
재귀(recursion)란?
- 알고리즘이나 함수가 수행 도중에 자기 자신을 다시 호출하여 문제를 해결하는 기법
- 정의자체가 순환적으로 되어 있는 경우에 적합한 방법
- 같은 코드를 반복적으로 사용해야할 때에, 유용하게 사용 -> 보다 간단하게 문제 해결
- 유의점 :
Break Point- 계속해서 반복호출하다보면 스택오버플로우(Stack Overflow) 오류가 발생할 수 있다.
용량은 한정되어있는데, 계속해서 호출하고 리턴하지 않으니 용량을 많이 차지하고 그러다보니 일어나는 것이라고 생각하면 되겠다.
(사탕을 비닐에 넣는데, 계속해서 사탕을 넣기만하면 비닐이 터져버리는 것과 같다고 생각하면 된다.) - 함수가 멈추지 않고 무한대로 실행되는 것을 방지하기 위해
종료 조건을 반드시 명시해주도록 한다.
- 계속해서 반복호출하다보면 스택오버플로우(Stack Overflow) 오류가 발생할 수 있다.
- 팩토리얼, 피보나치 수열, 하노이의 탑과 같은 문제에서 이용
재귀함수의 특성
- 재귀의 호출은 같은 문제 내에서 더 범위가 작은 값, 즉, 하위 문제에 대해 이루어져야 한다.
- 재귀함수 호출은 더 이상 반복되지 않는 base case에 도달해야 한다.
Base Condition (종료 조건)
재귀 함수는 특정 입력에 대해서 자기 자신을 호출하지 않고 종료해야 한다. 또한 모든 입력은 base condition 으로 수렴해야만 한다. 이를 지키지 않으면 무한루프에 빠져 에러가 발생한다.
함수의 명확한 정의
- 함수의 인자로 어떤 것을 받을 것인지
- 어디까지 계산하고 자기 자신에게 넘겨줄 것인지
재귀함수와 반복문
모든 재귀함수는 재귀구조 없이 반복문 만으로 동일 동작을 수행하는 함수를 구현할 수 있다.
재귀를 적절하게 잘 사용하면 코드가 간결해진다는 장점이 있지만, 메모리와 시간적 측면에서 어느정도 손해를 보게 된다.
따라서 반복문으로도 간단하게 해결이 가능한 문제라면 반복문을 사용해 구현하고, 반복문 만으로는 너무 코드가 복잡해질 것 같다면 재귀 구조를 이용하는 것이 좋다.
재귀의 장점
- 직관적이며 간단하게 구현할 수 있다.
- DFS, 백트래킹, 분할정복과 같은 알고리즘에 사용되기도 하여 기초가 되는 개념
- 변수 사용을 줄여준다.
재귀의 단점
- 재귀함수의 종료 조건을 잘 설정하지 않으면 재귀함수를 빠져나오지 못하게 되어 무한루프에 빠질 수 있다.
- 재귀 호출의 깊이가 너무 깊어지면 너무 많은 메모리를 사용하게 된다. 즉, 수행시간이 길어질 수 있다.
- 불필요한 반복 연산을 하게 될 가능성이 있다.
- 시간 복잡도가 반복문에 비해 계산하기 어렵다.
위와 같은 단점으로 인해 입력값이 정말 많은 알고리즘 문제를 재귀함수로 푸는 것은 매우 좋지 않다. 정지 조건을 아무리 잘 잡았다고 해도 무조건 시간초과가 걸린다.
요즘 코딩테스트에서는 어느 정도 난이도가 있으면 입력값이 100,000으로 주어지는 경우가 대부분이다. 이 데이터를 재귀함수로 다룬다고 생각해보면 매우 까다로울 것이다.
특히나 코드 효율성을 중요시하는 요즘 코테에서는 잘 안맞는 경우가 많을수도 있을 것이라 생각된다.
즉 문제를 풀기 전에 입력되는 값으로부터 시간복잡도를 미리 예상을 하고 알맞은 알고리즘을 생각하여 코드를 작성해야 하는 경우에 꼭 재귀함수를 사용해야 하는가?에 대해서 고민해보아야 한다.
우리가 사용할 수 있는 컴퓨터 자원은 한정되어 있기 때문에, 이를 고려한 코드가 중요하다고 생각된다.
재귀 알고리즘의 구조
- 순환 알고리즘은 다음과 같은 부분들을 포함한다.
- 순환 호출을 하는 부분
- 순환 호출을 멈추는 부분

- 만약 순환 호출을 멈추는 부분이 없다면?
- 시스템 오류가 발생할 때까지 무한정 호출하게 된다.
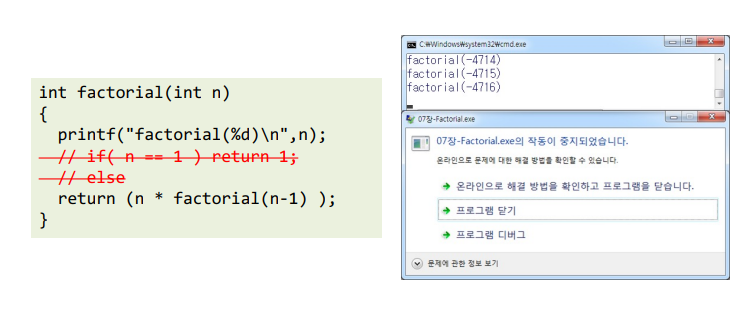
int factorial(int n)
{
printf("factorial(%d)\n",n);
// if( n == 1 ) return 1;
// else
return (n * factorial(n-1) );
}재귀 함수 예시
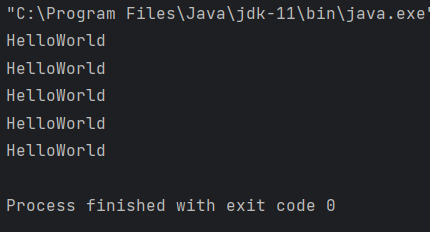
HelloWorld 출력 예시
public class Main {
public static void main(String[] args) {
HelloWorld(5); // HelloWorld 출력 메서드 호출
}
// HelloWorld 출력 메서드 선언
public static void HelloWorld(int n)
{
// n이 0인 경우 return
if(n == 0)
return;
System.out.println("HelloWorld"); // HelloWorld 출력
HelloWorld(n-1); // 재귀함수 시작
}
}
팩토리얼 함수 예시
public class Main {
public static void main(String[] args) {
int result = factorial(3);
System.out.println(result);
}
public static int factorial (int num) {
if (num == 1)
return 1;
return num * factorial ( num - 1 );
}
}재귀 호출 순서
- 팩토리얼 함수의 호출 순서
factorial(3)
= 3 * factorial(2)
= 3 * 2 * factorial(1)
= 3 * 2 * 1
= 3 * 2
= 6

재귀 <-> 반복
- 재귀(Recursion) : 순환 호출 이용
- 순환적인 문제에서는 자연스러운 방법
- 함수 호출의 오버헤드
- 반복(Iteration) : for 나 while 을 이용한 반복
- 수행속도가 빠르다.
- 순환적인 문제에서는 프로그램 작성이 아주 어려울 수도 있다.
- 대부분의 재귀는 반복으로 바꾸어 작성할 수 있음
재귀(Recursion)
1. 기본 경우에 도달하면 종료한다.
2. 각 재귀 호출은 스택 프레임(즉, 메모리) 에 부가 공간을 필요로 한다.
3. 무한 재귀에 들어가게 되면 메모리 용량을 초과해서 스택 오버플로우를 초래하게 된다.
4. 어떤 문제들의 해답은 재귀적인 수식으로 만들기 쉽다.
반복(Iteration)
1. 조건이 거짓일 때 종료한다.
2. 각 반복이 부가 공간을 필요로 하지 않는다.
3. 무한 루프는 추가 메모리가 필요하지 않으므로 무한히 반복된다.
4. 반복적 해법은 재귀적 해법에 비해 간단하지 않을 때가 있다.
ex) 팩토리얼의 반복적 구현
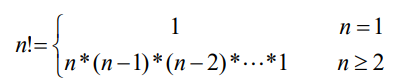
int factorialIter( int n )
{
int result=1;
for( int k=n ; k>0 ; k-- )
result = result * k;
return result;
}분할 정복 (divide and conquer)
분할 정복(Divide and Conquer)은 재귀 알고리즘의 일종으로, 큰 문제를 작은 부분 문제로 분할하고, 각 부분 문제를 독립적으로 해결한 후 그 결과를 결합하여 원래 문제의 해답을 구하는 방법이다.
분할 정복 방식이 하위 문제를 재귀적으로 해결하기 때문에 하위 문제 각각은 원래 문제보다 범위가 작아야 하며 하위 문제는 각 문제마다 탈출 조건이 존재해야 한다.
분할 정복 알고리즘은 일반적으로 세 가지 단계로 구성된다.
분할(Divide): 주어진 문제를 더 작은 부분 문제로 분할한다. 이 단계에서는 주로 문제를 반으로 나누는 방식으로 분할을 수행한다. 분할된 부분 문제는 독립적으로 해결될 수 있어야 한다.
정복(Conquer): 각각의 작은 부분 문제를 재귀적으로 해결한다. 이 단계에서는 분할된 부분 문제를 재귀적으로 호출하여 해결한다. 작은 부분 문제가 충분히 작아서 쉽게 해결될 수 있는 경우에는 재귀 호출 없이 직접 해결할 수도 있다.
결합(Combine): 작은 부분 문제의 해답을 결합하여 원래 문제의 해답을 구한다. 이 단계에서는 각 부분 문제의 해답을 결합하여 전체 문제의 해답을 얻는다.
분할 정복은 주로 문제를 재귀적으로 분할하고 해결하는 방식이므로, 재귀 알고리즘과 밀접한 관련이 있다. 문제를 더 작은 부분 문제로 분할하여 각각을 해결함으로써 전체 문제를 해결하는 효과적인 방법이다. 분할 정복은 병합 정렬, 퀵 정렬, 이진 검색 등 여러 알고리즘에서 사용되며, 문제를 효율적으로 해결하는 데에 큰 도움을 준다.
분할 정복에 이용되는 문제
- 정렬 (퀵 정렬, 병합 정렬)
- 이진 탐색 (Binary Search)
분할정복과 동적 프로그래밍(Dynamic Programming)의 차이점
분할 정복과 동적 프로그래밍은 주어진 문제를 작게 쪼개서 하위 문제로 해결하고 연계적으로 큰 문제를 해결한다는 점은 같다.
차이점은, 분할 정복은 분할된 하위 문제가 동일하게 중복이 일어나지 않는 경우에 쓰며, 동일한 중복이 일어나면 동적 프로그래밍을 쓴다는 것이다. 아래와 같은 몇개의 차이점이 있다.
-
문제의 접근 방식: 분할 정복은 주로 문제를 작은 부분 문제로 분할하고 각각을 독립적으로 해결한 후, 그 결과를 결합하여 원래 문제의 해답을 구하는 방식입니다.
동적 프로그래밍은 큰 문제를 작은 하위 문제로 나누지 않고, 하위 문제의 해답을 저장하고 재사용하여 최적의 해답을 구하는 방식입니다. -
하위 문제의 중복: 분할 정복에서는 하위 문제가 서로 중복되지 않습니다. 즉, 동일한 하위 문제가 반복해서 해결되지 않습니다.
반면에 동적 프로그래밍에서는 하위 문제가 중복될 수 있으며, 중복되는 하위 문제의 해답을 저장하고 재사용합니다. -
하위 문제의 종속성: 분할 정복에서는 하위 문제들이 독립적으로 해결되며, 하위 문제의 해답이 다른 하위 문제의 해답에 영향을 주지 않습니다.
하지만 동적 프로그래밍에서는 하위 문제들이 종속적이며, 한 하위 문제의 해답이 다른 하위 문제의 해결에 영향을 줄 수 있습니다. -
최적 부분 구조: 동적 프로그래밍은 최적 부분 구조(Optimal Substructure)를 가지는 문제에서 사용됩니다. 최적 부분 구조란 큰 문제의 최적 해답이 작은 부분 문제의 최적 해답으로부터 구해질 수 있는 성질을 말합니다.
분할 정복은 최적 부분 구조를 가지지 않는 문제에도 적용될 수 있습니다.
주어진 문제가 최적 부분 구조를 가지고 있고, 하위 문제들이 중복되는 경우에는 동적 프로그래밍을 사용하는 것이 효과적입니다. 반면에 문제를 작은 부분 문제로 분할하고, 하위 문제들이 독립적이며 중복되지 않는 경우에는 분할 정복을 사용하는 것이 적합합니다.

깔끔하게 정리해주셨네요~!!