딥러닝 프레임워크
딥러닝을 구현할 때 모든 것을 처음부터 구현할 수도 있다. 하지만 일반적으로는 이미 만들어져 있는 프레임워크를 사용하여 딥러닝을 구현한다. 많은 사람들이 사용하는만큼 자료가 많고, 표준으로 사용되기 때문이다. 대표적인 딥러닝 프레임워크로는 PyTorch와 TensorFlow가 있다.
PyTorch와 TensorFlow
Computational Graph
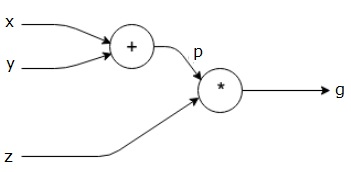
위의 그림과 같이 연산의 과정을 표현한 그래프를 Computational Graph라고 한다. 딥러닝 모델은 순차적으로 층을 통과하며 연산이 진행된다. 이 순서를 표현하는 방법으로 Computational graph를 사용한다. Computational graph를 사용하면 연산을 분해하고 단순화할 수 있으며, 연산 결과를 단계별로 저장할 수 있다. 이를 통해 역전파의 미분 과정을 쉽게 파악할 수 있다는 장점을 가진다.
PyTorch vs TensorFlow
PyTorch와 TensorFlow의 가장 큰 차이점은 computational graph를 생성하는 방식이다.
- Define and Run
Define and Run은 실행 전 작성된 코드를 바탕으로 미리 그래프를 정의하고 실행 시점에 데이터를feed하는 방식이다. - Define by Run (Dynamic Computational Graph, DAG)
Define by Run은 코드를 실행하면서 그래프를 생성하는 방식이다.
Tensorflow는 Define and Run 방식을 사용하고, PyTorch는 Define by Run방식을 사용한다. 두 방식은 디버깅에서 큰 차이가 난다. Define and Run 방식은 실제 데이터를 feed 하기 전까지는 중간 결과를 확인할 수 없다. 값이 들어가야 확인이 가능하기 때문이다. 반면 Define by Run 방식은 중간 결과를 확인할 수 있다. 실행 중 그래프를 구성하기 때문에 실행 중간에 여러 조건을 조정할 수 있다는 장점도 있다.
이처럼 PyTorch는 개발 과정과 디버깅이 장점으로 연구 분야에 많이 사용된다. 반면 Tensorflow는 Google에서 제공하는 도구로 실제 제품 개발, 상품화에 장점을 가지고 있다.
PyTorch
PyTorch는 Numpy + AutoGrad + Function(DL 함수)라고 할 수 있다.
PyTorch documentation : https://pytorch.org/docs/stable/index.html
패키지 구성
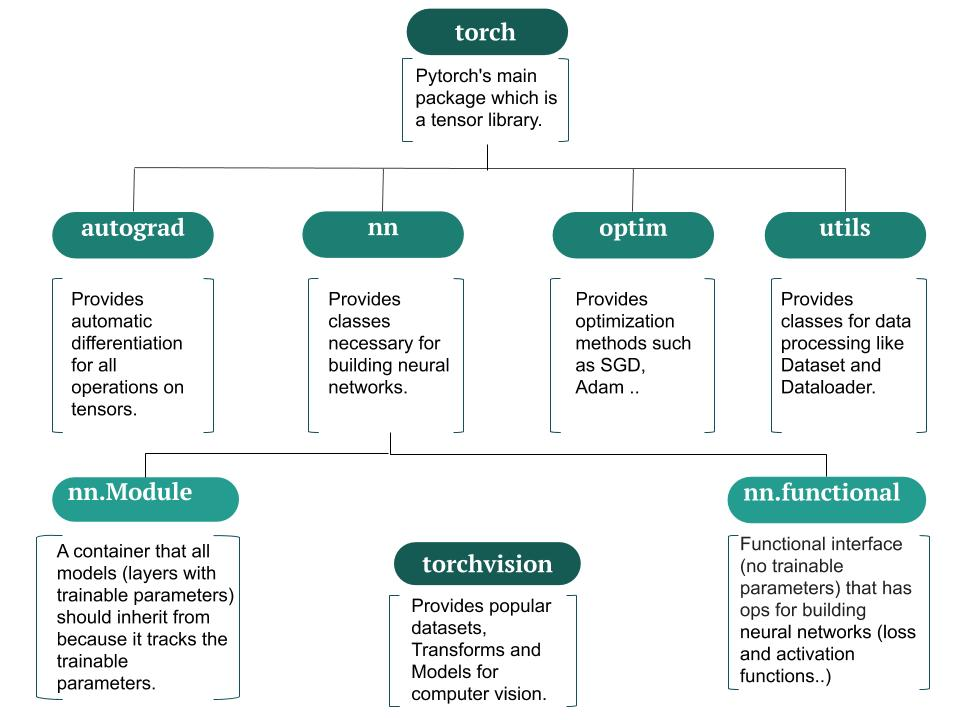
autograd:자동 미분을 지원하는 함수들이 포함되어 있다.nn: 모델 구축을 위한데이터 구조 및 레이어가 정의되어 있다.optim: 파라미터최적화 알고리즘이 구현되어 있다.torchvision: 유명한computer vision데이터에 대해 dataset, transformer, model이 이미 구현되어 있는 라이브러리이다.
일반적인 학습 과정
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from network import CustomNet
from dataset import ExampleDataset
from loss import ExampleLoss
###############
# 1. Modeling #
###############
# 모델 생성
model = CustomNet()
model.train()
# 옵티마이저 정의
params = [param for param in model.parameters() if param.requires_grad]
optimizer = optim.Example(params, lr=lr)
# 손실함수 정의
loss_fn = ExampleLoss()
############################
# 2. Dataset & DataLoader #
############################
# 학습을 위한 데이터셋 생성
dataset_example = ExampleDataset()
# 학습을 위한 데이터로더 생성
dataloader_example = DataLoader(dataset_example)
#################################################
# 3. Transfer Learning & Hyper Parameter Tuning #
#################################################
for e in range(epochs):
for X,y in dataloader_example:
output = model(X)
loss = loss_fn(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()일반적으로 학습은 위와 같은 구조를 가진다. 모델 준비 → 데이터 준비 → 학습 순으로 어떤 모델이나 최적화 방법을 사용해도 큰 흐름은 동일하다.
PyTorch Project Templete
개발 초기에는 결과를 바로 확인할 수 있는 대화식 개발 과정 (Jupyter...)이 유리하다. 하지만 배포 및 공유 과정에서는 프로젝트로 관리하는 것이 더 편하다. 프로젝트로 관리하면 개발 용이성 확보 및 유지보수가 쉬워진다는 장점도 있다. 일반적인 DL 프로젝트 구조는 다음과 같다.

Templete은 여러 파일로 나누어져있지만 앞에서 설명한 일반적인 학습 과정을 여러 파일에 나누어 놓은 것과 같다. trainer.py에는 학습 부분이, model.py에는 모델 준비 과정이 있는 식이다.
Templete
참고
- PyTorch 구조 : https://manalelaidouni.github.io
- computational graph : https://www.tutorialspoint.com, https://gr-st-dev.tistory.com/28
