
CLIP
CLIP(Contrastive Languate-Image Pre-Training)은 OpenAI에서 만든 멀티모달 모델이다. 이미지와 텍스트에서 공통 특징 공간의 feature를 추출할 수 있다.
cosine similarity
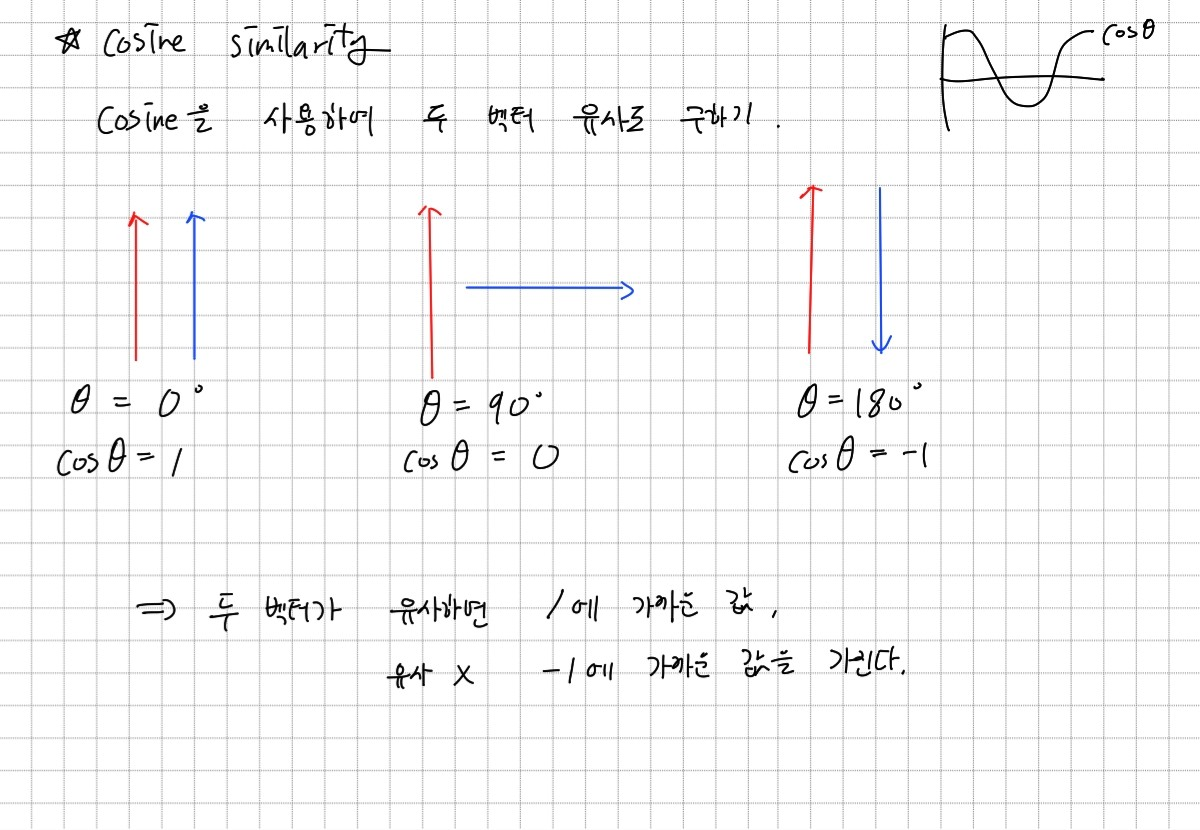
CLIP에서는 이미지에서 추출한 feature와 텍스트에서 추출한 feature가 유사한지 판단하기 위해 Cosine Similarity를 사용한다. Cosine Similiarity는 위와 같이 두 벡터의 유사도를 cosine을 사용하여 수치로 구하는 방법이다.
모델 구조
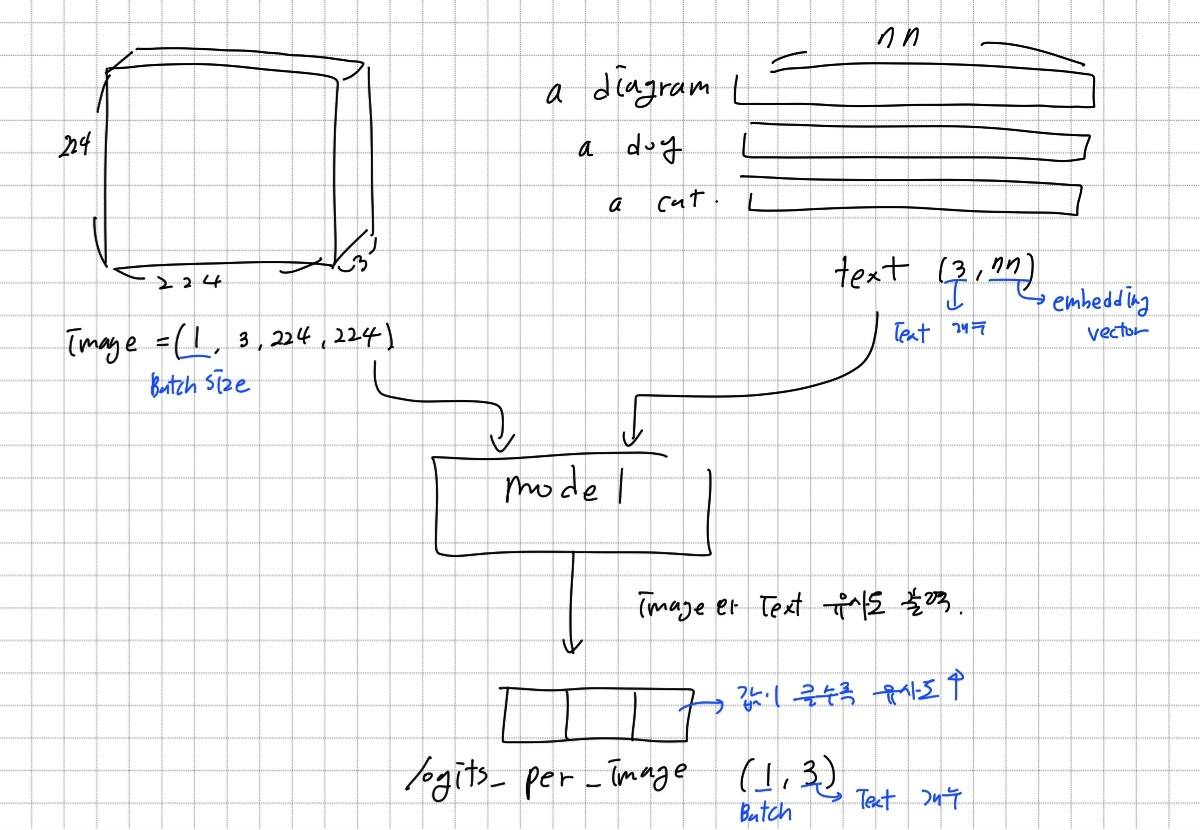
전체적인 모델 구조는 다음고 같다. 입력으로는 224×224 크기의 이미지와 77차원의 텍스트 임베딩 벡터를 받고, 이미지와 텍스트의 유사도가 수치로 나오게 된다. 텍스트를 77차원 벡터로 임베딩할 때는 CLIP 모델 안에 내장된 tokenizer를 사용한다. 결과 값에 softmax 함수를 적용하면 해당 이미지와 가장 유사한 텍스트는 무엇인지 확률로 알 수 있다.
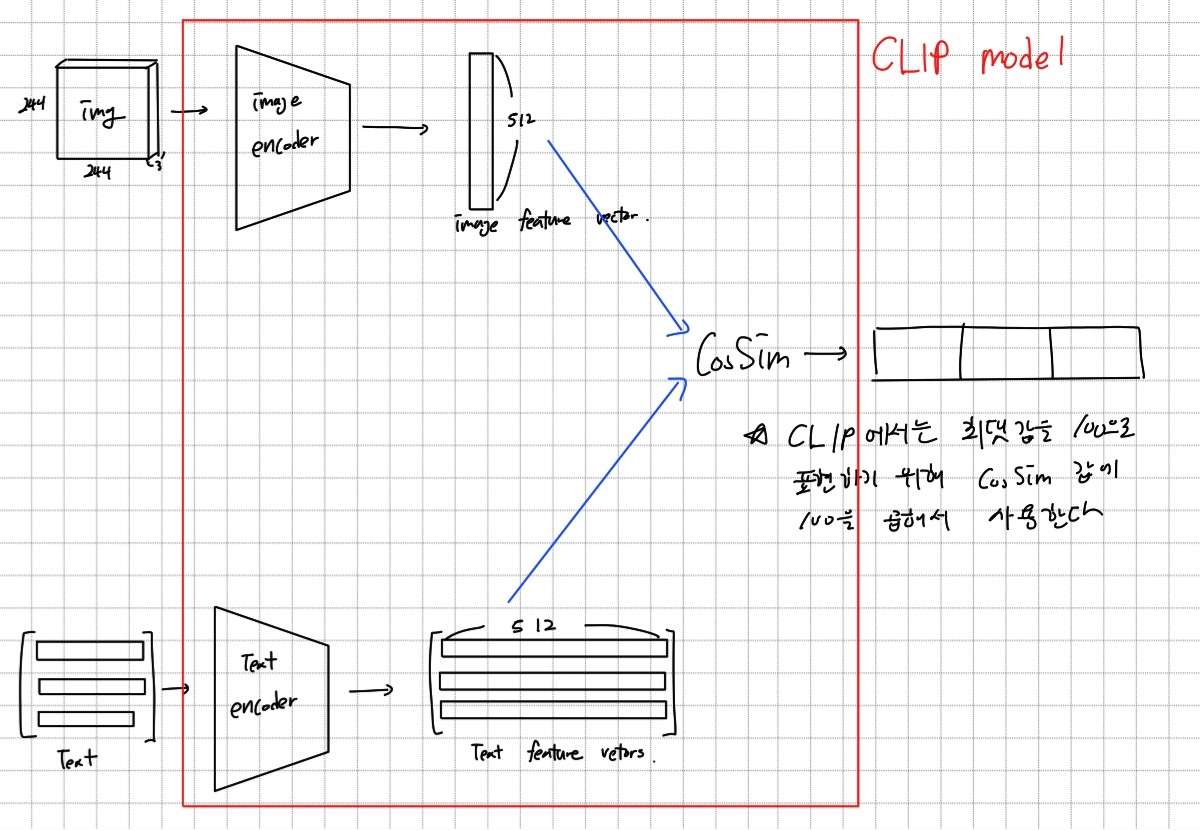
CLIP 모델을 더 자세히 살펴보자. CLIP모델은 Image encoder와 Text encoder로 이미지와 텍스트에 대응하는 feature 벡터를 만든 후 cosine similarity를 사용해 유사도를 구하는 방식으로 작동한다. 따라서 Image encoder와 Text encoder만 사용하여 512차원의 feature vector를 구하는 것도 가능하다.
Text2Image
CLIP 모델을 사용하여 텍스트가 주어지면 해당 텍스트를 잘 반영하는 이미지를 생성하는 생성 모델을 만들어 보자.
Generation Model 구조
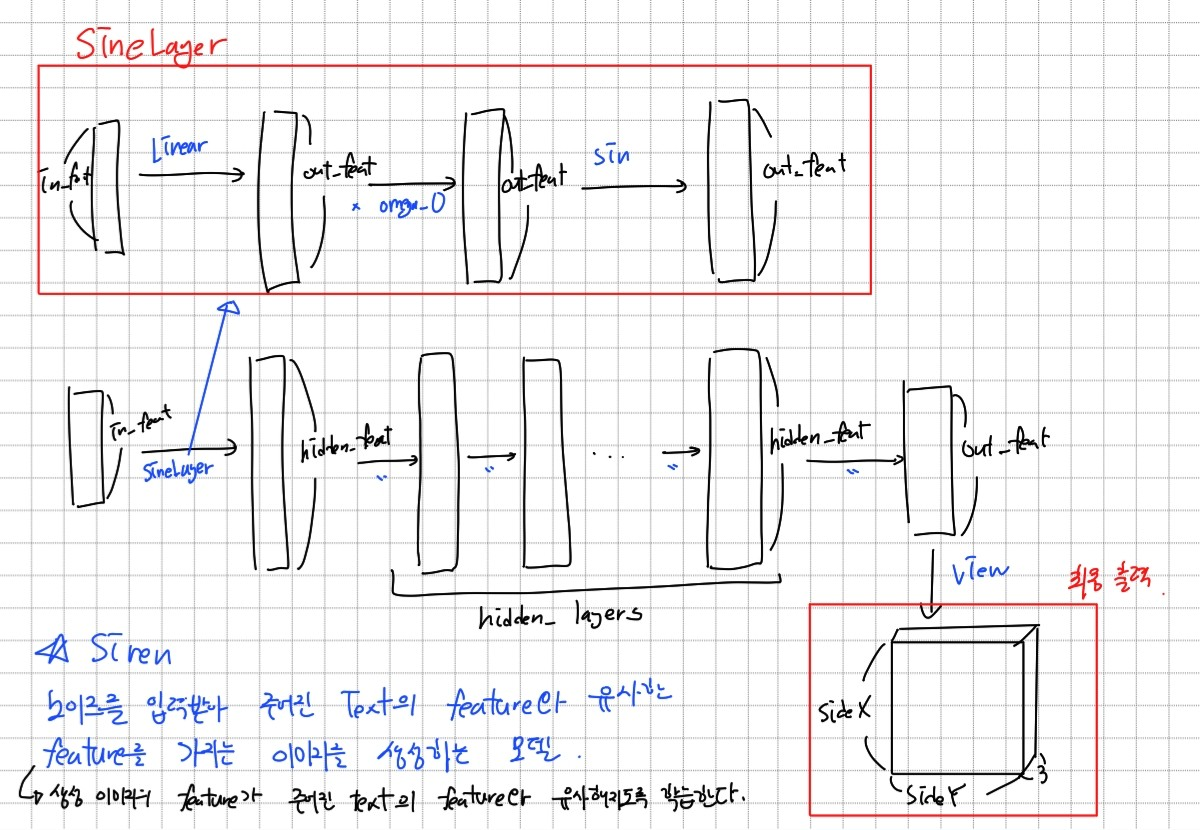
noise를 입력받아 여러층의 SineLayer를 거쳐 최종적으로 정해진 해상도에 맞는 3 채널 이미지를 생성하는 모델이다.
CLIP을 사용하여 학습
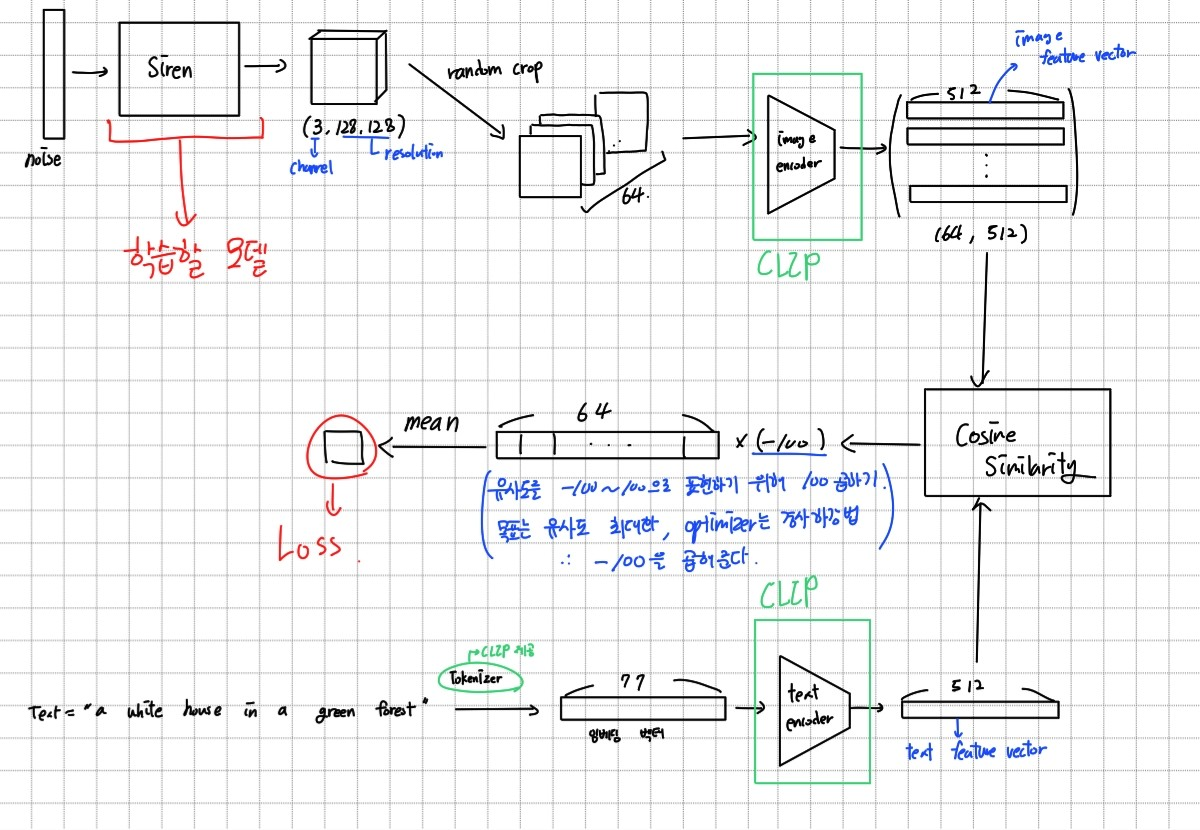
주어진 텍스트에 맞는 이미지를 생성한다는 것은 주어진 텍스트의 feature vector와 생성된 이미지의 feature vector가 유사하다는 것이다. 따라서 CLIP의 image encoder, text encoder로 텍스트와 생성된 이미지의 feature vector를 구하고 이를 생성 모델 학습에 사용한다. 즉 생성된 이미지의 feature vector가 주어진 text의 feature vector와 같아지도록 학습한다고 할 수 있다.
학습되는 부분은 생성모델이다. Image encoder와 text encoder는 이미 학습된 모델이므로 학습하지 않는다.
결과
-
코드 : Image2Text
-
학습 결과 이미지

해상도 128×128, text = "a white house in a green forest"로 200번 학습한 결과이다. 결과가 좋은 편은 아니지만 텍스트가 원하는 느낌은 나는 것 같다. -
학습 과정

노이즈에서 시작하여 학습을 통해 텍스트에 적합한 이미지를 생성하는 것을 볼 수 있다.
