GPU
CPU와 GPU
CPU는 순차처리 방식 특화, GPU는 병렬처리 방식 특화이다.

작은 연산을 수행할 때는 CPU와 GPU가 데이터를 주고받는 시간이 더 크기 때문에 CPU연산이 GPU 연산보다 빠르다. 병렬적으로 처리할 수 있는 매우 큰 연산은 GPU를 사용하는 것이 좋다.
Graphic Processing Unit
그래픽 처리, 3D 모델링을 위한 프로세서로 탄생하였다.
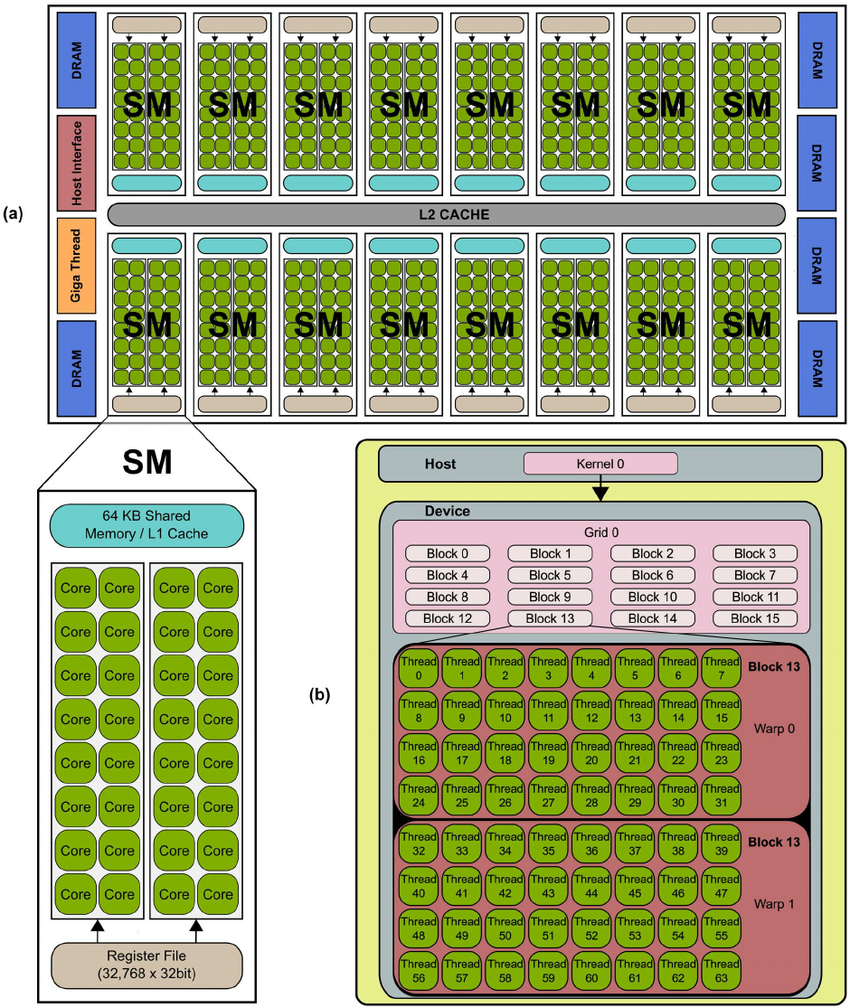
- host : 일반적인 CPU, 컴퓨터
- device : 병렬프로세서(GPU)
호스트로부터 병렬 프로그램 코드가 GPU로 전송되면, 스트리밍 다중프로세서(SM)들로 적절히 할당되어 처리된다. SM들은 실제 프로그램 코드를 실행하는 스트리밍 프로세서(SP)들로 구성된다.
초기 GPU 프로그래밍을 위해서는 GPU 내부 구조와 그래픽 API를 알아야 하고, 너무 복잡하다는 단점이 있었다. NVIDIA가 CUDA 프로그래밍 모델을 도입하면서 GPU가 널리 보급되기 시작하였다.
CUDA
CUDA는 일반적인 프로그래밍 언어로 GPU 프로그램을 쉽게 작성할수 있게 해주는 플랫폼이다. NVIDIA가 개발하였다.
CUDA 프로그램은 호스트가 실행하는 호스트 코드와 디바이스가 실행하는 디바이스 코드로 이루어진다. 두 코드는 컴파일 과정에서 분리된다.
호스트 코드 : ANSI C
디비이스 코드 : ANSI C +kernel function(커널 함수)
- 커널함수의 한 인스턴스를
스레드(thread)라고 부르고, 이는 GPU의 Core에 의해 실행된다.
CUDA 프로그램
// kernal function
__global__ void VecAdd(float *A, float *B, float *C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
VecAdd<<<1, N>>> (A, B, C);
...
}커널 코드는 __global__ 선언 지정자로 정의한다. 커널에 의해 생성될 블록 수와 스레드 수는 실행 구문 <<<...>>>지정 한다. 각 블록은 하난의 SM으로 할당된다.
호스트가 순차적으로 코드를 실행하다 커널 함수가 호출되면 병렬 커널 코드가 디바이스로 보내진다. 디바이스에서 커널이 SM, SP를 할당하고 SP가 한 스레드를 담당하여 실행한다. 모든 스레드 실행이 완료되면 결과 값이 호스트로 전송된다.
PyTorch의 Cuda
PyTorch는 CUDA를 지원한다. 이는 PyTorch가 NVIDIA GPU를 활용하여 모델을 학습하고 실행할 수 있음을 의미한다. PyTorch에서는 CUDA 커널과 유사한 연산을 수행하는 내장 함수를 제공한다. 따라서 사용자는 CUDA 커널 함수를 직접 작성하지 않아도 된다.
간단한 예시
import torch
# CUDA 디바이스 설정
device = torch.device('cuda')
# 텐서 생성
x = torch.randn(3, 3)
# 텐서를 CUDA 디바이스로 이동
x = x.to(device)
# 모델 정의
model = torch.nn.Linear(3, 1)
# 모델을 CUDA 디바이스로 이동
model = model.to(device)
# 모델 추론
output = model(x)
# 결과를 CPU로 이동하여 출력
print(output.to('cpu'))PyTorch의 텐서나 모델을 GPU로 이동시켜야 GPU에서 연산이 가능하다. 일반적으로 GPU는 CPU보다 메모리가 작기 때문에 연산이 모델 학습이 끝난 뒤에는 최종 결과를 CPU로 가져와 출력, 저장한다.
GPU/CPU로 tensor 보내기
- cuda (CPU -> GPU)
x = torch.tensor([1., 2., 3.]).cuda() # default : 가장 작은 cuda
# x = torch.tensor([1., 2., 3.]).cuda("cuda:0")- cpu (GPU -> CPU)
x_gpu = torch.tensor([1., 2., 3.]).cuda()
x_cpu = x_gpu.cpu()- to ( -> DEVICE)
x = torch.tensor([1., 2., 3.])
x_gpu = x.to("cuda:0")
x_cpu = x_gpu.to("cpu")to는 cuda, cpu와 달리 cpu/gpu간 이동 뿐만 아니라 다른 장치(ex. Mobile, TPU...)로의 이동도 지원한다.
주의 할 점
-
Tensor
Tensor의 cuda/cpu/to를 호출하면, 현재 Tensor가 변경되는 것이 아니라 원하는 device에 현재 Tensor를 copy한 새로운 객체가 생기는 것이다. -
Module

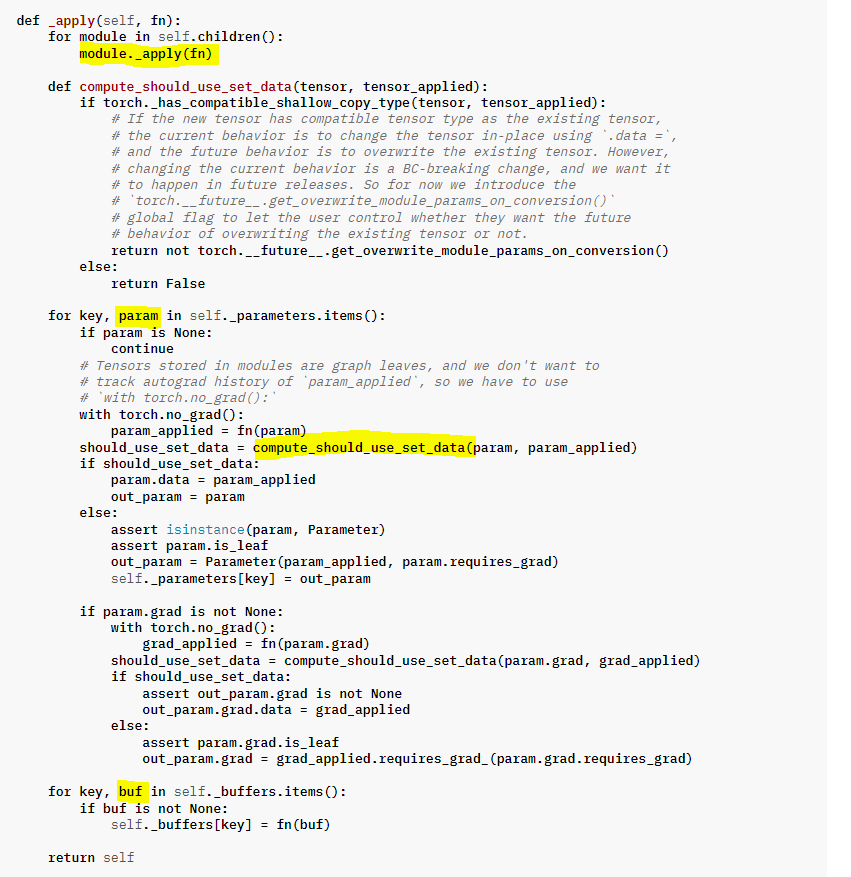
Module에서는 cuda/cpu/to를 호출하면 __apply함수를 사용하여 현재 Module의 모든 subModule에 cuda/cpu/to를 호출한다. 이때 Module에 포함된 Parameter가 새로운 객체로 변경되는 경우 compatible하다면 현재 Module의 parameter에 덮어써진다. 따라서 Optimizer를 생성하기 전에 파라미터와 버퍼를 device로 이동시켜야 한다.
cuda/cpu/to 활용 코드
# GPU 사용가능여부 확인
import torch
torch.cuda.is_available() # True
# GPU 이름 확인 (cuda : 0)
torch.cuda.get_device_name() # 'Tesla T4'
# 사용 가능한 CPU 개수
torch.cuda.device_count() # 1
# CPU에 선언
model = torch.nn.Linear(10,10)
x = torch.tensor([1.,2.,3.,4.,5.,6.,7.,8.,9.,10.])
y = torch.tensor([10.,9.,8.,7.,6.,5.,4.,3.,2.,1.])
print(model.weight.device) # cpu
print(model.bias.device) # cpu
print(x.device) # cpu
print(y.device) # cpu
# GPU로 이동
x_gpu = x.cuda()
# x_gpu = x.to("cuda:0")
print(x_gpu.device) # cuda:0
# Tensor to GPU
x_gpu[0] = 100.
print(x)
print(x_gpu)
print(x is x_gpu) # False
# Modeul to GPU (Optimizer 주의)
model_gpu = model.cuda()
print(model_gpu.weight.device)
print(model_gpu.bias.device) # True
print(model.weight is model_gpu.weight)
# CPU, GPU간 연산
model = torch.nn.Linear(10,10)
model(x_gpu) # RuntimeError
# gpu 연산
model = torch.nn.Linear(10,10).cuda()
result_gpu = model(x_gpu)
print(result_gpu)
print(result_gpu.device)
# 결과 cpu로 가져오기
result = result_gpu.cpu()
print(result)
print(result.device)참고
- cpu와 gpu : https://biz.chosun.com
- GPU : https://www.researchgate.net
- 김종현.『컴퓨터구조론(개정5판)』. 생능출판, 2022.
