Pytorch에서 Tensor를 복사하는 방법은 다양하다. 다양한 방법들은 Tensor를 복사한다는 점에서는 같은 역할을 하지만 requires_grad, Computational graph 유지, 메모리 공유에서 조금씩 차이가 있다.
python 코드 : 소스코드
1. copy_
x = torch.tensor([1.], requires_grad = True)
y = torch.tensor([1.], requires_grad = True)
z = x + y
z_copy = torch.empty_like(z).copy_(z)- requires_grad = 원래 tensor의 requires_grad
- computational graph 복사 : O
- 메모리 공유 : X
2. .data
x = torch.tensor([1.], requires_grad = True)
y = torch.tensor([1.], requires_grad = True)
z = x + y
z_copy = z.data
print(z_copy)
print(z_copy.requires_grad)- requires_grad = False
- computational graph 복사 : X
- 메모리 공유 : O
3. detach
x = torch.tensor([1.], requires_grad = True)
y = torch.tensor([1.], requires_grad = True)
z = x + y
z_copy = z.detach()
print(z_copy)
print(z_copy.requires_grad)- requires_grad = False
- computational graph 복사 : X
- 메모리 공유 : O
.data와 detach 차이
.data와 detach는 requires_grad = False이고 기존 tensor의 데이터를 공유하며, 기존 tensor의 computational graph와 관련없는 Tensor를 반환한다. .data와 detach의 차이는 안전성이다. .data는 경우에 따라 정확힌 gradient를 보장하지 못할 수도 있다. 그러나 detach는 정확한 gradient를 보장한다.
# .data
x = torch.tensor([1.], requires_grad = True)
y = torch.tensor([1.], requires_grad = True)
z = x*x + y
x_copy = x.data
x_copy.zero_()
z.backward()
# x.grad = 0
# y.grad = 1# detach
x = torch.tensor([1.], requires_grad = True)
y = torch.tensor([1.], requires_grad = True)
z = x*x + y
x_copy = x.detach()
x_copy.zero_()
z.backward() # runtime error.data를 사용하는 경우에는 원래 tensor 데이터가 변경되어도 autograd가 변경사항을 추적하지 않는다. 복사된 tensor에 의해 원본 값이 변경된 경우 backward 함수는 변경된 값을 사용해 gradient를 구한다. 반면 detach는 원본 데이터의 변경사항을 autograd가 추적한다. 따라서 복사된 tensor가 원본 값을 변경하는 경우 runtime error를 발생시킨다.
따라서 .data 보다는 detach를 사용하는 것이 좋다.
4. clone
x = torch.tensor([1.], requires_grad = True)
y = torch.tensor([1.], requires_grad = True)
z = x + y
z_copy = z.clone()
print(z_copy)
print(z_copy.requires_grad)- requires_grad = 원래 tensor의 requires_grad
- computational graph 복사 : O
- 메모리 공유 : X
5. clone + detach
# clone.detach
x = torch.tensor([1.], requires_grad = True)
y = torch.tensor([1.], requires_grad = True)
z = x + y
z_copy = z.clone().detach()
print(z_copy)
print(z_copy.requires_grad)# detach.clone
x = torch.tensor([1.], requires_grad = True)
y = torch.tensor([1.], requires_grad = True)
z = x + y
z_copy = z.detach().clone()
print(z_copy)
print(z_copy.requires_grad)- requires_grad = False
- computational graph 복사 : X
- 메모리 공유 : X
clone과 detach를 같이 사용하는 것이 tensor copy에 가장 추천되는 방법이다.
6. tensor
x = torch.tensor([1.], requires_grad = True)
y = torch.tensor([1.], requires_grad = True)
z = x + y
z_copy = torch.tensor(z)
print(z_copy)
print(z_copy.requires_grad)- requires_grad = False
- computational graph 복사 : X
- 메모리 공유 : X
torch.tensor(t)는 t.clone().detach()와 같다.
torch.tensor(t, reauiresgrad = True)는 t.clone().detach().requires_grad(True)와 같다.
7. new_tensor
x = torch.tensor([1.], requires_grad = True)
y = torch.tensor([1.], requires_grad = True)
z = x + y
z_copy = z_copy.new_tensor(z)
print(z_copy)
print(z_copy.requires_grad)- requires_grad = False
- computational graph 복사 : X
- 메모리 공유 : X
torch.newtensor(x)는 x.clone().detach()와 같다.
torch.new_tensor(x, reauires_grad = True)는 x.clone().detach().requires_grad(True)와 같다.
정리
| copy method | reqires_grad | computational graph copy | memory 공유 |
|---|---|---|---|
| copy | 원래 tensor의 requires_grad | O | X |
| .data | False | X (leaf node) | O |
| detach | False | X (leaf node) | O |
| clone | 원래 tensor의 requires_grad | O | X |
| clone + detach | False | X (leaf node) | X |
| tensor | False | X (leaf node) | X |
| new_tensor | False | X (leaf node) | X |
속도
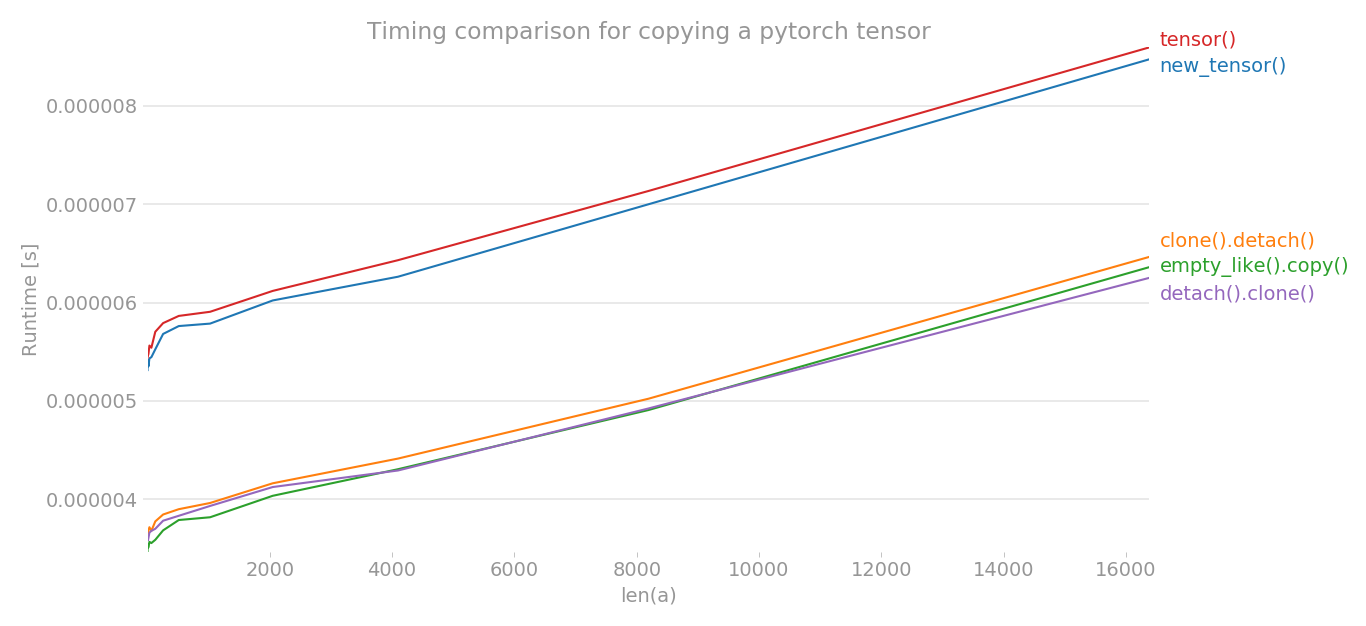
detach().clone()이 clone().detach()보다 빠른 이유
clone을 먼저하면 사용하지 않을 computational graph도 복사해야 한다. 따라서 computational graph를 복사하지 않는 detach().clone()보다 copy 속도가 느리다.
참고
copy 속도 : https://stackoverflow.com
