Convolution
Convolution 연산
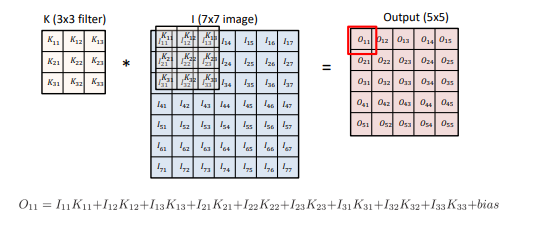
Convolution 연산은 위와 같이 이미지에 kernel(filter)을 찍어내는 연산이다. 이미지에서의 위치와 상관없이 모든 같은 kernel을 사용한다. Kernel을 어떻게 구성하느냐에 따라 결과 이미지가 달라진다. (blur, Emboss, Outline 등)
Convolution 연산에 필요한 정보는 stride와 padding이다. stride는 kernel을 몇 칸씩 띄어서 찍을 것이지를 나타낸다. padding은 이미지 외곽의 정보도 살리기 위해 이미지의 외곽에 값을 채우는 것을 의미한다.
Patameter 개수
Convolution 연산은 이미지 전체가 이미지 크기와 상관없이 kernel이라는 파라미터를 공유하는 것이다. 따라서 선형변환보다 파라미터의 개수가 훨씬 적다.
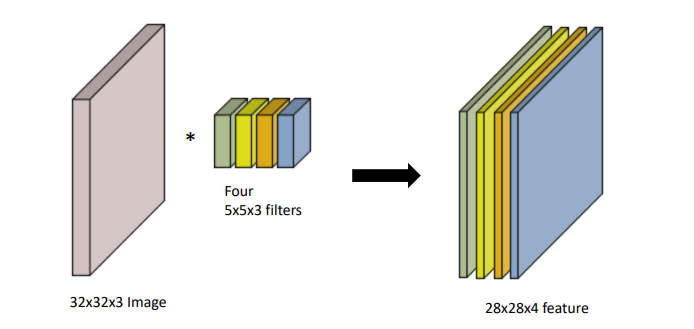
위와 같은 Convolution 연산을 한다고 하자. 32*32*3이미지를 28*28*1 이미지로 변환하기 위해서는 5*5*3 kernel이 필요하다. 이때 결과 이미지의 채널이 4개이기 때문에 5*5*3 kernel은 총 4개가 필요하다. kernel은 입력 이미지와 채널의 숫자가 같아야 하고, 출력 이미지 채널만큼의 kernel이 필요하기 때문이다.
따라서 필요한 파라미터 개수는 총 5*5*3*4 = 300개 이다.
Convolution Neural Networks
CNN 일반적인 구성
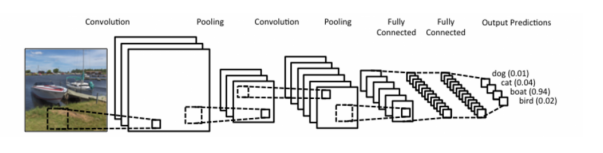
CNN은 일반적으로 feature를 추출하는 convolution layer와 pooling layer, decision making을 하는 fully connected layer로 이루어진다. Convolution, pooling layer를 거친 이미지를 flatten하여 fully connected layer의 입력으로 사용한다.
참고로 Fully conneected layer는 필요한 파라미터가 너무 많아 점차 없어지는 추세이다.
CNN 구현 코드
class ConvolutionalNeuralNetworkClass(nn.Module):
"""
Convolutional Neural Network (CNN) Class
"""
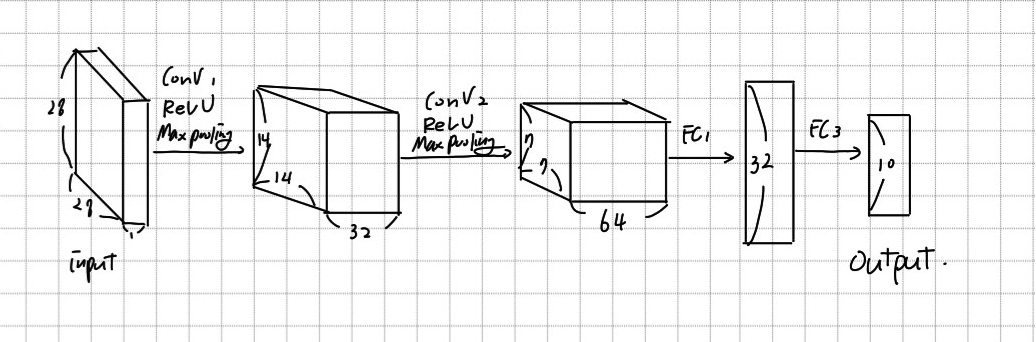
def __init__(self,name='cnn',xdim=[1,28,28],
ksize=3,cdims=[32,64],hdims=[1024,128],ydim=10,
USE_BATCHNORM=False):
"""
init 함수에 layer의 개수를 지정할 수 있게한다.
이는 param만 변경하면 다른 구조의 Model을 만들 수 있도록 한다.
xdim : 입력 이미지 크기
ksize : kernel size
cdims : Convolution layer channel size
hdims : fully connected layer 크기
ydim : 최종 출력 크기
"""
super(ConvolutionalNeuralNetworkClass,self).__init__()
self.name = name
self.xdim = xdim
self.ksize = ksize
self.cdims = cdims
self.hdims = hdims
self.ydim = ydim
self.USE_BATCHNORM = USE_BATCHNORM
# Convolutional layers
self.layers = []
prev_cdim = self.xdim[0]
for cdim in self.cdims: # for each hidden layer
self.layers.append(
nn.Conv2d(in_channels = prev_cdim, out_channels=cdim, kernel_size = self.ksize, stride=(1,1), padding=self.ksize//2) # Convolution
)
if self.USE_BATCHNORM:
self.layers.append(nn.BatchNorm2d(cdim)) # batch-norm
self.layers.append(nn.ReLU(True)) # activation
self.layers.append(nn.MaxPool2d(kernel_size=(2,2), stride=(2,2))) # max-pooling
self.layers.append(nn.Dropout2d(p=0.5)) # dropout
prev_cdim = cdim
# Dense layers
self.layers.append(nn.Flatten())
prev_hdim = prev_cdim*(self.xdim[1]//(2**len(self.cdims)))*(self.xdim[2]//(2**len(self.cdims)))
for hdim in self.hdims:
self.layers.append(nn.Linear(prev_hdim, hdim))
self.layers.append(nn.ReLU(True)) # activation
prev_hdim = hdim
# Final layer (without activation)
self.layers.append(nn.Linear(prev_hdim,self.ydim,bias=True))
# Concatenate all layers
self.net = nn.Sequential()
for l_idx,layer in enumerate(self.layers):
layer_name = "%s_%02d"%(type(layer).__name__.lower(),l_idx)
self.net.add_module(layer_name,layer)
self.init_param() # initialize parameters
def init_param(self):
for m in self.modules():
if isinstance(m,nn.Conv2d): # init conv
nn.init.kaiming_normal_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m,nn.BatchNorm2d): # init BN
nn.init.constant_(m.weight,1)
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.Linear): # lnit dense
nn.init.kaiming_normal_(m.weight)
nn.init.zeros_(m.bias)
def forward(self,x):
return self.net(x)- 모델 사용하기
C = ConvolutionalNeuralNetworkClass(
name='cnn',xdim=[1,28,28],ksize=3,cdims=[32,64],
hdims=[32],ydim=10).to(device)발전 과정
AlextNet
- 특징 : ReLU, LRN, Overlapping pooling, Dropout, Data augmentation
- ReLU, Dropot, Data augmentation 등 현재는 거의 모든 모델에서 기본적으로 사용하는 기술을 제시한 모델
VGG
- 특징 : 3*3 convolution filters
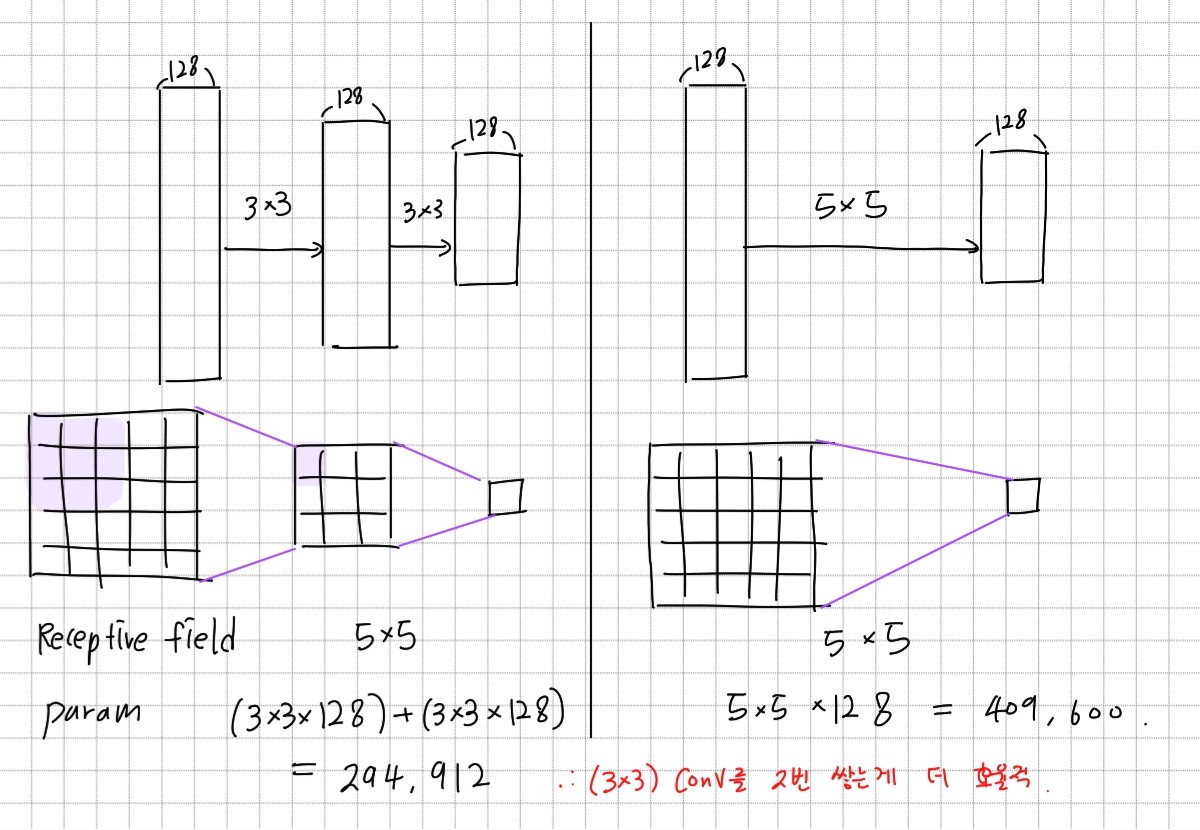
출력의 한 픽셀에서 고려되는 입력의 픽셀 개수는Receptive field라고 한다. 3*3 filter를 여러개 사용하는 것이 큰 사이크의 filter를 사용하는 것보다 효율적이다. VGG는 3*3 filter만을 사용하였다.
GoogLeNet
- 특징 : param을 줄이기 위한 1*1 convolution(inception block)
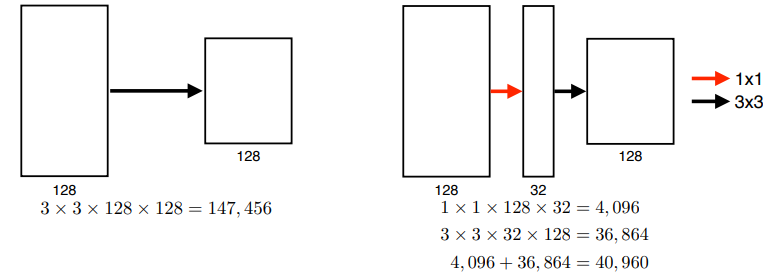
1*1 filter를 사용하면 입력과 출력의 채널을 동일하게 만들면서도 필요한 parameter 개수를 줄일 수 있다. GoogLeNet은 이를 사용하여 layer를 더 깊게 쌓으면서도 parameter 개수를 줄이는 방법을 제시했다.
ResNet
- 특징 : skip connection
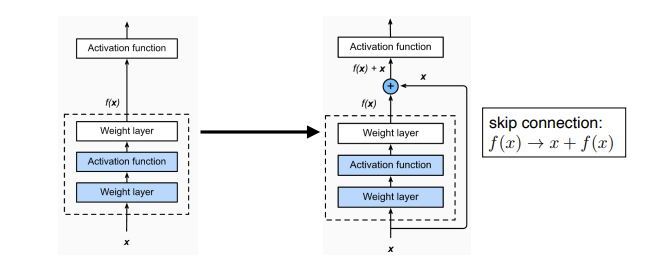
layer가 깊어질 수록 학습은 어려워진다. gradient vanishing, exploding 같은 문제가 발생하기 때문이다. ResNet은 skip connection을 사용하여 모델을 deep하게 쌓을 수 있게 한다. (ResNet 설명 참고)
