추천 시스템의 기본 중 하나인 Collaborative Filtering과 관련된 survey 논문입니다. Collaborative Filtering의 개념을 파악하기 좋은 논문입니다.
1. Introduction
오늘날, 많은 사람들은 다양한 분야에 걸쳐서 추천시스템에 의지하고 있습니다. 추천 시스템은 사용자에게 그들이 관심이 가질만하고 가치있는 정보를 제공하는데 큰 도움을 주고 있습니다.
Collaborative Filtering(CF)의 기본가정은 사용자 X, Y가 n개의 제품에 대해 유사한 평점을 주었거나 둘의 행동(구매, 시청 등)이 유사하다면 다른 제품에 대해서도 유사한 평점을 주거나 특정 행동을 한다는 것입니다.
CF는 추가적인 정보나 새로운 사용자가 좋아할지도 모르는 제품을 예측하기위해 사용자들의 제품에 대한 선호도를 담고 있는 데이터베이스를 사용합니다. 일반적인 CF 시나리오에 m명의 사용자 리스트와 n개의 아이템 리스트가 있으며 각각의 사용자들은 각자가 아이템에 준 평점 리스트 또한 존재합니다. 평점은 실제 1~5점과 같은 explict indication과 구매, 클릭과 같은 implict indication이 있습니다.

Table1에서 Tony는 추천해줄 대상인 active user입니다. Table1에서 볼 수 있듯이 matrix에는 빈칸으로 채워지지 않은 부분들이 존재합니다.
CF는 다양한 도전과제를 가지고 있습니다. 앞서 언급한 채워지지 않은 빈칸들로 인한 sparse data를 다루어야만 한다는 점이 하나의 예시입니다. 또한 사용자와 아이템의 개수가 늘어날수록 데이터의 크기가 커지기 때문에 방대한 양의 데이터를 효율적으로 다룰 수 있어야합니다. 그 외에 짧은 기간안에 만족스러운 추천 결과를 보여줄 수 있어야 하거나, 같은 아이템이지만 다른 이름을 가진 아이템을 추천해줄 수 있는 문제, 개인정보 보호 문제 등도 있습니다.
GroupLens와 같은 초창기의 CF system들은 사용자와 아이템간의 유사도나 가중치를 계산하기 위해 user rating data를 활용하였으며, 계산된 유사도를 바탕으로 추천을 해주었습니다. 이러한 Memory-based CF 방법이라고 불리는 방식은 간단하고 효율적이었기 때문에 아마존과 같은 전자상거래에서 널리 사용되었습니다.
유사도가 기존의 아이템들을 대상으로 계산되기떄문에 데이터가 희소하거나, 아이템 자체의 수가 작을 때 memory-based CF는 한계가 있습니다. Memory-based CF의 단점을 극복하고 더 나은 예측 성능을 얻기위해 model-based CF 방법들이 연구되기 시작했습니다. Model-based CF는 모델 자체가 학습을 통해 예측을 하기 위해 pure rating data를 활용하였습니다. Data mining, machine learining 등이 모델이 될 수 있었습니다. 잘 알려진 model-based CF 기술은 Bayesian belief nets(BNs) CF 모델, clustering CF, latent semantic CF 등이 있습니다.
CF 말고 content-based filtering 방법은 추천 시스템의 중요한 갈래입니다. Content-based fitering은 텍스트 정보의 분석 등을 활용하여 추천을 해줍니다. CF와 content-based filtering의 주된 차이점은 CF는 user-item rating data만을 사용하지만 content-based filtering은 예측을 위해 user나 items의 특징에 의존한다는 점입니다.
Hybrid CF는 CF와 content-based 기술을 혼합하여 각각의 방법의 한계점을 극복하기 위해 생겨났습니다.

CF 성능을 평가하는 지표로는 mean absolute error(MAE), precision, recall 등이 널리 활용되며 떄떄로 ROC sensitivity도 활용됩니다.
2. Characteristics and Challenges of Collaborative Filtering
CF systme에서 좋은 성능의 예측이나 추천을 만들어내는 것은 CF가 지니고 있는 특징으로 인해 발생하는 문제점을 얼마나 제대로 처리할 수 있는지에 달려있습니다.
2.1 Data Sparsity
현업에서 많은 전자상거래 추천시스템은 많은 양의 제품을 평가하기 위해 사용됩니다. CF에 사용되는 user-item matrix는 매우 sparse 해지게 되며, CF의 예측이나 추천 성능은 이로 인해 영향을 받게됩니다.
Data Sparsity 문제는 다양한 상황에서 발생할 수 있습니다. 특히, 새로운 사용자나 아이템이 추천 시스템에 처음 들어왔을 때 충분한 정보가 없기 때문에 유사한 사용자, 아이템을 찾아줄 수 없는 cold start 문제(new user problem or new item problem)가 대표적입니다. 새로운 제품은 누군가가 해당 제품을 평가하기 전까지는 추천이지 않으며 새로운 사용자는 해당 사용자가 매긴 평점이나 구매 내역이 존재하지 않기 때문에 좋은 추천을 받을 수 없습니다. Reduced coverage 문제는 존재하는 많은 수의 제품에 비해 사용자가 평점을 매긴 제품의 수가 적을 때 발생합니다. 그로 인해 추천 시스템은 제대로 된 추천을 해줄 수 없게됩니다. Neighbor transitivity 문제는 sparse database로 인해 발생하는 유사한 사용자를 찾을 수 없는 문제입니다.
Data sparsity 문제를 해결하기 위해 다양한 방법이 제안되었습니다. SVD로 대표되는 Dimensionality reduction는 user-item matrix의 차원을 낮추기 위해 대표성이 떨어지거나 중요도가 낮은 사용자나 제품을 제거합니다. 정보검색에 활용되는 LSI(Latent Semantic Indexing) 역시 SVD를 기반으로 하고 있습니다. 하지만 이러한 방법은 특정 사용자나 제품을 제거하기 때문에 제거된 사용자나 제품과 관련된 유용한 정보를 잃어버리는 것이기 때문에 추천의 성능이 떨어질 수 있습니다.
Content-boosted CF 알고리즘과 같은 hybrid CF 알고리즘은 새로운 사용자나 새로운 제품들의 예측을 위해 외부 정보를 사용하기 때문에 data sparsity 문제를 해결하는 데 도움을 준다고 밝혀졌습니다. Cold start 문제를 해결하기 위해 model fitting에 collaborative와 content information 모두를 사용하는 aspect model latent variable 방법이 제안되었습니다.
TAN-ELR로 대표되는 Model-based CF 알고리즘은 sparse data에 조금더 정확한 예측을 제공하여 sparsity 문제를 다루었습니다. Association retrieval technique, Maximum margin matirx fatorizations(MMMF), ensembles of MMMF, multiple imputation-based CF, imputation-boosted CF 방법 등 역시 활용되었습니다.
2.2 Scalability
사용자와 제품의 수가 많아질수록 CF는 컴퓨팅 자원의 한계로 인해 scalability 문제에 직면하였습니다.
SVD와 같은 dimensionality reduction은 scalability 문제를 다루었고 빠르게 좋은 성능의 예측을 해냈습니다. 하지만 이들은 matrix factorization 꽤 큰 비용이 드는 과정을 수행해야만 했습니다.
Item-based Pearson correlation CF 알고리즘과 같은 memory-based CF 알고리즘은 scalability 문제를 꽤 충분히 다룰 수 있었습니다. 모든 쌍의 유사도를 계산하는 것이 아닌 co-rated item에 대해서만 유사도를 계산하였습니다.
Clustering CF와 같은 Model-based CF 알고리즘은 전체 데이터베이스가 아닌 clustering 근처에 있는 사용자들만 다뤄 scalability 문제를 해결하고자 했습니다.
2.3 Synonymy
Synonymy 문제는 같은 제품에 대해 다른 이름이 붙었을 때 발생하는 문제입니다. 대부분의 추천시스템은 이러한 관계를 제대로 파악하지 못했기 때문에 어려움이 있었습니다. 이로 인해 CF 시스템의 성능은 낮아질 수 밖에 없었습니다.
SVD 방법 특히 LSI 방법은 synonymy 문제를 다룰 수 있었습니다. SVD는 term-document matrix를 통해 semantic space를 만들어냈습니다. Semantic space에서 유사한 term과 document들은 근접하도록 했습니다.
2.4 Gray Sheep
Gray sheep은 긍정, 부정 응답이 일정하지 않은 집단을 의미합니다. 이들의 정보는 CF 성능에 좋지 않은 영향을 미치게됩니다.
2.5 Shilling Attacks
본인들의 제품에 긍정적인 평가를 많이 하고 경쟁자의 제품에 부정적인 평가를 많이 하는 상황이 있습니다. CF는 이러한 현상이 발생하지 않도록 주의를 주어야 합니다. Item-based CF는 user-based CF보다 이러한 상황에 영향을 덜 받는다고 밝혀졌습니다.
2.6 Other Challenges
CF는 personal privacy 문제에 직면하기도 합니다.
사용자가 많아질수록 증가하는 noise 역시 문제가 될 수 있습니다.
Explainability 역시 또 다른 측면에서 추천시스템에서 중요합니다. 추천이 되는 이유를 명확하게 설명하는 것이 사용자들이 느끼기에 도움이 될 수 있기 때문입니다.
3. Memory-based Collaborative Filtering Techniques
Memory-based CF 알고리즘은 예측을 위해 user-item database 전체 혹은 일부를 사용합니다. 모든 사용자들은 유사한 취향을 가진 그룹의 일원이기 때문에 새로운 사용자의 유사한 취향을 가진 사람들을 찾는다면 좋은 예측 결과를 제공할 수 있습니다.
Neighborhood-based CF 알고리즘은 다음과 같은 단계를 통해 이루어집니다.
- 두 사용자 혹은 두 제품 간의 유사도 혹은 가중치를 계산합니다.
- 새로운 사용자에게 특정 아이템 혹은 사용자들에게 모든 사람들 혹은 아이템들이 평가한 점수의 가중평균을 활용하여 예측 결과를 제공합니다.
3.1 Similarity Computation
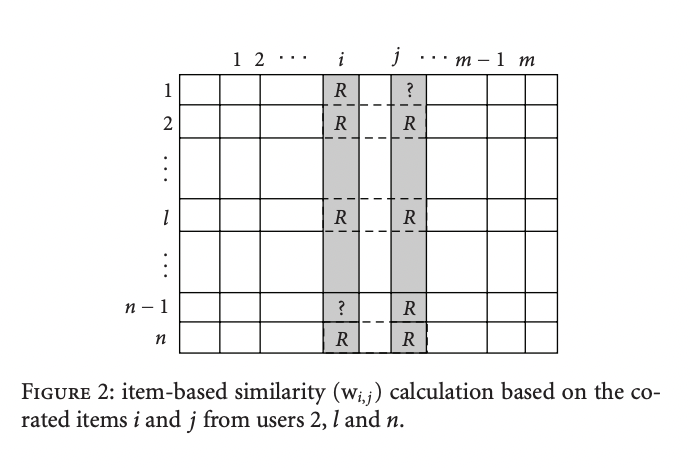
Memory-based CF에서 제품 혹은 사용자간의 유사도 계산은 매우 중요합니다. Item-based CF에서는 아이템 i, j의 유사도는 두 제품 모두에 평점을 준 사용자의 정보를 활용하여 유사도 계산 방식을 활용하여 계산됩니다.
User-based CF에서는 같은 제품에 대해 평점을 준 두 사용자 u, v에 대해 유사도를 구합니다.
3.1.1 Correlation-Based Similarity
사용자 간 혹은 제품 간 유사도를 Pearson correlation을 활용하여 계산합니다.


Pearsion correlation 외에 constrained Pearson correlation, Spearman rank correlation, Kendall's tau correlation 등이 활용될 수 있습니다.
3.1.2 Vector Cosine-Based Similarity
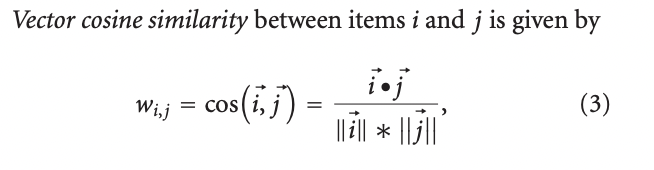
3.1.3 Other Similarities
Conditional probability-based simility는 주로 사용되지는 않지만 또 다른 방법으로 활용될 수 있습니다.
3.2 Prediction and Recommendation Computation
예측, 추천 결과를 얻는 것은 CF에서 가장 중요한 과정입니다.
3.2.1 Weighted Sum of Other's Ratings

3.2.2 Simple Weighted Average

3.3 Top-N Recommendations
Top-N recommendation은 상위 N 번째까지 추천되는 결과입니다. Top-N recommendation은 다른 사용자 혹은 제품과 관계를 찾기 위해 user-item matrix를 분석하고 추천 결과를 계산하기 위해 사용합니다.
3.3.1 User-Based Top-N Recommendation Algorithms
User-based top-N recommendation algorithm은 Pearson correlation이나 vector-space model을 활용하여 가장 유사한 k명의 사용자를 찾습니다. 구해진 k명의 사용자들의 데이터를 활용하여 그들이 자주 구매한 제품을 추리고, 추천 대상 사용자가 구매하지 않은 제품을 랭킹이 높은 순서대로 추천해줍니다. User-based Top-N recommendation algorithm은 scalability와 real-time perfomance 문제를 지닐 수 있습니다.
3.3.2 Item-Based Top-N Recommendation Algorithms
User-based top-N recommendtaion algorithm의 scalability 문제를 해결하기 위해 item-based top-N recommendation algorithm이 제안되었습니다. 해당 알고리즘은 먼저 k개의 유사한 제품을 찾습니다. 해당 후보군에서 이미 사용자가 구매한 제품은 제거합니다.
3.4 Extensions to Memory-Based Algorithms
3.4.1 Default Voting
대부분의 CF에서 유사도는 사용자들이 공통적으로 점수를 매긴 제품의 교집합에 대해서만 유사도가 계산됩니다. 이러한 방식은 전체적인 평가 행동을 반영하는 데 한계가 있습니다.
점수가 매겨지지 않은 값들에 대해 default voting 값을 가정한다면 CF의 예측 성능을 높이는데 도움이됩니다.
3.4.2 Inverse User Frequency
Inverse User Frequency는 대다수의 사람들이 좋아하는 제품은 흔하지 않은 제품들보다 유사도를 구하는 것이 효과적이지 않다는 아이디어입니다.
3.4.3 Case Amplification
Case amplification은 basic collaborative filtering 예측에 활용되는 가중치에 적용되는 transform을 의미합니다.
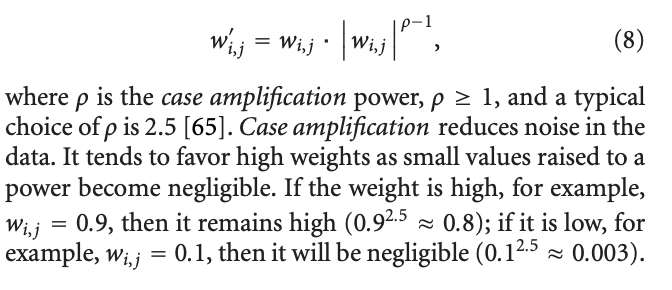
3.4.4 Imputation-Boosted CF Algorithms
Sparse한 data에 대해 missing value를 채우기 위해 imputation 기술을 활용합니다.
3.4.5 Weighted Majority Prediction
Weighted majority prediction은 동일한 column에서 관측된 데이터의 row를 활용하는 방식입니다.
4. Model-Based Collaborative Filtering Techniques
ML, data mining 방법들을 활용하여 만들어진 모델은 학습 데이터를 바탕으로 복잡한 패턴을 포착할 수 있게됩니다. 이를 활용하여 test data, real word data에 대해 좋은 에측 결과를 보일 수 있습니다. Memory-based CF의 단점을 극복하기 위해 Bayesian model, clustering model, dependency network와 같은 model-based CF 알고리즘들이 연구되었습니다.
4.1 Bayesian Belief Net CF Algorithms
4.1.1 Simple Bayesian CF Algorithms
Simple bayesian CF algorithm은 naive Bayes를 활용합니다.

4.1.2 NB-ELR and TAN-ELR CF Algorithms
Simple Bayesian algorithm의 한계로 인해 advanced BNs CF algorithm이 사용되었습니다.
TAN-ELR and NB-ELR은 complete, incomplete data 모두에서 높은 분류 정확도를 보였습니다.
TAN-ELR and NB-ELR은 simple Bayesian algorithm보다 나은 성능을 보였고 Pearson correlation memory-based CF보다도 나은 성능을 보였습니다.
하지만 학습 시간이 오래 걸린다는 단점이 있습니다.
4.1.3 Other Bayesian CF Algorithms
Bayesian belief nets with decision trees at each node 해당 모델은 각각의 노드가 BNs인 decision tree입니다. Pearson correlation-based CF와는 유사한 성능을 보였고 Bayesian-clustering과 vector cosine memory-based CF보다는 나은 성능을 보였습니다.
Baseline Bayesian model 은 Bayesian belief net with no arcs를 사용합니다.
4.2 Clustering CF Algorithms
유사도는 Minkowski거리와 Pearson correlation을 사용하여 clustering을 진행합니다.

Clustering 방법은 3가지 카테고리로 나눌 수 있습니다.
- partitioning methods : K-means
- density-based clustering methods : DBSCAN, OPTICS
- hierarchical clustering methods : BIRCH
4.3 Regresiion-Based CF Algorithms

Missing elements를 default voting 값으로 대체하기 위해 sparse factor analysis가 제안되었습니다.
4.4 MDP-Based CF Algorithms
추천 과정을 예측으로 보는것이 아닌 sequential optimization 문제로 보고 Markov decision processes(MDPs)를 사용하는 모델이 제안되었습니다.
4.5 Latent Semantic CF Models
Latent semantic CF 기술은 user communities와 prototypical interest profiles를 찾기위해 mixture model setting에 latent class variable을 활용하는 statistical modeling 기술에 의존합니다.
- Aspect model
- Multinomial model
4.6 Other Model-Based CF Techniques
- Two-stage order learning
- Association rule based CF algorithms
- Maximum entropy approach
- Dependency network
- Decision tree CF models
- Multiple multiplicative factor models(MMFs)
- Probabilistic principal components analysis(pPCA)
- Matrix factorization
5. Hybrid Collaborative Filtering Techniques
Hybrid CF는 CF를 다른 추천 기술과 혼합한 것입니다.
Content-based recommender system은 텍스트 정보 contents를 분석하여 추천을 해줍니다.
Content-based 기술은 충분한 정보가 있어야한다는 start-up problem을 갖습니다.
또 다른 방식으로 사용자 정보를 활용하는 demographic-based recommender system이 있습니다.
Utility-based recommender system과 knowledge-based recommender system은 모두 사용자의 요구를 충족시키는 특정 제품의 정보를 필요로 합니다.
5.1 Hybrid Recommenders Incorporating CF and Content-Based Features
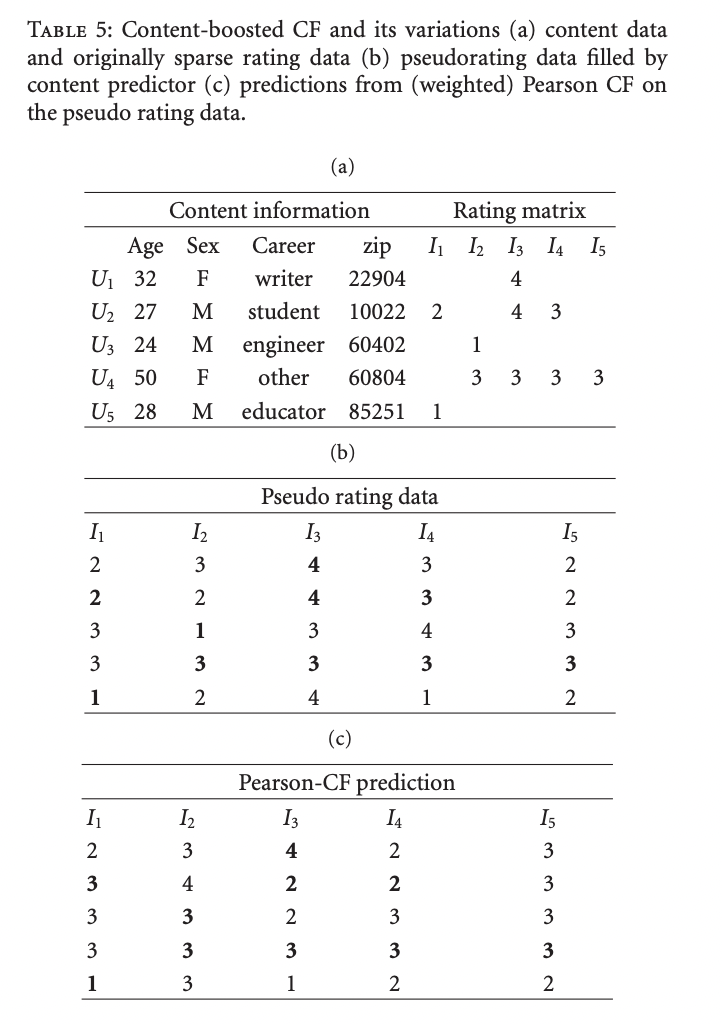
Content-boosted CF는 naive Bayes를 content classifier로 활용하여 rating matrix의 결측치를 채워 pseudo rating matrix를 만듭니다.Content-boosted CF는 cold start 문제를 극복하였고 sparisity 문제 역시 해결하였습니다.
5.2 Hybrid Recommenders Combining CF and Other Recommender Systems
- Weighted hybrid recommender
- Switching hybrid recommender
- Mixed hybrid recommender
- Cascade hybrid recommender
- Meta-level recommender
Hybrid recommender는 new user, new item 상황에서 정확한 예측을 보였습니다. 하지만 주로 활용하기 힘든 외부 정보에 의존하고 사용하기가 복잡하다는 단점이 있습니다.
5.3 Hybrid Recommenders Combining CF Algorithms
Probabilistic memory-based collaborative filtering(PMCF)는 memory-based와 model-based를 혼합했습니다.
Personality diagnosis(PD)는 memory-based와 model-based CF를 혼합한 hybrid CF 방식의 대표적인 예시이며 두 방식의 장점을 모두 갖습니다.
6.Evalutaion Metrics
6.1 Mean Absolute Error(MAE), Normalized Mean Absolute Error(NMAE)
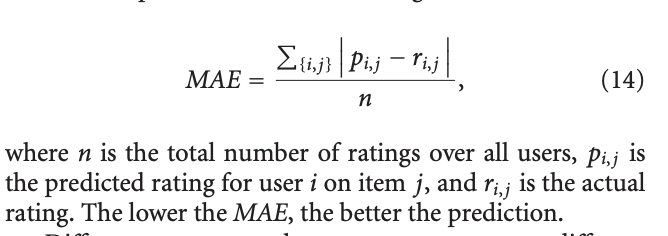

6.2 Root Mean Squared Error(RMSE)

6.3 ROC Sensitivity
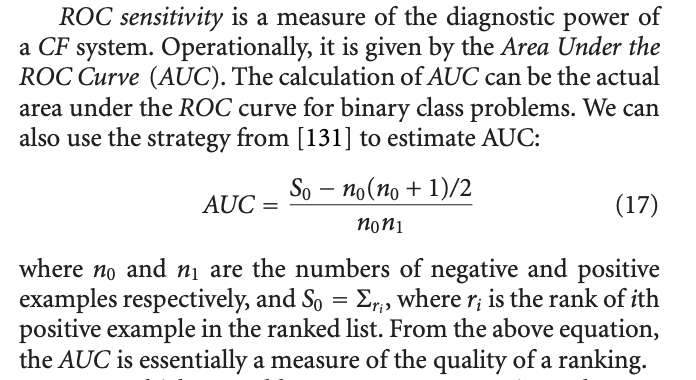
7. Conclusion
CF는 성공적인 추천 기술 중 하나입니다. 넓게 memory-based CF, model-based CF, hybrid CF가 있습니다.
Memory-based CF의 대표로 neighborhood-based CF는 사용자나 제품 간의 유사도를 계산하며 평점의 가중합이나 유사도 결과를 기반으로 하여 예측 결과를 만들어냅니다. Pearson correlation과 vector cosine similarity는 유사도를 계산하기 위해 사용됩니다. Top-N recommendation을 만들기 위해 neighborhood-based 방법은 유사도 결과 값을 활용합니다. Memory-based CF는 적용하기 쉬우며 dense dataset에 대해 성능이 좋습니다. Memory-based CF의 단점으로 사용자 rating 결과에 의존적이며, data가 sparse할 때 성능이 좋지 못하며, 새로운 사용자가 아이템에 대해서 문제가 발생할 수 있으며, data가 너무 클 때도 문제가 발생하게 됩니다.
Model-based CF는 Bayesian belief nets, clustering, MDP-based 등의 학습을 통하여 예측 결과를 만들어냅니다. Advanced Bayesian belief nets CF는 missing data를 다룰 수 있으며 simple Bayesian CF와 Pearson correlation-based보다 좋은 성능을 보였습니다. Clustering CF는 cluster 안에서 추천 결과를 만들어냅니다. Model-based CF는 data가 극도로 sparse할 때 효과가 없고, 차원 축소나 여러개의 class를 binary class로 바꾸었을 때 성능이 떨어질 수 있으며 model-building expense가 높으며 예측 성능과 scalability 사이에 trade-off가 존재한다는 단점이 있습니다.
Hybrid CF는 CF를 content-based나 다른 추천 시스템과 혼합하여 단점을 보완하고 예측과 추천 성능을 높입니다. 성능을 높여주지만 hybrid CF는 사용하기가 어려운 content information에 의존도가 높다는 단점과 복잡도가 높아진다는 단점이 있습니다.
CF를 수행하기 쉽게 만들고 적은 자원을 활용하고 정확안 예측과 추천 성능을 보이고 data sparsity, scalability, synonymy, privacy protection과 같은 현실 데이터의 문제점을 극복하는 것을 요구합니다. Sparsity 문제를 해결하기 위해 TAN-ELR과 같은 missing-data algorithm, Bayesian multiple imputation 같은 imputation 기술, SVD와 matrix factorization과 같은 차원축소 방법이 활용됩니다. Scalability 문제를 해결하기 위해 clustering CF, incremental SVD CF와 같은 방법이 사용됩니다. Synonymy 문제를 해결하기 위해서는 LSI가 사용됩니다. User privacy를 막기위해 sparse factor analysis가 활용됩니다.
