Save and Load
학습 결과를 공유하거나, 재연성을 향상하기 위해서는 모델을 저장할 필요가 있다. Pytorch는 모델을 pickle로 저장할 수 있는 함수 torch.save를 제공한다. 모델 저장은 architecture와 parameter를 같이 저장하는 모델 저장 방식과 Parameter만 저장하는 파라미터 저장방식으로 나뉜다.
모델 저장
# 모델 save
torch.save(model, path) # model을 path에 저장
# 모델 load
new_model = torch.load(path) # path에 저장한 모델 불러오기파라미터 저장
# 파라미터 save
torch.save(model.state_dict(), path) # model의 parameter를 path에 저장
# 파라미터 load
new_model_parameters = torch.load(path) # path의 parameter정보를 load
new_model.load_state_dict(new_model_parameters) # parameter 정보를 model에 적용checkpoints
early stopping과 같은 기법을 사용하기 위해서는 학습의 중간 결과를 저장하고, 원하는 순간의 모델을 불러와야 한다. 일반적으로는 모델이나 파라미터만 저장하는 것이 아니라 epoch, loss 등을 같이 저장한다. Checkpoint는 torch.save를 사용해 모델의 정보를 epoch, loss와 같은 부가 정보와 같이 저장하는 것을 의미한다. 여러 정보를 dictionary 형식으로 저장하고 불러와 dictionary처럼 사용한다.
# path에 원하는 정보를 dict로 저장
torch.save({'epoch' : e, 'loss' : l, 'model_state' : model.state_dict(), 'optimizer_state' : optimizer.state_dict()}, path)
# checkpoint 불러와 사용하기
checkpoint = torch.load(path)
model.load_state_dict(checkpoint['model_state'])
optimizer.load_state_dict(checkpoint['optimizer_state'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']Transfer learning
Transfer Learning이란 다른 데이터로 학습한 모델을 현재 데이터에 적용하는 방법이다. 일반적으로 대용량 데이터를 사용하여 만들어진 모델의 성능이 높다. 따라서 성능을 높이기 위해 대용량 데이터로 학습한 backbone architecture를 현재 데이터에 맞게 일부분만 변경하여 사용한다.
Freezing
Transfer learning 중에서 backbone architecture에 다른 layer를 붙여서 모델을 다시 훈련시키는 방법을 fine-tuning이라고 한다. 기존 학습된 모델을 기반으로 architecture를 목적에 맞게 변형하고, 가중치를 미세하게 조정시키는 것이다. 이러한 Fine Tuning 전략 중 하나가 Freezing이다.
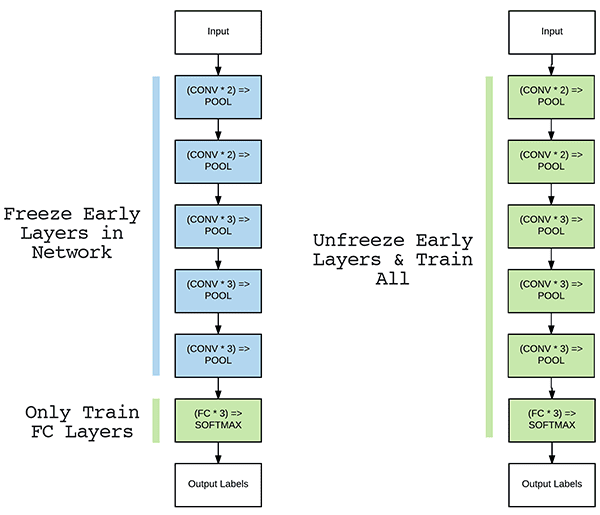
Freezing은 pretrained model을 활용할 때 모델의 일부분을 frozen 시킨다. Frozen된 부분은 학습 중 파라미터의 업데이트가 발생하지 않는다.
참고
- checkpoint : https://jimmy-ai.tistory.com/310
- transfer learning : https://newindow.tistory.com/254
- freezing : https://pyimagesearch.com
