Data feeding
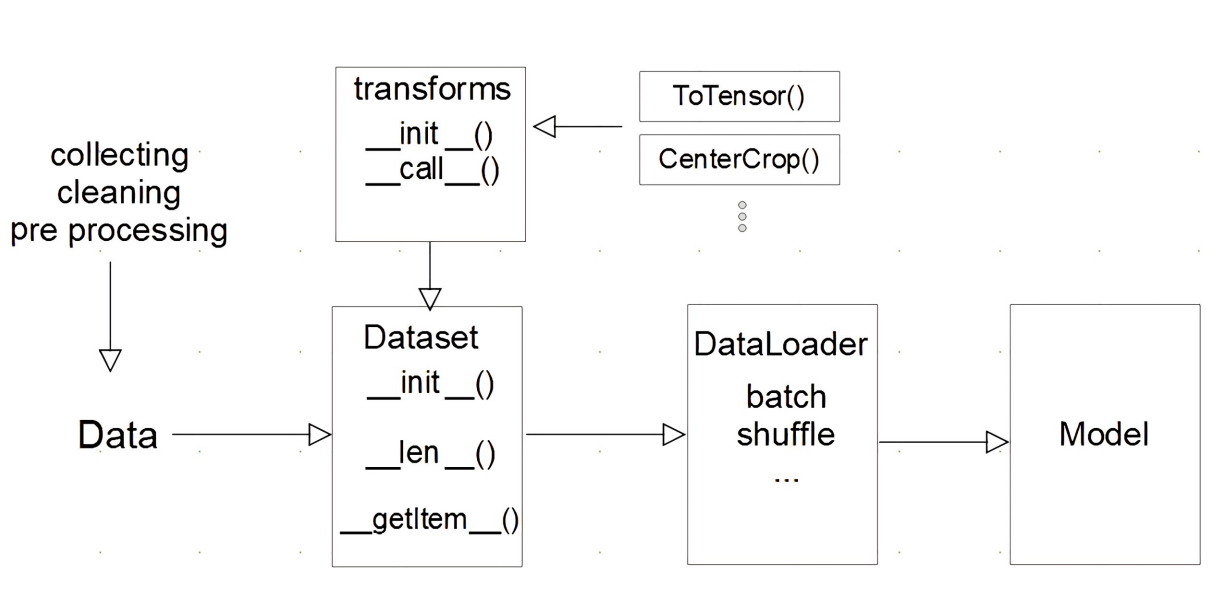
Model에 데이터를 feeding하는 흐름은 위와 같다. 데이터는 Dataset과 DataLoader를 통해 Model에 제공된다.
Dataset
Dataset은 데이터를 읽어와 전처리까지 책임진다. 즉 데이터가 무엇이든 Model에 들어가는 데이터는 표준화된 데이터가 되도록 데이터 입력 형태를 정의하는 클래스이다. torch.utils.data.Dataset 클래스를 상속받아 만들 수 있다. Dataset을 만들 때 구현해야 할 함수는 __init__, __getitem__과 __len__이다. __len__ 함수는 필수적으로 구현하지는 않아도 되지만 Dataloader에서 sampler를 사용하기 위해서는 구현하는 것이 좋다.
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self,):
# 데이터를 불러온다.
pass
def __len__(self):
# 데이터의 길이를 반환한다.
pass
def __getitem__(self, idx):
# 데이터를 transform하여 반환한다.
passDataloader
Dataloader는 Model에 데이터를 feeding하기 위해 사용하는 클래스이다. 데이터의 Batch를 생성한다. Dataloader는 dataset을 인자로 요구한다. 사용할 수 있는 옵션은 다음과 같다.
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)- batch_size : batch 사이즈
- shuffle : 데이터를 섞어서 사용
- sampler : 데이터의 index를 컨트롤 (shuffle은 False이어야 사용할 수 있다.)
- collate_fn : 데이터를 batch 단위로 바꾸기 위해 필요한 기능
(즉,((피처1, 라벨1) (피처2, 라벨2))와 같은 배치 단위 데이터가((피처1, 피처2), (라벨1, 라벨2))와 같이 바꿀수 있도록 하는 함수를 넣어준다.)
