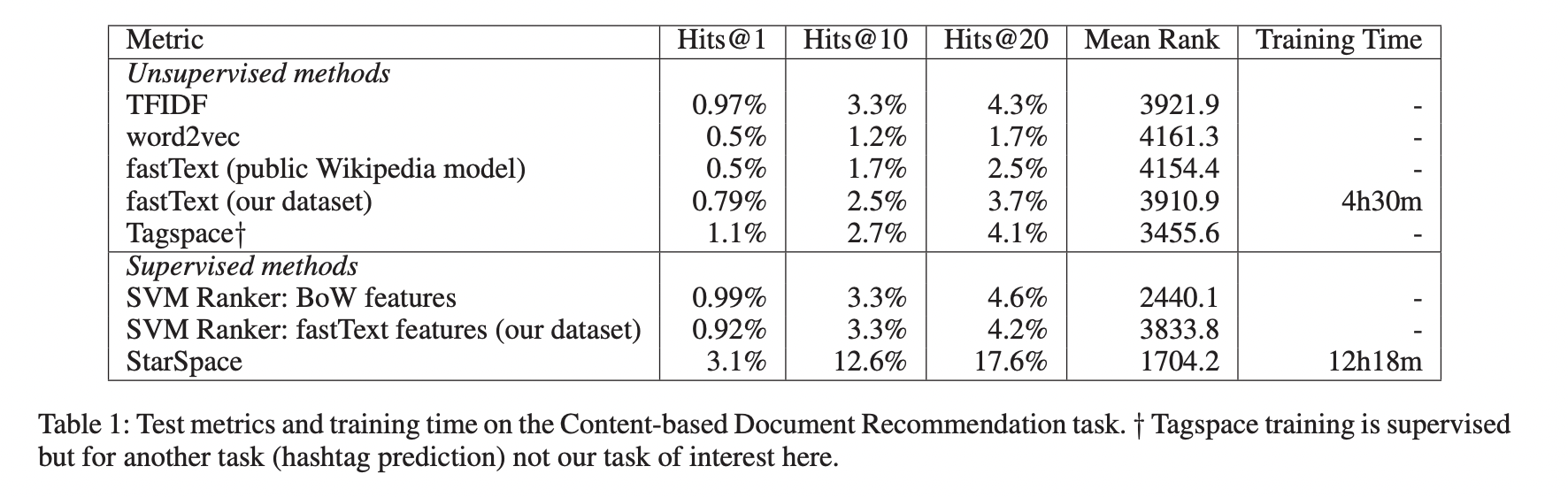
Document recommendation task에 있어서 word embedding에 unsupervised methods는 StarSpace보다 성능이 좋지 않다는 것을 확인할 수 있습니다.
Link Prediction: Embedding Multi-relation Knowledge Graphs
논문에서는 StarSpace가 knowledge representation task에서도 활용될수 있다는 것을 보여줍니다.

Influence of k
논문에서는 negative search example의 갯수에 따라서 모델의 복잡도가 어떻게 되는지 설명합니다. dim은 50으로 정하고 모델 당 최대 학습시간을 1시간으로 고정하였습니다. 해당 시간 안에 알고리즘이 수행할 수 있는 학습 epoch 수를 기록하였고 k값에 따른 성능 지표를 기록하였습니다.

Wikipedia Article Search & Sentence Matching
StarSpace를 Wikipedia article 검색과 sentence match에 활용합니다.
- Task1 : Wikipedia article의 문장 하나를 search query로 주어졌을 때 해당하는 문서를 찾는 task
- Task2 : Wikipedia article에서 임의의 2개 문장을 선택한 후, 하나를 search query로 했을 때 나머지 1개의 문장이 같은 문서에서 나왔는지 판단하는 task
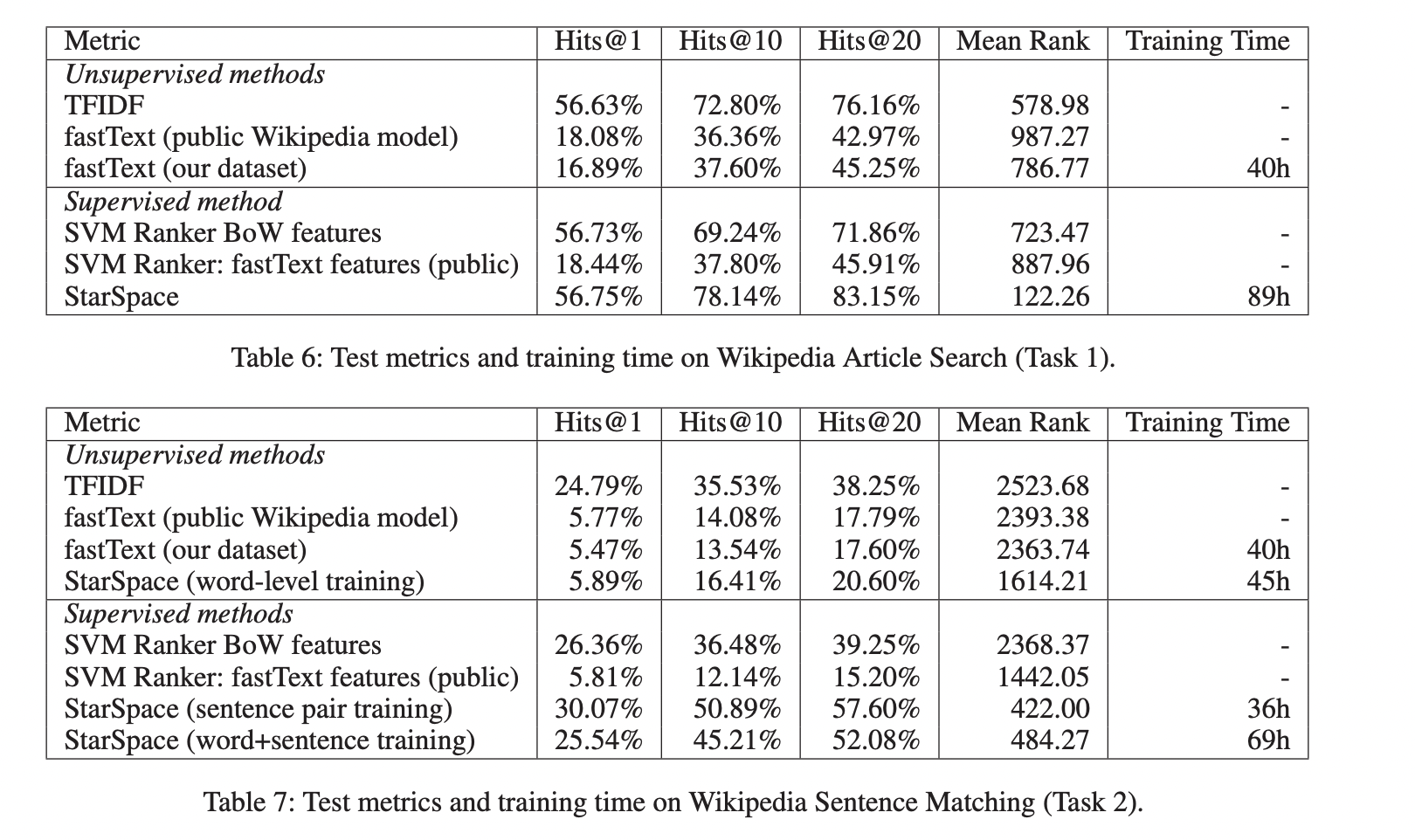
아래 결과를 통해 fastText는 의미적으로 대략적으로 맞는 결과를 보이지만 정확도가 부족했습니다. 하지만 StarSpace는 phrase간의 관계를 이해하여 검색을 할 수 있었습니다.

Learning Sentence Embeddings
StarSpace을 통해 만들어진 sentence embedding의 성능을 평가하기 위해 SentEval을 사용하였습니다.

5. Discussion and Conclusion
해당 논문에서는 StarSpace라는 embedding 방법이자 entity 사이의 관계를 사용하여 entity 간의 순위를 정하는 방법론을 소개했습니다. StarSpace는 아래의 task들에대해 성능이 좋았다는 것도 보였습니다.
- Text Classification / Sentiment Analysis
- Content-based Document recommendation
- Link Prediction in Knowledge Bases
- Wikipedia Search and Sentence Matching tasks
- Learning Sentence Embeddings
StarSpace는 논문에서 소개하지 않은 다른 classification, ranking, retrieval과 같은 task에 잘 적용될 것입니다. 기존 embedding model들에 비해 StarSpace가 가질 수 있는 장점은 다음과 같습니다.
- 분류를 하거나 순위를 매기고자 하는 label을 표현하는 데 활용되는downstream prediction / ranking task에 따라 바로 학습이 가능한 features 사용이 자유롭다.
- Task에 적합한 서로 다른 positive, negative selection 방법을 활용할 수 있다.
