1️⃣ 개념
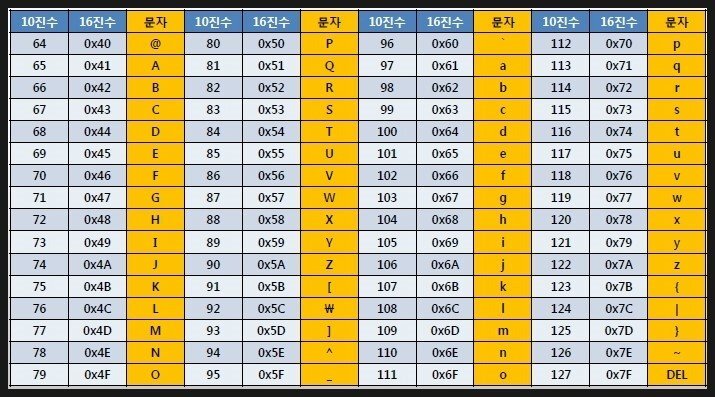
아스키코드
A(65), Z(90), a(97), z(122)
- ord() - 문자 -> 아스키코드
- chr() - 아스키코드 -> 문자
관련 함수
- replace(old, new) = 문자열 안에서 특정 문자(old)를 새로운 문자(new)로 변경
-> 문자열 공백 없애기 str.replace(' ', '')
- s.zfill(2) = 0 포함해서 원하는 자릿수(2자리)만큼 출력
- str2.startswith(str1) = str1이 str2의 접두어인지
- s.upper() / s.lower() = 대소문자 변환
- s.count(특정 문자) = 문자열에서 특정 문자 개수 세기
- eval() = 문자열로 된 수식을 계산해서 결과를 리턴해주는 함수 (결과는 int)
- s.isalpha() = 문자열의 구성이 알파벳이면 True 반환
- s.title() = 문장의 모든 단어의 첫 글자를 대문자로, 나머지는 소문자 (띄어쓰기 뿐만 아니라 알파벳 이외의 문자들을 기준으로 구분해서 첫 글자를 대문자로 바꿔줌!)
- s.capitalize() = 문장의 첫 글자만 대문자로, 나머지는 소문자
- Counter() - 문자열 or 리스트 내 각 문자의 개수를 세어 딕셔너리로 iterable한 형태로 반환해주는 함수
- Counter().most_common() - Counter 결과에서 데이터의 개수가 많은 순으로 정렬함
from collections import Counter
w = "hello world"
print(Counter(w))
# {'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1}
# 리스트를 인자로 받으면
print(Counter(['hi', 'hey', 'hi', 'hi', 'hello', 'hey']))
# {'hey': 2, 'hi': 3, 'hello': 1}
print(Counter(['hi', 'hey', 'hi', 'hi', 'hello', 'hey']).most_common())
# {'hi': 3, 'hey': 2, 'hello': 1}
# 리스트를 문자열로
result = ' '.join(map(str, str_list))
# 문자열을 리스트로
result = list(str)
result = list(map(int, arr[i][0].split(":")))정규표현식
🖤 메타문자
- 문자클래스 [] = [] 사이의 문자들 중에 매치되는 것이 있는지 ([abc]는 a, before와 매치됨)
- Dot(.) = 줄바꿈(\n)을 제외한 모든 문자와 매치 (a.b는 aab, a0b와 매치)
- 반복(*) = * 바로 앞에 있는 문자 0~무한대 반복 (ca*t는 ct, caaat와 매치)
- 반복(+) = +바로 앞에 있는 문자가 1번 이상 반복 (ca+t는 cat, caaat와 매치)
- 반복({m, n}) = {} 바로 앞에 있는 문자가 m~n회 반복 (cat{2}t는 caat와 매치)
- 반복(?) = ?는 {0, 1}과 같은 표현 (ab?c는 abc, ac와 매치)
🖤 문자집합
- /s, /S - 공백문자, 공백문자 이외의 모든 문자
🖤 정규표현식
- match = 문자열의 처음부터 검사
import re
p = re.compile('[a-z]+') # 패턴 객체
m = p.match('python')
print(m) # <re.Match object; span=(0,6), match='python'>
m = p.match('3 python')
print(m) # None
- search = 처음이 일치하지 않아도 일치하는 부분을 찾아서 리턴
import re
p = re.compile('[a-z]+')
m = p.search('python')
print(m) # <re.Match object; span=(0,6), match='python'>
m = p.match('3 python')
print(m) # <re.Match object; span=(2,8), match='python'>
m = re.search('[a-z]+', 'python)
print(m) # <re.Match object; span=(0,6), match='python'>
- findall = 매치되는 모든 문자열을 리스트 형식으로 리턴
import re
p = re.compile('[a-z]+')
m = p.findall('life is too short')
print(m) # ['life', 'is', 'too', 'short']
- finditer = 매치되는 모든 문자열을 오브젝트 형식으로 리턴
import re
p = re.compile('[a-z]+')
m = p.finditer('life is too short')
for r in m:
print(r)
# <re.Match object; span=(0,4), match='life'>
# <re.Match object; span=(5,7), match='is'>
# <re.Match object; span=(8,11), match='too'>
# <re.Match object; span=(12,17), match='short'>
🖤 match 객체의 메소드
- group() - 매치된 문자열을 리턴함
- start() - 매치된 문자열의 시작 위치를 리턴함
- end() - 매치된 문자열의 끝 위치를 리턴함
- span() - 매치된 문자열의 (시작, 끝)에 해당되는 튜플을 리턴함
import re
p = re.compile('[a-z]+')
m = p.match('python')
print(m.group()) # python
print(m.start()) # 0
print(m.end()) # 6
print(m.span()) # (0,6)
🖤 컴파일 옵션
- DOTALL, S = .이 줄바꿈 문자도 포함하여 매치될 수 있도록
p = re.compile('a.b', re.DOTALL) # = re.compile('a.b', re.S)
m = p.match('a\nb')
print(m) # <re.Match object; span=(0,3), match='a\nb'>
- IGNORECASE, I = 대소문자와 관계없이 매치될 수 있도록
p = re.compile('[a-z]', re.I)
print(p.match('python')) # <re.Match object; span=(0,1), match='p'>
print(p.match('Python')) # <re.Match object; span=(0,1), match='P'>
print(p.match('PYTHON')) # <re.Match object; span=(0,1), match='P'>
- MULTILINE, M = 여러 줄과 매치될 수 있도록
data = """python one
life is too short
python two
you need python
python three"""
p = re.compile("^python\s\w+", re.M)
print(p.findall(data)) # ['python one', 'python two', 'python three']
- VERBOSE, X = 정규표현식을 줄바꿈과 공백으로 나눌 수 있도록 (정규표현식을 보기 좋게 함)
charref = re.compile(r"""
&[#]
(
0[0-7]+
| [0-9]+
| x[0-9a-fA-F]+
)
;
""", re.X)
2️⃣ 문제 풀이
* 프로그래머스 가장 긴 팰린드롬 (Level 3)
팰린드롬은 앞뒤를 뒤집어도 똑같은 문자열을 말함
복잡하게 문자열을 절반으로 나눠서 비교할 생각하지 말고 걍 전체를 뒤집는 게 쉽다!
* 프로그래머스 매칭 점수 (Level 3)
https://school.programmers.co.kr/learn/courses/30/lessons/42893
pages는 다음과 같이 3개의 웹페이지에 해당하는 HTML 문자열이 순서대로 들어있음
<html lang="ko" xml:lang="ko" xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta charset="utf-8">
<meta property="og:url" content="https://a.com"/>
</head>
<body>
Blind Lorem Blind ipsum dolor Blind test sit amet, consectetur adipiscing elit.
<a href="https://b.com"> Link to b </a>
</body>
</html>
import re
def solution(word, pages):
webpage = []
webpageName = []
webpageGraph = dict() # 나를 가리키는 외부 링크
for page in pages:
url = re.search('<meta property="og:url" content="(\S+)"', page).group(1)
basicScore = 0
for f in re.findall(r'[a-zA-Z]+', page.lower()):
if f == word.lower():
basicScore += 1
exiosLink = re.findall('<a href="(https://[\S]*)"', page)
for link in exiosLink:
if link in webpageGraph:
webpageGraph[link].append(url)
else:
webpageGraph[link] = [url]
webpageName.append(url)
webpage.append([url, basicScore, len(exiosLink)])
# 링크점수 = 해당 웹페이지로 링크가 걸린 다른 웹페이지의 기본점수 ÷ 외부 링크 수의 총합
# 매칭점수 = 기본점수 + 링크점수
maxValue = 0
result = 0
for i in range(len(webpage)):
url = webpage[i][0]
score = webpage[i][1]
if url in webpageGraph.keys():
# 나를 가리키는 다른 링크의 기본점수 ÷ 외부 링크 수의 총합을 구하기 위해
for link in webpageGraph[url]:
a, b, c = webpage[webpageName.index(link)]
score += (b / c)
if maxValue < score:
maxValue = score
result = i
return result
🐥👩💻💰