Recurrent Neural Network (RNN)
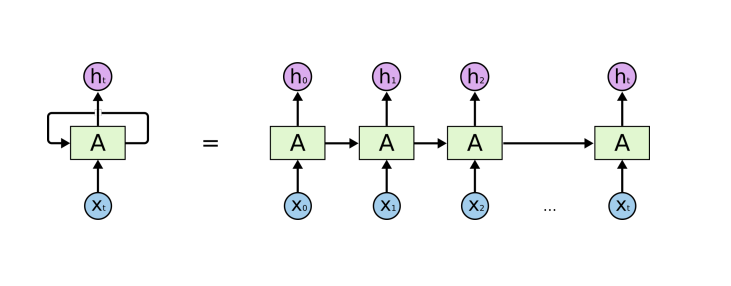
RNN은 sequaltial data를 처리하는 network이다. Sequantial data는 길이를 알 수 없고, 현재 데이터를 처리하기 위해 이전의 모든 데이터를 고려해야 한다. 이를 해결하기 위해 RNN은 이전 정보들을 요약한 Hidden State(그림의 A)를 만들고, 현재 입력과 직전의 hidden state로 출력을 만든다.
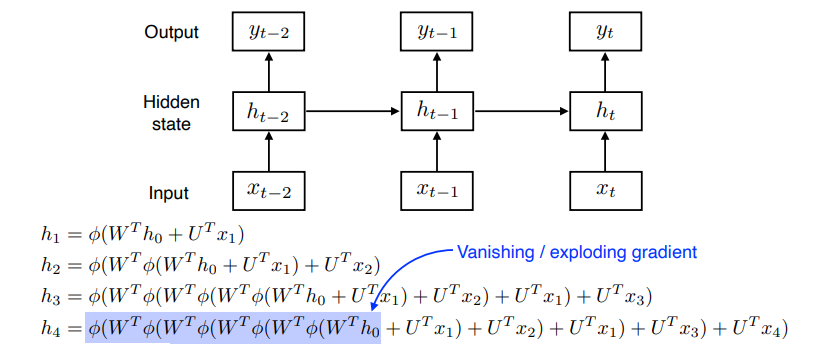
RNN은 가까운 과거의 정보는 충분히 남아있지만, 먼 과거의 정보는 hidden state에 남아있기가 어렵다는 단점이 있다. 뿐만 아니라 직전의 hidden state와 입력 데이터에 가중치를 곱하고, 비선형 함수를 통과하는 과정이 반복되어 gradient vanishing, exploding이 발생할 가능성이 크다.
LSTM (long short term memory)
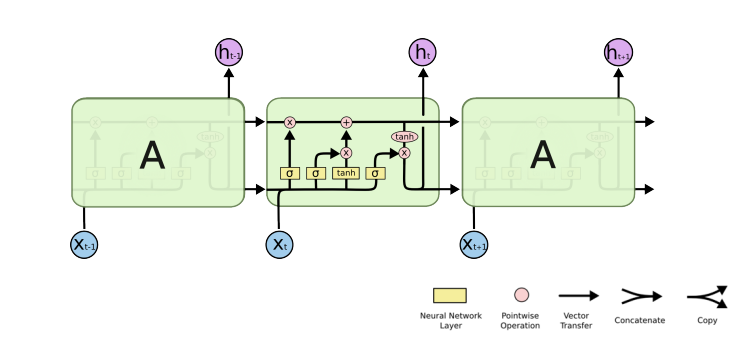
RNN의 장점을 해결하기 위해 나온 LSTM은 위와 같은 구조를 가진다. LSTM은 파라미터가 적을 것 같지만, 결국 dense layer이기 때문에 매우 많은 파라미터가 필요하다.
LSTM은 내부에 3가지 게이트를 사용하여 데이터를 처리한다.
1. Forget Gate

직전 hidden state와 현재 입력으로 cell state에서 버릴 값 결정
- Input Gate
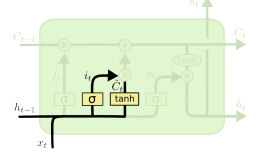
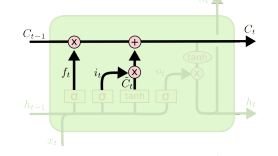
직전 hidden state와 현재 입력으로 cell state에 새로 저장할 값 결정
Update cell
forget gate와 input gate로 결정한 값을 이용해 cell state를 업데이트
- Output Gate
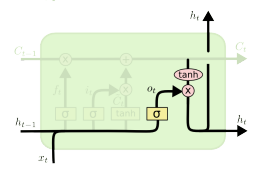
update한 cell state를 바탕으로 어떤 값을 hidden state로 내보낼지 결정
LSTM 구현 코드
MNIST 데이터를 분류하는 RNN 모델이다.

모델의 전체적인 구조는 28*28크기의 이미지를 한줄씩 LSTM에 sequence로 입력한 후 마지막에 나온 결과값을 dense layer의 입력으로 넣어 크기가 10인 벡터로 바꾸어 주는 것이다.
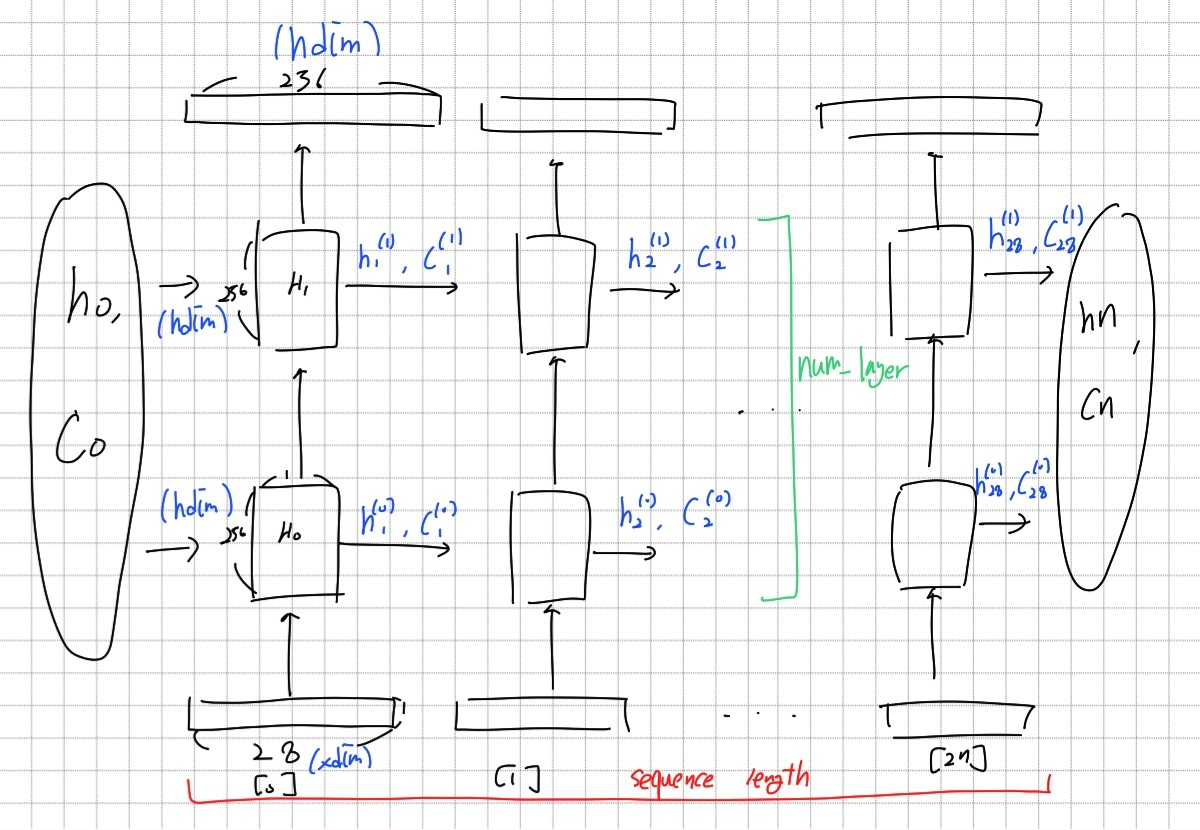
LSTM은 위와 같은 구조로 작동한다. Hidden layer를 num_layer만큼 쌓아 올린 형태이다. hidden state와 cell state의 초기값, 데이터를 입력받아 rnn_out(결과 값)과 hn, cn이 출력된다.
- 모델 정의
class RecurrentNeuralNetworkClass(nn.Module):
def __init__(self,name='rnn',xdim=28,hdim=256,ydim=10,n_layer=3):
super(RecurrentNeuralNetworkClass,self).__init__()
self.name = name
self.xdim = xdim
self.hdim = hdim
self.ydim = ydim
self.n_layer = n_layer # K
self.rnn = nn.LSTM(
input_size=self.xdim,hidden_size=self.hdim,num_layers=self.n_layer,batch_first=True)
self.lin = nn.Linear(self.hdim,self.ydim)
def forward(self,x):
# Set initial hidden and cell states
h0 = torch.zeros(self.n_layer, x.size(0), self.hdim).to(device)
c0 = torch.zeros(self.n_layer, x.size(0), self.hdim).to(device)
# RNN
rnn_out,(hn,cn) = self.rnn(x, (h0,c0))
# x:[N x L x Q] => rnn_out:[N x L x D]
# Linear
out = self.lin(rnn_out[:, -1, :]).view([-1,self.ydim])
return out - 모델 사용하기
R = RecurrentNeuralNetworkClass(
name='rnn',xdim=28,hdim=256,ydim=10,n_layer=2).to(device)