Fasttext를 소개하는 논문입니다. 단어를 문자(알파벳) 단위로 쪼개 skip-gram을 적용하였으며, 그렇기 때문에 좋은 성능의 out-of-vocabulary word vector를 얻을 수 있습니다.
[Abstract]
라벨링이 되어 있지 않는 큰 말뭉치에서 학습도는 continuous word 표현은 많은 자연어 처리 task에서 유용합니다. 이러한 표현을 학습하는 유명한 모델들은 대부분 단어의 형태학적 요소를 고려하지 않습니다. 이는 매우 큰 사전과 희소한 단어가 많을 때 단점이 될 수 있습니다. 해당 논문에서는 skip-gram 모델을 기반으로 하며 각 단어들은 단어의 n-gram 문자를 통해 표현됩니다. n-gram 문자를 통해 표현된다는 것의 의미는 n-gram 문자들의 합을 통해 단어를 표현한다는 의미입니다. 소개되는 방법은 빠르고, 학습 데이터에 존재하지 않는 단어를 표현할 수 있다는 특징이 있습니다.
1. Introduction
단어의 continuous represetaion 학습은 자연어 처리에 있어 깊은 역사가 있습니다. 이러한 표현방식은 동시등장 통계량을 사용하여 라벨링 되지 않은 대량의 말뭉치에서 구해집니다.
신경망을 활용하는 방식에서는 단어의 왼쪽에 있는 2개단어, 오른쪽에 있는 2개 단어를 통해 타깃 단어 예측을 통해 feed-forward 신경망을 학습하여 word embedding을 얻습니다.
대부분의 방식에서는 parameter를 공유하지 않은 채로 사전 내의 각 단어들을 서로 다른 vector로 표현합니다. 그렇기 때문에 형태학적 요소가 풍부한 언어(morphologically rich language)에 있어 중요한 단어 내부의 구조를 무시하게 됩니다. 형태학적 요소가 풍부한 언어에서는 단어를 만드는 것이 규칙을 통해 이루어지기 때문에 음소 단위의 정보를 활용한다면 향상된 vector를 얻을 수 있습니다.
해당 논문에서는 n-gram 문자의 표현 학습과 단어를 해당 n-gram 문자 표현의 합으로 표현하는 방법을 제안합니다. 주된 기여는 continuous skip-gram 모델의 확장을 했다는 점으로 볼 수 있습니다.
2. Related work
Morphological word representation
단어 표현에 형태학적 정보를 포함시키기 위한 많은 시도들이 있었습니다. 그 중 하나로 단어를 특징의 집합으로써 표현하는 factored neural language model이 있습니다. 단어의 특징은 형태학적 정보를 포함할 수 있습니다. 최근에는 형태소로부터 단어의 표현을 유도하는 많은 시도들이 있습니다. 한 가지 방법으로는 해당 논문에서는 시도하지 않은 단어를 형태소로 분리하는 것에 의존하는 방식이 있습니다. 또 다른 방식으로는 형태학적으로 유사한 단어를 유사한 표현을 갖도록 학습하는 방식이 있습니다. 해당 논문과 유사한 방식으로 볼 수 있는 다른 방식에는 음소 4-gram을 SVD를 통해 학습한 후 4-gram 표현을 합하는 방식이 있고, n-gram count vector로 표현하려는 시도도 있었습니다.
Character level feature for NLP
문자 단위의 모델로는 recurrent neural network, convolutional neural network를 활용한 것들이 있습니다. Restricted 볼츠만 머신 기반의 언어모델도 있으며 기계번역에서는 rare 단어 표현을 위해 subword를 활용하기도 합니다.
3. Model
해당 논문에서는 형태학적 요소를 고려한 단어 표현방식을 학습하는 모델을 소개합니다. 형태소를 subword unit을 고려하여 모델링하였으며 단어를 n-gram 문자 표현의 합을 통해 표현하였습니다.
3.1 General model
간단하게 해당 논문의 기반이 된 continuous skip-gram 모델을 소개하겠습니다. Skip-gram 모델의 목적은 단어 각각의 vetor를 학습하는 것입니다. Distributional hypothesis에 영감을 받아 단어 표현은 같은 문맥에 등장하는 단어를 잘 예측하는 방식을 통해 학습됩니다. Skip-gram 모델의 목적은 아래의 log-likelihood를 최대화 시키는 것입니다.
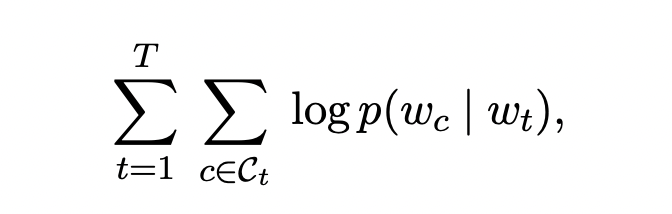
이 때 문맥 C_t는 단어 w_t 주변에 있는 단어들의 index입니다.
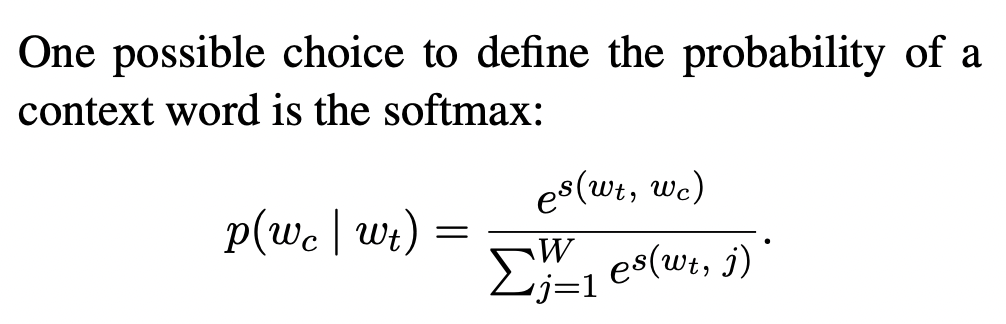
이 때 scoring function s는 (word, context) 쌍에서 점수를 얻어 실수 값으로 표현하는 함수입니다.
문맥을 예측하는 문제는 binary classification 문제로 바꿔 생각할 수 있습니다. 문제를 바꾸게 된다면, 목적은 문맥 내부에 해당 단어가 존재하는 지 여부를 예측하게 됩니다. Positive sample과 negative sample을 모두 뽑고, 문맥 c에 대해 아래의 negative log-likelihood식을 얻습니다.
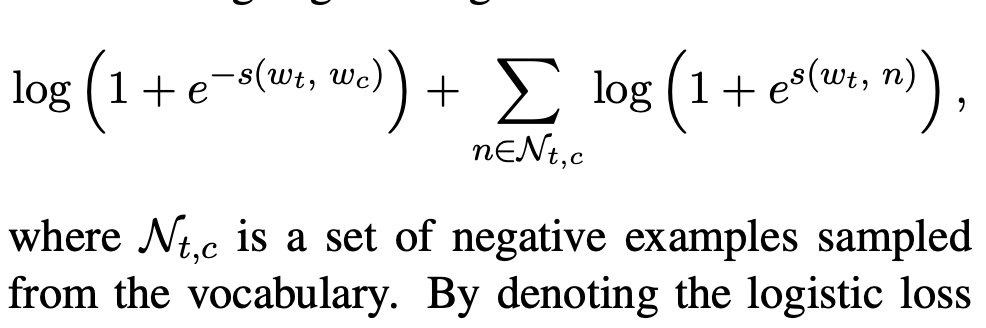
타깃 단어 w_t와 문맥 단어 w_c 사이의 scoring function s의 parameter를 단어 vector로 활용할 수 있습니다. u_w와 v_w를 각각 input, output vector라고 합니다. 이 때 타깃 단어와 문맥 단어의 score는 scalar product를 통해 계산될 수 있습니다.
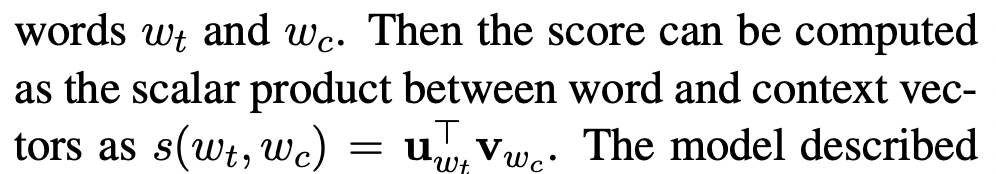
3.2 Subword model
각 단어를 서로 다른 vector로 표현함으로써 skip-gram 모델은 단어 내부 구조를 무시합니다. 해당 논문에서는 단어 내부 구조를 고려하기 위한 다른 scoring function s를 소개합니다.
각 단어 w는 n-gram 문자로 표현됩니다. 다른 문자집합과 접두어, 접미어를 구분할 수 있도록 단어 앞, 뒤로 <, >와 같은 special boundary symbol을 추가합니다. 또한 n-gram 문자 집합에 원본단어 w를 포함시킵니다.

N-gram에서 n값은 3이상 6이하의 값을 사용합니다.
크기 G를 갖는 n-gram 사전이 있다고 가정합시다. 단어 w의 n-gram 집합 G_w는 전체 n-gram 사전의 부분집합이 됩니다. z_g를 각각의 n-gram g의 벡터라고 합시다. 해당 논문에서는 단어를 해당 단어의 n-gram들의 vector들의 합으로 표현합니다. 새롭게 얻은 scoring function은 아래와 같습니다.
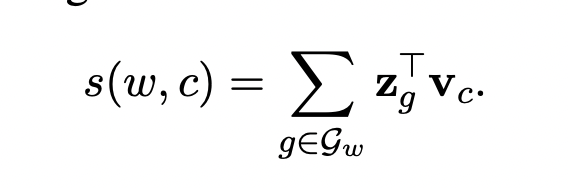
이런 단순한 모델은 단어 표현들을 단어들마다 공유할 수 있게 해줍니다. 이를 통해 자주 등장하지 않은 단어에 대해서도 신뢰성 있는 표현을 얻을 수 있습니다.
4. Experimental setup
4.1 Baseline
4.2 Optimization
- stochastic gradient descent on the negative log likelihood
- linear decay of the step size
4.3 Implementation details
- word vector 차원 = 300
- 1개의 positive sample 당 5개의 negative sample
- window size = 1~5
- 학습 데이터에 5회 이상 등장한 단어들을 대상으로 학습
- step size = 0.025
4.4 Datasets
- Wikipedia data
5. Results
5.1 Human similarity judgement
사람의 판단결과와 vector 사이의 cosine similarity 값의 스피어만 상관계수를 계산하여 word similarity/relatedness task를 통해 해당 논문의 표현방식을 평가합니다.
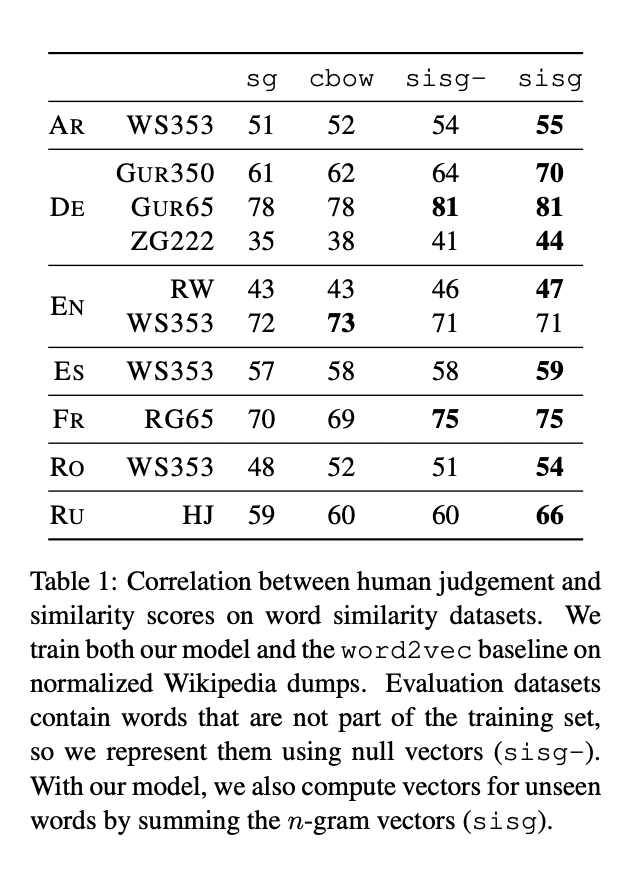
해당 논문에서 제시하는 모델은 subword 정보를 사용하기 때문에 OOV에 대해서도 적당한 표현 방식을 얻을 수 있습니다. OOV vector를 Null로 둔 SISG-와 해당 논문의 방식을 통해 OOV vector를 표현한 SISG를 비교하였을 때 SISG의 성능이 더 좋은것을 볼 수 있습니다. 이는 n-gram 문자 정보를 활용하는 것의 이점이 있음을 반증합니다.
5.2 Word analogy tasks

형태학적 정보는 문법 task의 성능을 높이는 것을 확인할 수 있습니다. 또한 baseline 모델과 비교하였을 때 형태학적 요소가 많은 언어들에 대해 더욱 큰 성능 향상이 있음을 볼 수 있습니다.
5.3 Comparison with morphological representation
해당 논문의 방식과 과거 subword 정보를 포함한 word vector 모델과의 성능 비교를 진행하였습니다.

5.4 Effect of the size of the training data
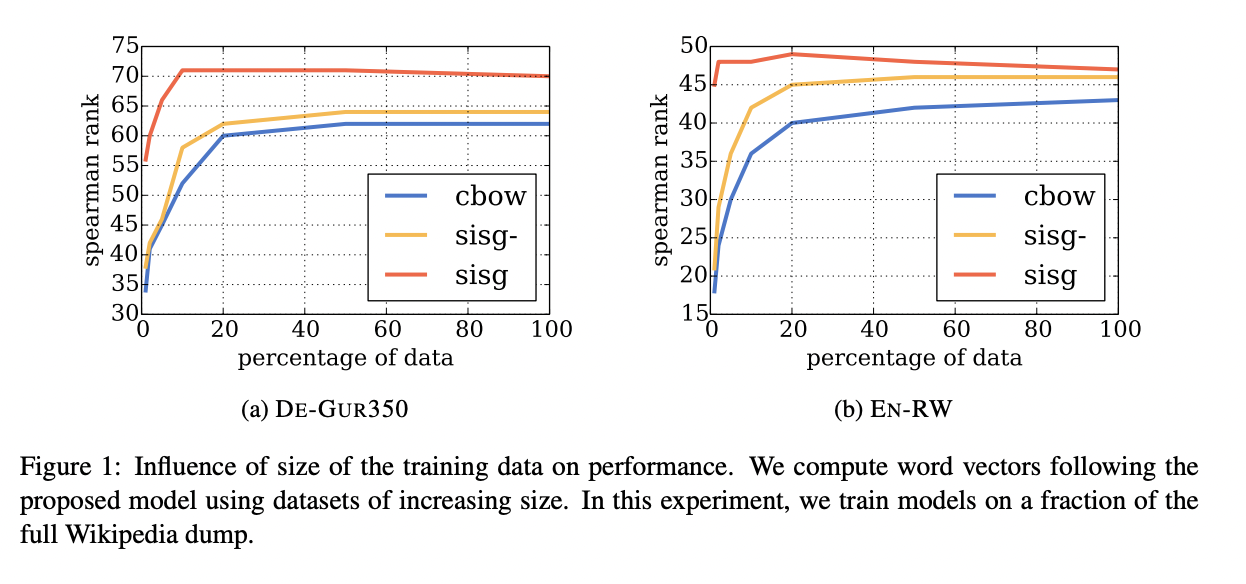
OOV 비율은 dataset이 줄어들 수록 커지게됩니다. 그러므로 SISG-와 CBOW 성능은 dataset이 줄어들 수록 나빠집니다. SISG는 baseline 보다 성능이 좋지만, dataset이 늘어날 수록 CBOW의 성능은 매우 빠르게 증가하지만 SISG의 성능은 금방 일정 수준에 도달하여 증가하지 않음을 알 수 있습니다.
해당 논문에서 제안한 방식은 매우 적은양의 dataset만으로도 충분한 성능을 낼 수 있습니다.
5.5 Effect of the size of n-grams
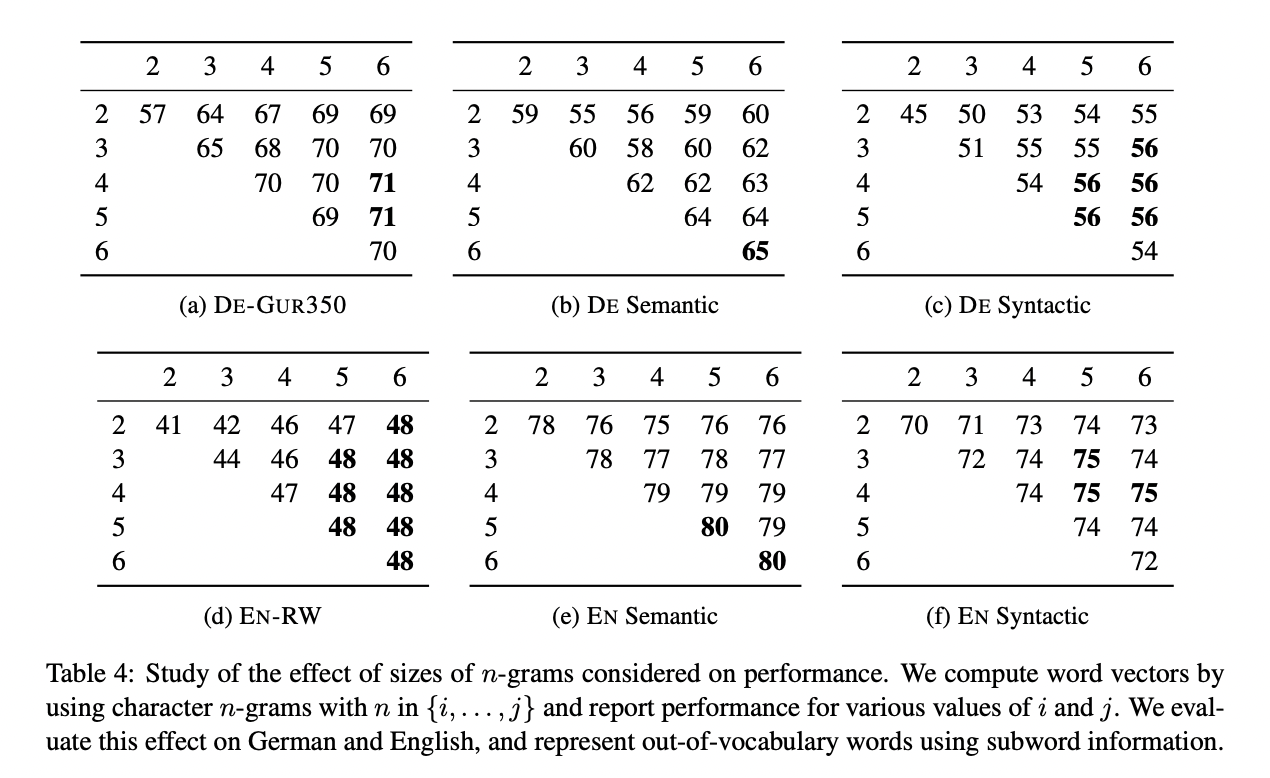
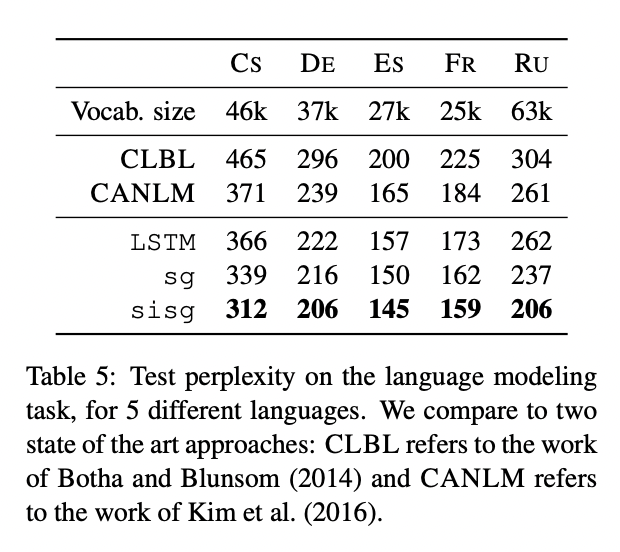
5.6 Language modeling
6. Qualitative analysis
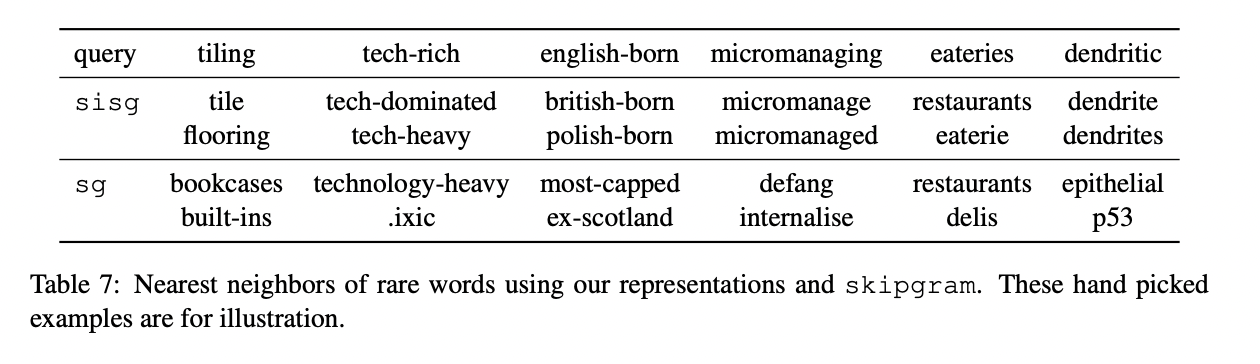
6.1 Nearest neighbors
6.2 Character n-grams and morphemes
각 단어에서 가장 중요한 n-gram이 실제 형태소와 일치하는 지 여부를 평가합니다.


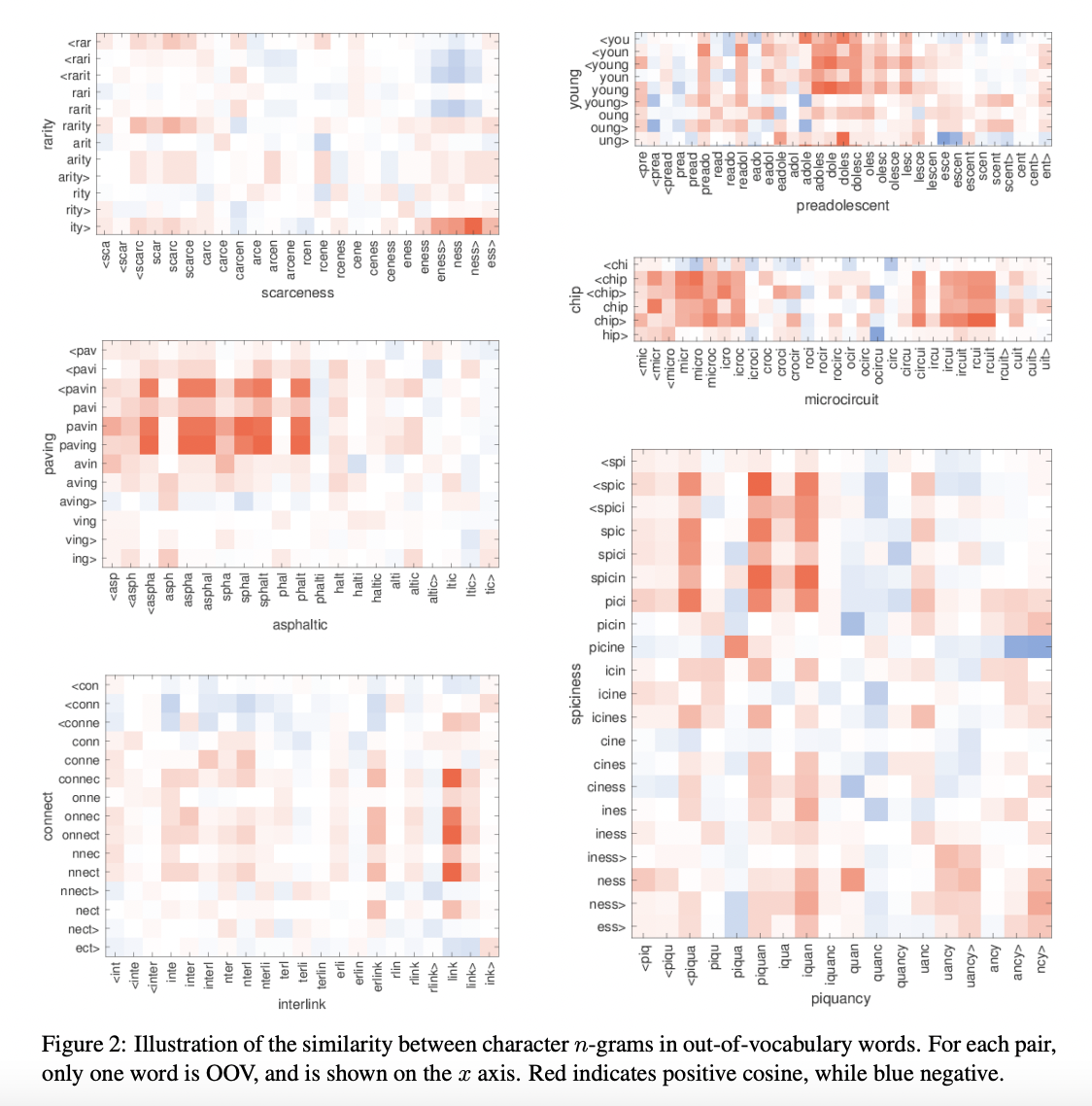
6.3 Word similarity for OOV words
앞서 여러번 언급했듯이 해당 논문의 모델은 학습 데이터에 등장하지 않은 단어에 대해서도 word vector를 얻을 수 있습니다.
7. Conclusion
해당 논문에서는 subword 정보를 고려하는 단어 표현방식을 학습하는 방법을 소개했습니다. 제안된 방법은 Skip-gram 모델에 n-gram 문자를 포함하는 방식으로 볼 수 있습니다. 모델이 간단하기 때문에 학습 속도도 빠르고 전처리 등이 필요하지 않습니다.
