
Generative Model
Generative Model은 입력 데이터의 분포를 학습한다. 이후 해당 분포를 샘플링 하여 원하는 이미지를 만들어 내는 것이다. GAN은 generator와 discriminator로 이루어진다.
Generator: 이미지를 생성하는 객체Discriminator: 입력된 이미지가 실제 이미지인지, 가짜 이미지인지 판단하는 객체
GAN은 Adversarial Training(적대적 학습)을 한다. Generator는 discriminator가 가짜라고 구분할 수 없는 이미지를 만들기 위해 노력하고, Discriminator는 Generator가 생성한 이미지를 구분하기 위해 노력한다. 결국 이런 학습이 지속되다 보면 Generator는 Discriminator가 구분할 수 없는 이미지를 만들게 된다.
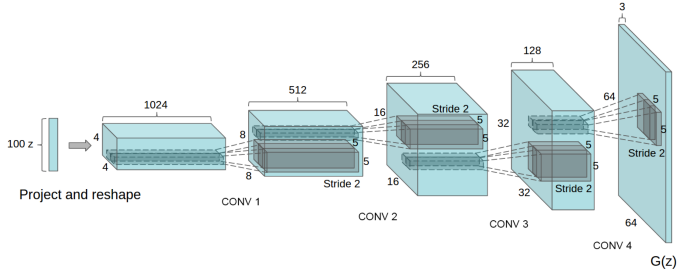
위 그림은 Generator 구조이다. Generator와 Discriminator는 다른 task의 CNN 구조와 별로 다른 점이 없다. GAN이 다른 task와 가장 다른 점은 Loss function 구성이다.
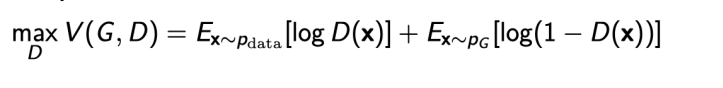
GAN의 loss function은 위와 같다. 먼저 실제 이미지(학습할 데이터)를 Discriminator에 넣어 판별 결과로 loss를 만든다 (첫번째 항). 이후 Generator가 만든 이미지를 Discriminator에 넣어 loss를 만든다(두번째 항). 만약 discriminator가 잘 판별했다면 전체 값이 0에 수렴하고 잘못 판단했다면 -∞로 발산하게 된다.
Loss function을 식으로 보면 어렵다. 의미를 생각하면 조금 쉽게 이해할 수 있다.
예를 들어 discriminator가 실제 이미지라면 1을, generator가 생성한 가짜 이미지라면 0을 출력하다고 하자. 먼저 실제 이미지를 discriminator에 넣고 그 결과가 첫번째 항의 D(x)가 된다. 두번째로 Discriminator에 Generator가 생성한 가짜 이미지를 넣는다. 그러면 그 결과가 두번째 항의 D(x)가 되는 것이다.
우리의 최종 목표는 첫번째 항의 D(x) = 1, 두번째 항의 D(x) = 0이 나오는 것이다. 따라서 잘 최적화가 되면 log(1) + log(1) = 0이 되고, 반대로 잘못 최적화가 된 경우에는 log(0) + log(0) = -∞가 된다.
Conditional Generative Model
Conditional Generative Model은 Generator의 입력으로 noise만 주어지는 것이 아니라 condition이 같이 주어지는 모델이다. Generator는 condition이 주어졌을 때 noise를 기반으로 원하는 이미지를 생성한다.
MNIST 생성하기
0~9를 one-hot vector 라벨과 noise를 입력으로 받아 숫자 이미지를 생성하는 cGAN을 구현하는 과제이다. 0~9의 라벨이 condition이 된다.
구조
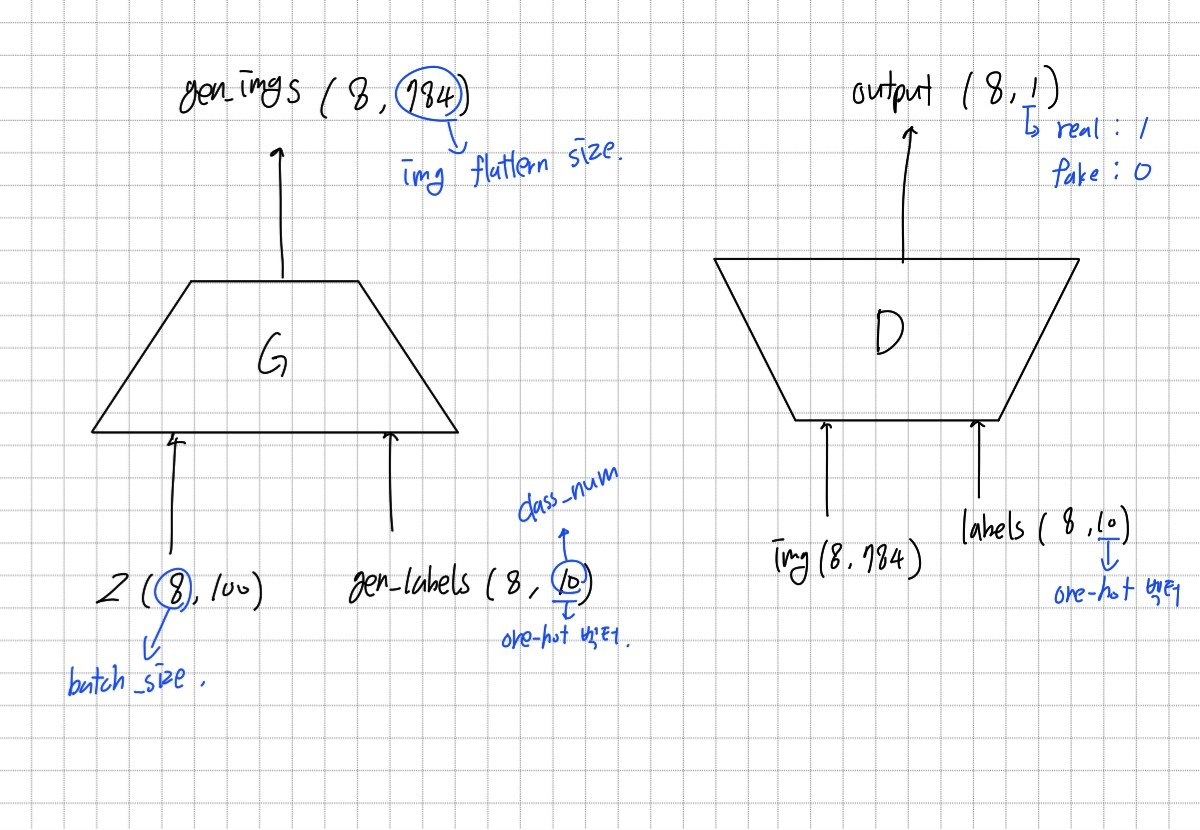
Generator와 Discriminator는 위와 같은 입력과 출력을 가진다.
- 학습 과정
GAN 학습에는 Generator와 Discriminator의 학습이 같이 이루어져야 한다. 따라서 한번의 학습은 Generator를 업데이트 한 뒤 Discriminator를 업데이트 하는 방식으로 구성된다.
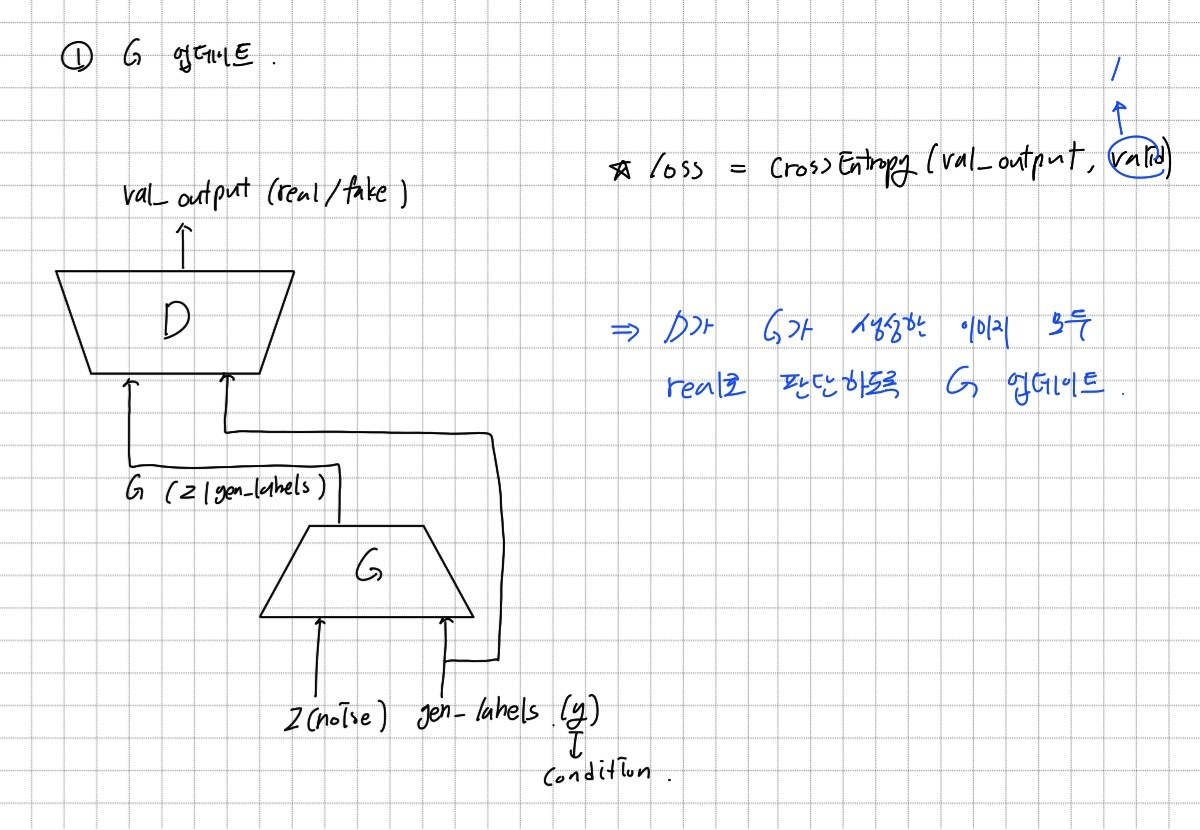
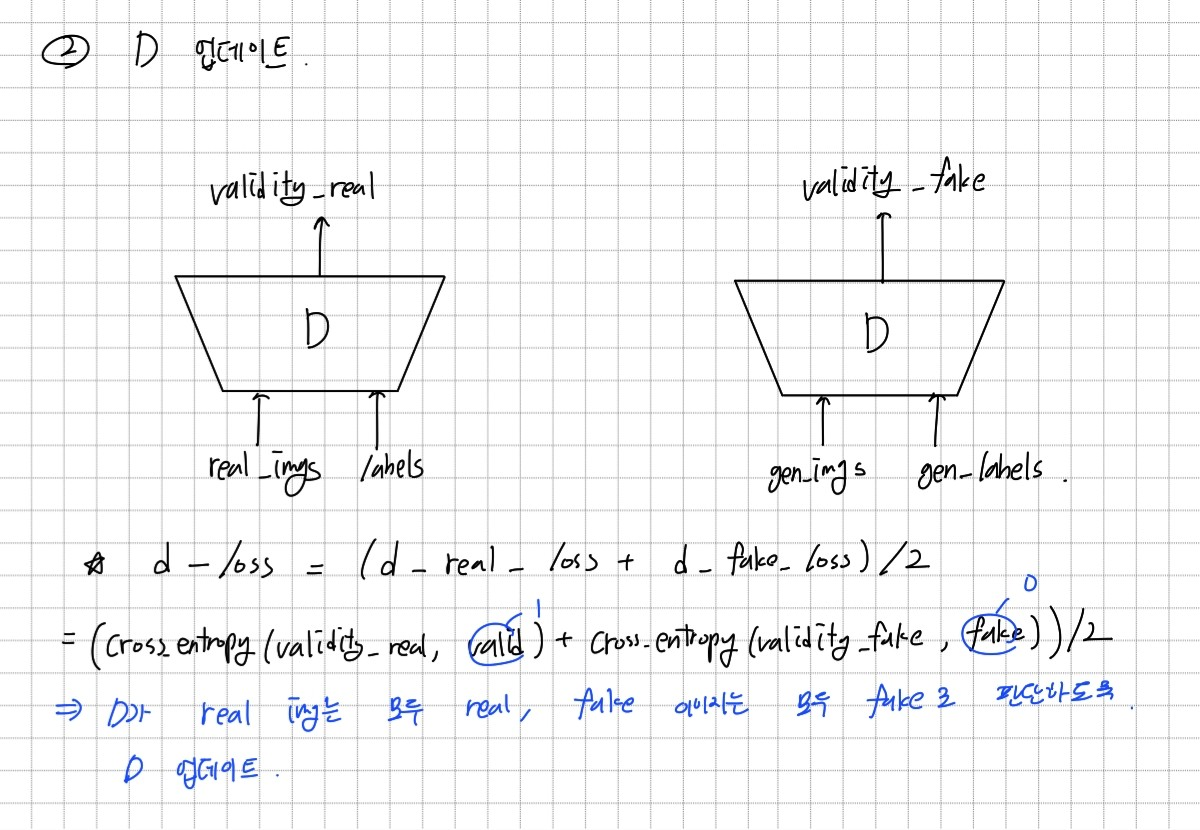
설계
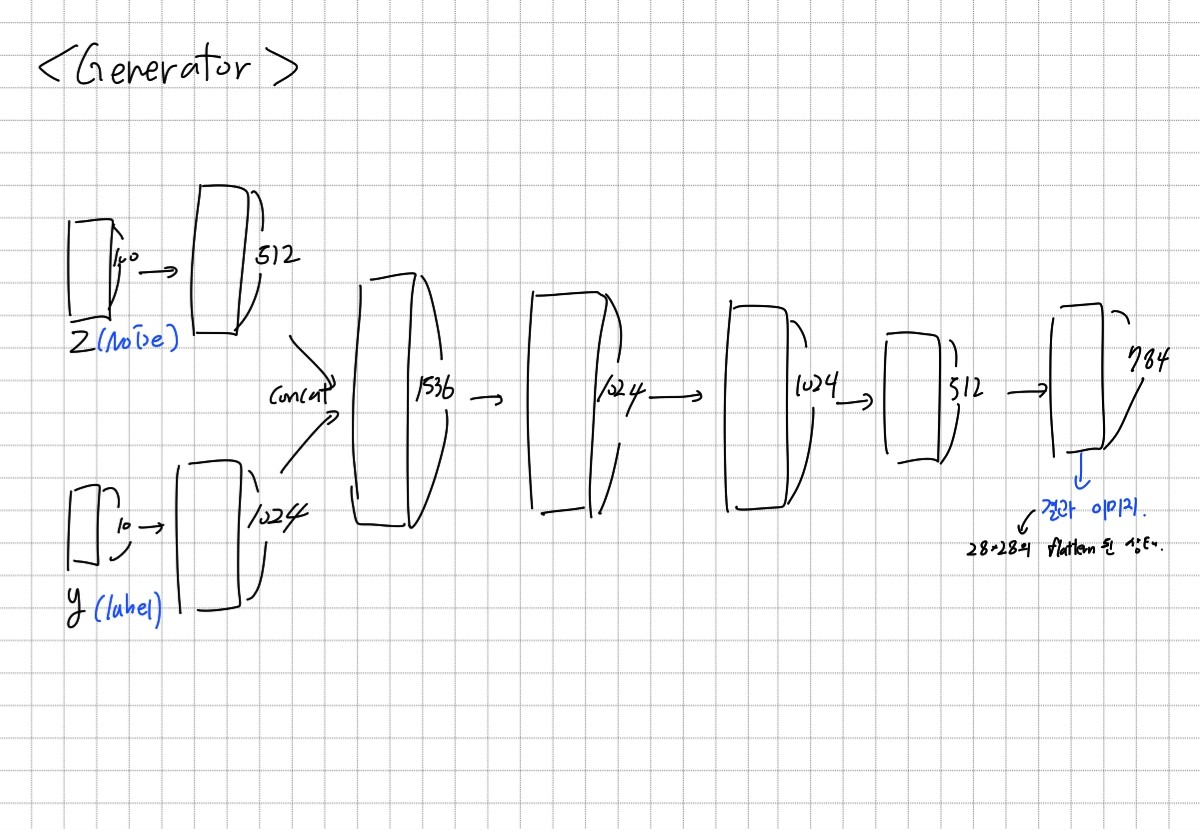
class Generator(nn.Module):
# initializers
def __init__(self):
super(Generator, self).__init__()
self.fc1_1 = nn.Linear(100, 512)
self.bn1_1 = nn.BatchNorm1d(512)
self.fc1_2 = nn.Linear(10, 1024)
self.bn1_2 = nn.BatchNorm1d(1024)
self.fc2 = nn.Linear(1536, 1024)
self.bn2 = nn.BatchNorm1d(1024)
self.fc3 = nn.Linear(1024, 1024)
self.bn3 = nn.BatchNorm1d(1024)
self.fc4 = nn.Linear(1024, 512)
self.bn4 = nn.BatchNorm1d(512)
self.fc5 = nn.Linear(512, 784)
self.bn5 = nn.BatchNorm1d(784)
# weight initialization
self.weight_init(mean=0.0, std=0.01)
# weight_init
def weight_init(self, mean, std):
for m in self._modules:
normal_init(self._modules[m], mean, std)
# forward method
def forward(self, input, label):
z = self.fc1_1(input)
z = self.bn1_1(z)
z = nn.ReLU()(z)
y = self.fc1_2(label)
y = self.bn1_2(y)
y = nn.ReLU()(y)
x = torch.cat((z, y), dim = 1)
x = self.fc2(x)
x = self.bn2(x)
x = nn.ReLU()(x)
x = self.fc3(x)
x = self.bn3(x)
x = nn.ReLU()(x)
x = self.fc4(x)
x = self.bn4(x)
x = nn.ReLU()(x)
x = self.fc5(x)
x = self.bn5(x)
x = nn.Sigmoid()(1.1*x)
return x각 linear transform 뒤에는 Batch normalization과 ReLU를 사용했다. 마지막 출력 부분은 Sigmoid를 사용한다. 중간값을 없애고 검은색과 흰색이 더 잘 구분되면 좋을 것 같아서 Simoid에 1.1을 곱해서 넣어줬다.
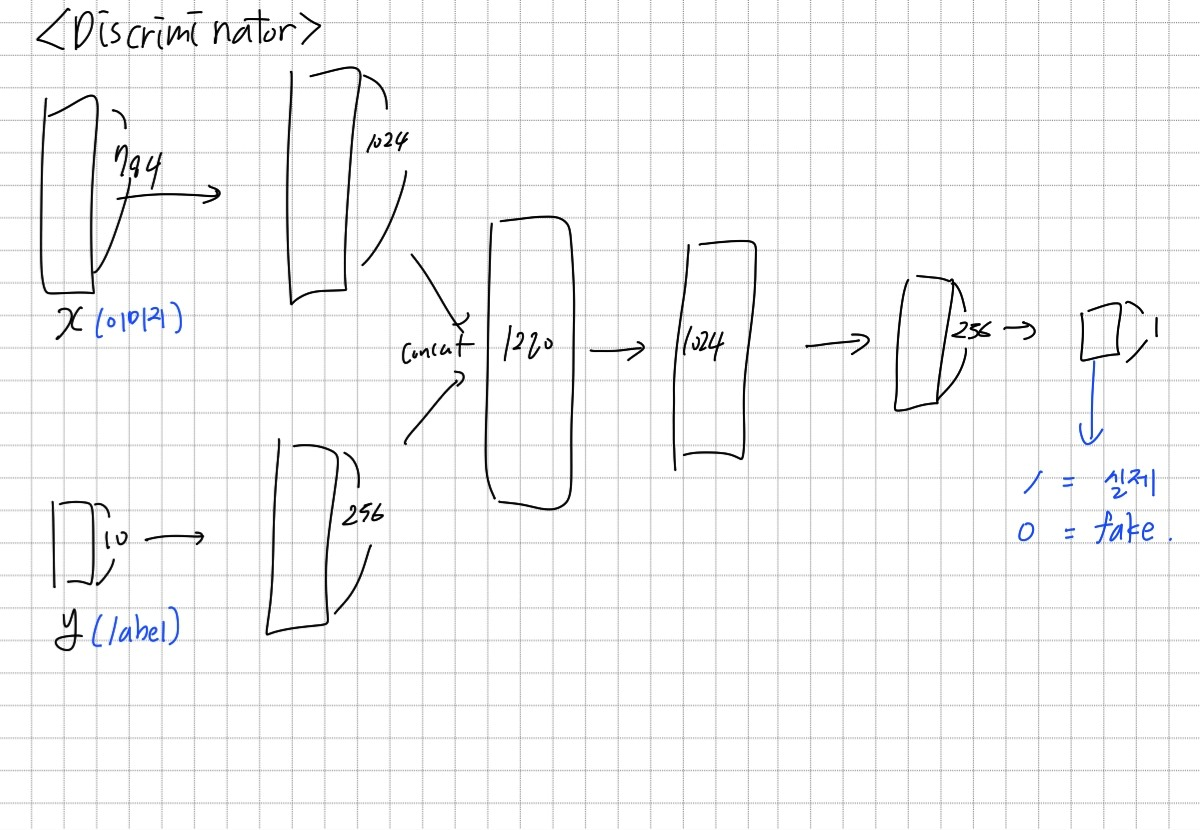
class Discriminator(nn.Module):
# initializers
def __init__(self):
super(Discriminator, self).__init__()
self.fc1_1 = nn.Linear(784, 1024)
self.bn1_1 = nn.BatchNorm1d(1024)
self.fc1_2 = nn.Linear(10, 256)
self.bn1_2 = nn.BatchNorm1d(256)
self.fc2 = nn.Linear(1280, 1024)
self.bn2 = nn.BatchNorm1d(1024)
self.fc3 = nn.Linear(1024,256)
self.bn3 = nn.BatchNorm1d(256)
self.fc_out = nn.Linear(256, 1)
self.sigmoid = nn.Sigmoid()
self.weight_init(0, 0.01)
# weight_init
def weight_init(self, mean, std):
for m in self._modules:
normal_init(self._modules[m], mean, std)
# forward method
def forward(self, input, label):
z = self.fc1_1(input)
z = self.bn1_1(z)
z = nn.ReLU()(z)
y = self.fc1_2(label)
y = self.bn1_2(y)
y = nn.ReLU()(y)
x = torch.cat((z, y), dim = 1)
x = self.fc2(x)
x = self.bn2(x)
x = nn.ReLU()(x)
x = self.fc3(x)
x = self.bn3(x)
x = nn.ReLU()(x)
x = self.fc_out(x)
x = self.sigmoid(x)
return x결과
-
학습 모델 : model.pt
-
학습 결과

batch size를 32, learning rate를 0.001로 50 epochs 학습시켰다. 위 그림은 epochs 별로 0~9를 생성한 이미지이다.
중앙에 숫자가 생기는 부분은 노이즈가 덜 생기고 테두리는 노이즈로 인해 하얀색이 많다. 노이즈를 좀 없애고 싶어서 sigmoid 함수를 사용하였는데 왜 중앙 부분이 원 형태로 나타나는지 잘 모르겠다.
+2023.04.06 내용 추가
가운데 원형을 제외하고 테두리에 노이즈가 생기는 이유는 Discriminator가 중앙의 숫자 부분에서만 특징을 추출하여 분류하기 때문으로 추측한다. Genorator는 Discriminator를 잘 속이는 방향으로 학습하는데 테두리 부분은 Discriminator의 판단에 영향을 미치지 않아서 학습이 안되는 것이 아닐까?
