대표적인 Tokenizing 알고리즘 중 하나인 BPE를 소개하는 논문입니다. BPE는 Sentencepiece와 같은 Tokenizing 방법의 base이기도 합니다.
[Abstract]
신경망기계번역(NMT)은 주로 고정된 사전을 바탕으로 작동합니다. 하지만 번역은 대부분 open-vocabulary 문제의 특성을 갖고 있습니다. 과거에는 사전에 존재하지 않은 단어(out-of-vocabulary word) 번역을 위해 backing off(you go back to a n-1 gram level to calculate the probabilities when you encounter a word with prob=0)을 활용하였습니다. 이 논문에서는 rare하거나 unknown 단어들을 subwords 단위들의 연속체로 encoding하여 open-vocabulary 문제를 해결하는 신경망기계번역 모델을 만드는 방법을 소개합니다. 해당 논문에서는 simple character n-gram model과 BPE(byte pair encoding)과 같은 다양한 word segmentation 기술들 중 적합한 것들에 관해 생각해봅니다.
1. Introduction
신경망기계번역은 최근 좋은 결과를 보이고 있었지만 rare words에 대해서는 여전히 제대로 된 해결법이 존재하지 않았습니다. 신경망 모델의 사전은 주로 30000개에서 50000개 가량으로 한정이 되어 있었지만 번역은 대부분의 경우 open-vocabulary한 특징을 지니고 있었습니다. 특히 교착어, 합성어와 같은 productive word foramtion 과정을 지닌 언어에서는 번역 모델은 단어 수준 차원보다 낮은 mechanisms을 필요로 했습니다. 합성어를 예로 들었을 때, 분리되고(segmented) 다양한 길이(variable-length)의 표현방식은 직관적으로 단어를 고정된 길이의 벡터로 표현할 때 유용하였습니다.
단어 수준의 신경망기계번역 모델에서 OOV 단어들의 번역은 back-off to a dictinary look-up을 통해 이루어졌습니다. 또한 단어 수준 모형에서는 unseen words을 번역하거나 만들어낼 수 없었습니다. Unknown words를 target text에 그대로 갖다 쓰는 것은 합리적인 전략이었으며 형태학적인 변화(Morphological changes)나 transliteration이 때때로 필요하기도 했습니다.
해당 논문에서는 subword 수준의 신경망번역 모델에 관해 연구했습니다. 주된 목표는 rare words에 대해 back-off model이 필요하지 않은 채로 open-vocabulary 번역을 수행해내는 신경망번역 모델을 만들어내는 것입니다. 번역 과정을 단순화하는 것뿐만 아니라 subword model은 rare words에 있어서 large-vocabulary 모델과 back-off dictionary보다 좋은 정확도를 보였으며 학습 하지 않았던 새로운 단어들도 생산적으로 만들어냈습니다. 해당 논문의 분석은 신경망 네트워크가 subword representation으로부터 compounding과 transliteration을 학습했다는 것을 보여줍니다.
해당 논문은 2가지 주된 공헌을 지니고 있습니다.
- open-vocabulary 신경망번역은 subword 단위를 통해 (rare) words를 encoding하여 가능해집니다. 제시하는 구조는 large vocabulary나 back-off dictionay보다 단순하며 효과적입니다.
- 해당 논문에서는 압축 알고리즘인, byte pair encoding(BPE)을 활용했습니다. BPE는 open vocabulary의 representation을 고정된 크기의 길이가 다양한 character들의 sequences들을 통해 가능해지도록 합니다.
2. Neural Machine Translation
신경망기계번역 system은 RNN으로 이루어진 encoder-decoder network로써 작동됩니다.
Encoder는 gated recurrent units를 포함한 bidirectional neural network입니다. 이는 input sequence를 forward sequence of hiddne states와 backward sequence를 계산합니다. 그 후 각각의 hidden states를 이어붙여(concat) annotation vector를 얻습니다.
Decoder는 target sequence를 예측하는 RNN입니다. target sequence의 각각의 원소는 recurrent hidden state, 이전에 예측된 단어, annotation vector들의 가중합으로 계산되는 context vector에 의해 예측됩니다. 이 때 annotation들의 가중치는 alignment model에 의해 계산됩니다.
3. Subword Translation
해당 논문의 주된 motivation은 단어들의 번역은 사람들에게 새롭더라도 형태소와 음소와 같이 이미 알려진 subword unit들에 의해 번역이 되는 뛰어난 번역기에 의해 번역되었을 때 번역 결과가 명백해진다는 점입니다.
독일어 학습 데이터에서 100개의 rare token들을 분석했을 때, 대다수의 token들이 더 작은 단위를 통해 영어로 번역될 수 있었습니다.
해당 논문에서는 rare word를 적절한 subword 단위로 나누는것이 신경망번역 네트워크가 명확한 번역을 할 수 있도록 학습하며, 이전에 본 적 없는 단어들을 번역하고 만들어내는 지식을 일반화할 수 있도록 해준다고 가정합니다.
3.1 Related Work
통계적기계번역(SMT)에서도 unknown word 번역은 주된 연구대상이었습니다.
대부분의 unknown word들은 name들이었으며 name은 target text가 같은 알파벳을 공유한다면 그대로 복사하여 사용되었습니다. 만약 서로 다른 알파벳을 사용한다면 transliteration이 필수적이었습니다. 관련도가 깊은 언어 사이에서 특히 성공적이었던 Charater-based 번역이 phrase-based 모델과 함께 연구되었습니다.
형태소적으로 복잡한 단어의 segmentation은 SMT에서 널리 활용되었고 형태소 분리를 위한 다양한 알고리즘들이 연구되었습니다. Phrase-based SMT에서 활용되는 segmentation 알고리즘들은 보수적으로 분리를 하는 경향이 있었습니다. 반면에, 해당 논문에서는 공격적인 분리를 통해 open-vocabulary 번역을 가능케하고 back-off dictionary에 의지하지 않도록하는 것을 목표로 합니다.
해당 논문의 다양한 길이를 갖는 representation 방법으로 attention 메커니즘이 좋은 효과를 받을 수 있을 것이라 기대합니다.
또한 해당 논문은 text 길이가 길어지게된다면 효율성이 떨어지게 되고 신경망 모델이 정보를 전달하기 위한 distance가 길이가 증가하기 때문에 compact representation을 추구합니다.
해당 논문은 text의 좋은 압축률을 제공하는 사전을 학습할 수 있도록 해주는 byte paire encoding(BPE)를 기반으로 한 segmentation 알고리즘을 제안합니다.
3.2 Byte Pair Encoding(BPE)
BPE는 자주 등장하는 byte pair들을 사용하지 않는 하나의 byte로 반복적으로 대체하는 data 압축기술입니다. 해당 논문에서는 자주 등장하는 byte pair를 합치는 것이 아닌, character나 character sequences를 합칩니다.
먼저 symbol vocabulary를 character vocabulary로 초기화를 하고, 각 단어들을 character들의 연속체로 표현한 후 단어의 끝을 표시할 수 있도록 '・'을 붙여줍니다. 그 후 반복적으로 모든 symbol 쌍들의 개수를 세고 가장 자주 등장하는 쌍 예를 들어 ('a', 'b')를 ('ab')라는 새로운 symbol로 합쳐줍니다. 이와 같은 병합과정은 charater n-gram을 표현하는 새로운 symbol을 만들어줍니다. 자주 등장하는 charater n-gram(혹은 전체 단어)는 결국 하나의 symbol로 합쳐지게 됩니다. 최종 symbol vocabulary의 크기는 초기 vocabulary 크기에 병합과정의 수(하이퍼파라미터로 설정)를 더한 값이 됩니다.

기존의 다른 compression 알고리즘과의 차이는 논문에서 제안하는 방법은 subword units으로써 여전히 해석가능하고, network가 이런 subword units을 기반으로하여 새로운 단어를 번역하고 만들어내는 것에 대한 일반화를 학습할 수 있다는 점입니다.

해당 논문에서는 BPE를 적용하는 2가지 방법을 평가합니다.
- source, target 각각을 통해서 2개의 독립적인 encoding을 학습
- source, target을 합쳐 1개의 통합적인 encoding을 학습
전자는 text와 vocabulary 크기가 compact하다는 장점과 subword unit들을 training 과정에서 이미 관찰되었다는 것이 보장됩니다. 반면에 후자는 source와 target 사이의 일관성을 증가시켜줍니다.
4. Evaluation
논문에서는 다음의 질문을 답하는 것을 목표로 합니다.
- subword unit들로 표현된 rare and unseen 단어들을 신경만번역을 통해 번역 성능을 높일 수 있는가?
- vocabulary size, text size, translation quality 측면에서 어떠한 segmentaion이 가장 좋은 성능을 보이는가?
CHRF3는 character n-gram F3 score로 인간의 판단과 유사도가 높다는 특징이 있어 사용합니다.
해당 논문의 주된 주장은 rare and unseen word의 번역과 관련있기 때문에 각각들에 대한 통계량을 보여줍니다.
4.1 Subword statistics
실험적으로 명확히해야하는 번역 질과는 별개로 논문의 주된 목적은 compact fixed-size subword vocabulary를 통해 open vocabulary를 표현하고 training과 decoding을 효율적으로 하는 것입니다.
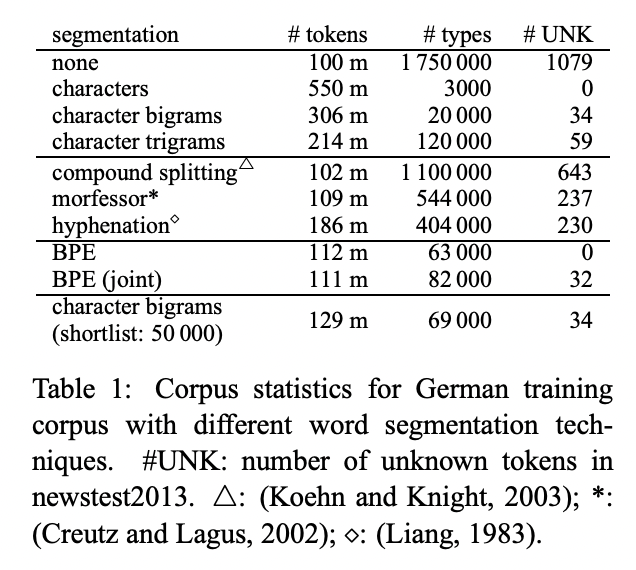
기본이 되는 segmentation은 character n-gram입니다. Character n-gram은 n의 값에 따라 sequence length(# tokens)와 vocabulary size(# types) 사이의 trade-off를 보입니다.
이전 SMT연구에서 자주 활용되던 segmentation 방법들은 vocabulary size는 줄여주지만 unknown 문제는 풀어주지 못하기 때문에 논문의 목적인 open-vocabulary 번역에는 적합하지 않습니다.
BPE는 open-vocabulary 목적을 만족하고 학습된 merge operation은 test set에 적용되어 unknown symbol이 없이 segmentaion을 수행해줍니다. Charater-level 모델과의 주된 차이점은 BPE의 compact representaion이 shorter sequences를 허용하고 attention model을 길이가 변하는 unit에 적용할 수 있도록 해줍니다.
4.2 Translation experiments
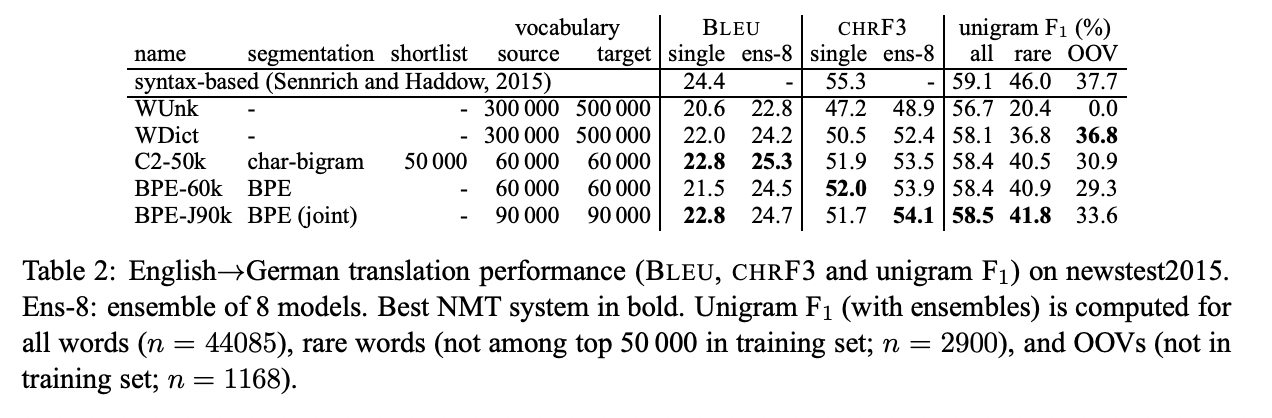
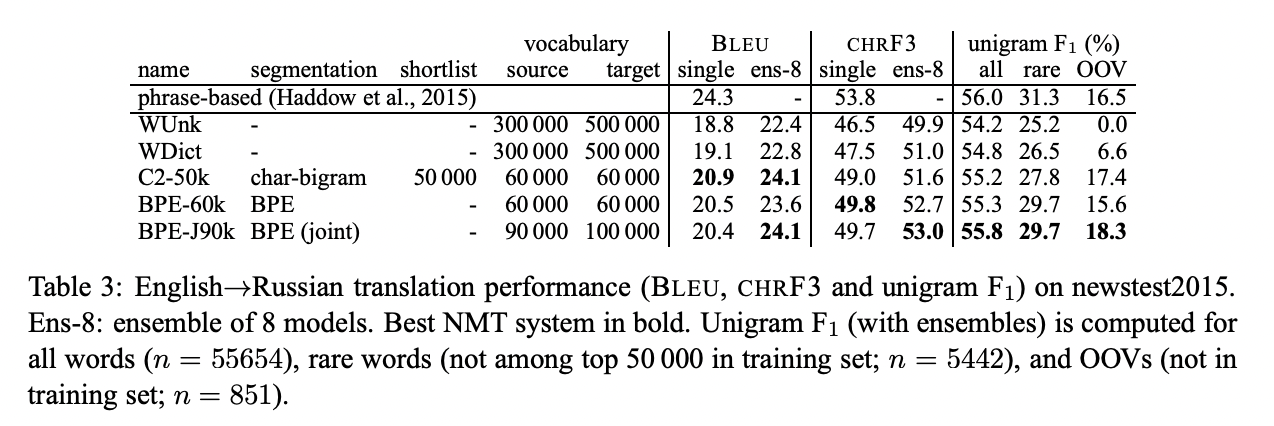
해당 논문의 baseline인 WDict은 back-off dictionary를 활용하는 word-level 모델입니다. WUnk는 back-off dictionary를 활용하지 않으며 out-of-vocabulary 단어를 UNK로 표현합니다. Back-off dictionary는 rare and unseen word의 unigram F1 값을 높여줍니다.
BPE-J90K는 BPE symbol을 통합하여 학습(후자)한 것이고, BPE-60K는 따로 학습(전자)한 것입니다.
Unigram F1 socre는 BPE-J90K가 BPE-60K보다 높았습니다.
5. Analysis
5.1 Unigram accuracy
논문의 주된 주장은 rare and unknown 단어들의 번역은 word-level NMT 모델에서는 성능이 좋지 못하고 subword 모델에서는 번역 성능을 높인다는 것입니다. 다른 subword segmentaion의 효과를 설명하기 위해 논문에서는 target-side 단어들을 training set에 등장하는 빈도에 따라 정렬하여 plot을 했습니다.
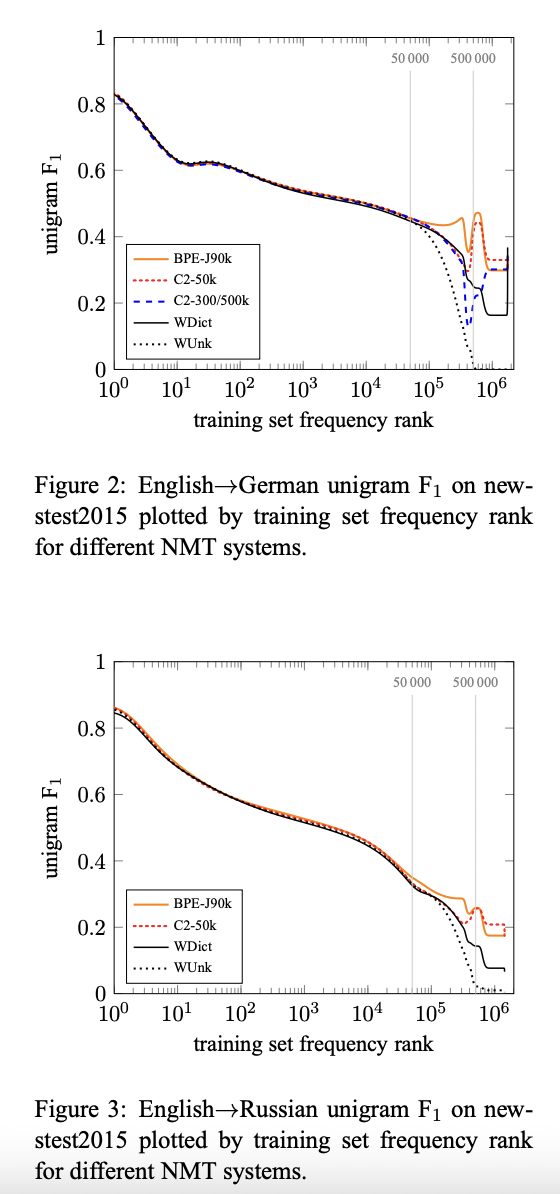
Figure2에서 모든 system에 대해 Unigram F1 값이 저빈도 단어들에 대해 감소하는 것을 확인할 수 있습니다.
5.2 Manual Analysis

6. Conclusion
논문의 주된 기여는 rare and unseen word를 subword units의 sequence로 표현함으로써 신경망기계번역 system이 open-vocabulary 번역을 할 수 있다는 것을 보여주었다는 점입니다. 이 방법은 back-off translation 모델을 사용하는 것보다 간단하며 효율적입니다. 또한 논문은 word segmentation을 위한 다양한 길이의 subword unit들의 compact symbol vocabulary를 활용하여 open vocabulary를 encoding할 수 있는 다양한 BPE를 소개했습니다.
분석을 통해 baseline NMT system이 out-of-vocabulary 단어뿐만 아니라 rare in-vocabuary 단어에서도 좋지 않은 성능을 보이는 것을 밝혔고, subword 모델의 vocabulary 크기를 줄이는 것이 실질적으로 성능 향상에 도움이 되다는 것도 보였습니다.
해당 논문에서 vocabulary size는 임의로 정해졌습니다. Translation task를 위한 적당한 vocabulayr size를 찾는 연구가 추후에 이루어지면 좋을 것입니다.
