Deep Learning
Deep Learning이란

사람의 지능을 모방한 것을 인공지능이라고 한다. 인공 지능 중에 데이터를 통해 학습하는 것을 Machine Learning이라 하고, 그 중에서도 학습에 Neural Network를 활용하는 방법을 Deep Learning이라 한다.
key component
Data: Model이 학습할 정보Model: Data를 원하는 결과로 변환하는 연산 구조Loss: Model의 성능을 측정하는 지표Algorithm: loss를 최소화하기 위한 Parameter 조정 방법
Deep learning 논문을 읽을 때 위의 4가지를 고려하면서 읽으면 해당 논문의 contirubution을 파악하기 쉽다.
Neural Networks
Neural Network(인공신경망)은 인간의 두뇌 신경세포를 모방한 모델이다. Deep learning은 인공 신경망 여러 층으로 깊게 쌓아서 사용하는 것이다. Neural Network가 잘 작동하는 이유는 단순히 뇌를 모방했기 때문은 아니다. 현재의 Neural Network의 동작은 뇌의 동작과는 많이 다르다. (역전파 등)
Linear Neural Networks
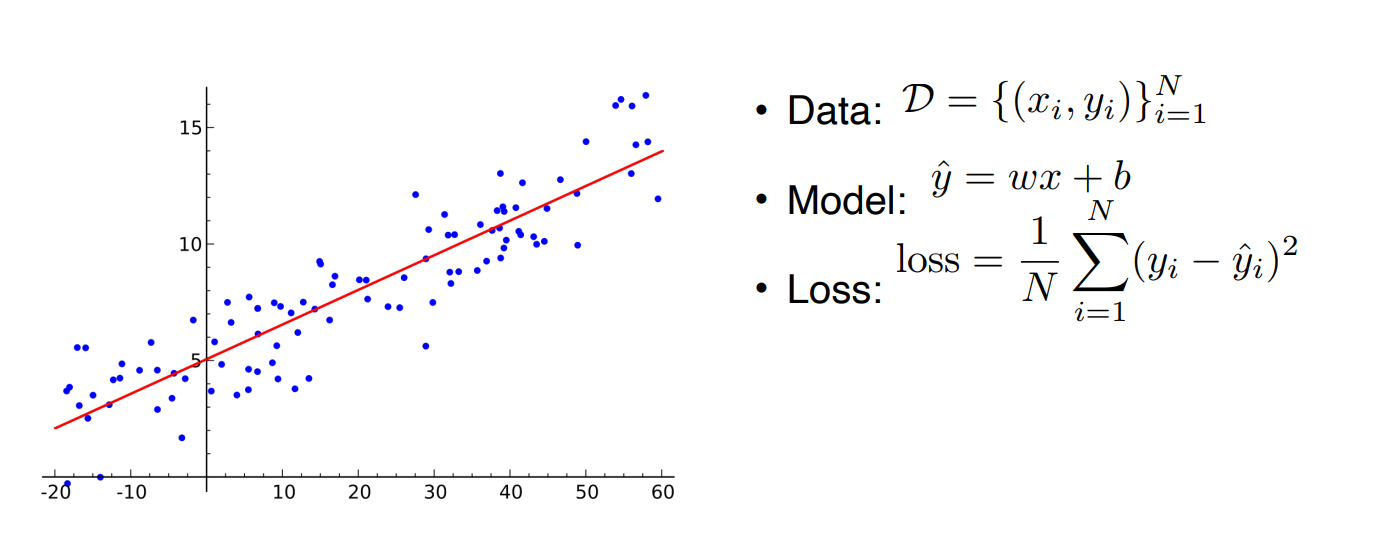
Linear Neural Network는 선형회귀를 나타낸다. Linear Neural Network를 학습시키는 것은 기울기 W와 절편 b를 찾는 것을 의미한다. 일반적으로 편미분 값을 이용하여 SGD, Adam 등의 최적화 방법을 사용한다.
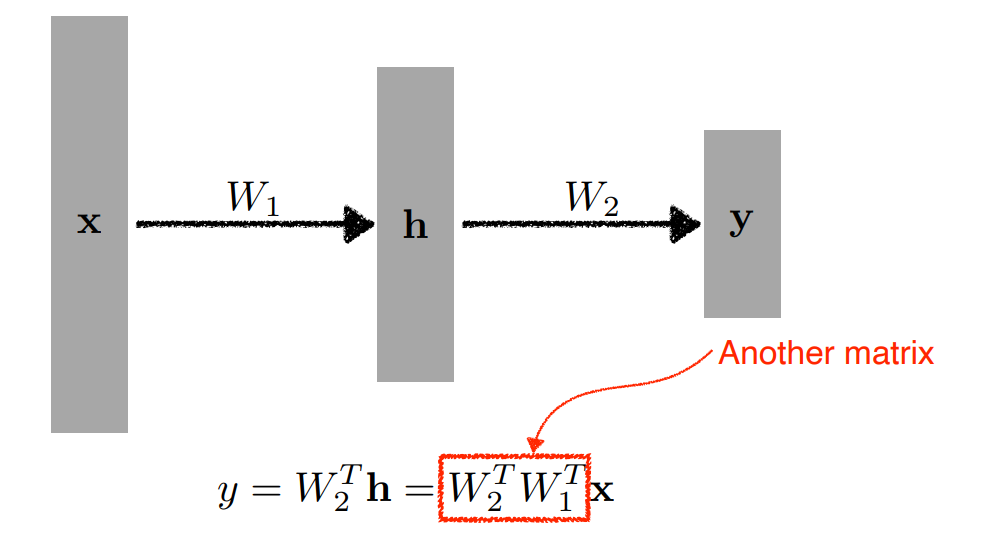
위와 같이 Linear Neural Network 여러개를 쌓을 수도 있다. 하지만 이 경우에는 결국 Linear Neural Network를 하나 사용하는 것과 다를 것이 없다.
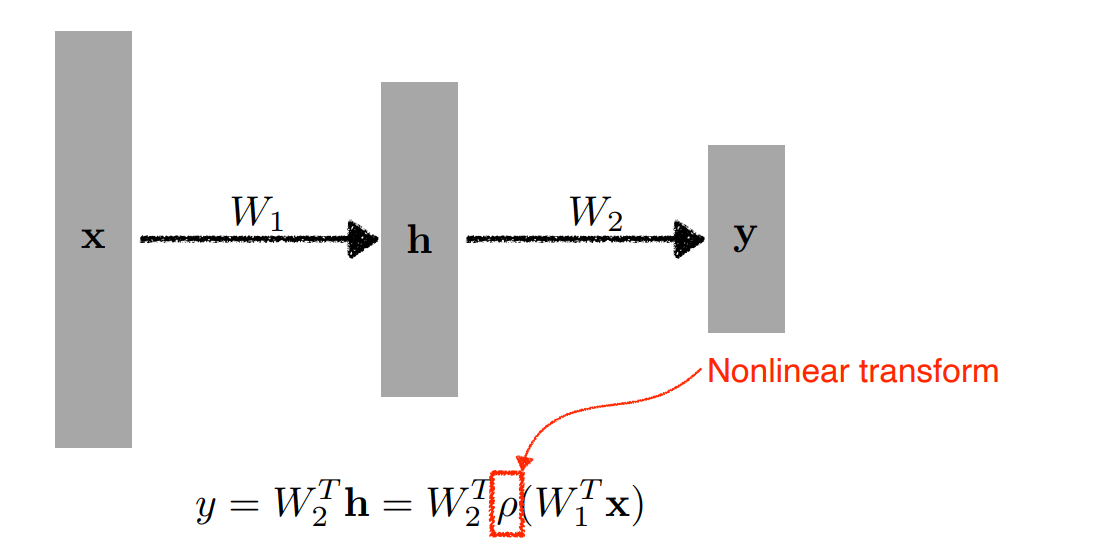
따라서 선형 변환 뒤 비선형 함수를 사용해서 Neural Network의 표현력을 극대화한다.
Activation Function
선형 변환 뒤 Neural Network의 표현력을 극대화하기 위해 사용하는 비선형 함수를 activation function이라고 한다. ReLU, Sigmoid, Hyperbolic Tangent 등을 사용할 수 있다.
Universal Approximation Theorem
Neural Network를 여러 층으로 쌓을 때 입력과 출력을 제외한 층을 Hidden layer라고 한다. Hidden layer가 있으면 거의 모든 연속함수를 근사할 수 있다는 것이 Universal Approximation Theorem이다. 연속함수를 근사할 수 있다는 것은 Model의 표현력이 높다는 것으로 Neural Network가 잘 작동하는 이유이다.
하지만 주의할 점은 우리가 학습시킨 모델이 원하는 연속함수를 근사하는 것이 아니라는 점이다. Universal Approximation Theorem이 말하는 것은 세상 어딘가에 우리가 원하는 연속함수를 근사하는 Neural Network가 있다는 것이지, 우리가 학습시킨 모델이 그 Network라는 의미가 아니다.
Multi-layer Perceptron
Percentron(퍼셉트론)은 다수의 값을 입력받아 하나의 값으로 출력하는 인공 신경망이다. 입력층과 출력층 사이에 1개 이상의 Hidden layer가 있는 경우 Multi-layer Perceptron(다층 퍼셉트론)이라 한다.
MLP 구현
-
사용할 데이터

torchvision의 MNIST Dataset을 사용한다. MNIST는 손으로 쓰여진 숫자 이미지로 구성된다. 이미지는 gray scale의 28*28 사이즈이다. 라벨은 0~9이다. -
MLP 구조
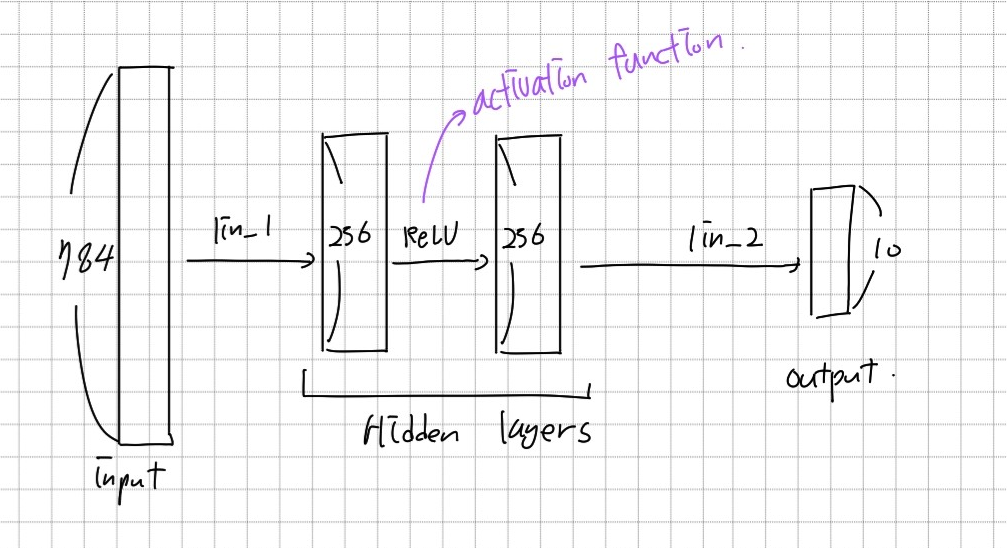
MNIST의 이미지를 입력으로 받아 10개 카테고리의 One-hot vector를 출력하는 모델을 만들려고 한다. 따라서 입력 크기는 28*28이 되고, 출력 크기는 10이다.
- 데이터 준비
from torchvision import datasets,transforms
# dataset
mnist_train = datasets.MNIST(root='./data/',train=True,transform=transforms.ToTensor(),download=True)
mnist_test = datasets.MNIST(root='./data/',train=False,transform=transforms.ToTensor(),download=True)
# dataloader
BATCH_SIZE = 256
train_iter = torch.utils.data.DataLoader(mnist_train,batch_size=BATCH_SIZE,shuffle=True,num_workers=1)
test_iter = torch.utils.data.DataLoader(mnist_test,batch_size=BATCH_SIZE,shuffle=True,num_workers=1)- MLP 모델 정의
# 모델 정의
class MultiLayerPerceptronClass(nn.Module):
"""
Multilayer Perceptron (MLP) Class
"""
def __init__(self,name='mlp',xdim=784,hdim=256,ydim=10):
super(MultiLayerPerceptronClass,self).__init__()
self.name = name
self.xdim = xdim
self.hdim = hdim
self.ydim = ydim
self.lin_1 = nn.Linear(xdim, hdim)
self.lin_2 = nn.Linear(hdim, ydim)
self.init_param() # initialize parameters
def init_param(self):
nn.init.kaiming_normal_(self.lin_1.weight)
nn.init.zeros_(self.lin_1.bias)
nn.init.kaiming_normal_(self.lin_2.weight)
nn.init.zeros_(self.lin_2.bias)
def forward(self,x):
net = x
net = self.lin_1(net)
net = F.relu(net)
net = self.lin_2(net)
return net
# 모델 생성
M = MultiLayerPerceptronClass(name='mlp',xdim=784,hdim=256,ydim=10).to(device)parameter 초기화
- weight
weight는nn.init.kaiming_normal_함수를 사용하여 초기화 하였다.
위와 같이 입력, 출력의 크기에 따른 std를 가지는Normal distribution을 따르는 값으로 weight값을 초기화하는 함수이다. weight를 이렇게 초기화하는 이유는vanishing gradient와exploding gradient를 방지하기 위해서이다.- bias는 모두 0으로 초기화했다.

- optimizer와 loss function
# loss function
loss = nn.CrossEntropyLoss()
# optimizer
optm = optim.Adam(M.parameters(),lr=1e-3)- 평가
def func_eval(model,data_iter,device):
with torch.no_grad():
model.eval() # evaluate (affects DropOut and BN)
n_total,n_correct = 0,0
for batch_in,batch_out in data_iter:
y_trgt = batch_out.to(device)
model_pred = model(batch_in.view(-1, 28*28).to(device))
_,y_pred = torch.max(model_pred.data,1)
n_correct += (y_trgt == y_pred).sum().item()
n_total += batch_in.size(0)
val_accr = (n_correct/n_total)
model.train() # back to train mode
return val_accr- 학습
M.init_param() # initialize parameters
M.train()
EPOCHS,print_every = 10,1
for epoch in range(EPOCHS):
loss_val_sum = 0
for batch_in,batch_out in train_iter:
# Forward path
y_pred = M.forward(batch_in.view(-1, 28*28).to(device))
loss_out = loss(y_pred,batch_out.to(device))
# Update
optm.zero_grad() # reset gradient
loss_out.backward() # backpropagate
optm.step() # optimizer update
loss_val_sum += loss_out
loss_val_avg = loss_val_sum/len(train_iter)
# Print
if ((epoch%print_every)==0) or (epoch==(EPOCHS-1)):
train_accr = func_eval(M,train_iter,device)
test_accr = func_eval(M,test_iter,device)
print ("epoch:[%d] loss:[%.3f] train_accr:[%.3f] test_accr:[%.3f]."%
(epoch,loss_val_avg,train_accr,test_accr))train() / eval()
nn.Module은 dropout layer와 같이 train 단계와 test 단계에서 다르게 작동해야하는 module을 위해작업 switching 방법을 제공한다.eval()함수는 Module을 evaluation(inference) mode로 바꿔준다.train()은 Module을 training Mode로 바꿔준다.
참고
- Perceptron : https://heytech.tistory.com/332
- kaimimg initialization : https://towardsdatascience.com
