Tensor
PyTorch에서는 Array를 Tensor라는 클래스로 표현한다. Numpy의 ndarray와 사용법이 거의 동일하다. 다만 Tensor는 GPU에 올려서 사용가능하다.
- view / reshape
view와 reshape모두 tensor의 shape을 변환하는 함수이다. 다만contiguity보장에는 차이가 있다. array는 메모리상에 연속적으로 저장된다. 이를 contiguity라고 하는데,view는 contiguity를 보장하지 않는 경우 error를 발생시켜 원래 tensor와 새로운 tensor가 값을 공유하는 것을 보장한다.
반면reshape은 contiguity를 보장하지 못하는 경우 값을copy하여 새로운 array를 만들어 사용한다. 따라서 reshape은 contiguity를 보장할 수 있으면 view와 같이 동작하고, 보장할 수 없으면 copy하여 새로운 array를 사용하여 shape을 변화한 값을 반환한다.
# view - contiguity 보장 가능
a = torch.tensor([1,2,3,4,5,6])
b = a.view(2,3)
b[0][0] = 10
a # [10,2,3,4,5,6]
# view - contiguity 보장 불가능
a = torch.tensor([[1,2],[3,4],[5,6]])
b = a.t()
b = b.view(6) # error 발생# reshape - contiguity 보장 가능
a = torch.tensor([1,2,3,4,5,6])
b = a.reshape(2, 3) # view와 동일
b[0][0] = 10
a # [10,2,3,4,5,6]
# reshape - contiguity 보장 불가능
a = torch.tensor([[1,2],[3,4],[5,6]])
b = a.t()
b = b.reshape(6) # copy 반환
b[0] = 10
a # [[1,2],[3,4],[5,6]]Transpose
T,t(),transpose()등 전치행렬을 구하는 경우에는 contiguity가 깨지지 않고 원래 행렬과 값이 공유된다.
- squeeze / unsqueeze
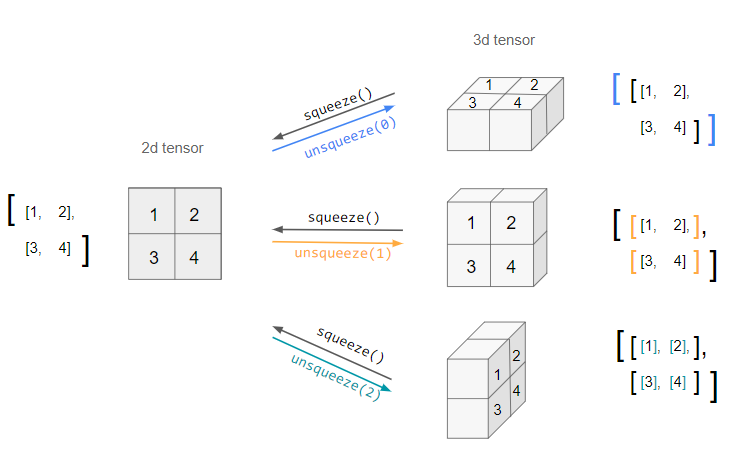
squeeze함수는차원 크기가 1인 모든 차원을 제거한다. 만약 파라미터를 dim을 지정해주는 경우에는 해당 차원만 제거한다.
unsqueeze함수는 특정 위치에크기가 1인 차원을 생성한다. 차원을 추가하는 것이므로 어느 차원을 추가할 것인지 꼭 dim 파라미터를 통해 지정해주어야 한다.
Module
Module은 neural network를 만드는데 기본이 되는 class이다. torch.nn 모듈에 포함되어 있다. Module은 Module을 포함할 수 있어 Tree구조와 같은 network를 구성할 수 있다.
function → layer → model
1.function: Module에 최소한의 기능을 담은 객체
2.layer: Module에 여러 function을 담은 객체
3.model: Module에 여러 layer를 담은 객체
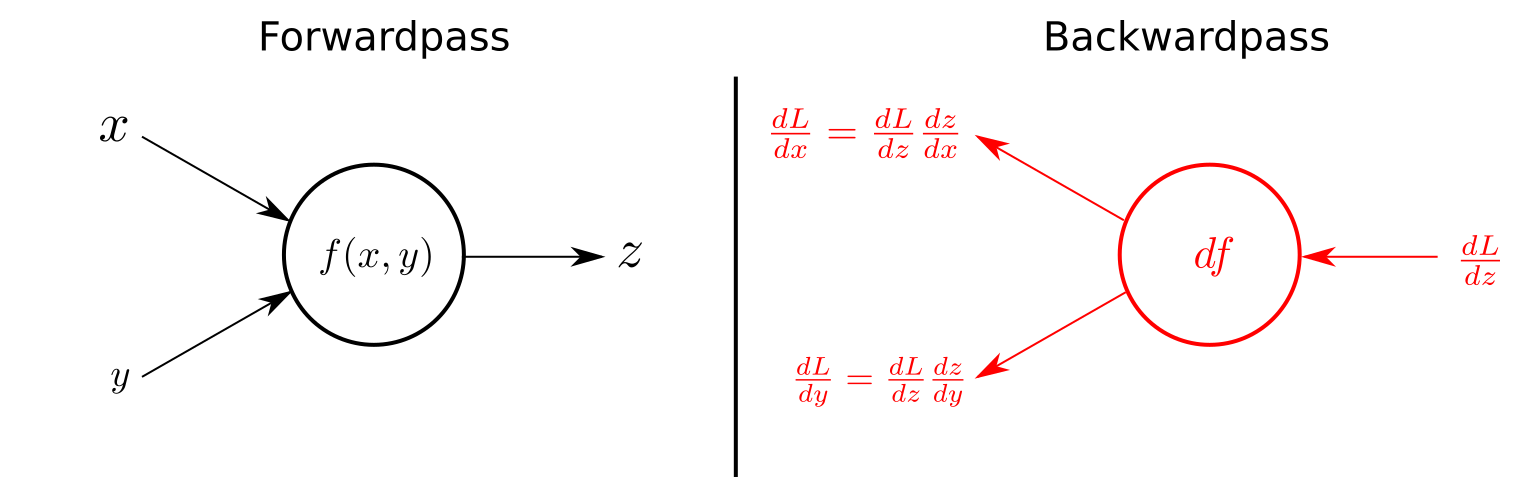
forward
forward 함수는 Module 호출시 수행 할 연산을 정의하는 Module의 멤버 함수이다. forward 함수는 Module을 정의하기 위해 무조건 overriding 해야한다. 만약 overriding 하지 않으면 NotImplementedError가 발생한다.
backward
Module은 backward 함수를 정의할 필요가 없다. PyTorch는 Autograd(자동 미분)을 지원하기 때문이다. Backward 함수는 모듈 내부의 Parameter의 미분을 수행하고 기울기를 grad 변수에 저장한다. (Autograd 참고)
Parameter
Tensor를 상속받는 객체로 학습의 대상을 의미하는 객체이다. nn.Module의 attribute가 되면 텐서에 대한 기울기를 저장하겠다는 의미인 requires_grad가 True가 자동으로 지정된다. Module 내에서 사용할 경우 Tensor와 달리 자동으로 Module의 parameter라는 attribute에 추가된다.
Tensor vs Parameter vs Buffer
| tensor | Parameter | Buffer | |
|---|---|---|---|
| gradient 계산 | X | O | X |
| 값 업데이트 | X | O | X |
| 모델 저장시 값 저장 | X | O | X |
Custom model 만들기
import torch
from torch import nn
from torch.nn.parameter import Parameter
# Function
class Funcion1(nn.Module):
def __init__(self):
super().__init__()
self.W = Parameter(torch.rand(2, 2))
def forward(self, x):
return x + self.W
class Funcion2(nn.Module):
def __init__(self):
super().__init__()
self.W = Parameter(torch.rand(2, 2))
def forward(self, x):
return x - self.W
class Funcion3(nn.Module):
def __init__(self):
super().__init__()
self.W = Parameter(torch.rand(2, 2))
def forward(self, x):
return x * self.W
class Funcion4(nn.Module):
def __init__(self):
super().__init__()
self.W = Parameter(torch.rand(2, 2))
def forward(self, x):
return x / self.W
# Layer
class Layer1(nn.Module):
def __init__(self):
super().__init__()
self.func1 = Funcion1()
self.func2 = Funcion2()
def forward(self, x):
x = self.func1(x)
x = self.func2(x)
return x
class Layer2(nn.Module):
def __init__(self):
super().__init__()
self.func3 = Funcion3()
self.func4 = Funcion4()
def forward(self, x):
x = self.func3(x)
x = self.func4(x)
return x
# Model
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = Layer1()
self.layer2 = Layer2()
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
return x
model = MyModel()참고
- forward, backward : https://github.com/Vercaca/NN-Backpropagation
